►
From YouTube: Gateway API Meeting (APAC Friendly Time) for 20210407
Description
Service APIs Meeting (APAC Friendly Time) for 20210407
A
B
Yeah
yeah,
so
we
wanted
to
make
sure
that
we
got
one
of
the
goals
we
want
to
get
a
blog
post
on
the
kubernetes
blog
before
kubecon,
just
to
generate
some
buzz.
Now
that
I
think
you
know
this
is
probably
a
good
time
to
start
being
more
vocal,
I'm
in
the
process
of
writing
it
right
now.
What
I
was
going
to
do
is
I
was
going
later
today.
I
was
just
going
to
open
the
doc
post
issue
in
the
gateway
chat
and
people
can
give
it
lgtms.
B
What
I
was
planning
on
doing
is
basically
asking
for
each
of
kind
of
the
major
contributors
here
to
put
their
name
on
it,
and
so
we
could
get
in
the
authors
list.
It
would
basically
be
you
know,
you
know
one
or
two
people
from
each
company-
that's
kind
of
been
contributing
to
it,
so
that
that'll
be
kind
of
at
the
at
the
blog
post,
so
it
just
kind
of
shows
that
it's
a
multi-vendor
kind
of
thing,
but
anyways
yeah.
That
was
pretty
much
it.
A
Awesome,
that's
great
yeah.
It
feels
like
leading
up
to
kubecon
in
the
next.
I
guess
few
weeks,
we're
really
going
to
have
a
lot
more
content
out
around
gateway,
and
I
think
that's
going
to
cause
more
people
to
pay
attention
and
maybe
get
some
more
involvement
here.
Some
more
people,
testing
out,
implementations
and
so
excited
to
see
what
what
comes
of
that,
but
yeah
thanks
thanks
for
taking
the
lead
on
a
blog
post
here.
A
A
B
What
you're
thinking
yeah
yeah
yeah,
if
you
just
want
to
go
just
scroll
down
a
little
bit?
I'm
just
gonna
go
through
this,
so
this
has
been
that's
perfect.
This
has
been
the
issue
that
I've
been
concerned
about
from
the
start,
which
is
basically
the
bullet
points
here.
Detail
it
like
some
level
of
proprietary
capabilities,
are
used
for
every
single
gateway
controller.
It
doesn't
matter
which
one
it
is.
B
If
it
doesn't
do
that
a
hundred
percent,
then
all
these
companies
will
end
up
supporting
two
separate
apis
and
yeah.
So
that's
that's
the
rationale
for
you
know
why
this
is
important
further
on
is
I
I
use
the
word
policy
in
this
doc,
but
it's
super
overloaded
term.
It's
really
I'm
just
talking
about
traffic,
mostly
traffic
settings,
but
some
security
things.
B
C
You
gave
kind
of
the
traffic
time
out
and
as
an
example
a
few
different
times
for
the
driver
for
this
document,
so
that
I
had
created
a
pr
early
on
it's
still
there,
because
we,
you
know
we're
kind
of
going
back
and
forth
like
does
this
belong
along
a
4-2
or
does
this
belong
in
a
a
back
end
and
it's
still
kind
of
been
up
for
debate.
So
I
guess
what
I'm
getting
at
is
like.
B
Yeah,
I
I
I
agree,
I
think,
there's
ultimately,
what
we
can
put
in
the
core
api
are
the
things
that
all
the
vendors
do.
Similarly
right,
if
everybody
supports
the
configuration
of
connection
timeouts
at
the
granularity
level
or
at
the
scope
of
like
an
individual
service
and
and
the
semantics
of
the
timeouts
all
mean
the
same
things
between
us.
Well
then
great
we
can
it
can
go
in
the
core
api
right
and,
like
things
like
path,
matching
and
header
matching
are
unambiguous
and
they're.
B
Yet
health
checks,
I
think,
might
be
one
example
because
I
feel
like
the
parameters
for
health
checks
are
somewhat
uniform
across
different
implementations,
but
other
things
are
not
so
much,
and
so
this
is
really.
This
is
the
scope
of
this
is
focused
on
those
custom
parameters
and
how
to
extend
the
api
with
those
things.
B
B
So
you
couldn't
do
it
any
more
granularly
and
if
you
had
multiple
like,
if
you
have
it
caused
all
kinds
of
issues
because
there's
mismatch,
but
basically
it
points
to
the
fact
that,
like
we've
implemented
things
different
at
different
levels,
and
so
it
does
require
the
ability
to
attach
policy
at
different
levels
as
well.
There's
also
kind
of
a
policy
based
element
here,
where
some
people
want
to.
B
B
Maybe
you
could
set
health
checks
at
the
gateway
class
as
like
a
default
health
check
that
always
gets
applied
or
maybe
they're
set
at
the
gateway?
Maybe
they're
set
on
the
route,
maybe
they're
set
on
the
route
rule
which
is
like
you
know
the
forward
two,
maybe
they'll
set
on
the
service,
maybe
they're,
set
on
the
subset
of
the
service.
There's
many
levels
from
broad
to
granular
across
which
any
of
these
configuration
fields
could
apply
and
they'll
be
valid
and
not
valid
for
different
implementations.
B
A
Yeah,
I
think
this
is
a
really
good
part
yeah.
I
think
I
think
this
is
a
really
good
point
and
it
kind
of
lines
up
with
what
damian
was
saying.
Earlier
too,
we
were
really
struggling
with
where
policy
belonged
right.
You
could
make
an
argument.
Well,
you
might
want
to
have
a
default
timeout
for
an
entire
class.
You
know
that
or
you
might
want
to
have
a
timeout
on
a
route
rule
or
you
might
want
to
have
it
attached
to
a
specific
service.
A
Whatever
it
happens
to
be,
you
can
imagine
that
you
want
to
have
these
kinds
of
config
attached
at
different
points,
and
although
this
dock
and
this
concept
is
really
tied
to
how
we
might
want
to
attach-
you
know
kind
of
implementation,
specific
policy,
I
think,
there's
a
lot
of
overlap
with
even
policy
that
finds
its
way
into
the
core
api.
We're
struggling
with
these
same
issues
of
where
does
it
belong,
and
can
we,
you
know,
provide
a
standard
way
that
you
can
attach
at
multiple
points
so
yeah
anyway?
B
B
Oh
okay,
I'll
stop
here.
So
basically,
I'm
proposing
and
the
names
maybe
should
be
different.
So
there's
there's
a
couple
different
ways:
how
like
standalone
policy
resources,
column
configuration
resources,
get
attached
to
services
in
gke
ingress.
We
happen
to
have
a
model
that
I
actually
I
don't
like
very
much
where
the
policy,
the
service
resource,
has
an
annotation
that
references,
this
policy
resource
and
it's
basically
so
service
references
to
the
policy
resource,
there's
other
ones
where
the
the
back-end
policy
that
we
already
have.
B
That
goes
the
other
way,
so
the
back-end
policy
references
the
service
like.
If
you
look
at
something
like
the
destination
rule
for
istio,
it
is
policy,
it's
basically
a
standalone
policy
resource
that
references,
the
service
by
the
host
name
of
the
service,
which
is
a
very
different
way
of
doing
it.
B
So
I
looked
at
all
these
and
one
of
the
things
I
did
like
around
the
resources.
Referencing,
the
policies
is
that
you
can
trace
the
poli,
like
all
the
all
the
policy
that
affects
everything
by
just
going
through
the
christmas
tree
of
different
resources,
and
you
can
like
you
can
basically
go
look
at
the
service.
Look
at
the
resources,
it
references
and
then
you
can
understand.
You
know
very.
B
You
can
write
it
down
on
paper
and
you
can
understand
what
policy
is
affecting
it,
whereas
if
you
have
like
the
back
end
policy
that
we
have
today
in
the
gateway
api
references
the
other
way-
and
you
can't
do
that
unless
you
know
about
that
resource
yourself,
so
it's
a
little
bit
harder
to
trace
so
anyway.
So
I
have
this
so
I
propose
that
there
is
this
policies
field
and
that
this
policies
field
should
exist
at
multiple
levels
within
the
gateway
api,
maybe
even
multiple
levels
within
the
same
resource.
B
So,
for
instance,
it
could
exist
in
the
under
the
forward
two.
It
could
also
exist
kind
of
on
the
other
route
itself.
It
could
exist
on
the
service,
the
gateway
or
the
gateway
class,
and
the
policies
field
is
a
list
that
references
that
allows
it
to
reference.
Arbitrary
crds,
these
are
basically
policy
crds,
you
know,
here's
one
that
we
would
have
for
for
gcp
and
we're
just
I'm
just
calling
a
service
policy
crd
and
these
these
crds
have
any
kind
of
config
in
there.
That
is
specific
to
implementation.
B
I
think
the
next
yammel
after
this,
I
think
the
full
the
full
example
so
here's
an
example
of
basically
yeah.
Let's
say
in
our
service
policy,
we
have
a
minimum
tls
version,
and
so
I've
created
basically
three
different
service
policy
resources
and,
and
then
I've
referred
to
them
on
the
gateway.
Now
this
was
totally
inspired
by
the
tls.
B
How
tls
is
designed
in
the
gateway
right
now,
where
there's
basically
an
override,
so
any
resource
can
reference
a
policy
and
it
then
it
can
also,
you
know,
allow
or
deny
policy
override,
which
basically
means
any
resources,
any
gateway,
api
resources,
southbound
of
it,
can
or
cannot
override
that
policy
resource
and
the
fields
in
that
policy
resource.
So
this
example
basically
shows
it
references
two
of
the
same
crds
right.
Both
service
policy,
crds
of
the
same
api
group.
B
One
is
set
that
it
allows
policy
override,
so
the
gateway
foo
policy
allows
it
the
gateway
default
policy,
it
denies
it,
and
so,
if
you
look
at
the
gateway
default
policy,
it's
like
okay,
hbs,
redirects,
true
limit
connections,
so
those
things
cannot,
those
fields
cannot
be
overridden
and
the
gateway.
The
fields
in
the
gateway
foo
policy
can
be
overwritten,
and
so
this
allows
policy
to
compose.
B
You
know
each
one
at
the
highest
level
gets
to
define
whether
you
know
they
are
having
something
that
can
be
overridden
or
not.
So
this
flexibility
it
allows
totally
arbitrary
configuration
to
be
applied
at
multiple
levels.
It
it
allows
it
to
compose
such
that
we
can
use
like
the
exact
same
policy
resource
at
multiple
levels.
B
Not
every
field
in
your
implementation
has
to
even
be
supported
at
that
level.
Like
there
may
be
an
instance
where,
like
you
know,
perhaps
for
your
implementation,
ssl
policy,
just
you
can't
configure
it
at
the
granularity
of
an
individual
service,
maybe
something
that's
only
can
be
configured
at
the
granularity
of
a
gateway.
That's
fine!
In
in
your
documentation.
You
would
not
allow
it
to
be
configured
at
other
levels.
It
would
be
basically
an
error
or
something
so
rob
if
you
go
to
the
next
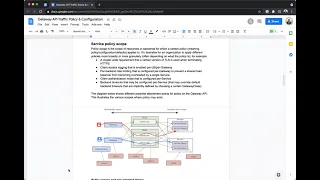
picture.
This
just
shows
a
diagram
of
what
this
all
looks
like.
B
So
yeah,
so
it's
basically
showing
there's
policy
fields
within
each
of
these
resources
and
it's
just
showing
how
they
all
compose
together
to
one
effective
list
of
you
know
configurations
that
apply
to
a
specific
service.
So
that's
the
gist
of
it.
I
think
it's
a
little
rough,
but
it's
just
one
proposal.
I
I
don't
know
you
know
very
many
good
ways
to
kind
of
achieve
all
the
goals
of
all
the
flexibility
we
need
without
also
totally
killing
the
ux.
C
Hey
mark
I
like
how
you
brought
up.
You
said
it's
like
a
christmas
tree
right
where
you
could
look
at
a
service
and
then
reference
the
service
policy
and
just
start
connecting
the
dots
from
there
right.
I
like
that,
brought
up
like
the
example
of
like
minimum
tls
and
so
that
you
know
as
an
implementer.
It's
something
that
I
thought
about
and
there's
I
believe
it's
the
options
field
and
the
tls
config,
where
it
is
meant
to
be
kind
of
like
implementation,
specific
options
that
can
be
passed,
and
I
always
thought
about.
C
You
know
using
that
for
contour
to
specify
things
like
minimum
tls
and
look
at
the
gateway
class,
and
you
know
it
references
the
crd,
which
is
meant
for
implementation,
specific
parameters.
I
just
mentioned
options
and
tls
config.
So
we
have
kind
of
all
these
different
extension
points,
and
I
just
wonder
if
we
need
to
go
back
and
like
look
at
these
use
cases
that
you
that
you
describe
as
use
cases
for
something
like
service
policy
and
maybe
circle
back
to
these
extension
points
and
say:
okay,
did
we
miss
something
here?
C
C
B
Yeah
and
now
one
thing
I
want
to
be
weary
of
is
not
to
turn
this
into
a
dumping
ground
for
all
configuration
because,
like
it
can
easily
just
become
this
massive
crt.
That
basically
has
everything
in
it,
and
you
know
like
the
this,
like
gateway.
Api
resources
have
a
very
structured
shape
because
they're
like
they're
built
for
the
specific
ux
of
the
use
cases,
which
is
like
configuring,
load,
balancing
and
like
I
I.
I
definitely
think
this.
B
Well,
then,
that
does
belong
in
tls
options,
because
that's
where
it
makes
sense
and
also
then
you
can
have
it
in
line,
which
is
always
an
advantage
to
have
it
in
line
as
opposed
to
another
resource,
so
yeah.
So
I
think,
like
the
more
the
more
ubiquitous
and
common
something
is
the
more
we
should.
Look
at
trying
to
keep
it
in
something
core,
but
if
that
just
can't
be
done,
this
is
a
way
to
give
us
that
escape
hatch,
to
really
kind
of
provide
that
arbitrary
configuration,
but
we
shouldn't
abuse
it.
B
A
A
Maybe
it
belongs
on
the
route
or
maybe
it
it's
something
that
should
be
a
default
for
the
entire
gateway
or
the
entire
gateway
class.
You
know
like
you,
you
could
make
an
argument
that
it
belongs
at
any
of
those
points
and
the
model
I
like
here
and
I'm
I'm
not
sure
you
know
again.
I
haven't
thought
about
this
enough,
but
the
idea
like
I
really
like
what
we
did
with
tls
right,
where
you
have
the
ability
to
set
something
like
on
gateway
and
then
to
allow
resources
south
of
it
to
override
that.
A
So
in
this
case
you
could
set
defaults
for
say
timeout
or
I
don't
know,
health
checks,
whatever
whatever
kind
of
things
might
be
included
in
this
kind
of
resource
and
then
override
them
at
lower
levels.
If
routes
differ
from
the
norm
or
if
back
ends
are
somewhat
different,
right
and
and
this
kind
of
structure
seems
like
it
could
be
applicable
to
more
than
just
implementation,
specific
policy,
but
maybe
even
you
know
like.
Maybe
this
replaces
what
we
have
for
back-end
policy
right
now.
D
D
B
Yeah
yeah,
we
can
hear
you
so
boy
yeah,
I
mean
I
agree
with
that.
It's
kind
of
like
this
is
if
this
is
the
extension
that
you
use
for
a
particular
configuration,
then
you
are
also
you
know:
you're
honoring,
the
fact
that
it
you
know
it.
It
has
to
apply
to
all
these
override
policies
and
things
like
that.
They
use
a
different
field.
It
doesn't
have
that
meaning,
and
so
you
don't
get
that
override.
We
could
also
use
like,
in
addition
to
like
third-party
crds,
to
represent
this
policy.
B
You
know
back
the
back
end
policy
could
basically
take
this
kind
of
form
as
well,
so
there
is
like
maybe
a
standardized
one
but,
like
I,
I
definitely
favor
in-line
stuff
as
much
as
possible
like
because
it
just
makes
it
easier
than
having
a
ton
of
different
resources.
So
wherever
we
can
put
things
in
line
in
a
core
resource
is
definitely
preferable.
If
it's
possible.
D
Yeah,
like
I
think,
going
back
to
my,
we
can't
simply
remove
those
extension
points.
Is
I
think,
those
serve
a
sort
of
a
slightly
different
purpose
like
if
you
think
about
filter,
it's
kind
of,
for
example.
Let's
say
we,
we
take
all
filters
and
replace
them
with
policy,
like
probably
95
percent
of
filters,
don't
make
sense
to
have
this
sort
of
inheritance
model
and
then
you'd
have
to
explain.
Well,
actually
you
can't
attach
it
at
the
gateway,
it
probably
doesn't
make
sense.
D
So
yeah,
the
the
two
do
serve
different
purposes.
Mark
yeah
is
there
in
your
proposal
how
to
display
the
compose
policy
to
users
like
what?
How
do
they
understand
that,
because
that
is
basically
the
killer
for
these
kind
of
models
and
like
the
best
thing
I've
seen,
is
your
css
debugger
in
your
browser?
That
tells
you
exactly
where
things
are
coming
from?
That's
that's
very.
B
Much
yeah,
no,
there
isn't.
I
mean,
there's
an
example
of
how
like
of
what
the
effect
of
policy
is
given,
I
think,
rob
there's
that
box.
That
shows
like
three
different
policies:
it's
like
a
nine
by
three
by
three
box
somewhere.
There
you
go
so
we
like
this
shows.
You
know
with
different
ones,
are
over
overriding
it
or
denying
the
override
at
different
levels,
and
it
shows
kind
of
what
the
effect
of
policy
is.
We
would
need.
B
D
Yeah
the
the
challenge,
I
think,
with
this
proposal-
and
you
know
it
does
make
sense
to
me-
is
like
how
much
how
much
do
we
need
to
say
explicitly
as
to
the
behavior
versus
the
underlying
system
has
a
particular
behavior
like?
Is
it
the
case
that
policy
composition
is?
We
can
write
generic
code
kind
of
like
how
the
validation
pr,
where
basically,
we
describe
the
the
resolution
like
100
like
it
is?
D
Obviously,
the
first
one
is
great,
because
then
we
can
just
fully
document
the
behavior
and
that's
that
the
second
one
is
like
well.
If
your
system
has
some
specific
implementation
that
if
it
understand
these
overrides,
for
example,
and
better
than
it's
better
performance
or
something
that
one's
always
challenging
when
building
these
portable
layers.
B
B
Policy
that
might
be
it
could
be,
I'm
just
brainstorming.
That
could
be
an
interesting
way
to
do
it
so
basically
yeah
like
it
would
show
you
the
effect
of
policy
at
every
level
so
like.
If
you
create
a
policy,
that's
referenced
from
a
service.
It
shows
you
the
effective
policy
at
that
level.
If
you
create
a
policy
resource
at
the
http
reference
from
the
hp
route,
each
the
status
shows
you
the
policy
at
that
level,
which
actually
would
be
different
than
the
service
level.
D
A
A
D
So
the
yeah
and
we
can
structure
a
status
to
kind
of
have
that
css
debugger
flavor.
What
was
I
going
to
say
shoot,
oh
right,
so
mark
as
part
of
this
proposal.
We
are
basically
saying
that
we're
going
to
stipulate
like
the
merging
happens
in
this
very
particular
way,
like
there's,
no
flexibility
about
that,
because
that
makes
it
easier
to
describe
to
users
but
might
of
course
people
are
going
to
be
like.
B
Yeah
I
mean
the
I.
I
think
the
goal
is
to
provide
really
black
and
white
merging
that
is
really
easily
understandable,
otherwise
we'll
get
into
a
kind
of
a
quagmire,
and
I
realized
that
one
I
haven't
really
addressed
kind
of
what
this
merging
would
look
like,
because
it's
not
clear
whether
it's
like
a
deep
murder
like.
Is
it
going?
You
know
if
there's
a
struct
inside
the
this
policy,
what
gets
merged
the
whole
at?
What
level
do
things
merge
and
I
think
that's
something
that
needs
to
be
discussed,
but
so
like.
B
Alternatively,
we
could
look
at
the
exact
same
proposal,
but
take
out
the
pulse,
the
override
part
of
it,
and
the
problem,
like
I
started
with
that
originally
and
the
problem
that
I
realized
is
just
that
if
you
happen
to
reference
the
same
field
in
multiple
layers,
there's
no
obvious
conflict
resolution
and
it's
an
easy
thing
to
do,
because
you
have
different
people
that
are
operating
on
the
gateway
or
the
route
or
the
service,
and
so
it's
not
like.
You
could
also
then
have
entirely
different
policy
resources
at
each
level.
B
A
Yeah,
I
agree
with
that.
I
think
there's
a
lot
of
promise
here,
but
I
guess
we
need
to
sketch
it
out
more
give
give
more
time
to
think
about
it,
but
I
I
was
really
interested
in
this.
I
wanted
to
make
sure
we
had
some
time
to
discuss
it
today,
because
a
lot
of
the
things
you
know
coming
up
on
our
agenda,
you
know
on
the
v
0.3.0
milestone
are
in
some
way
related
to
policy
or
where
they
might
fit.
A
C
And
really
quickly,
too,
I
mean
robbie
kind
of
bring
up
the
overlapping
he's
brought
up
the
back
end
policy
earlier
and-
and
I
do
I
mean-
that's-
definitely
a
concern
that
it's
like
the
amount
of
overlap
I
mean,
should
we
then
get
rid
of
back-end
policy?
If
we
proceed
with
service
policy,
I
mean
initially,
it
seems
like
that
would
be
the
case,
and
then
you
know
just
the
the
concern
I
have
of
the
extension
points
that
we
have
right
is
like
as
an
implementer
like.
D
Yeah,
I
think
we
should
definitely
write
out
like
what
makes
sense.
I
think
extension
points
to
me
are
very
like
physical,
like
the
filters
is
a
good
example
like
that
one
doesn't
seem
like
we
can
do
without.
Probably,
this
will
supersede
back
end
policy
because
they
serve
very
similar
purposes.
We'd
have
to
work
out
some
of
the
referencing
issues
of
which
direction
it
goes
in
who
controls.
D
A
Yeah,
I
think
the
the
big
issue
with
back
in
policy,
back-end
policy,
references
service
or
any
other
kind
of
back
end,
and
that's
you
know
all
we
can
do
because
it's
hard
to
add
a
field
to
service
or
other
resources,
but
it's
also
a
very
confusing
you
know
tree
or
lack
of
a
tree.
In
this
case.
It's
not
the
direction.
Users
are
really
looking,
and
so,
if
we
can
find
a
better
way
to
attach
at
that
level,
then
I
think
the
attachment
points
at
all
the
levels
we
do.
A
Control
like
routes
and
gateways
are
much
more
straightforward.
If
we
do
have
something
like
this
and
I'd
agree
like
filters
that
this
feels
very
separate
from
filters,
I
think
filters
are
very
good
extension
point.
We
all
we
do
have
some
other
extension
refs
throughout
the
api
that
this
may
overlap
with,
I'm
not
sure
but
yeah.
We
do
need
to.
D
A
D
One
thing
to
clarify
is
that:
is
it
the
case
that
if
you
use
one
of
these
policies,
it's
going
to
be
valid
in
all
of
so
mark?
Your
diagram
here
has
like
the
little
policy
decorators
at
every
layer
like.
Is
it
the
case
that
this
thing
means
that
it's
valid
at
every
layer
or
do
we
want
to
end
up
in
a
situation?
Well,
it's
like
this.
One
can
decorate
gateway,
but
actually
it
doesn't
really
care
about
inheritance
because
you
actually
can't
plug
it
in
those
places.
Other
places.
B
Yeah,
I
think
that's
I
think
every
single
implementation
is
going
to
have
configuration
that
is
only
supported
at
a
few
of
the
layers.
Some
will
be
like
one
layer
like.
I
think
your
point
about
filters
is
a
really
good
point,
because
filters
really
only
make
sense
exactly
where
they
are
right
at
that
one
place
inside
the
route.
B
You
know
we
we
get
the
benefit
of
having
like
a
single
uniform
resource
to
configure
this
policy,
so
you
don't
have
a
bunch
of
different
crds,
but
the
downside
is
the
individual
fields
in
that
resource
may
have
different
scopes,
upon
which
they're
supported
where,
like
some
things,
you
know,
are
supported
at
the
service
or
the
route
layer.
Some
things
maybe
make
sense
at
the
gateway
and
the
gateway
class
layer
and
the
route,
but
not
lower
than
that,
which
is
something
that
I
was
thinking
just
is
makes
sense
to
fix
through
documentation
through
the
implementation
documentation.
B
A
Yeah,
I
think
that
makes
sense
all
right
one
one
last
follow-up
on
here.
I
know
we've
spent
a
good
good
amount
of
time
on
this
dock
and
I
do
want
to
move
on,
but
I
I
wanted
to
make
sure
that
we
got
some
feedback
from
you
know
other
implementers
here
we,
we
obviously
have
our
own
ideas
of
the
kinds
of
policy
that
we
think
would
be
useful
to
attach
at
different
levels,
but
I'm
interested
in
in
you
know
what
other
implementers
are
thinking
about.
A
A
And
no
need
to
respond
here,
but
if
you
have
comments,
I
think
I
think
mark
you're
going
to
fall
file,
a
issue
to
track
this
as
well
on
gateway
api,
and
so
maybe,
if
we
can
just
have
more
of
a
discussion
there,
but
really
interested
in
what
others
are
thinking
about.
How
you
know
these
kinds
of
extra
details
that
may
not
fit
inside
core
can
be
attached
to
the
api.
C
And
I
didn't
jump
in
and
respond
right
away,
because
I
wanted
to
give
an
opportunity
for
others
to
jump
in,
but
of
course,
on
the
contour
side
to
have
myself
and
some
of
the
other
contour
maintainers
of
you
know,
we've
been
in
the
thick
of
things
with
the
implementation,
and
you
know
a
few
of
the
use
cases
mark
that
you
mentioned,
like.
I
said
I've
kind
of
thought
through
some
of
that,
like
using
the
tls
options,
field
and
tls
to
express
minimum
tls
versions.
C
You
know
some
of
the
connection,
timeout
settings
and
and
so
forth-
that's
been
in
the
back
of
our
minds,
but
I
think
again
it
hasn't
been
a
high
priority
right
now
because
of
other
areas
of
the
implementation
that
we've
been
focused
in
on,
but
yeah.
That's
just
an
extension
point
that
you
know
we
as
a
community
know
needs
to
get
addressed
and
it
you
know
we've
kind
of
just
gone
back
and
forth
like.
Where
is
the
right?
C
You
know
where's
the
right
place
in
the
apis
to
express
the
connection
settings
right
so
again
I
think
it's
just
it
really
be
helpful
to
kind
of
list
out.
Hey
here's
the
use
case:
here's
either
why
or
why
here's?
Why
or
why
not
the
current
apis
don't
support.
The
use
case
would
be
helpful
because
at
least
where
I'm
at
right
now
the
implementation,
the
extension
points
are
working
out.
But
again
you
know
we
still
have
a
long
way
to
go
in
the
contour
community
for
full
support
gateway,
yeah.
B
Yeah,
okay,
I
I
think
it's,
it's
really
good
feedback.
I'll,
add
a
section
of
stock
in
which
we
can
track.
You
know
the
types
of
things
that
are
appropriate
for
this
kind
of
generic
service
policy
and
things
that
are
maybe
better
suited,
for
you
know
more
specific
or
built-in
fields
within
the
gateway
resources.
E
Yeah,
I
think
we
should
make
sure
too,
that
we
don't
get
too
far
down
the
custom
resource
extension
point,
which
makes
us
even
more
different
between
each
other
between
each
implementation.
I've
heard
a
lot
of
folks
wanting
to
move
the
gateway
api,
saying
hey.
I
want
to
use
this
because
it
solves
my
problems
and
it's
generic.
It's
a
community
supported
thing,
but
then,
if
you
have
too
many,
I
don't
have
a
good
answer
for
it
either.
B
That's
a
really
good
point,
because
this
basically
just
becomes
like
slightly
better
than
annotations,
maybe
even
worse,
because
more
resources
and
like
if,
like
everything,
goes
into
them,
then
we've
kind
of
just
put
ourselves
in
the
exact
same
place.
Yeah
so
like
I
did,
I
yeah.
We
need
to
be
judicious
about
what
we
actually
put
in
here
and
try
to
push
as
much
into
core
as
we
can
given
like
that.
B
A
C
Yeah
evolving
the
back
end
policy,
and
we
already
have
a
couple
use
cases
there
for
the
next
generation
of
back-end
policy
that
we
potentially
call
service
policy
right.
What
it
supports
currently,
which
is
some
of
the
upstream
tls
config
right
along
with
potentially
adding
the
the
connection
settings
that,
as
a
use
case
mark,
brings
up
here,
yeah
yeah,
exactly.
A
A
A
A
The
other
one
is
one
that's
new
and
one
that
I
discussed
earlier.
It's
an
earlier
issue
that
I'd
kind
of
been
wanting
to
take
on
for
a
while,
and
maybe
the
best
way
to
explain
it
is.
If
you
look
at
our
if
you've
modified
docs
recently,
you
notice
that
we
have
a
really
flat
structure
and
that's
fine.
It's
worked
for
us
so
far,
but
you
can
imagine,
as
we
continue
to
extend
our
docs
and
hopefully
make
them
more
thorough.
A
This
lack
of
structure
is
going
to
get
pretty
frustrating.
It's
already
somewhat
frustrating
to
find
the
file
you
want
to
work
on.
So
my
idea
is
really
simple.
It
is
to
you
know,
update
that
directory
to
match
the
site
structure,
the
navigation
structure
so
just
put
things
in
folders
to
match
the
navigation
patterns
we
have
on
the
surface.
I
think
that
seems
really
straightforward.
A
D
A
I
was
concerned
about
that
just
like
internal
links
with
stock
that
there's
there's
a
lot
that
has
to
change
here.
I've
changed
a
bunch,
but
I'm
sure
there's
more
that
have
to,
but
the
the
thing
I'm
concerned
about
is
okay,
say
we
link
to
this.
What
this
link
would
become
is
contributing
slash
community
right
because
it's
now
nested
under
here,
so
I
don't
think
there's
too
many
external
sites
linking
to
anything
other
than
just
our
route.
A
So
I
think
this
is
an
acceptable
risk,
as
long
as
we
can
ensure,
I
think,
there's
some
tooling.
We
can
use
to
ensure
that
all
our
internal
links
still
work.
I
think
that's
the
majority
of
links
within
here,
but
that
is,
that
is
a
risk
for
anything.
We
know
that
might
be
linking
into
this
specific
doc
site.
A
C
Especially
you
know
if
we
get
this
done
before
kubecon,
because
I
think
that's
where
we're
going
to
see
a
jump
in
interest.
So
I
agree:
let's
do
it
now
I'll
I'll,
take
a
a
review
of
both
of
these
pr's
and,
let's,
hopefully,
get
it
merged
so
yeah
as
long
as
none
of
the
internal
links
are
broken,
I'm
all
for
moving
forward
with
this
pr.
A
Cool
and-
and
let
me
say
that
I
I
have
not
guaranteed
yet
that
all
internal
links
are
are
not
broken.
I
wanted
to
I
create
this
pr
and
then
rely
on
the
netlify
generated
content
to
actually
run
through
and
test
out
the
links
myself,
I
think,
they're
upstream
we
have
a
one
of
our.
Maybe
it's.
The
docs
website
has
something
that
checks
for
broken
links,
so
I'm
also
interested
to
see
if
we
can
try
and
copy
that
little
test.
So
we
don't
have
to
manually
check
these
every
time,
but
yeah
cool.
A
I
glad
to
glad
to
hear
that
this
is
reasonable,
and
hopefully
we
can
get
this
in
soon.
It's
it
feels
like
a
good
time
because
there's
not
any
huge
docs
prs
in
flight.
Obviously,
if
you're
going
to
make
a
docks
pr,
it
would
conflict
with
this
pretty
heavily,
because
this
is
moving
all
the
things.
But
hopefully
we
can
get
this
one
in
pretty
soon.
C
A
Yeah,
that's
a
great
point.
It's
definitely
something
that
I
I
want
to
at
least
look
into
before
this
pr
merges.
I
am
less
sure
of
what's
involved
because
I've
I've
just
seen
the
the
results
of
it.
I
can't
remember
if
it's
a
bot
or
if
it's
an
actual
like
pre-commit
hook
or
what
is
actually
implementing
it,
or
maybe
I'm
remembering
wrong,
but
that's
that
is
something
I
want
to
look
into
and
actually
understand,
and
hopefully
it's
it's
a
pattern
that
we
could
copy
here,
but
not
sure,
but
at.
A
Yeah
that
that
makes
sense,
I
think,
that's
the
most
reasonable
way,
because
I
still
do
have
a
follow-up
here
I
want
to
do.
I
want
to
either
make
sure
myself
that
all
the
links
I
can
find
are
not
broken
or
have
some
kind
of
automation.
Do
it
so
yeah,
I
think
that's
reasonable.
I
don't
think
we
need
reviews
right
away,
but
I
want
to
do
my
own
due
diligence
first
and
then
I'll
I'll
ping.
A
couple
of
you
to
see
if
you
can
review
it,
yeah
perfect,
all
right.
A
A
A
I
know
this
one's
on
me.
I
need
to
actually
do
a
little
bit
more
due
diligence
with
api
machinery
to
see.
If
there's
you
know
if
this
is
the
right
compromise
to
make.
As
far
as
adding
new
fields
to
populate
coop
cuddle
output
mark
this
getting
started
refresh
is
this:
are
you
waiting
on
review
on
this
one.
D
A
A
And
okay-
and
I
think
there
were
a
couple
issues
that
we
haven't
had
time
to
cover
yet
john
had
a
great
one
which
is
and-
and
I
experienced
this-
and
I
I
really
should
have
taken
some
time
in
this
in
today's
meeting,
because
I
I've
gone
through
all
the
current
implementations.
I
know
of
that
are
implementing
this
api
and
for
the
sake
of
the
kubecon
demo,
I
you
know
ran
through
using
all
of
them
and
it's
really
cool
first
to
see
them
all
working
and
working
well.
A
But
I
also
want
to
add
that
it's
interesting
to
see
the
little
differences
between
how
they're
used
so
as
an
example,
I
think,
contour
and
traffic.
In
their
examples
the
installation
includes
a
gateway
class
and
in
some
cases,
a
gateway,
whereas
istio's
installation
doesn't
include
a
gateway
class
or
a
gateway
and
gke
will
include
a
gateway
class
but
not
gateways,
obviously,
and
so
like
there's,
there's
differences
in
how
things
are
actually
bundled.
John
go
ahead.
Sorry.
F
Oh
yeah,
I
was
going
to
say.
I
think
that
what
you're
saying
is
also
very
interesting,
but
I
actually
was
not
talking
about
that
here.
What
I
meant
was
more
downstream,
like
the
grafana
helmchard
prometheus
home
chart.
All
these
other
helm
charts
just
normal
applications
today,
a
lot
of
them
ship
with
an
ingress
right.
F
So
you
can
easily
get
an
ingress
with
your
charge,
but
in
the
future
we
hopefully
will
have.
You
know
the
gateway
api
ship
with
them,
and
it
would
be
good
to
kind
of
explain
to
people
how
they
should
do
that.
I'm
just
a
bit
worried
that,
like
some
will
be
like
I'm
gonna
include
a
gateway,
and
maybe
they
shouldn't
be
including
a
gateway,
but
instead
of
route,
and
maybe
now
we
have
like
10
different
ways
that
people
do
like
the
route
selection
to
the
gateway.
F
A
F
A
F
A
Good
point:
okay,
cool
yeah
and
so
yeah.
I
guess
what
I
was
describing
is
entirely
different
here,
but
it's
it's
also
just
different
experiences.
When,
when
provisioning
or
installing
implementations
of
this
api,
it's
interesting-
and
I
don't
know
what
the
best
practice
is-
there,
either
cool.
Okay,
the
next
one,
multiple
route
filters
of
the
same
type
are
supported.
D
A
D
A
Okay,
cool
well
thanks
for
following
up
on
this
one,
I
know
we're
past
time
so
yeah
thanks
thanks
to
everyone
for
the
good
feedback
here
again
reminders.
Blog
posts
will
be
well
draft.
Blog
posts
will
be
coming
soon
for
review,
then
more
feedback
on
service
policy,
which
I
think
is
going
to
turn
into
an
issue
soon
for
tracking
and
yeah.
I
think
that's!
That's
it
thanks
to
everyone
for
the
great
feedback
here
and
we'll
talk
to
you
next.