►
From YouTube: Kubernetes Data Protection Workgroup Meeting 20210210
Description
Kubernetes Data Protection Workgroup Meeting - 10 February 2021
Meeting Notes/Agenda: -
Find out more about the Storage SIG here:
https://github.com/kubernetes/community/tree/master/wg-data-protection
Moderator: Xing Yang (VMware)
A
A
A
B
B
B
I
think
we
can
put
it
on
the
chat
on
the
share
doc
for
everyone
to
lead
it
in
later.
If
you
like
today,
I
will
present
how,
in
this
portion
of
the
designer
that
specified
on
how
a
backup
workflow
would
do
this
cbt
service,
that
we
propose
here
the
cbt
api
that
we
propose
here
to
make
a
backup
efficiently
or
make
a
visual
or
efficiently
right.
So
the
the
step
of
detail,
the
detail
step
is
all
right
here,
but
to
make
it
more
interesting,
I
did
a
quick
animation
of
it.
B
So
let
me
present
it
in
the
animation
fashion
to
make
it
more
fun.
So
this
is.
Can
you
see
the
the
slide
now?
Yes,
okay,
so
this
is
a
typical
uses
of
a
block
device
right.
So
when
we
have
an
application
part,
that's
using
a
block
device,
what
it
does
is
it
create
a
pvc
and
a
pv
associated
with
that
and
you
can,
on
the
back
end
on
the
started
back
end.
This
pv
is
mapping
to
a
block.
C
B
B
B
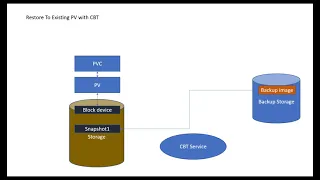
Then
the
backup
workflow
does
next
is.
It
will
create
the
pvc
with
the
snapshot
volume
as
the
source
of
the
pvc
of
the
data
source,
and
it
will
mount
this
pvc,
the
new
p,
the
pvc
that
is
created
into
like
a
pod
or
something
to
start
backing
it
up
this
pvc,
the
entire
pvc
right.
So
this
is
a
typical
workflow.
This
is
very
inefficient.
B
Is
that
because
it
mounted
and
it
backup
entire
pvc,
even
though
only
a
few
blocks
here
and
there
have
changed
so
at
this
point,
we
if
we
know
that
the
previous
backup
exit
and
the
previous
backup
was
mapping
with
the
let's
just
say,
snapshot
zero
right
now
now
we
know
that
the
curtains,
the
current
backup
is
associated
with
snapshot.
One
and
a
previous
backup
is
associated
with
snapshot
zero.
At
that
point,
the
backup
solution.
Instead
of
backup
everything
what
it
does
is,
it
will
communicate
with
this
tpg
service.
B
Providing
these
two
snapshot
id
snapshot,
zero
and
snapshot,
one.
It
will
return
back.
It
got
back
a
list
of
chain
blocks
between
these
two
snaps
on
it.
So
then,
instead
of
backup
everything,
it
will
then
only
backup
the
blocks
that
change,
and
this
reduce
the
backup
efficient.
I
mean
introduce
the
number
of
blocks
that
they
need
to
back
up
significantly
and
on
the
the
chain
list
that
we
have
here.
So
this
is
the
backup
workflow
of
and
one
of
the
most
important
thing
in
this
backup
image.
B
Is
that,
because
each
of
these
backup
images
now
have
to
store
additional
all
the
blocks
that
it
has
for
the
data
which
also
store
the
snapshot.
Information
right,
this
snapshot
information
is
very
critical
in
the
restore
step
and
and
how
to
see
this
syntax
type,
because
each
of
these
backup
image
now
is
not
a
full
backup
image.
It's
only
have
a
certain
lot
that
chain
so
in
order
to
con
construct
reconstruct
the
full
image.
The
backup
storage
vendor
need
to
have
a
way
to
re-synthesize
this
whole
disk.
B
Using
this
block
and
the
previous
backup
image
right
so
most
of
the
vendors
already
have
that
way.
For
example,
in
for
data
domain
right
dot
domain,
which
currently
emc
we
have
data
data
domain
and
that
domain
already
have
all
of
these
way
to
synthesize
these
blocks
from
previous
image
and
so
on
and
so
forth.
So
these
are
vendor
specifics.
I
will
not
talk
about
here.
B
So
let's
talk
about
two
resource
scenario.
The
first
restorative
scenario
is
to
restore
entire
disk
from
scratch
and
and
restore
to
a
new
disk
completely
right.
So
this
typical
workflow
for
this
one
would
be
now
we
have
a
backup
image
in
the
backup
storage
right.
What
we
does
is
we
create
a
new
persistent
volume
right
and
a
pvc
associate
with
it
and
on
the
back
end
they
will
the
back
end.
B
Storage
will
create
some
started
block
device
associated,
and
then
we
use
we
mount
this
restore
pvc
on
either
a
restore
port
or
similar
fashion.
Then
we
read
block
from
blocks
all
the
blocks
from
the
backup
image
to
this
restore
pvc
right.
This
is
a
normal
workflow
right.
However,
because
remember
this
is
the
cbt
backup.
We
don't
have
the
full
image
in
this
folder
and
oh,
we
do
not
have
all
the
blocks
in
this
backup
image.
B
What
we
need
to
do
is
we
need
to
somehow
synthesize
it
from
the
with
the
previous
backup
that
the
backup
image
was
based
on.
So
that
way
we
can
have
a
full.
All
of
the
blocks
belong
to
this
pvc
so
again
the
way
to
synthesize.
This
is
vendor
specifics.
I
will
not
talk
about
here.
So
after
the
pvc
have
been
restored,
we
unveiled
it
and
restart
the
application
start
the
application
with
the
with
the
pvc.
So
now
we
go
back
to
the
inside.
The
whole
function
functioning
application
with
all
the
data
being
restored.
B
B
We
want
to
take
advantage
advantage
of
this
cbt
technology,
this
lgbt
api
here
right.
So
the
way
we
do
that
is
that
we
know
that
the
the
the
backup
image
that
we
have
from
two
days
ago
is
associated
with
snapshot
zero
right.
That
is,
that
information
is
being
stored
in
the
backup
image,
and
so
what
we're
going
to
do
next
is
we
first.
B
B
So
let's
just
say,
if
we
don't
have
a
way
to
nicely
share
the
pvc
right
there
right
two
parts
riding
into
the
same
pvc
at
the
same
time,
if
we
don't
have
a
nice
way
to
do
it,
the
first
the
safe
way,
which
is
just
mounted
right
and
what
we
do
next
is
we
take
the
snapshot
of
the
curtain
situation
like
the
curtain.
This
uses
right
now
we
take
a
snapshot
of
it.
Let's
call
it
snapshot
zero
right,
then
we
have
now.
B
B
The
cbt
service
will
provide
us
with
a
bunch
of
block
that
different
between
these
two,
the
difference
between
the
previous
snapshot
and
the
current
snapshot.
So
what
we
do
is
we
will
reform
the
backup
image.
Only
the
block
that
is
different
between
the
previous
backup
and
the
current
time
only
those
shoe
as
a
consequence.
Instead
of
restore
the
entire
image
from
the
previous
basket,
we
only
might
need
to
restore
a
few
blocks
like
the
blocks
that
actually
change
between
the
backup
time
and
the
current
time.
B
B
B
Only
see
in
store
a
few
blocks,
the
there's,
a
one
thing
that
I
want
to
point
out
here
is
the
block
that
chain
between
the
previous,
with
between
the
backup
image
and
the
current
time.
The
block
that
change
may
not
belong
to
the
backup
image
at
let's
just
say
two
days
ago,
but
it
that
block
may
belong
to
the
data
may
belong
to
you
know
the
backup
image
10
months
ago,
and
the
backup
sorted
will
have
the
way
to
the
backup
start.
B
Vendor
will
have
a
way
to
provide
the
the
specific
block
for
that
resource
task,
and
that
again,
is
the
vendor
specific.
So
I
don't
want
to
import
it
down
here,
but
I
just
want
to
point
out
so
to
make
sure
that
to
we
have
be
aware
that
the
backup
image
at
the
specific
time
may
not
contain
all
the
blocks
that
you
need.
You
might
have
to
combine
it
with
the
previous
backup
image
to
got
all
the
blocks
at
a
specific
time.
B
F
I've
got
a
question,
I'm
curious
like
it's.
It
feels
like
this
solution
relies
on
the
ability
to
mount
any
given
volume
as
either
a
file
system
volume
or
a
raw
block
volume,
because,
or
I
mean
assuming
you
assuming
the
pod,
the
application
pod
is
consuming
a
file
system
volume
to
be
able
to
do
the
change
block
tracking.
You
need
to
be
able
to
get
behind
the
file
system
and
access
the
blocks
which,
like
in
general,
you
know
in
kubernetes
at
least
volume
is
always
either
a
file
system
volume
or
a
raw
block
volume.
F
B
F
Well,
I
guess
yeah
I
want
to
understand
like
for
the
for
the
thing
that's
doing
the
the
actual
reading
and
writing
of
the
blocks
from
the
volumes
whatever
that
is,
it
needs
raw
block
access
to
the
volume,
regardless
of
what
is
actually
up
above
right.
Yes,
okay,
so
is
that
is
that
another
kubernetes
pod?
That's
doing
that?
Are
you
presuming
the
existence
of
something
else
that
can
perform
direct?
I
o
on
the
volume
that's
outside
of
kubernetes.
B
D
F
H
F
F
F
F
I
thought
that
kubernetes
had
protections
or
sorry
csi
protection,
so
if
a
volume
has
a
file
system
mode
or
whatever,
we
call
it
the
csi
layer
and
you
take
a
snapshot
of
it
and
then
you
later
try
to
turn
that
snapshot
into
a
raw
block
volume
that
you
would
be
prevented.
For
some
reason,
I
might
just
be
hallucinating
that
maybe
that
doesn't
exist.
I.
A
B
B
Just
to
have
experiment
on
one
of
our
dell
storage
is
power
effects
and
we
have
done
experiment
using
so
the
left
hand
side.
The
pvc
on
the
left
is
a
file
system,
but
in
the
back
end
is
the
device
we
create
a
snapshot
of
it
and
then
on
the
restoring
path.
We
use
the
pvcs.
We
create
a
new
pvc,
but
this
pvc
is
not
a
file
system.
B
A
A
B
C
B
Can
in
theory
we
can
because
if
we
do
in
the
restore
data
we
don't
go
diverse
direction.
Eventually,
we
end
up
with
a
block
device
on
the
back
end
here
right,
then
we
can
create
the
five
pvc
file
system
pc
using
that.
But
again
I
have
I
I
haven't.
Personally
I
have
an
experiment
that
so
I
cannot
say
for
sure.
C
C
F
A
A
B
F
A
C
Is
clear,
I
think
the
code?
Okay,
it
should
be
backed
by
a
block.
But
yes,
the
point
here
is
at
a
user
level
right,
I'm
creating
a
persistent
volume
type
file
system
and
then
for
my
backup,
I'm
creating
a
the
first
thing
I
do
is
create
a
volume
snapshot
right,
that's
the
first
thing
I
have
to
do
after
creating
the
snapshot.
The
next
step
shows
create
a
pvc
from
that
snapshot.
C
B
B
A
A
E
E
Okay,
if
there
are
no
objections,
so
basically,
what
you're
proposing
is
that
we
want
to
make
a
distinction
between
snapshots
and
backups
right
in
a
way,
snapshots
are
a
baseline
for
backups,
but
backups
through
the
cbt
service.
We
want
to
make
it
more
efficient
by
just
setting
the
deltas,
that's
basically
the
gist
of
what
you're
proposing
right.
Yes,
so
so
that
leads
to
a
few
questions.
One
is
basically
we're.
Gonna
expose
backup
as
a
new
through
new
api,
as
opposed
to
leveraging
existing
snapshot.
Apis
is.
A
B
A
A
B
B
E
B
B
It
should
work
with
your
existing
backup,
workflow
right,
if
you
don't,
if
you
want
to
spend,
send
out
all
of
the
blog
to
the
backup
store
that
you
can
go
ahead
and
do
it.
But
if
you
want
to
do
it
more
efficiently,
you
might
only
need
to
send
the
block
you
want
to
only
need
to
back
up
the
block
that
chain.
B
B
C
B
C
C
I
E
I
guess
you
know.
Basically,
the
model
we're
assuming
here
is,
for
example,
look
for
cloud
type
volumes
library
when
you
do
a
snapshot
that
implies,
you
know,
pushing
the
volume
data
to
an
object
store.
You
know
for
those
type
of
things
for
those
type
of
backhands,
where
the
snapshots
are
remote,
copies,
we're
going
to
be
ending,
ending
up
with
two
copies
one
generating
by
the
snapshot
by
the
csi
plugin
that
generates
a
snapshot
and
one
by
this
backup
service
that
does
its
work
behind
the
scene
right.
Oh,
I.
A
A
E
So
basically
I
mean
given
that
for
each
backup
there
is
a
corresponding
snapshot
right
most
likely
when
a
disaster
happens,
we're
gonna
use
the
snapshot
copy
for
restore.
Unless
you
know
that
restore
copies
that
snapshot
copy
is
gone,
so
we
have
to
restore
from
the
backup
site
right
and
my
question
is:
how
does
cbt
get
involved
during
the
restore
workflows,
because.
E
H
E
Right,
but
my
point
is
this:
let's
say
I
mean
obviously
like
this
whole,
the
main
benefit
of
the
cbt
service
is
that
you're
only
sending
the
deltas
right
when
the
backup
happens,
so
the
backup
happens
faster
right
and
it's
also
more
space
efficient
on
the
right.
You
know,
so
there
is
a
trade-off,
because
when
we
do
restore,
we
also
have
we
don't
pull
all
the
data
right
away.
All
the
data
is
not
available
right
away.
We
just
have
to
incrementally
pull
them
right
from
from
the
backup
source.
No,
I
think
that's.
A
E
A
A
A
I
don't
know
whether
we
want
to
like
accommodate
both
in
the
same
solution,
not
sure
yeah,
but
I
definitely
that
that's
also
useful
right,
because
then
that
way
you
can
actually
restore
quickly
if
you
still
have
your
local
snapshot.
Of
course,
that's
much
quicker
than
you
have
to
download
from
someplace
else.
B
I
think
the
the
the
scenario
that
got
mixed
up
a
little
bit
here
is
that
we
formed
his
questions.
We
always
have
two
separate
device
right:
the
the
backup
storage
device
and
the
curtain
storage
divide
that
the
customer
might
have
in
you
know
to
do
the
production
environment
right.
So
these
of
the
when
we
restore.
We
assume
that
the
backup
vendor
was
able
to
synthesize
all
the
blocks
belong
to
a
certain
backup
image.
They.
B
We
assume
that,
because
a
lot
of
mac
vendor
providing
that
service
right
now
is
data
domain
is
one
of
those
that
I
use.
I
think
aws
also
have
the
way
to
synthesize
your
whole
disk.
It's
just
a
bunch
of
blocks
right
so
and
then
your
question
relates
to
how
the
cbt
being
testing
advances
here.
If
we
restore
the
entire
pvc,
then
the
cpt
does
not
provide
any
advantage
here
at
all.
It
just
copied
all
the
block.
Def
of
the
block
from
the
backup
started
back
to
the
storage.
B
So
only
these
few
blocks
will
be
restored,
and
then
you
can
go
back
to
your
yesterday
image
very
quickly.
Instead
of
restoring
two
terabyte
data,
you
only
need
to
restore
a
few
blocks
end
up
with
a
few
megabytes
that
you
can
have
your
production
environment
back
and
running
within
a
few
minutes.
Instead
of
a
few
hours
of
restore.
E
Yeah,
the
part
that
doesn't
make
sense
to
me
is
this,
so
I
mean
I
think
we
should
talk
about
also
the
restore
workflows.
So
let's
say
from
the
kubernetes
point
of
view:
if
I
want
to
do
a
restore
restore
volume,
I
would
imagine
what
are
you
proposing
to
have
like
a
new
volume
source
which,
instead
of
a
snapshot,
is
like
a
backup
image
or
are?
Are
we
still
relying
on
leveraging
the
same
snapshot
as
the
source?
Look
first,
what's
the
workflow
here.
H
C
H
So
yeah
so
I
mean
so
it's
a
part
right.
That
will
be.
Finally
writing
it.
So
you
create
a
new
pv
on
this
new
storage
and
then
pvc
and
then
mount
it
to
a
pod,
and
this
port
can
now
go
read
from
the
backup
storage.
I'm
guessing
the
pod
will
be
from
the
backup
vendor.
It
will
go
read
from
the
backup,
storage
and
right
to
this
tv.
So.
C
C
H
H
C
H
J
J
I
I
kind
of
agree
with
the
with
the
previous
point,
where
the
restoration
cases
may
not
necessarily
fit
into
the
efficiency
piece.
The
efficiencies
may
not
necessarily
fit
into
the
restore
case,
especially
for
when
you
lost
the
whole
storage
system,
because
that
way,
you
know
you
might
will
have
your
snapshot
already
ready
on
the
snapchat
system.
Why
do
you
even
bother
to
copy
the
change
blocks.
J
A
Yeah,
I
think
change
block
is
mainly
for
the
backup
about
top
time
is
faster
at
the
restore
time
you
would
still
have
to
well.
I
think
I
I
think
fun
also
mentioned
some
like
incremental
restore
some
time
ago,
right
if
it's
like,
if
your
production
system
is
still
there,
maybe
you
just
want
to
roll
back
something
like
remember.
He
mentioned
something
like
that,
but
if
you
really
have
lost
everything
you
have
to
start
from
scratch.
Of
course
you
have
to
do
a
full,
restore.
E
A
A
B
Actually
true
that
if
we
lost
everything
and
there's
no
there's
no
efficient,
there's
no
way
to
can
use
the
cbt
service
here
to
do
anything.
This
is
restore
everything
right,
although
this
is
like
an
incremental
restore
instead
of
you.
So
everything
if
you
only
need
to
your
system
is
running,
but
you
only
need
to
revert.
You
know
one
one
part
from
today
due
to
previous
day
right
with
the
better
of
yes
yesterday.
Well,.
A
C
E
I
guess
the
bigger
question
is
this:
like
whether
these
backup
images
are
going
to
be
like
some
standard
format,
because
if
it's
a
standard
format,
then
you
can
have
a
generic
cbt
service
that
can
handle.
You
know
different
kinds
of
volumes,
but
if
the
backup
image
is
a
proper
proprietary
and
each
backup
vendor
has
its
own
image,
then
each
backup
vendor
is
going
to
have
their
own
cpt
service
and
then
I
think
that's
going
to
be
an
issue.
Look
what's
the
plan
here.
I
think
we're.
B
B
Aws,
microsoft,
azure
and
we
be
proposing
this
cbt
api
here,
and
this
only
spelled
out
the
change
on
a
certain
offset
to
a
specific
size.
So
this
is
the
list
of
chain
each
of
the
block
which
is
on
this
file.
There
are
the
offsets
and
the
size
and
and
the
we
do
not
touch
how
the
backup
image
is
format.
That's,
except
to
the
backup
vendor.
E
I
I
A
B
Oh,
I
think
you
are,
I
think
what
you
meant
is
like,
for
example,
the
chain
block.
Let's
just
say
I
have
this-
that
block
number
five
in,
but
the
block
in
the
new
block,
the
new
data
and
now
is
o
zero,
so
instead
of
the
vendor
have
to
copy
a
new
block
that
contains
all
the
xero
from
the
starter,
to
the
backup
vendor
and
to
the
backup
storage.
B
There's
any
way,
we
can
optimize
that
to
tell
the
the
back
end
that
hey
just
that
chain
by
just
delete
the
block,
instead
of
you,
know,
copy
the
whole
block
zero
over
or
something
like
that
right.
My
answer
for
that
is
it's
up
to.
I
don't
think
we
should
specify
such
a
specific
case
for
our
optimization
in
the
api,
especially
for
the
first
attempt.
This
is
really
our
first
attempt
to
do
that.
That's
the
thing
it's
up
to
the
vendor,
then.
J
I
think
we
discussed
this
a
little
bit
before
I
have
gotten
another
question,
which
is
a
deletion
workflow
right.
One
of
the
things
on
the
concerns
I
do
have
is
it
assumes
that
the
cpt
service
will
have
to
be
in
the
business
of
managing
my
life
cycle
of
snapshots
and,
unfortunately,
snapchats
are
managed
also
out
of
bounds
as
well
by
one
snapshot,
objects
right.
What
is
the
conclusion
on
that?
Do
you
still
remember.
B
J
B
B
J
B
A
J
H
J
A
The
so
I
mean
so,
the
backup
vendor
will
need
to
keep
track
of
this
right,
because
backup
vendor
will
be
the
one.
The
backup
software
right
will
be
the
one
who
is
creating
a
volume
snapshot.
It
will
get
a
one
snapshot
content
which
has
the
snapshot
id,
so
it
needs
to
track
those
personally
right.
Yeah.
J
C
A
A
B
Have
five
minutes?
Maybe
how
about
this?
We
can
continue
that
discussion
in
our
cbt
group
meeting
yeah,
that
sounds
good,
yeah,
sure
we'll
follow
up
yeah
and
then
and
then
yeah
today.
We
just
we
just
want
to
present
the
backup
on
and
backup
and
restore
google
and
how
they
take
advantage
of
the
cbt
service
that
we're
proposing
the
in
there
to
make
it
more
efficient
and
we
can
because
this
is
not.
B
E
E
I
think
that
can
be
completely
independent
of
life
cycle
of
a
snapshot
because
backups,
you
know
they
have
their
own
life
cycles.
You
know
you
cannot
go
your
snapshots
for
30
days
or
90
days
or
you
know
one
year,
so
they
shouldn't
be
completely
coupled
with
the
life
cycle
of
snapshots
and
they
should
be
get
managed
through
the
back
overflows.
If
you
want
to
do
the
backup,
you
should
just
do
it
through
the
backup
interface
yeah,
because
completely
asset
of
kubernetes.
A
We
need
to
yeah,
we
I
think
we
should.
We
need
to
draw
like
several
different
boxes
on
that
diagram
right.
So
what
is
the
responsibility
of
a
ubcs?
I
said
car,
and
then
you
also
have
a
backup
software
that
is
orchestrating
all
of
this
right,
so
yeah.
I
think
we
need
to
have
those
details
sorted
out.
B
A
A
J
A
L
Yeah,
I'm
sorry,
I
was
having
audio
issues,
so
I
added
some
content
and
you
know
feedback
is
always
appreciated.
I
think
we
still
want
to
make
some
of
the
pseudocode
have
kind
of
a
common
voice
of
that,
but
feel
free
to
add
comments
as
we're
going
they're
in
the
their
links.
I'll
link
them
here,
but
they're
also
linked
to
the
main
document.