►
From YouTube: Community Meeting, January 10, 2022
Description
No description was provided for this meeting.
If this is YOUR meeting, an easy way to fix this is to add a description to your video, wherever mtngs.io found it (probably YouTube).
A
Everyone
today
is
January
10th.
This
is
the
kcp
community
meeting.
We
do
have
an
agenda
for
today.
I
will
go
ahead
and
paste
a
link
to
it
in
the
chat.
If
you've
got
anything
that
you
would
like
to
ask
demo
or
discuss
or
anything
else.
Please
feel
free
to
add
a
comment
to
the
agenda
here.
If
you
don't
get
a
chance
to
feel
free
to
use
the
raise
hand
feature
in
meet
and
we
can
call
on
you
after
we
go
through
these
items.
A
B
B
Okay,
so
I've
kcp
running
this
comes
from
a
branch
we
have
merged
all
of
it
yet,
but
we
are
not
far
so
what
I'm
wanting
here
is.
Basically
everybody
knows
that
already
is
a
Sharda
test
server
and
this
time
it's
it's
really
shorted.
So
we
have
a
number
of
shots
too
and
yeah
in
the
locks.
Here
you
will
see
there
are
kcp
one
lines
and
kcpz
online.
B
Is
another
shot
and
on
the
left,
I
have
yeah
I'm
a
terminal,
two
pedal
and
I'm
at
the
moment,
I
guess
in
Hoots
here
I
am
and
if
I,
if
I
look
here
around,
then
you
see
on
the
right
side.
You
see
in
the
green.
You
see
the
green
lines,
which
are
the
proxy,
the
epoxy
redirects
to
the
right
chart,
and
you
see
every
time.
I
do
something
kcp0
so
so,
which
Shard
and
the
woodwork
space
is
served
by
kcp
zero
at
the
moment
and
what
we
can
do
now.
B
We
can
create
a
workspace
which
is
not
on
the
root
chart.
So
for
that
we
added
a
flag
to
cube
cutter,
create
workspace,
called
location,
selector
and
that's
just
an
A
labor
selector.
In
the
workspace
object
and
at
the
moment
the
scheduler
is
still
hard-coded
to
root.
If
we
don't
do
anything
so
everything
lands
on
wood,
but
we
will
change
that
soon,
so
probably
going
to
some
some
random
selection.
B
But
at
the
moment
you
must
be
explicit,
so
you
have
to
tell
the
system
I
want
to
be
on
short
one,
and
we
can
do
that
and
I
also
enter
the
workspace
here
directly.
This
one
we
have,
let's
call
it
demo
and
you
see
nothing
special,
a
demo.
Workspace
is
created
and
we
have
entered
it.
But
this
time,
when
we
do
something
inside
you
see
on
the
right
tab
here,
kcp
one
is
serving
the
request
and
the
proxy
knows
about
the
new
workspace.
So
it
knows
when
it
goes
to
clusters,
food,
colon
demo.
A
B
Look
spectacular,
it's
getting
more
interesting
when
you,
when
you
ask
yourself:
how
is
this
actually
works
so
before
I?
Do
that
answer
the
question?
So
let's
do
a
bit
more.
Of
course
we
can
get
more
demos
here,
so
we
are
now
in
who
would
demo
demo
Devo
and
all
of
them
are
on
chart
one.
But
of
course
we
can
create
another
layer
here
and
go
back
to
roots,
and
now
we
are
back
on
the
on
the
wood
chart.
B
So
if
we,
if
we
do
something,
let
me
scroll
down
also
locks
lots
of
logs.
Yes,
when
we
do
something,
we
add
that
one
would
on
the
blue
chart
with
this
workspace.
So
when
you
see
so
it's
a
hierarchy
now,
which
is
yeah
completely
mixed.
Basically
root
is
a
woodchuck
first,
three
demos
on
chart,
one
is
last:
one
is
on
the
root
chat
again,
so
it's
completely
transparent.
The
user
does
not
notice
anything,
but
of
course
it
can
be
yeah.
B
So
you
have
seen
here
in
the
in
the
history
here
was
a
good
Universal
workspace,
so
every
every
one
of
those
actually
is
a
good
Universal.
So
what
we've
created
is
a
workspace
type,
A
workspace
or
workspace
type
Universal,
and
this
one
is
in
the
wood
chart.
So
something
happens.
Obviously,
in
the
background
that
chart
one
knows
about
the
universal
workspace
type,
and
there
are
many
more
things
which
are
pretty
much
invisible.
B
B
B
B
B
We
talked
about
the
charts
themselves,
the
exports,
the
resource,
schemas,
everything
around
yeah
binding
an
API,
and
we
talked
about
authorization.
So
everything
about
our
buck,
those
objects-
we
we
replicate
between
charts
and
replicating
between
charts,
basically
means
that
so
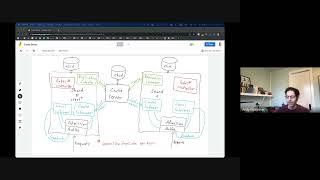
I've
drawn
here.
Both
charts
on
the
left
side
says
chart
0,
which
is
called
root
and
chart
ones
on
the
right
side
in
the
middle
there's,
something
we
call
a
cache
server.
B
A
cache
server
is
basically
it's
a
replica
of
the
data
which
we
replicate
so
it
it
holds
all
those
objects
which
are
relevant
to
all
the
shards.
So
it's
a
partial
copy
if
you
want
eventually
consistent
of
all
the
files
in
the
system.
So
it's
a
special
case
here.
It
will
copy
lots
of
stuff
from
the
wood
chart
from
the
woodwork
space
on
the
wood
chart
into
the
cache
server
and
chart.
B
One
will
use
that
there's
a
second
Informer
which
you
see
here
to
do
whatever
it
has
to
do
like
authorization
do
admission,
do
scheduling
everything,
so
the
cache
server
is
is
filled
with
data
by
my
replication
controller.
So
the
green
boxes
here
are
application
controllers
and
every
application
controller
proofs
data
from
the
local
chart.
So
in
this
case
here
on
the
left
side
from
0
into
the
cache
server
and
the
right,
one
will
cache
start
one
data
into
the
cash
flow.
B
The
question
of
I
won't
go
into
the
details
here
it.
It
has
a
way
to
list
watch
by
shards
and
it
has
a
way
to
just
watch
just
by
resource,
so
those
green
controllers
here
they
see
only
their
data
and
it's
a
simple,
simple
controller,
which
just
copies
data
and
deletes
data.
I.
Think
deletion
is
even
not
implemented
at
the
moment,
but
basically
it
sees
only
its
own
data
in
the
cache
and
it
replicates
into
that
and
make
sure
the
objects
are
up
to
date
and
so
on.
B
So
those
greens,
those
screen
controllers,
do
this
pushing
from
all
directions.
We
have
another
controller,
if
you,
if
you
go,
if
you
look
here,
API
resource
schemas,
export
shots
and
types
for
those
for
those
kinds.
We
we
basically
want
all
the
objects,
so
we
don't
filter
in
any
way.
We
just
push
everything
with
those
screen
controllers
into
the
cache,
but
forever
objects.
We
don't
need
everything
we
just
need
those
which
matter
better
for
authorization.
B
So,
for
example,
when
we
want
to
bind
the
resource
yeah
find
an
export,
we
have
to
check
that
we
are
allowed
to
bind
and
at
the
end
we
have
to
when
we
access
the
resource,
we
have
to
check
some
extra
permission
claims.
So
we
know
exactly
which
Arabic
objects
we
need-
and
we
have
a
couple
of
special
controllers:
I
call
them
Naval
controllers.
B
Here
they
label
their
back
objects,
which
we
want
to
share,
which
we
want
to
replicate,
so
we
label
them
and
then
the
green
controller
goes
on
and
copies
them
onto
the
cache
server.
What
else
is
interesting?
Yeah
I
I
mentioned
it
already,
so
we
have
an
Informer
against
the
cache
so
yeah.
The
cache
Informer
here
is
this
blue
box,
which
talks
to
the
cache
server
and
we
have
a
local
informal.
B
That's
the
inform
us
we
we
have
had
before
already,
but
it's
important
that
we
have
those
two
sources
of
information
from
listers,
so
admission
and
authorization,
for
example,
and
other
controllers,
which
needs
this
information.
They
have
two
informers
to
look
up
data
so,
for
example,
when
authorization
wants
to
look
up,
I
know
whether
we
can
bind,
for
example,
if
you
check
first
as
a
local
informal
as
an
airbag
object,
so
it
will
authorize
against
that.
B
If
permission
we
will
go
to
the
caching
format
and
do
the
same
thing.
So
this
is
a
pattern
we
have
everywhere,
so
all
controllers,
which
our
course
workspace.
They
do
the
same
thing,
so
we
will
wire
in
both
controllers
and
both
inform
us,
and
those
controllers
have
to
check
those
informas
for
information
yeah.
So
last
thing
this
labeling.
B
B
You
will
see.
There
is
a
comma
separated
list
of
words
and
at
the
moment
we
only
have
one
of
those
label
controllers,
which
is
for
the
apis,
API
Group,
and
it
just
puts
the
apis
dot
kcpio
into
that
annotation.
But
it
can
be
a
list,
so
there
can
be
multiple
label
controllers,
one
for
API,
apis
API
Group,
another
one
for
tenancy,
another
one
for
TMC.
So
you
can
imagine
there
are
many
reasons
why
we
want
to
replicate
something,
and
then
this
will
be
a
list
of
comma
separated
list.
B
Yeah
I
think
that's
most
of
I
want
to
talk
about,
and
yeah
I
didn't
mention
that,
of
course,
the
cache
server
is
also
Etc
based,
so
it
can
serve.
Inform
us.
That's
why
we
use
sde,
but
that's
not
set
in
stone.
I
think
the
most
important
bit
here
is
the
programming
model,
which
is
behind
out
all
of
that,
so
the
cache
informal,
the
second
format.
This
is
a
different
kind
of
programming
to
I
mean
compared
to
normal
controllers
and
Tube
and
how
it's
implemented.
B
A
B
Around
yeah,
it's
the
information.
The
cache
server
is
based
on
on
API
sentence,
but
with
some
hex
it
doesn't
have
to
be
I
mean
it
doesn't
have
to
be
based
on
this
code
space.
But
at
the
moment
we
just
do
that.
It's
it's
an
API
server
which
has
to
serve
this
launch
and
can
create
and
update
objects.
B
Maybe
one
point
here
which
is
interesting:
we
haven't
tried
that
yet,
but
the
theory
is
everything
we
have
done
here.
You
can
switch
off
the
root
shot
and
chart.
One
should
have
everything
necessary
as
long
as
the
cache
server
is
up
and
chart
one
itself,
of
course,
and
that's
the
chart.
One
can
serve
information,
that's
very
important.
So
imagine
so
what
chart
is
in
a
different
region?
It
goes
down
on
agency
is
higher,
Network
latency
goes
up
or
something
this
doesn't
matter,
because
we
have
replication,
replicated
data
in
the
cache
server
and
also
Imagine.
B
E
B
B
Kcp,
exactly
it's,
the
proxy
sits
outside
and
the
proxy
at
the
moment.
It
watches
all
logical
clusters
in
all
workspaces
and
forms
that
it
can
build
tables
internally,
like
in
memory
tables
which
can
be
used
for
lookup.
So
when
you
go
to
root
demo
as
I
have
shown,
it
will
know
who
demo
belongs
to
short
one,
and
it
belongs
to
our
GE
cluster,
that
F
8
5
or
something.
A
F
F
So
I've
done
some
setup
before
the
demo,
so
here
what
I'm
doing
I
will
show
you
that
we
are
in
a
normal
workspace,
nothing
special
then
I
will
get
the
same
targets.
They
have
previously
set
up
one.
Once
in
Target
we
have
a
kubernetes
cluster
running
and
well.
What
you're
going
to
see
is
basically
how
transparently
we
can
access
the
logs
from
from
a
pot
that's
running
on
the
kubernetes
cluster
from
kcp,
so
here
in
kcp
I
have
a
deployment
created?
F
F
So
what
we
need
to
do
is
take
this
spot,
that's
running
on
the
downstream
kubernetes
cluster
and
we
need
to
upsync
it
into
the
kcp
into
kcp
Okay,
so
kcp
I
will
never
create
Bots,
but
the
Sinker
will
get
a
running
pod
on
kubernetes
and
then
create
it
on
kcp
and
keep
it
in
sync.
This
is
something
that
is
not
ready
yet
so
it
has
been
a
manual
step.
Let
me
show
you
the
manual
step,
what
we
are
doing
here.
Just
stop
me
at
any
time
for
questions.
F
I
know
this
is
perhaps
confusing,
but
what
we
are
doing
here
is
basically
getting
the
bot
name
that
has
been
created,
Downstream
the
destination
in
kcp
of
the
bot,
and
then
we
populate
some
of
the
information
then
seeing
Target
key.
And
how
do
we
create
that
bot?
Well,
this
will
be
done
by
the
sinker,
but
we
use
the
virtual
workspace
called
appsyncer,
so
basically
constructing
the
proper
URL.
That's
something
that,
of
course
the
user
doesn't
need
to
know
anything
about
constructing
the
proper
URL.
F
We
will
create
that
part
okay.
So
it's
already
done
so.
If
I
go
here
and
list
the
port
in
kcp,
we
will
see
that
we
have
the
acquired
tunneler
bot
created
in
kcp.
It's
not
ready.
This
is
something
because
I
didn't
sync
the
status,
but
this
is
something
that
will
be
okay,
totally
automatic
and
undone
by
The,
Thinker
sort
of
I
guess
so
what
we
can
do
now
kcpk
it's
a
nalias
of
cube
CTL
with
the
proper
admin
curve
config.
F
F
Let
me
try,
so
what
we
are
doing
is
API
the
full
port
blah
blah
blah.
So
we
are
using
the
the
basic.
There
is
nothing
magic.
It's
totally
transparent
cubic
CTL
works
as
it
expected,
as
we
are
doing
internally
a
redirection
to
the
proper
Sinker,
because,
thanks
to
the
work
that
Antonio
was
doing
with
the
tunneler,
when
the
Sinker
starts,
it
basically
creates
an
inverse
connection
with
with
kcp.
F
It
creates
a
connection
to
kcp
waiting
for
the
user
to
ask
for
a
pot
a
sub
resource
of
the
Pod,
for
example,
and
what
we
do
is
when
we
get
a
request
for
for
a
potluck.
We
identify
the
sync
Target
that
we
need
to
look
for
and
once
we
identify
the
sync
Target
and
everything
is,
you
know
properly
in
place
the
authorization
and
everything
what
we
do
is
proxy.
The
request,
transparently
to
the
scene,
Sinker
running
on
the
on
the
kubernetes
cluster,
get
the
bot
and
send
that
back
to
the
to
the
user.
F
Of
course
well,
you
can
see.
Sometimes
there
is
some
some
issue
well
now
now
it's
fine,
but
sometimes
there
is
something
with
the
tuner,
but
that's
my
My
Demo
setup.
Apart
from
that,
we
can
do
an
exec
if
we
want,
of
course,
we
can
exec
and
do
ID.
Who
I
am
it's
nobody,
so
we
are
tunneling
all
the
sub
resources
to
the
Sinker
running
Downstream.
F
All
of
these
is
feature
flag.
Feature.
Gate,
sorry
is
behind
a
feature
gate.
Even
the
Sinker
has
a
feature
gate
for
this
and
kcp.
So
it
is
still.
You
know
we
are
working
on
that,
but
we
are
setting.
We
have
proper
authorization,
so
we
check
that
the
user
can
access
these
logs
and
everything
and-
and
we
control
that
with
roles.
Let
me
show
you
quickly.
Sorry,
Place
APK
get
raw
cluster
roles,
sorry
cluster
roles,
so
we
have
this
allowed
tuner
cluster
role.
C
Yeah
I
was
asking,
with
the
permission,
is
for
a
specific
sync
Target
or
you
you
you.
You
will
have
multiple
workspaces
you're
using
the
Samsung
sync
Target
and
where
whether
you
can
have
the
permission
per
workspace
so
that
you
know
people
having
access
to
workspace
a
can
access
local,
but
in
his
workspace,
but
not
in
another.
One.
F
G
Maybe
I
would
ask
add
also
something
it
seems
to
me
that
we
can
distinguish
two
levels
of
authorization.
One
is
the
fact
that
an
end
user
would
be
authorized
to
access
the
sub
resource.
You
know
logs
or
exec
on
a
pod,
and
this
one
completely
relies
to
standard
authorization
in
kcp,
because
you
know
the
end
user
access
to
accesses
the
standard
arrest
URL
to
to
the
possible
source.
So
obviously-
and-
and
this
is-
and
any
redirection
that
finally
Ender
ends
up
internal
link-
is
done
after
the
standard
authorization
in
kcp.
G
G
So
that's
one
level
of
authorization
and
then
there
is
the
other
one
level,
the
other
level
of
authorization
which
is
related
to
sync
targets,
to
the
real
to
nailing
itself
and
that's
not
per
end
User.
It's
per
Synchro
service
account
because
in
fact,
the
only
client
external
client
that
will
access
the
you
know
specific
URL.
That
sets
up
the
the
the
the
tunel
and
and
do
the
connection
and
reverse
connection.
This
is,
in
fact
the
Sinker.
G
So
so
that's
the
second
level
of
authorization
that
is
based
on
on
such
a
a
permission
that
that
your
Kim
showed
and
then
there
would
be
probably
a
third
level
of
authorization
that
is
still
not
implemented,
which
would
be
at
the
Sinker
level
directly.
That
means
at
the
very
end
of
the
of
the
chain.
G
You
have
some
some
network,
Network
traffic,
that
comes
into
the
Synchro
and
and
at
this
time
we
would
also
need
to
to
have
a
third
level
of
authorization
here.
But
that's
not
not
anymore,
on
the
kcp
side,
but
but
more
much
more
on
the
central
side,
something
probably
a
bit
more
low
level.
Does
it
answer.
G
Of
course,
we
would
prune
the
part
from
many
fields
that
are
not
necessary,
because
we
only
need
mainly
the
name
of
the
part,
maybe
or
just
some
basic
Vegas
basic
stuff
here
and
so
puts
on
the
Upstream
side
would
only
be
some
sort
of
you
know,
placeholders
to
know
that
the
product
exists
and
to
be
able
to
access
to
the
sub
resource
through
the
standard
URL
and
also
to
a
lower
airbag
on
it.
And
so
that's
something
that
should
lunch
in
the
in
the
next
weeks.
G
F
G
F
F
A
D
And
maybe
I
use
the
wrong
term,
maybe
it's
generic
control
plane,
but
this
is,
you
know
regarding
the
issues
of
upstreaming
the
kcp
work.
I
know,
there's
been
some
not
enthusiastic
reception
of
everything,
but
you
know
when
we
last
talked
about
it.
Andy,
you
said:
there's
been
an
agreement
on
accepting
some
of
the
work
in
the
form
of
creating
a
repo
or
Library
called
I
forget
whether
it
was
generic
API
server
or
generic
control,
plane,
control.
D
B
Yeah,
basically,
we
have
two
big
tasks
to
want
to
execute
on.
Let's
say
in
q1
Q2
one
is
basically
the
Cube
site,
which
knows
nothing
about
logical
clusters,
but
everything
which
is
in
package
generic
control
plane
in
our
Fork.
This
should
become
Something
official
in
Cube
and
Cube.
Api
server
should
even
build
on
that.
So
that's
the
first
big
task
and
we
have
agreement
from
Upstream
that
we
can
do
that
and
that
we
get
the
reviews
and
everything
prereq
has
any
set
and
presentation
in
the
apis
meeting
and
everything.
B
So
as
a
normal
process.
The
other
task
task
2,
is
basically
building
on
top
of
that
something
yeah
you
want
probably
recorded
kcp
core
or
something
so
basically,
a
generic
API,
server,
control,
plane,
plus
logical
clusters.
So
this
will
include
the
regulatory
clusters
or
the
core
types
which
we
have
Cloud
repository
and
API
export
binding,
but
not
much
more,
nothing
with
hierarchy,
that's
in
world
workspaces,
really
just
yeah
those
bits,
starting
will
be
there,
but
functionality
is
completely
missing.
B
So
those
are
the
steps
we
want
to
do
and
whether
we
do
another
repository
for
the
second
task
like
for
this
core
kcp
I,
don't
think
in
the
beginning,
because
the
mono
repo
just
buys
us
velocity.
So
we
we're
much
faster
doing
that
in
one
repository,
but
it
will
certainly
be
another
CMD
command
and
maybe
a
different
sub
hierarchy
of
positive.
Always
something
like
that.
We
can
talk
about
that.
Nothing.
There
is
set
in
stone,
but
that's
a
rough
plan.
D
A
D
All
right
and
so
I
won't
ask
you
to
write
that
cap
on
the
call,
but
I
just
want
to
make
sure
I
understand
the
basic
outline
of
the
idea.
My
recollection,
my
previous
conversation
with
you
was
the
idea
is
that
this
would
be
basically
what's
in
the
Kube
API
server
minus
the
built-in
types
that
are
responsible
for
containerized
workload,
management.
A
Yeah,
it's
it's
interesting
because
you
can
either
look
at
it
as
the
cube,
API,
server
minus
things
or
an
API
server
with
things.
So,
ultimately,
what
we
want
is
crds
and
the
other
things
that
are
necessary
like
namespaces
and
authorization
admission
are
back,
but
I
wouldn't
expect
that
you
would
see
all
the
other
things
like
like
pods
and
deployments
and
whatnot.
D
B
Three,
my
my
dream
is
that
we
build
in
a
way
VIA
those
options,
drugs
that
you
can
really
disable
everything
you
want
like
you
get
to
fully
whatever,
basically
enumerated.
It's
a
full
generic
cube
apis
of
experience
minus
the
virtual
stuff,
but
if
you
don't
want,
for
example,
you're
not
airbag
and
authorization
for
reasons
or
you
don't
want
education,
you
should
be
able
to
switch
it
off
easily.
C
A
D
D
B
D
E
A
A
All
right,
let
me
go
through
these
here,
14.
all
right,
we'll
start
at
the
top
and
I
know.
We
talked
about
this
in
December
to
make
our
website
have
documentation
for
older
releases.
We
do
want
to
do
that
so
I'm,
going
to
put
this
in
the
backlog
if
you're
new-
and
you
haven't
seen
us-
go
through
the
these
issues
before
the
goal
is
to
just
triage
them
to
decide.
A
Essentially,
do
they
go
in
the
backlog
like
we
decide,
we
want
to
do
them
at
some
point,
or
are
they
more
critical
and
we
we
put
them
in
next,
but
that's
kind
of
what
we're
looking
to
do
here
so
like
we
need
to
deal
with
I'm
actually
going
to
start
putting
flakes
in
next.
Unless
you
all
disagree,
because
they
are,
are
and
have
been
annoying
to
CI
yeah.
A
A
G
A
G
F
C
F
We
generate
a
hash
based
on
several
information,
but
in
some
cases
that
hash
has
been
generated
in
a
different
way,
so
the
Thinker
using
the
Thinker
can
use
an
Informer
to
look
up
for
the
proper
namespace.
But
when
we
upsync
a
pot,
kcp
doesn't
have
an
Informer
Downstream.
We
cannot
do
that
because
we
need
to
go
through
thinker,
so
we
need
some
way
to
signal
from
where
was
that
resource
upsync?
G
Know
yeah,
so
that's
mainly
a
question
of
managing
migration
if
you,
if
in
the
kcp
server
the
logic
to
generate
the
physical
cluster,
the
namespace
changes-
and
we
use
this
Logic
on
the
kcp
side
to
find
by
the
namespace
to
which
we
have
to
communicate
with
the
Pod.
You
know
to
see
the
logs,
for
example.
Then
it
would
be
the
wrong
one.
G
So
we
have
to
mainly
store
into
the
absinct
port,
the
namespace
it
the
downstream
namespace,
where
it
was,
it
was
created
where
it
comes
from,
that's
mainly
what
it
means
so
mainly,
maybe
mainly
maybe
we
can
put
that
as
new
and
then
add
that
in
the
Epic
in
the
app
syncing
you
know
in
the
Pod
logs
AP,
because
it's
it
seems
to
be
related
to
this
type
of
to
this
use
case.
There
are
a
number
of
other.
You
know
upsyncing
scenarios
where
we
will
not
need
that.
G
F
H
H
In
some
workspace,
you
can
define
a
so-called
maximum
permission
policy
based
on
the
local
object,
permissions
on
your
API
export
to
type,
and
then
you
can
say
with
some
convention
that
only
certain
you
know,
groups
or
certain
users
are
allowed
to
do
certain
things
on
the
types
that
you
are
exporting.
This
is
cool
and
works.
H
However,
this
doesn't
work
on
Native
types
that
we
have
inside
kcp,
that
is
conflict
maps,
secrets
and
so
on
and
so
forth,
because
these
things
don't
have
a
clear
owner
today
we
discussed
this
briefly
on
slack
and
there
are
a
couple
of
yeah
possibilities.
For
instance,
we
could
declare
a
maximum
permission
policy
on
kcp
Native
types.
E
H
B
Yeah
I'm
not
convinced
that
we
wanted
like
why
you
should
just
be
customizable.
That's
my
question
and
we
have
to
my
memory.
We
have
a
admission
plugin,
which
does
something
like
that
for
a
couple
of
system
resources
already
so
in
other
words,
just
hard-coded
in
the
code,
you
can
apply
any
constraints.
You
like
I'm,
not
sure
about
the
value
to
do
that
globally
and
configurable
in
the
roots
or
anything
like
that.
H
Yeah,
like
the
discussion
came
up
with
the
issue
of
you,
know
exporting
actually
the
API
by
Links
type
that
is
having
you
know
the
possibility
to
bind
any
type
inside
a
user's
workspace,
and
she
came
up
the
discussion
that
there
is
currently
no
way
of
restricting
a
maximum
permission
policy
on
you
know
kcp
like
on
Native
types,
I'm
totally
fine.
With
closing
this,
if
you
find
this
is
not
useful.
My.
H
H
A
And
then
clarify
workspace,
privilege,
group,
Behavior,
I'm
gonna,
just
put
that
next
for
you
and
this
one
I
know
came
in
and
Vince
here,
looking
at
this
right
now,
right,
okay,
all
right!
That's
it
for
these
and
we're
close
to
the
end.
So
unless
there's
any
last
minute
things
I'm
going
to
suggest,
we
adjourn
and
see
you
all
next
time.