►
From YouTube: Scaling Jitsi Meet in the Cloud Tutorial
Description
Overview and guide on how to setup Jitsi Meet to scale and load balance in a cloud environment such as AWS. Add capacity and geo-redundancy.
Subscribe for our new videos: http://bit.ly/2QVLZCG
See more at https://jitsi.org
Try it now at https://meet.jit.si
Download the Jitsi Meet package or iOS and Android apps: https://jitsi.org/downloads/
See the code at https://github.com/jitsi/jitsi-meet
A
Hello,
everyone
and
welcome
to
cloud
auto-scaling
and
H
a
proxy
balancing
for
a
GT
meet.
We
are
continuing
the
series
with
a
tutorial
for
launching
large
GT
me,
distillation,
z--,
the
free
and
open-source
web
RTC
video
conferencing
platform
GT
meet
can
easily
handle
smaller
setups.
The
default
installation
packages
will
feed
the
needs
of
your
company
or
online
community
meetings.
But
if
you
are
building
a
large
online
service
in
you
need
the
cavalry
the
scaling
and
balancing
setups
can
save
the
day.
A
What
we
can
do
is
add
more
video
bridges
or
duplicate
the
whole
platform
and
load
balance
over
it
with
H
a
proxy
or
you
can
do
both.
Adding
video
bridges
will
help.
You
increase
the
number
of
simultaneously
hosted
conferences
and
also
will
act
as
a
failover
for
your
service.
If
one
bridge
goes
down,
there
will
still
be
another
one
to
create
new
conferences
in
and
adding
more
GT
mid
instances
can
help.
You
also
balance
between
these
different
shots.
If
one
GT
mid-shot
goes
down,
there
will
still
be
another
one
to
create
new
conferences.
A
All
the
components
of
the
platform
can
be
stout
on
different
servers,
but
for
convenience.
Here
we
accept
that
prosody
jika
for
the
web,
server
nginx
by
default
and
the
GT
mid
front
end
are
all
installed
and
running
on
one
machine.
We
call
this
machine
GT
mid
server.
Please
take
that
into
account.
If
you
have
different
set
up,
all
the
video
bridges
are
on
separate
servers.
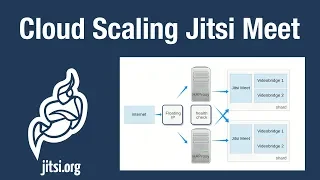
A
A
So
for
each
GT
mid
instance,
you
have
one
GT
mid
server
facing
the
Internet
and
one
or
more
GT
video
bridge
servers
group
together
and
all
connected
to
the
GT
mid
server.
You
can
configure
them
in
an
auto
scale,
group
and
think
of
them
and
their
mid
server
as
a
whole
unit.
We
call
this
a
shart
and
it's
the
basic
scaling
unit
to
scale.
You
need
a
shard
inside
the
shard.
The
video
bridges
are
a
lot
balanced
and
the
least
loaded
takes
the
new
conference
to
prepare
the
scaling.
A
You
can
use
your
cloud
platform
tools
if
ones
are
available
or
you
can
use
your
own
scripts.
A
lot
of
cloud
providers,
give
you
the
tools
to
create
scaling
groups
or
to
have
an
image
of
a
server
and
to
quickly
provision
a
new
copy
of
this
server
using
the
image.
If
you
are
using
your
own
IaaS
cloud
platform
with
OpenStack,
for
example,
you
will
have
the
freedom
to
implement
this
from
bottom
up.
If
you
are
using
a
cloud
provider
like
Amazon,
Web,
Services,
digitalocean
or
Google
cloud
platform,
you
can
use
the
tools
they
provide.
A
A
A
Then
detection
of
the
scaling
down
need
shutting
the
video
bridge,
gracefully
and
waiting
for
all
its
conferences
to
end
stopping
and
terminating
the
needed
video
bridge.
Of
course,
you
can
use
the
tools
for
a
lot
of
other
things,
like
gathering
statistics,
checking
the
monitoring
and
alarms
if
you
have
AWS
cloud
watch
enabled
and
so
on.
A
A
Although
all
the
video
bridges
are
the
same
and
they
do
exactly
the
same
work,
they
can
share
one
component
configuration
each
video
bridge
must
have
its
own
slot
in
prosody
to
click
in,
and
these
components
are
predefined
in
the
prasada
config
files.
So
for
any
change
in
them
to
become
active,
a
real
load
of
prosody
is
needed.
A
You
can
either
use
scripts
to
edit
and
reload
the
config
on
each
scaling
event
or
which
is
a
lot
more
convenient,
have
all
the
components
configured
from
the
start
and
waiting
for
video
bridges
to
appear.
For
example,
if
you
plan
to
have
a
maximum
of
10
video
bridges,
you
simply
create
ten
components
configurations
most
of
the
time.
Most
of
them
won't
be
connected
and
you
may
see
warnings
in
the
porosity
locks,
but
it's
not
a
problem
on
the
video
bridges.
You
also
have
to
prepare
the
configs
on
scaling
up.
A
A
A
It
goes
to
the
first
chart
and
when
new
people
join
this
conference,
the
H
a
proxy
will
know
to
point
them
to
the
same
place.
Even
if
there
are
people
from
all
around
the
globe
in
some
conferences
chances
that
there
will
be
a
lot
of
local
conferences
that
won't
be
put
randomly
on
a
bridge
in
a
distant
region.
The
same
will
happen
when
a
group
of
medical
experts
join
a
health
conference
or
a
community
of
IT
experts
opens
a
room
to
talk
about
IT
tech.
A
The
point
is
that
having
such
setup,
you
can
scale
the
whole
charts
and
still
be
sure
each
participant
goes
to
the
right
place
and
you
can
implement
geolocation
mapping
and
redirecting
in
H
a
proxy
by
using
geoip
database
and
binding
it
with
H
a
proxy
access
control
lists.
Oh,
this
is
beyond
the
scope
of
such
short
tutorial.
So
please
consult
the
AG
proxy
documentation
and
examples.
A
Also,
please
have
in
mind
that
geolocation
mapping
is
not
always
reliable,
because
IP
addresses
change.
The
geoip
database
gets
old
and
also
a
lot
of
people
today
use
proxies
in
VBS.
So
while
it
sounds
cool,
take
the
geolocation
option
with
a
grain
of
salt
with
all
the
scaling
can
load-balancing
options.
You
have
a
very
flexible
system,
but
once
the
conference
is
started,
you
have
a
critical
single
point
of
failure,
and
that
is
the
video
bridge
where
this
conference
is
running.
A
A
A
Once
again,
please
consult
the
aichi
proxy
documentation.
Here
is
just
an
example.
The
servers
that
receive
the
forward
that
requests
are
grouped
in
backends.
Each
back-end
is
responsible
for
a
certain
type
of
request
and
consists
of
multiple
interchangeable
servers.
If
you
add
more
servers
to
a
specific
back-end,
you
scale
it
horizontally
and
it
can
take
more
of
the
same
load.
If
you
add
more
backends,
you
can
deal
with
different
kinds
of
traffic,
for
example,
coming
from
different
IP
ranges.
A
A
Have
in
mind
that
the
service
of
GT
meat
is
not
as
simple
as
having
a
web
page
on
HTTP,
although
from
outside
it
kind
of
looks
like
it.
If
you
have
a
simple
web
page,
you
can
have
a
complex
high
availability
set
up
in
front
of
it
and
be
sure
that
the
service
has
practically
no
interruption
at
all.
Gt
meat,
on
the
other
hand,
has
not
only
to
serve
the
web
part
of
the
application,
but
also
hosts
the
conference's,
which
is
the
real
meaning
of
the
service,
and
this
was
created.
A
The
conference's
can't
be
moved
from
one
bridge
to
another.
There
is
no
true
high
availability
in
the
strict
meaning
of
the
term.
You
can
add
more
video
bridges
to
a
shark
to
scale
it
and
you
can
add
more
shots
to
distribute
them
geographically
and
balance
them
with
each
a
proxy.
You
can
also
add
a
second
H,
a
proxy
and
set
up
an
active/passive
H,
a
proxy
pair
working
behind
a
floating
IP.
A
This
way,
you
won't
lose
the
ability
to
host
new
conferences,
even
if
one
of
the
H
a
proxies
goes
down,
but
if
the
video
bridge
on
which
a
specific
conference
is
hosted
goes
down
currently
there
is
nothing
you
can
do
to
save
this
conference.
So
all
the
load,
balancing
scaling
and
failover
will
work
on
the
level
of
the
whole
service
for
each
separate
conference.
A
Now
you
know
how
to
scale
up
and
down
the
GT
mid
platform
on
a
cloud
infrastructure
and
also
how
to
load
balanced,
two
or
more
GT
mid
instances
with
H
a
proxy
for
scaling.
You
need
some
automation
to
start
and
stop
the
new
bridges
either
from
your
cloud
platform
or
through
your
scripts,
or
both.
The
new
bridges
must
be
configured
to
quickly
connect
to
produce
components
and
also
when
scaling
down.
They
must
be
shut
gracefully
when
all
their
conferences
expire
for
the
balancing
you
have
to
plan
and
prepare
your
shots,
distribute
them
geographically.
A
If
you
want
on
really
very
loaded
setups,
you
can
use
a
pair
of
active
passive
AGA
proxies
with
failover
IB,
and
always
the
most
important
thing
to
keep
in
mind
is
that
currently
conferences
can
be
moved
between
video
bridges.
If
a
bridge
breaks
down
the
people
go
down
in
the
river
with
it,
so
take
care
of
your
bridges.
Thanks
for
watching
take
care.