►
From YouTube: Data Protection WG's Bi-Weekly Meeting for 20200618
Description
Data Protection WG's Bi-Weekly Meeting for 20200618
A
B
Yeah,
so
this
is
a
I'm
going
to
attempt
to
keep
this
short,
so
we
have
time
for
other
things.
This
is
actually
partially
a
review
of
a
presentation.
I
did
a
couple
months
ago
when
I
introduced
my
vision
for
data
populators,
I've
added
some
slides
and
some
illustrations
to
try
to
help
make
it
clear
and
I've
also
added
a
little
bit
of
new
stuff
at
the
end,
based
on
my
thinking
for
the
last
few
months.
B
B
So
so
in
this
example,
the
user
would
instantiate
the
cr
in
his
namespace
I'm
using
the
default
namespace
here
for
my
illustration,
and
he
gives
it
a
name
and
then,
in
the
next
step
the
user
creates
a
pvc
and
he
populates
the
data
source
field
of
his
pvc,
pointing
back
to
that
instance.
Of
that
hello
object.
B
I
just
call
it
hidden
for
this
example
that
looks
a
lot
like
the
original
pvc.
It
has
the
same
size,
the
same
storage
class,
the
same
volume
mode,
some
other
fields
are
copied
over.
I
set
the
access
mode
to
rwo,
always
and
most
importantly,
I
zero-
I
empty
out
the
data
source
field,
so
so
this
new
pvc
that
I'm
creating
looks
a
lot
like
the
original
pvc,
but
it's
supposed
to
be
empty
and
it's
in
another
namespace.
B
C
D
C
C
B
No,
no,
I
I
I
get
what
you're
getting
at
and
I
have
not
tested
it
and
it
definitely
deserves
testing.
But
I
I
don't
see
any
reason
why
this
scheme
couldn't
be
made
to
work
in
the
bind
on
first
use
case.
As
long
as
we
copy
everything
appropriate-
and
you
know
the
hello
world
populator
was-
was
an
example
and
it
could
be
expanded
to
to
validate
those
kinds
of
of
things
and
say:
yes,
it
actually
does
work.
E
B
B
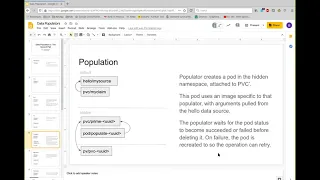
The
external
provisioner
sees
this
new
pvc
prime
creates
an
empty
pv,
it's
not
name
spaced
and
then
the
bind
controller
binds
them
like
it
normally
does
so
so
here's
the
here's
the
population
pod.
So
then
the
populator
will
create
a
special
pod
attached
to
pvc
prime,
using
an
image,
that's
specific
to
the
popular.
That
knows
how
to
do
whatever
it
needs
to
be
done
and
that
part
will
be
constructed
with
command
line,
arguments
that
are
pulled
from
the
original
cr
so
that
it
knows
exactly
what
to
do
so.
B
B
F
B
F
A
B
G
G
E
B
E
B
B
F
B
B
Yeah,
okay,
so
I'll
continue
with
the
the
normal
workflow,
where
we
don't
have
to
worry
about
wait
for
first
consumer,
so
the
populator
then
waits
until
this
populating
pod
succeeds.
If
it
fails
it
just
retries
it
so
we
can
handle,
you
know,
nodes
going
away
or
pods
getting
evicted
or
whatever.
Until
eventually
this
pvc
has
the
right
data
and
then
here's
the
trick
after
the
populator
has
confirmed
that
the
pod
has
successfully
written
whatever
data
needs
to
be
written
into
pvc.
B
Then
we
wait
for
the
blind
controller
to
notice
that
and
update
the
binding.
So
now
the
original
pvc
is
bound
to
the
pv
and
pvc
prime
just
becomes
lost.
This
is
a
state
that
a
pvc
can
go
into
when
the
bind
controller
doesn't
know
what
happened
so
now.
This
pvc
is
just
sitting
there
unattached
to
anything.
B
B
At
this
point,
and
then
I
cover
the
the
last
step
is
usage
where
the
user's
pod
binds
to
the
or
is
attached
to
the
claim,
and
it
does
its
thing
so
so
in
the
case
of
wait
for
first
use,
we
would
have
to
wait
for
this
pod
to
come
into
existence
before
we
did
any
of
the
other
things.
But
that's,
I
think,
a
solvable
problem
and
that's
that's
how
it
works
today.
That's
the
perfect
concept.
It's
it's
a
little
bit
hairy
with.
B
You
know
the
second
name
space
and
the
second
pvc,
but
it
does
it
does
work
and
it
doesn't
require
the
csi
drivers
to
know
anything
at
all
about.
What's
going
on
they
just
they
say:
oh
I'm
creating
an
empty
volume.
Okay,
that's
fine,
and
they
do
it.
The
other
things
I
wanted
to
talk
about
is
error,
handling
and
sorry.
This
is
just
a
wall
of
text.
B
So
when
we
added
the
any
volume
data
source
feature
gate
in
118,
we
kind
of
removed
some
of
the
validation
that
no
longer
made
sense
with
this
new
feature
gate.
What
that
means
now
is
like
nothing
is.
If
you
put
garbage
into
the
data
source
field,
nothing
is
going
to
tell
you
that
you
put
garbage
in
there
and
the
system
will
just
hum
along
happily.
B
So
normally
the
thing
that's
responsible
for
giving
you
feedback
is
the
external
provisioner,
sidecar
it'll,
look
at
what
you
put
in
the
data
source
and
it'll
say:
oh,
I
see
you.
This
is
a
snapshot.
Oh,
this
snapshot
doesn't
exist
yet,
therefore
I'll
post,
an
event
that
says
the
snapshot
doesn't
exist.
Yet
I'm
waiting.
B
If
we
presume
that
you'll
always
install
the
populator
sort
of
controller
alongside
the
crd
that
that
specifies
a
certain
type
of
data
source,
then
the
existence
of
the
crd
could
be
a
signal
to
end
users
that
the
populator
is
there
and
that
it
works.
You
know
if
the
populator
hasn't
been
installed,
the
crd
wouldn't
be
there
and
then
attempts
to
create
instances
of
that
data
source
would
simply
fail
because
cube
api
server
would
say.
I
don't
know
what
that
is
and
and
that
that
might
be
good
enough.
B
B
E
E
B
Or
we
could
at
the
time
we
installed
this
new
crd,
just
create
one
for
volume,
clones
and
create
one
for
snapshots.
That's
true
have
them
there,
there's
no
reason
we
can't
just
I
mean
even
if
they
get
ignored,
they
can
just
be
there
or
maybe
in
the
future.
We
would
want
to
decompose
the
external
provision
or
sidecar
even
more,
so
that
those
jobs
would
be
outsourced
to
something
else.
B
Potentially
I
don't
know
my
last
slide
real
briefly,
because
I
know
we're
running
a
little
short
on
time
is
about
csi.
So
this
whole
presentation
has
been
about
the
subject
of
generic
data
populators.
You
know
populators,
where
you
can
just
write
a
pod.
That
just
does
the
work.
You
don't
need
to
know
anything
about
the
the
guts
of
the
storage
underneath
we,
as
we
all
know
that
there
are
certain
types
of
things
where
you
you,
the
the
storage
underneath
has
to
be
involved.
B
So
the
storage
controller
can
do
some
smart
version
of
restoring
a
backup,
but
you
also
want
a
way
to
just
have
it
work
generically
so
that
so
that
for
certain
for
csi
drivers,
that
don't
support
that
specific
type
of
thing,
you
have
a
sort
of
a
fallback
way
of
handling
it,
and
so
what
I'm?
I
have
another
poc
that
I
did.
B
You
know
figuring
out
what
that
protocol
is
for,
should,
should
it
be
done
through
csi,
or
should
it
be
done
through
the
generic
populator,
so
I
just
want
to
throw
that
out
there
that
I
believe
this
is
still
a
solvable
problem.
Even
with
this
external
populator
approach,
you
just
have
to
do
it
on
a
crd
by
crd
basis
and
then
put
the
logic
into
the
external
provisioner
sidecar.
B
B
And
so
when
we
define
with
those
those
rpcs
and
I
have
a
prototype
that
works,
you
know
you
would
have
some
other
things.
That
would
give
it
enough
information
to
to
query
and
say:
do
you
support
this
and
if
it
says
yes,
you
would
do
it
and
if
it
says
no,
you
would
say:
okay,
I'm
going
to
let
somebody
else
do
it,
and
that
would
just
be
part
of
the
the
new
csi
rpc.
For
that
type
of
thing.
A
A
B
Well,
I
mean
but
you're
going
to
have
a
you're
going
to
have
an
object
in
kubernetes
that
refers
to
the
backup
that
has
whatever
metadata
is
necessary
to
understand
where
it
is
what
it
is,
how
it
is.
You
know
all
that
stuff
you
should
be
able
to
get
from
what's
in
kubernetes
and
then
the
theory
is,
is
you
could
have
a
some
sort
of
a
query
mechanism
or
a
test
that
the
external
provisioner
calls
the
driver
and
says?
B
G
H
B
That's
all
that
the
that
the
external
provisioner
has
to
go
on
at
that
point
is
it's
looking
at
a
data
source
field
of
a
pvc
and
it
has
an
api
group
and
a
kind
and
a
name,
and
so
it
looks
at
the
api
group
and
the
kind
and
says
I
don't.
I
don't
know
how
to
handle
this
because
I
only
know
snapshots
and
volumes.
So
I
need
to
go
see
if
someone
else
knows
what
this
is.
E
Approach
is
that
you
can
point
a
data
source
to
a
pvc
to
no
data
source,
and
so
now
you
have
the
ability
to
differentiate
between.
I
have
created
a
pvc
and
it
has
a
data
source,
but
I
didn't
really
create
the
cr
crd
for
that
data
source.
Yet
so,
please
hold
off
on
making
this
volume
available
to
the
consumer,
so
there's
no
kind
of
races
there.
B
B
Yeah
so
like
for
for
the
hello
world
populator,
all
you
would
do
is
you
would
have
one
instance
of
the
crd
that
says
you
know.
Api
group
is
hello
and
then
a
kind
is
hello
world
or
whatever.
I
forget
what
I
use,
but
you
know,
and
that
would
be
all
and
and
then
and
then
the
external
provision
would
say.
Okay,
if
I
see
one
of
these,
I'm
going
to
just
say
that's
fine,
and
if
I
see
something
that
I
that
that's
not
registered,
I
will
report
an
error
and
say
this.
B
F
B
F
B
F
B
F
B
In
in
the
in
the
pve
c
instance,
yeah
there's
the
name
and
the
populator
will
actually
go,
read
that
and
then
see
that
it
exists.
But
you
know
you
have
these
situations
where
you
create
the
pvc
first
and
then
the
data
source
second,
and
so
the
first
time
that
the
populator
sees
it
it'll,
say:
there's
nothing
with
this
name
and
it'll
put
an
event
out
on
the
on
the
pvc
and
then
later,
when
the
user
actually
instantiates,
that
the
source
and
it
retries
it'll,
say:
oh
now,
it's
there
now.
B
B
G
B
B
G
B
Think
we
could
go
either
way
on
that,
but
the
pattern
so
far
has
been
to
just
keep
adding
to
the
external
provisioner
sidecar.
As
we
add
new
things,
you
can
create
volumes
from
and
the
only
thing
that's
new
with
the
data
populators
is
like
this
doesn't
require
csi
at
all,
so
it
doesn't
make
any
sense
to
put
anything
in
the
external.
A
I
think
that
how
we
do
this
restore
right.
So
if
we
just
say
a
very
simple
process,
just
say:
create
a
voting
firm
back
up
just
like
one
step
thing
that
maybe
makes
sense
to
add
it
in
the
next
existing
external
provisioner.
But
it
involves
more
steps
than
probably
need
to
be
handled
by
separate
controller.
A
B
A
E
E
B
B
A
So
the
next
one,
so
we
just
we
want
to
give
an
update
on
the
container
notifier
proposal.
We
talked
about
it
before
so
we
had
a
meeting
with
the
sig
node
this,
and
one
alternative
suggested
from
that
meeting
is
to
have
a
way
to
probe
what
happens
to
the
container
notifier.
So
this
is
the
the
proposal.
I
think
we
went
through
this
one
last
time
and
then
I
just
want
to
go
through
and
share
with
you
what
comments
we
got
so
what
update
we
have
done
so
far.
A
So
so
the
comments
I'm
getting,
I
think,
there's
one
comment
was
saying,
because
initially
we
had
a
container
notifier
probe
paired
with
the
content,
notifier
action,
so
team
was
saying
that
well,
actually,
the
probe
will
need
different
ways
other
than
just
this
exact.
We
should
also
allow
http,
so
there's
actually
already
a
existing
probe
struct
here,
so
we
can
just
go
ahead
and
use
it.
We
don't
have
to
invent
our
own,
so
this
one-
you
see
this
pro
this
in
the
core
api.
A
A
Time
that
you
can
define
so
initial
delay,
how
you
know
the
time
that
you
want
delay
before
you
start
to
to
check
this
and
then
the
timeout,
how
often
to
do
the
probe
successful,
so
you
run
it
once
you
think.
That's
that
means
it's
successful.
You
or
you
need
to
run
multiple
times
so
for
us.
I
think
this
one
should
be
enough
and
minimum
failure.
So
so,
if
you
run
the
several
times
how
how
many
times
you
try
and
then
you
you
declare
that
okay
failed,
it's
it's!
A
A
So
this
is
a
team
suggestion.
I
think
initially
this
one
was
saying
it
must
be
a
dns
label.
So
here
this
change
here
is
that
we
can
have
some
well-known
names
that
does
not
have
any
prefix
so
like.
So,
for
example,
if
you
want
to
say
choice,
this
is
a
well-known
reserved
names,
so
we
can
have
that.
But
then,
if
we
want
to
define
customized
ones,
then
you
can
just
have
a
prefix.
You
can
have
a
you
know
the
previous
exam
example.com
and
then
your
label
style
name
for
this
notifier.
A
So
when
user
created,
this
notification
object
to
request
a
container
notifier,
will
you
know
the
it
can
get
back
the
notification
status
from
kublet?
So
initially
we
just
have
this
defined
as
conditions,
but
actually
because
the
this
we
can
actually
have
multiple
containers
within
the
pod.
That
has
the
same
notifier
name,
because
in
that
case
we
just
send
this
request
once
all
of
them
were
run,
but
our
status
did
not
really
consider
those
in
at
least
in
our
previous
proposal.
A
This
is
just
like
one
one
status
there's
no
way
to
differentiate
whether
it
is
successful
for
one
container
and
filled
on
the
other
or
not
so
so.
This
is
the
new
notification
status.
This
is
actually
from
our
previous
proposal
for
the
execution
hook.
We
have
the
some
similar
type
of
status
like
this,
so
here,
instead
of
just
one
single
status,
we
would
have
a
list.
So
we
will
have
an
array
of
container
notifications
status
and
each
container
notification
status
will
have
a
pawn
name
container
name
and
then.
A
Whether
whether
it
is
successful
or
not
and
error,
and
and
then
when
it
has
started
so
we
have
all
of
this-
and
we
can
know
whether
whether
it
is
successful
in
a
particular
container
or
not,
and
then
based
on
that
the
vancouver
can
retry
only
the
ones
that
have
failed
instead
of
retry
everything.
So
that's
that's
the
change.
This
actually
makes
this
proposal
a
little
bit
more
complicated.
A
A
And
other
than
that,
we
still
have
not
really
reached
the
consensus.
Yet
so
here's
some
comments.
Basically,
this
is
from
seth,
basically
thinking
that
he
basically
does
not
agree.
That
cubelet
must
be
the
one
that
is
running
this
command,
but
not
he
does
not
agree
the
assumptions
that
we
make
that
if
cubeless
cubelet
is
the
one
running
this
it
will
be
safer.
A
Then,
if
we
like
let
an
external
controller
around
this
using
the
exact
sub
resource,
so
that
I
think
the
mainly
that
so
he's
that's
actually
the
this
is
actually
from
the
signal
side.
That
was
what
we
got
last
time
as
well.
They
are
still
not
quite
sure
about
this
approach,
so
we
need
to
have
an
another
meeting
to
discuss
and
hopefully
to
make
some
progress.
D
A
Yeah
definitely
definitely
yeah.
I
can
definitely
see
that
yeah.
If
it's
just
up
to
me,
I
would
be
thinking.
We
don't
really
need
this
probe,
because
because
we
do,
we
already
have
the
status
in
you
know
this
is
actually.
This
is
not
even
the
probe
part.
This
is
the
we
are
here.
We
are
only
talking
about
the
the
first
container,
notify
notify
action.
Part
right,
so
we
get
all
of
the
status
already
tells
us
whether
it
is
successful
or
not.
A
A
So
they
want
to
be
able
to
have
a
reliable
way
to
check,
but
it's
yeah
you
can
see.
I
can
see
that.
Definitely
this
it's
going
to
take
longer
right
because
you
you
want
a
choirs
to
be
really
quick.
You
don't
want
to
wait
for
that
long.
But
then,
if
we
do
this
way,
you
first
you
first
basically
run
the
command
in
container.
Notify
action
and
then
we're
checking
the
status
retry.
A
So
then
finding
that
return
success
and
then
you
still
need
to
make
another
call
using
a
probe
and
then
wait
for
that
to
come
back
right.
So
yeah
I
mean,
in
my
opinion
this
is
not
really
necessary,
but
we
are
trying
to
address
their
concerns,
but
also,
I
think,
probe
is
optional.
It's
just.
We
need
to
provide
something
like
this,
so
if
it
is
provided
then
then
cubelet
will
run
those
but
yeah,
but
I
can
definitely
see
the
overhead
that
we
add
that
we
are
adding
to
kubelet.
G
A
Initially
would
just
say:
okay,
we
we're
going
to
call.
We
always
just
make
this
one
call
to
all
the
containers
that
has
this
notifier,
but
now
we're
saying:
okay,
we
are
only
calling
the
specific
ones
right.
So
that
part
then,
basically
couple
it
well,
you
have
to
differentiate,
then
that's
something
extra,
so
yeah.
So
that's
what
we
have
so
far.
A
A
A
There
are
different
options
when
you,
when
you
create
a
working,
the
volume
group
and
then
different
story,
vendors
may
support
different
things,
so
we
did
get
some
some
feedback.
We
got
this
from
tom
and
I
think
mainly
from
tom
and
then
I
think,
there's
one
thing
that
I'm
still
not
quite
sure
about.
I
think
this
that's
this
part.
I
was
just
reading
it
before
the
meeting
for
the
for
the
restore.
There
will
be
multiple
possibilities.
A
Group
snapshot
returned
only
one
group
snapshot
id,
but
not
individual
snapshot.
Ids
there
is,
must
be
via
group
snapshot
id.
I
don't
think
I
address
this
one
in
the
in
updated
cap
and
then
well.
The
second
one
is
the
uk
stand.
You
have
individual
snapshot
ids,
so
remember
this
one.
Is
this
one
brought
up
by
ben?
I
believe
right
ben.
Are
you
still
there.
A
Yeah,
so
I
was
just
having
a
question
because
I
actually
forgot
this
one
when
I
was
updating
the
cabin-
and
I
just
noticed
this
one
before
today's
meeting.
I
just
wanted
to
get
more
information
from
you.
I
think
this
one
so
for
some
stretch
systems
when
they,
when
they
create
a
group
snapshot
after
that's
created,
it
can
only
retain
a
group
snapshot
id,
but
not
individual
snapshot
ids.
I
think
this
is
a
scenario
you
brought
up
right.
A
A
B
B
B
G
A
A
A
A
A
B
A
And
then
but
you're,
but
you
do
have
10
only
handles.
I
guess
that's
my
I'm
confused,
so
you
you
can
still
I
so
I
think
you
can
still
have
those
you
may
not
use
them.
I
I
think
what
I'm
trying
to
understand
is.
I
think
you
may
not
need
to
use
them
during
the
during
the
restore
you're
saying
that
you
you
don't
want
to
like
create
one.
I.
B
B
A
B
A
B
B
You
get
a
snapshot
of
both
things
and
and
again,
and
we
do
that
because
it's
cheaper
in
this
in
in
the
in
how
much
memory
and
cpu
it
consumes
on
our
storage
controller,
if
you
group,
multiple
ones
together
on
the
same
volume
you
get
economies
of
on
cpu
memory
and
and
it
allows
us
to
get
larger
numbers
of
ones
in
the
end.
So
for
people.
A
B
Yeah
yeah
because
they're
independent
things
with
independent
lifetimes
and
independent
users,
they
could
be,
they
could
be
owned
by
different
different
users.
In
different
name
spaces.
They
can
be
deleted,
deleted
and
resized
independently.
All
the
things
you
can
do
normally
exist,
except
for
snapshots.
What
we
can't
do
is
take
a
snapshot
of
just
one
of
those
things.
B
A
A
But
but
if
we
let's
say
if
at
restore
time,
if
we
also
need
to
accommodate
that
and
also
come
update
the
other
case,
then
that
means
we
okay.
So
that
actually
means
we
need
to
create
a
create.
A
pv,
let's
say,
create
a
volume
group
and
and
have
a
source
as
a
group
snapshot
and
then
do
that
in
just
like
in
in
one
shot.
One
step.
G
A
Think
we
just,
I
think
we
removed
that.
I
think
I
just
removed
that
because
it's
like
more
complicated,
at
least
I'm
thinking,
maybe
the
first
step.
We
don't
do
that
if
it's
actually
workable
and
that's
also
not
the
not
like
most
people
probably
is
not
in
that
situation,
because
otherwise
we
have
to
support
both
right.
Then
that's
more
complicated.
I
guess.
B
Is
anything
that
that
puts
that
makes
assumptions
about
how
the
storage
controller
does
what
it
does,
but
unfortunately
like
if
you,
if
you're
too,
if
you're
too
relaxed
about
it,
then
then
nobody,
then
it
makes
it's
not
us.
It's
not
useful.
So
you
have
to
make
some
assumptions
somewhere
about
you
know.
Well,
either
these
things
are
mutable
or
they're,
not
mutable,
or
I
can
restore
them.
One.
B
A
Right
so
I
was.
This
is,
of
course,
not
really
based
on
what
we
already
done
right
in
cinder
and
also
in
manila.
I
think,
and
so
so
I
always
thought
number
two
would
work.
So
I'm
thinking
that
I'm
leaning
towards
we
will
start
with
this,
and
then
you
know,
if
in
the
future,
need
to
do
the
second
this
one
then,
but
I
think
I
still.
I
still
need
to
think
more
about
how
how
the
controller
is
going
to
handle
this.
B
A
Well,
we'll
have
scoop
step
shelf
because
otherwise
this
then
what's
the
point
of
having
this
kappa,
so
we
need
to
have
a
group
center.
I
was
talking
about
restore
I'm
only
talking
about
restore
time,
so
maybe
I
didn't
we
can
talk
more.
I
think
we
are
almost
out
of
time.
We
can
talk
more
tomorrow
and
let
me
think
about
this
one,
a
little
bit
more.
I
was
just
thinking
about
this
like
when
you
restore.
F
B
A
Right
yeah,
so
yeah.
I
think
it's
also
think
about
you
know
like.
If
we
have
to
support
all
the
cases,
then
maybe
it's
at
least,
especially
in
the
beginning
right
when
you
try
for
initially
trying
to
together
proposal,
you
want
to
do
everything,
then
it's
getting
really
really
complicated,
so
yeah.
So
let's
talk
more
about
that
in
tomorrow's
meeting.