►
From YouTube: Kubernetes WG Batch Weekly Meeting for 20220707
Description
No description was provided for this meeting.
If this is YOUR meeting, an easy way to fix this is to add a description to your video, wherever mtngs.io found it (probably YouTube).
B
B
C
B
B
D
D
Before
going
to
the
cloud
native
site
was
hpc
and
basically
we
used
a
lot
basically
in
high
performance
computing.
We
we
have
similar
problems.
What
people
have
to
deal
with
in
kubernetes
nowadays,
so
we
are
having
distributed
computing
and
a
lot
of
the
workloads
are
processed
in
a
pet
shop
manner
and
there
are
different
solutions.
How
to
do
the
scattering
and
resource
management,
and
very
popular,
of
course,
is
learn.
So
I
thought
it
would
be
a
nice
kind
of
think
to
share
what
was
done
in
hpc
with
the
community
here.
D
D
D
D
If
you
compare
it
to
to
other
tools,
I
don't
know
how
big
kubernetes
is,
for
example,
but
it's
quite
compact
for
the
tasks
what
it
has
to
do
with
and
very
efficient.
If
you
have
used
it
in
the
past
on
the
hpc
systems,
you
most
probably
aware
that
the
two
can
scale
to
thousands
of
nodes
basically
can
submit,
or
you
can
run
jobs
on
thousands
of
nodes
and
basically
the
deployment
time
or
the
time
to
start.
D
The
job
usually
on
such
kind
of
clusters
is
within
a
minute
what
I
heard
in
the
past.
So
it's
really
quite
optimal
solution,
so
you
can
find
details
more
about
the
the
actual
software
in
the
link
below.
But
I
tried
to
capture
some
key
points
and
give
you
some
overview.
What's
learned
this
and
can
do.
D
D
We
got
in
the
time
of
the
first
multi-core
processors
and
so
on.
So
basically,
the
idea
is
how
I
can
can
we
run
parallel
applications
in
a
similar
way.
Why
we
do
it
on
standard
pc?
You
see
an
example.
You
have
an
linux
application,
some
application
a
and
you
want
to
execute
it
on
linux.
This
is
very
simple.
You
just
call
the
application
and
slurm
in
slurm.
D
You
can
execute
the
version
of
certification
just
with
a
single
command,
s-run
and
you're
running
a
parallel
application,
and
eight
tells
that
you
want
to
run
eight
copies
of
that
application.
So
it's
quite
intuitive
idea,
let's
say,
and
in
hpc,
usually
behind
the
a
stays,
a
mpi
parallel
application.
D
This
was
the
main
idea.
What's
what
they
want
to
achieve.
Originally
and
yeah,
the
two
became
quite
big
and
offered
a
lot
of
additional
features.
It's
it's
fault,
tolerant,
full
scale,
cluster
management
tool.
Basically,
it
has
three
main
things
you
can
use
it
as
a
resource
manager,
so
it
can
deal
with
all
the
resources
available
on
the
compute
hardware,
allocate
them
free
them.
D
D
D
I
think
most
probably
everybody
in
the
this
community
is
aware
of
that
resource
management.
How
do
you
allocate
resources
on
the
compute
nodes,
so
resources
can
be
cores
memory,
caches
networks,
gpus
switches,
so
many
many
things
are
seen
as
resources
and
job
scheduling
is
yeah.
How?
How
can
you
schedule
your
jobs
more
optimal
if
you
have
complex
network
topologies,
if
you
have
time
slices,
if
you
want
to
limit
the
execution
of
jobs,
let's
say
we
have
in
my
company
the
case.
D
D
Actually,
there
are
more
solutions
out
there
for
that.
You
see
below
some
small
kind
of
table.
Slurm
covers
both
resource
management
and
scheduling
aspects,
and,
if
you
ask
yourself
what's
kubernetes
today,
kubernetes
also
covers
both
resource
management
and
scheduling.
So
it's
another
kind
of
bar
in
in
this
table.
D
D
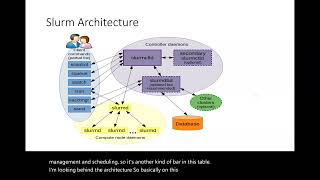
So
basically,
this
is
the
main
main
component
with
which
the
users
are
speaking
to
issue
commands,
but
also
it
speaks
with
the
database.
This
is
the
swarm
database,
which
is
mostly
managing
the
accounting
values
like.
If
you
want
to
introduce
users,
policies,
time
limits,
those
will
be
stored
in
the
database
and
the
control
demon
will
ask
for
them
or
basically
they
will
be
pushed
back.
D
D
You
have
a
slurm
daemon,
which
is
responsible
for
basically,
you
get
the
job
request
from
the
users
it's
registered
from
the
control
daemon
and
the
control
demon
sends
it
to
to
the
actual
nodes.
The
actual
nodes
running
the
swarm
daemon
will
take
care
then
for
resource
allocation
and
and
job
execution.
D
So
the
slurm
demon
is
something
like
cubelet.
If
you
search
for
or
some
sort
of
references
or
connection
to
existing
kubernetes
architecture
in
terms
of
commands,
what
the
user
are
using,
you
can
see
them
in
this
blue
box.
Speaking
with
the
control
demon
is
done
with
the
s
control.
Basically
sq.
You
can
ask
what
queues
are
available
on
the
system.
You
can
view
the
queues
if
the
jobs
are
acute.
D
How
much
you
have
to
wait
that
your
job
gets
running.
You
can
achieve
that
through
the
sq
in
queueing.
Job
happens
with
as
patch,
so
as
batches
just
fire
and
forget
at
some
point
you
don't
you,
you
get
an
output
from
the
job
and
then
s
run
is
more
interactive
blocking
process.
So
actually
you're
you
enqueue
your
job,
you
block
or
the
control
daemon
is
blocking
the
user
request
and
you,
your
job,
gets
running
up
and
running.
D
B
D
B
I
guess
they're
trying
to
mention
here
like
in
kubernetes,
like
you,
don't
have
these
calls
being
explicitly
made
between
components
like
components,
don't
call
each
other
directly
here
they
do
like,
for
example,
s
run
which
is
running
on
the
client.
It
actually
makes
an
rpc
call
to
slam
d.
In
our
case
the
cubelet
explicitly
to
start
a
job
node.
D
D
Some
of
the
basic
utility
is
used
to
submit
jobs,
are
as
patched
as
run.
Jobs
are
basically
text
files,
simple
text
files.
I
will
show
an
example
how
a
search
file
looks
like,
but
you
just
call
as
patch
with
this
job
file
and
then
all
all
goes
to
the
controller
and
the
job
x
is
executed.
It's
very
simple
and
you
can
also
have
something
like
interactive
jobs.
D
D
B
D
Right
right,
you
can
request
to
block
to
to
allocate
10
nodes,
let's
say
and
run
as
run
with
an
argument
to
allocate
the
nodes.
It
will
wait
that
the
10
nodes
are
available
from
the
queue
for
the
certain
time
span.
You
can
provide
the
time
information.
I
want
to
allocate
those
nodes
for
10
minutes.
So
if
the,
if
the
nodes
are
available
on
the
queue
and
you're
the
next
user,
who
can
get
them,
then
you
get
unblocked
at
some
point
and
you
can
do
your
work
with
that.
D
B
D
I
did
not
see
such
thing.
Usually
there
are
users
submitting
jobs,
so
you
don't
have
some
sort
of
connection
to
to
some
events.
It's
not
really
events
driven
concept.
Most
probably
you
you
can
do
some
some
implementation,
which
does
that,
but
maybe
kubernetes
and
the
whole
components
have
better
ways
to
do
that.
If
you
want
to
react
to
an
events
and
stuff
like
that,.
D
F
D
F
D
D
Right,
so
there
are
a
little
bit
alternative
commands.
You
can
just
allocate
nodes
and
attach
to
them
later.
This
can
be
done
with
slog
as
attached,
and
you
see
some
additional
arguments
you
can.
We
have
accounts
associated
to
the
whole
commands,
so
there
there
is,
there
are
components
for
permission
models
and
so
on.
You
can
give
the
time
spans
and
so
on
so
quite
yeah.
D
A
lot
of
features
available
through
the
api
very
interesting
is
to
look
on
the
s
batch
files.
They
are.
I
I
saw
some
examples,
how
you
are
thinking
to
define
jobs
for
kubernetes
and
the
nice
thing
about
slurm
drops
they're
very
compact.
Very
you
could
see
what
you
need
to
express
a
bad
job,
maybe
through
through
this
example.
So,
basically
you
have
the
name
of
the
of
the
bad
job.
You
can
tell
how
many
nodes
you
need.
You
can
have
different
number
of
tasks.
D
The
task
can
be.
You
can
assign
also
how
many
cpus
you
want
per
task,
how
much
memory
you
want
per
cpu.
So
you
do
similar
things.
What
you
do
in
your
pots,
basically
with
requesting
resources.
So
it's
a
little
bit
different
here.
The
resource
requests
are
inside
the
batch
job.
So
if
you
are
thinking
how
to
implement
this
in
kubernetes,
you
will
need
to
find
a
way
to
translate.
D
If
you
want
similar
kind
of
interface,
it
becomes
interesting.
How
do
I
do
I
translate
that
to
bot
requests,
so
it's
a
little
bit
difficult
problem
and
again
you
have
time
you
can
specify
after
that,
and
usually
what
this
is.
This
part
is
the
job
description
part
where
you
have
resource
requests,
some
some
definition
of
time
and
so
on.
After
that,
it's
usually
shell
scripting.
What
follows
and
you
can
execute
any
kind
of
linux
application
inside.
D
D
D
D
I
will
spend
a
little
bit
more
time
on
partitions,
because
I
find
this
concept
very
nice
how
you
could
distinguish
between
different
types
of
resources,
or
so
you
could
group
basically
pieces
of
your
cluster
in
partitions.
You
can
tell
this
part
of
the
cluster
is
partition.
One.
This
part
is
partition,
two,
where
it's
useful,
you
could
imagine.
Let's
say
you
have
a
hybrid
cluster.
D
You
have
some
cpu
only
part
of
the
cluster,
and
then
you
have
gpu
only
or
a
cluster
with
gpus,
so
you
could
build
two
partitions
and
instead
of
giving
access
or
scattering
to
all
the
nodes
and
basically
allocating
some
drop
on
which
which
uses
more
cpu
on
the
gpu
node,
you
could
control
that
through
the
partitions
and
actually
in
in
slurm.
This
can
be
done
automatically,
so
you
could
reset
a
request,
a
resource,
let's
say
a
gpu
resource,
and
then
the
scheduler
should
find
out
automatically.
D
What's
the
best
suited
partition
or
you
will
see
later,
you
can
specify
also
explicitly
what
partition
you
want
to
use
and
under
the
hoods
for
each
partition,
you
have
a
queue
which
is
basically
then
responsible
for
inquiring,
the
jobs
or
getting
the
jobs,
and
then
they
are
served
in
the
order.
Accordingly,.
B
D
D
Okay,
this
is
summary
of
the
resource
requests.
What
you
usually
will
see
in
the
jobs.
Okay,
this
is
more
on
the
cpu
side.
There
are
further
things
what
you
can
control
with
plugins
for
gpus
and
so
on,
but
yeah.
This
is
how
usually
you
can
control,
how
many
cores
you
get
and
and
so
on,
and
how
much
memory
per
cpu
and
so
on
now
back
to
the
partitions.
So,
for
example,
if
you
want
a
bird
you
could
this
example,
which
I
took
from
enroll?
D
It
was
with
two
islands.
You
had
an
island
roughly
100
nodes
which
had
let's
say
hard
drive
capabilities
above
one
terabyte,
so
you
could
basically
group
them
and
every
job
request
which
wants
to
use
which
needs
file
system
bigger
than
one
terabyte
will
be
served
by
this
another
example.
You
could
group
by
memory,
so
you
could
tell
at
least
make
a
queue
or
make
a
partition,
basically,
which
will
cover
all
requests
with.
D
For
jobs
having
more
than
requiring
more
than
96
gigabyte
of
memory-
and
you
in
that
you
can
have
two
clusters,
as
you
see
so
one
with
192.,
it
doesn't
have
to
be
homogeneous,
but
you
can
bind
them
in
one
partition.
One
queue
both
both
will
fulfill
the
requirements.
This
is
just
a
simple
example,
and
this
is
extended
further.
You
can
have
a
third
one
with
gpus
and
the
way
how
you
specify
your
your
requests.
D
D
Yeah
they
are
actually
recommending
to
to
do
explicit
resource
requests,
but
you
have
also
the
possibility
to
choose
the
partition
on
explicitly.
You
can
list
them,
so
you
you
can
they
are.
You
can
always
see
what
what
are
the
available
partitions,
what
kind
of
how
many
nodes
you
have
inside
and
then
there
is
an
argument:
minus
p.
I
think
what
you
can
pass
to
the
s
patch
to
to
use
the
explicit
partition,
but
they
are
not
advertising
that
usually.
D
Yeah
this,
this
is
the
example.
Basically,
you
have
the
standard
s
run
command.
You
have
a
time
parameter.
How
many
nodes
you
want
four
nodes,
basically
with
that
capacity
of
memory.
So
this
is
how
you
request
it
or
if
you
want
a
bad
job
or
if
you
want
a
bad
job
donating
what
you
need
to
change
you
you
do
this
s
run
to
s
patch,
then
it
will
basically
push
it
on
the
queue
and
give
you
the
control
back
right
and
here
another
example.
D
D
D
G
D
D
F
I
maybe
this
is
shane
cannon
from
nurse
berkeley
lab.
Maybe
just
I
wanted
to
comment
that
one
thing
that
I'm
not
sure
was
covered
and
maybe
it'd
be
worth
having
you
know
a
presentation
separately
on
that
is
a
lot
of
what
slarn's
designed
to
do
is
give
a
policy
kind
of
framework
where
the
resource
provider
can
put
priorities
on
how
jobs
are
scheduled.
So
you
might
favor
large
jobs
over
smart,
small
jobs,
for
example,
where
you
may
give
certain
types
of
jobs
priorities
over
others.
You
know
really
what
it's
designed
to
do
is.
F
Typically,
you
have
a
backlog
of
work
that
exceeds
the
amount
of
resource
you
have
at
any
point
in
time,
and
so
it's
trying
to
make
decisions
about
how
to
schedule
that
workload
and
where
it
can
get
challenging
is
you
might
have.
If
you
need
to
schedule
a
really
large
job,
then
you
have
to
start
putting
aside
resources
so
that
you
can
run
that
right.
F
D
Yeah
it
it
has
very
sophisticated,
schedulers
and,
and
the
reservation
systems
are
also
nice.
Yes,
so
you,
you
can
basically
specify
as
an
argument
that
you
want
to
to
use
a
reservation.
So
this
is
one
of
the
nice
features
yeah.
So
there
are
a
bunch
of
very,
very
good
ideas
in
insights,
learn
the
partitions
the
limits.
I
think
the
whole
accounting
is
very,
very
sophisticated,
already
very
mature.
Already.
B
D
D
They
they
organize
them
in
islands,
because
islands
are,
if
you
stay
within
an
island
you
might
have.
Basically
you
might
be
on
a
single
rack
or
something
like
that.
So
in
in
some
cases
you
have
possibility
to
access
an
entity
of
the
data
center
through
a
partition.
So
basically
you
know
through
taking
this
partition.
D
G
D
The
administrator
has
some
level
of
control.
There
is
most
probably
a
default
pool
where
the
jobs
will
land,
so
you
will
have
a
default
or
administrator.
Has
the
the
power
to
define
the
default
pool
where
all
the
jobs
will
go.
You
can
limit
the
access
also
to
the
partitions,
not
give
access
to
everybody
for
for
the
fat
nulls
or
something
that
this
is.
G
D
H
D
We
are
looking
at
benchmarking
and
and
how
to
approach
cloud
native
benchmarking
so
and
the
team
had
the
idea
to
look
to
classical
ci
tools,
white
jenkins,
ron,
jenkins,
job
and
stuff
like
that
and
yeah.
For
me,
I
don't
know
if
this
is
a
good
model,
because
benchmarking
usually
can
be
done
as
a
bachelor.
D
D
We
want
to
benchmark,
let's
say
a
cluster
of
four
nodes,
eight
nodes,
so
you
can,
you
can
expose
all
the
nodes
make
them
available
through
sloan
first
and
then
slurm
allows
you
to
to
start
a
job
and
in
some
sort
of
prologue
script
you
can
provision
a
kubernetes
cluster
on
the
located
nodes.
This
was
the
idea
and
then
you
just
run
the
the
benchmark,
gather
the
results
and,
at
some
point
the
result
or
the
job
is
completed,
so
you
could
theoretically
combine
both
worlds.
D
You,
at
least
in
this
example,
for
benchmarking
and
make
it.
But
this
is
in
the
case
where
you
want
to
test,
maybe
the
whole
kubernetes
system
in.
In
other
cases,
you
might
have
just
one
kubernetes
cluster
and
you
just
want
to
submit
bad
jobs.
You
don't
need
all
this
overhead.
So
most
probably
it's
not
very
efficient
way
in
in
terms
of
provisioning
and
so
on,
but
it
should
be
possible.
B
Are
there
like
times
where
you
would
have
resources
being
set
aside,
while
them
is
trying
to
accumulate
the
amount
of
resources
required
for
the
all-or-nothing
drug?
And
it's
like
for
how
long
does
it
do
that,
like
I'm,
just
trying
to
understand
how
it
implements
all
or
nothing?
By
trying
to
minimize
maximize
you
know
or
minimize
the
case
where
you
have
as
resources
set
aside,
it
can
be
used
while
accumulating.
F
Required-
and
maybe
I
could
comment
on
that-
yes
it'll-
definitely
do
that.
So
that's
what
I
was
talking
about
earlier
is
it'll
make.
If
it's
trying
to
schedule
a
large
job,
it
can
create
sort
of
automatically
a
reservation
out
in
time
when
it
thinks
it's
going
to
be
able
to
have
those
resources
available
based
on
the
time
limits
that
have
been
specified
for
all
the
different
jobs,
and
so
it'll
say
you
know,
I
think
at
six
o'clock
I'll
have
all
the
resources
to
run
a
thousand
node
job,
and
it
will
it'll
make
that
reservation.
F
F
What
a
wall
time
is
they
don't
have
to,
but
typically
a
wall
time
is
either
specified
by
the
job
or
a
default
is
applied
based
on
what
partition
they're
going
to.
What
is
the
typical
that
you
see
like?
Is
it
it
can
be
hours
to
days,
but
typically,
you
know
many
many
days
starts
to
get
towards
the
limit
of
what
a
typical
hpc
center
might.
You
know
allow.
B
F
They
will
try
to
game
the
cues
to
try
to
get
their
jobs
to
as
fast
as
they
can,
but
it's
within
the
limits
of
the
how
the
policies
have
been
configured
so
there's
constraints
on
that.
You
know
like
a
smart
user,
will
sit
there
and
say
like
I
can
fit
my
job
in
that
big
backfill
slot.
Let
me
size
it
the
right
way,
so
it'll
jump
in
you
know
others,
just
they
just
want
it
to
run
at
some
point,
they'll
submit
it
and
they'll
wait
for
it
to
come
out.
The
other
side.
F
The
resources
tend
to
be
very
consistent,
so
you
kind
of
have
a
feel
for
that,
but
you're
right
it
can
vary.
It
can
vary
more
because
of
things
like
io
congestion
or
things
like
that,
but
they'll
typically
put
in
you
know
the
expected
time
and
then
they'll
put
in
some
safety
factor.
They
won't
get
charged.
They
only
get
charged
for
what
they
use.
Typically,
so
they're,
it's
more
about
just
trying
to
get
the
time
right
so
that
it'll
it'll
schedule
sooner
than
otherwise.
D
Yeah
yeah:
this
is
another
thing
which
I
did
not
cover
the
charging,
so
they
are
usually
in
the
hpc
data
centers.
They
connect
that,
with
with
some
sort
of
budget,
the
users
have
budgets
of
hours
compute
hours,
so
you
can
make
it
automatically
that
the
compute
hours
are
then
deducted
based
on
the
on
the
actual
used
compute
types.
A
D
Yeah
this
goes
into
checkpointing,
usually
what
of
the
applications
are
doing
or
the
hpc
applications
are
trying
to
support
checkpointing.
It
depends
a
little
bit
also
on
your
code.
If
your
code
supports
checkpointing,
you
can
make
checkpoints
in
time
and
basically
start
from
from
a
certain
checkpointed
state
later.
So
it's
not
completely
automatic
that
you
make
a
copy
of
the
memory,
and
then
you
can
restart
it's,
not
the
virtual
machine
or
something
which
is
running
so
your
application
has
to
support
it.
D
B
Yeah,
thank
you
very
much
attorneys
and
shane
also
for
backing
us
with
some
of
these
questions.
We're
five
minutes
late.
I
guess
that's
really
great.
Please
like.
If
you
have
more
questions,
maybe
tag
shane
or
thank
us
on
the
working
group,
slack
channel
and
maybe,
as
as
some
mentioned
on
the
chat
we
can
invite
also
people
from
skid
md.
I
did
meet
with
them
before
they
schedule
defaults
and
mention
to
them
that
we
have
a
working
group
in
case,
so
we
will
try.
D
B
Right
like
how
do
we,
how
is
planning
to
support
like
auto
scaling,
for
example
in
cloud
environments?
I
guess
there
is
a
work.
There
is
a
ton
of
work.
There
is
happening
right
now,
so
that
would
be
also
interesting,
because
everything
that
we've
discussed
so
far
kind
of
works
well
on
an
on-prem
cluster.