►
From YouTube: Community Meeting, August 2, 2022
Description
No description was provided for this meeting.
If this is YOUR meeting, an easy way to fix this is to add a description to your video, wherever mtngs.io found it (probably YouTube).
A
C
D
So
you
get
a
string
with
upper
and
lower
case
and
alphanumeric
string.
So
you
will
see
that
change.
If
you
have
some
kcp
already
running,
I
don't
know
what
will
happen
honestly.
I
guess
it
will
resync
everything
and
that's
that
has
been
done
to
provide
uniqueness
to
the
label
as
before
cluster
one
could
refer
to
a
scene
target
in
multiple
different
workspaces.
D
C
What
one
addition,
maybe
also
for
the
y-
we
don't
want
to
leak
cluster
workspace
or
sync
target
names
right,
so
yeah
we
in
in
the
past.
We
talked
about
with
clayton.
At
the
time
we
talked
about
using
the
uig
or
something
which
is
basically
the
same
thing
with
some
string
encoded
in
nice
format
as
nice
as
possible,
at
least
in
label,
and
it
gives
us
a
uniqueness
plus
not
leaking
anymore.
A
C
If
you
deploy
shots
multi-region
and
how
the
primitives
we
have,
for
example,
in
the
cluster
workspace
chart,
object
yeah
how
they
can
be
used
to
enable
this
topology
this
to
the
topology.
Is
it's
not
a
must
like
just
one
option,
maybe
a
natural
one
but
yeah.
If
you
have
different
goals,
maybe
some
things
will
be
differently
designed,
but
anyway,
what
we
have
done
here?
Maybe
you
can
zoom
a
bit,
so
you
can
see
it
better.
C
C
So
it's
a
address.
You
can
talk
to
a
short
directly
black
one
is
external
url.
This
is
used
in
cluster
workspaces
and
it
will
most
probably
point
to
the
front
proxy.
So
if
you
go
down
yeah,
that's
one
proxy
say
multiple,
so
maybe
the
black
bubbles
there
are
not
even
equal,
but
maybe
they
are
depending
on
anthropology
has
consequences,
of
course,
but
that's
the
external
url
everybody
knows
and
when
you
say
cube,
cutter,
ws
and
then
a
workspace
name,
it
will
use
the
black
address
and
the
search
one
is
the
red
one.
C
We
we
put
the
red
addresses
into
different
objects
like
in
api
exports.
You
will
have
in
the
status
the
urls
which
point
to
the
virtual
workspaces
of
charts,
so
those
are
copied
there
and
yeah.
If
you,
if
you
put
that
into
a
topology
here
with
a
private
network,
maybe
we
need
a
load
balancer
in
front.
C
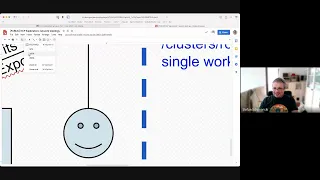
So
basically
there
is
this:
this
person
in
the
middle
that
smiley
is
a
head
face.
This
talks
to
the
dns
and
then
that
one
talks
to
the
dns
and
then
talks
to
the
front
proxies
such
a
person
like
a
human
user,
will
never
talk
to
the
virtual
workspace.
But
controllers
do
so.
We
have
pictured
two
instances
of
a
controller
which
talks
to
an
api
export
here,
one
in
the
us
one
in
europe
and
they
will
also
use
the
foreign
proxies.
C
So
the
black
addresses
to
talk
to
basically
to
get
the
data
from
the
api
exports.
So
the
export
is
on
the
right
side,
the
one
which
has
those
three
red
bubbles.
So
for
that
it
will
go
through
the
point
proxy,
but
after
that
it
will
do
list
swatches
against
the
addresses
addresses
of
virtual
workspaces.
C
In
the
picture
we
have
three
of
them,
so
the
three
red
load
balancers
here
and
we
played
with
the
idea.
So
we
talked
about
that
before
that,
somehow
we
have
to
reflect
topology
into
controllers
and
one
idea
here
was:
maybe
we
extend
a
list
of
virtual
workspaces
with
labels,
so
every
virtual
workspace
has
labels
and
in
there
there
would
be
something
like
region.
So
if
you
zoom
in
again,
we
don't
do
it
so
in
the
labels
of
the
list
there
on
the
right
side,.
C
A
C
C
Yeah
at
the
bottom,
those
are
the
labels.
Basically
maybe
they
come
from
the
short
labels,
so
we
haven't
discussed
that
yet
how
you
define
them.
If
you
move
up
a
bit,
I
call
them
topology
labels.
They
are
so
those
are
the
ones
copied
into
the
to
the
list
on
the
export,
but
in
any
case
the
controllers
will
see
those
labels.
So
a
controller
author
can
use
them
to
do
sharding.
C
C
So
when
you
look
at
the
left
controller,
it
has
three
outgoing
arrows,
two
of
them
point
to
the
us
charts
and
then
there's
a
gray
one
which
points
to
the
ueu
one.
So
the
left
controller
has
a
workspace,
a
virtual
workspace,
selector
usb1,
so
it
will
not
be
responsible
for
european
charts.
That's
why
this
is
grace
which
it
doesn't
talk
to
that
one
it
could
in
theory,
but
the
controller,
runtime
or
client
go
based.
C
D
C
D
C
C
D
A
Yes,
the
controller
runtime
example
that
we
have,
for
example,
you
give
it
the
name
of
an
api
export
and
it
will
retrieve
it
which
in
theory,
would
go
through
the
front
proxy
and
then
it
uses
the
currently
only
one
url
in
the
status
and
then
up
creates
a
client
that
will
talk
to
the
virtual
workspace.
So
this
is
just
an
expansion
of
all
of
that.
C
A
C
Yeah,
but
it's
just
a
service
account,
this
doesn't
change.
It's
a
service
account
against
api
export,
so
there
will
be
subject
access
review
and
potentially
this
is
an
area
where
we
have
to
think
what
happens
when
so
there's
this
blue
line,
which
is
authentic
if
the
identic
strikes
and
there's
no
connection
anymore
between
the
shots.
What
happens
like?
How
does
chart2
do
such
an
access
review
against
chart
one
so
replication
and
those
things
will
come
into
play
here
and
also
in
this
direction?
The
the
green
arrows
I
haven't
talked
about.
C
So
what
lucas
is
implementing
at
the
moment?
So
we
are
trying
to
get
two
shots
running
and
the
solution
is
basically
to
take
or
to
implement
this
upper
left
green
arrow.
So
if
you
can
select
that
and
ignore
everything
to
europe,
basically,
this
arrow
is
what
lucas
is
implementing
so
basically
charge.
One
will
watch,
shot,
zero
and
chart
zero
will
watch
chart
one,
so
we
have
two
informers
and
controllers
will
also
have
two
informers
at
least
those
which
we
touch
at
the
moment.
So
we
start
with
important
or
the
core
ones.
C
Api
binding
api
export
cluster
workspace
scheduling
those.
We
start
with
and
just
play
with
this
model,
where
you
have
to
inform
us
in
the
future.
Maybe
we
don't
have
to
inform
us,
because
this
explodes
of
course,
number
of
shots,
so
the
options
where
you
do
replication
of
just
the
important
data-
that's
one
option
so
replication
into
etsy
into
the
local
lcd
and
there's
a
third
model.
So
if
you
go
to
from
the
left
sub
zero
sure
one
can
beat
that
this
is
step
zero.
This
is
the
same
format
based
solution.
C
One
to
the
right
is
a1.
I
think
I
called
it
that's
that
application,
so
we
copy.
For
example,
we
copy
the
root
workspace
to
every
chart
like
every
object.
Everything
we
copy,
just
that
you
have
the
api
bindings
and
exports
and
everything
and
the
third
one
one
to
the
right
is
a
1b,
that's
a
model
where
basically,
every
controller
can
subscribe
to
certain
objects.
C
So
as
an
example,
the
api
binding
controller
has
to
watch
the
corresponding
api
export
right,
and
this
is
a
pretty
clear
relationship.
So
you
know
what
you
want
to
watch
and
the
controller
the
binding
controller
can
for
its
local
bindings
can
claim
access.
Like
a
list
watch
in
the
background
events
and
everything
for
this
one,
api
export
and
in
the
background
you
would
have
some
kind
of
list
watch
manager
and
as
long
as
the
controller
at
least
tells
this
manager
here
I
want
to
watch
this
object.
C
I
want
to
watch
it
every
30,
30
minutes,
for
example,
this
this
watch
would
stay
active
and
you
would
get
events,
but
if
the
controller
forgets
about
this
rarely
export
this,
this
watch
will
be
just
stopped.
This
is
very
similar
to
what
cubelet
does
cubelet
and
secrets
is
the
same
model.
Basically
you
say
if
there's
a
pot
which
mounts
a
secret
there's
an
informer.
If
the
pot
dies
the
informal
stopped
so
both
models,
we
can
implement
they're,
not
exclusive.
C
They
are,
I
think
they
are
places
and
controllers
where
the
second
model
is
better
like
this
binding
controller,
but
for
other
things,
for
example,
if
you
want
to
you,
want
to
serve
subject
access
review,
you
basically
need
a
lot
of
objects,
since
it's
very
hard
to
describe
which
objects
you
need
for
that,
and
their
replication
might
be
better.
So
if
you
know
in
advance,
you
want
to
to
you
depend
on
many
objects,
maybe
a
complete
workspace
or
something.
Then
an
application
is
better
than
the
second
model.
That's
the
hood
of
stuff!
C
All
right,
maybe
last
just
last
comment:
chris
asks
that
when
do
we
have
to
port
all
controllers
for
the
moment,
basically,
every
workspace
is
automatically
scheduled
to
hoot.
This
will
stay
for
quite
some
time,
so
you
have
to
in
end
to
end.
You
have
to
opt
in
into
scheduling
onto
another
chart,
so
we
can
really
selectively
run
tests
which
support
sharding,
but
most
others
like
by
far
the
majority,
will
just
run
on
one
chart
for
the
time
being.
F
D
F
Do
you
see
my
screen?
Yes,
so
mainly
what
we
call
invert
thinking
is
is
a
sort
of
new
feature
that
popped
up.
You
know
whose
requirement
popped
up
initially,
especially
in
the
case
of
kcp
storage,
mainly
feature
wise,
if
you
think
of
all
the
objects
that
are
at
stream
in
kcp
and
the
other
side
or
the
objects
on
on
physical
clusters.
F
You
would
have
dynamic
provisioning,
but
as
soon
as
at
least
in
the
simple
cases
and
guy
would
be
able
to-
you
know,
say
more
about
that,
but
in
in
the
simple
case
the
pv
would
be
brought
back
to
the
kcp
layer
and
then
would
have
to
be
synced
along
with
the
pvc,
so
pre
pre-provisioned
in
fact
pv
on
on
the
second
cluster.
So
the
whole
point
here
is
at
least
to
open
a
door
for
up
thinking
or
for
invert
seeking
for
bringing
objects
from
so
status
and
spec
as
well.
F
This
would
not
be
something
expected
to
be.
You
know,
long
term
up
thinking,
but
at
least
taking
one
object
being
able
to
upsync
at
some
point
and
when
some
external
component,
like
coordination
controller,
would
you
know
detect
it's
the
time,
then
this
object?
Would
you
know,
be
now
a
kcp
object
that
you
can
sync
back
to
one
cluster
or
another.
So
that's
that's
the
main
goal
in
terms
of
features
and
in
terms
of
components.
F
What
we
had
already,
of
course,
is
the
synchro
virtual
workspace
with
the
spec
sinker
and
status
thinker,
and
they
all
you
know,
take
the
source
of
truth
from
from
here
from
the
workspace
and
obviously
the
upsync
is
something
quite
different.
In
fact,
it's
not
not
necessarily
following
the
same
flows
and
the
same
logic
for
creation
deletion,
all
the
the
various
steps
and,
and
so
the
the
ide.
F
The
approach
that
that
we
agreed
on
during
the
design
is
mainly
to
have
in
the
sinker
agent
over
the
single
process
on
the
physical
cluster
on
the
sync
target,
have
an
additional
controller,
and
also
that
would
look
for
some
objects
that
would
be
levied.
Labeled
with
and
let's
say
up.
Sync
label
typically
and
from
those
object
would
then
create
through
a
distinct
virtual
workspace,
which
is
mainly
just
like
the
synchro
virtual
workspace
but
dedicated
to
upsync.
F
For
example,
you
have
a
number
of
things
that
you
might
want
to
change
in
the
tv
before
bringing
it
back
to
kcp,
and
also
there
is
the
question
of
maintaining
links.
You
know
cross-references
between
the
pvc
and
the
pv
so
that
that's
mainly
the
model
and
then
on
the
sinker
side.
Obviously,
there
could
be
because
pvs
and
pvcs
are
typically
just
standard
cube
objects.
So
a
storage
controller
that
would
be
able
to
detect
that
a
pvc
has
been
bound,
and
so
you
know,
label
the
corresponding
pv
for
upsync.
F
In
order
to
for
this
to
be
checking
in
account
by
the
upsync
controller,
so
that's
mainly
the
the
long-term
id
of
up
syncing
and
the
plan
is
really
to
keep
that
really
scoped.
You
know
limited
to
the
the
the
minimal
use
case.
The
use
case
is
because
still
the
main
flaw
is
obviously
always
from
kcp2
is
the
the
usual
thinking
from
kcp
to
sync
targets,
and
obviously
this
is
not
in
the
very
near
future,
because
it
would
also
require
creating
a
new
virtual
workspace,
also
having
transformation
completely
learned
in
the.
F
You
know
specific
to
cube
storage,
primitives,
pvcs
and
pvs,
and
especially
doing
the
transformation,
the
required
transformations
directly
here
and
then
directly
also
pointing
to
the
workspace.
Obviously
it's
a
limited
case.
It's
you
know
a
short-term
step
that
we
could
very
quickly
implement,
but
this
requires
this
limitation
that
the
workspace
this
in,
which
you
have
the
sync
target
and
the
workload
workspace
would
be
the
same,
which
is
the
case
mainly
for
now,
and
if
we
stick
to
this
limited
use
case,
then
it's
possible
quite
easily
to
implement
this
transformation.
A
C
Yeah,
maybe
we
should
put
it
under
feature
gate,
that's
easy
to
do
and
we
prevent
wrong
expectations
and
just
to
give
a
number
andy,
I
think
we
have
something
like
a
month
overlap,
also
so
the
work.
So
yes,
we
I
mean
if
we
had
a
second
or
third
david,
we
could
do
the
virtual
workspace.
Now
we
don't
so
that's
why
we
just
realized
that
sure.
D
F
B
F
A
B
B
For
for
this
design
I
mean
the
the
intention
is
and
then
one
of
the
the
diagrams
we
have
the
replication
mentioned,
but
there
is
no
design
for
it.
So
I
think
the
if
we,
if
we
want
to
test
how
up
syncing
works
in
the
longer
term
storage
cases
we
might
want
to
continue
and
follow
up
that
discussion
and
look
at
the
replications
as
well.
So
we
see,
if
that
you
know,
fits
well
under
those
use.
Cases
too.
F
Yeah
and
that's
probably
also
a
reason
why
it's
quite
important,
even
if
it's
not
the
complete,
you
know
full
picture
to
start
with
the
intermediate
state,
because
then
we
can
start
experimenting
with
the
coordination
controller.
With
the
way
we
manage
the
sync
labels
up,
sync,
with
the
precise
orders
and
and
see
how
it
you
know,
also
fits
the
the
case
which
are
less
simple
than
the
read
write,
execute
case.
A
B
E
A
E
Oh,
I
can
screech
you
real,
quick,
thank
you
for
those
presentations.
That
was
really
great.
I
appreciate
that
for
folks
who
may
be
new
on
the
call
we
are
trying
to
make
a
conscious
effort
to
share
more
design
details
and
facilitate
a
little
more
conversation.
So
if
you
see
something
you
like,
then,
as
andy
said
jump
right
in
or
if
you
have
feedback,
let
us
know
how
we
can
improve.
E
E
E
So
we
would
expect
that
that
continues
with
the
same
setting.
Folks,
we
would
want
to
see
new
epics,
or
at
least
the
existing
epics
move
to
the
correct
milestone
and
scoped
for
0.8,
so
we'd
be
looking
for
that
breakdown,
maybe
by
the
next
community
call,
so
we
can
see
what's
going
to
be
in
the
milestone
and
for
any
new
design
items.
C
Yeah,
I
haven't
prepared
any
slides
or
documents.
We
have
some,
but
they're
not
polished
anyway,
so
I
can
try
to
describe
so.
Basically
it's
about
the
first
steps
into
more
network
support
and
service
connectivity
is
the
primary
thing
we
want
to
have
like
availability
of
the
service
object
and
when
services
have
a
name
in
kcp
and
you
reference
them
workloads
which
run
in
containers
and
ports,
they
must
be
able
to
talk
to
the
service
and
talking
to
the
service
is
either
done
by
a
service
ip
in
cube
or
via
dns.
C
So
pots
must
basically
use
whatever
is
defined
in
the
semantics
of
pod
specs,
basically,
which
tells
a
part
about
the
existence
of
a
service
like
an
environment
variable
as
a
downstream
api
or
just
by
convention.
Those
things
must
work,
and
this
means
we
have
to
require
probably
prospects
so
that
the
environment
variables
for
the
services
in
the
same
namespace.
C
They
are
mapped
to
services
which
are
actually
on
the
physical
cluster
and
a
similar
thing
for
dns.
If
a
service
looks
up
under
a
service
name
of
kcp
and
the
namespace
name
or
kcp,
it
has
to
get
the
same
answer.
Like
the
logical
answer,
the
s
answer,
which
it
would
expect
in
a
real
cube
cluster,
but
now
we
are
in
downstream,
so
we
have
zoomed
object
down
to
a
physical
cluster
name.
C
Space
has
a
different
name,
so
the
dns
resolution
must
be
changed,
so
there's
work
around
core
dns
and
somehow
faking
this
logical
picture
of
the
dns
and
the
network
topology
of
kcp
into
a
physical
cluster
and
yeah.
Those
are
the
big
steps.
There's
a
third
topic
may
be
involved
with
that
network
policies.
At
some
point,
I'm
not
sure
we'll
do
it
here
and
zero
eight,
but
probably
in
one
of
those
next
milestones.
C
Network
policies
are
a
similar
thing
because
it
reference
topology
and
the
logical
topology
in
kcp
is
different
and
in
the
downtown
cluster.
So
if
you
want
to
make
them
to
work-
and
we
know
we
need
the
topologies
for
security
reasons,
there's
also
lots
of
work
to
be
done
again
same
pattern,
implementing
something
and
mapping
which
makes
the
container
think
it's
running
in
the
kcp
namespace,
while
actually
it's
in
without
same
namespace,
which
has
a
different
name.
C
E
So
the
next
steps
here
are
folks
can
put
their
names
beside
topics
they're
already
working.
If
you
want
to
jump
into
a
topic,
please
put
your
name
there,
so
somebody
can
reach
out
to
you
anything
that
does
not
get
an
assignment.
We
will
either
talk
to
folks
for
a
direct
assignment
on
ownership.
If
it's
something
we
want
to
commit
to,
or
we
would
move
it
out
of
the
milestone.
D
A
D
A
This
looks
like
it
would
be
nice
to
get
around
to
at
some
point
so
no
hard
milestone.
Although
I
do
have
a
question
so
paul
and
anyone
when
we
at
some
point,
we
probably
should
go
back
and
look
at
anything.
That's
in
here
that
is
tbd
and
see.
If
any
of
these
147
we
want
to
specifically
assign
to
0.7.
A
D
A
I
know
that
we
had
cells
added
in
a
pr
that
merged,
so
this
is
a
request
to
document
that,
which
I
think
is
a
great
request,
just
a
reminder.
Unless
something
is
critically
needed
for
0.7
our
upcoming
milestone,
it's
just
going
to
get
placed
into
tbd
until
we
do
that
planning
session.
That
paul-
and
I
were
just
talking
about
or
revisiting
the
tvs,
this
one.
B
A
A
And
if,
if
folks
are
interested
in
helping
to
debug
and
to
triage,
I
will
make
as
much
time
available
as
you
all
need
to
walk
through
my
process
for
triaging,
if
that's
helpful,
especially
if
you're
looking
at
test
flakes.
So
if
you
take
a
pull
request
as
an
example-
and
I
don't
know,
here's
one-
that's
failing.
A
C
A
C
A
C
I
will
leave
that,
but
maybe
remove
label
epic
and
just
look
for
non-epics,
because
we
are
sony
yeah.
So
maybe
we
should
gmail:
okay,
yeah,
zero,
zero,
seven,
modern
epics,
better,
milestone,
blockers
yeah;
no,
I'm
not
blockers,
but
anything
everything
we
have.
We
plan
for
zero
seven,
but
to
come
to
says
anything.
You
really
want
to
have
nobody.
A
C
A
A
C
F
E
F
C
A
D
D
C
F
D
D
A
C
D
A
D
F
C
C
D
C
D
C
D
D
C
C
F
I
just
added
one
in
the
comments
1388.
Yes,
I
think
this
one.
The
plan
is
probably
for
me
to
restart
on
the
already
started
task
and
and
finish
that
for
the
end
of
the
week,
the
the
impact
behind
this
is
that
this
would
probably
require
wiping
the
atcd
and
just
ensuring
that
that
everyone
starts
back.
You
know
with
all
workspaces
created
in
their
home
and
not
in
organization,
workspaces
and
top
level
or
workspaces
as
as
was
before.
F
Yeah,
the
thing
is
that,
as
soon
as
there
are
you
know,
there
are
specific
subject:
access
review
and
and
checks
on
the
virtual
workspace
for
personal
workspaces,
especially
when
we
detect
that
the
workspace
created
by
someone
is
inside
the
top-level
org.
Then
we
don't
check
the
same
thing
because
we
have
to
to
be
compatible
with
the
previous
checks.
F
This
is
the
previous.
You
know
back
rules
that
were
different.
The
model
was
different,
so
for
now
we
kept
the
compatibility
not
to
break
everything,
but
at
some
point
we
have
to
to
break
that
simplify
things
and
assume
that
there
is
no
personal.
You
know
all
style,
personal
workspaces
anymore,
because
at
some
point
there
would
not
be
accessed.
They
would
not
be
not
be
able
to
access
them
anymore.