►
Description
Kubernetes Data Protection WG - Bi-Weekly Meeting - 14 December 2022
Meeting Notes/Agenda: -
Find out more about the Data Protection WG here: https://github.com/kubernetes/community/tree/master/wg-data-protection
Moderator: Xiangqian Yu (Google)
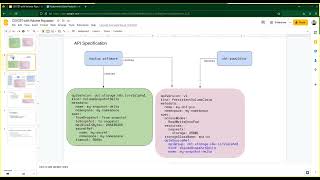
A
B
C
E
C
E
I
was
kicked
off
for
some
unknown
reason.
Sorry
about
that
folks,
anyway,
pretty
happy
holidays.
Today
it's
been
recorded
right,
yes,
Wednesday
2022,
and
this
is
probably
the
last
working
group
meeting
for
this
year.
The
day
we
have
only
one
agenda
item.
This
is
the
over
there
Yvonne
and
Prasad
talking
about
CBD
updates,
except
for
up
from
the
last
last
transition
and
then
we'll
open
the
composition.
Today,
a
conversation
to
the
entire
team.
A
A
D
Know
you
can
share
whatever
you
have
on
your
plate,
so
yeah
hi,
everybody
so
yeah.
Since
the
last
working
group
I've
been
trying
to
like
you
know,
just
spend
some
time
doing
a
prototype
on
the
CBT
cap,
using
the
volume
populator
mechanism,
I
haven't
had
a
chance
to
finish
it
yet,
but
I
just
want
to
quickly
share
the
status
today.
D
D
In
the
last
meeting
we
talked
about
letting
the
populator
hang
handle
all
this
PPC
and
test
management.
I.
Think
that's
like
code.
It
up
and
try
a
few
things.
I
think
it's
easier
and
simpler
if
the
backup
software
have
full
control
over
the
life
cycle
of
the
volume
and
the
disk,
where
eventually
like,
where
all
the
CVT
entries
will
be
returned
to
the
general
idea
is
still
like
backup.
D
Software
says:
I
wanted
Delta
between
two
snapshots
and
by
the
way
I'm
gonna
provision
a
pre-provision
one
volume,
or
this
a
pool
of
volumes,
and
some
of
them
would
be
like
after
the
assault
reference
point,
two:
the
volume
snapshot,
Delta
CR
that
we
it
created
and
then
the
CBT
populator
within
it.
There
is
a
controller
that
watches
for
the
creation
of
the
PVC
and
they
identify
that
hey.
D
I
know
like
so
one
of
the
I'll
come
back
to
address
like
all
right.
Let's
discuss
like
the
concerns
we
had
last
time
about,
like
latencies
and
extra
resource
overhead
in
in
a
few
minutes,
so
yeah,
so
the
CPT
populator
volume
populator
within
the
CSI
driver
on
the
left
hand,
side
issue
RPC,
call
to
the
CSI
plugin
get
back
all
the
CBT
payload
spin
up
a
ephemeral
pot
Mount
that
volume
there
was
pre-provisioned
by
the
backup
software
and
I
just
write.
D
D
D
So
it's
kind
of
like
the
general
direction
of
the
Prototype,
like
I,
haven't,
had
a
chance
to
like
really
go
into
more
benchmarking
effort
to
see
like
how
long
it
takes
to
provision
pves
and
a
volume,
but
based
on
my
like
very
very,
like
preliminary
testing
like
say
with,
like
you
know,
in
our
internal
lab,
like
with
FCD
like
we
got
like
I,
could
get
like
a
volume
of
like
a
10
gig
10
like
two
three
seconds.
Of
course.
D
That's
just
all
like
you
know,
sub
cluster
dependent
and
environment
dependent
right,
so
it
could
be
fast.
Always
it
might
be
a
lot
of
people,
but
so
far
like
now
this,
in
my
like
preliminary
testing
like
young,
there
hasn't
been
too
much
of
an
overhead
in
provisioning
like
volume
song
to
like
10
gig
I
would
just
imagine
like
it's
a
reasonable
size
for,
like
your
CBT
metadata
it'd,
be
interesting
to
see.
How,
like
you
know,
is
that
continued
to
scale.
D
You
know
if
we
change
the
size
of
the
volume
and
I
guess
one
of
the
things
that
I
like
about
using
letting
the
backup
software
it's
like
to
pre-provision
or
provision
the
PVC
is
like
I
can
choose
the
size,
the
speed
you
know
of,
however,
it
wants
like
the
volume
you
can
pre-provision
approve
of
it.
If
you
want,
you
know,
etc,
etc.
The
assumption
that
I
meet
there
is
just
like
you
know,
backup
software
is
generally
good
provisioning
volumes.
D
A
A
B
D
Yeah
good
point,
like
everything
is
free
right,
like
with
aggregated
FPS
out
there
get
stuff
there
too,
that
needs
to.
There
will
be
some
sort
of
overhead
in
some
way
or
the
other
I
think
like
it's
a
matter
of
like
you
know
like
stability
over
of
the
over
the
network
or
stability.
Like
of
writing,
like
large
amount
of
data
into
volumes,
well,.
B
D
D
It
is
the
volume
populator
essentially
so
the
the
trade
again
right,
like
I,
know,
sunshine.
You
haven't
been
around
I.
Think
the
main
like
pushback
we
have
from
the
architecture.
Architecture
is
like
the
amount
of
volume
that
we
pushed
through
the
kubernetes
in
cluster
Network,
going
through
the
control
plane.
D
Okay
argue
that
they
will
still
be
networking,
but
that
happens
between
the
provider
and
the
CSL
like
the
couplet
right,
essentially
when
the
data
is
classified,
but
at
least
like
it
doesn't
go
into
like
the
kubernetes
network
or
over
the
network.
So
that's
one
way
to
you,
know
I,
guess,
I
guess.
The
objective
like
I
have
in
mind
when
I
came
up
with
involving
populated
approach.
A
E
C
D
D
D
E
D
E
Might
be,
it
might
be
concerning
to
the
API
reviewers
if
we
want
to
take
this
approach,
because
the
the
data
source
is
therefore
over
here,
it
sounds
like
the
popular.
What
the
popular
would
be
doing
is
actually
create
a
volume
that
is
from
the
volume
Slap
Shot
Delta
corrected
from
two
snapshots:
it's
basically
a
restoration
process.
Instead
of
storing
the
media
results,
we
process,
it
might
be
a
little
bit
confusing
there.
E
D
B
B
D
The
idea,
sorry,
the
in
the
inside
the
code
right,
it's
just
like
hey,
you
know,
go
find
this,
go,
find
this
thing
and
then
find
like
the
the
volume
snapshots
and
then
like
issue
the
grpc
call
so
in
a
sense
like
yeah,
maybe
I
guess
maybe
potentially
the
confusing
part.
It's
like
this
is
not
like
data
source
per
se,
like
literally
a
dinosaurs.
This
feels
like
the
way
for
the
volume
popular
to
say:
okay
I,
you
know
this
PVC.
It
will
contain
data
from
this
particular
thing.
D
E
E
E
B
E
B
I,
haven't
came
up
with
this
idea
that
we
could
put
the
change
block
data
into
a
PV
and
then
read
it
from
the
PV,
so
this
is
actually
coming.
So
the
data
the
CBT
data
is
coming
from
the
CSI
provider
being
you
know,
provided
to
the
volume
populator
which
then
writes
it
into
the
disk,
and
it's
basically
going
in
there's
a
file.
So
we
could
read
the
file
by
attaching
it
sure.
B
C
E
B
D
D
Yeah,
you
know
like
this
information
around,
like
you
know
at
the
end,
so
the
idea
is
like
yes,
this
ephemeral
part
is
writing
it.
It
was
just
a
synchronously
update
like
the
state
which
you
can
start
in
some
resource
and
eventually
we're
just
say
when
it's
all
said
and
done,
it
would
just
say:
okay,
we're
done
how
many
blocks
did
I
see
the
block
size
that
the
provider
told
me
was
this
amount
and
how
many
have
I
returned
to
how
many
bytes
have
I
returned
to
that
this?
A
E
D
D
D
Yes,
yep
I
think
like
there
is
like
I
think
like
there
was
the
inside,
the
they
have
a
hello
world
like
CBD
I,
have
a
lower
volume
populated
on
how
on
what
they
did
was
like.
They
put
it
into
like
a
an
ephemeral
file
between
like
the
populator
and
then
like
yeah
and
then
like
somehow,
and
then,
like
the
ephemeral
pot.
Like
is
able
to
read
that
you
know
file
inside
yeah,
that
is
on
the
CBT
populator
ephemeral
volume.
C
C
C
D
That
data
move
apart
with
Mount
the
CPT
volume
and
then
at
the
same
time.
Ideally,
it
should
also
be
able
to
mount
like
that.
The
volume
of
the
idea
blocks
right.
So
this
is
not
taking
into
consideration,
like
the
data
token
approach
that
they
brought
up
last
meeting,
because
it's
just
like
already
the
current
way
of
how
the
data
mover
pot
would
mount
the
volume
and
to
get
to
the
actual
VM
box.
A
D
D
C
D
Guess
yeah
I
think
that's
like
definitely
a
legitimate
concern,
so
you
know
seems
like
you
know,
multiple
or
a
few
of
you
have
brought
brought
this
up.
I
brought
it
up,
I
think
like
so
I'm
gonna
at
a
point
where
I
feel
like
it'd
be
nice
to
get
some
like
would
not
be
nice,
but
I
think
it'd
be
necessary
to
get
some
benchmarking
to
see
how
bad
it
is.
It's
just
like
again
right.
It's
just
like
the
networking
argument.
D
Right
like
there
was
prison
that
was
presented
to
us,
always
bad,
but
nobody
knows
how
bad
it
is.
You
know
I
feel
like
this
one
one
approach
or
the
other
like
it's
up
to
us
to
come
up
with
some
numbers
to
you
know
convince
ourselves
and
convince
others
outside
of
this
working
group
that
you
know
it's
not
that
bad.
You
know
but
legitimate
concern,
but
it's
like
how
bad
it
is.
It's
up
to
us
to
come
up
with
the
actual
numbers
to
convince
ourselves
and
convince
others.
D
So,
like
I
said
right,
like
I,
haven't,
had
a
chance
to
fully
like
Benchmark
like
the
the
overhead.
You
know
like
the
at
least
like
yeah
I'm,
just
from
on
our
side
like
it
didn't
seems
like
that.
Big
of
an
overhead
is
something
that,
like
you
know,
we
can.
You
know
at
least
for
our
like
product
like
something
that
we
can
like.
D
Exactly
exactly
so
so
it
works
for
us.
I
would
say
like
it
sounds
at
this
level.
It
feels
like
it
works
for
us.
That's
why
I
said
I
cannot
say
it
works
for
by
us,
I
mean
their
products
and
also
like
from
what
some
of
the
internal
benchmarking
we
have
FCD
and
stuff
like
that
so
and
hands
like
you
know,
this
is
the
receiving
the
Prototype
phase.
We
still
have
any
discussion
about
this.
How
this
can
serve
like
community
at
large?
Not
just
like
you
know,
one
or
two
specific
providers.
D
D
Okay,
so
before
we
go
back
to
the
resource,
the
overhead
like
from
API
from
a
workflow
perspective,
is
it
reasonable?
So
it's
you
know,
then
we
can
if
it.
If
this,
if
there's
something
like
fun
about
like
the
API
or
the
workflow
itself,
then
you
know
we
can
just
you
don't
even
need
to
argue
about
like
a
resource,
contentions
and
overhead
right.
E
D
E
Sure
about
how
how
I
I
was
trying
to
imagine
how
backup
software
can
make
that
orchestration
happen
right
the
the
data
source
reference
it
it's
basically
designed
or
I'm,
not
sure.
What's
the
current
status,
maybe
it
changed,
but
in
the
early
days
it
is
purely
designed
for
serving
as
external
source
of
populating
our
volume.
D
A
E
D
D
I
I
mean
I,
know
which
I
know,
which
example,
yeah,
I'm,
sorry
I-
know,
which
example
you're
referring
to,
but
I
felt
like
that
kind
of
data
source
details.
It's
not
I,
guess
the
whole
point
of
having
an
API
is
like
the
backup
software
doesn't
need
to
know.
What
is
behind
that
crd
right,
you
say
hey.
This
is
from
by
looking
at
it
from
my
API
perspective.
A
E
B
A
D
So
I
think,
like
the
I
I
haven't
finished,
like
the
implementation
of
this
mounting
part,
yet
I
think
essentially
like
once
it
gets
these
CBD
payload.
Initially
it's
going
to
be
in
memory
right,
so
it
has
to
we
can
potentially
like
have.
This
would
be
have
to
be
some
sort
of
local,
like
ephemeral
volume
that
is
mounted
to
the
populator,
and
then
this
is
where,
like
it
will
go
like
the
CBT
in
memory
will
get
returned
to,
and
it's
kind
of
like
the.
A
E
D
E
D
E
A
D
Then
it
then
now
we
just
have
to
stand
it
like
then
we
might
as
well
just
go
back
to
like
directly
sending
like
the
CBT
entries
back
to
the
background
software
right.
If
this
part
here
has
to
be
networking,
number
three
has
to
be
now:
okay,
then
the
E
minor
rewinds
directly
push
it
back
to
the
backup
software.
There's
no.
E
So,
if
there's
a
difference
over
here
right,
if
it's
pushing
back
to
the
backup
software,
then
reinforcing
backup
softwares
to
implement
the
same
apis.
The
CPT
populator
in
this
diagram
can
talk
to
by
having
our
own
service
means
that
we
can
standalize
that
push
API
and
we
can
expose
the
get
API
for
backup
software.
E
E
E
D
I
I
agree
with
you
if
there's
no
other
way
to
do
number
three
without
get
another
volume,
then
I
personally
kind
of
don't
like
it
because
of
just
yeah
like
no.
We
need
to
like
get
exactly
like
what
you
said.
There's
too
much
orchestration
orchestration
that
need
to
happen
internally.
At
least
you
know,
and
you
can
I
mean
one
can
argue
that
one
can
argue
that
at
least
all
of
this
is
abstract
and
in
from
the
backup
software
backup.
Software
is
insulated
from
all
these
complexity,
but
still
I.
D
Think
it's
a
bit
more
than
I
want
to
maintain.
You
know
at
least
from
at
this
stage,
so
yeah
no
I,
don't
know
yeah
off
the
top
of
my
head.
I,
don't
know
how
to
do
this.
Actually
we
felt
like
and
yeah
another
volume
pin,
I,
don't
think
it's
then
by
then
they
say
forget
it.
You
know,
like
just
send
it
back
to
the
network
over
the
network
back
to
the
backup
somewhere
directly
to
have
all
things.
D
I
know
like
even
like
sukana
and
I
have
been
discussing
this
too.
You
know
like
I,
feel
like
at
the
end.
We
might
just
end
up
falling
back
to
that
initial
design
from
like
I,
don't
know
five
months
ago,
where
we
just
exposed
like
an
external
rest
endpoint,
then
you
know
then
end
up
like
we
don't
get
sick
architecture
won't
be
concerned
about
it.
Then
we
can
have.
Then
we
don't
have
like
volume
pre-provision
over
him,
Etc.
D
D
We
need
to
manage
TLS
search,
you
know,
but
if
you,
but
it
feels
like
yeah,
you
know
like
we
might
just
end
up
going
back
to
that
at
the
end,
you
know
if,
like
volume
populated,
doesn't
work
and
aggregated
okay,
so
it
continues
to
you
know:
if
we're
not
able
to
convince
the
architecture
that
you
know
aggregate
the
API
server
would
not
be.
You
know,
potential
bottleneck
or
like
resource
thing.
D
I
mean
like
so
yeah
we've
been
chatting
about
this
like
as
well
and
I.
Think
the
main
thing
was
like
I,
don't
know
if
I
have
it
here,
I
think
the
main
thing
is
like,
let's
see,
I,
think
the
last
a
bit
slow
here,
the
last
feedback
we
got
from
Clayton
was
that,
like
you
know,
where
is
it
okay?
If
y'all
can
see
my
GitHub
h,
I?
D
Think
it's
just
here
right
like
his
thing
is,
like
you
know,
somehow,
like
the
API,
the
bandwidth
requirement
did
not
material
change,
the
P99
bandwidth
profile
of
the
API
server,
what
I
mean
by
that?
So
so
again,
he
said
like
there's
also
like
he's
going
to
like
why
this
is
appropriate
for
exact
port
forward,
but
not
not
appropriate
for
hours.
D
So
if
we
can
prove
this
right
like
if
we
roll
this
out
into
like
a
kubernetes
clusters
and
test
it
with
some
reasonably
sized
volume
and
pull
like
the
CBT
entries
and
then
like
this,
the
the
P99
it
doesn't
affect
the
P99
latency
of
API
server,
then
we
at
least
we
have
like
something
that
to
go
back
to
them
and
say:
hey
it's
not
as
bad
now
tangibly.
What
does
this
mean?
Not
much
information
here,
I
reach
out
and
say
Hey,
you
know
just
like
I'm,
just
trying
to
like
tap
chat.
D
Have
a
good
chat
with
us
in
here.
I
have
enough
conversation
here
first
before
I
ping,
him
directly
about
this,
to
create
some
clarification
by
knowledge
and,
for
example,
like
the
API
server.
Actually,
on
slack
it
has
the
Avi
the
kubernetes
API
server.
It
has
some
SLO
alert
that,
like
would
measure
and
predict
like
the
the
latencies
of
the
API
server
yeah.
You
know
if
it
goes
beyond
like
that.
D
Slo,
like
the
alert
is
gonna
fire
it
and
then
it
just
and
then
like
the
API
fairness
and
priority
thing
is
going
to
kick
in
and
API
server
is
just
going
to
start
throttling
and
stop
like
I'm
cutting
off
rate
limit,
like
all
the
some
of
the
API
calls.
I.
Think
that's
the
main
case
in
here.
So
I
mentioned
right.
I
also
mentioned
to
you
like
hey,
you
know,
I
talk
about
a
priority,
In
fairness
or
financing,
probably
I,
always
I
can't
always
remember.
D
We've
come
first
I
mentioned
it
in
this
cap,
too.
I
was
like
hey,
you
know,
and
I
talked
to
Jeff
about
it
too,
and
then
he's
he
said
like
he
liked
that
we
include,
like
you
know,
we
account
for
fairness
and
priority,
but
he
also
understands
like
where
Clayton
is
coming
from
so
I.
Guess
it's
really
up
to
us
to
prove
that
you
know
what
if
we
throw
this
out
as
an
educated,
API
server,
you
know
if
you
have
some,
the
SL
alert
is
not
gonna
fire.
C
D
D
Yeah
because
I
remember,
if
I
might
be
yeah
I,
remember
being
that
person
who
put
all
this
in
yes,
I
spent
like
two
months
dealing
with
this.
It's
not
fun
to
do.
I
think
this
is
the
main
thing.
If
we
can
somehow
spin
up
a
cluster
and
say,
like
you
know
what
oh
yeah,
this
is
terminates
the
request,
because
apis
have
a
world
terminate
your
request.
Imagine
like
this
kicked
in
while
you're
doing
it
halfway
doing
your
backup
operation
and
then
the
kubernetes
API
say
oh
I'm,
going
to
start
terminating
your
request.
D
D
D
Yeah
I
am
open
to
like
suggestions
on
like.
Shall
we
continue
to
try
to
figure
out
if,
while
in
popular
will
work,
shall
we
I
mean
okay,
so
yeah
multiple
feels
like
there
are
multiple
friends
that
we
can
attack
this,
which
I
think
like
you
know,
we
can
come
up
with
some
numbers
and
say
Hey.
You
know
the
P99
is
not
that
bad.
D
E
Kind
of
agree
with
the
cotton
on
his
statement.
Typically,
you
want
to
avoid
data
pass
traffic
through
the
control
plane,
because
data
pass
typically
needs
to
be
a
little
bit
more
available
than
the
control
plan
components
but
I
like
well.
Your
your
PV
controller
may
have
a
99.9
of
availability,
but
your
data
path
of
writing
data
into
the
volume
has
to
be
like
six
nines
or
seven
nines
or
whatever.
It
is
five
nines.
E
Typically
within
a
cluster
yeah,
going
through
allowing
the
data
plan
traffic
through
the
control,
plane
itself,
bottlenecks,
the
availability
of
the
system
to
the
availability
of
the
control
plane.
So
that's
one
thing,
the
other
thing.
The
main
thing
is
that
we're
talking
about
is
actually
a
network
bandwidth
issue.
We
can
do
throttling
to
make
sure
we
don't
bleach,
but
in
general,
if
we
could,
maybe
maybe
we
should.
B
B
E
Right
we
did
some
math
before
right,
Dave
and
even
for
for
that,
I
think.
The
the
really
thing
is
the
first
one
right
when
we
first
take
a
snapshot
over
the
big
volume
and
between
the
first
volume
to
no
there's
no
snapshot
previously
then
effective
with
the
change
blockage.
It's
basically
the
entire
thing
right.
B
Yes,
but
we
really
have
to
look
at
things
like
returning
extents,
so
you
know
we
should
be
returning
extents
not,
but
we
have
the
bitmap
idea,
but
in
general
we
should
be
returning
extents,
like
block
X,
to
block
y
changed,
and
so
your
worst
case
is
every
other
block
was
changed.
That
gives
you
all
the
extents
are
you
know
size
one
and
there's
every
other
extent.
If
the
entire
disk
changes
you
know,
then
you
have
one
extent:
zero
to
n.
B
B
Yeah,
so
I
I
worry
that
we're
trying
to
design
for
the
worst
case
when
the
worst
case
is
really
the
one
you
can
probably
ignore,
because
things
like
every
other
block
on
the
disk
changed
just
back
the
whole
thing
up.
It's
really,
you
know
you're
really
not
gaining
that
much
by
skipping
half
the
blocks.
D
E
B
E
B
B
B
A
B
B
D
I
guess
like
not
just
the
so
even
if
we
park
like
the
worst
case
scenario,
it's
like
you
know
like,
even
though
the
worst
case
scenario
is
not
that
bad
I'm,
just
trying
to
think
like,
even
if,
like
we
go,
it's
just
from
a
formative
perspective
again
right.
Just
rereading
like
the
comments
there
in
the
cap
a
matter
of
some
stability
right,
if
something
like
goes
bad,
assuming,
like
everything,
goes
through
the
kubernetes
control
plane.
D
D
B
B
D
So
if
kubernetes
API
server,
like
you
know
the
the
P99,
the
SL
other
fire
I,
just
have
to
rate
limit
and
throttle,
and
you
know
basically
the
API
calls
that
affects
the
control
plane
that
affects
the
rest
of
the
cluster.
So,
regardless
of
where
the
best
case,
you
know
what
we
do
on
a
backup
service
like.
B
B
Now
there
has
to
be
a
blanket
server
statement.
I
mean
you
can
say
it's
1K
10K
one
megabyte
right,
I
mean
there's
got
to
be
a
point
where
the
API
server
handles
it
or
it's
broken
so
I
mean
that's
kind
of
like
saying
you
can't
put
anything
through
the
API
server,
because
anything
might
overload
it
because
you
might
be
running
on
somebody's
wristwatch.
I
mean
it's
like
that's
you
know,
there's
there's
always
some
minimal
reasonable
expectation.
B
D
Is
not
different
from
anything
else
right
right
and
hence
they
have
the
SLO.
You
know
metrics
defined.
So
it's
up
to
us
to
proof
that
you
know
like
so
a
week
is
5K
10K.
Whatever
numbers
we
we
plug
in
here,
is
it's
just
speculation
right?
Those
enhance,
like
you
know
those
other
Matrix
that
I
share
are
like
concrete
data
that
we
is
up
to
us
to
prove
that
it
doesn't.
B
E
E
B
B
D
D
I
think
like
so
it's
about
the
I
think
like
Prasad
has
agree
to
like
maybe
do
some
of
the
help
us
with
some
of
the
networking
benchmarking
there
maybe
like
we
can
talk
about
it
offline
about
how
to
put
some
like
concrete
numbers
to
back
up
our
claims.
At
the
end
of
the
day.
You
know
it's
I
think
like
somehow
to
some
extent
like
we
ourselves
here
are
conv.
We
have
concerns,
but
we
you
know.
D
We
also
convinced
to
some
point
that
maybe
that
is
the
right
approach,
but
we
need
to
convince
like
the
bigger
group,
a
launch,
but
one
last
thing:
I
know
it's
10
o'clock,
but
I
have
brought
up
this.
A
few
times
alluded
to
this.
A
few
times
like
I
we
found
like
are
currently
not
being
active
on
the
cap.
D
I
don't
know
when
he
will
be
returning
to
this
cap
if
he
is
I
need
to
help
with
like
someone
to
co-author
with
the
cat,
I
think
I
believe
that
Prasad
has
kindly
agreed
and
to
step
up
to
a
co-authorship
role
to
help
manage
the
cap
and
move
things
forward.
In
case,
like
you
know,
I'm,
on
holidays
or
whatever
so
yeah
is
that
all
right
is
that
the
okay.