►
From YouTube: Community Meeting, March 1, 2022
Description
No description was provided for this meeting.
If this is YOUR meeting, an easy way to fix this is to add a description to your video, wherever mtngs.io found it (probably YouTube).
A
All
right,
hello
and
welcome
everyone
to
kcp
community
meeting
march
1st
and
or
february
29th
2022.
We
have
some
items
on
the
agenda
today.
I
don't
know
if,
if
stefan
you
wanted
to
go
first
and
and
go
through
the
the
sort
of
walkthrough
you
intended
to
do
or
if
we
want
to
do
regular
business
and
give
you
the
rest,
I'm
totally.
C
Right,
so
that's
a
talk.
Basically,
I
I
gave
internally
and
with
some
ibm
works
before
giving
an
overview
to
people
who
don't
know
kcp
or
have
some
vague
understanding
what
it
might
be,
but
everybody
basically
has
his
own
view
projects
his
own
use
cases
on
it,
and
I
try
to
to
give
an
overview
of
how
we
see
that
and
the
vision
behind
everything
we
are
doing.
We
often
lose
ourselves
in
details
as
usual
as
engineers.
This
happens,
but
there's
a
big
vision
behind
it,
and
I
just
want
to
repeat
that.
C
If
you
start
in
kcp
in
the
depository
you
will
find
this,
and
before
I
go
into
that
disclaimer
when
I
say
technically,
it
is
it's
present
tense,
but
lots
of
the
things
here
are
vision
or
direction.
So
it's
not
that
the
thing
we
are
building
at
the
moment
is
ready
for
one
million
workspaces.
This
is
basically
a
goal
and
we
are
working
towards
that.
So
please
take
it
is
in
this
sense.
C
The
third
thing
is
compute.
Compute
is
different,
compute
should
be
utility,
and
the
mechanism
we
we
have
here
we
are
working
on
is
called
transparent
multi-cluster,
and
this
basically
allows
us
to
attach
an
existing
cube.
Openshift
aws
cube
whatever
some
kubernetes
cluster
s
compute
to
a
kcp,
not
only
one
but
many,
many
of
them
as
many
as
you
want
in
many
regions
and
many
clouds
wherever
they
like,
they
must
be
cube
compatible.
C
Obviously
it
must
be
two
clusters
and
the
fourth
thing
is
scale,
so
we
are
thinking
about
yeah
some,
some
numbers
here:
one
million
workspaces,
10
000
orcs,
a
thousand
shards,
that's
basically
the
dimension.
We
are
talking
about
a
question
I
I
get
very
often,
especially
from
people
who
heard
the
project
very
early.
Is
this
federation
three
like
do
we
reinvent
federation
and
as
a
very
super
short
answer,
federation
is
basically
one
to
n.
C
You
have
one
app,
basically
in
your
in
your
root
cluster
and
you
federate
that
to
n
clusters
in
different
regions,
usually
to
get
availability
for
example,
or
near
to
your
users.
This
is
federation
when
one
to
n
kcp
is
not
one
to
n.
Kcp
is
n
to
at
least
the
focus
of
kcp
is
n21,
which
means
you
have
one
cluster
one
chart.
It
can
host
many
many
apps
super
isolated.
C
You
have
shared
compute
and
on
the
shared
compute,
you
run
those
apps,
so
it's
n21,
there's
a
but
obviously
kcp
can
and
will
get
one
to
n,
so
federation
as
well.
But
it's
something
independent
might
be
a
feature
on
top
the
core
ideas:
the
two
core
technical
things
we
build
at
the
moment.
They
are
about
n
to
one.
C
C
For
example,
you
don't
see
nodes,
so
I
have
the
meaning
here
at
the
bottom.
You
can
access
a
url
set
it
as
a
cluster
in
your
in
the
config
and
under
this
url
you
can
do
everything
you
can
do
against
the
cube
cluster,
so
you
can
deploy
a
deployment.
You
can
get
config
map
secrets,
you
might
be
able
to
see
pots.
You
can
create
your
own
clds
everything
you
expect
from
a
cube
cluster,
but
some
things
they
are
not
there.
C
Nodes
are,
for
example,
not
visible,
so
the
goal
is
to
have
a
complete
tube
experience,
but
not
100
in
the
sense
that
nodes
are
there
and
all
low
level
types
are
there,
but
everything
which
matters
and
nodes,
obviously
usually
don't
matter
for
for
many
many
use
cases,
that's
the
goal,
so
cube
is
our
goal.
Kcp
is
cube.
We
use
cubes
api
is
our
cube.
C
Everything
here
is
cube,
so
this
is
really
important
if
you
want
to
run
one
million
cube
clusters
starting
one
million
cube
clusters,
that's
probably
not
the
right
solution,
so
we
we
don't
want
to
to
run
one
million
controller
managers,
one
million
schedulers,
one
million
everything.
Basically,
we
don't
want
that.
So
one
decision
here
is
very
early
just
by
the
size
of
the
numbers,
one
million.
C
We
cannot
just
do
many
of
the
same
many
of
the
cube
clusters
we
have
so
our
goal
is
to
have
a
cube
user
experience
but
radically
question
how
we
reach
this
goal.
So
one
million
that's
a
pretty
big
number
and
you
have
to
do
things
differently
to
reach
that
and
obviously,
if
you
can
do
that,
one
goal
is
to
make
it
cheaply
so
cheap,
cheap
clusters,
cheap
workspaces.
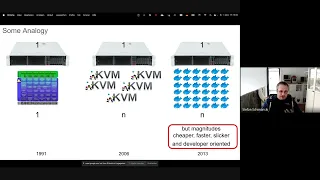
C
What
the
terminal
is
actually
is
one
of
the
core
goals
and
we'll
see
that
in
a
second
a
bit
more
analogy
in
the
in
the
first
yeah
in
the
years
from
from
the
beginning
of
the
of
the
linux
kernel,
there
was
one
kernel
per
cluster,
then
per
per
server.
Eventually,
people
did
virtualization;
eventually
they
moved
fertilization
into
the
cube
kernel,
which
was
on
kbm,
and
you
could
run
many
kernels
on
one
server
and
then
something
happened.
A
few
years
later,
docker
came
around
and
what
is
different
between
docker
and
kvm.
C
Both
do
basically
to
end
one
server,
many
applications,
but
there
is,
of
course,
a
big
difference.
It
really
knows
that,
but
remembers
the
first
moment
seeing
seeing
docker
what
it
does
it's
much
cheaper,
because
everything
is
faster
and
less
leads.
Less
resources
feels
slicker
and
it's
developer
oriented.
So
it's
the
same
n
to
one
or
one
to
n,
but
there
is
a
big
difference
and
basically
this
is
what
we
try
to
do
with
kcp
and
cube.
C
If
you,
if
you
run
one
million
clusters,
so
the
user
basically
sees
their
cube
urls,
they
can
connect
to
the
apis
and
do
whatever
they
like.
The
outside
view
is
cube
inside.
It
might
be
very,
very
different.
So
that's
why
I
painted
it
gray
here
so
inside
it's
it's
cube
code.
We
reuse
lots
of
the
things
that
cube
has
in
the
main
repository,
but
we
also
do
things
differently.
C
As
I
said
before,
compute
is
externalized,
so
compute
is
just
utility,
so
we
can
attach
many
many
compute
clusters
could
be
openshift
could
be
eks
gte,
whatever
some
homegrown
on
premise
cube
cluster.
You
can
attach
them
and
you
can
run
your
workloads
and
those
shards
make
sure
that
workloads
are
scheduled
onto
those
yes,
so-called
real
cube
clusters.
Physical
clusters
is
how
we
call
them
physically,
because
they
they
have
notes
and
they
can
run
the
real
proxy
and
not
just
about
the
control
plan
and
logical
objects.
C
The
bigger
picture,
of
course
here
is
that
this
doesn't
end
with
q,
but
you
have
many
many
services
on
top,
so
kafka,
sql,
nosql
monitoring
registry
is
the
usual
things
you
you
can
build
on
top
as
services
and
kcp.
Basically
is
a
platform
below
that
so
when
you
want
to
build
such
a
system,
super
multi-tenant,
so
many
many
users
and
you
want
to
offer
services.
C
If
you
look
on
applications,
how
applications
look
like
in
cube,
usually
many
applications.
They
are
in
the
50s
control
resources,
so
there
are
50
or
maybe
100
resources
for
one
for
one
application,
but
there
are
many
of
them
on
one
cluster,
usually
their
name
spaces
to
separate
them,
and
you
run
those
in
name
spaces,
but
multi-tenant
yeah.
It
has
limits.
C
Everybody
knows
that
it's
hard
to
get
right,
people
or
should
have
tried
and
it
kind
of
works,
but
it's
still
a
very
complex
system
which
you
get
out
of
that
and
in
kcp
a
workspace
basically
replaces
all
of
this
trouble.
A
workspace
is
something
like
a
namespace,
but
by
design
very
deep
in
the
in
the
api
server
and
the
api
machinery,
we
make
sure
that
the
workspace
is
very
independent
or
super
independent
from
other
workspaces.
C
C
C
Workspaces
are
cheap.
That's
what
we
talked
about
already
a
couple
of
times.
Our
goal,
basically,
is
a
rule
of
thumb.
A
new
workspace
should
be
created
in
the
tens
of
kilobytes.
Basically,
there
is
a
definition
of
object
for
for
workspace
called
cluster
workspace
in
the
codebase.
At
the
moment
when
this
exists,
you
can
use
your
workspace
and
basically,
this
object
is
all
which
is
stored
in
in
kcp.
For
this
moment.
In
the
moment,
you
create
data
inside
of
a
workspace.
C
Of
course
it
grows,
but
the
overhead
for
having
workspaces
instead
of
namespaces
is
is
basically
not
there,
like
workspaces,
have
the
same
cost
same
spaces.
That's
the
goal,
authorization,
it's
another
thing
which
we
try
to
do
different
and
one
reason
why
multi-tenant
is
hard,
because
people
want
to
do
certain
things.
They
need
permissions.
C
On
the
other
hand,
you
have
to
restrict
them
because
of
security.
Obviously,
isolation
to
other
users
and
visibility
leaking
of
information.
You
don't
want
that.
Our
goal
is
by
design.
Everybody
should
be
able
to
be
admin
in
their
workspaces,
basically
be
able
to
do
everything
they
want.
Like
install
cds,
install
something
with
ham,
everybody
should
do
that
self-service
in
their
workspaces.
C
There
might
be
restrictions
which
we
have
to
add
like
if
you
subscribe
to
apis
from
a
service
provider
like
the
ss
there's,
a
threat
manager
as
our
running
example,
a
cert
manager
provider.
Who
gives
you
an
api
for
search,
then
this
this
service
provider
should
be
able
to
restrict
certain
certain
things
like
you,
shouldn't
update
status
of
objects
which
are
served
or
given
to
you
by
a
search
manager
from
the
platform.
So
there
are
some
restrictions,
but
other
than
that,
your
admin,
you
can
do
everything
you
like
you
can
do
whole
bindings
holes.
C
If
you
go
to
the
repository,
so
I
I
got,
I
talked
to
people
and
they
asked
me:
is
this
ready
for
production?
Can
I
just
use
that,
for
whatever
use
case,
there's
a
big
warning
in
the
in
the
readme
at
the
moment
this
is
a
prototype,
it's
not
even
a
project.
We
are
slowly
migrating
or
moving
into
this
project
phase
of
the
of
the
kcp.
C
You
see
that
in
the
in
the
meeting
here
it's
growing
and
more
people.
We
are
slowly
moving
from
feasibility
studies
into
something
usable
like
the
apis
are
evolving
and
we're
trying
to
make
them
yeah
turn
them
into
something
that
can
stay,
that
we
don't
have
to
change
too
much.
Everything
is
still
we
want
alpha
one
so
to
be
clear
about
that,
but
we
are
moving
into
a
direction
that
this
becomes
a
project.
People
can
build
on
our
main
focus
at
the
moment.
Visibility
is
mostly
clear
for
many
things,
but
we
have
to.
C
Of
course
we
have
to
approve
the
value
proposition.
I
mean.
Why
do
we
do
all
of
this,
and
we
try
to
get
this
ready
for
early
external
consumption
to
prove
that
those
concepts
and
those
goals
and
the
vision
make
sense
for
those
who
have
not
tried
to
use
kcps
themselves.
So
I
I
mentioned
workspace.
All
the
time,
a
workspace
is
basically
a
tube
cluster.
C
Basically,
a
workspace
is
something
you
can
use
group
cuddle
against,
and
you
get
what
you
expect
from
a
tube
cluster.
You
can
say
tube
couple:
api
resources,
you
see
everything
you
can
apply
or
create
a
cid
and
you
create
the
cid
and
use
custom
resources
against
it.
Everything
like
that,
that's
what
you
get
from
a
workspace
workspaces
are
hosted
in
organizations.
That's
one
one:
separation
to
just
get
to
one
million
objects.
That's
the
main
motivation
here.
It's
also
yeah,
it's
a
separation
or
it's
a
it's
a
borderline
between
access,
probably
in
the
future.
C
C
And
yeah
the
the
user
experience.
This
is
a
sketch.
Not
everything
here
is
real.
Yet
I
got
asked
about
two
catalog
in
there.
Isn't
such
a
thing?
No,
there
isn't,
but
the
user
experience
is
like
that.
You
look
into
kcp
with
some
login
command.
This
might
look
a
bit
different
could
be
kcp
login.
Eventually,
you
can
go
to
some
workspace
index
where
you
can
see
the
workspaces
you
have
access
to.
So
the
ssq
cutter
workspace
enter
thing.
C
You
enter
an
index,
you
get
the
workspaces,
you
see
all
the
workspaces
you
have
access
to
so
the
default
one
which
is
my
my
case,
would
be
my
my
home
workspace,
stefan,
the
index
itself
and
all
the
applications.
I
have
my
app
as
an
example,
and
you
can
create
another
one.
You
can
create
a
workspace,
you
can
enter
it,
you
can
create
deployments
in
it
and
you
can
switch
between
workspaces
very
easily
via
simple
commands.
That's
basically
the
vision
of
cx.
C
Charting
is
a
thing.
Obviously,
one
lcd
cannot
host
all
the
data,
so
there
must
be
something
like
location
of
workspaces
on
charts.
The
big
vision
is
that
as
soon
as
you
have
a
group
config
for
workspace,
this
will
always
work,
and
I
said
in
the
beginning,
cube
or
kcp
is
cube
for
service
providers.
Service
providers
might
be
interested
in
moving
workspaces
around
like
one
chart
is
busy,
because
there
is
a
very
noisy
workspace
on
it,
which
needs
lots
of
resources.
C
Let's
call
it
against
this
example,
and
you
work
space
b
is
is
there,
but
the
slowest
performance
by
the
system
cannot
be
satisfied
anymore,
so
so
bright
rate
is
not
just
enough
on
this
lcd,
so
your
workspace
b
should
be
moved
to
another
chart.
This
is
a
it's
a
core
use
case
which
we
want
to
implement
here
and
you
as
a
user.
C
C
C
I
mean
you
have
to
handle
the
life
cycle
of
your
cids,
which
you
offer
to
customers.
So
you
you
want
to
offer
a
postgrad
cld,
for
example,
and
now
you
hold
out
a
new
version.
This
must
be
handled
somewhere
somehow
or
somewhere,
and
crds
are
just
not
enough
for
that.
So
one
big
word
item
we
have
and
we
are
actively
working
at
the
moment
on
that
for
the
next
prototype.
The
first
steps
to
this
direction
is
api
export.
C
So,
basically,
you
can
publish
apis
with
symantec
with
behavior
to
other
users,
other
workspaces
in
the
kcp
instance-
and
there
are
many
many
details
here.
We
can
show
that
in
a
different
session.
Obviously-
and
you
will
see
in
some
offset
this
next
in
the
next
prototype-
so
stay
tuned-
there
are
many
topics
which
are
deep,
important,
new
research-like
and
listed
a
few
of
them
here.
C
C
We
try
to
upstream
things
which
we
have
to
build
in.
We
try
to
be
modular
against
cube
like
extended
in
a
way
that
we
don't
have
to
fork.
You
so
cube,
isn't
it's
a
non-goal,
an
anti-goal
of
what
we
are
doing
here,
enabling
the
client
ecosystem?
So
if
you
offer
a
service
like
a
postgres,
you
want
to
operate
on
many
workspaces,
not
only
one.
So
you
need
something
like
a
client
like
informers
which
can
work
against
many
workspaces
in
parallel,
even
with
one
instance
of
an
operator
and
and
everything
systems.
Ecosystem
is
one
goal.
C
C
If
you're
in
one
lcd,
you
have
one
consistent
domain,
things
are
pretty
easy,
but
if
you
want
to
go
cross
chart
things
get
much
more
complicated
yeah.
This
is
this
client
ecosystem
thing
for
multi
workspace.
It
has
one
one
angle
which
is
interesting
at
the
moment
you
go
cross
chart
with
one
informer.
C
This
informer
must
be
resilient
to
shots
which
come
and
go
workspaces
which
are
not
available
for
some
time.
So
informers
need
awareness
of
workspaces
basically
and
charting,
and
this
is
its
own,
pretty
complicated
topic
which
is
yeah.
It's
basically
the
next
step
after
step
4
here,
and
this
is
to
go
multi-shot
multi-region
these
kind
of
things-
and
this
brings
us
to
the
last
topic
here-
topology
awareness
kcp
is
something
which
should
run
multi
region
in
a
way,
so
those
shots
are
distributed
over
many
many
data,
centers
and
topology
becomes
a
thing
in
cube.
C
It's
not
really
it's
it's
somehow
in
scheduling
to
a
degree,
but
here
it's
becoming
a
much
more
core
concept,
and
we
are
thinking
about
how
to
make
this
visible.
For
example,
to
to
operators
which,
in
this
example,
if
you
provide
cost
quests
postgres
instances,
you
want
to
know
what
the
topology
is
and
maybe
you're
not
the
one
defining
the
technology,
because
the
kcp
platform
does
that.
So
there's
a
big
topic
about
how
to
make
that
visible
to
controller
authors,
for
example,
yeah
everybody
who's
here
knows
that
already,
maybe
not
all
of
that.
C
There's
a
google
group.
So
if
you
want
to
read
documents
which
we
work
on,
those
are
usually
shared
to
this
google
group,
so
just
join
that
and
announcement
of
new
docs
are
there
and
you
can
just
join
the
discussion
and
contribute
you're
welcome
to
do
that.
The
kcp
repository
everybody
has
seen-
and
the
last
thing-
maybe
not
everybody
knows
about-
is
the
youtube
channel
where
you
can
re-watch
all
the
recordings
of
the
community
call
which
we
are
doing
at
the
moment.
A
A
D
I
wanted
to
ask
about
the
user
experience
specifically.
What
is
what
is
set
in
stone
and
what
is
and
what
can?
What
can
adapt,
for
example,
in
in
k
native
when
they
wanted
to
try
to
address
the
the
user
experience
for
stateless
workloads?
They
started
from,
we
need
a
container
and
we
will
give
you
a
url,
and
then
I
can
see
here
that
it's
centered,
probably
around
the
core
apis
like
pods
and
services,
etc.
But,
for
example,
something
like
a
workspace
or
an
api
export
are
a
little
bit
different.
D
C
I
guess
formally,
we
are
still
in
the
prototype
phase,
so
things
can
change
and
input
is
welcome.
I
think
the
vision
like
the
goal,
what
we
have
here
this
is
mostly
set
in
stone.
Like
one
million
workspaces,
is
on
our
goal:
it's
not
to
have
giant
single
clusters,
so
this
is
pretty
much
set
in
stone,
but
how
we
do
that?
How
we
make
those
things
visible.
C
C
C
A
Say
also
the
like
the
cli
user
experience
is
entirely.
You
know
flexible
if
that
will
change
like
all
the
time
before
we
come
to
any
solid
solution.
Also,
k
native
should
run
on
top
of
this
so
like,
if
you're
talking
about
like
what
is
the
experience
for
a
person
who
just
has
a
container
and
wants
it
to
run
somewhere
and
doesn't
care
where
I
think
our
solution
would
be
put
k-native
into
into
kcp,
and
now
you
get
that
you
know
also
cross-cluster
also,
you
know
scheduled
to
who.
E
Knows
where
yeah
work
pattern?
The
key
pattern
here
is
someone
can
take
a
cube,
app
and
deploy
it
to
clusters
and
not
care.
That's
like
the
first
pattern.
There
is
a
second
pattern
which
is
teams
can
define
a
set
of
the
set
of
apis
that
they
want
what
kind
of
context
they
want
to
work
in
so
like
in
a
workspace
you
get
a
set
of
apis.
What
is
that
set
of
advanced?
It
could
be
knative
plus
service,
bindings,
plus
generic
db
construct,
or
you
know,
kafka
as
a
service
topic
apis.
E
That
would
be
an
event
driven
that
second
and
third
there's
like
a
couple
that
people
have
thought
they
were
brought
up.
Those
aren't
really
being
actively
focused
on
right
now,
but
those
should
guide
like
that's
where,
like
people
should
be
able
to
say
like.
Oh,
I,
like
crossplane
but
cross
plane
should
be
able
to
hit
50x
the
scale
and
also
have
a
whole
bunch
of
ergonomics.
But
it's
you
know
to
do
that.
You
either
have
to
write
your
own
api
front
plane
or
you
live
with
cube's
limitations.
E
E
What
are
the
fundamental
elements
of
that?
That
if
you
worked
at
the
higher
level
you're
like
we're
gonna
strip,
all
the
other
stuff
away,
the
accidental
complexity
and
be
like?
I
can
create
a
pipeline
attacked
on
pipeline
and
it
does
stuff-
and
I
can
connect
it
to
my
services.
But
aha,
it
doesn't
have
to
be
in
the
same
cluster.
D
D
Yeah,
I
I
know
it's
not
it's
not
something
that
that
that
have
an
easy
answer.
I
think
I'm
more
interested
in
what
are
smaller
concepts
that
maybe
people
like
folks
who
worked
in
k
native
maybe
can
import,
as
or
upstream
into
kcp,
for
example,
something
like
addressable
services
or
something
like
that,
and
what
are
that
are
going
to
be
on
top
of
kcp.
So
I
know
this
is
not
something
that
can
be
finalized
right
now,
but
yeah
thanks.
That
was
that
was
good
to
know.
Thank
you.
It.
E
Would
be
awesome
if
there
were
good
working
groups
that
we
could
organize
in
the
community
to
really
chase
some
of
those?
I
know
like
everybody's
kind
of
chasing
kind
of
the
core
scenario
right
now,
but
I
would
like
I'd
love
to
see
like
a
try
to
get
a
couple.
People
have
some
time
to
really
like
think
through
these
and
like
actually
spend
some
time
like
come
back
as
a
as
a
hey.
We
went
and
thought
about
this,
and
are
we
getting
the
right
guidance?
Do
we
have
the
right?
E
A
All
right,
thank
you
again
for
for
putting
this
together
for
for
sharing
with
us.
I
think
I
actually
want
to
when
this
meeting
goes
up.
I
want
to
put
a
link
to
this
on
our
read
me
because
this
is
the
the
current
latest
snapshot
of
what
we
think
we're
doing.
I
think
the
last
video
we
had
about
this
was,
you
know,
maybe
almost
a
year
old.
So
this
is
great.
A
A
A
We
need
to
stay
in
this
tab
where
it
doesn't
present,
and
I
think
that
the
question
was
basically.
This
was
bumped
from
p2
or
priority
prototype
2
to
prototype
3,
which
we
are
now
in,
but
it's
not
currently,
I
think,
being
prioritized
for
prototype
3..
I
think
we
all
know
it's
something
we
need
to
do
for
something.
It's
it's
something.
We
need
to
do.
A
I
think
the
question
is
really:
is
it
going
to
be
a
prototype
3
thing,
or
is
it
going
to
be
a
prototype
4
plus
the
longer
we
bump
it
the
more
on
fire
it
gets,
so
we
should
probably
address
it
before
prior
prototype,
nine
or
whatever
does
anyone
have
any
more
to
say
on
this?
I
can
go
into
sort
of
more
detail
about
what
it
is,
but
if
there's
anybody
yeah
andy
go
ahead.
F
A
Right
yeah,
this
is
this:
is
you
can't
deploy
a
controller
to
kcp
because
it
will
just
get
scheduled
to
its
well
depending
on
what
you
are
syncing?
It
will
get
scheduled
to
a
physical
cluster
and
at
most
successfully
talk
to
its
physical
cluster
api
server
and
things
will
go
weird,
so
yeah.
I
guess
the
the
next
question
that
falls
out
of
that
is.
Is
there
anybody
who
is
interested
in
doing
this
or
anybody
who
wants
to
de-prioritize
anything
else
in
favor
of
this.
A
H
A
C
To
highlight
this
is
something
I
mean
you
see
the
items
here
like
eight
or
nine.
We
can
work
on
that
and
make
progress,
there's
no
reason
to
decide
whether
we
don't
work
at
all
or
we
try
to
get
it
in
just
to
progress.
I
mean
we
have
certain
things
here:
work
on
them,
yeah,
they
don't
harm,
I
think
most
of
them
in
the
code
of
say.
I
just
have
done.
A
F
I
would
just
add
if
you
feel
like
you're
blocked
on
something,
but
you
have
an
interest
in
this
epic
or
other
epics.
Please
reach
out
on
slack
comment
on
the
issue.
You
can
tag
me
staphon,
I'm
ncdc
on
github
staphon
is
s-t-t-d-s,
so
we
are
here
to
help
unblock
and
provide
guidance
and
direction.
So
please
feel
free
to
speak
up.
A
F
Yes,
thank
you,
so
I
was
chatting
with
stefan
earlier
today
and
paul
as
well
and
had
some
thoughts
on
how
we
can
be
a
bit
more
transparent
and
trackable
in
what
we're
working
on.
So
the
these
are
suggestions
not
set
in
stone.
So
let's
talk
through
them
as
a
community
and
decide
what
we
want
to
do
so.
My
first
suggestion
is
that
we
do
have
actionable
steps
and
action
items
like
we
do
in
280
that
we
were
just
looking
at
also.
F
I
I
happen
to
link
418,
but
it's
the
same
thing.
So
if
you
look
under
the
action
items,
thank
you
jason.
There's
a
lot
of
stuff
in
there
to
do,
and
ideally
these
are
each
one
may
represent
a
single
pull
request.
Maybe
a
couple
of
them
would
be
combined
into
a
pr,
but
ideally
we
work
together
to
to
flush
out
the
items
for
the
epic
and
they
don't
need
to
be
converted
into
individual
issues.
That
would
just
create
a
ton
of
issues.
F
I
think
it's
probably
a
bit
fluid
as
to
which
ones
become
separate
issues
and
which
ones
just
stay
as
tasks.
I
think,
if
there's
something
that's
a
very
big
feature
that
goes
into
part
of
an
epic
it,
it
probably
makes
sense
to
create
it
as
a
separate
issue.
But
you
know
we'll
talk
about
those
on
a
case-by-case
basis,
but
ideally
we
work
together
to
flesh
these
out
and
then,
as
folks
are
starting
to
work
on
them.
F
If
we
can
do
this
related
to
that
is
number
three
making
every
effort
possible
to
set
the
in
progress
label
on
whatever
you're
actively
working
on.
I
personally
don't
do
a
great
job
of
it,
but
it
does
help
just
to
to
see
what's
going
on.
So
my
ask
would
be
to
try
and
remember,
and
then
the
last
two
are
around
milestones.
A
F
I
think
I
will
open
up
a
pull
request
against
our
contributing
doc,
which,
if
you
haven't
seen
it
yet
there
is
a
contributing
dot,
md
file,
it's
fairly
new
and
can
probably
be
augmented
and
fleshed
out
a
bunch,
but
we
have
some
place
to
start
so
I'll,
open
up
a
pr
and
add
these
items.
There
comments
are
welcome
and
if
there's
anything
else
that
you'd
like
to
see
in
the
contributing
doc,
please
feel
free
to
open
prs
as
well.
Thanks.
A
F
F
If
everything
passes,
I
don't
know
what
sort
of
infra
we
can
potentially
use
for
running
e
to
e
tests,
but
I
at
least
think
the
unit
test
could
go
through
github
actions,
so
this
would
be
nice
to
be
able
to
do,
and
this
was
from
a
conversation
with
steve
who
yeah
forget
the
test.
But
yes,
this
that's
a
long-term
priority.
I
don't
know
that
it.
F
It
needs
to
be
in
priority
or
in
prototype
three,
so
maybe
per
site
four
or
I
also
I
created
a
milestone
or
renamed
a
milestone
to
tbd
and
the
purpose
of
tbd
is
it
means
we've
looked
at
it.
We've
talked
about
it.
We
know
we
want
to
do
it,
but
we
don't
have
a
particular
prototype
in
which
we
have
an
assignment
for
it.
A
A
A
F
A
A
A
A
A
A
H
J
But
this
is
just
a
small
feedback
item.
I
think
this
is
good
initial
sort
of
like
experience
feedback
as
well
like
what
we
have
to
think
about
generally,
how
good
we
want
to
make
sort
of
like
the
default
experience
like
what
we
have
prototypes
so
far
is
definitely
not
like
100
in
sync.
What
we
have
in
cube
today,
like
we,
have
invented
like
this
authorization
scheme,
where
you
grant
access
against
the
contents
of
resource.
If
you
forget
about
it
or
if
you
don't
see
it,
it
may
be
not
obvious.
Why
you
don't
see
things?
J
A
J
Right,
if
you
look
at
my
commands
right,
what
kyle
tried
to
do
is
like,
in
order
to
make
cube
cuttle
api,
like
the
very
last
commands
on
my
site,
yeah
exactly
there.
What
kyle
tried
to
do
is
like,
if
you
have
basic
access
to
kcp
and
you're,
like
literally
just
system
authenticated
from
a
q
perspective,
and
you
do
cube
cattle
api
resources
like
you're
expected
to
to
just
work.
J
If
system
authenticated
is
bounded
against
the
system.
Discovery
role
right,
that's
that's
sort
of
like
standard
cube.
The
things
that
you
have
to
add
currently,
on
top
of
that
is
the
two
last
paragraphs
on
the
yaml
that
I
added
there.
So
you
have
to
grant
also
in
this
case
to
the
default
workspace
of
the
root
cluster.
Also
basic
access
permissions
to
authenticated
users
such
that
they
can
see
the
content
of
the
default
workspace
of
the
root
cluster,
including
things
like
discovery
right.
J
So
that's
the
things
that
is
on
top,
that
is
the
delta
to
standard
cube,
so
to
say
at
least
on
the
current
iteration
right.
So
I
picked
also
you
andy
on
this
one
and
obviously
stefan
it's
it's
a
thing
that
gives
me
a
little
thought
that
you
know
might
be
worth
reiterating
how
we
can
make
this
a
little
easier
in
the
future.
It's
not
obvious
if
you're
coming
from.
A
K
J
A
J
Yeah
yeah,
currently
it's
documentation.
I
would
definitely
want
to
contribute
an
authorization
markdown
readme
in
the
kcp
thing.
We
already
have
a
big
list
of
what
we
want
to
do
in
prototype,
3,
4
and
5,
even
for
authorization
together
with
stefan.
So
yes,
but
it
might
be
good
to
have
a
marker
as
a
reminder
I'll
make
sure
to
add
it
to
the
dock
that
we
have
created
of
tasks
and
to
lose.
A
J
A
C
C
Just
mentioned
authorization
md,
we
have
a
docs
folder
and
I
think
we
should
start
documenting
the
at
least
a
big
big
epics,
which
we
implement,
like
authorization
is
not
obvious.
Everybody
knows
that
and
has
just
seen
it.
Workspace
is
the
same
thing,
the
concepts
we
are
building
they
become
non-trivial.
A
Yeah,
I
think,
like
specifically,
this
is
stuff
we
do
that.
That
is
beyond
what
what
kubernetes
already
does
we're
like.
I
don't
want
to
have
like
a
copy
of
all
of
kubernetes
docs
in
here,
but
the
the
specific
kcp
workspaces
are
a
whole
new
concept
with
a
whole
new
set
of
stuff
and
the
way
we
do
auth
as
a
result
is
more
complex,
so
yeah
that
sounds.
That
sounds
good.
A
A
A
L
L
You
know
externally
visible
workspaces
and
the
cluster
workspace,
which
is
mainly
the
implementation
of
it,
based
on
sharding
on
the
workspaces
that
click
on
charts.
This
didn't
distinction
was
not,
you
know
done
so
currently
in
the
workspaces
that
are
available
from
this
endpoint
from
the
virtual
workspace.
L
There
is
nothing
to
to
to
update,
in
fact
in
the
spec.
So,
okay,
I
mean,
I
think
at
least
the
priority
of
this
is
probably
quite
low.
Until
we
know
I
mean
if
we
want
to
surface
in
the
externally,
visible
workspace
object
in
the
public.
The
workspace
object.
If
you
want
to
surface
things
in
the
spec
that
would
be
common
to
all
implementations,
and
that
could
be
you
know
updated.
Then
probably
this
would
become
more
a
higher
priority,
but
for
now
I
think
it's
quite
low
on.
F
L
A
L
Yeah
indirectly,
I
mean
at
least
that
would
probably
be
fixed
while
working
on
on
prototype
three
issue,
which
I
did
not
create
because
it's
you
know
related
to
stefan
work
on
organizations
last
week.
I'm
updating
the
workspaces
virtual
workspace
and,
in
the
context
of
this
work,
possibly
the
watch
support
would
be
added,
but
you
know
just
indirectly.
L
F
Yeah,
without
going
in
too
much
detail
like
we
may
or
may
not
use
the
namespace
controller
from
upstream,
like
we'll,
have
something,
but
it
may
be
something
different.
So
this
is
a
an
experience
and
probably
data
integrity
thing.
So
when
you
go
to
delete
a
workspace,
you
need
to
make
sure
all
the
content's
deleted
in
the
workspace
and
in
all
the
namespaces.
A
C
B
A
F
A
A
I
forget
who
said
it
who
who
proposed
it,
but
I
think
it's
a
good
idea
every
week
to
have
like
housekeeping
as
the
first
or
as
one
of
the
standing
topics,
but
first
we
have
to
like
clean
the
house
so
that
every
weekly
housekeeping
is
small
yep
all
right
well
great.
Unless
there's
any
late,
breaking
news
I'll
see
you
all
next
week
or
on
the
internet
until
next
week.