►
From YouTube: 2021-05-25 Community Meeting
Description
No description was provided for this meeting.
If this is YOUR meeting, an easy way to fix this is to add a description to your video, wherever mtngs.io found it (probably YouTube).
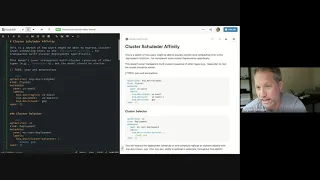
A
A
The
demo,
the
initial
kubecon
demo
was
stand
up.
Kcp
send
a
deployment
to
it,
watch
it
get
split
into
two
clusters
and
run
and
schedule
and
do
stuff.
I
think,
the
next
sort
of
for
our
next
trick
we're
going
to
try
to
get.
I
think
we
go
one
of
two
ways
and
probably
both
ways
which
is
allow
the
deployment
author
to
give
some
information
about
how
that
should
be
split
right
now.
A
A
A
This
is
a
rough,
a
rough
look
at
this
where
you
could
say
you
know:
cluster
usc
1
is
in
gcp
cloud
and
is
in
u.s
east
one
region
and
then
the
deployment
that
says
only
run
me
on
gcp
clouds
would
do
this
kind
of
gross
thing.
It's
not
final
and
I
don't
love
it,
but
as
a
as
a
jumping
off
point,
I
think
we
can
start
discussion
from
there.
Okay,.
B
A
B
I
kind
of
thought
you
were
going
to
go
to
go
transparent
on
deployment
and
then
manage
the
splitters
down.
Both
of
those
are
fine.
Are
the
use
cases
subtly
different
in
a
way
that
the
splitter
wouldn't
be
a
logical
step
was
maybe
the
question
that
we
would
have
to
ask
so
like,
if
you
add
the
additional
constraint
that
the
object
isn't
copied
at
the
kcp
level
or
it's
not
always
clear,
like
deployment
is
the
only
thing
you
can
really
split
like
this.
Well
deployment
is
the
obvious
one.
You
can
split
like
this.
B
You
know
there'll
be
others.
Do
you
want
to
go
to
the
archetype
of
splitting
one
more
step,
because
you
think
it's
the
most
productive?
Or
do
you
want
to
jump
to
the
next
one?
Because
I
think
both
are
fine?
I
just
you
have
to.
We
want
to
convince
that.
We're
doing
something
that
then
leads
back
to
transparent.
A
Right
yeah,
if
I
can
rephrase
to
make
sure
I
understood
what
you
said
right.
This
is
very
this
entire
document
is
very
deployment.
Centric
and
not
you
know,
demon
set
aware
or
anything
else
aware,
and
we
don't
have
to
solve.
We
don't
have
to
talk
about
constraints
at
all.
To
get
the
next
like
another
compelling
demo
is
to
do
the
like
at
a
cluster,
see
it
spill
over,
delete
a
cluster,
see
it.
You
know,
re
rejoin
that
doesn't
require
constraints
at
all,
and
so
yeah
there's
like
three
directions.
A
B
B
B
It's
summarized
up,
you
don't
know
the
difference
so
for
deployment
all
three
of
those
approaches,
fit
it
you're
doing
constraints,
and
then
I
think,
there's
a
separate
one
which
is
assignment
so
there's
like
the
policy
side
and
then
there's
the
actual
atomic
thing
that
has
to
work
for
transparent,
so
that,
no
matter
what
we
do,
like
jason,
you
nailed
it
we're
not
going
to
be
able
to
change
the
scheme
of
the
objects
in
order.
We
want
to
to
make
transparent
work.
B
B
A
kind
of
an
interesting
thing
here,
which
is
like
all
policy-based
stuff,
is
kind
of
orthogonal
to
transport,
to
to
transparent,
because
transparent
either
just
magically
works,
or
you
have
a
different
kind
of
policy
which
makes
it
spread,
but
you
will
need
to
have
enough
of
us
a
substructure
force,
preference
and
how
preference
is
carried
over
from
things
to
in
the
long
run.
So
again,
I'd
probably
say:
maybe
we
just
define
it
as
two
axes:
full,
transparent
and
policy.
B
A
Yeah,
I
guess
I
had.
I
had
imagined
the
next.
The
next
level
was
a
bit
specific
to
to
deployments
so
that
we
can
get
experience
with
it
and
understand
how
to
do
it
and
then
generalize
it.
We
can
definitely
generalize
like
if
you
want
to
have
a
fu
crd
splitter
that
does
something
based
on
whatever
a
foo
is.
You
should
also
be
able
to
give
it
these
labels
and
have
the
foo
splitter
understand
how
to
split
it
and
how
to
constraintedly
split
it.
B
And
maybe
a
way
of
saying
that
differently,
so
transparent,
multi-class
to
transparently
multi-cluster,
implicitly
assume
strategies
or
how
it's
copied,
and
that
involves
sync
strategies
as
well
as
split
strategies.
Maybe
there's
other
strategies
we
haven't
thought
about
yet
so
continue
to
explore.
The
split
strategy
of
transparent
multi-cluster
is
useful
because
it's
somewhat
more
complex
and
it
actually
shows
a
net
benefit,
which
is
we
know,
transparent
multi-cluster
for
moving
is
interesting,
but
transparent.
Multi-Cluster
for
transparent
would
be
almost
more
interesting
because
transparent,
aha
for
clusters,
like
moving,
is
a
prerequisite
for
other
things.
B
We
should
maybe
we
can
do
splitting
and
then
come
back
to
moving,
and
I
think
that's
fine.
So,
like
just
some
nitpicking
I'd
probably
say
we
should
use
json
and
annotations,
because
annotations
can
be
longer
and
json.
Doesn't
it
compresses
a
lot
better
and
you
can
convert
all
json
to
yaml,
but
not
vice
versa,
so
I'd
probably
say
like
just
from
those
two
like:
if
we
do
annotations
for
the
policies,
can
you
create
a
namespace
for
it
and
the
other
one
was
like?
You
chose
labels
that
were
different.
I
don't
like
why?
A
B
We
don't
know
what
the
pod,
how
the
pod
template
is
materialized
when
we
look
at
a
generic
workload,
object
like
a
job,
a
stateful
set
of
data
sets
those
probably
will
all
end
up
with
strategies
that
are
tied
to
the
workload
type.
If
someone
gave
us
like
an
ncd
crd
and
said
generically
split
this,
I
don't
know
that
we
could,
without
picking
one
of
an
archetype
so
like
we
could
say
that
the
splitter
strategy
has
some
strategies
which
are
archetypes
of
like
particular
workload
types.
B
So
you
could
say
like
because
replica
set
deployment,
probably
both
fall
within
this
characteristic
and
then
maybe
you
could
override
the
characteristic.
That
might
be
like
another
dimension
of
policy
that
comes
in
later,
or
we
figure
out
if
we
take
one
of
these
existing
ones.
But
your
point
about
like
again
like
the
thought
about
transparent,
I
was
like
so
this
is
why
I
was
looking
I
was
like
so
now.
I
have
to
know
these
specific
labels
that
are
different
than
what
the
cluster
is
going
to
have.
B
What,
if
I
already
had
those
labels
set,
and
then
we
ignored
them
in
transparent.
So
that's
not
a
yes
or
no,
but
like
thinking
about
it
like
does
if
I've
made.
If
I
have
a
spread
policy
on
a
pod
today
that
says
spread
by
zone,
should
I
be
able
to
deploy
that
to
a
multi-zone,
gcp
cluster
and
three
single
zone,
gcp
clusters
and
the
right
thing
happens
at
a
transparent
level.
A
B
And
then,
like
the
flip
side
of
that,
then
is
like
well.
We
could
always
add
additional
affinity,
rules
to
a
deployment,
spec
template
and
say
strip
those
off
as
they
go
through,
which
would
be
the
cluster
scheduling
and
and
actually
so
then
like
the
third
bit
would
be
we're
using
cluster
for
right
now.
I
do
want
us
to
put
an
asterisk
anytime.
We
say
cluster,
which
is,
I
think
we
want
to
have
something
more
generic
than
cluster,
because
cluster
comes
with
so
much
baggage
right.
I
think
we
should
explicitly
label.
B
I
think
it
would
help
us
to
say:
let's
come
up
with
a
word:
that's
not
clustered!
That's
like
location
or
spot
that
could
be
interfacing
yeah,
and
then
that
way,
and
then
that
also
helps
break
some
assumptions
because,
like
then
it's
not
a
cluster
selector
and
then
you're
like
well.
If
I
don't
have,
if
I'm
not,
if
I
don't
know
what
I'm
targeting,
maybe
what
I'm
targeting
actually
isn't
explicitly
said.
Like
I
don't
say,
I'm
targeting
a
location,
I
define
properties
that
the
location
has
and
those
are
like
just
two
different
models.
A
B
A
Yeah
I
mean
so
the
whole.
The
whole
system
should
be
like
the
the
scheduler
doesn't
know
what
the
string
location
means.
It's
just
a
it's
just
a
key
that
has
a
value,
and
it
knows
that
two
replicas
shouldn't
have
the
same
thing
with
the
same
value.
Right
like
it
doesn't
location,
doesn't
mean
anything
to
the
code.
Location
is
a
word
that
means
something
to
the
user.
So
it's.
B
B
And
maybe-
and
maybe
what
we
should-
we
did
this
okay,
so
this
is
actually
like
we're
like
turning
over
a
lot
of
like
this
is
like
the
meeting
that
you
and
I
probably
could
have
had
but
like.
Let's
do
it
here,
because
it's
actually
even
better
for
more
audience,
so
there's
placement
criteria
for
accomplishing
resiliency
objectives
or
placement
policy
for
for
accomplishing
criteria,
objectives
so
like.
B
So
all
those
logical
clusters,
some
of
them,
are
apps.
Some
of
them
are
random
joe
blow
creating
a
a
demo
app
about
a
k-native
function.
Joe
blow
does
not
match
the
security
profile
of
trusted.
Microservice
team,
a
so
thinking
about
like
location,
is
like
anything
we
can
do
to
kind
of
put
that
into
our
mind.
Path
is
good,
so
like
and
that's
kind
of
like
where
affinity
comes
in,
but
it's
also
where,
like
the
strip
affinity,
might
come
out
which
would
be
like
this
workload.
B
I
can
just
tack
a
label
onto
it
that
gets
stripped
off
automatically,
doesn't
go
down
or
it's
ignored
by
most
participants,
but
then
I
could
quickly
and
easily
write
an
integration
that
says
no.
No,
no.
No.
I
want
all
workloads
that
just
declare
this
capability
to
go
here
or
the
workloads
who
don't
have
this
permission
to
also
get
pre-constrained.
We
don't
like
that'll,
be
an
input
to
scheduling
or
placement
or
policy.
We
just
haven't
figured
out
what
it
is
like.
It
might
be
admission
to
policy.
B
It
might
be
a
mission
to
creation
like
we
could
decorate
these
objects
on
a
mission
if
we
had
to
or
it
could
come
from
the
logic
cluster
and
actually
that's
that
that
is
the
that's.
Maybe
like.
Let's
say
this
a
different
way,
the
policy
for
scheduling
is
influenced
by
the
locations
that
are
available
whatever
we
call
the
object,
but
it
could
also
be
influenced
by
the
policies
applied
to
that
logical
cluster.
B
Can't
be
too
generic
if
it's
too
generic
nobody
figures
out
how
to
use
it
can't
be
too
specific,
because
then
it's
hyper-specialized,
like
no
selectors,
were
too
specific,
very
useful
raw,
primitive
tolerations
were
an
approach
that
improved
on
it.
Tolerations
have
problems
because
someone
can
tolerate
all
tanks
which
completely
defeats
the
value
of
the
toleration
system
instantly
so
there's
already,
and
then
we
we
also
rely
on
other
policies
that
are
kind
of
more
implicit
matching.
B
So
we
have
to
take
like,
I
think,
like
this
kind
of
gets
back,
like
I
think,
is
the
right
thing
to
do
jason
to
be
influenced
by
these
and
then
the
next
step
would
be
how
much
indirection
should
we
have.
I
bias
a
little
bit
more
towards
a
stronger
indirection
from
clusters
and
a
stronger
indirection
from
assuming
that
it'll
be
just
one
input.
I
kind
of
think
we
might
actually
need
to
be
taking
multiple
inputs
and,
like
that,
would
be
a
scheduler
predicate
or
whatever,
like.
B
Let's
assume
that
we're
reusing
a
logical
structure,
that's
a
little
bit
like
the
cube
scheduler
with
predicates
and
priorities,
a
predicate
might
be
these
labels.
Could
we
do
it?
Generically
enough
that
we
could
like
that,
that
we
could
solve
the
different
use
cases
with
the
same
couple
concepts.
That's
probably
what
we're
interested
in.
We
should
try
them
like.
This
is
fine
to
try
that's
kind
of
the
thought
going
through
my
head.
A
A
B
So
so,
actually,
let's
frame
it
like
this
so
like
we
want
to
have
a
series
of
logical
steps
that
make
kcp
the
idea
desirable.
That's
we
have
a
set
of
components
like
minimal
api
server
and
then
syncer,
and
then
I
think,
like
what
we
want
is
someone
to
be
able
to
easily
do
these
super
obvious
integrations
and
I
think
it's
actually
desirable
to
call
them
obvious,
which
is
obviously,
if
you
were
somebody
today,
you
could
go
build
this.
How
would
you
go
build
this
today?
B
You
go
run
a
hub
cluster
and
then
you
would
like-
and
this
is
what
virtual
cluster
has
done.
They
literally
are
hacking
around
the
limitations
of
cube,
and
so
then,
if
we
have
the
mindset
which
is
like
okay,
how
do
we
relax
that
restriction?
Then
they
can
fit
into
the
kcp
idea.
Hierarchy
tree
and
see
benefit
so
like
v.
Cluster
could
use
kcp
right
or
use
the
minimal
api
server
with
a
set
of
our
opinionated
things,
and
we
can
say:
okay
now,
v,
cluster
virtual
cluster.
B
Sorry
virtual
cluster,
then
only
has
to
add
one
abstraction,
which
is
the
cut
through
of
the
scheduler
level.
So
it's
kind
of
like
making
ourselves
useful
and
thinking
in
the
way
that
they're
already
solving
the
problem
and
then
say
hey.
We
can
help
solve
this
problem.
Here's
an
example
of
it
and
then,
but
what
we
think
is
that
everybody
should
moving
like
now.
It's
like
the
we're
building
everybody's
building
like
they
take
the
current
idea
and
they
add
one
change.
B
All
we're
trying
to
do
is
take
three
ideas,
put
them
together
and
then
pull
together
everybody's
one
ideas
into
some
hierarchy
of
those
things
so
yeah.
I
think
that's
a
reasonable
approach.
We
should
just
treat
it
as
if
it's
a
stepping
stone,
not
a
destination
and
call
it
out
like
that,
like
hey
here's,
the
simplest
possible
cluster
scheduling
where
you
could
just
reuse
that
here's
a
write-up
of
how
you
could
do
it
right,
that's
left
to
the
reader.
B
C
Or
because,
finally,
the
the
current
scheduler,
even
part
of
the
current
cluster
controller
would
be
sort
of
examples.
In
fact,
I
mean
use
cases,
examples
of
use
of
the
minimum
api
server
and
maybe
pairing
this-
I
mean
some
sort
of
re-org
of
of
the
repo
sources
first
to
reflect
that
pairing,
the
such
rear
with
you
know
the
the
facts
to
provide
kcp
as
a
as
an
api.
Just
you
know
even
the
simplest
simplest
bits
of
of
this.
C
You
know
extracting
part
of
the
kcp
main
file
to
allow
people
around
run
their
own
code
on
you
know,
just
after
after
on
post
start
or
something
like
that,
I
don't
know,
but
at
least
maybe
a
first
step
could
be
just
rear.
The
code
to
separate
the
core
kcp
value,
minimal,
api
server
resource
type
imports,
cd
negotiation
and
and
separate
that
inside
the
card
from
other
packages,
which
would
be
more,
you
know,
in
a
different
area,
so.
B
That
would
be
my
bias
because
I
I
do
think
if
we
can't
prove
transparent
multi-cluster
can
be
made
to
work
and
jason
david
me,
and
then
you
know
others
who
pay
attention
and,
like
you
know,
devon
cares
about
kind
of
a
very
specific
use
case
and
the
virtual
cluster
guys
will
care
about
a
very
specific
use
case.
Jason
and
the
minimal
api
server
will
care
about
minimalism.
B
We
want
everybody
to
kind
of
see
their
thing,
but
we
still
have
to
if
we
can't
do
transparent
multi-cluster.
A
lot
of
the
house
of
cards
comes
tumbling
down.
I
feel
like
we
need
a
mental
pattern
that
we
can
be
like
yep.
We
think
this
is
achievable
and
then
we
scale
it
so
like
the
scaling
might
be.
Let's
get
three
people
working
on
minimal
api
server
and
the
cut
for
the
library.
B
Let's
get
three
people
working
on
what
the
what
the
syncer,
the
the
starting
from
the
scaffolding
with
the
generic
secret,
and
then
we
can
say:
okay,
hey
virtual
cluster,
so
we're
pretty
convinced
that
our
crazy
use
case
would
be
there.
We're
ready
to
double
down
on
making
sure
that
we
could
fold
the
two
code
bases
together
and
we'll
take
this
of
yours
and
yours
with
this
and
then
like.
B
A
Yeah
yeah
yeah.
I
think
I
think
I
went
down
a
wrong
path,
not
that
it's
a
bad
path,
but
a
wrong
path
about
what
transparent,
multi-cluster.
How
much
transparency
you
were.
Looking
for,
right,
like
like
to
be
able
to
express
constraints,
requires
some
visibility
into
what
multi-cluster
is
happening
but
yeah,
so
it's
like,
but
at
the
same.
B
Time
like
this
is
the
so,
if
we
can't
do
95
percent
transparency,
we
have
to
go
back
and
and
and
come
out
a
different
approach.
But
if
you
can
do
95
transparency,
then
we
then
have
to
be
able
to
do
preference
of
five
different
dimensions.
I
think
the
preference
stuff
helps
and
what
would
be
is
like
okay.
So
now
we
got
a
preference
step
in
that'll
color.
How
we
think
about
the
rest
of
it.
We're
gonna
have
to
do
that
anyway.
A
Yeah
so
right,
this
work
is
not
wasted,
it's
just
not
yet.
First
so
for
the
for
the
next
demo,
we're
not
going
to
care
about,
I
think
you're
saying
we
should
not
care
about
preference.
We
should
not
care
about
expressing
scheduling
constraints.
We
should
focus
on
being
able
to
do
the
demo
of
add
a
third
cluster.
It
spills
over
delete
it.
It
goes
back
to
the
two
yep
and.
B
Then
do
delete
and
I
think
like
delete
the
one
and
it
moves
so
spill
or
move.
We
can.
We
could
do
spill
and
then
do
move
next
or
we
can
do
spill
and
move
at
the
same
time.
Move
requires
a
bunch
of
other
coordination,
so
there's
a
bit
of
like
we
can
do
it
without
the
app
level
stuff
and
be
like
the
same
thing
like.
B
A
I
think
the
the
code
for
being
able
to
spill
into
a
third
cluster
is
if
it
is
generalizable
enough,
is
the
same
code
for
saying,
oh
no,
I
am
only
in
like
I
am
supposed
to
be
scheduled
across
as
many
clusters
as
we
have,
and
there
are
only
two.
It's
it's
just
the
controller
right.
It's
just
saying
like
fit
me
into
what
is
available
at
all.
B
Well,
a
well-designed
control
loop,
I
think,
is
the
fundamental
it's
easy
to
do
the
one
way
and
then
not
think
about
the
sync
loop,
but
like
with
the
inputs
to
the
sync
loop
right
and
so
that
that
may
be.
My
argument
for
changing
from
cluster
to
location,
which
would
be
the
location
coordinates,
could
just
be
a
cluster
name
and
it's
okay
for
it
to
stay
cluster
now.
But
if
then,
if
you
say
like
clusters,
we
want
to
at
least
once
we
get
to
the
transparent
part.
B
A
B
Safely
and
transactionally
too,
and
I
think
that's
that
that's
part
of
the
transparent
multi-cluster,
which
is
if
we
can't
move
a
singleton
stateful
set
because
we
know
pvs
are
going
to
be
harder
to
move,
but
like
we
have
a
rough
idea
of
how
you
could
like
you,
use
the
snapshot.
Api
you'll
create
a
new
pvc
on
the
new
cluster
and
you'll
say
snapshot
source
like
the
coordinates
of
the
underlying
and
we'll
hack
that
together
make
it
work.
We
know
how
multi-cluster
ingress
could
work.
Joaquin
did
a
demo.
B
That's
like
super
easy
to
reason
about
which
is
like
you
know.
Each
of
the
clusters
can
say:
oh
this
has
the
same
route.
Therefore,
I
just
give
it
to
traffic,
or
I
redirect
it
to
one
of
the
others
service
to
service.
We
don't
have
to
worry
about
yet,
and
then
we
can
kind
of
gloss
over
identity
and
all
those,
but
once
we
have
that
bones
in,
we
definitely
need
it
to
go
from
like
one
two
three
down
to
one
one,
to
zero
one
to
one
one
to
two
to
one.
B
All
of
those
are
all
of
those
are
just
modes
of
it
and
then
the
different
strategies,
if
we
had
the
sinker
the
split
strategy,
yes,
that
syncer
and
these
like
with
the
stripper
not
strip
like
I
don't.
I
won't
call
this
like
a
workflow
engine
for
my
transparent
multi-cluster,
but
at
least
in
my
head,
like,
I
think,
we're
probably
gonna
end
like
just
looking
at
the
list
of
resources
like
there'll,
be
a
set
of
strategies.
B
That
also
then
leads
into
the
library
aspect,
which
is
oh,
you
want
your
specialized
thing.
Maybe
kcpa
is
a
project
when
it
gets
to
that
phase
could
be
like
we
will.
Let
anyone
in
the
world
give
us
a
sync
strategy
that
has
minimal
dependencies
on
existing
code
as
long
as
it
works
for
the
use
case,
and
we
can
generalize
it
so
then
like
then
we
would
be
very
open
to
like
hey
you've
got
crazy.
You
got
an
scd
object.
Oh
this
is
an
open
source
project.
B
Please,
like
you,
need
an
lcd
strategy
and
it
doesn't
generalize
it's
a
little
bit
like
the.
I
was
thinking
like
the
linux
kernel
tree,
which
is,
if
you're
willing
to
support
a
driver.
You
can
merge
a
driver,
but
you
have
to
follow
the
kernel
conventions
and
then,
when
you
get
refactored,
you
have
to
have
the
test
or
you
know,
we'd
have
to
have
the
test,
but
if
we
could
come
up
with
enough
of
that
in
like
strategies
or
like
the
scalable
things
so
that
anybody's
like,
oh,
I
want
to
go.
B
Do
a
object,
storage
strategy.
That's
like
you
know
it
does
very
specific
things.
If
you
can
get
that
code.
Decoupled
enough-
or
you
can
say
like
all.
I
need
is
this
strategy
that
my
controller
will
pick
it
up.
Maybe
we'll
merge
it
and
then
we'll
we'll
say
like
add
an
ed
test
and
verify
or
add
a
unit
test.
Well
refactored
as
we
go,
we
guarantee
you
that
once
that's
merged
it
stays
working.
B
That
could
be
like
a
long-term
that
was
like
a
yeah,
because
the
alternative
is
like
everybody,
forks
it
right
and
it's
like
one
fix,
but
no
one
and
like
this
could
be
a
way
for
us
to
be
like.
Oh
look:
if
anybody's
willing
to
go
fix,
ncd
object,
syncing
and
you
can
show
that
it
works.
Awesome.
We've
got
that
syncer
and
then,
if
you
don't
like
that
syncer
you
can
create
a
v2
syncer
and
choose
that
different
strategy.
It's
just
like.
B
Types,
I
don't
know,
that's
a
great
question.
I
would
hope
that
we
can
have
strategies
that
are
mostly
non-parameterizable,
but
if
you
need
us-
and
maybe
this
is
like
what
we
have
to
think
about-
it's
like
okay,
so
say
transparent,
multi-cluster
starts
working
and
someone
wants
to
extend
transparent
multi-cluster
for
a
net
new
thing.
They
reuse
a
strategy,
they
build
their
own
extension
yeah.
So
that's
like
delegation.
C
Yeah,
because
it
makes
me
think
you
know
in
theords,
for
example,
for
the
scale
and
and
status
of
resources,
you
can
define
mainly
the
field
in
the
object
that
that
will
be
used
to
implement
this
typical
behavior.
We
possibly,
we
could
have
some
sort
of
strategies
that
are,
you
know,
always
the
same
typical
behavior,
but
then
that
take
their.
You
know,
information
from
a
different
field,
some
some
sort
of
templates
for
strategies
that
are
already
prepared
that
but
people
that
and
then
people
can
declaratively.
B
So
so,
like
hypothetically,
just
looking
at
what
jason
already
has
done
for
splitter
cube,
fed
v1
and
v2,
both
had
policies
that
are
gonna
like
that,
both
share
basic
routes
with
what
jason's
done
and
then
go
in
a
couple,
different
directions.
Carmada
has
a
couple,
it
seems
to
me
like,
and
I
want
to.
I
want
to
play
this
out
a
little
bit
with
us
first,
but
I
bet
you
there's
an
80
20
rule
at
play
here
for
splitting,
which
is
the
vast
majority
of
the
people.
B
The
vast
majority
of
the
time
would
be
better
off
with
a
couple
of
basic
match,
existing
use
cases
and
that's
kind
of
what
those
projects
represent.
If
we
could
get
the
splitter,
the
stateful
set
down
to
like
four
patterns
with
three
patterns
like
the
staple
could
be
like
the
stateful
strategy
could
potentially
just
actually
be
a.
Maybe
it's
like
the
field
that
you're
going
to
split
on
the
field
that
you
have
to
inject
whatever,
like
that's.
When
we
do
it
and
we'd
say
like
hey.
B
B
That's,
like
you
know,
someone
who's
using
a
staple
set
today
might
rely
on
the
fact
that
the
zero
end
entity
is
the
leader
we
would
might
have
to
put
something
that
says
only
set
a
boolean
on
the
first
one
and
pick
in
the
first
one
like
that
could
be
part
of
a
strategy
but
again
like
if
the
strategies
are
reasonably
based
on
use.
Cases
cover
an
eighty
percent
role
with
twenty
percent
of
the
features,
then
the
escape
patch
is
either
go.
Build
a
sub
resource.
B
I
haven't
quite
figured
out
how
writing
a
controller
would
work,
but
we
should
talk
about
that
as
we're
going,
which
is,
it
might
be
that
pre-scheduling
we
do
something
at
the
kcp
level
that
lets
people
provide
input
about
scheduling
constraints
in
a
way
that
the
scheduler
doesn't
so
like.
In
cube
admission
like
with
namespaces,
we
made
a
mistake
with
namespaces,
which
is
we
did
tear
down,
but
not
initialization,
and
we've
tried
to
get
momentum
to
get
namespace
initialization
back.
The
initializer's
work
in
cube
was
gonna,
be
generic.
B
We
think
about
the
initialization
for
extensibility
cube
did
not,
and
it's
a
mistake
so
that
there's
a
there
might
be
a
pattern
there,
which
is
like
the
scheduler's,
like
I'm
still
waiting
for
input,
because
I
know
that
there's
a
couple
of
people
waiting
for
in
pogba,
it's
an
initializer
pattern
or
whatever,
and
so
it
waits
until
enough
info
is
in
and
then
it
makes
a
scheduling
decision
and
if
it
can
move
gracefully
at
some
point,
like
maybe
some
strategies
explicitly
say
they
don't
support
movement.
I
can
imagine
a
few
like
that.
B
It
might
be
that
the
scheduler
is
like
I've
got
to
make
a
good
decision,
a
perfect
decision
versus
I
can
make
it
good
enough
and
just
move
it
later
then
moving
it
later
would
be
ideal.
So
that
would
be
great
because
then
we
would
just
build
that
like
we
would
take
the
core
controller,
jason
and
then
we'd
say
right.
B
A
Okay,
so
thinking
toward
next,
what
the
next
demo
will
be,
it's
effectively
going
to
be,
instead
of
splitting
once
and
calling
it
a
day,
we
keep.
We
keep
splitting
based
on
current
information
as
of
right
now.
So
when,
when
a
new
cluster
comes
in
it'll
split,
do
we
also
want
to
then
go?
There's
there's
always
100
directions.
A
B
And
it's
interesting
too,
because
the
spreader
strategy
could
be
implemented
on
the
sync
side
if
we
didn't
need
to
service
the
status
the
same
way.
So
maybe
the
question
then,
is:
how
do
you
generalize?
The
splitter
pattern
is:
what
is
the
user
expectation
for
transparent
multi-cluster
so
that
they
know
how
do
they
know
which
clusters
this
lands
on?
So
there's
a
couple
ways:
we
could
do
it
the
splitter.
B
The
separate
object
is
a
bit
advantageous
up
until
you
have
lots
of
clusters
and
then
I
think
splitter
gets
a
little
painful,
but
the
splitter
has
one
advantage,
which
is
you
could
go
tweak
those
objects
individually?
That's
not
really
transparent,
though,
and
k
nate
or
cube
fed
struggled
with
this,
which
was
like
at
some
point
like.
What's
the
transparency
you
want,
is
it
an
80
20
rule,
or
is
it
like
a
policy
that
you're
willing
to
do
up
front?
I
think
we're
kind
of
leaning
towards
80
20,
where
it's
like
you
should.
B
We
should
kind
of
support
the
like
it
kind
of
just
works
with
some
really
simple
stuff,
and
then
you
go
all
in,
but
all
in
requires
you
to
add
an
object
that
totally
customizes
the
strategy
and
the
moment
you're
in
those
deep
use
cases
you're
not
in
transparent
multi-customer.
That
would
be
my
bias,
because
that
creates
a
nice
gap
in
the
middle
which
is
like
most
people
are
happy
transparent.
B
You
can
still
accomplish
complex.
What
does
that
trade-off?
Look
like
then.
The
second
option
would
be
like
status
summarization
so
like
we
could
just
create
a
couple
of
conditions
and
yeah.
Do
it
that
way,
another
one
is
sub-resource,
and
then
the
question
is
like
one
of
the
nice
advantages
of
writing
it
to
the
object.
Is
I
kind
of
at
some
point
think
that
we
want
to
have
all
of
the
client
of
the
table.
A
B
Annotation
or
annotation,
or
whatever
the
annotation
as
a
state,
you
could
absolutely
say:
oh,
let's
figure
out
how
to
make
the
table
printer,
be
dynamic
to
something
that's
a
characteristic
of
the
logical
cluster
or
the
extension
new
use
case,
and
we
can
hack
it
in
at
first
and
then
come
back
to
it
and
then
what
it
and
then
that
also
tees
up
the
one
that
I
said.
I
was
going
gonna
work
on
and
haven't
worked
on
yet,
which
is
the
the
punch
through
sub
resources
or
the
punch
through
resources,
which
would
be.
B
It
may
be
that
it's
okay
to
have
the
one
deployment
up
top,
but
then
you
can
tell
call
cube
control,
get
replica
sets
and
you
see
all
the
replica
sets
stitched
in
from
the
child
clusters
in
a
synchronous
call
kind
of
fashion.
I
wonder
if
these
play
around
with
that,
but
there
could
be
a
sub
resource
which
just
summarizes
it
cube.
Fed
one
was
a
cube
fed
one
or
two:
it
was
q
fed
one,
because
q
fed
two
didn't
have
aggregated
api
servers
that
I
remember
the
sub
resource.
B
One
would
be
interesting
because
then
that
would
also
encourage
us
to
do
make
it
cube
control,
get
sub
resource
work.
So
then
you
could
say,
like
you
know,
control
get
pods
or
control
get
deployments.
It
lists
the
locations,
cube,
control,
get
deployments
dash,
dash,
sub
resource
locations,
shows
you
the
details
about
where
it
got
placed
in
a
way.
That's
actually
interesting,
and
maybe
the
sinker
has
a
custom
sub
resource
that
pairs
with
it
like.
B
So
it's
a
way
of
like
forcing
us
to
think
about
the
end
user
experience
is
what
matters
for
transparent,
multi-cluster,
the
flexibility
and
the
orthogonality
is
the
we
have
to
do
that,
but
we
have
to
do
it
in
use
case.
What
does
a
human
want?
They
just
want
this
stuff
to
just
work.
It's
and
that's
why
transparent's
nice,
because
we
can
basically
say
if
it
would
confuse
an
existing
cube
user
can't
be
done.
C
Yeah,
because
the
the
current
demo
that
you
know
shows
you
three
deployments
on
the
kcp
side
is
is
quite
I
mean
can
be
quite
disturbing.
Why
do
you
see
the
other
deployments
as
a
typical
user?
I
would
expect
those
two
subsidiary
deployments
that
will
be
synced
to
physical
clusters
to
be
created
in
some
sort
of
other
name
space
or
some
place.
That
is
not
visible
by
default
right,
but
we
know
that.
B
B
I
don't
know
I
mean
the
thing
about
transparent,
so
cube
fed.
These
were
all
mixed
and
I
actually
think
that
you're
right
about
persona,
but
like
one
of
the
challenges
with
q
fed
was
you
had
a
perspective
for
a
cube
cluster
and
a
perspective,
a
q
cluster
app
and
a
perspective
for
a
cube,
fed
app
and
they
weren't
the
same
and
they
behave
differently.
B
B
Cube
user
has
to
come
here
and
it
just
works
the
way
they
expect
up
until
the
point
where
we
peel
the
curtain
away
because
it
doesn't
be
perfect
and
then
they
can
go,
get
the
additional
data,
but
they
go
from
the
it
just
worked.
The
way
I
expected
and
there's
just
one
little
thing
that
I
oh
this
is
interesting.
Oh
I
dig
in
now
I
can
yeah
yeah.
A
A
B
And
maybe-
and
maybe
this
is
like
in
the
generic
like-
so
maybe
the
splitter
strategy
and
again
like
cube,
fed
kind
of
tried
this,
but
I
I
want
to
come
back
and
like
examine
what
they
did
and
then
try
something
different
which
would
be.
Maybe
the
splitter
strategy
actually
writes
an
annotation
back
to
the
object
that
has
that
has
the
behavior
of.
B
Maybe
that
then
comes
with
location,
which
is
maybe
splitter
strategy
is
itself
something
that
could
show
up
in
acute
control
get
because
what
we
say
is
like
you
know,
I
can
look
at
an
object,
figure
out
what
locations
it's
on
or
what
it's
assigned
to
0,
1
or
n,
but
I
could
also
get
info
status
from
the
strategy
either
as
conditions,
because
conditions
can't
carry
arbitrary
fields.
So
maybe,
like
the
condition
message,
has
it
but
then
there's
something
like
the
annotation.
B
Just
for
the
sake
of
argument
for
right
now
also
carries
information
about
the
strategy
which
could
be
generically
shown
and
then
maybe
there's
a
strategy.
Sub-Resource
or
maybe
there
could
be
multiple
strategies
like.
I
guess
it
really
depends
like
we
need
to.
We
need
to
work
through
deployments
enough
that
we
can
be
like
one
strategy
with
three
parameters.
Is
enough
or
one
strategy
with
no
parameters,
but
an
upper
separate
object.
So
then,
naturally,
when
I
see
that
location
you'll
be
like
hey,
do
you
have
a
policy
or
not?
C
C
B
That's
the
difference
from
cube,
fed,
b1,
logical
clusters,
the
other
difference,
if
you
get
it
all
working
now,
that
cube
is
super
successful
and
you
can
add
extensions.
Can
the
strategy
apply
to
other
resources?
If
you
can
do
all
three
of
those
things,
you
have
demonstrated
something
that
no
one
else
can
do
quite
yet,
which
is
like
just
make
multi-cluster
a
detail.
B
And
is
a
concrete
strategy.
I
think
it's
also
a
great
way
to
start,
because
we
don't
actually
have
to
go
to
a
generic
strategy
approach,
and
so
we
have
a
splitter.
That
represents
the
split
strategy
and
we
can
say,
like
oh,
like
what
other
resources
might
fit
into
the
splitter
strategy.
Yeah
config
right.
B
C
A
C
Yes,
the
second
point
you
mentioned
because
it
it's
amusing
it
it
makes
me
think
of
it.
I
think
there
are
some
common
aspects,
especially
you
know.
For
now
we
just
import
always
the
api
resource
of
the
last
cluster.
We
don't
do
any
negotiation
any
div,
so,
of
course
we'll
have
to
be
able
to
if
you
have
a
resource
already
existing
that
had
been
imported
by
a
crd
into
a
logical
cluster,
and
then
you
plug
a
new
physical
cluster
that
will
try
to
import
the
same
resource
as
well.
B
C
Exactly
and
the
implementation-wise
that
you
know
what
we
were
discussing,
I
see
a
sort
of
parallel
between
the
the
two
cases
because
for
the
deployments
for
example,
of
course
it's
the
it's
at
the
level
of
of
the
objects
of
the
instances,
but
then
for
one
deployment,
one
abstract
deployments.
Let's
say
like
that.
C
You
have
two
subsidiary
deployments
on
the
kcp
side
that
will
be
synced
and
then
we
would
have
you
know
at
some
point
and
to
if
they
exist
as
real
deployments
or
as
subresources
or
as
statues
of
a
strategy
instance
or
anything
else.
At
some
point
we
have
to
to
describe
them
and
and
to
track
them
as
well,
and
that's
a
bit
the
same
for
cds,
because
now
we
import,
you
know
the
result
of
the
import
of
of
an
api
resource
as
a
crd
in
the
logical
cluster.
C
But
then,
when
we
start
thinking
about
how
do
we
track
that
in
time?
If
there
is
one
c,
if,
if
there
is
an
api
resource
of
a
given
physical
cluster,
that
changes
one
imported
crd
from
another
logical
cluster,
that
changes
for
example,
then
we
have
to
reconcile
that
to
check
that
everything
is
still
consistent.
So
we
have
something
to
track
and
finally,
we
would
have.
C
B
That's
a
pretty
complex
graph
theory
problem,
but
it's
tractable.
What
I
would
probably
say
is
we're
looking
for
the
semantics
on
the
crds
such
that
callers.
Don't
have
to
worry
about
this
stuff,
and
so
I
think
one
mental
model
would
be
somewhere.
You
have
to
record
the
decision
of
the
set
of
fields
for
yeah.
That's
the
point
for
given
logical
clusters.
You
said
that
could
be
a
crd
in
that
logical
cluster,
but
if
we
have
to
reuse
it
across
a
lot
of
them,
we
might
need
some
abstraction
there.
B
So
it's,
I
think
the
crd
mechanism
is
going
to
be
a
lot
of
code.
Honestly,
maybe
there's
a
simpler
approach,
but
from
a
use
case
perspective
you
have
to
lock
in
a
set
of
versions.
You
have
to
know
what
that
schema
is
and
then
an
incompatible
chain
like
if
you
brought
in
a
new
location
and
that's
incompatible
with
those
you
have
to
make
a
decision
one
way
or
another
like
location,
yeah
or
you
or
you
break
all
three
of
them.
B
A
Yeah,
I
think
I
think
we
can.
We
can
get
a
demo
of
this.
That
is
so.
The
the
next
demo
is
add.
A
third
cluster,
see
it
take
up
space
in
that
cluster.
Remove
that
cluster
it
goes
back.
We
can
also
do
add.
A
third
cluster.
Okay,
now
upgrade
to
a
version
of
kubernetes
where
init
containers
don't
exist,
but
my
deployment
requires
init
containers,
and
so
it
had
been
scheduled
there.
It
gets
evacuated
from
there
and
sucked
into
the
two.
A
B
Be
distinct
from
other
types
of
schedulers,
it
explicitly
depends
on
syncing,
like
a
fairly
generic
mindset
to
resource
thinking
and
a
logical
model
of
are
the
things
that
I've
already
synced
compatible
with
the
new
thing.
But
the
idea
would
be
to
make
the
sinker
not
have
to
worry
about
that
and
the
scheduler
to
only
loosely
care
about
that.
But
the
the
crd
normalization.
A
B
C
C
B
Constraint,
which
would
be
it's
like
the
storage
of
that
I
would
go
ahead
and
think
of
that
as
a
different
resource
type
than
crd
yeah,
because
it's
part
of
a
controller,
logical
subsystem
that
maybe
and
like
yeah
so
goal
one
is
represent
that
history
merge
it
into
crds
logical
clusters,
goal
two
might
be
make
it
really
efficient
or
goal
two
might
be
figure
out
how
it
fits
into
a
hierarchy.
Like
does
I
kind
of
think
crds
are
driven
by
location
for
transparent
multi-cluster.
B
B
B
B
Yeah
and
and
maybe
like
the
the
like,
you
can
imagine
a
future
state
where
the
sinker
is
creating
these
crds
or
creating
the
other
types
of
crd
resources
for
versions
and
then
the
whole
crd
serving
mechanism
in
kcp
in
the
minimal
api
server
is
completely
stripped
and
replaced
by
a
more
advanced
version
of
it
to
solve
the
logical
multi-cluster
case
in
a
way,
that's
flexible.
That
probably
could
be
how
it
plays
out,
which
is
like
cube,
stays
the
same.
B
We
make
the
cut
points
in
the
cube
api
server
palatable
for
replacing
the
whole
crd
implementation
with
a
separate
one
which
it
is
today
like
it's
not
actually
that
coupled,
but
we
would
make
those
cut
lines
stronger
and
then
there
would
be
an
explosive
multi-cluster
crd
normalization
exposure
mechanism
that
reads
these
other
crd
types:
surfaces
them
into
logical
clusters
based
on
what
locations
are
there
and
then
someone
else
could
take
that
and
remix
that
and
do
whatever
they
want.
Maybe
it's
only
us,
or
maybe
it
goes
into
core
cube
and
every
cube
cluster
has
this.
B
C
So
from
no
bigger
bigger,
so
for
now
I'll
continue,
I
started
implementing
a
share,
my
difference
already
just
you
know
you
have
two
sheamus
from
from
cod
jason,
jesus,
props
and
and
then
you
get
the
div
and
based
on
that,
we
we
could.
You
know,
go
the
next
steps
and
define
rules
to
know
when
shamers
are
compatible
or
not,
and
how
to
and
and
and
you
know
the
rules
also
to
to
to
deduce
if
it's
valid
or
not
to
create
a
lcd
and
based
on
that
we
would
be
able
to.
C
You
know,
go
within
the
past,
you
you
mentioned
and
storing
the
the
various
shame
as
and
then
including
all
that
into
a
higher
reconciliation
loop,
so
that
when
some
api
changes
that
were
that
was
imported,
we
would
check
again
the
validity
of
all
the
the
sources
from
the
currently
used
resulting
crd.
Does
it
make
sense
to
you
as
a
you
know,.