►
From YouTube: Community Meeting July 27, 2021
Description
No description was provided for this meeting.
If this is YOUR meeting, an easy way to fix this is to add a description to your video, wherever mtngs.io found it (probably YouTube).
A
B
A
But
we
didn't
have
a
meeting
last
week
in
the
ensuing
two
weeks,
we've
had
some
conversations
sort
of
offline
in
various
groups
about
part
of
the
best
way
to
proceed,
one
of
one
of
the
ways
that
one
of
those
conversations
is
with
michael
elder
who's
here,
who
it's
from
the
open,
cluster
management
and
and
red
hat
acm
ocm
is
open.
Cluster
management
acm
is
advanced.
Cluster
management.
A
Is
that
correct
team
at
red
hat,
and
basically
I
mean
we-
we
have
been
talking
and
he,
the
ocm,
community
and
organization
and
project
have
have
tried
some
of
these
paths
before
some
of
the
things
that
ocm
does
are
different
than
what
kcp
plans
to
do,
but
some
are
very
similar
in
particular,
going
over
the
architecture
of
ocm.
The
cluster
registration
process
is
quite
a
lot
better
than
what
we
have
in
kcp
today
I
mean,
I
think
we
know
kcp
does
not
like
the
cluster.
A
Registration
is
kind
of
bad,
but
ocm
has
a
really
good
one,
and
I
think
we
could
learn
a
lot
from
it.
They
also
have
interesting
models
for
describing
where,
like
here,
is
a
deployment.
Here's
where
to
put
it,
I
guess
and
and
how
to
pass
that
down
to
the
cluster
there's
they
don't
just
send
the
deployment
down.
They
send
it
in
like
an
envelope
object.
So
I
guess
michael,
I
will
pass
it
off
to
you.
B
B
Now,
okay,
so
first
off,
maybe
just
a
quick
ten
thousand
foot
level.
Why
am
I
here?
What's
the
objective
for
today,
what
do
we
wanna
get
across?
I
just
wanted
to
come
and
talk
about
what
we're
doing
in
open
cluster
management.
I
wanted
to
explore
some
of
the
concepts
that
are
there,
where
I
think
there
is
some
complimentary
or
overlapping
capability
that
might
help
accelerate
some
of
the
goals
of
kcp.
B
So
I'll
explain
a
little
bit
about
the
open
cluster
management
project
and
then
I
wanted
to
walk
through
some
of
the
concepts
that
I
think
are
useful
I'll.
Try
to
put
them
in
context
of
kcp,
so
bear
with
me
just
a
minute,
I'm
going
to
talk
about
open
cluster
management,
and
then
I'm
going
to
try
to
use
that
context
to
talk
about
how
it
it
might
be
interesting
to
explore
integration
between
kcp
and
open
cluster
management
or
evolving.
B
Some
of
what's
in
open
cluster
management
to
better
support
the
use
cases
in
kcp,
we
can
dive
into
some
command
line
examples
of
a
open
cluster
management
hub
managing
a
fleet
of
clusters.
If
we
want
to
get
more
concrete
on
on
those
examples,
so
first
off
open
cluster
management,
this
is
a
project
that
has
originated
from
red
hat.
We
have
been
engaging
in
open
community
meetings
about
every
other
week
going
back
to
just
before
the
beginning
of
the
year.
B
We
have
been
engaging
ant
group
and
financial
group
somali
cloud
and
then
most
recently
tencent
in
contributing
and
getting
engaged
in
the
community.
So
while
it
was
started
by
red
hat,
we're
beginning
to
see,
other
vendors
also
participate
in
the
in
those
community
contexts
in
this
community
meetings.
B
The
objective
of
open
cluster
management
is
to
provide
a
way
that
we
can
understand
an
entire
fleet
and
to
address
the
problems
that
we
typically
see
an
operator
or
an
orchestrator
has
to
address.
In
order
to
become
multi-cluster
aware,
it
is
a
different
scope
of
problem
than
I
think
what
kcp
is
really
going
after
open.
Cluster
management
is
very
much
a
white
box
capability,
we're
layering
a
set
of
apis
that
we
expect
cluster
administrators
or
fleet
administrators
other
roles
that
are
specific
to
application,
release,
automation
or
rules
that
are
specific
to
governance
and
compliance.
B
All
would
would
basically
be
amplified
on
top
of
their
existing
behaviors
for
individual
clusters
through
what's
in
open
cluster
management,
and
so
that's
a
very
different
goal
set
than
one
where
kcp
is
providing
a
more
developer.
Centric
facade.
On
top
of
you
know
this,
this
close
box
idea
of
how
we
actually
get
code
running
somewhere
so
from
there.
B
B
There
is
another
proposed
project
in
a
similar
domain
around
carmada,
which
is
an
injury
from
huawei
in
this
space.
There
are
some
concepts
that
that
are
consistent
between
what's
in
carmada
and
what's
an
open
cluster
management,
but
there's
no
formal
intent
to
align
or
organizational
alignment
in
that
today,
but
just
be
aware
that
they've
also
submitted
to
cncf
project
proposal
as
well.
But
if
we
look
at
what's
in
open
cluster
management,
there
are
capabilities
that
focus
on
inventory,
work,
scheduling,
work,
distribution
and
things
like
rbac
and
as
a
whole.
B
B
So
three
examples
that
are
that
certainly
have
some
related
use
cases,
but
have
very
different
concepts
that
are
that
they're
trying
to
provide
to
users
each
of
these.
Ultimately,
needs
a
way
to
think
about.
First
off
the
inventory
of
available
clusters
and
open
cluster
management
defines
a
open
cluster
management.io
api
domain,
and
within
that
there
is
a
managed
cluster
api
kind.
B
Then
we
need
a
way
to
assign
desired
applications
or
configuration
to
some
part
of
that
set
of
clusters.
There's
an
api
kind
of
run
placement.
To
some
extent.
You
can
almost
think
about
placement
as
describing
a
like
a
sql
select
right.
It's
going
to
describe
a
set
of
conditions
that
are
evaluated
against
the
available
clusters
and
a
set
of
decisions
are
generated
which
can
then
be
used
by
any
multi-cluster
aware
orchestrator.
B
B
B
This
is
very
consistent
with
kcp's
notion
of
a
syncer,
but
it's
implemented
in
a
different
way,
so
the
goal
of
manifest
work
is
simply
to
assemble
a
set
of
parts,
a
set
of
kubernetes
api
objects
that
are
reconciled
and
applied
to
a
target
cluster.
If
I
delete
the
manifest
work,
api
kind,
the
corresponding
objects
will
get
removed
from
the
target
cluster.
B
This
is
today
a
pole.
Centric
model,
an
agent
known
as
a
cluster
lit
on
the
target
cluster,
is
calling
back
into
the
hub
seeking
desired,
manifest
work
that
need
to
be
applied.
Reconciling
those
on
manage
cluster
and
reporting
status
and
feedback
to
the
hub
was
it
applied
successfully?
Is
there
a
conflict,
dot
that
dot
and
then
finally,
one
of
the
key
aspects
is:
how
do
we
make
the
management
of
a
fleet
consumable
to
a
organization,
and
a
lot
of
that
has
to
do
with?
How
do
you
express
our
back?
B
How
do
I
express
I
want
this
team
of
human
beings
to
be
able
to
consume
and
access
this
collection
of
clusters,
and
so
there's
a
concept
introduced
as
manage
cluster
set.
The
term
cluster
set
is
intentionally
derived
from
work.
That's
in
sick
multi-cluster,
but
manage
cluster
set
to
some
extent
you
can
think
about.
You
can
oversimplify
as
a
project,
type
of
construct
or
namespace
construct
that
the
only
thing
that
goes
in
it
are
cluster
related
things.
B
Strictly
speaking,
that
includes
managed
cluster,
but
also
because
we
are
focused
on
provisioning
life
cycles
for
openshift.
We
also
have
a
way
to
assign
content
from
hive,
including
things
like
hive
cluster
deployment,
which
is
an
object
that
represents
a
provisioned
openshift
cluster,
a
hive
cluster
pool,
which
is
a
self-service
concept.
B
Now
these
are
sort
of
the
four
primary
value
statements
that
we
think
differentiated
over
other
approaches
in
the
community
today,
because
it's
not
necessarily
trying
to
be
the
only
way
that
you
federate
all
the
things.
But
it's
trying
to
be
an
underpinning
core
capability
that
can
be
consumed
by
other
projects
to
become
multi-cluster
aware.
C
One
of
the
things
that
I
want
the
kcp
side
to
explore
is
very
much
the
idea
that
those
manifests
are
already
cube-like
objects
and
in
their
innate
sense
they
are
transformed
without
going
like
they
don't
have
to
be
collected
from
sources,
because
they're
already
in
the
source
doesn't
mean
manifest.
Work
may
not
be
useful
for
them,
but
there's
less
there's
no
requirement
for
them
to
be
collected
from
external
sources,
like
that's
an
external
problem.
C
So
you
could
actually
see
manifest
work
existing
on
the
left
side
of
a
transparent,
multi-cluster
pipeline,
or
you
could
see
it
being
used
on
the
right
side,
but
I
think
that
would
be
like
that's
actually
a
really
useful
distinction.
It's
the
idea
that
it's
not
about
transforming
arbitrary
sources,
there's
already
an
api
source
object
that
gets
one
to
one
mapped
or
one
to
end
mapped
so
working
through,
like
maybe
like
there's
a
terminology
gap
here,
is
like.
What's
the
concept
that
underpins
manifest
work?
C
B
B
B
B
Well,
let
me
let
me
maybe
do
this.
Let
me
set
the
context
for
manifest.
Work
is
an
object
that
a
user
could
define
right,
a
user
can
stand
it
up
and
apply
it
and
it'll
get
distributed
out
to
a
fleet,
and
we
can
also
build
additional
higher
level
abstractions.
That
leverage
manifest
work
to
accomplish
a
goal.
B
So
I'll
come
back
to
this.
This
picture
in
just
a
minute
but
I'll
show
another
abstraction,
which
is
a
policy.
A
policy
represents
a
desired
set
of
configuration
along
with
compliance
and
categorization
data.
That's
used
to
understand
how
this
technical
requirement
maps
back
into
a
data
standard
for
security,
so
how
it
maps
into
the
pci
dss
data
standard
or
the
nist
0853
or
190
data
standards.
B
So
the
reason
that
I
point
this
out
is
that
subscription
itself
doesn't
require
the
user
to
add
all
of
the
child
objects
into
an
envelope.
The
subscription
can
actually
just
point
to
a
github
repo
and
say:
go
fetch
the
customization
yaml
go
fetch
the
helm,
charts,
go
fetch
just
a
raw
directory
of
kubernetes
objects
and
then
deliver
them
out.
If
I
look
at
one
of
the
subscriptions
subscriptions
have
a
concept
of
how
they
link
to
the
placement.
B
B
Historically,
it's
not
actually
generating
a
manifest
work
object
because
manifest
work
evolved
along
a
parallel
horizon,
but
conceptually
it
would
generate
a
manifest
work.
Had
we
built
subscriptions
after
we
built
manifest
work,
we
actually
kind
of
reversed
into
manifest
work
from
other
use
cases.
B
But
I
show
you
this
because
here's
an
example
of
something
that's
not
in
itself
strictly
an
envelope.
It
is
a
pointer
and
a
binding
to
a
placement.
But
under
the
covers,
the
controller
can
package
up
the
children
from
github,
maybe
inject
them
with
templatized
values,
parameters
whatever
and
then
ultimately
create
the
manifest
work.
And
then
the
agent
is
synchronizing
that
manifest
work
envelope
to
a
set
of
clusters.
C
Yeah-
and
I
actually
think
that's
another
good-
that's
another
good
like
thing
to
tease
apart
is
which
constructs
are
orthogonal
or
not,
and
one
of
the
like
any
point
time
you
make
an
api,
you
pick
a
set
of
things
that
are
orthogonal
set
of
things
that
aren't
sometimes
those
are
hit
by
the
implementation.
Sometimes
those
are
right
there
in
the
api.
C
The
idea
that,
like
in
a
lot
of
respects,
there's
similarities
between
manifest
work
and
templates
as
they
were
originally
envisioned,
and
so
there's
the
idea
that
there
is
a
set
of
objects
that
should
exist
and
then
there's
an
ownership
of
the
fields
in
them.
So,
like
the
manifest
work,
owns
all
the
spec
fields
and
maybe
doesn't
ignore,
but
let's
say
for
the
sake
of
argument
like
status
is
ignored
and
then
the
manifest
work
does
manifest
work
today.
Do
you
have
a
pipeline
step
after
manifest
work
in
the
cluster
lit
or
no.
B
B
That
example
is
also
true
for
thanos,
where
we're
basically
configuring
health
management.
It's
true
for
some
work,
we're
doing
upstream
with
argo,
but
that's
a
distinction
where
to
me.
That's
the
type
of
overlap
that
we
would
see
with
things
like
the
splitter
concept.
I'll
show
another
picture
of
that
in
a
minute.
But
let
me
make
sure
that
this
this
flow
of
concepts
makes
sense,
yeah
and.
C
That's
a
good,
so
I
think
yeah,
it's
like
I.
I
think
what
we're
we're
not
concrete
enough
on
is
like
the
transparent,
multi-cluster
idea
and
how
it's
actually
materialized,
like
the
implementation,
is
kind
of
hazy,
because
we're
still
working
on
more
of
the
discussion
points
around
what
the
inputs
would
be
but
like
as
an
example,
manifest
work
is
a
synchronous,
materialization
of
a
of
a
plan,
and
then
it
also
is
a
coordination
point
for
each
individual
cluster
to
check
in
on.
C
Conversely,
if
you
want
to
do
some
deep
transformation
of
that,
you
have
to
figure
out
how
to
represent
what
the
transform
does,
but
you
could.
You
could
put
a
transformation
pipeline
after
the
manifest
work
step,
for
instance,
then
there's
the
question
of
what,
if
you
actually
want
to-
and
I
think
this
is
kind
of
where
we're
we
haven't
yet
gotten
far
enough
to
say
but
it'd
be
like
when
you
want
to
blur
the
lines
actually
between
different
clusters.
C
There
is
no
hub
cluster
in
some
mental
ways
of
thinking
about
like
kcp
like
there
is
no
kcp
instance,
you
don't
talk
to
a
kcp
instance.
You
just
look
at
a
bunch
of
clusters
and
make
a
decision
from
those
apis,
but
the
mindset
would
be
like
you
could
move
manifest
work
at
any
point
like
it.
You
know
something
could
generate
a
set
of
manifest
work
and
keep
a
synchronous
thing.
C
C
Looking
at
policy
objects
generating
manifest
work,
and
then
you
assume
that
the
manifest
work
cluster
lit
pair
well
there's
another
way
of
doing
it,
which
is
a
transformation
to
the
left
of
the
controllers,
might
actually
be
on
the
right
and
replace
cluster
lit
with
controller,
and
then
that
controller
and
that's
like
kind
of
how
that's
one
way
to
think
about
the
splitter
in
the
sinker
that
we're
not
really
exploring
yet.
But
you
could
imagine
a
controller
living
on
an
individual
cluster,
looking
at
50
input
clusters
and
synthesizing
that
into
a
manifest
work.
C
But
well,
if
you
have
no
objects
on
the
left,
you
do
need
to
materialize
it
in
fcd
at
one
point
or
materialize
it
in
the
store.
So,
like,
I
think
we're
like
it's
like
we're.
This
is
really
good
to
see
this,
because
it
can.
We
can
kind
of
like
map
out
what
the
pipeline
looks
like
today
here
and
say:
are
we
going
after
unique
ways
of
looking
at
this
pipeline?
C
That
actually
would
want
us
to
take
those
chunks
and
reuse
them
in
different
spots,
because
manifest
work
is
a
lot
like
a
template
where
you
could
turn
like.
You
could
write
a
controller
that
looks
at
a
set
of
git
repos
and
turns
it
into
a
template.
We
don't
have
a
use
case
for
that
and
I
think
the
manifest
work
concept
and
the
stuff
that's
in
acm
and
ocm
actually
does
better
at
that.
C
B
Point
I
want
to
get
across
is
that
each
of
the
concepts
that
are
in
ocm
are
are
very
loosely
coupled
the
fact
that
we
have
a
subscription
model
that
is
github's
aware
that
could
use
manifest
work
under
the
covers
or
policy
model.
That
is
not
explicitly
get-offs
aware,
but
can
be
tied
into
get-ops.
It
uses
manifest
work.
How
we
configure
submariner,
how
I
can
figure
thinness.
All
of
these
you
know
somewhat
very
different
use
cases
can
leverage
this
same
primitive
under
the
covers,
and
I
think
that's
a
powerful
aspect.
B
I
and
I
let
me
actually
close
this
thought
as
well
about
the
placement
again.
Placement
is
orthogonal.
Placement
of
placement
decision,
don't
strictly
know
about
manifest
work
and
manifest
work
doesn't
strictly
know
about
placement
and
placement
decision
at
least
not.
Today.
There
may
be
some
some
hypothesis
that
it
may
in
the
future,
but
it
does
it
today.
Today
we
expect
that
a
client
is
using
a
placement
in
order
to
define
a
set
of
objects
and
because
of
historical
reasons,
bear
with
me
how
many
you'll
see
placement
rule
policeman.
B
B
Don't
get
too
hung
up
on
that,
but
the
key
thing
about
a
placement
concept
is
that
when
I
represent
this-
and
I
represent
this
api
object
as
a
consumer
of
it.
All
I
need
to
be
able
to
do
is
read
what
are
the
matching
clusters
that
were
selected,
so
the
controller
for
placement
rule
understands
how
to
look
at
the
inventory
understands
how
to
restrict
it,
based
on
access
control
rules
and
then
come
up
with
a
specific
list
of
target
clusters
that
we
want
to
deliver
configuration
against
from
here.
B
A
controller
can
leverage
the
placement
concept
and
generate
the
appropriate,
manifest
work.
The
manifest
work
objects
are
cluster
or
assigned
to
a
cluster
based
on
being
put
in
the
namespace
or
content
for
that
target
cluster,
so
a
manifest
work.
If
I'm
delivering
it
to
three
clusters,
I'm
basically
replicating
it
to
namespace
one.
Two
and
three,
and
then
the
agent
on
each
end
of
those
three
clusters,
is
calling
back
and
can
only
see
configuration
in
the
name
space
that
it's
been
allocated.
So
agents
don't
have.
B
A
lot
of
you
know,
visibility
to
other
peers
through
any
mechanism
that
they
go
back
to
the
hub.
For
so
I
want
to
make
sure
that
the
concept
here
is
important,
because
the
concept
here
is
understood
because
it
demonstrates
how
we
can
take
a
concept
like
placement
and
manifest
work,
and
you
can
use
them.
I
don't
necessarily
have
to
create
manifest
work
objects.
If
I
use
placements,
I
don't
have
to
use
placements.
If
I'm
going
to
use
manifest
work
to
distribute
configuration
and.
C
I
think
that's
a
so
it's
interesting
too,
because
I
think
so
it's
good.
So
so
then,
let's
explore
the
idea
here
of
one
of
the
things
I
think
you
could
say
is
that
the
cluster
list,
the
cluster
lit
today,
implicitly
trust
that
manifest
work
is
accurate,
so
effectively
the
cluster
that
is
delegating
to
the
man,
the
thing
that
is
creating
the
manifest
work
as
an
objective
source
of
truth.
C
C
That's
reconciling
another
api,
which
is
the
host
level
process
hierarchy
poorly
and
that's
not
a
that's,
not
a
ding,
it's
like
if
we
could
go
back
and
do
the
cubelet
over
again
there's
a
lot
of
different
ways
that
we
might
approach
it.
We
lack
some
of
the
relax.
We
still
lack
some
of
the
constructs
to
go.
Do
that,
but
the
idea
that
you
have
a
source
of
truth,
you
reconcile
the
current
state
to
that,
like
a
great
example,
would
be
like
if
your
connection
to
the
cube
api
service
cutoff,
you
have
no
local
state.
C
One
of
the
differences
between
manifest
work
and
cluster
lit
is
in
theory,
cluster
lid
has
already
transformed
so,
like
you
could
say,
like
that's
the
spot,
where
the
cubelet
and
cluster
that
are
different,
but
they're
still
both
trusting
like
here's.
The
pod,
I'm
going
to
run
as
root
trusted
to
do
everything
the
transformations
go.
B
C
Yeah
and-
and
I
think,
there's
and
controllers
run
through
a
variety
of
these,
like
most
controllers-
trust,
their
truth,
trust
that
whatever
they're
reading
is
accurate,
but
then
they
have
to
impose
a
set
of
like
you
know,
checks,
and
sometimes
it
doesn't
have
those
checks
like
the
apis
that
we
construct
like
because
again
controllers,
just
wait
for
saying
like
given
all
these
things
are
true.
What
do
I
make
happen?
C
The
construct
that
I
think
is
is
important
to
talk
about
when
we
talk
about
policy
would
be.
When
are
the
cases
where
a
centralized
model
of
truth
or
a
single
source
of
truth?
Actually
don't,
and
so
I
think,
a
kcp,
a
workload
exploration
goal
would
be.
There
will
be
places
where
there
should
be
hard
policies
that
a
compromise
kcp
can
only
compromise
the
workload
so
creating
that
boundary,
I
think,
is
something
that,
like
the
transformation
step,
is
it's
not
actually
it's
about.
C
C
The
choice
of
how
you
do
placement
strategy
implicitly
assumes
somebody
who
has
visibility
and
decides
to
carve
stuff
up.
I
would
actually
say
that's
not
really
an
assumption
and
I
think
in
the
transparent
multi-cluster
we
care
about
breaking
up.
You
know
all
these
things
have
capacity
share
across
it.
That's
very
much
like
the
cubelet
as
well,
and
that
is,
I
think
again
like
it's.
It's
not
saying
that,
like
we
can't
align
these
things.
C
It's
just
saying
thinking
about
like
where,
in
the
pipeline,
the
what
are
we
trying
to
achieve
is
a
little
bit
less
of
a
pre-planned
story
and
a
little
bit
more
of
an
organic
story.
But
the
organic
placement
is
not
so
organic
that
it's
not
centralized
it's
just
the
apis
we
choose,
for,
we
might
have
a
set
of
policy
apis,
but
then
we
also
might
bring
in
other
sources
but
doesn't
mean
that
that's
not
the
same
mechanism
where
we
couldn't
reuse.
Those.
B
B
We
could
define
a
model
where
the
placement
rules
on
how
we
evaluate
and
assign
work
is
driven
on
factors
that
are
less
concrete.
Today,
placement
rules
as
they're
currently
implemented
and
has
been
implemented
for
several
years,
really
are
using
matching
label
selectors
match
expressions
and
some
basic
awareness
of
resource
utilization
as
a
hint.
I
wouldn't
I
wouldn't
articulate
it
as
a
full-fledged.
B
As
we
look
at
evolving
this
into
the
placement
api,
that
api
is
much
more
opinionated
about
things
like
affinity
and
anti-affinity
for
spreading.
It
will
ultimately
be
more
opinionated
about
things
like
resource
distributions
and
optimization
of
resource
management
and
likely
other
constraints
as
well.
There's
a
number
that
are
coming
out
of
consumers
like
ant,
maybe
in
time
consumers
like
tencent
because
and
has
used
open
cluster
management
and
deployed
it
to
manage
their
kubernetes
fleet
in
production.
Today,
completely.
B
A
C
So
there
needs
to
be
enough
of
a
hard
boundary
between
the
way
that
someone
up
top
thinks
about
it
and
the
way
that's
used,
but
the
just
creating
that
hard
boundary
basically
gives
us
carp
launch
to
to
add
policy
on
the
back
end,
but
we
need
the
right
policy
construction,
like
cube,
like
cube
kind
of
suffers
from
this
a
little
bit,
which
is,
we
didn't,
really
have
a
large
set
of
existing
con
and
it
suffers
benefits
whatever
the
cube
scheduler
right.
Originally,
we
said.
Oh,
you
know
we
want
relatively
flexible
policies
for
scheduling
in
practice.
C
C
If
we
had
come
into
cube
with
a
little
bit
more
of-
I
don't
say
prior
art,
because
there's
plenty
of
prior
art,
but
existing
concepts
that
we
could
overlay
or
compose
there
would
have
been
a
lot
more
desire
to
be
able
to
reuse
some
of
those
right
like
the
ecosystems
that
existed
before
cube.
Were
you
know
people
did
this
early
on,
they
had
their
own
schedulers
that
do
complicated
distributed.
They
built
schedulers
on
top
of
cube,
but
those
didn't
mesh
well.
C
A
key
goal
is
the
reason
why
we're
like
kcp
as
a
prototype
kind
of
tugs
at
the
cuba
ecosystem
is.
The
goal
is
to
keep
most
of
the
web
in
place,
but
to
bring
some
of
those
same
kind
of
like.
Could
we
go
do
the
same
kind
of
thing
that
cube
did,
which
was
like
a
bunch
of
core
primitives?
You
just
don't
worry
about
the
details
because,
most
of
the
time
they
don't
matter,
but
we
have
all
those
concepts.
Like
you're
saying
we
have
placement,
we
have
existing
cube,
scheduler
things.
C
How
do
we
fit
those
into
the
web
is
a
little
bit
of
a
harder
problem,
but
the
argument
is
a
more
achievable
part
pattern
for
reuse,
because
in
theory
we
already
have
examples
of
how
placement
rules
and
these
concepts
can
be
used.
If
we
can
create
that
hard
boundary
between
the
application
and
the
underpinning,
we
can
reuse
many
of
those
same
apis
as
inputs
to
placement.
C
We
actually
get
something
out
of
it
because
before
we
couldn't
reuse
much
of
it
because
they
were
all
there
were,
there
was
a
whole
bunch
of
concepts
you
had
to
take
at
once
like
if
you
took
a
monolithic,
scheduler
and
tried
to
layer
it
on
top
of
cube.
In
the
early
days
of
cube,
you
were
bringing
you
know,
tens
of
thousands
of
concepts
that
were
completely
orthogonal.
In
this
case
placement,
as
you
say,
is
already
kind
of
so
I
think
that's
good
that,
like.
B
B
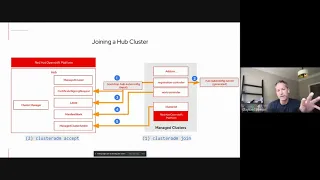
Signing
request
and
the
registration
controller
uses
that
to
create
the
csr
there's
an
approval
flow
where
the
hub
can
establish
that
it
trusts
the
identity
of
the
agent
that
it
is
requesting
to
connect,
and
there
is
a
separate
decision
point
where
the
administrator
can
then
allow
that
cluster
to
join
the
hub,
and
once
that
happens,
then
the
registration
controller
can
generate
a
coop
config
secret
foreign
identity.
That
can
discover
information
from
the
assigned
project
or
namespace
and
do
things
like
generate
leases,
introspect,
manifest
work,
consume,
add-ons,
etc.
B
But
this
registration
flow
very
much
mimics
and
in
fact,
if
you
don't
have
the
manage
cluster
pre-created,
the
registration
controller
will
actually
create
it
on
your
behalf,
much
in
the
way
that,
like
a
kublet,
is
going
through
a
csr
process
to
have
a
node
join
a
cluster
right.
It's
intentionally
kind
of
following
that
paradigm.
Pattern.
A
B
C
And
I
actually
say
it
might
even
really
so
there's
an
open
question
here
about
whether
we
we
actually
don't
allow
kcp
like
let's,
let's
invent
a
new
term
now
so
there's,
let's
call
it
application
control
plane.
Just
for
the
sake
of
argument
and
kcp
is
kind
of
like
got
a
whole
bunch
of
meanings,
and
then
we
have
what
we
would
call
like
a
step
down,
which
is
like
all
the
component
technology
pieces.
C
Like
say,
you
have
like
an
application,
control
plane
and
an
administrative
control
plane
and
the
administrative
control
plane
is,
you
know,
offering
a
set
of
capabilities
to
centralized
control
and
then
there's
a
set
of
capabilities
where,
like
end,
users
are
the
ones.
So
it's
like
you
kind
of
have
like
the
the
low
cardinality
fan
out,
which
is
like
I'm
making
this
available
to
you
and
what
I've
made
available
to
you
you
can
consume.
You
might
then
want
to
integrate
in
your
own.
B
Of
driving
on
right
is
that
we
establish
enough
overlap
where,
even
though
a
user
and
I'll
put
down
two
to
this
picture,
even
though
a
user
may
not
ever
touch
a
manifest
work
and
placement
may
be
something
that
is
underneath
the
kcp
api
server.
Even
if
a
user
never
sees
those
concepts
as
a
kcp
consumer,
they
simply
see
this
ability
to
deliver
a
set
of
objects
to
the
api
server
magic
happens
and
on
the
other
side,
there's
running
workload.
C
C
So,
like
cube,
has
this
problem
today,
which
is
if
I
can
create
like
the
thing
about
these
is
like
if
you
drew
a
threat
model
of
cube
and
you
can,
if
you
can
create
a
pod
in
a
certain
name
space
or
if
you
can
create
a
pod,
that's
rude
on
the
host
there's
a
little
line
on
a
graph
between.
I
can
do
this.
Therefore,
I
can
do
this.
Therefore,
I
can
do
this.
C
Therefore,
I
can
become
root,
so
this
is
like
the
you
build
like
your
security
graph
and,
like
we've
talked
about
the
sure
cube
of
one
of
the
things
that
we
really
want
to
do
is
up
front
snip
the
lines
that
result
in
people
escalating
right
and
the
only
way
you
can
do
that
is
if
the
actions
you
can
do
are
no
more
than
you
can
see
so
like
for
you
to
do
an
action.
Someone
has
to
give
you
that
action
right
like
it's,
not
an
implicit
part
of
the
system
and
cube.
C
What's
the
application,
control
plane
experience
and
the
administrative
control
plane
experience
and
where
do
those
top
level
concepts
intersect
so,
for
instance,
being
able
to
edit
my
policy
of
placement
would
be
inappropriate,
but
it
doesn't
mean
that
I
can't
use
that
placement
policy
as
an
admin,
just
not
exposed
user,
but
it
does
exactly,
but
it
could
mean
that
we
just
are
missing
an
api
construct
that
sits
alongside
placement,
which
is
the
the
dual
of
it
right.
So
there's
one
which
is
explicit
placement
and
the
other
is
implicit
placement.
C
B
The
application
side
could
absolutely
either
bring
along
enough
implicit
behavior
about
how
it
wants
to
express
its
distribution
right
and
for
the
sake
of
argument,
that
implicit
definition
of
placement
might
really
be
tied
to
a
desired
level
of
sla
and
redundancy
right.
I
desire
a
certain
minimum
up
time
and
I
want
to
be
able
to
tolerate
this
level
of
world
ending
catastrophe
and
I'm
willing,
you
know
to
pay
more
for
that
or
I'm
willing
to
tolerate.
B
You
know
two
nines
of
availability
and
you
figure
out
the
required
distribution
and
that's
what
crosses
you
know
for
this
green
object.
Whatever
these
are
through
to
kcp
and
then
kcp
behind
the
scene
says.
Okay,
here
is
the
implicit
desired
uptime
and
allowed
error
budget
construct,
and
those
are
the
only
two
parameters
that
get
fed
into
it.
It
gets
injected
into
a
function
and
out
the
other
side
comes.
B
A
very
concrete
here
is
the
desired
placement
and
placement
decisions
that
should
be
used
in
order
for
this
application
to
achieve
its
desired
sla
or
desired
solo.
I
guess
in
that
case
and
then
from
there
okay
in
order
to
distribute
it
among
these
three
clusters.
In
these
three
different
regions,
I'm
going
to
generate
I'm
going
to
package
up
the
desired.
You
know
ingress
object
in
this
flow
package.
C
And
getting
like
at
the
end
of
the
day,
maybe
another
way
to
frame
this
would
be
expecting
someone
to
use
pod
replicas
2
is
an
implicit
statement
about
aha,
the
implicit
scheduling
policies
and
cube
lead
to
that.
The
problem
is:
is
that
that's
not
sufficient
and
you
actually
have
to
go
create
a
bunch
of
other
objects
to
reach
that
is,
you
have
to
create
a
pdb?
Your
administrator
has
to
do
the
correct
things
with
pdb.
Your
administrators
have
to
not
do
things
like
force
deleting
pods
your
administrators
have
to
set
up.
C
C
C
So
what
we
need
to
do
in
the
mid
term
is
firm
up
in
a
dialogue
or
in
a
loop
identify
the
constructs
at
the
application
level
that
express
that
intent,
identify
where
the
gaps
are
and
existing
so
like
replicas,
2,
isn't
sufficient,
there's
a
set
of
implicit
api,
there's
an
implicit
or
explicit
api
that
exists
somewhere.
That
should
do
the
right
thing
for
someone
and
then
how
would
that
get
mapped
after
we
have
those
concepts
mapped
out
enough,
which
is
kind
of
like
that
short-term
prototyping
window
that
we're
still
in
for
a
kcp.
B
A
Yeah,
I
think
I
think
it's
useful,
like
I
think
it's
a
really
good
point
to
keep
in
mind.
That
ocm
is
not.
You
know,
etched
in
stone
and
immutable
for
all
time.
I
think
it's.
I
think
it's
worth
going
through
the
the
exercise
of
saying
like
here's,
what
we
would
need
to
do
to
ocm
and
here's
what
it
would
look
like
at
the
end
of
it
to
like
meet
our
needs.
A
B
A
The
like
comparison,
because,
at
the
end
of
the
day
we
might
find
that
the
path
we're
on
is
the
path
we
want
to
be
on,
but
at
least
we
have,
you
know,
prove
it.
We've
we've
done
the
homework
to
say,
like
you
know,
we
are
on
the
path
we
want.
We
looked
at
that
path.
We
decided
to
do
it
or
not,
but
we
at
least
like
have
the
the
comparison
for
it.
I
think
that's
a
useful
exercise,
because
I
think
the
question
keeps
coming
up
and
I
don't
want
to.
A
C
The
set
of
things
that
allow
us
to
look
at
lots
of
sources
of
truth,
but
still
get
the
benefits
of
a
controller
model,
is
what
we
are
trying
to
do,
and
specifically,
that
is
how
do
you
effectively
write
an
integration
which
looks
at
like
today.
We
look
at
one
source
of
truth
with
one
api
across
and
usually
it's
across
all
name
spaces
so
like
this
is
like
you
know,
we
go
back
all
the
way
to
olm
and,
like
all
the
gaps
and
operators.
C
Today,
if
someone
says
I
want
to
write
this
operator
and
only
point
it
to
three
namespaces,
they
have
no
solution,
so
the
the
arc
for
multi-cluster
controllers,
let's
reframe
it
and
say
I
need
to
be
able
to
write
effective
multi-context
where
context
is
a
namespace,
a
physical
cluster,
a
single
logical
cluster,
single
logical
cluster,
namespace,
multiple
physical
namespaces,
multiple,
logical,
namespaces
or
multiple.
What
is
the
pattern
that
helps
that
scale?
The
the
best
outcome
would
be.
C
Let's
concretely
look
at
the
things
that
we
have
today,
but
it's
not
enough
just
to
go
solve
one
logical
cluster,
pointing
to
one
we
really
do
need.
How
could
I
look
at
75?
How
can
I
have
a
set
of
chunks
of
work
that
I
can
go,
look
at
and
efficiently
get
a
list
watch
across
all
of
them
that
I
can
then
turn
into
effective
work.
So
I
think
all
of
the
things
we've
said
are
necessary
inputs.
It
needs
to
be
around
something
concrete
and
real,
but
part
of
the
reason
to
structure.
A
B
What
I've
shown
today,
where,
like
the
work
controller,
couldn't
be
restricted
or
running
multiple
work
controllers
that
source
input
from
multiple
sources,
like
the
controller
today,
will
do
that.
What
you
have
to
contend
with
is
if
registration
controller,
one
sourcing
content
from
kcp,
logical,
cluster,
1
and
registration
controller,
2
sourcing
content
from
logical
cluster
2..
B
If
those
two
inputs
decide
to
conflict
because
they're
both
targeting
the
default
namespace,
that
behavior
today
would
be
undefined
and
so
understanding
how
to
define
that
partition
of
the
context
is
a
gap
that
you
know
we
could
work
together
to
help
address
and
and
provide
more
access,
control
and
scope.
That's
that's
something
that
we
often
get
asked.
B
How
can
I
define
a
slice
of
name
spaces
across
these
three
clusters,
because
a
lot
of
current
deployments
stand
up
four
or
five
or
ten
big
honking
clusters
and
then
assign
the
same
three
name
spaces
to
this
team
on
every
cluster
and
these
three
namespaces
to
that
team
on
every
cluster
and
today,
ocm
doesn't
effectively
handle
that
specific
use
case.
There's
things
we
can
do
to
help
with
that.
B
C
That
intersection
is,
how
do
you
effectively
define
a
context
that
some
work
happens
and
you
take
name
spacing
context
out
of
the
hard
requirements
and
put
them
into
the
soft
requirements?
I
think,
like
the
the
kcp
problem
of
transparent
multi-cluster
and
the
set
of
initial
inputs
should
expose
one
particular
variant
of
that.
It
would
be
a
mistake
for
us
not
to
say
okay,
and
then
we
have
another
variant
of
that
which
is
I'm
doing
this
mapping
today.
As
you
said
with
you
know,
a
set
of
ocm
use
cases.
C
A
C
Would
be
you
have
to
have
one
place
that
you
store
something?
That's
you
know
a
source
of
truth
that
then
people
downstream
can
look
at
we'll
have
places
where
we
go
through
a
funnel
and
we'll
have
places
where
we
don't
go
through
a
funnel.
We
need
the
same
outcome
in
both
cases,
so
yeah,
let's,
I
would
probably
say
even
just
that
discussion,
let's
carve
that
off
into
the
multi-context
controllers
and
we
don't
really
have
an
investigation
thread
for
that.
C
But
the
sinker
is
an
example
of
that
and
the
cluster
would
also
be
an
example
of
that
and
the
work
controller
are
three
concrete
examples.
We
know
we'll
have
a
couple
of
others
like
integrating
cloud
services
into
logical
clusters,
so
we
know
that
there'll
be
an
additional
one
or
two.
That
really
probably
should
be
its
own
investigation
thread
and
we
should
probably
create
an
investigation
doc
for
that.
That
goes
through
the
initial
inputs,
and
that's
something
maybe
michael
you
and
I
can
kind
of
tease
apart
yeah.