►
Description
Kubernetes Data Protection WG Bi-Weekly Meeting - 24 August 2022
Meeting Notes/Agenda: -
Find out more about the DP WG here: https://github.com/kubernetes/community/tree/master/wg-data-protection
Moderator: Xiangqian Yu (Google)
A
A
The
first
thing
is
it
events
to
Canada
to
continue
to
give
a
talk
with
regarding
to
CBT,
we
had
a
very,
very,
very
meaningful
discussion,
a
couple
weeks
back
and
even
has
some
updates
on
this
piece
and
we'll
kind
of
go
through
this,
and
then
shin
has
some
updates
on
the
William
group
cap
last
meeting.
We
discussed
this
quite
a
bit.
I
think
there's
some
left
eye
leftover
item
over
there
as
well,
and
then
we
will
open
the
discussion
to
the
group.
A
A
B
Can
you
see
my
web
browser
yeah?
Okay,
cool
thanks,
yeah
hi
everybody
so
yeah
about
four
weeks
ago
we
had
some
really
good
discussion
discussions
and
also
learning
along
the
way
around
like
aggregated
API
server
and
how
that
can
be
a
very
promising
solution
for
the
change
block
tracking
cap,
and
you
know
all
the
subsequent
implementation,
so
I
just
want
to
do
a
very
quick
recap,
just
so
that
you
know
I
have
to
bring
everyone
on
the
same
page.
B
There
are
two
main
things
that
we
got
out
of
the
meeting
from
four
weeks
ago.
The
first
one
is
like
using
like
aggregated
API
server,
so
we
did
an
additional
like
prototyping
to
try
to
like
hack
like
and
aggregate
API
server
and
bend
it
to
our
will.
So
the
first
thing
that
we
came
up
was
like.
Let
me
scroll
down
here.
B
Simply
by
you
know,
appending
like
all
these
additional
query
parameters
to
our
requests
so
the
trick
there
was
that,
like
we
were
able
to
extend
our
aggregated
API
server
to
implement
this
rest,
connector
connector
interface.
Now
for
those
of
us
who
are
familiar
with
go,
you
could
see
like
it
allowed
us
to
implement
and
Define
this
method,
and
the
trick
here
is
that,
like
we
can
return
a
custom,
HTTP
handloader,
because
the
moment
we
have
access
to,
we
can
return
the
casa
Handler.
B
B
So
that's
the
first
thing.
The
second
thing
that
we
discover
and
discuss
like
during
the
last
meeting
was
that,
like
we
were
not
able
to
implement
this
aggregated
API
server
as
a
sidecar,
the
main
reason
there
being
that
like.
If
we
have
multiple
like
CSI
drivers
and
they
each
have
a
zip
CBT
sidecar,
they
would
end
up
stepping
on
each
other's
toes,
because
during
the
bootstrap
process,
I'll
just
aggregator
API
server
site
car
is
going
to
come
up
and
try
to
register
yourself
with
the
kubernetes
API
server.
B
You
know
you
can
just
imagine
like
many
of
these
Cyclops
will
say:
hey
I'm
responsible
for
volume
of
snapshot,
Delta
and
another
one
came
up
and
said:
I'm
also
responsible
for
volume
snapshot
Delta.
There
was
no
way
for
the
kubernetes
API
server
to
multicast,
like
a
single
request
to
all
the
Sidecar,
and
so,
like
you
know,
at
the
end,
like
the
kubernetes,
API
server
will
only
see
one
sidecar,
even
in
an
environment
where
we
may
have
like
multiple
CSI
drivers
and
out
of
the
conversation
we
decided
that
hey.
B
Dear
I
want
to
quickly
walk
us
through
it
and
then
like.
There
will
be
definitely
definitely
money
opportunities
like
to
interact
and
feedback
and
questions
and
stuff
along
the
way.
So
this
entire
booster
model.
Currently,
like
you
know
in
this
design,
it
looks
like
this.
Now
we
have
an
aggregated
API
server
running
as
a
common
external
service
like
the
asset
deployment
workload
and
then
like.
We
also
introduce
a
CBT
site
car
this,
the
Sidecar
get
embedded
into
like
the
storage
provider
CSI
driver.
B
So
during
the
bootstrap
process,
the
aggregated
to
the
server
comes
up.
There's
only
one
of
these
in
the
entire
kubernetes
cluster.
It
comes
up
and
it
registers
itself
with
the
kubernetes
API
server
and
says
hey
from
now
on
I'm
responsible
for
this
volume
snapshot,
Delta
custom
resource,
all
of
them
come
to
me,
I
haven't
you
know,
have
an
endpoint
for
it.
I
handle
it
for
it
and
I'll
agree
with
it
and
then
the
site
car.
B
When
it
comes
up
during
the
bootstrap,
it
will
register
itself
with
this
like
new,
like
custom
resource
definition
that
we'll
be
introducing-
and
it's
basically
saying
that
like
is
this
custom
resource.
It's
really
just
we
call
it
driver
Discovery.
It's
really
just
a
way
for
the
aggregator
API
server
to
discover
like
the
CSI
driver.
C
B
It
sounds
it
sounds
yeah.
It
sounds
similar.
I
think.
The
part
that
he
was
referring
to
is
just
the
client
configure
property,
so
this
client
can
fit
yeah.
It's
like
it's
a
similar,
it's
exactly
the
same
concept
as
a
admission
weapon.
Basically,
it's
just
a
way
of
saying
you
know
for
the
I
guess,
for
the
part
to
say:
I
have
a
service
in
front
of
me.
This
is
my
part
and
my
endpoint,
and
this
is
like
the
cert,
that
you
know
we
used
to
do.
B
C
B
B
B
B
So
this
is
saying:
hey
get
me
like
a
volume
snapshot,
Delta
custom
resource
and
the
default
namespace
with
the
name
of
the
test
Delta
so
which
is
what
like
it
was
created
earlier
here
and
then
like,
and
so
the
response
would
just
be
like
you
know
as
similar
to
actually
you
know
identical
to
what
I
show
you
in
the
Prototype
readme
earlier.
It
will
just
return
like
the
exact
same
object.
You
know
we
created,
you
know
like
yeah,
like
return
it
back
to
the
client.
B
So
in
this
case
like
it's,
it's
simple:
it's
identical
to
what
you
can't
get
while
in
snapshot
Delta
space,
test
Delta.
So
now
there's
no
like
changeable
tracking
entries
or
records
yet
because
we
haven't
hit
the
CSI
driver.
So
now
with
this,
of
course,
this
is
just
it's
not
it's!
No
longer
so
I'll
come
back
to
this.
So
the
next
request
is
that,
like
we
hit
the
same
point,
we
issue
the
get
request
and
we
hit
the
same
endpoint.
B
B
So
it's
able
to
it
get
it
go
to
it's
a
CD
and
pull
out
that
driver
Discovery
resource
that
was
created
during
the
bootstrap
process.
Now
it's
so
it's
like
it's
like
yeah,
with
the
volume
Delta
like
resource,
we
are
able
to
get
the
volume
snapshot,
object
and
then
we're
able
to
get
the
volume.
Oh
sorry,
water
volume,
snapshot,
yeah
and
content
resources
as
well,
and
then
we're
able
to
see
the
driver
name
and
other
information
like
you
know,
for
example
the
snapshot
class
name.
So
it's
a
driver
name.
B
We
are
able
to
ask
for
the
exact
driver,
Discovery
resource,
and
now
this
is
how
we
discover.
Okay,
given
this
volume
Delta,
it
has
a
base
and
a
Target
volume
snapshots
and
then
now
we
know
which
CSI
driver
is
responsible
for
it,
because
we
can
extract
the
name
from
here
and
then
from
there.
We
pull
out
and
retrieve
the
driver,
Discovery
resource,
which
tells
the
end
point
to
this
specific
CSI
driver.
B
B
You
know
the
lower
level
volume
handles
of
the
volume
snapshot,
so
we
can
send
like
all
this,
like
I
guess,
parameters
in
a
Json
object
to
our
driver.
Oh
CSI,
the
storage
provider
driver
and
then
the
site
card
from
here
like
it
would
do
like
the
very
familiar
workflow
of
okay.
I
got
this
HTTP
s
request
coming
in
with
a
post
body,
I'm
gonna
issue
a
grpc
requests
over
Unix
socket
to
the
CSI
grpc
API
to
the
actual
CSI
plugin
Sidecar.
B
So
this
is
the
storage
provider
manage
CSI,
plugin
and
then
the
this
this
icon
here
you
know
it
will
know
like
how
to
to
call
into
the
actual
CVT
endpoint
provided
by
the
storage
provider.
So,
for
example,
if
this
is
a
CSI
AWS
on
EBS
driver,
this
CSI
plugin
would
be
part
of
that.
You
know
AWS
EBS
driver
already,
and
then
you
would
know
how
to
do
like
the
AWS,
credential,
authentication
and
authorization
I
am
handling.
B
You
will
know
how
to
call
into
the
EBS
direct
endpoint
based
and
then
like
return
on
the
result
back
to
us
to
our
Sidecar
and
I
was
like
I'll.
Send
it
back
to
you.
I
could
get
an
API
server
and
back
to
the
client,
and
the
response
would
look
something
like
this,
so
you
would
have
all
this
the
original
object
and
then,
with
all
this
additional
data
coming
back
from
the
storage
provider,
API
endpoint
and
all
of
these,
this
entire
block
here
like
is,
is
never
like
persisted
into
STD.
B
D
B
Yeah
so
I
think
it
would
be
so
I
think
like
Okay.
So
yes,
yes,
we
will
get
that
like
because,
like
whether
it
is
like
computer
or
client
go
like
as
long
as
like
it
looks
for
like
some
sort
of
like
I
guess:
oh
I'm
glad
I
have
this
here.
It
looks
for
like
some
sort
of
like
continue
like
Lister
properties
that
is
inside
the
requests.
If
it
does,
then
it
will
know
how
to
do
the
auto
pagination.
E
Well,
the
the.
If
you
look
into
the
parameter
of
the
get
the
first
get
on
the
top
you're
gonna
see
it
have
an
offset
right,
so
the
first
one
will
be
offset
zero
and
if
there
is
more
chain
block
need
to
be
respond,
then
we
will
provide
parameters
the
next
offset,
so
that
you
can
recall
I
mean
you
can
call
again
with
the
next
offset
for
the
next
page.
B
Yeah,
so
in
our
prototype
it
is
so
so
yeah
the
in
our
prototype.
It
is
like
a
I
guess,
like
a
a
more
like
manual
steps
like
you
know,
the
the
backup
software
says:
hey
I
need
to
submit
another
offset
a
second
request,
maybe
after
100.,
but
like
I
think,
like
I'm,
pretty
sure
that
client
go
and
cuddle
they
have
like
or
whatever
two
minutes
clients.
They
have
built-in
automation,
automated
pagination.
So
it
looks
for
like
a
very
specific,
like
property.
B
I
think
they
call
it
continue
like
the
key
is
literally
called
continue.
The
value
is
whatever
comes
back
from
the
server
so
and
then
with
that,
like
you
will
know
how
to
okay
now,
I
need
to
do
more,
so
I
think
like
it
really
boils
down
to
like
what
sort
of
how
do
we
want
to
how
much
flexibility
we
want
to
give
it
to
the
client?
Do
we
want,
like
the
client
to
say?
B
Okay
I
have
I'm
at
page
20
I,
don't
want
the
rest
anymore,
I'm
done
or
like
do
we
want
to
follow
that
more
I
guess
cute
cuddle
experience
as
long
as
there's
something
you
kind
of.
Would
just
keep
doing
the
auto-pagination
until
you
control
C,
to
kill
the
process
or
whatever
so
I
think
they
have
some
flexibility
there
like
I
guess,
thanks
to
like
the
the
this
is
the
I
guess,
the
power
and
the
flexibility
of
the
aggregated
API
server.
If
that
makes
sense,
hopefully
sorry.
A
B
Yeah
so
the
there
isn't
like
a
formal,
formal
contract
like
a
Proto
buff
spec,
because,
like
from
between
the
clock,
backup
software
and
the
aggregated
API
server
is
really
just
HTTP
request,
but
on
Inside
Out
code
we
actually
have
to
formalize
it.
So
the
trick,
it's
very
again
very
similar
to
what,
for
example,
log
does
like
we
have
to
formally
Define
an
option
object.
B
B
So
there
is
some
some
discussion
in
previous
meetings
around
like
okay,
a
second
okay,
so
there
are
two
parts
to
that
question.
So
for
one
there
are
two
parts
to
that
to
to
the
answer
of
that
question
like
the
first
part
is
like
a
you
know
like
first
of
all,
are
we
for
Alpha
like
we
want
to
keep
it
to
the
minimum,
and
you
know
if
they
are
more
like
driver,
specific
stuff
that
we
want
to
add
to
the
our
API.
You
know
we
can
over
that.
B
That
conversation
is
still
open
and
we
can
revisit
that
for,
for
example,
for
in
the
beta
phase.
Now
the
second
part
of
the
answer
is
like
the
feedback
that
we
got
was
we
don't
want
like
to
introduce
like
parameters
that
are
very
it's
a
bit
vague,
I
and
I'm
more
like
a
more,
not
fake,
but
more
like
it's
context,
context
dependent,
you
know,
so
we
don't
want
to
have
some
sort
of
free
form
like
map.
B
B
B
A
A
That
sounds
perfect.
That's
actually
that's
actually
the
what
I
prefer
as
well,
but
the
the
two
one,
the
three
things
that
define
over
there
I
kind
of
you
know
I
just
want
to
make
sure
I
understand
this.
It's
kind
of
you
universally
applies
to
all
the
drivers,
and
that
comment
like
limit
one
offset,
which
CBD
is
a
different
thing.
So
it's
fine,
so
limit
yeah
an
offset
it's
basically
yep.
All
the
drivers
will
need
that
is,
that
is
that
is
minus
any
correct.
D
I
think
it
was
fine
I
think
it
was
fine
what
you
know
what
what
I've
been
saying
here,
yeah
I,
would
you
know
I
think
the
the
key
thing
is
we're
gonna.
We
wanna
make
sure
that
the
cube
cuddle,
slash,
go
client,
slash,
Java
client,
whatever
talks
to
this
without
having
to
make
changes,
and
so
whatever
we
wind
up
with.
As
long
as
that
works,
that's
good
right.
B
E
Go
ahead,
I
also
have
a
comment
on
page
number.
Two
I
think
we
discussed
it
in
our
private
meeting
and
I
want
to
bring
it
out
to
the
community
too,
so
whether
that
that
box,
that
ping
block
on
the
left,
it
is
the
crd
that
we
need
do.
We
need
still
need
to
to
have
it
as
a
city
and
start
in
SCD,
or
it
can
be
simply
an
internally
short
maintained
by
the
CBT
API
aggravated
apis
part.
B
B
You
know
so
like,
for
example,
like
this
this
stuff.
This
go
code
here
and
also
this
this
one
here,
the
volume
essential
Delta.
It
must
exist
at
the
code
level
and
then
we
must
like
register
that
with
the
API
server.
Second
part
of
your
question:
does
it
need
to
be
persisted
into
SCD
so
now?
That
is
an
interesting
part.
B
So
if
we
look
back
at,
for
example,
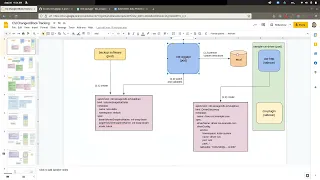
for
example,
this
diagram
we
have,
we
are
introducing,
like
the
volume
stash
of
Delta
custom
resource
and
then
as
well
as
the
driver
discovery
on
resource.
So
the
challenge
here
in
our
prototype
is
like:
we
persist
them
into
STD.
Now
they
are
really
small
resources.
You
know,
and
the
challenge
is
like
I
haven't,
found
a
way
to
persist
this
into
the
kubernetes
SCD.
B
B
This
two,
this
two
tipping
box
pink
box
into
the
SCD.
That
is,
you
know
that
is
owned
by
like
a
aggregated,
API
server
so
to
to
funds
question
like
I
mean
they
can.
You
know,
I
think
we
we
had
this
chat
during
our
last.
You
know
CBT
engineering
meeting
to
Frank's
Point
like
do
we
actually
need
to
persist
this
volume
Delta
at
all
like?
D
That's
why
I
was
thinking
of
using
like
a
a
resource,
selector
and
things
like
your
start.
You
know
your
your
Target
and
your
base
snapshot.
Id
could
be
fields
in
the
change
block
Delta,
you
know
theoretically
right
and
then
the
the
selector
would
say:
I
guess
it'd
be
a
label.
Selector
would
well.
No
it's
a
resource.
Selector
would
say
what
your
base
snapshot
ID
and
what
your
target
snapshot
ID
would
be
that
you're
searching
for,
but
those
would
come
through.
Basically,
is
you
know,
arguments
in
the
URL.
D
B
D
B
Api
version
Okay,
so
yes,
so
API
version
and
then
like
it
will
have,
but
here's
like
so
all
of
like
as
far
as
you
know,
kubernetes
API
server
endpoints.
All
of
them
like
follow
it.
Follow
this
form.
Sorry,
it
might
be
hard
to
see
you
follow
this
format.
There
is
like
a
group
of
version
and
then
you
have
to
tell
it
the
namespace
and
the
actual
name
of
the
object.
So
if
this
was
never
created,
then
it
would
it
won't
even
get
to
our
aggregate
API
server.
D
D
B
D
B
Base
equal,
you
know,
okay
and
then
like
and
then
Target
equal
I
think
in
they
might
be
doable.
It
will
become
like
I
think
it
might
be
doable,
yeah
I
think
like
because
now
it
will
interpret
it
as
a
list
instead
of
a
get
which
is
fine,
yeah
I
think
that
might
be
doable
for
at
least
for
the
yeah
there's
a
chance
that
we
won't
yes,
I,
think
that's
actually
I
would
say,
there's
very
good
chance
that
my
work.
D
B
B
E
Yeah,
yes,
I
I
agree
with
that.
The
driver
Discovery
Park
is,
is
another
I,
guess
another
crd
that
that
we
can
Define
to
help
with
the
you
know
controlling
the
functionality
of
the
CBT,
but
the
chant
action
of
the
different
Source,
the
volume
snapshot
Delta
chain
accent
itself
is
a
stateless,
gen
action.
You
just
get
the
differential
snapshot
and
give
it
back
to
me
just
one
chain.
Action
no
thing
need
to
be
saved
on
that
CBD,
aggregated
API,
yeah,.
B
So
the
the
the
interesting
thing
there
is
like
what
we
ever
want
to
look
back
at
this
resource
I'm.
So
so
sorry
like
I
guess
in
the
past.
So
if
you,
if
we,
if
you
recall
like
you,
know,
we
used
to
have
a
little
bit
more
here,
like
we
have
things
like
parameters,
etc,
etc.
Right,
but
now
all
of
those
have
been
removed
because
we
want
to
you
know
we
we
talk
about
letting
the
parameters
be
solved
inside
the
volume
snapshot
class.
B
So
right
now
like
we
thought,
because
that
was
why,
like
we
had
this
one
of
the
reasons
why
we
had
this
constant
resource
in
the
past,
because
we
want
to
be
able
to
retrieve
all
this,
but
during
the
second
half
of
the
request.
But
now
we've
discussed
yeah
I
think
yeah
found
to
your
point.
This
become
really
like
a
stateless,
well
I
guess
yeah
quote
say
this
thing
that
there's
really
just
no
reason.
We
need
to
persist
this
now.
The
question
is
like
do
how
for
Alpha
like
implementation?
B
Are
we
okay
with
you
know
just
I
I
need
to
try
I
think,
like
I
feel
like
Dave's
proposal.
Will
work,
which
should
be
able
to
just
do
this
or
whatever,
without
a
name
of
the
or
like?
If,
if
we
feel
like,
okay,
hey,
maybe
down
the
road,
we
may
have
one
more
things
in
the
spec
that
we
want
to
the
aggregated
API
server
need
to
pull
up
from.
We
can
again
just
extend
this
to
another.
Have
another
psychologist,
say
CBT.
B
E
B
B
F
Can
I
ask
a
question
here,
yeah
sure,
so
we
have
two
CR
this
year
the
driver
Discovery
actually
so
yeah
the
driver,
Discovery
object
is
actually
straightforward.
It
can't
get
stored
in
crd
as
a
crd
right,
because
it's
very
small
there's
really
not
much
to
it.
Yeah
the
reason
we're
looking
at
aggregated
apis
level
for
the
volume
snapshot
Delta
object
is
because
it
can
get
potentially
large
there's
a
lot
of
churn
there,
and
because
of
that,
we
want
to
use
aggregated
API
server.
D
F
B
D
F
So
the
only
so
potentially
we
can
have
a
crd4
driver
Discovery,
because
it's
okay
I
mean
if
you
want
to
store
net
City,
it's
not
really
a
big
issue
and
that
CRT
by
itself
is
not
really
useful
right.
So
the
fact
that
you
know
we
have
multiple
sidecars
for
different
objects
doesn't
really
help
us
much
because
at
the
end
of
the
day
you
need
to
have
both
objects
builted
into
in
order
to
proxy
the
request
to
the
right,
CSI
driver
right.
F
F
The
second
decision
was
basically,
we
don't
want
to
have
a
CID
for
volume,
snapshot
Delta
because
of
all
the
churning
at
CD,
and
it
can
get
too
large
and
whatnot
right.
So
there
is
no
crd,
there
I
mean,
so
we
should
just
forget
about
any
crds
there
and
then
the
idea,
API
server,
become
just
a
proxy
that
I
would
process
the
internal
snapshot.
Delta
object
with
the
driver,
Discovery
object,
which
can
be
a
crd
and
that's
it.
You
know
that
we
just
have
a
single.
F
E
D
So
so
the
driver
Discovery
I
mean
that
shouldn't
be
handled
by
the
aggregated
API
server
and
that
could
be
either
by
making
a
CVT
or
sorry
crd.
That
has
a
different
API
version,
so
it
doesn't
go
to
the
aggregated
API
server
or
you
can
make
a
config
now
right,
but
in
any
case
it
doesn't
need
to
be
stored
by
the
aggregated,
API
server.
In
fact,
you
probably
want
it
to
not
be
because.
B
D
D
So
you
want
them
to
be
able
to
advertise
without
that
stuff
being
installed.
So
I
think
saying
that
those
are
standard.
Kubernetes
resources
to
get
Stores
the
place
where
we're
running
into
a
persistence
requirement
is
because
of
I
think
we
have
two
ways
to
interact
with
things
so
volume
snapshot,
Delta
is
being
handled
as
a
resource.
D
The
user
writes
that
then
gets
a
status,
that's
updated,
and
that
implies
persistence
because
once
you
write
something,
you
expect
that
it's
going
to
stay
there
and
so,
for
example,
like
if
the
aggregated,
API
server
goes
down
and
comes
back
up.
You
would
expect
that
the
volume
snapshot
Delta
is
still
sitting
there
and
that
you
can
come
back
later
and
read
the
status
from
it.
So
that's
where
the
persistence
comes
in
is
because
of
the
the
style
that
we're
using
here.
Does
that
make
sense
to
everybody.
F
D
F
D
Well,
that's
right!
Well,
that's
already
suggesting
that
if
we
instead,
so
that's
that's
a
model
where
we
have,
we
write
some
state
and
then
we
check
the
status
right.
So
that's
one
way
to
do
things
if
we,
if,
instead
we
took
it
as
like
the
change
block
Deltas,
where
we're
listing
out
the
ones
we're
interested
in,
and
we
could
do
that
a
couple
different
ways.
So
one
way
would
be
to
put
all
of
the
fields
in
there
control
things
like
Target
base
offset.
D
F
D
B
D
C
C
D
C
D
And
that's
that's
kind
of
why
you
need
the
persistence
against
the
restart
of
the
aggregated
API
server,
because
you
wrote
a
resource
that
has
specific
data
that
you
wrote
into
it,
and
you
expect
that
resource
to
be
there
in
the
future
and
it
would
be
a
named
resource
right.
So
did
you
give
it
a
name
so
you'd
come
back
with
you
know:
Dave's
volume
snapshot,
Delta,
53.
yeah,
and
so
it's
a
unique
thing
that
you
created.
So
it
has
to
be
persisted
so.
B
B
Okay,
so
like
okay,
the
only
time
right
now
in
the
Prototype
right,
the
only
time
where
the
status
of
resource
has
any
entries
is
like
the
query
parameters
are
provided.
So
if
I
restart
my
aggregate,
API
server
and
I
send
back
a
request
with
without
any
query
per
minute.
I
will
only
see
what
is
persistent.
B
D
B
D
Well,
you
kind
of
have
to
because
that's
that's
the
contract
that
the
style
that's
being
used.
The
expectation
from
anybody
using
it
is
that
they
write
that
resource.
They
could
come
back
next
week
next
year
and
it's
still
there,
and
even
you
know
at
least
within
15
minutes,
which
so
you
know
restarting
the
API
server
would
mean
that
if
it's
only
in
memory,
it
goes
away.
C
F
Part,
the
part
that
you
know
I
mean
first
of
all,
like
this
left
green
rectangle.
Here
you
know
as
far
as
the
spec
portion
of
it.
This
is
something
that
the
backup
software
specifies
so
the
backup
software
has
an
idea
of
what
it's
asking
for
right,
and
you
know
I'm,
okay,
with
whether
backup
software
internally
stores
that
somewhere
or
you
know
if
it
gets
stored
on
you
know
as
part
of
kubernetes
in
kubernetes
City.
F
D
F
F
D
D
F
B
F
F
F
There
is
also
ready
right
and
given
that
there
is
also
large,
you
can't
get
the
entire
set
of
results
in
one
Chunk
in
one
operation
right
and
that's
where
the
officers
come
into
picture
right,
yeah.
So
the
back
of
software
knows
that
as
a
cookie
that
it
has,
for
example,
the
first
100
results,
the
first
hundred
blocks,
so
it
can
resume
from
there
right
right.
So
as
far
as
like
the
status,
really,
all
the
backup
software
really
cares.
Is
that
up
to
what
point
it
has
really
processed
the
results
and.
E
D
It's
not
the
status,
that's
the
problem
so
that
we
can
fill
in
on
the
Fly
and
that's
what
we
that's.
That's
the
plan
and
that's
fine!
That's
that's
not
a
problem.
The
the
thing!
That's
not
really
shown
here,
scroll
up
a
little
bit
with
Javan,
so
the
URL
that's
being
shown
here,
isn't
so
so,
for
example,
what
we're
doing
here
is
we're
fetching
something
called
a
volume
snapshot,
Delta,
that's
the
type
of
the
record
right
and
then
it's
named
test
Dash
Delta
So,
that's
its
name
in
the
API
server.
C
What
I
thought
I'd
say
was:
there's
this
time
period
between
creating
this
object
and
the
ability
for
the
back
end
to
have
to
be
able
to
serve
records,
and
if
you
keep
state
in
this
object
or
the
green
object
here,
it
could
tell
us
when
the
back
end
is
now
ready
to
serve
and
so
accept
this
call.
Otherwise
you
know,
let's
say
we
make
this
query
call.
What
would
it
do
will
just
block
you.
C
And
it's
not
not,
you
know
saying
which
we
should
or
you
should
not
do
it.
What
I
heard
him
suggest
is
when
the
score,
when
this
object
is
created.
At
that
point,
the
the
aggregate
API
reaches
out
to
the
CBT
HTTP
sidecar
for
that
driver
and
is
I,
guess
validates
the
the
arguments
and
B
initiates
right
some
operations,
which
can
give
you
back
a
status
at
some
point,
but.
D
C
D
Expectation
is
that,
once
you
wrote
it
you're
able
to
read
it
at
some
point
in
the
future,
and
that
implies
persistence,
because
if
you
restart
the
aggregated
API
server
between
the
right
and
the
read,
the
spec
would
disappear
if
it's
only
kept
in
memory.
Agree!
Okay,
so
that's
why
the
need
for
persistence
is
because
of
the
style
that's
being
used.
Okay,
so
I
want
to
confirm.
B
D
We
use
this
style,
and
so
that's
I
think
there
are
two
options
here
that
we
could
look
at,
and
you
know,
there's
probably
other
ones,
but
I
can
think
of
of
two
off
the
top
of
my
head.
So
when
I
did
that
write-up
the
other
week,
what
I
had
returning
in
the
status
was
a
was
a
uuid
and
in
my
proposal
the
original
one
was
this
volume
snapshot.
Delta
record
was
a
crd
wasn't
handled
by
the
API
server
and
so
that
way
or
wasn't
angered
by
the
aggregated
API
server.