►
From YouTube: CVE-2018-1002105 post-mortem
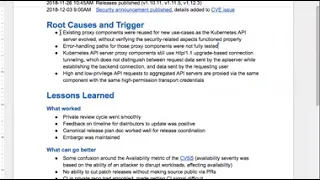
Description
CVE-2018-1002105 post-mortem
See https://github.com/kubernetes/kubernetes/issues/71411 for details
A
A
This
document
that
we're
going
to
be
reviewing
has
already
been
constructed
and
reviewed
by
the
people
who
participated
in
the
incident
and
those
gonna
be
gonna,
be
reviewing
the
document.
Muttering
questions
read
questions
feel
free
to
add
them
to
the
doc
or
call
them
out
on
the
call,
and
we
can
discuss
them
and
then,
after
this
call
we'll
be
publishing
publishing
this
document
as
a
PDF
links
to
from
the
website
somewhere
all
right,
so
I'm
going
to
just
start
reviewing
this
and
feel
free
to
interrupt
with
questions
and
we'll
go
from
there.
A
So,
just
to
summarize
what
the
issue
was,
there
was
a
vulnerability
that
allowed
TCP
connection
reuse
for
connections
that
were
proxied
through
the
API
server
to
back-end
servers
and
the
to
escalation.
Paths
that
were
known
were
through
the
API
server
to
aggregated
api's
and
then
through.
The
API
server
to
cubelets
in
particular
calls
through
the
accuser,
her
to
aggregated
API
servers
could
be
exercised
via
discovery,
api's
that
were
by
default,
permitted
to
anonymous
users.
A
There's
a
link
to
the
github
issue
that
really
dives
into
a
lot
of
the
details
about
which
particular
versions
were
affected,
which
particular
configurations
so,
if
you're
interested
feel
free
to
follow
that
link
and
find
out
more.
But
hopefully
most
people
are
familiar
with
that
by
now
jumping
down
to
the
timeline
for
the
incident,
the
bug
was
first
reported
publicly
against
the
rancher
component.
A
Actually,
they
made
use
of
the
API
server,
and
some
users
noticed
that,
when
load
balancers
would
speak
to
the
API
server,
this
TCP
connection,
reuse
vulnerability
would
actually
manifest
as
a
bug
we're
connected,
we
get
stuck
open
and
the
load
balancer
would
reuse
it
and
then
get
error,
error
responses
that
didn't
make
any
sense.
So
it
sat
as
a
bug
report
for
a
few
months,
while
they
were
trying
to
figure
out
what
was
going
on
with
it.
A
You,
the
following
day
a
second
proof-of-concept
exploit
for
the
anonymous
upgrade
attack,
was
produced
and
so
that
lengthened
the
review
process
to
make
sure
that
all
of
the
all
of
the
ways
that
this
could
be
exploited
were
understood
and
that
we
knew
what
the
severity
was
before
we
moved
forward.
The
following
day,
the
fix
was
the
review
was
completed
and
CI
tests
in
the
Private
Security
repository
were
green,
with
the
fix
so
in
to
end
integration
and
unit
tests
were
passing.
A
A
Revealed
that
the
proxy
components,
the
particular
component
that
had
the
vulnerability
had
existed
since
kubernetes,
100
and
originally
was
used
for
pod,
exec
and
port
forward
and
then
later
was
used
for
additional
proxy
use
cases,
specifically
the
aggregation
when
that
was
added
in
the
1
6
1
7
time
frame
those
components.
The
test
cases
were
primarily
focused
on
making
sure
that
the
function
that
they
were
used
for
worked
correctly,
and
so
the
tests
were
primarily
positive
tests,
not
testing
error
conditions
or
negative
tests.
A
And
finally,
the
the
method
used
to
transfer
authentication
information
from
the
API
server
to
backends
is
secured
via
mutual
TLS
connection
and
both
high
and
low
privileged
API
requests
are
proxied
in
the
same
way,
which
allowed
a
low
privilege
request
like
a
discovery
request
via
the
discovery
API
once
that
dropped
down
to
a
TCP
connection
to
be
reused.
To
make
high
privileged
requests
like
mutating
API
requests.
A
Most
of
the
most
of
the
lessons
learned
were
around
the
actual
review
and
release
process,
and
so
I
wanted
to
jump
down
to
some
of
the
action
items
that
came
out
of
the
technical
root
causes
before
we
go
through
some
of
the
existing
feedback.
So
some
of
the
issues
that
have
been
opened
either
to
investigate
changes
or
to
lock
down
existing
behavior.
A
Another
item
is
to
lock
down
the
upgrade
protocols
that
we
allow
to
the
ones
that
we
expect
so
specifically
use,
maybe
in
WebSockets
a
lot
of
these
are
kind
of
been
done
in
parallel.
If
we
switch
these
HTTP
two
that
would
remove
the
need
for
locking
down
the
upgrade
protocols,
but
something
like
HTTP
2
switch
is
likely
to
take
longer
because
of
deprecation
policies
and
maintaining
api
compatibility,
and
so
we're
looking
for
ways
to
reduce
our
surface
area.
B
A
In
addition
to
specifically
testing
air
conditions,
fuzz
testing
could
possibly
have
helped
catch
some
of
these
things
like
I
mentioned.
This
was
originally
reported
as
a
bug
that
was
encountered
in
the
wild,
and
so
it
was
possible
to
trigger
with
act
and
with
accidental
requests
and
so
fuzz
testing
that
would
have
triggered
an
air
condition
in
the
back
end
could
possibly
have
detected
that
it
wasn't
being
handled
correctly.
A
In
the
interest
of
the
attack
surface
available
to
unauthenticated
requests,
there's
an
issue
open
to
investigating
narrowing
which
endpoints
are
allowed
to
anonymous
users.
Currently,
unauthenticated
requests
are
allowed
to
obtain
health
information,
which
is
basically
an
up
or
down
signal
at
the
API.
Server
is
healthy
version,
information
and
discovery.
Information,
health
and
version
are
likely
to
continue
to
be
allowed
because
those
are
frequently
used
by
load
balancers
that
don't
have
the
ability
to
authenticate,
but
those
are
much
better
understood.
A
A
A
A
Alright,
that
is
the
end
of
the
technical
action
items.
The
remaining
ones
are
around
communication
and
the
release
process
itself,
and
so
I'm,
going
to
jump
back
up
to
the
lessons
learned
section
I
do
want
to
pause
there,
just
if
there
are
questions
about
any
of
those
action
items
or
other
other
points
that
people
wanted
to
raise
on
the
technical
side
before
we
continue.
A
A
A
A
The
private
review
and
testing
win
smoothly.
That's
good!
That
hasn't
always
been
the
case.
The
timeline
that
was
provided
to
distributors
to
test
and
release
the
fix
within
their
distributions
feedback
was
that
the
timeline
was
reasonable.
It
was
particularly
tricky
just
given
the
time
of
year
and
that
holiday
freezes
and
Black
Friday,
and
things
like
that
were
in
play
and
so
trying
to
navigate
those
in
addition
to
getting
the
fix
out
as
quickly
as
we
could
and
making
sure
it
made
it
into
one.
Thirteen
as
well.
A
All
right
so
some
things
that
we
got
feedback
on
that
could
have
gone
better.
Not
all
of
this
was
publicly
visible,
but
the
initial
announcement
to
distributors
had
a
cbss
score
that
was
high.
It
was
still
critical,
but
it
didn't
consider
the
ability
to
impact
workloads
availability
via
this
vulnerability,
and
so
we
had
a
follow-up
that
increased
that
score
to
the
one
that
is
in
the
public
issue.
Now
we're
still
trying
to
figure
out
how
to
map
some
of
the
metrics
for
these
vulnerabilities
to
the
cbss
score,
given
that
different
configurations
might
be
differently
affected.
A
The
public
releases
were
still
cut
publicly
so
on
the
26th.
The
fix
that
had
been
tested
and
reviewed
and
given
to
distributors
was
opened
into
the
public
repo,
and
then
there
was
a
time
delay
of
several
hours.
While
that
merged
and
see
I
ran
and
build,
artifacts
were
produced
and
rpm
and
Debian
packages
were
built
and
pushed.
We
would
still
like
to
shorten
the
window
from
when
a
fix
is
publicly
visible
to
when
they
really
started
backs
are
available.
A
This
was
a
minor
issue
but
see
I
in
the
private
repo
continually
atrophies
and
because
we
aren't
continuously
cutting
security
releases.
Thank
goodness,
it
means
that
when
we
do
jump
into
the
private
repo
to
do
this,
it
was
usually
ci
fixes
that
need
to
be
made.
So
that
delayed
us
about
a
day.
If
you
look
at
the
timeline,
the
review
completed
on
the
6th
and
it
took
us
until
the
7th
to
get
green
CI
I
was
trying
to
get
that
working
again.
A
While
we
were
cutting
the
releases,
the
patch
managers
for
the
three
releases
are
in
drastically
different
time
zones,
and
so
there
was
some
coordination
difficulty
around
making
sure
that
we
weren't
making
him
stay
up
until
midnight
just
to
cut
a
release.
And
so
there
was
some
handoff
issues
there
that
we
worked
through,
but
required
a
little
bit
of
scrambling
at
the
last
minute.
A
This
was
more
public-facing.
If
you
look
at
the
public
issue,
seven
one
four
one
one
and
look
at
the
number
of
times
the
the
description
of
that
was
edited.
The
initial
announcement
and
text
tried
to
lay
out
which
versions
and
which
configurations
were
impacted,
but
a
lot
of
questions,
kind
of
revealed
that
there
was
confusion
about
that,
and
so
part
of
this
was
because
there
were
two
escalation
pads
with
two
different
permission:
levels
that
affected
two
different
version
ranges.
So
the
cube,
cubelet
pod,
exec
attached
path
affected
all
the
way
back
to
one.
A
There
are
also
questions
about
which
versions
were
vulnerable
for
users
that
are
using
commercial
distributions,
so
not
consuming
the
open
source
release
artifacts,
but
consuming
something
from
a
commercial
vendor,
and
so
some
of
the
follow-up
items
for
that
were
to
be
sure
that
we
include
very
concrete
steps
for
determining
if
a
cluster
is
vulnerable,
not
necessarily
proof
of
concept
exploit.
But
if
you
look
at
the
what
we
ended
up
with
in
the
description,
but
we
ended
up
with
was
a
lot
more
specific
than
the
original
text.
A
Additionally,
the
rancher
developers,
once
they
figured
out
what
the
issue
was,
had
fixed
the
issue
in
a
patch
again
without
reference
to
the
security
implications,
and
so
we
found
ourselves
in
kind
of
the
odd
position
of
pre,
disclosing
the
security
issue
to
distributors
and
giving
them
a
patch
that
was
essentially
already
available
publicly
elsewhere.
And
so
we
couldn't
in
good
conscience,
say
that
the
patch
was
embargoed,
but
the
security
implications
of
the
patch
were
embargoed,
and
so
we
got
feedback
that
that
was
difficult
to
understand
and
some
very
security-conscious,
distributors.
A
Probably
you
went
overboard
in
how
cautious
they
were
to
the
point
of
not
even
giving
their
team's
the
patch
that
we
had
sent
them
because
they
didn't
want
to
break
embargo,
and
so
we
we
definitely
heard
the
feedback
that
the
communication
with
distributors
needs
to
be
very
explicit,
very
clear.
You
may
do
this,
you
may
not
do
this,
you
may
produce
builds,
you
may
not
produce
builds.
You
may
install
those
builds
in
hosted
environments.
You
may
ship
builds
to
end-users,
whatever
is
or
is
not
allowed
under.
A
Another
point
of
feedback
was
that
coordination
between
distributors
was
difficult
again.
People
were
being
very
conscientious,
which
is
greatly
appreciated,
but
in
cases
where
there
were
two
distributors
that
were
both
on
the
pre
disclosure
list
and
also
have
shared
customers
or
installations,
it
wasn't
clear
how
they
were
supposed
to
coordinate
on
the
issue
while
under
embargo.
And
so
one
of
our
action
items
is
to
make
sure
that
there
is
a
communication
channel
for
distributors
on
the
pre
disclosure
list
to
to
coordinate
prior
to
embargo.
Lifting.
A
This
last
last
bit
is
probably
not
interesting
to
anyone
except
the
product
security
team,
but
again
things
atrophy
and
since
the
last
time
we
had
a
security
release,
some
of
the
channels
that
we
announced
things
on
had
changed.
So
the
kubernetes
users
group
got
archived
and
the
discuss
forum
got
created
and
we
didn't
have
posting
permission
to
the
right,
the
right
places
in
the
forum
or
the
announcement
slack
channel,
and
so
it's
kind
of
inside
baseball,
but
making
sure
that
the
people
who
are
supposed
to
send
out
announcements
have
permission
to
do
so.
A
And
if
we
jump
down
to
the
follow-up
items,
some
of
the
things
around
process
that
were
wanting
to
take
into
consideration
having
multiple
patch
managers
per
release,
which
is
something
the
release
team
sig
release,
had
already
plans
to
do
for
114,
which
is
great
having
having
backups
for
that
is
great
spreading.
Those
across
time
zones
would
be
even
better
if
possible,
and
so
that's
being
added
to
the
things
to
consider
when
picking
patch
release
managers,
some
follow-up
items
to
simplify
and
clarify
how
the
distributors
announce
list
is
maintained.
A
B
A
software
that
uses
kubernetes
that
happens
to
be
like
you
know,
be
visible
in
some
way
or
you
don't
I
mean
like
some
faster
channel
for
not
like
I,
think
if
it
was
like
not
specifically
forth
security,
but
for
bugs
in
general
that
with
some
security
people
looking
on,
there
might
be
kind
of
a
faster
channel.
If
that
makes
sense,
yeah.
A
That's
an
interesting
question:
I
I!
Don't
so!
If
you
look
at
our
our
dependencies,
we
actually
do
monitor
our
dependencies
for
security
vulnerabilities
but
kind
of
going
the
the
other
direction
and
saying
oh,
this
thing
is
built
on
top
of
kubernetes
and
encountered
a
bug
that
maybe
look
suspicious
I
I.
Don't
think,
there's
any
monitoring
of
that
the
volume
that
that
would
involve,
probably
isn't
tenable.
Given
the
current
number
of
people
who
are
watching
these
issues
of.
B
Course
I'm
just
thinking
about
it,
like
you
know,
in
the
parallel-
and
you
know
if,
like
if
kubernetes
and
all
of
its
all
of
the
platforms
that
use
it
we're
part
of
one
company,
this
type
of
thing
would
be
flagged
by
support
right
support
would
go.
Oh
somebody
reported
about
me.
Actually,
maybe
this
is
something
that
is.
You
know
actually
belongs
in
a
different
component
right
and
then
those
channels
and
discovering
security
things
quicker
right.
A
A
One
of
one
of
the
other,
the
other
dimension,
is
across
like
the
kubernetes
product
project,
not
just
in
Zig
off
or
this
product
security
team.
We're
looking
at
the
process
that
changes
to
kubernetes
goes
through,
so
the
the
kept
process,
kubernetes
enhancement
proposal.
Looking
for
specific
questions
and
evaluation
of
security
impact
of
changes
so
trying
to
make
sure
that
this
is
something
that
everybody
in
the
project
is
considering
as
they're
making
changes
or
working
on
issues,
and
so
that
dimension
is
trying
to
improve.