►
From YouTube: Kubernetes Community Meeting 20160121
Description
We have PUBLIC and RECORDED weekly video meetings every Thursday at 10am US Pacific Time.
https://docs.google.com/document/d/1VQDIAB0OqiSjIHI8AWMvSdceWhnz56jNpZrLs6o7NJY
This week we heard from Paul Brown about how Salesforce is investigating Kubernetes. As well as reports from the configuration and federation SIGs. Lastly, we discussed the state of our automated testing and blocked merge queue.
A
I
am
recording
this
meeting
so
array.
Thank
you
all
for
joining
us.
We've
got
20
participants
today.
This
is
awesome
what
a
relatively
full
agenda
and
they
see
some
friendly
faces.
So
it's
great
to
have
you
all
here.
First,
up
on
our
agenda
today
was
Paul
Brown
from
Salesforce
and
they're
just
getting
involved
with
the
community.
So
I
figured
I'd.
Ask
them
to
talk
about
what
they're
interested
in
well
asked
Paul
to
talk
about
what
Salesforce
is
interested
in.
B
Yeah,
actually
speaking
for
sales
forces
is
kind
of
a
big
deal
and
you
have
to
get
certified
and
I
I'm
gonna
really
try
to
avoid
that.
So
I
will.
I
will
speak
in
more
general
terms,
and
you
know
so
from
from
a
tactical
perspective.
You
know:
coo
bonetti
means
like
a
great
tool
right
to
the
you
know.
You've
you've
got
a
consistent
engineering
experience
from
development
through
integration,
testing
on
to
internal
data,
centers
or
public
cloud
got
well
factor
layers
that
make
a
lot
of
things
work
right
right.
B
B
Yeah
there
you
go,
hopefully
we,
the
use
of
the
case
for
a
use
case
is
not
like
just
so
played
out
for
you
guys
at
this
point
that
it's
tiresome,
but
indulge
me
so.
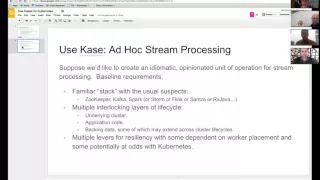
The
use
case
I'd
like
to
highlight
you
know,
is
one
of
creating
an
idiomatic
opinionated
operation
for
stream
processing,
so
one
one
that
we
care
about
very
much
and
one
that
I
think
plays
2qu
bonetti
strengths
and
one
that
may
have
some
interesting
motivational
or
foundational
questions.
B
So
the
the
baseline
set
of
requirements
which
may
or
may
not
be
familiar
with,
but
probably
if
you've
worked
outside
of
Google
or
outside
of
Amazon
on
systems
like
this
are
a
bunch
of
open
source
components.
You've
got
zookeeper,
Kafka
spark
and
these
all
have
their
own
set
of
operational
expectations.
Right
zookeeper,
you
move,
35,
etc.
You've
got
a
set
of
nodes
that
need
to
communicate
with
each
other
kafka.
You've
got
a
set
of
nodes
that
need
to
communicate
with
each
other
and
zookeeper
or
you've
got
a
master
and
a
bunch
of
workers.
B
B
Kind
of
interactions
and
behaviors
now,
on
top
of
that,
you
know
things
that
aren't
necessarily
in
the
scope
of
Cooper
Nettie's,
but
are
interesting.
Is
that
you've
got
multiple
interlocking
layers
of
life
cycle
valium
underlying
cluster
got
it
up
and
start
up
for
the
various
pieces
that
you
know
who
wants
what,
when
to
feel
like
they're
healthy
and
not,
you
know
kind
of
dude
turtle
thing
of
lying
on
their
back
with
their
legs
waving
in
the
air,
you've
got
actual
application
code
and
then
you've
got
backing
data
right.
B
So
things
like
this
aggregated
storage,
SF
s,
three,
as
your
block
store.
Hdfs
are
all
you
know
of
interest
to
us
and
both
within
and
without
the
life
cycle
of
a
cooper.
Nettie's
cluster
write
some
data.
You
may
want
to
survive.
It's
not
you
don't
care
about
so
much
and
then
they're
also.
You
know
mixed
in
there
multiple
lovers
for
resiliency
and
placement.
B
We
don't
want
to
have
to
of
the
zookeeper
nodes
attached
to
a
physical,
node
or
two
physical
nodes
that
are
behind
the
same
Power,
Distribution
unit,
dot,
dot
dot,
and
this
goes
on
up
a
stack
to
brokers,
leaders
for
partitions
and
bark
and
or
storm,
and
with
that
all
may
be
asked
if
there
are
questions
or
comments
from
hooks
on
the
pimple
phone
who
thought
about
similar
things
or
I've
part
of
my
team
here
in
the
room
with
we
can
get
questions
or
make
comments.
I
have.
E
A
question
first,
though
I
know
we
spent
a
fair
bit
of
time
kind
of
starting
with
the
community
version
of
Cassandra
for
Cassandra,
for
Cooper
Nettie's
and
had
to
kind
of,
like
you
know,
tweak
it
in
tune
it
to
make
it
a
little
bit
more
fully
baked.
My
impression
is
that
the
park,
the
sort
of
standard
community
are
getting
packaging
of
spark
is
sort
of
a
similar
state,
which
is
that
there's
a
there's
kind
of
a
good
start
there,
but
it
isn't
probably
fully
baked,
for
you
know
wide
scale
production
use.
E
B
You
know
in
part,
I
think
part
of
the
perspective.
There
is
that,
at
least
from
a
from
a
top-level
view,
we're
presuming
that
it's
going
to
make
more
sense
for
us
to
manage,
occur.
Benetti's
clusters
containing
spark,
rather
than
attempt
to
manage
sparkasse
something
like
a
larger
mesas
cluster.
That's
shared
between
a
multiple
kubernetes
cluster
right,
so,
where
you're
breaking
our
hierarchy
down,
maybe
a
little
differently
than
night
30.
E
I
agree
with
that
general
perspective
entirely
and
that's
the
same
direction.
We're
headed
my
really
my
real
question
was
there.
There
is
in
the
Cobra
Nettie's
project
patch
packaging
efforts
around
a
bunch
of
these
systems,
and
the
question
was:
are
you
using
those
and
how's
it
been,
and
are
you
contributing
back
on
those
and
any
perspective
on
that?
If
you
did
your
own
packaging
just
started
straight
from
the
Apache
side,
then
that's
a
that's
a
different
answer.
I'd
say:
you're
being
courteous
parrot
with
the
true
pernetti's
project
version
of
those
and
help
us
improve
them.
E
E
B
E
E
I
just
want
to
say
how
much
we
appreciate
the
work.
Certainly,
this
is
a
workload
that
we
hear
a
lot
of
that
people
want
to
run
against
Cooper
Nettie's,
so
we're
really
excited
to
have
someone.
Let's
definitely
just
sink
offline
I
actually
just
spoke
to
Zak
who's
about
10
meters.
For
me,
right
now
about
the
state
of
production,
pneus
of
the
zach,
the
spark
example
he
reported
that
you
know
he
has
a
big
data
background
and,
and
he
said
it
was
in
pretty
good
shape,
but
he
had
definitely
hadn't
done
load
testing
against
it.
E
B
Woman
and
I
really
do
mean
you
know
the
didn't,
bold
it
or
anything
else,
but
you
know
where
the
opinionated
unit
of
operation,
I
think,
is
something
that
we
feel
very
strongly
about.
You
know
we
don't
want
to
wrap
things,
we
don't
want
to.
You,
know,
obscure
or
otherwise,
sort
of
deface
them
and
presenting
them
to
our
our
users,
and
you
know
for
our
own
purposes.
B
A
B
B
A
G
Hey
Paul,
this
is
Joseph
Joseph
jacks
I've
actually
had
some
conversations
with
the
folks
of
our
confluent
about
Kafka
and
some
upstream
issues
and
Kafka,
preventing
their
their
cues
and
brokers
from
running
properly
and
in
containers
and
there's
there's
a
JIRA
issue.
I
think
I
can
point
you
to
once
I
get
that
from
them,
but
otherwise
they're
actually
super
interested
in
this
and
finding
like
real
users
to
point
to.
As
examples
of
you
know,
people
running
Kafka
on
Cooper
Nettie's,
so
that
I'd
be
really
interested
in
following
what
you're
doing
there.
Ok.
B
Cool
one
and
we're
we're
going
to
share
one
by
the
way.
One
really
interesting
thing:
if
any
of
you
guys
are
following
Sam's
ax
is
there
was
one
guy
and
it's
probably
a
month
back
or
so
on
the
sansa
mailing
list
who
actually
broke
out
the
yarn
pieces
and
replaced
them
with
Cooper,
Nettie's
or
work
management,
and
therefore
yeah
that
that
might
be
a
really
interesting
thing
to
play
with
two
so
but
yeah
would
would
love
a
would
love
a
pointer
to
that.
Juror
sounds
good.
A
H
C
I'm,
actually
here
sorry,
I'm
sharing
with
the
button
I,
have
trouble
connecting
actually
figured
out
later
yeah,
so
the
config
sig
has
been
meaning
to
past
subtly.
The
meetings
are
on
Wednesday
1
p.m.
pacific
time.
Usually
the
you
can
there's
also
a
Google,
Group
and
/
channel
to
reach
out
covering
topics
for
application
deployment
and
configuration
not
deployments
of
Coober
Nettie's
itself.
That's
something
that
the
oftentimes
surprises
people,
but
so
the
topic
of
the
the
last
several
meetings
has
been
reuse
of
configurations,
specifically
parameterization
of
configuration.
C
One
is
scoping,
just
you
can
create
the
objects
with
names
and
label
selectors,
and
so
on
that
don't
collide
or
overlap,
and
that
is
addressed
reasonably
well
by
clustering,
namespace
scoping,
but
another
common
need
is
a
slight
customization.
So
you
know
plugging
in
your
database
password
or
changing
the
amount
of
CPU
RAM
that
our
particular
instance
needs.
Things
like
that.
So
you've
been
discussing,
there
have
been
a
few
proposals
for
configuration
parameters.
Ation
there's
one
open
shift
actually,
which
is
built
on
tour.
C
Nettie's
actually
has
a
mechanism
called
templates
for
this,
which
is
basically
a
list
of
objects
which
have
some
values
of
some
fields,
parameterised
and
a
list
of
parameters
that
need
to
be
provided
to
instantiate,
that
list
of
objects.
So
there's
a
proposal
to
slightly
simplify
that
and
upstream
it-
and
there
was
another
proposal
for
dealing
substitution
in
keep
control
and
I
guess.
C
C
For
example,
in
the
database
case,
you
need
to
complete,
create
a
pod
and
a
persistent
volume
claim
together
and
the
persistent
vol-plane
needs
to
persistent,
be
stable
and
then
identity
in
the
pod,
easy
match
to
the
identity
of
that
versus
and
volume
claim.
You
may
also
need
to
create
secrets
or
other
resource.
Other
communities
objects
together
with
those
pods.
Similarly,
for
scheduled
job
you
may
need
to
create.
You
know
we
have
this
new
job
API.
C
You
need
to
create
a
sequence
of
jobs
and
they
need
to
be
parametrized
in
some
way
like
in
the
cron
case.
They
may
be
parametrized
by
time
and
the
pet
Casey
and
you
need
to
be
parameterize
by
index,
or
they
may
have
different
command
line.
Arguments
teach
instance
like
one
might
be
the
master
and
others
like
slaves
or
whatever.
C
At
the
same
time,
we
do
want
to
support
this
more
sophisticated
substitution
and
expansion,
approaches,
configuration
dsl's
in
the
lifelike,
jinja
jinja,
json,
a
full
python,
and
so
on.
So
we
agreed
that
those
would
be
implemented
outside
the
system
as
they
are
as
they
are
now,
but
we
have
this
new
third-party
resource
under
development
that
will
allow
them
to
store
state
in
Cooper
Nettie's
and
its
key
value
store.
So
if
they
need
to
store
their
configuration,
objects,
the
not
be
processed
objects
or
other
state,
they
can
use
that
third-party
resource
to
do
so.
C
So
that
is
likely
a
route
that
some
of
the
systems
will
take.
So
anyway,
the
configuration
space
is
very
large
and
different
people
have
different
kinds
of
approaches
they
want
to
use
depending
on
where
they
come
from,
like
some
people
might
want
to
use,
compose
and
then
compose
to
cube,
translate
it
to
criminate
these
resources
or
other
people.
My
way
is
tarah
forum
or
other
people
might
wanna
use
json
it
whatever
we
want
to
ensure
that.
C
Functionality
built
for
communities
is
targets
right,
love,
a
little
distraction.
So,
and
so
you
know
things
like
rolling
update
works
on
concrete
turn.
Adiz
it
got
resources
to
regardless
of
how
you
generate
those
resources.
You
can
use
rolling,
update
the
there's,
a
new
proposal
to
generate
automatically
generate
secrets
that
was
originally
tied
to
the
template
proposal
I
mentioned
earlier,
but
we
decided
to
decouple
it
from
that.
C
So
again,
regardless
of
what
configuration
mechanism
you
used
you
can
you
utilize
that
secret
generation
feature
so
that
will
you
know
so
that
approach
I
think
will
allow
cumin
eighties
to
sort
of
meet
people
where
they
are
and
use
whatever
configuration
system
works
best
for
them
or
that
they
have
experience
with,
or
you
know,
especially
if
they
use
something
to
configure
resources
outside
of
communities
as
well
as
inside
communities.
They
can
use
a
single
mechanism
for
everything.
C
So
the
you
know
if
you're
interested
in
this
topic,
do
you
get
involved
in
the
cig
start
discussion
on
the
google
group.
This
discussion
is
pretty
much
done,
so
you
know
the
meetings
are
open
for
new
topics
and
in
future
meetings
training
next
week.
So
if
you
have
a
deployment
or
configuration
application,
configuration
related
issue,
you
want
to
discuss,
that's
a
good
place
to
discuss
it.
So.
A
B
C
Well,
I
think
the
number
of
configuration
objects-
I,
imagine-
is
going
to
be
proportional
to
the
number
of
communities
objects
right
right.
So
if
you
have
10,000
services,
you
might
have
order
10,000.
You
know
by
some
small
constant
factor,
number
of
configurations
or
something
so
that
doesn't
seem
that
problematic.
There
is
definitely
a
spectrum,
and
you
know
if
things
be
very
large
objects
like
if
you
have
configuration
instantiated
is
Java
jars
or
something
like
that
which
maybe
tens
of
megabytes
in
size.
C
Those
probably
are
not
appropriate
to
store
in
community,
so
it
would
probably
be
more
appropriately
pushed
as
dr.
images.
So
that's
another
feature
that
we
hope
that
system
is
the
equivalent
of
sort
of
volumes
from
and
doctors
ability
to
mount
an
image
as
a
volume
into
your
container.
So
if
you
have
a
large
configuration
blob
or
basically
data
like
all
the
data
from
a
website,
something
like
that,
like
we
have
git
repo
volumes.
For
this
reason,
you
can
pull
the
data
through.
That
other
means.
C
So
if
you
need
to
pull
data
from
s3
or
from
a
Google,
Cloud
storage
or
from
get
or
wherever
you
can
either
or
from
a
doctor
registry
I
want
there
to
be
a
mechanism
that
makes
that
easy.
It
would
not
be
the
same
as
the
kinds
of
configuration
that
I
was
talking
about
and
we
do
have
a
new
config
map
API.
C
That
is
almost
done
and
we'll
be
in
1.2
for
small
amounts
of
configuration,
data
that
can
be
easily
injected
into
volumes
and
to
environment
variables
to
decouple
application
configuration
from
pod
configuration,
which
I
think
will
be
useful
for
a
lot
of
use
cases
and
enhance
configuration,
reuse
as
well,
but
yeah
I
mean
at
some
point.
You
need
to
draw
the
line
so
there's.
C
C
It's
kind
of
on
a
case-by-case
basis
and
some
people
want
their
clusters
to
scale
to
very
large
numbers
of
users
and
those
probably
can't
support,
can't
be
as
forgiving
about
the
size
of
config
objects,
but
smaller
clusters,
you
know
large
config
objects
are
probably
fine,
so
I
don't
know.
There's
the
one
size
fits
answer,
darkly
speaking
at
TD.
Has
it
with
it,
though
I
mean
SED
has
a
hard
hard
limit.
Currently
remember.
A
Find
out
more
about
what
the
conversations
are
and
most
of
the
cigs
seem
to
have
their
their
discussions
either
in
the
mailing
lists
that
exist.
So
you
can
search
google
groups
for
anything
that
begins
q,
brunetti
stash
cig
or
in
the
slack
channel
for
each
of
the
cigs
and
then,
of
course,
many
of
them
have
regular
meetings
which
are
negotiated
on
those
mailing
lists.
Earned
the
slack
channel
so
take
a
peek
there
for
more
ways
to
contribute.
A
I
I
think
I'm
gonna
give
it
oh
okay,
excellent,
I'm
Quinn
today's
leading
our
sig,
but
there's
a
lot
of
community
participation.
So
I'm
you
give
an
update
on
where
we
are
by
way
of
background.
First
we've
nicknamed
the
effort
to
run
federated
clusters.
We've
called
that
goober
Nettie's
Quinton
has
a
talk.
I
Getting
into
things
like
cloud
bursting.
We
identified
a
very
sort
of
simpler
use
case,
which
is
to
run
a
single
cluster
in
multiple
zones,
single
cloud
and
that's
something
where
we've
started
and
we're
calling
that
effort.
Uber
net
is
a
light
and
we're
working
on
that
in
parallel
with
the
full
multi
plaster
Federation
effort
which
we're
calling
uber
Nettie's.
I
So
I'll
give
you
all
a
spoiler
we're
still
finalizing.
The
design
for
your
gonna
do
is
full,
but
we
are
planning
on
shipping
benetti's
light
on
AWS
and
GCE
in
1024
uber
net
he-hey,
for
whom
it
is
full.
There's
a
design
doc,
which
is
19,
313
and
Huawei,
is
leaving
the
design
and
implementation
of
that
urban
Eddie's
full
we'll
start
by
adding
an
implementation
of
the
Cooper
Nettie's
API.
That
will
combine
multiple
clusters.
So
when
you
create
an
object
in
the
uber,
Nettie's
API
it'll
basically
be
formed
out.
I
Individual
could
manage
tremendous
clusters
and
the
goal
is
to
use
the
existing
communities
API.
So
you
have
to
learn
a
new
API
even
have
to
reinvent
all
our
tooling
and
Huawei.
Has
a
team
actively
working
on
this,
and
I
will
put
a
link
in
for
the
that's
the
design
dog
for
Cooper
days
on
urban
areas.
Light
I
thought
I'd
talk
about
we're
planning
on
shipping
and
not
shipping
in
102
scope
in
one
or
two.
I
Maybe
today
we
to
have
some
volume
awareness,
so
we
have
an
emission
controller
that
tags
persistent
volumes
when
you
create
them,
but
there
is
own
information
and
then
the
scheduler
will
only
schedule
pods
using
those
volumes
on
two
nodes
in
the
same
zone,
which
sells
the
problem
that,
above
on
both
GCE
and
AWS,
you
can't
attach
a
volume
to
an
instance
in
a
different
zone.
Atos
support
is
merged
and
GCE
should
again
go
in
this
week.
We've
tested
and
loeb
answers
do
work
across
them,
so
that
will
just
work
out
of
the
box.
I
The
Master
will
remain
a
single
point
of
failure,
but
will
hopefully
get
to
that
in
13
and
on
both
GCE
and
AWS.
Now
we
we
have
added,
or
we
now
have
the
ability
to
sort
of
auto
restart
the
the
master.
So
if
it
crashes,
it
will
at
least
be
restarted
by
the
cloud
monitoring.
Ap
is
so
that's
what
we're
going
to
ship
at
through
Nettie's
light
a
single
cluster
that
can
span
multiple
zones
and
makes
reasonable
decisions.
I
hope
we're
not
planning
on
building
a
whole
lot
more
into
benetti's
light.
I
We're
not
planning,
for
example,
on
building
zone
awareness
into
cute
proxy
so
that
traffic
might
bounce
around
a
fair
bit
inside
your
cluster
and
if
you
want
to
run
multi
region
or
multi-cloud,
that's
never
going
to
be
a
new
Braddock,
Google
Nettie's
light!
That's
where
urban
areas
comes
in,
but
for
Barry's,
102,
we'll,
hopefully
meet
a
lot
of
people's
needs
that
do
want
to
run
multi-zone
for
some
h
a
support
and
come
help
us
with
you
ready.
So
we
can
get
into
13
a
question
on
religious.
E
Light,
yes,
so
what
you're
describing
seems
very
sensible
and
useful
a
near
use
case
to
that
is,
if
you're
running
in
your
own
data
center
environment,
on
bare
metal,
and
perhaps
you
might
even
think
of
a
rack
as
being
a
zone
or
something
sounds
like
most
of
what
you
do,
it
would
adapt
to
that
pretty
easily.
But
could
you
comment
further
absolutely
so
the.
I
For
that,
for
that
scenario,
or
for
other
clouds,
if
you,
if
you
late
I,
just
the
same
labels
to
your
nodes,
then
the
the
existing
spreading
spreading,
scheduler
or
spreading
preference
will
work.
So
if
you
wanted
to
label
you
know
each
your
racks
with
a
different
zone
or
whatever
everyone
I
allocate
that
then,
yes,
we
will
spread
out
across
racks
or,
however,
you
decide
to
do
it.
The
volume
thing
again,
if
you
have
you
know
like
an
ass
and
at
the
top
of
each
rack
or
an
age
data
center.
I
Then
yes,
if
you
should
probably
tag
that
or
go
through
some
mm
yeah
as
long
as
you
tag,
if
you
tag
your
volumes
then
or
your
persistent
volumes,
then
that
will
also
work.
If
you
want
to
automatically
tag
them,
you
have
to
go
in
and
add
some
code
so
that
when
you
create
the
to
the
admission
controller
so
that
when
you
create
the
persistent
volume,
you'll
have
to
I,
don't
know:
query
you,
you
know
your
internal
environment,
but
as
long
as
you,
it's
all
controlled
by
by
labels.
E
For
those
that
don't
know
what
Bob
is
describing
and
what
just
describing
is
how
we
in
fact
run
at
Google,
where
once
you
basically
anytime,
there's
a
difference,
a
significant
difference
in
latency
or
performance,
or
something
like
that
between
a
given
cluster.
That's
when
you
want
to
start
having
your
cluster
scheduler,
be
aware
of
those
kind
of
things.
E
That's
obviously
coming
in
over
Nettie's
proper
in
uber
Nettie's
light
as
long
as
your
nodes
have
a
tolerance
of
latency
between
them,
and
you
can
do
exactly
as
Justin
said
between
ingress
and
egress,
and
you
know,
there's
no
cost
and
things
like
that
and
absolutely
you
could.
You
could
have
knowed
pools
per
rack
and
that
would
work
perfectly
well.
A
Excellent
thanks,
Justin
and
I
think
you're,
one
of
the
people
who
make
secure
Brittany's
go
on
AWS.
So
if
you
want,
if
anybody
wants
to
work
on
that,
Justin
would
be
one
of
the
people
to
reach
out
to
because
he's
done
in
a
normal.
My
work
on
that
thus
far
all
right.
If
there
are
no
further
questions
about
uber
Nittis,
like
if
everybody
admitted
to
check
if
their
own
mute
and
asking
questions
and
then,
if
not,
we
will
run
on
to
talking.
A
We
had
a
question
last
time
about
conformance
tests
and
more
broadly
testing,
but
they
don't
think
we
can
get
into
the
the
more
broad
testing
picture,
because
the
testing
and
continuous
deploy
stuff
is
a
different
person.
But
we
have
each
year
of
the
video
who
is
who
has
been
working
on
the
conformance
testing
or
is
beginning
to
work
on
the
conformance
testing.
And
so
I
won't.
I
didn't
track
last
time
who
asked
questions
about
conformance
tests,
but
I
did
bring
ike
to
answer
them.
A
J
The
question
was
kind
of
driven
towards
like
how
you
conformance
tests
factor
into
the
release
process
and
what
is
the
release
process
look
like
for
what
not
to
like.
Just
during
the
scalability
sake
about
an
hour
ago,
somebody
was
talking
about
a
code
/
or
code
freeze,
and
that
was
sort
of
the
first
time
I
as
an
outsider
who's.
Not
a
Googler
have
heard
about
that.
J
Maybe
that's
representative
of
me
not
being
plugged
in
somewhere,
but
I
just
was
sort
of,
maybe
that's
taking
that
out
of
scope
of
just
conformance
tests,
but
I
think
there
was
a
plan
to
get
conformance
tests
more
tightly
integrated
into
the
release
process
and
it
was
kind
of
interested
in
it.
From
that
perspective,
yeah
totally
notice.
A
K
F
K
From
Samsung
myself
and
Joe
beta
and
a
cool
of
other
folks
sat
down
and
sort
of
tried
to
hack
out
what
we
would
like
conformance
testing
to
look
like
and
Aaron
opened
an
issue.
I
have
it
open
its
issue:
18
16,
to
18
16,
to
modify
conformance
test
policy
to
use
tests
from
release
branches,
and
that
represents
a
bit
of
a
shift
from
it's
sort
of.
K
K
My
my
cluster
is
v1
conformant,
but
that
it's
v
1.1
conformant
or
v
1.2
conformant,
because
it
you
know
factors
in
it,
you
know,
has
the
ability
to
schedule
jobs
or
other
features
that
we've
added
thus
far,
so
we
do
expect
conformance
tests
to
be
forward
compatible
but
not
backward
compatible.
So
a
video
v1
conformance
tests
should
work
on
a
v
1.2
cluster,
the
1.2
conformance
tests
should
not
work
on
a
v1
cluster
necessarily
be
one
point
out
is
what
I'm
USA
be
one
that
may
or
may
not
always
be
the
case.
K
Unfortunately,
some
tests,
you
know
we
realize
we're
poorly
written
and
we
need
to
make
them
better.
So
we
will
be
encouraging
people
to
use
conformance
the
latest
conformance
tests.
That
said
also,
we
will
also
have
the
concept
of
conformance
tests
ahead.
They
will
move
quicker
because
head
moves
quicker,
are
mastered,
you
know,
whatever
you
want
to
call.
It
moves
quicker
than
a
release
branch,
but
you
know
that
is
sort
of
what
we
expect
to
be
passing
as
we're
coming
up
to
the
1.2
branch.
K
You
know
we
would
like
people
who,
like
providers,
to
be
sort
of
watching
their
conformance
on
against
master,
to
make
sure
that
when
we
do
that
branch,
there's
not
a
last-minute
scramble
to
cherry-pick
a
bunch
of
stuff
into
the
release
branch
to
make
all
the
providers
that
we
want.
Conformant
informant
are.
K
So
when
I
heard
about
these
questions
last
week,
I
thought
to
myself.
Oh,
we
should,
you
know,
probably
actually
start
scheduling,
sig
testing
meetings.
So
if
there
is
interest
enough
to
make
it
worthwhile
to
schedule
say
testing
meetings,
I
can
certainly
do
that.
I
would
love
to
start
getting
input
from
from
folks
outside
of
Google
I
know,
Carl
KFI
from
asos
and
Aaron
have
both
expressed
some
interest.
I
haven't
turned
explicitly
like.
We
need
more
face
time
with
you
all,
but
if
that
is
the
case,
I'm
happy
to
drive
that
yeah.
J
So
this
is
aaron
asking
a
question
thanks
for
really
bad,
adding
a
lot
of
context
there
and
I
do
think.
We
probably
are
at
the
point
where
some
of
this
some
of
the
the
sausage-making
about
how
testing
is
actually
implement.
It
does
need
to
be
discussed
at
state
testing,
but
I
still
kind
of
curious
for
this
audience.
J
I
do
think
Carl's
done
a
lot
of
great
work
at
back
porting,
some
of
the
new
conformance
test
policy
stuff
into
the
release,
one,
not
one
branch,
it's
unclear
to
me
if
the
work
is
going
to
continue
back
to
the
release,
10
branch
and
maybe
that
legacy
can
form,
is
test
branch.
So
it's
just
kind
of
curious,
since
it
does
seem
like
we're
converging
towards
a
1
dot
to
release
how
much
of
this
conformance
testing
policy
do.
J
K
I
I
would
love
to
see
it
happen
before
the
one
dot
to
release.
I
think
you
know
the
limitation.
There
is
not
do
we
want
it
to
happen
or
not.
The
limitation
is,
do
we
have
the
resources
to
make
it
happen
in
time
or
not,
and
you
know
I
Aaron
you
and
I
have
both
talked
about
like
this
is
high
priority.
It's
just
that
there's
a
bunch
of
other
stuff,
that's
even
high
priority
and
absolutely
you
and
I
are
both
in
the
same
place
on
that.
K
E
I'll
use
this
some
I'll
use
this
opportunity
to
state
that
this
should
be
the
number
one
priority
for
the
entire
project
and
that
the
notion
that
there's
all
this
feature
stuff,
that
needs
lots
of
work
and
it's
higher
priority.
I
know
I've,
said
this
before,
but
I'm
going
to
keep
saying
it.
This
should
be
the
number
one
project
project
priority
ahead
of
any
feature:
edition
cool
stuff,
which
I
know
attracts
everybody's
attention,
but
this
is
just
too
critical
for
it
to
be
a
second-class
citizen.
B
K
F
K
E
One
of
the
people
with
their
finger
on
the
button
so
to
speak,
I
also
feel
this
feel
your
pain
and
so
on.
I
think
that
that
everyone
here
recognizes
how
quickly
we've
been
moving-
and
you
know,
there's
some
backfilling
of
software
maturity
that
needs
to
go
on
and
we
are
invested
in
it
from
our
side.
We
also
very
much
what
the
community
invest
in
as
well,
and
you
know
our
our
brand
new
test
lead
and
some
other
things
will
help
with
that.
E
But
I
mean
you
know,
you
can
argue
that
that
Sarah
is
pointing
out
of
the
work
that
Justin
doing
on
AWS
is
a
symptom
of
the
same
thing
right
like
how
do
we
formalize
our
testing
around
that
and
distributed
and
all
that
good
stuff?
So
this
is
an
extremely
high
priority.
We
would
love
help
from
anyone
as
we
build
up
this
infrastructure
and
ask
for
a
whole
bunch
of
volunteers
to
help
keep
us
honest,
David.
E
Me
say:
I'm
putting
we're
putting
our
money
where
our
mouth
is
on
this
pretty
much,
almost
all
what
my
team
does.
Is
you
a
and
testing
related
work
and
David
I?
Think
that
was
you
commenting
earlier
I
I
think
I
certainly
appreciate
the
nod
towards
the
importance
of
testing
but
I
think
when
you
actually
start
pulling
people
off
of
the
future
projects
that
are
going
on
and
putting
them
directly
on
the
QA
stuff
and
making
that
the
most
important
thing
for
us
to
have
right
for
any
release.
E
I,
don't
think
we'll
have
been
at
the
right
at
the
right
place,
get
the
replacement,
I,
so
I
totally
agree.
I
realize
you
don't
see
internal
headcount
allocation
for
google,
but
there
are
full-time
sui's
and
tests
and
folks
working
on
this
as
we
speak,
Iike
is
just
one
and
there
are
others.
Great
we'd
love
to
have
looked.
I
was
just
bugging
Sara
about
this
earlier
we'd
love
to
makes
us
a
priority
in
the
community
meetings,
getting
updates
and
really
making
it
a
priority
in
the
in
this
kind
of
community
discussion
as
well.
C
E
Would
be
great
I
share
that
sentiment,
I
think
the
probably
our
number
one
failing
right
now
is.
We
don't
have
a
single
artifact
that
we
can
share
from
there's.
There's
a
lot
of
anecdote
like
this
works.
This
doesn't.
This
is
broken
I.
You
know.
One
of
our
top
priorities
is
developing
an
artifact
that
everyone
can
have
very
clear
awareness
of
what's
working
and
what's
not
not
just
a
google
but
across
the
community.
J
J
This
needs
the
dovetail
into
the
cig
testing
group
for
a
little
bit
more
discussion,
filling
it
out
absolutely
great,
not
like
there,
because
there
has
been
a
lot
of
tremendous
work.
Bye,
bye,
I
can
Carlin's
bunch
of
other
folks
who
I'm
not
naming
it's
just.
This
is
a
couple
of
guys
who
really
just
want
to
like
make
their
lives
easier
to
the
releases,
go
a
little
bit
more
smoothly
and
I.
Think
what
you
guys
are
talking
about
is
a
longer
term
project
that
needs
a
team
behind
it.
Yeah
yeah.
B
You
know
make
your
reducing
friction
for
contributing
to
open
source
and
the
the
place
where
you
know
we'll
really
be
able
to
help
populate
that
kind
of
upper
triangular
matrix
of
version
compatibility
issues
is,
as
we
bring
more
work
loads
onto
communities
internally.
You
know
our
integration,
testing
pipelines
will
be
producing
bugs
and
we'll
be
sharing
those
and
trying
our
best
to
fix
them
ourselves
as
we
go.
J
Only
other
comment
in
this
regard
is
that
part
of
the
other
reason
I'm
being
noisy
about
this
is
because
I
think
this
may
be
late
to
why
the
e2
ISA
make
you
is
blocked.
I
asked
about
this
last
week
got
an
answer
that
was
like
boy:
we'd
really
love
it
if
he
could
help
out,
but
we
think
we
basically
got
it
fixed
at
this
point
and
every
time
I've
gone
back
to
check
on
my
PRS
they've
always
been
blocked
because
of
the
heat
eq.
J
It's
kind
of
unclear
to
me
like
who
do
I,
hang
of
where
do
I
jump
in
to
help
out,
because
it
still
seems
like
it's
it's
an
issue
and
again
I'm
not
sure
what
the
date
is
for
the
supposed
code
freeze
for
the
one
dot
to
release,
but
it
seems
like
the
submit
Q
is
not
moving
at
a
high
enough
velocity
to
support
that.
No.
H
Concretely,
just
just
so
people
understand
there's
a
couple
of
different
places.
You
can
go
to
look
if
you
look
any
issues.
Every
single
test
of
this
flaky
has
the
flake
mark
on
it.
Many
of
them
are
marked
p0.
Any
of
those
are
fair
game
for
people
to
go
and
take
a
look
in
turn
fix.
That's
you
know.
The
reason
this
make
you
gets
blocked
up
is
because
some
of
the
tests
are
flaky.
Now,
there's
also
problems,
sometimes
with
that
have
to
do
with
the
specific
details
of
the
Jenkins
boxes
that
we
are
running.
H
G
K
G
H
Cause
for
these
things
to
run
slowly
so
and
then,
and
likewise
we
will
make
sure
that
everything
that
is
lgtm
and
ready
to
go
in
goes
in
before
any
sort
of
code.
That's
right,
there's
sort
of
a
grandfathering
of
things
that
are
in
the
cute,
so
don't
I,
wouldn't
I,
wouldn't
worry,
I
mean
and
and
trust
me.
A
A
All
right
well
to
David's
point.
We
have
four
minutes
three
now
and
then
we
have
our
next
meeting
on
just
these
things
internally
and,
of
course,
I
get
the
joy
of
sitting
in
that
now
is
going,
and
how
can
we
pull
in
more
community
members?
How
can
they
help
you,
so
I
will
continue
with
that
charge
and
we
will
talk
about
the
1.2
release
timeline
more
next
week.
That
is
an
item
for
the
agenda
and
I'm
open
for
other
items.
A
F
So,
just
on
the
last
topic,
this
is
the
racking
team.
We've
been
doing
work
to
automate
deployment
on
multiple
platforms,
actually
to
do
a
validation
test,
so
we're
doing
work
like
this,
but
it
doesn't
involve
the
actual
Cooper
Nettie's
test
suite
and
if
there's
a
company
that
wants
to
help
with
that
works.
F
The
key
word
for
us,
we're
tiny,
startup
so
sponsor,
but
it's
work
that
we
were
doing
in
the
open
to
try
and
basically
crank
through
and
Jenkins,
based,
full
deploy,
pipeline
and
test,
and
so
we'd
love
to
be
coordinating
with
with
some
of
the
bigger
names
in
this
on
this
call
who
want
to
help
build
that
infrastructure.
We've
already
got
a
lot
of
pieces
so
so.