►
From YouTube: Operation and Custom Plugins for High Availability
Description
When a cluster crashes and is not able to function normally, how do you failover requests from the failed cluster to another healthy Kong cluster to reduce downtime as much as possible and ensure an optimal user experience? In this Kong Summit 2019 session, Yahoo! Japan Site Reliability Engineer, Jun Cui explains how organizations can deploy a huge Kong cluster and operate them for high availability using Yahoo! Japan as a case example.
A
A
So
at
first
please,
let
me
introduce
myself,
I
set
through
a
lability
engineer
at
Piarco,
japan
responsible
for
the
development
and
maintenance
of
multi-tenant
api
gateway
and
supporting
api
idea
to
a
users
company-wide.
Currently,
our
team
is
working
on
internal
and
external
API
idea
to
a
platform
using
Kong.
Thank
you.
A
A
A
So,
in
order
to
to
handle
those
services
more
than
1
and
50,000
bill,
metal
servers
are
running
24
hours
a
day,
note
that
they
are
all
bare
metal,
not
virtual.
So
over
150,000
servers
procs
process
more
than
17
4
billion
page
views
per
month,
2018,
as
you
can
see
a
who
Japan
is
virtual
site,
so
we
provide
API
gateway
platform
with
Kong
Enterprise
Edition.
The
here
is
the
timetable
of
API
gateway
platform.
A
A
Sure
is,
configurations
has
been
created
so
more
than
220
workspaces,
519
services,
690
groups
have
been
created
in
one
cluster
pure
last
month.
The
requests
second
is
more
than
7000
on
marriage
and
that
will
exceed
to
12,000
on
one
cluster.
Ok
I
think
you
have
caught
the
scare
of
Kong
in
Yahoo
Japan
from
what
I
said
earlier.
So.
A
A
A
A
Also
want
to
show
how
we
fare
over
requests
from
shared
server
to
another
hershey
server
by
active
stem
by
plugging
and
I
will
talk
about
active
standby
in
detail
in
custom.
Plugins
part
con
cluster
at
the
east
data
center
proceeds
request
to
front-end
server
in
general,
and
this
front-end
server,
also
at
East
data
center
and
con
chicks
up
streams
hers
on
a
regular
basis.
If
one
of
front-end
server
is
not
able
to
function
normally
active
stem
by
plugging
could
overall,
the
request
to
the
other
healthy
front.
A
End
server,
which
had
at
West
data
center
cohn
for
back
end
also
can
do
the
same
thing.
So
in
this
case
we
could
continue
offering
our
services,
even
if
one
of
front-end
or
back-end
server
has
been
crashed.
Of
course,
proceeds
will
be
returned
to
the
original
F
front-end
or
back-end
server
after
failed
server
has
been
recovered.
A
A
A
First,
let
me
introduce
complicated,
Yahoo
Japan
internal
network
briefly,
so
if
we
want
to
log
into
one
production
server,
we
need
to
access
to
springboard
server
using
one-time
password
at
first
then
access
to
production
server
from
springboard.
So
when
we
deploy
Kong,
we
need
to
access
to
every
con
node
from
local
PC
and
install
necessary
packages
and
to
environment
settings.
As
you
remember,
we
have
240
nodes,
so
we
use
ansible
to
implement
automatic
deploy.
A
So
ansible
is
an
IT
automation.
It
can
configure
systems
deploy
software
using
ansible
playbook
playbook
can
describe
a
set
of
steps
in
general
IT
process
such
as
package
install
and
environment
settings.
So
we
put
playbook
on
kids,
but
the
seniors
we
can't
use
get
at
production
environments
directly.
So
we
have
to
pick
source
code
to
RPM
packages
and
publish
to
auto
factory
using
screwdriver.
Then
we
can
install
RPM
package
medium.
A
So
this
is
example
for
setting
group
variables
configuration
of
unstable,
so
original
con
config
file
would
be
updated
by
what
we
configured
here,
such
as
kong,
log
level,
2
arrow
and
custom
plugins
listed
here,
would
be
installed
by
unstable.
What's
more,
we
also
can
arrange
ssl
certificate.
She
other
required
packages,
so
all
of
them
could
deploy
with
us.
Go.
A
The
first
one
is
traffic
abuse
prevention,
so
this
plug-in
sends
required
information
to
traffic
abuse
prevention,
server
from
consumer
and
check
if
request
meets
the
requirements.
For
example,
if
developer
decided,
each
user
could
access
only
10
times
in
one
minute,
they're
from
allowance
access
would
be
denied
by
this
plugin
so
that
could
protect
from
toast
attack.
A
A
A
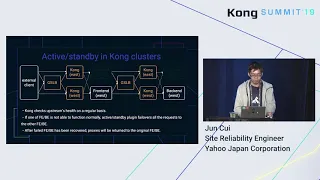
So
this
figure
shows
the
typical
cons
behavior
in
normal.
If
all
the
proceeds
Tanisha
knows
become
unhealthy
state
con
can't
block
traffic
to
upper
stream
and
return
of
fixity
response
immediately
without
proceeding
request.
Sorry
page
plug-in
could
respond.
Customized
content
and
status
code
to
end
users
instead
of
fixed
response
and
developers
could
customize
that
for
each
end,
point.
A
In
the
third
plug-in
is
active
standby,
so
cone
would
closely
request
to
API
node
of
first
cluster
in
normal.
If
all
the
process
destination
a
panels
become
a
hair
state,
a
to
standby
plug-in,
could
switch
or
request
to
APA
knodel.
Second
cluster,
of
course,
after
one
of
a
payload
of
first
class
cluster
has
been
recovered,
proceeds
will
be
returned
to
first
cluster,
so
also
we
think
this
function
could
implement
by
canary
bees.
So
when
we
develop
this
plug-in.
A
Here
is
a
comparison
of
configuration
required
by
canary
and
active
standby.
So,
as
you
can
see,
canary
have
much
more
parameters
need
to
be
filled.
Users
spend
more
time
to
read
or
understand
documents
to
implement
active
standby
functionality.
Using
this
plug-in
accused
ember
has
only
one
parameter,
so
it
is
easier
to
understand
and
more
simple
uses
then
can
already
this
plug-in,
but
this
plug-in
is
for
active
standby
only
so
the
functionality
is
not
as
rich
as
can
our.
A
A
One
more
thing
is
actually
two
months
ago
someone
kissed
Yahoo
Japan
services
on
Twitter,
the
front-end
server
responded
internal
error
message
directly
to
the
end-user,
so
which
is
chimera,
so
he
or
she
tweeted,
hey
Yahoo.
What
is
Cornero?
Who
is
gorilla,
so
the
second
issue
is
display
Conneaut,
when
the
users
is
not
expected,
especially
for
front-end
developers,
and
we
will
develop
a
custom
plugin
for
front-end
developers
to
show
customers
a
page
to
end
users
instead
of
Canario.