►
From YouTube: WG API Expression Bi-Weekly Meeting for 20200915
Description
WG API Expression Bi-Weekly Meeting for 20200915
A
A
C
C
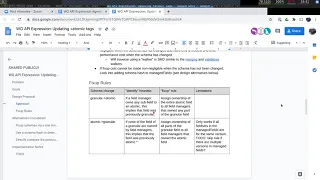
The
bug
was
that
in
kubernetes,
the
label
selector
is
marked
as
granular
or
separable,
which
means
that
each
part
of
it
is
considered
its
own
thing.
You
can
own
just
a
little
bit
of
the
label
selector
just
one
field
or
something
that
doesn't
really
make
any
sense,
and
it
gets
really
confusing.
There's
a
whole
bug
about
all
the
confusion
that
can
happen
so
that
so
it
needs
to
be
atomic,
which
is
really
easy.
Conceptually
to
do
like
you
can
add
atomic
to
it.
C
It'll
do
the
right
thing,
but
that
creates
a
new
problem,
because
you
have
pre-existing
data
and
field
sets
that
show
ownership
of
these
pieces
of
this
strut
from
data
that
was
written
before
you
made
it
atomic
and
this
this
exists
in
the
wild
today
right.
So
it's
a
real
problem.
We
have
if
we
want
to
fix
this
label
selector
problem.
C
C
All
right,
if
you
refresh
that,
should
show
now,
and
so
this
exists
in
two
different
ways.
So
so
one
way
you
can
run
into
this
is
the
way
that
we're
running
into
kubernetes,
like
you,
basically
don't
want
to
introduce
a
v2
of
every
type
of
kubernetes
to
fix
those
problems,
because
server
side
apply
is
still
in
beta.
Like
that's
a
pretty
it's
it's
an
intractable
thing
to
do
right,
nobody's
going
to
go
for
that,
so
we
have
to
do
it
in
an
unversus
way.
C
So
I
have
to
we
have
to
somehow
kind
of
detect
that
the
problem
has
happened
and
then
fix
it
and
that's
actually
doable.
I
have
code
that
does
that
it
can
detect
that
anywhere
that
you
own
the
subfields
of
something
that's
atomic.
Clearly
you
have
the
change,
even
though
we
don't
even
know
what
the
schema
was
before
you
can
kind
of
imp
infer
in
a
very
safe
way.
C
C
But
it's
not
right,
like
you
should
be
able
to
say
I'm
introducing
v2
of
something,
and
you
should
just
be
able
to
change
anything
about
the
schema
and
people
expect
that
to
be
fine,
but
it
turns
out
that
that's
actually
a
problem
too,
so
this
exists
as
a
problem
in
both
of
those
cases,
and
so
I've
figured
out
how
to
do
one
of
the
changes
going
from
granular
to
atomic.
I
can
do
going
from
atomic
to
granular.
C
It
turns
out,
it
is
much
harder
to
detect
and
I
don't
think
I'm
going
to
spend
the
whole
time
talking
about
it
here,
but
it
basically
involves,
like
you
kind
of,
have,
to
try
and
infer
it,
but
you
need
you
need
like
a
bunch
of
information
about
all
the
field
managers,
the
entire
schema
all
of
the
live
objects.
It's
really
complicated
to
do
it's!
C
It's
like
a
three-way,
merge
right
of
data,
and
I
I
actually
almost
have
it
working,
but
it's
going
to
be
really
expensive
to
do
and
we're
gonna
have
to
potentially
do
it
on
every
apply,
because
you
don't
know
if
the
scheming
has
changed,
yeah
so
anyways.
This
is.
This
is
turning
into
like
a
little
bit
of
a
mess.
C
So
one
thing
I
was
thinking
of
doing
was
solving
the
granular
to
atomic
one
now,
which
gets
us
out
of
the
immediate
problem
with
the
field
label
selector
and
closes
a
bug
and
then
start
to
continue
to
build
out
documentation
about
why
going
from
atomic
to
granular
is
so
hard,
but
I
just
kind
of
wanted
to
surprise
it
to
people
and
kind
of
explain
the
problem
in
broader
scope.
If
anybody
has
any
thoughts
on
this
document,
pretty
well
covers
it.
There
are
some
alternatives
we
consider
down
below.
C
One
of
them
is
instead
of
doing
it,
instead
of
doing
the
fix
up,
which
I'll
call
this
the
fix
up
when
you
detect
that
there
is
a
schema
change
somehow,
instead
of
doing
the
fix
up
as
part
of
the
wide
serving
path,
you
could
try
and
do
it
as
like
some
kind
of
background
migration
task,
but
that
runs
into
like
a
correctness.
Problem
right,
you
can't,
you
can't
serve
you
can't.
Handle
applies
on
objects
where
they've
changed
safely
until
you
fix
them
up.
C
So
if
you
do
it
as
a
background
thing,
then,
basically,
once
the
scheme
has
changed,
you
have
to
like
stop
the
world
from
applies
or
any
rights.
Actually
until
you
left
up,
you
could
mitigate
that
still
by
going
through
and
saying
well,
we
know
which
ones
have
been
migrated
and
not
if
it
hasn't
been
migrated,
then
the
online
circumpress
could
like
proactively,
do
it,
but
then
you're
getting
into
this
really
complicated
implementation.
C
Yeah
do
that
in
the
alternatives,
and
what
that
does
is
that
helps
that
helps
reduce
the
cost
when
nothing's
changed.
So,
for
example,
if
if
we
built
this
and
then
I
performance
tested
it,
and
we
found
that
it
was
super
slow
like
unacceptably
slow
and
there's
nothing
that
we
could
do
to
do
it
better,
we
could
we
could.
We
could
bring
up
that
idea
as
a
way
to
optimize
it.
I
was
kind
of
holding
off
to
do
that
until
we
saw
like
what
the
performance
was,
but
even
that
doesn't
change.
C
A
B
C
A
B
C
B
You
have
a
new,
so
I'm
assuming
this
is
true
for
built-in
types
and
crds
right
yeah.
So
so
the
built-in
type
is
built
inside
the
api
server.
So
let's
say
you
have
a
new
version
of
the
api
server
where
it
went
from
granular
to
atomic
yeah,
and
now
you
update
to
this
version
of
the
api
server,
but
because
it's
maybe
an
hr
cluster
or
whatever
the
upgrade
is
not
atomic.
B
It's
granular,
and
so
it's
going
to
work
one
way,
but
some
may
see
the
fields
as
being
epitomic,
even
though
see
what
I'm
saying
like
yeah
you're,
going
to
transform
some
object
from
granular
to
atomic
and
then
another
api
server
is
maybe
going
to
want
to
go
from
granular
back
to
atomic
yeah.
I
know
it
could
totally
happen.
C
C
To
we
kind
of
have
to
deal
with
that
anyways
because
say
you
have
a
v1
and
v2
and
then
v2
you
make
something
granular
and
v1,
it's
still
atomic,
then
for
an
undefined
period
of
time
you
have
some
clients
working
against
something
that
thinks
it's.
Atomic
and
some
bookings
against
somebody
thinks
it's
granular,
but
there
are.
B
C
It's
it's
the
ideal,
yes,
but
unfortunately
the
way
that
we
work
with
field
ownership.
It's
kind
of
we
we
do
a
lot
of
like
set
operations
to
figure
out
like
how
the
field
ownership
was
supposed
to
work
in
a
different
version
and
then
like
transform
that
into
the
other
version,
and
it
doesn't
really
consider
the
granular
atomic
change.
C
Interesting,
so
it's
gonna,
there's
gonna,
be
there's
gonna
be
problems.
I
think
the
short
of
this
is
that,
like
this
is
actually
a
really
nasty
problem
like
hidden
underneath
this
are
a
lot
of
things
that
make
it
very
hard
to
solve.
Even
if
we
had
the
previous
schema,
like
some
things,
get
a
lot
better,
but
it's
still
like
some
of
the
things
we
mentioned
aren't
solved
by
that
like.
If
we,
if
we
had
the
previous
schema,
then
you
would
actually
know
exactly
what
the
change
was
on.
Mbus
you'd
be
like.
C
B
C
I
I
think
yeah
I
think
we
can.
I
think
I
think
we
could
do
the
one
we
would
need
now,
which
is
go
from
granular
to
atomic,
solve
the
labor
selector
problem
that
actually
exists
in
kubernetes.
Right
now
sure
we
can
prove
that
the
aha
state
might
be
conflict
heavy
briefly,
but
will
coalesce
to
something
sane
like
it
will.
B
C
Yeah
we
need
to,
we
need
to
see
what's
happening
there.
If
we
don't
implement
that
and
we
only
implement
granular
to
atomic,
then
then
you'll
have
some
clients
that
are
still
like
writing
that
as
granular
again,
but
then
the
upgraded
ones
will
keep
trying
to
transition
to
atomic
once
everybody's
upgraded
they'll
they'll
eventually
agree
that
it's
atomic,
and
during
that
period
I
think
you
might.
C
B
C
A
C
The
problem
is,
is
once
if
you
go
to
atomic,
then
you
end
up
owning
just
the
top
level
of
the
the
record,
and
so
then
anybody
that
owns
granular
fields
doesn't
necessarily
see
that
as
a
conflict,
okay,
yeah
yeah-
if
they
just
don't
want
part
of
the
field,
they
don't
conflict
with.
Somebody
owns
just
the
top
of
it.
They
would.
C
C
C
All
right,
okay
and
then,
if
we
let's
see
how
we
do
it
on
time,
I've
used
13
minutes,
yeah,
so
tombstones.
I
didn't
want
to
show
everybody
everything.
Everybody
remembers
the
previous
one
I
had,
but
if
you
go
down
to
alternatives
considered,
I
blew
out
two
examples
and
I
thought
they
were
kind
of
interesting
and
just
as
context.
I
know
antoine
asked
me
this.
So
the
reason
that
we're
looking
at
tombstones
now
is
not
to
do
an
implementation.
C
It's
so
that
if
we
go
to
ga
we
can,
we
can
say
with
with
authority
like
this,
could
be
a
post,
ga
task,
and
we
know
we
know
that,
because
we
know
how
we
could
implement
it,
which
I
think
is
something
that's
going
to
come
up.
So
one
of
the
alternatives
was
instead
of
modifying
the
way
we
represent
the
the
actual
applied
configuration.
C
We
allow
appliers
to
write
the
managed
fields
and
by
doing
that,
any
any
field.
They
claim
they
own
here
if
it
doesn't
exist
in
their
object,
they're
effectively
saying
they
tombstoned
it.
The
really
nice
property
about
this
is
when
you
tombstone
objects.
This
is
the
resulting
field
set
anyway
right.
This
is
this
is
how
we're
going
to
represent
that
you
own
something
that
you
don't
have
in
your
object,
so
you're
actually
just
doing
apply
on
the
manage
fields.
C
It's
very
declarative,
like
you're,
actually
changing
the
state,
it's
going
to
be
in
you're,
not
doing
anything
magical.
It
has
a
couple
nice
properties,
so
it
has
a
nice
property.
It's
very
declarative,
right,
you're,
actually
setting
the
state
to
what
you
want
to
see.
If
you
read
it
back
again,
you'll
actually
see
what
you
wrote,
which
is
really
nice
you're,
not
changing
the
the
apply
configuration
at
all,
so
we're
not
breaking
the
schema
rules.
We're
not
changing
anything
like
that.
C
The
main
downside
of
it
is
that
it's
arguably
less
like
agronomic
right
if
you're
a
developer-
and
you
do
have
to
tombstone
something
you
do
have
to
figure
out
how
to
write
this.
It
may
not
be
super
obvious
how
to
do
it
and
a
point
that
antoine
may
that
I
agree
with.
Is
you
also
have
to
put
the
manager
in
here
because
it's
required
as
a
key
to
actually
be
able
to
write
the
field
set,
so
here
the
manager
is
coop
cuddle.
C
So
that's
not
super
great
because
you
could
imagine
if,
like
you're,
writing
these
files
somewhere,
you
might
not
even
know
what
your
manager
is,
and
it
could
be
that
it's
applied
from
different
by
different
managers
into
different
systems.
So
that's
actually
probably
the
biggest
like
practical
downside
to
this.
If
you
write
like
language
bindings
like
if
you
write
like
a
go
client
that
helps
you
do
tombstone,
you
would
never
even
have
to
worry
about
where
this
stuff
goes
right.
C
C
C
The
next
alternative
is
just
kind
of
like
that
one,
except
for
instead
of
saying,
instead
of
actually
writing
to
the
managed
fields.
Stanza
we
create
like
a
new
stanza.
It
doesn't
have
to
be
called
tombstone,
but
that's
you
know
just
as
an
example
like
a
straw,
man
and
you
don't
put
the
manager's
name
in
this.
You
just
put
the
fields
that
you
want
tombstone,
that's
the
difference
between
this
and
the
previous
one.
So
it's
just
a
variant
on
that
and
then
the
last
alternative
was
one
that
had
been
mentioned.
C
A
couple
different
ways.
Antoine
mentioned
it,
but
in
a
slightly
different
way-
and
I
think
daniel
mentioned
it
exactly
this
way-
which
is
you
actually
do
yaml,
you
can
have
different
co,
you
can
have
different
parts
separated
by
dash
dash
dash.
So
the
idea
was
that
you
allow
a
second
a
second
body
in
the
apply
request,
which
is
the
things
you
want.
Tombstone
there's
the
practical
problems
with
this
is
there's
a
lot
of
machinery
already
for
kubernetes.
That
probably
doesn't
understand
that
you're
allowed
to
have
a
dash
dash
dash
here.
C
It's
also
it's
a
little
easier
to
write
because
you're
kind
of
using
the
object
structure,
I'm
not
a
huge
fan
of
this
approach.
I
feel
like
it
feels
a
little
bit
magical.
There's
some
there's
some
variants
on
this
approach.
One
approach
would
be
like.
Instead
of
having
to
be
a
separate
thing,
you
have
to
be
like
a
sub
resource
or
something,
but
then
you
lose
atomicity.
C
A
C
Okay,
so
what
I
think
I'm
going
to
do
with
this
is
I'm
going
to
definitely
comment
on
the
ones
you
like.
In
addition,
what
you
say
in
this
meeting,
I'm
probably
going
to
swap
out
the
leading
design
with
one
of
these
recommendations
and
then
what
we'll
probably
do
is
shelve
this
design,
and
I
think
what
we'll
do
at
that
point
is
when
we
talk
about
ga,
we'll
kind
of
use
this
as
a
as
a
reference
for
why
we
think
we
have
you
know
because,
like
this
one,
for
example,
you
could
implement
this
postgame
right.
C
B
You
forgot
about
me
so
sorry,
okay,
so
we
need
to
see
the
api
machinery
is
trying
to
decide
if
what's
going
to
happen
soon
in
api
machinery,
and
so
obviously
the
question
of
solo
site
apply
is
coming
up
and
we
need
to
know
daniel
was
suggesting
or
asking.
If
we
were
planning
on
making
silverstein
apply
ga
for
121.
D
C
B
You
definitely
need
some
time
to
suck
the
features
if
needed.
So
that's
something
to
remember,
and
eventually
we
want
to
land
in
gta.
I
don't
think
we
want
solar
setup
like
to
not
be
ga
for
too
long
joe
has
done
this
process
of
going
for
ga
in
the
past.
It's
not
like.
I
haven't
withdrawan
and
div
with
julian,
but
I'm
expecting
some
inputs
from
joe,
because
the
crds
were
significantly
more
difficult,
yeah
happy
to
do
that.
But
so
what
do
you?
C
C
Some
of
the
things
that
I
didn't
expect
that
ended
up
being
really
important
was
you
have
to
get
conformance
to
a
certain
level,
so
you
you're
you're,
going
to
dedicate
quite
a
bit
of
manpower
to
defining
agreeing
on
and
getting
written
and
approved
and
committed
a
bunch
of
conformance
tests
around
your
feature
to
make
sure
that
it's
implemented
by
other.
You
know
that
anybody
that
says
they're
a
compliant
certified
kubernetes
distributionist
actually
has
the
functionality
that
you
expect
that
took
a
lot
of
time.
C
So
like
we
had
to
be
fairly
crisp
on
like
like
how
did
we
think
about
scalability
performance
like
how
did
we
like
map
that
back
to
the
way
that
the
rest
of
like
six
scalability
thinks
about
things?
So
we
talked
to
scalability
for
quite
a
bit
of
time
made
sure
we
understood
like
what
their
their
guarantees
were,
mapped
them
back
to
crds
and
everything
ended
up
being
like
you
could
have
so
many
crds
of
you
know
different
things
and
so
forth,
and
it
it
was.
Quite
that
was
a
fairly
involved
project.
C
C
C
I
think
part
of
part
of
going
to
ga
is
like
you
have
to
prove
to
the
right
stakeholders
that
this
is
not
just
ga
in
terms
of
implementation
quality,
but
ga
in
terms
of
like
usage
right
are:
are
there
enough
people
using
this
thing
that
it
should
be
part
of,
or
so
to
speak
those
were
some
of
the
big
ones?
Some
of
those.
B
C
C
Yeah
so,
for
example,
crds
going
to
ga
versioning
had
to
be
fully
fleshed
out.
Crd
versioning
was
like
a
big
like
partially
incomplete
thing,
so
we
had
to
like
change
the
way
this
custom
resource
definition
objects
were
structured,
so
you
could
have
multiple
versions,
so
you
could
have
conversion
web
hooks,
so
the
conversion
web
hooks
were
all
like
set
up
and
secured
tls
all
the
things
you'd
expect
from
a
web
hook.
There
was
a
whole
push
around
like
metrics
and
then
from
instrumentation.
C
C
There
was
a
fairly
substantial
burn
down
one
of
one
of
the
hardest.
Things
was
getting
agreement
on
like
what
the
remaining
like
bug
and
feature
gaps
were
those
those
two
lists
were
like
pretty
serious
and
there's
a
lot
of
back
and
forth.
Like
sig
apn
machinery
on,
like
you
know,
there
was
a
major
complaint
about
web
hook
ordering
for
web
hooks,
and
this
is
web
hooks
and
so
like.
C
What
we
would
do
is
we
would
call
out
all
the
things
that,
yes,
we
agreed
need
to
be
done
at
some
point,
but
don't
necessarily
need
to
be
part
of
ga,
and
our
criteria
for
ga
was
like
it's
needed
for
the
feature
to
be
useful
and
it's
or
it's
something
that
we
can't
change
without
like
breaking
backwards
compatibility
in
some
way,
because
once
you
go
to
ga,
you
really
lock
down
your
api
like
you're.
That's
now
a
forever
api
and
so
being
able
to
like
show
that
like
yeah.
That's
that's
important.
C
It's
a
really
nice
feature,
but
people
are
using
crds
today
and
they
would
really
benefit
from
having
a
v1
and
if
we
don't
give
them
a
v1
because
of
that
that's
actually
not
in
their
service.
Right,
like
we
can
add
that
postga
and
it
will
still
be
they'll,
still
be
just
as
good
as
it
was
now,
and
there's
no
reason
why
it
can't
be
added
post
ga
so
that
list
building
that
list
and
then
advocating
that
a
bunch
of
stuff
belonged
in.
A
C
B
B
A
A
B
How
am
I
starting
I'm
I'm
still
working
on
that?
The
more
I
work
on
that
the
more
difficult
it
is.
I
will
I'm,
I'm
literally
working
on
that
damn
the
prime
is
still
that
built-in
and
crds
are
not
the
same,
and
if
we
want
to
have
something
that
makes
sense,
we
want
them
to
be
as
similar
as
possible,
but
we
don't.
Even
I
don't
know
if
we
even
understand
properly
what
the
differences
are,
and
so
I'm
trying
to
investigate
and
work
on
that.
C
B
The
defaults
should
be
very
easy
if
we
solve
the
other
one.
I
mean
the
two
are
very
tightly
related.
I'm
trying
to
not
make
them
be
the
same
so
that
we
can
simplify
the
process,
but
at
some
point
we
almost
we're
almost
considering
merging
these
two
together
because
they're
so
tightly
coupled,
but
I'd
rather
not
do
that
right,
yeah.
We
simply
need
defaulting
to
do
that.
B
A
Yeah,
instead
of
swiping,
I
I
think
a
week
ago
I
had
some
short
time
to
push
something,
but
remember
my
my
last
two
weeks
were
way
too
full
it's
there's
still
way
stuff.
That's
waiting
for
review
like
you
can
look
at
it
and
I
still
need
to
do
the
pod
util
stuff.
Sadly,
but
it's
it
should
be
mostly
finished.
C
One
of
the
reasons
I
say
is
when
we
went
to
stig
api
machinery
there
would.
The
the
guidance
was
don't
build
something
in
kate's
cates
go
experiment
elsewhere,
see
if
you
can
prove
value
with
the
developer
community,
which
made
me
wonder
if
if
sig
apm
machine
really
really
wants.
This
is
part
of
like
a
ga
prerequisite.
B
C
C
No,
it
wouldn't-
and
it's
not
clear,
it's
not
clear
to
us
yet
that
that
the
majority
of
developers
that
are
getting
value
out
of
it
need
need
that
right
now
we
might
get
more
developers
later
from
it.
Maybe,
but
we
don't
know
yeah,
I
think
there
you
go
okay,
so
we
can
mark
that
one
as
post,
ga
and
I'll
talk
to
the
sig
api
machinery
and
let
them
know
we're
thinking
that
way.
A
A
A
A
C
C
B
C
B
A
C
B
A
B
A
B
C
B
B
C
B
B
C
B
B
B
Oh
yuck
yeah,
if
you
send
an
end,
it's
going
to
be
canonicalized
to
a
string
and
we're
going
to
think
there
is
a
change
every
single
time
I
see
so
we
need
to
know
we
need
to
be
able
to
canonicalize
audio
in
server
side
of
player
or
somewhere
before
that,
and
ideally
this
is
part
of
the
open
api.
So
we
know
how
to
but
it's
kind
of
difficult,
because
we
would
need
to
know
how
the
canonicalized
function
works
inside
the
open
api
definition,
and
I
mean
yeah,
we
don't
have
any
such
thing.
B
B
Also,
I
don't
see
how
this
is
different
from
a
mutating
white
hook.
What
if
the
canonicalization
was
done
by
a
mutating
my
hook,
we
would
always
have
this
problem,
wouldn't
we
yeah,
so
I
mean
technically
anyone
can
build
a
system
that
is
going
to
be
broken
in
such
a
way
and
there's
nothing
we
can
do
about
it.
C
B
Yeah,
so
we
see
we
compare
the
object
against
the
new
object
against
the
live
object
and,
let's
say
the
live.
Object
has
a
string.
The
new
object,
the
new
applied
object
has
an
end,
even
though
the
int
would
be
canonicalized
to
the
same
string.
We're
like
oh
you're,
trying
to
change
the
object,
and
so
we
record
that
inside
the
timestamp
date
yeah.
A
B
B
A
B
A
B
This
one
absolutely
needs
to
be
fixed,
yeah
quantity
phase,
stop
checking,
because
if
you
receive
a
need,
I
think
it
completely
fails
outside
of
play,
because
it's
like
you
send
that
you
sent
on
it
and
it
needs
to
be
a
yeah.
That's
just
a
string
yeah
and
I'm
pretty
sure
we
had
solved
that
problem
initially.
I
can
definitely
remember
working
with
daniel
on
this
specifically,
so
I'm
very
surprised.
B
And
andrea
sent
an
update
in
the
slack
channel
about
that.
I'm
gonna
make
the
update
for
him,
but
jordan
found
out
that
this
bug
was
not
because
of
server
side
of
like
yay,
oh
cool,
but
it's
it's
still
confusing
for
many
reasons.
So
we
need
to
update
something
so
that
it's
not
that
confusing
and
the
documentation.
A
C
B
B
A
C
B
C
C
D
B
B
C
B
C
A
B
Got
it
yeah
because
back
then
tracking
the
fields
was
very
expensive,
so
we
couldn't
just
run
the
tracking
for
every
single
mutating
web
hook.
There's
also
the
possibility
of
running
it
once
and
say.
This
is
admission
controllers
in
general
that
made
these
changes
having
the
specific
details
of
like
hey,
who
has
changed
this
field?
Oh
it's!
Actually,
this
mutating
web
hook,
that's
actually
very
useful.
I
think.
B
A
C
B
A
B
I
think
if,
if
I
had
to
give
my
a
quick
opinion
on
that,
how
do
I
do
that?
I
think
julian
and
I
have
done
a
ton
of
work
on
this
already
and
so,
and
julian
has
been
really
on
top
of
everything
for
that.
So
any
experience
glitch
that
we've
seen
on
server
side
apply
so
far
has
been
tackled
extremely
quickly,
so
I
wouldn't
be
so
I
wouldn't
be
surprised
if
this
is
actually
fine.
B
We
don't
I
mean
besides,
maybe
the
fact
that
people
are
frustrated
with
the
managed
fields
being
two
verbals
in
gets
and
stuff,
but
beside
that,
I
think
the
experience
has
been
somewhat
polished
already.
So
I
wouldn't
be
surprised
if
we
don't
have
anything.
I'd
be
curious
about
going
about
the
flags
again,
because
we
have
like
many
flags
and
the
conflict
with
client
side
of
play
flags,
but
I
wouldn't
be
surprised
if
this
is
mostly
good.
C
That's
great,
I
remember
when
we
were
talking
with
sig
ap
my
machinery.
One
of
the
questions
we
had
was
like:
should
we
be
converting
controllers
to
be
using
apply
and
the
answer
I
seem
to
to
get
there
was
that,
like
most,
the
built-in
controllers
were
not
going
to
change,
so
I
think
I
think
if
anybody
asks
during
jf,
we
should
be
like
migrating
controllers
or
things.
I
think
the
answer
should
be
metal.
Does
everybody
agree
with
that?.