►
From YouTube: Kubernetes SIG Azure community meeting 8-9-2017
Description
http://bit.ly/sig-azure for the agenda and notes
A
All
right
welcome
everyone
to
the
azure
special
interest
group.
It
is
August
9th,
2017
and
I
am
pleased
to
see
you
here.
If
you
would
like
to
see
the
meeting
minutes
for
this
meeting,
they
are
available
at
bit.
Ly
/.
Cig
azure,
probably
should
make
that
an
aka
Ms
URL
at
some
point,
because
that's
sort
of
what
we
do,
but
for
now
it's
still
bitly
/
sig
azure.
A
B
B
A
ton
I
guess
is
up
to
the
interpretation
of
the
beholder,
but
for
the
for
the
purposes
of
the
API
that
serves
all
of
these
underlying
infrastructure
resource
requests,
it
has
determined
that
that's
a
ton
of
traffic
over
a
certain
amount
of
nodes,
I'm
going
to
use
a
hundred
as
a
kind
of
simple
demarcation
point
for
you
know
below
that.
We're
not
considering
that
a
large
cluster.
B
It's
actually
not
quite
that
simple,
but
if
you're
building
100
node
200
node
300
clusters,
what
you're
going
to
notice
is
that
your
kubernetes
clusters
are
going
to
generate
a
lot
of
traffic,
just
reconciling
a
various
resource
bits
and
when
new
infrastructure
needs
to
be
scaffolded,
then
those
requests
are
dispatched
to
the
azure
API
and
at
a
certain
point
the
azure
API
thinks
it
might
be
being
da
stand.
So
it
will
respond
with
certain
types
of
throttle.
Later
429
responses
that
will
D
optimize
your
cluster
and
under
certain
conditions,
actually
make
it
unusable.
B
So
what
we
did
to
address
that
is,
we
introduced
into
the
cloud
rider
code
itself
in
upstream
kubernetes,
some
backup
responses
to
these
API
requests
and
also
rate
limiting,
and
so
these
are
all
configurable,
often
options
by
default,
they're
disabled,
so
it's
backwards
compatible
for
the
pre-existing
cloud
provider
implementation
with
when
we
deliver
this
feature.
It's
it's
an
opt-in
flag
and
additionally,
there's
a
the
the
vector
at
which
we
sort
of
support.
This
usage
is
our
ACS
engine
project
inside
as
or
so
I
suspect.
A
few
of
you
guys
know
about
ACS
engine.
B
The
best
way
to
put
it
in
a
way
it's
an
SDK
for
standard
SLA,
supported
API
calls
between
the
sort
of
high
level
API
s
and
low
level.
Libraries
that
actually
are
responsible
for
dispatching
requests
in
an
azure
compatible
way.
Another
sense:
it's
actually
you
can
compile
it
and
run
it
as
a
CLI
to
generate
your
own
templates
and
create
custom
cluster
configurations.
So
the
latter
thing
that
I
just
described
is
kind
of
how
we
wanted
to
address
customers
who
are
building
large
clusters
and
who
wanted
this.
B
B
A
great
question,
so
it's
in
one
six
stick
so
actually
I've
got
in
my
screen
share
here,
the
PR,
the
original
PR
for
this
and
I
actually
don't
know.
If
there's
a
decoration
commentary
here,
it
looks
like
it's
not
in
the
comments,
but
this
this
original
PR
went
out
with
one
six.
Is
that
right
case
I
getting
that
right?
B
B
Cool,
so
a
quick
demo
of
ACS
engine,
which
is
again
what
I'm
going
to
use
as
the
kind
of
user
vector
to
build
the
cluster
configuration
that
includes
these
features
and
give
myself
a
template
that
I
can
then
dispatch
to
a
sure
API
for
building
a
large
cluster.
So
I'm
going
to
go
over
here
to
my
vs
code
window
and
look
at
we
call
an
API
model.
This
is
really
simple
terms.
Just
a
representation
in
according
to
an
you
know,
an
ad
your
specific
interface
of
how
your
cluster
will
be
configured
for
ACS.
B
So
the
important
things
are
yes,
Jason.
Can
you
would
you
please
in
picking
the
font
in
bigan
eyes?
Yeah?
Is
that
as
simple
as
this
all
right?
So
the
big
version
of
thought,
which
should
be
readable
now
so
to
keep
the
key
points
are
as
was
asked.
This
is
a
this.
Is
the
the
kubernetes
version
that
we
want
to
specify?
B
So
there's
a
lot
of
description
in
the
docs
here
we
have
when
we,
when
we
merge
all
this
usage
into
a
chess
engine.
If
you
go
to
Docs
and
kubernetes
large
clusters
that
mark
down
you'll
see
a
more
persistent
description
of
this
I'm
still
going
to
walk
through
it,
but
for
those
who
conclude
that
I'm
going
too
fast
at
the
end
of
this
discussion,
you
can
go
to
this
document
and
it
has
some.
It
has
a
really
good
actually
doesn't
have
the
anyway.
B
B
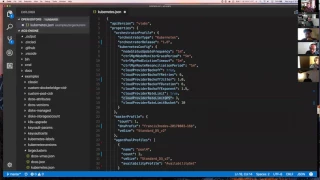
This
is
the
initial
duration
seconds,
and
this
is
the
exponent
that
the
algorithm
uses
to
determine
success
of
retry
attempts
so
normal.
If
you
like,
we're
thinking
like
vanilla,
exponential
back
out
to
the
power
two
would
be
that
and
then,
if
you
wanted
to
really
say,
try
once
and
I
really
trusted.
If
it
doesn't
succeed,
I
don't
want
to
try
for
a
long
time
using
like
that
and
then
the
second
feature
I
mentioned
is
a
rate
limiting
feature.
B
So
if
you
set
this
to
true
in
your
API
model,
you
can
this
is
going
to
be
in
line
for
several
specific
API
type
requests.
So
basically
what
we
determined
the
kinds
of
API
requests
that
are
most
likely
to
be
side
effects
of
normal
cluster
behavior,
that,
in
a
large
cluster
configuration
result
in
a
lot
of
traffic.
So
these
go
through
this
rate.
When
you
opt
into
this
feature,
all
of
these
requests
go
through
this
rate.
Limiting
enforcement
logic,
so
QPS
is
what
it
sounds
like
and
bucket
is
basically
a
buffer.
B
So
if
your
QPS
in
such
a
three
and
you
send
a
forth
request
in
the
fifth
request,
etc,
it
will
fill
that
buffer
until
it
runs
out
of
bucket
units,
after
which
point
those
requests
will
simply
be
dropped.
So
that's
how
that
works
and
again,
if
you
read
the
PR,
the
code
is
actually
pretty
clear.
These
are
not
novel
implementations,
they're,
they're
copied
from
or
reused
I
should
say
from
existing
well
used,
backup
and
rate-limiting
libraries,
okay,
going
still
going
real,
quick
anybody
has
chat.
B
B
This
is
a
couplet
configuration
parameter
that
determines
how
often
nodes
check
in
with
the
master
agent
nodes
check
in
with
a
master
with
standard
sort
of
health,
heartbeat
type
information.
The
default
for
most
recent
versions
of
kubernetes
is
ten
seconds.
I.
Think
a
long
time
ago
was
five
seconds
and
it
was
increased
to
ten.
B
So
by
setting
this
to
one
minute,
what
you're
actually
doing
in
practice
is
D
optimizing
your
kubernetes
clusters,
reconciliation
loop-
if
that
makes
sense,
so
there's
their
side
effects
of
nodes
checking
in
less
frequently
with
the
master,
one
of
which
is
going
to
be
a
reconciling
where
pods
should
be
so
the
master
is
responsible
for
doing
that,
and
it's
going
to
reschedule
pods
to
what
it
determines
a
an
offline
node
is
only
after
it's.
This
threshold
has
been
exceeded
and
the
node
hasn't
checked
in
after
that.
B
So
by
setting
this
to
one
minute
from
ten
seconds,
you
are
going
to
increase
by
50
seconds
more
or
less
when
those
types
of
events
occur.
So
it's
definitely
something
to
be
aware
of
another
going
through
these
three
control
manager
configurations.
This
is
related
and
this
is
going
to
determine
when
a
note
actually
goes
to
not
ready.
So
this
on
the
control
manager
says,
in
effect,
if
I
haven't.
If
five
of
these
intervals
have
passed,
then
I'm
actually
going
to
mark
that,
though
it's
not
ready.
B
This
is
a
pod
eviction,
timeout,
referring
to
my
first
example
off
the
top
of
my
head.
I'm
not
gonna,
be
able
to
explain
it
exactly,
but
it
basically
has
to
match
these.
All
these.
These
values
have
to
mass
match
reasonably
to
make
sure
that
your
reconciliation
loop
doesn't
get
into
a
permanent
race
condition
where
it
never
reconciles.
So,
we've
published
some
examples
and
there's
some
other
resources
to
look
at
for
this
kind
of
thing
when
you're
tweaking
these
values.
B
B
B
B
B
B
B
C
It's
not
ACS
engine
specific,
it's
really
just
more
for
people
deploying
using
vanilla,
but
at
least
they
would
have
the
equivalent
they
don't
have
to
go
and
search
for
all
these
configs
to
what
do
they
need
to
turn
on
to
have
the
same?
The
same
configuration
apply
on
the
Clifton
little
bit
thing
great.
A
Okay,
so
moving
along
thanks
for
the
demo
Jack,
that's
great,
so
I
wanted
to
point
out
works
in
progress
right
now,
there's
a
link
in
there
to
a
plan
about
Windows
server
container
stats.
If
we
won't
go
through
that
necessarily
in
this
meeting,
but
I
would
ask
that
if
you
could
just
take
a
look
at
that
and
give
feedback
if
you
feel
that's
appropriate,
this
is
a
really
interesting
proposal
and
I
think
it
looks
good.
So
please
do
that.
A
I
below
that
you'll
see
all
the
open
PRS
currently
assigned
to
cig
Asher
and
I
also
would
request
that
people
review
those
and
and
help
make
sure
that
they're
staying
current
I
would
really
like
to
set
a
norm
for
our
sig,
if
possible
in
the
future,
we're
essentially
at
least
one
sig
meeting
per
month.
We
go
through
and
knock
out,
or
at
least
try
and
knock
out
as
many
issues
and
PRS
as
possible,
so
that
we're
not
introducing
a
lot
of
debt
into
each
release
cycle.
I.
A
So,
let's,
let's
set
the
example
and
have
a
really
nice
clean
backlog
in
our
own
group
as
much
as
possible
below
that
you
will
see
PRS
meeting
review
and
attention
the
first
one
came
through
cig,
Asher
slack
channel,
and
this
is
somebody
who's
been
doing
a
lot
of
work
and
a
lot
of
questions
and
stuff
and
the
channel,
and
they
put
up
this
pull
request
and
I
just
wanted
people
to
take
a
look
at
it
to
be
done.
So
he
gets
some
attention
and
I.
A
Don't
I,
don't
really
have
the
chops
to
necessarily
comment
on
it,
but
I
would
love
for
you
all
to
take
a
look
and
make
sure
that
it
gets
some
attention
either
a
thumbs
up
or
thumb
down,
so
that
we're
not
sitting
on
top
of
that
code
and
the
remaining
two.
So
is
there
anybody
who's
representing
either
of
these
any
of
the
remaining
pull
requests?
That
wants
to
speak
to
these
or
speak
to
what
you
need
for
help.
A
All
right,
so
that's
a
no
on
that.
Please
take
a
look
at
those
at
your
leisure
in
in
sort
of
backing
up
what
I
said
moments
ago
about
making
sure
that
we
look
through
our
issues
right
below.
The
next
section
is
an
answered
issues,
meeting
intention
review.
These
are
issues
that
aren't
getting
traction
so
in
some
cases
specific
people
on
the
community
of
called
out
its
meaning
to
contribute
to
these
or
some
they
just
need
general
help.
A
E
E
So
so
I'm
bringing
this
up
to
the
community,
because
this
is
a
request
from
customers
that
on
AWS,
so
on
AWS
the
ELP
when
it
gets
created
a
low
balance
there,
the
code,
what
it
does
is
like
it
creates
a
name
out
of
it
out
of
the
service,
and
the
name
is
based
on
the
UID
of
the
service.
So
in
other
words,
the
name
that
is
given
to
the
ELB
is
a
big
massive
hash.
E
So
it
gets
very
difficult
for
customers
to
find
out
which
of
their
a
of
these
are
being
used
for
which
service
and
for
which
kubernetes
clusters,
because
they
just
have
a
whole
bunch
of
hashes
on
the
elby's.
Now
they
do
have
tags
that
define
that,
but
just
by
looking
at
them
a
very
bad
name.
So
instead
we're
we
are.
E
It
still
follows
the
same
rules
as
before
starts
with
the
first
letter,
as
TC
requires
is
only
32
characters
WS
requires
and
those
the
only
restrictions
over
there
before.
So
those
restrictions
are
still
there,
I
still
backwards
compatible,
but
those
annotations
please
make
sure
that
it
is
compatible
with
your
with
the
cloud
provider.
A
E
A
E
A
A
Okay,
so
moving
along
I
think
we've
hit
the
unanswered
issues.
Work
it
there.
So
quick
bit
about
releases
really
status.
1.8
is
post
feature
freeze,
so
there's
some
work
and
I'm
actually
meeting
with
the
people
working
on
Windows
rc3
coming
up,
but
essentially
there's
there's
a
certain
amount
of
work.
That's
going
to
be
coming
in
for
the
windows,
containers
and
whatnot,
and
also
wonders
networking.
A
So
you
can
have
multiple
pods
connecting
multiple
containers
in
the
pod
connecting
natively
through
the
networking
system
in
Windows.
That
work
is
being
done,
but
that's
not
a
not
consider
a
feature
because
basically
the
the
work
that's
going
to
be
done
for
Windows
nodes
is
considered
parody,
work
and
not
necessarily
feature
so
just
if
you're
interested
in
tracking
that
work.
A
It's
good
to
note
that
that
will
be
not
in
the
features
repo
that
will
actually
be
under
PRS
for
parity
code
freeze
for
the
1.8
releases
coming
on
September
1st,
the
actual
1.8
release
time
is
going
to
be
set
in
September
27th
and
we're
going
to
be
hopefully
cutting
some
alpha
soon.
So
if
you
want
to
poke
around
with
it
that
we
create
the
the
challenge
there
is
that,
in
order
to
cut
an
alpha,
all
the
tests
infrastructure,
the
blocking
tests
need
to
be
green
and
so
far
that's
an
almost
unobtainable
state.
A
So
we
are
working
on
trying
to
do
that.
Then
part
of
that
is
coming
from
upgrade
tests
which
are
notoriously
nasty,
so
stay
tuned,
I'll.
Let
you
know
if
there's
now
for
coming
out.
So
if
you
want
to
poke
around
with
the
ekn
1.73
or
1.7
dot,
three
was
out,
as
of
last
week
same
with
16.8,
we
had
an
ACF
engine
release
of
Odette
5.0,
and
that
is
exciting
for
you
to
take
a
look
at
there's
a
lot
in
there.
A
C
Updates
on
the
cloud
provider
separation,
so
I've,
like
we've
seen
in
the
PR
like
this
person
on
Flag,
which
made
some
changes
in
the
Asia
top
provider.
We
know
it's
going
to
be
branched
out
and
work
differently.
So
with
the
status
here,
can
we
still
work
on
augmenting
the
cloud
provider
upstream
or
there's
a
hard
cutoff,
a
code
freeze?
We
should
not.
We
should
stop
so
what's
the
status
on
this
migration
right.
A
Now,
I'm
working
on
getting
engineering
resources
within
Microsoft
to
start
coding
out
a
at
least
a
alpha
version
of
what
the
external
cloud
provider
would
look
like
right
now,
the
the
cloud
working
group-
that's
that's
sort
of
overseeing
that
work
from
the
procedure.
Standpoint
has
not
gotten
very
far
so
I'm
I'm
I'm
wondering
if
it's
going
to
slip
another
release
for
a
beta
for
that.
So
regardless
we're
taking
it
very
seriously
and
we're
going
to
be
setting
up
some
engineering
researches
around
it.
So.