►
From YouTube: Kubernetes SIG Apps 20190204
Description
No description was provided for this meeting.
If this is YOUR meeting, an easy way to fix this is to add a description to your video, wherever mtngs.io found it (probably YouTube).
A
Welcome
to
kubernetes
cig
apps
for
February
4th
2019
I,
just
shared
the
meeting
minutes
into
chat
and
so
for
February
4th
hi.
My
name
is
Matt
Farina
I'll
be
chairing
today
and
admins
here
as
well
he's
one
of
the
other
co-chairs
of
cig
apps.
So
you
got
two
of
the
three
of
us
today:
offer
the
announcements,
there's
one
that
I
added
a
feature
freeze,
so
a
feature
freeze
for
the
next
release
was.
A
Can
your
their
fantastic
feature?
Freeze
was
supposed
to
be
last
Friday
and
for
realsies
it's
today.
So
this
is
just
a
reminder
that
we
are
in
feature
freeze
right
now,
which
basically
means
that
whatever
you
have
needs
to
be
implementable,
if
you're
thinking
in
cat
forms
at
this
stage
of
the
game,
if
it's
going
into
the
next
release,
if
you've
got
any
questions
about
that,
please
feel
free
to
ask
but
we're
at
feature
freeze
and
then
with
that
we
are
up
for
our
demo.
Do
we
have
somebody
on
to
demo
this?
A
C
C
All
right
so
I
wanted
to
share
with
you
a
an
idea
that
I
have
implemented
a
few
months
ago.
I
am
a
consultant,
so
I
do
consulting
for
for
openshift,
which
is
just
the
reddit
distribution
for
for
kubernetes,
and
very
often
I
find
myself
in
conversation
with
my
customers,
where
they
are
not
comfortable
giving
ownership
of
some
of
the
namespaced
objects
to
to
the
end
developers.
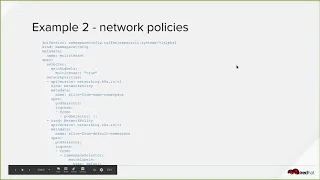
C
Okay,
so
and,
for
example,
I'm
talking
about
network
policies,
quotas
limit
ranges
and
this
this
type
of
object
that
are
a
little
bit
on
the
borderline
between
normal
workload,
type
of
workload,
objects
that
developers
normally
define
and
and
more
you
know,
administrative
and
configuration
type
of
objects,
and
so
we
given
that
problem
and
given
that
some
some
customers,
large
enterprise
financial
institution
they
would
they
want,
don't
want
to
give
control
over.
For
example,
fiber
rules
like
which
are
network
policies.
You
know
per
shift
or
quotas
or
limit
range
to
to
the
developer.
C
We
we
often
end
up
in
creating
provisioning
workflow
or
we
cut
some
time.
We
call
them
onboarding
processes
where
these
objects
are
defined
when,
when
the
namespace
is
first
created
and
handed
over
to
the
developer
team-
and
this
is
fine-
but
it's
a
little
bit
rigid
and
it's
also.
Oh,
the
enforcement
point
is
just
at
creation
time
and
that's
never
an
easy
way
to
check
that
the
configuration
is
maintained
in
the
future.
C
So
idea
is
just
to
solve.
This
problem
was
to
create
a
controller
or
an
operator
to
enforce
configurations
on
inside
namespaces
and
by
configuration.
I
mean
these
type
of
objects
that
a
little
bit
borderline
and
inside
inside
namespaces,
so
that
because
of
the
operator
control
loop,
this
configuration
and
constantly
enforced
and
and
then
it's
also
easy
to
pause,
multiple
configurations
inside
the
same
namespace.
C
C
Okay,
so
now
my
provisioning,
what
I
call
the
initially
the
provisioning
workflow
the
onboarding
process,
it's
simplified
because
I
just
need
to
be
able
to
set
labels
on
namespaces
that
are
created,
and
then
the
policies
or
this
configuration
will
be
applied
driven
by
those
labels
and
I
have
another
example
here,
for
example,
this
is
a
network
policy
type
of
configuration
in
a
multi-tenant
environment
we
by
default.
We
want
the
all
the
process
to
be
isolated
from
one
another.
This
is
the
assumption,
and
so
this
will
on
the
project
at
our
label
multi-tenant.
D
Had
a
similar
situation,
I'm
helping
a
customer
with
an
open
shift
environment,
and
we
also
had
a
similar
use
case
as
this,
so
we
wanted
our
tenants
to
be
able
to
provision
projects
themselves
as
well.
So
it
looks
like
in
your
process
flow
on
three
you're
still
having
cluster
admins,
create
these
projects
or
namespaces
for
tenants
and
labeling
them
appropriately
to
be
listened
to
by
your
controller.
Is
that
the
process
flow
currently,
for
you
know.
C
C
D
Okay,
I
see
so
yeah.
We
have
our
permission
split
up
by
LDAP
group
so
that
admins
tenant
admins.
We
call
them
have
the
ability
to
provision
projects
and
then
allocate
cluster
resource
quotas
to
sub
projects
within
that
tenant
environment.
But
we
wanted
to
make
sure
that
all
these
tenant
projects
are
created
with
a
standard
configuration
network
isolation,
as
you
talked
about
default
role
bindings
for
users
coming
in,
so
that
when
new
projects
are
created,
developers
automatically
have
edit
capabilities.
D
Because
well,
I'm
kind
of
running
as
the
sysadmin
ish
on
that
current
effort
and
I
don't
want
to
be
in
the
process
of
creating
projects
and
permissions
at
a
global
scale,
I'd
rather
delegate
that
responsibility
to
the
tenant
admins.
But
how
do
you
like
that?
Differentiation
between
keeping
it
from
the
cluster
admin
side
and
letting
them
dictate
what
our
network
Paul?
What
do
you
call
them?
C
I
think
that's
fine.
If
you
have
that
level
of
delegation
I,
think
overall
also
this
tenant
admin
they
could
use
an
automation
like
the
one
I
am
presenting
they
would
just
do.
This
configure
will
just
create
configurations
that
only
select
their
own
in
spaces
that
they're
controlling,
but
eventually
I,
think
I.
Think
the
value
here
is
that
these
configurations
are
not
just
created
and
set
at
the
beginning
when
when
the
namespace
is
initially
created,
but
there
is
a
controller
that
continually
enforces
them.
C
So,
for
example,
let's
say
that
let's
go
back
to
the
example
here
of
the
quota,
let's
say
that
we
decide
all
together.
That's
the
small
size
quota
now
shouldn't
just
be
for
CPU
and
gigabytes,
but
it
becomes
a
CPU
and
a
gigabyte.
I
can
just
come
here
and
change
these
objects
and
reapply
it,
and
it
would
be
automatically
applied
to
all
the
projects
that
were
under
that
configuration.
C
So
this
level
of
automation,
I,
found
it
to
be
difficult
to
achieve
when
you
have
when
you
have
this
policy
is
set
up
only
at
the
provisioning
time
and
then
and
that
everything
else
becomes
manual.
So
this
is
regardless
of
whether
you
you
have
the
cluster
and
mean
doing
the
provisioning
or
you
have
this
intermediary
tenant.
That
means
that
do
the
provisioning.
D
D
C
This
is
yeah.
This
is
a
very
interesting
question
now
when
I
was
thinking
about
this
problem,
I
was
thinking
about
one
one
cluster
at
a
time,
but
I've
been
recently
working
on
also
on
Federation,
right
and
any
of
multi
clusters
and
with
Federation
you
could
propagate
C
R
DS
relatively
so
you
could
propagate
these
dis
policies.
If
you
wanted
to
do
that,
I
just
haven't
explored
this
option.
E
Thank
you,
another
thought
would
be.
You
could
actually.
So
if
you
have
multiple
clusters
and
you
use
some
type
of
the
get
ops,
workflow,
2.2,
CR
DS
in
particular,
posit
or
E's-
maybe
the
same
CRD
if
you're
looking
for
a
uniform
configuration
across
clusters
or
otherwise,
you
should
be
able
to
actually
achieve
that
today.
Right,
like
you,
could
have
one
custom
as
long
as
the
controller's
installed
across
many
clusters.
E
If
you
have
one
resource
that
describes
the
default
behavior
for
configuring,
a
namespace
globally
across
all
of
your
infrastructure,
you
could
there
are
ways
to
apply
that
to
many
clusters
outside
of
the
scope
of
actually
doing
it
inside
of
kubernetes
itself.
That
would
provide
you
with
the
uniform
repeatable
behavior.
C
C
My
last
thought
is:
I
started
this
with
a
predefined
set
of
types
that
I
was
going
to
support,
which
are
listed
here,
because
these
were
the
ones
that
most
of
the
time
come
up
in
those
discussion
with
the
customers.
But
then,
when
I
was
implementing
the
code,
I
realized
I
was
writing
the
same
piece
of
code.
For
you
know
six
seven
times
for
each
of
those
types
so
I
was
wondering.
Is
there?
Is
there
a
better
way
to
to
do
like
generic
operation
on
an
object
on
okay
VI
objects?
So
it
turns.
C
F
C
E
C
I
actually
didn't
give
that
those
permissions
by
default.
So
if
you
want
to
be
able
to
do
those
type
of
things,
you
have
to
add
those
permission
to
the
service
account
running
there.
The
controller
yeah
I
thought
that
was
much
by
default
so,
depending
on,
if
you're,
using
or
binding
a
cluster
of
binding
objects,
depending
on
what
I'm
trying
to
do,
you
would
have
to
have
those
permissions
yep.
E
E
If
you
made
it
unstructured
and
work
on
a
generic
type,
how
would
we
manage
configuring
our
backup
appropriately
to
give
the
controller
the
permissions
it
needs
to
modify
the
objects
it's
configured
to
create,
or
would
you
have
to
just
grant
kind
of
broad
star
permissions
across
the
entire
cluster?
That
would
be
one
being
concerned
with
doing
something.
That's
any
type
now.
C
A
C
C
C
A
C
A
Yes,
actually
could
you
link
this
presentation
into
the
agenda
for
today,
I
see
that
you
linked
a
blog
post
in,
but
you've
got
some
useful
things
in
here,
such
as
a
link
to
the
git
repo
or
blog
post
repo
you've
already
linked
a
blog
post.
You
could
either
put
this
presentation
in
or
if
you
just
want,
also
link
to
get
repo
in,
so
people
can
find
it
whatever
you
want,
please
feel
free
to
add
it
to
the
notes
from
today.
Okay,.
C
C
C
A
G
G
Sure
so,
there's
going
to
be
two
different
options
that
we
have
keep
going
eeyew.
We
can
either
have
the
same
as
last
time,
which
was
an
intro
session
which
I
think
that
is
about
five
minutes
and
then
or
35
minutes,
maybe
and
then
also
a
35
minute
deep
dive
session,
or
we
can
put
them
together
and
have
a
single
session.
That's
18
minutes
long,
so
the
single
session
would
be
the
deep
dive
and
we'd
probably
have
kind
of
like
a
meet
and
greet
and
just
kind
of
open
discussion
about
various
different
topics.
G
G
So
I
think
I
can
give
my
personal
take,
which
is
that
I
think
that
in
the
past,
when
we've
had
the
longer
sessions,
they've
been
more
useful
and
we're
able
to
kind
of
have
just
a
longer
time
to
discuss
different
topics
and
people
can
kind
of
go
into
different
groups
and
discuss
different
things
also
provides
a
good
kind
of
time
to
meet
and
greet
so
I
personally
prefer
those
sessions,
but
but
I'm
interested
to
hear.
If
anyone
finds
the
intro
sessions,
you
saw.
A
A
E
Kind
of
agreed
whoa-
my
experience
has
been
this
when
we
do
the
intro
and
the
deep
as
deep
end
as
separate
things.
You
do
definitely
get
to
different
audiences
for
the
intro
and
the
deep
dive,
but
we
get
more
time
than
we
actually
probably
need
for
the
intro
and
I'm
for
the
deep
dive.
The
D
style
always
runs
long
and
well.
The
diet
always
ends
before
everything
is
finished.
I
guess
you
say
we
usually
need
more
time
for
in
the
intro.
Basically,
we
don't
usually
need
as
much
time
for
me.
Intro
speech
like
that.
E
G
E
E
A
A
All
right,
the
next
topic
that
we
have
up
here
today
is
the
CN
CF
SIG's.
Yes,
the
CN
CF,
the
parent
organization
of
kubernetes
and
Prometheus
and
helm
and
linker
D
and
G
RPC,
and
all
of
these
things
the
TOC
is
looking
to
introduce
special
interest
groups,
and
so
nobody
was
surprised,
and
everyone
sees
how
things
relate.
I
thought
it
would
be
a
good
idea
to
kind
of
talk
about
some
of
that
here.
So
I'll
go
ahead
and
share
that
document.
A
Just
a
moment
there
we
go,
please
let
me
know
when
you
can
see
my
screen
quick.
Is
it
all
right?
So
this
is
the
final
draft
of
the
document.
That's
in
work
that
describes
the
SIG's.
It
has
been
worked
on
over
a
period
of
law,
as
you
can
see
several
months
to
try
to
figure
out
the
the
purpose
of
this
and
and
right
at
the
top.
It
says
it
is
to
scale
the
contributions
to
the
CN
CF
and
and,
quite
frankly,
the
TOC
has
a
lot
of
responsibility.
A
That's
the
technical
Oversight
Committee
of
the
CN
CF.
They
have
a
lot
of
responsibilities
from
identifying
new
projects
that
need
to
come
in
to
looking
at
just
cloud
native
and
all
of
this
and
they're
all
very,
very
busy
people,
and
so
they've
been
trying
to
figure
out.
How
do
you
get
working
groups
and
groups
of
people
around
particular
topics
and
so
far
they've
had
four.
A
For
example,
there's
been
a
CI
working
group,
there
has
been
a
server
list
working
group
that
created
cloud
events
as
a
spec
from
it,
which
is
one
of
the
CN
CF
projects.
And
how
do
you
do
that
and
the
organization
around
the
original
working
groups
was
very
loose,
and
so
they
said,
how
do
we
create
working
groups
version
two
and
that
kind
of
morphed
into
SIG's
special
interest
groups
modeled
a
little
bit
on
kubernetes,
except
the
one
big
important
caveat.
These
SIG's
have
no
authority
over
any
of
the
projects
themselves.
A
A
Here's
the
link
to
that
document,
and
so
basically
the
objective
is
to
strengthen
the
ecosystem,
identify
gaps
in
the
CNC
F
portfolio
like
what
should
be
working
on
next.
Where
are
there
holes
in
cloud
native
that
there's
nothing
there
for
that
the
CNC
F
doesn't
have?
Maybe
nobody
even
has
educate
and
inform
users?
That's
a
big
thing
right
now
is:
how
do
we
get
good
information
out
there
to
different
kinds
of
end
users?
A
A
So,
if
you're
talking
about
lured
the
infrastructure
like
where
something
like
a
rocket
and
container
D
and
those
things
fit
what's
just
going
on
in
that
space
in
general,
what's
happening,
what
are
projects
doing
both
or
C
and
C
F,
and
on
C
and
C
have
projects.
This
is
to
also
to
inform
the
TOC
to
have
expert
decisions.
Things
like
that
perform
project
discovery
and
outreach
on
any
candidate
projects
and
then
help
those
projects
when
they
present
to
the
TOC
and,
of
course,
one
of
the
big
things
here
is
actually
perform.
A
Health
checks
on
CN
CF
projects
for
some
things
like
kubernetes.
That's
not
a
real
big
deal
for
some
of
the
other
CN
CF
projects,
actually
finding
the
health
of
those
and
getting
information
on
those,
and
maybe
looking
at
where
they're
struggling
to
help
reinvigorate
them
is
an
actual
concern.
But
this
is
kind
of
their
scope.
When
it
comes
to
the
projects,
then
they
get
into
end-user
communication,
which
is
outbound.
How
do
you
educate
end
users
on
what's
going
on
here,
and
you
see
things
like
presentations
and
white
papers?
A
Some
of
the
stuff
is
very
similar
to
what
we've
done
here
in
cig
apps
over
time,
but
it's
all
about.
How
do
you
go
out
to
the
world
and
show
the
value,
the
processes,
the
tools
things
like
that
to
help
people
understand,
and
a
lot
of
this
is,
if
you
look
at
the
technology
adoption
lifecycle
kubernetes
is
still
very
early
on,
especially
when
you
look
at
enterprises
and
a
lot
of
what
we
know
here
and
what
we
know
around
kubernetes
space
and
things
like
that
is
tribal
knowledge.
A
It's
not
written
down
and
communicated
well
enough
yet,
and
so
if
we
want
to
unboard
more
people,
if
that's
the
idea
of
educate
out,
then
there's
the
whole
idea
of
inbound
communication,
which
is
gather
all
of
this
information.
We've
talked
about
and
look
at
sharing
it
up
and
sharing
it
out
to
some
of
the
projects
like.
How
do
you
get
case?
Studies
pain,
points,
details
from
end
users
and
then
share
those
with
the
particular
projects,
whether
it's
kubernetes
or
link
or
D,
or
you
know
just
different
projects
to
say,
hey.
A
How
do
you
share
these
things
out
and
there's
actually
some
other
things
going
on
now
with
the
end
user
group,
which
is
another
part
of
the
C
and
C
F
of
people
who
don't
produce
services
or
products
but
just
consume
all
this
stuff?
We're
gonna
be
able
to
tie
into
those
through
the
C
and
C
F,
and
then
how
do
you
share
this
around,
but
it's
stuff
like
this
and
there's
community
enable
meant
you
know
all
the
good
words
and
then
just
kind
of
run
those
meetings
and
have
those
responsibilities.
A
This
is
kind
of
the
scope
of
it,
which
is
similar
to
ours
and
they've
got
the
operating
model
here,
which
is
loosely
based
on
what
kubernetes
does
they've
had
chairs
tech
leads
things
like
that
elections,
governance,
all
the
fun
stuff
right,
but
work
it's
interesting
and
I
just
scrolled
to
it
is.
If
you
look
at
the
the
first
group,
o6
SIG's
that
they're
suggesting
this
started
off
as
far
more
than
ten,
and
they
said
how
do
we
collapse
this
down
and
get
smaller
and
smaller
and
smaller
to
something
they
can
start
with?
A
You'll
actually
see
one.
That's
app!
Dev,
ops
and
testing-
it's
very
similar
to
what
we
have
here
and
it
has
you
know
things
like
telepresence
we've
had
demoed
here,
build
packs,
I,
don't
know
that
we've
talked
much
about
cloud
events
we've
in
the
past,
we've
talked
a
ridiculous
amount
about
home,
a
CNC
FCI
if
you're
not
familiar
with
this
CNC
FCI
actually
looks
at
if
it'll
load
how
things
are
running
in
different
CI
systems
and
by
the
way
this
is
not
widely
shared.
A
Yet
it's
the
cross
cloud
CI
approach,
but
they're
trying
to
get
CI
running
in
all
of
these
different
environments.
For
many
of
the
projects
that
needed
or
wanted,
and
a
lot
of
when
you
see
things,
failure,
it's
it's
just
a
failure
to
get
things
up
and
running
smoothly
right
now.
It's
not
saying
the
projects
failing
or
the
infrastructure
is
failing
or
things
don't
work,
it's
more
complex
than
that
and
getting
a
particular
testing
environment
running
everywhere.
Just
isn't
easy
and
that's
what
that
group
does.
A
But
that
is
also
one
of
those
things
that
they're
they're
talking
about
being
in
there,
although
that
may
be,
since
it's
more
infrastructure,
a
something
that
needs
to
live
elsewhere,
but
this
is
all
tentative
and
so
they're
looking
at
here's
the
projects
that
it
would
be
looking
at
the
health
of
and
overseeing
in
just
that
kind
of
space.
This
is
alternative,
probably
to
be
discussed
at
the
next
meeting,
which
I
think
is
tomorrow.
A
Maybe
finalize
and
get
that
going,
and
so
this
is
one
of
those
things
where
we'll
probably
want
to
look
at
kubernetes,
see,
gaps
and
see
and
CFC
gap,
dev,
ops
and
testing
and
see
where
there's
an
overlap
and
see
how
we
we
move
forward
with
that.
Does
anyone
have
any
thoughts?
I
didn't
share
everything
in
here,
I
know
most
of
what's
in
this
document.
E
A
Perfect
so
they
report
up
to
the
TOC.
They
are
a
support
group
for
the
TOC,
all
their
authority.
Anything
that
they
do
is
based
within
the
TOC
realm
right
and
they
will
not
be
making
decisions
on
projects,
whether
it's
new
projects
coming
in
or
anything,
but
they
may
provide
guidance
and
expert
guidance
to
people
on
the
TOC
and
the
TOC
may
use
it,
reject
it
do
what
they
want
with
it.
A
It's
really
the
TOC
is
the
the
body
in
this
place
as
far
as
the
things
that
they
produced
a
lot
of
it
is
to
provide
for
education
and
things
like
that
and
reference
architectures
stuff,
like
that,
like
one
of
the
that's
been
talked
about
a
lot
and
I'm,
not
sure
where
it
governance
is
where
I
felt
in
was
some
of
the
security
stuff.
How
do
you
do
good
security
practices
for
dealing
with
things
like
in
your
cluster,
who
gets
access
to
what
and
then
what
kind
of
practices
are
people
doing?
A
And
how
do
you
communicate
that
so
people
are
coming
on
board
can
see.
What's
going
on
right,
it's
user!
That's
access
management!
How
to
use
our
back
well
stuff,
like
that?
That's
one
of
the
things
that's
been
discussed.
In
fact,
there's
been
a
proposed
CN
CF
working
group
for
a
while.
That's
been
just
meeting
in
doing
this
and
they're
looking
at
the
kinds
of
materials
and
education,
and
things
like
that
that
they
want
to
share
out
to
the
world
just
to
say
here
are
good
practices
based
on
things.
A
E
E
A
E
A
No,
no,
these
are
wonderful
questions,
so
the
tech
lead.
One
is
one
that
I
also
poked
at
because
I
said
why
you
you
don't
own
a
technical
thing
in
any
particular
area.
What
what's
the
purpose
of
the
tech
lead
and
and
really
the
whole
idea
was
the
role
of
a
tech.
Li
requires
a
different
set
of
skills
from
chairs,
and
sometimes
you
have
people
who
sometimes
it's
different
chairs
kind
of
have
to
wrangle.
People
deal
with
action,
items
and
organizational
things,
and
there's
lots
of
people
like
this.
A
At
the
TOC
and
CN
CF
level
who
are
willing
to
wrangle.
Things
are
expert
meeting
Wranglers
right,
but
then
they
need
technical
people
who
I
don't
think
a
lead
is
the
right
word
because
they're
not
leading
the
technology,
but
they
are
experts
in
it
who
can
be
pulled
in
and
do
reviews
and
say
I'm
I'm
willing
to
guarantee
time
to
look
at
these
projects.
A
I
can
talk
in
depth
on
the
technologies
and
the
reasons
and
the
patterns
and
all
of
that
stuff
and
there's
places
where
people
with
that
expertise
are
known
and
they
want
them
to
be
able
to
say.
I
will
regularly
commit
just
showing
up
and
doing
these
technical
reviews
of
things
and
that's
where
the
tech
lead
comes
in
I,
don't
think
the
lead
is
really
because
you're
not
actually
leading
anything,
but
that's
the
name
that
they've
chosen.
This
was
one
that
I
still
think
I
don't
know
right.
A
There's
a
specific
community
and
those
are
all
people
from
different
companies.
In
fact,
if
you
go
look
at
the
CN
CF
website
and
you
go
to
people,
you
will
see
the
end
user
community
and
this
is
just
any
end-user.
Although
I'll
argue,
you
should
look
at
all
the
end
users,
these
are
actually
companies
that
pay
to
be
part
of
the
end-user
community
of
kubernetes
and
support
the
CN
CF.
A
A
They
do
things
different
ways
and
whether
there's
a
right
process
or
a
long
process
or
many
right
processes
or
many
wrong
processes,
is
something
that
people
that
all
these
companies
love
to
argue
and
one
of
the
things
that
they
want
to
foster
out
of
this
is
that
one
companies
or
organizations
way
of
doing
things
doesn't
overly
dominate
what
they
say
can
or
should
be
done
to.
Let
many
companies
who've
done
many
different
processes
have
the
ability
to
have
those
incorporated
in
it
and
then
let
other
people
make
the
call
on
what's
right
for
them.
A
That's
kind
of
a
philosophy
of
not
letting
somebody
dominate
on
the
way
to
do
things
when
there's
actually
a
bunch
of
people
who
think
there's
a
bunch
of
different
ways
and
because
they're
organized
around
company
unit,
that's
kind
of
how
they
want
to
ensure
that
diversity
of
that.
If
that
helps
provide
the
background,
for
it
can.
B
I
interject
please
thanks.
I
agree
with
kanan's
comment,
but
I
think,
maybe
in
a
different
context,
I
think
just
the
terminology.
It
seems
like
an
unfortunate
like
it's
fine
if
they
have
a
focus
of
what
you
just
described,
but
but
defining
that
as
diversity
might
be
confusing
to
some
people
and
I
am
one
of
those
people.
It's
seems
to
think
that
Helen
wording
is
wrong.
I
would.
E
Say
that
if
we
want
to
have
reasonable
discussions
about
diversity
in
the
CNC
F
for
the
kubernetes
community
and
you
bring
those
around
employer,
that
really
throws
out
any
legitimacy
to
having
a
discussion
about
diversity
based
on
the
modern
understanding
of
what
diversity
in
the
workplace
needs.
So
I
would
definitely
braid
that
differently
and,
like
kind
of
seek
to
communicate
that
we
want
to
not
have
a
dominant
of
any
one
company
and
opposed
to
doing
it.
The
other.
A
Way
so
so
let
me
suggest
this:
okay
I
was
involved
in
the
writing
of
this
document
in
certain
sections
of
it.
Now
there
were
a
whole
lot
of
people
involved
in
writing
this
and
so
along
the
process
I
actually
pushed
back
and
gave
my
two
cents,
such
as
you
question
the
terminology,
slightly
I
did
that
as
well.
A
Now
you
see
how
far
my
two
cents
went
with
it
because
they
have
it
anyway,
so
my
suggestion
would
be
is
to
either
come
to
the
CN
CF
meeting
or
jump
on
the
toc
mailing
list
or
give
feedback
in
that
capacity.
Well,
I
would
love
to
carry
it.
The
things
that
have
come
up
here
are
things
that
I
know
that
I
can't
carry
and
have
influence
in.
But
if
more
voices
were
to
come
along
from
different
people
and
suggest
these
things,
then
there
might
be
that
ability,
but
I
can't
actually
carry
these
particular
issues.
A
B
Me
I
agree
with
the
things
you
said
Matt
and
like
instead
of
having
like
us
individually,
try
and
come
like
it
might
make
sense,
I
think
there's
other
people
who
feel
this
way
as
well.
Just
like
we
could
get
a
group
of
people
together
that
all
show
up
together
at
the
same
time
and
say
yes,
this
is
like.
We
all
feel
this
way
in
my
do
you
think
that
would
have
the
or
maybe.
A
Now
you
all
know
Quentin,
so
I
would
also
suggest
maybe
tying
off
with
him
on
this,
because
Alexis
has
been
very,
very
busy
lately
and
he's
the
one
who
started
this,
but
Quentin
has
had
room
to
carry
this
kind
of
to
the
completion
and
so
that
ability
to
have
squish
and
and
influence
and
that
it's
all
going
through
him.
So
if
you
have
time
between
now
and
tomorrow,
I
would
suggest
maybe
trying
to
tie
off
with
him
on
it
as
well
and
see
what
he
thinks.
Okay,.
B
A
Don't
have
a
month,
I
don't
have
a
month.
So
let
me
let
me
check
real
quick.
So
by
the
way,
that's
the
last
toc
meeting,
which
was
several
weeks
ago
now,
like
three
weeks
ago,
there's
been
two
weeks
in
between
is
when
this
all
this
curation
happened
was
between
those
meetings
based
on
this
stuff.
There
have
been
other
ongoing
meetings.
The
last
meeting,
where
all
of
this
really
happened
and
really
got
cleaned
up
and
got
showcased
was
last
Tuesday.
A
So
this
is
actually
the
first
sick
apps
meeting,
since
this
happened
and
I
think
they're
moving
alexis
was
moving
to
get
it
quickly.
Sorry
I'm
looking
for
the
TOC
agenda
to
see
if
it's
on
the
meeting
that
it's
for
tomorrow
but
I,
think
they
wanted
to
get
it
moving
very
quickly,
but
I'm
also
not
sure
how
the
meeting
is
gonna
go
because
they
also
wanted
this
to
be
a
handoff
between
the
old
projects.
There's
an
old
TOC
and
the
new
TOC
and
I'm
not
sure
how
the
timings
gonna
end
up
working.
It
is
on.
A
So
the
agenda
is
a
graduation
announcement,
the
election
and
everything
to
do
with
the
election
and
they're
electing
a
new
chair
and
everything
to
do
with
that.
Okay,
so
they're
they're
electing
a
new
chair
and
going
through
that
process
and
they're
going
to
talk
about
that.
And
then
there
is
this
CN
CF
SIG's
and
that's
the
the
three
things
on
the
agenda
for
tomorrow.
So
I
don't
know
that
there
is
much
time.
A
A
Then
the
last
thing
that
I
had
on
here
and
again
I
added
this
one
and
it
actually
came
out
of
the
helm
discussion-
was
the
CR
D
version.
Lifecycle
management,
workflows
in
helm.
We've
been
talking
about.
How
do
we
manage
CR,
DS
and
we've
had
some
interesting
cases
come
up.
For
example,
cert
manager
will
say
we
have
a
version
will
just
say
v1
alpha
1
and
we
want
to
go
after.
A
This
has
been
deployed
in
a
cluster
update
it
and
change
descriptions
or
change
validations
on
the
same
version
right
they're,
gonna
change,
some
of
those
things
which
becomes
of
course
interesting
problems
when
you're
dealing
with
management
in
different
ways,
because
CR
D
is
our
cluster
wide
right.
So
if
you
deploy
something
in
and
maybe
you've
got
to
namespaces
to
people
doing
two
different
things,
and
now
you
want
to
update
that
one
person
from
one
side
wants
to
update
that
that
impacts.
Somebody
else
is
stuff
running
in
the
same
cluster.
A
It
kind
of
gets
into
this
whole.
How
do
you
manage
not
just
install
but
then
manage
versions
and
things
like
that?
What
kind
of
patterns
need
to
happen?
Interesting
timing
is,
this
is
come
up
in
the
sega
architecture.
It
looks
like
this
was
one
of
the
topics
that
we
were
hoping
to
talk
about
last
week
and
there's
a
doc
with
a
proposal,
although
I
don't
have
access
to
this
dock
yet
because
it's
not
in
public,
I'm
quested
access.
A
Oh
sorry,
I
got
access
while
we
were
chatting
here,
and
so
how
do
we
go
about
doing
that
and
before
we
want
to
do
anything
in
helmand,
I'm
sure
any
other
tool
does
we
should
probably
figure
out?
How
do
we
manage
CR
DS
inside
of
kubernetes?
What's
like
the
right
way
to
do
that?
Install
upgrades
deletions
your
basically
your
crud
operations
when
it
affects
multiple
things
across
the
cluster,
and
so
we
wanted
have
a
conversation
or
start
that
about
what
do
we
do?
Where
do
we
go
right.
E
Now
do
not
delete
the
RV's
unless
you
want
to
make
all
of
the
resources
that
are
defined
by
that
definition
suddenly
disappear,
break
everything
in
your
cluster.
If
deletion
is
not
really
an
option
right
now,
now's
a
great
time
for
people
who
are
interested
to
get
involved
in
the
conversation
around
CRD,
versioning
and
CRV
conversions,
I'm,
pretty
sure
the
current
implementations
still
utilizes
mutating
web
hooks
in
order
to
implement
the
conversions
for
the
CID
on
the
API
server
side,
we
can
talk
about
I,
guess
what
the
envision
the
workflow
for
that
is.
A
E
Would
be
the
same
thing
to
do
potentially
changing
validation
in
a
way
that
doesn't
invalidate
prior
objects,
but
with
only
a
malady
things
that
don't
yet
exist
would
be
safe
to
do
the
way
it
would
work
in
practices.
You
have
to
implement
a
resource
definition
at
a
new
group
version
and
install
that
and
then
do
a
conversion
to
that
and
separate
validation.
That
new
group
version,
which
I
think
is
also
a
less
traumatic
way.
E
The
same
we
took
the
same
things
that
were
the
challenges
about
building
types
and
we
can't
get
out
of
them
when
we
started
doing
custom
versions.
So
there
are
ways
to
do
an
update
like
prescriptively
I,
wouldn't
say.
The
only
safe
thing
to
do
is
again
to
create
a
new
group
version
where
the
semantics
are
changed
and
then
implement
a
converting
weblog.
That
goes
between
the
two,
but
remember
just
like
with
the
built-in
types
there
is
a
rule
that
that
has
to
be
strict.
There
has
to
be
strict
battle:
compatibility
between
the
two
versions,
gif.
E
Again,
these
rough
edges
cases
providing
feedback
now,
particularly
from
what
the
challenges
using
a
helm
in
order
to
do
things
like
update
or
potentially
installed
to
Helen
charts
that
have
different
versions
of
the
same
crd
or
installing
a
Helen
chart.
That
depends
on
another
at-home
chart
where
you
have
base
plates,
but
so
you
can
install
two
home
charts
that
both
depend
on
different
versions
of
the
same
CRT
like
what
looks
like
to
do
it
in
the
same
place.
A
It's
any
of
the
tools
that
are
out
there
and
flows
out
there,
because
you
may
have
to
people
who
don't
even
know
about
each
other,
doing
things
in
two
separate
namespaces
and
maybe
they're,
just
even
deploying
their
own
entirely
raw
resources
in
there
and-
and
you
know,
maybe
they're
both
installing
raw
cert
manager
or
trying
to
leverage
it
and
having
to
deal
with
this.
It
just
ends
up
becoming
very,
very
difficult
with
API
versions.
E
One
of
the
convert,
the
other
conversation
is
kind
of
going
on.
Right
now
is:
do
we
need
some
notion
of
what
namespace
to
resource
definitions?
You
have
to
remember
the
concept
of
a
custom
research
definition
is
I'm,
going
to
teach
the
API
machinery
to
talk
about
a
new
resource
and
implicit
in
that
is
sort
of
like
the
person
who's
modifying
what
the
API
machinery
is
capable
of.
E
Processing
is
a
cluster
administrator
that
doesn't
work
well
for
everybody's
organization,
in
particular,
if
your
model
of
tenancy
revolves
around
namespaces,
and
you
have
many
teams
who
are
acting
kind
of
in
an
administrative
way
inside
of
my
main
space
right
and
then
you
have
the
division
of
a
resource
definition,
which
is
only
the
cluster
scope
and
if
you
clear,
there's
no
definition
of
a
namespace
custom
resource
definition.
A
these
are
clusters,
field
object
by
people,
and
this
isn't
even
bringing
into
the
difficulties
in
terms
of
our
back
with
respect
accessing
the
resources
defined
by
it.
E
Rightly
there's
a
lot
of
saying
the
API
server
machinery
and
we
custom
use
cases
is
still
very
very
complicated.
I
mean
the
only
thing
we
see.
People
be
successful
with
usually
held
in
conjunction
with
this
is
the
administrator
flow
for
creating
custom
resources.
It's
still
separate
from
what
you're
putting
inside
the
home
chart
and
then
held
in
charge
of
depends
only
on
the
custom
resources,
themself
right.
E
F
A
Become
a
new
beta,
yeah,
so
everything's
still
in
working
in
flux,
so
yeah,
that's
what
I'm
trying
to
also
figure
out
is
is
what's
what
are
the
good
guidance
here,
because
people
are
already
doing
this
stuff
upstream
and
how
they
want
to
share
things
and
tell
people
do
with
other
applications,
and
they
all
need
general
guidance
right
now.
So
it's
also
for
to
authors,
people
who
are
sharing
their
applications
with
each
other,
because
they're
building
third-party
applications
to
install
on
everyone's
clusters.
F
Honestly,
I
think
the
simple
guidance
is
you?
Don't
you
see
armies
unless
you
own
the
cluster
or
you
just
to
be
beautiful
cluster,
because
in
any
other
way
you
are
automatically
religious
like?
If
how
many
is
granted
privileges
to
create
customer
service
definitions,
it
means
any
user
can
do
that
and
you
are.
You
are
bumping
into
the
movie
attendance
issues
that
would
have
been
parented
by
the
Arabic
setting
appropriate
well.
B
F
I've
been
talking
with
you,
make
sure
you
get
those
namespace
yardies,
but
the
state
right
now.
People
are
misusing
CR
for
cases
when
they
just
won't
structured
config
for
their
application.
It's
not
extending
the
cross
to
that,
basically
make
it
structured
up
with
something
that
makes
you
that
forces
you
to
be
Custer
admin
which
is
wrong,
but
yeah
and.
E
Not
only
you
have
to
be
able
to
have
administrator
privileges,
so
you
have
to
be
able
to
create
cluster
scoped
objects
in
particular
sphere
at
ease,
but
the
power
to
do
that
is
useful
without
having
elevated
privileges
to
control
arm
at
your
rules
to
grant
access
to
those
series
which
means
either
being
able
to
create
cluster
rule
linings
or
roll
bindings
and
generally
the
whole
line.
Is
you
have
to
do
it,
one
of
her
name,
space
bases,
which
means
you
probably
also
have
to
be
able
to
create
the
principles
that
are
associated
with
those?
E
A
E
I
mean
this
is
something
that's
already
kind
of
been
discussed
in
API
machinery,
as
well
as
big
architecture.
So
it's
not
like
we'd,
be
starting
a
new
conversation,
but
for
people
who
are
interested
in
in
the
direction
that
this
heads
and
trying
to
shape
it
participating
in
the
conversation
would
be
something
you
want
to
do
like
soon
real
soon.
A
Yeah,
okay,
whoo,
okay,
so
we
can
follow
up
and
chase
down
folks
in
sig
API
machinery
and
the
sig
architecture
space.
To
talk
about
this.
If
there's
anybody
else
interested
in
these
problems,
let
me
know,
but
CRTs
are
being
massively
used
in
the
wild
for
lots
of
different
use
cases
and
it's
become
an
app
problem
because
lots
of
apps
are
using
this,
and
so,
if
we
want
something
different
out
of
them,
we
need
to
give
them
guidance
and
we
need
to
hear
the
use
cases,
because
this
is
just
kind
of
how
they're
doing
things.
E
Do
this
and
the
largest
people
that
have
problems
with
this
are
running
it
on
bare
metal
and
they
are
using
namespaces
they're,
trying
to
run
largest
clusters
using
namespace
tenancy
right
and
they
wanted
their
visual
teams
to
have
these
permissions
and
that
becomes
a
nightmare
for
them,
the
most
part,
but
the
way
that
this
gets
approached
and
the
problem
that
we
need
to
solve
isn't
necessarily
a
hundred
percent
clear,
but
yeah
I
mean
you
should
get
more.
People
involved
in
the
conversation
for
sure,
make
sure
other
people
z/28
hard
on
this.
So.