►
Description
No description was provided for this meeting.
If this is YOUR meeting, an easy way to fix this is to add a description to your video, wherever mtngs.io found it (probably YouTube).
A
A
first
step
just
have
flexible
deployment
decisions,
or
our
capabilities
as
a
second
step
permanently
shifting
around
might
also
be
relevant,
but
first
it's
about
initial
decisions.
They
are
at
workload
should
go,
and
you
are
looking
at
environments
that
consist
of
pose
edge,
resources
and
cloud
resources.
So.
C
C
D
E
E
C
C
We
had
a
session
about
nqp
protocol
and
how
it
can
be
used
in
adduced
cases
earlier
this
year,
and
we
did
a
little
bit
of
demo
of
that
in
queue
from
Barcelona,
so
Ted,
then
we
will
introduce
the
scupper
project,
which
is,
which
is
something
we
did
work
working
on
after
it
taught
to
make
these
things
easier
and
more
consumable
and
I.
Think.
The
other
topic
we
had
here
is
proposal
for
the
coop
corn
or
North
America.
We
had
the
deadline,
I
think
on
Friday
to
make
a
proposal
is
a
working
group.
C
D
E
D
D
One
one
comment:
I
wrote
an
email,
so
we
discussed
two
weeks
ago
about
the
queue
on
North,
America
and
and
I
brought
in
an
idea
whether
we
can
cover
that
or
add
that
as
a
potential
topic,
which
is
the
network
that
we're
scheduling.
Even
it's
also
here
now.
So
we
discussed
this
two
weeks
ago
and
that's
the
reason
why
I
thought.
Maybe
it's
a
good
idea
to
give
a
short
presentation
today,
but
if
we
don't
fit
it
in
timewise,
we
have
to
sing
about
and
alternatives
how
we
can
do
that.
Yeah.
B
E
C
E
C
E
C
E
All
right,
I'm
good,
so
so
as
dejan
introduced,
we're
talking
about
I'm
talking
about
a
it's
actually
a
new
project
that
we're
starting
up.
We
call
it.
It's
called
scupper,
dot,
IO
and
we
haven't
even
published
our
website
yet
because
we
just
got
approval
from
our
trademark
folks
on
the
name.
But
what
what
it
is?
It's,
it's,
not
new
technology,
but
it.
F
E
Of
a
focus
on
a
use
case
of
an
existing
technology
and
the
upstream
project
in
question
here
is
from
Apache
Cupid.
It's
called
Apache
Cupid
dispatch
router.
It's
also
productized,
with
in
Red
Hat,
with
under
the
name
of
a
MQ
interconnect,
and-
and
it
is
a
networking
technology
for
messaging,
it
was
developed
to
support
messaging
in
order
to
scale
messaging
systems
out
into
into
large
large
deployments
and
large,
like
multi-site
deployments
and
as
such,
it
is.
E
It
is
multi-site,
it's
natively
multi-site,
so
it
was
designed
from
the
from
the
very
beginning
to
be
multi-site
and
it
works
more
like
a
networking
solution
than
it
does
like
a
messaging
solution.
But
what
we
have
found
over
the
years
is
that
containerization
and
kubernetes
in
particular,
is
a
really
good
fit
for
this
technology
and
and
we're
actually
focusing
some
of
our
effort
here
on
the
application
of
Apache
Cupid
dispatch
with
in
in
multi
cloud
environments,
so
we're
building
some
tooling
around
it.
We're
going
to
have
demonstrations
around
it.
E
So
let
me
start
off:
I'll
just
go:
I'm
not
gonna,
show
any
supplies,
but
I'm
going
to
show
you
the
console
and
and
then
the
various
components
that
are
running
and
what
you,
what
I'm
showing
you
here
is
the
actually
Cupid
dispatch
console,
and
this
is
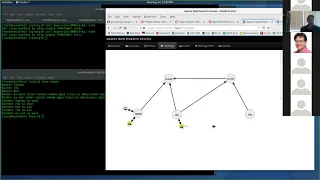
the
topology
view,
so
it
actually
shows
a
graphical
representation
of
what's
connected
to
what
so
each
of
these
circles
represents
a
locations.
Actually,
in
this
case
it
represents
a
specific
kubernetes
cluster
or
OpenShift
cluster.
E
Where
we,
you
know,
I've
got
one
running
in
Amazon.
U.S.
East
I've
got
one
running
in
Amazon
Europe
central
in
Frankfurt.
These
are
both
running
open
chef
version.
4.1
I've
got
three
of
them
that
are
more
in
an
edge
configuration
where
I've
got
one
in
Brno
Czech
Republic
I've
got
one
in
raleigh-durham.
I've
got
one
running
on
my
laptop,
so
each
of
these
three
are
actually
ok,
d3
one
one.
E
There's
no
reason
why
this
can't
be
a
mixed,
kubernetes,
openshift
and
various
flavors
of
you
know
of
the
kubernetes
implementations
they
all
interoperate,
fine
and-
and
the
other
thing
I
should
mention
at
the
outset-
is
that
we're
not
doing
anything
here?
That's
fancy
with
regard
to
networking,
so
there's
no
VPNs
installed,
there's
no
Software
Defined
Networking!
There's
nothing!
That's
done
in
firewall
rules
that
is
out
of
the
ordinary.
The
only
thing
that
we're
using
is.
F
E
These
two
public
locations
is
that
openshift
route
or
an
ingress
so
that
we
can
make
a
connection
from
you
know
from
other
points
inbound.
So
these
connections
are
all
mutual
TLS.
In
fact,
when
we
deployed
this
network
we
created
a
certificate
authority,
that's
dedicated
to
it.
The
certificate
authority
is
then
used
to
sign
certificates
for
each
of
the
locations,
so
it
makes
it
very
secure
with
regard
to
rogue
elements
trying
to
join
the
network,
they
can't
do
so
unless
they
actually,
unless
they
have
a
certificate,
that's
issued
by
that
authority.
B
B
I
get
the
impression
that
you've
got
like
global
visibility
here
of
what's
going
on
with
your
networking,
but
I'm
wondering
when
I
consumed
this
networking
from
saya
kubernetes
app.
Is
this
managing
these
network
connections
down
at
the
kubernetes
node
level?
In
other
words
the
Linux
hosts?
Or
would
this
be
apt
to
have
in
a
typical
use
case.
E
I'm
not
sure
I
fully
understand
what
what
you're
asking
there,
what
we're
not
joining
the
networks
together,
okay,
we
are
and
when
I
say,
I've
got
a
global
view.
I'm
actually
I
have
a
console
that's
connected
in.
So
let
me
show
you
what's
going
on
and
if
I
don't
answer
your
question,
please
react
it,
but
let
me
show
you
what's
going
on
the
consoles
of
these
of
these
clusters,
so
this
is
the
one
that's
in
the
Virginia,
the
US
East,
and
it's
got
one
pod
running
and
it's
a
2d
router
Jesus
today.
E
This
is
the
router
that
is
part
of
Apache
Cupid
dispatch
and
I've
got
so
that's
running
here.
It's
also
running
in
the
in
the
EU
central
cluster.
The
way
this
is
configured
right
now.
These
are
purely
pass
throughs
that
I
don't
have
any
actual
application
services
running
on
those
locations,
just
the
router
and
then,
if
I,
look
at
the
one
that
is
on
my
my
local
laptop,
you
know:
I've
also
got
the
routers.
E
E
B
E
These,
these
smaller
yellow
circles
and
again
this
is
this-
is
not
an
application
console.
This
is
really
more
of
an
infrastructure
console,
but
it
is
showing
the
connectivity
and
I
should
also
point
out
that
these
arrowheads
are.
They
depict
the
direction
in
which
the
connection
is
established.
So
we
make
a
connection
from
more
private
to
less
private,
because
that's
the
way
the
firewalls
allow
us
to
connect
now.
I
didn't
show
you
the
consoles
on
rdu
and
Brno,
because
these
are
both
configured
strictly
as
localhost
clusters.
E
B
E
E
E
Behind
network
address
translation,
they
are
not
reachable,
there's
no
VPNs,
there's
no
holes
and
firewalls,
so
the
only
way
that
they
can
connect
in
is
by
making
an
outbound
connection
to
a
public
location,
but
once
that
connections
style
now
we
have
an
overlay
network
that
can
flow
in
all
directions
and
that's
what
I'm
going
to
show
you,
so
you
can
think
of
these
lower
locations
as
being
edge,
and
we
can
deploy
these
as
edges
in
very
large
numbers.
You
know
in
thousands,
tens
of
thousands
or
you
know
whatever
is
needed.
E
It
can
be
deployed
in
very
large
numbers,
but
I
want
to
show
just
quickly
how
it
is
that
this
is
set
up,
because
this
is
actually
one
of
the
things
that
we
have
spent
quite
a
bit
of
time
on
and
right
now
we
have
a
very
flat
static
way
of
doing
this
and
I've
got
this
text
here.
Hopefully
you
can
read
it's
big
enough.
E
This
is
the
description
of
the
network,
who
I
just
declared
a
router
I've
got
one
declared
for
laptop
I've
got
one
for
raleigh-durham.
I've
got
one
for
no
I've
got
one
for
us
and
one
for
you,
you
central
and
in
the
US
East
and
Europe
central
I
provided
the
URL
for
the
route.
This
is
kind
of
a
temporary
measure,
we're
building
tooling
around
to
make
this
just
automatic.
E
But
the
way
we
right
now
is
I
provided
the
route
that
will
be
used,
the
URL
that's
used
to
contact
them
and
then
once
it
declared
the
locations,
then
I
defined
the
connectivity.
So
I
said
you
know
laptop
should
connect
the
u.s.
East.
Are
you
the
u.s.
East
Russia?
Are
you
connecting
both
ways
for
the
redundancy
bro?
Can?
Actually
you
Central
and
use
central
cash,
the
u.s.
East?
E
E
All
I
did
was
go
to
those
clusters.
Do
an
OC
apply
or
you
know,
queue
control,
apply
of
the
animals
and
then
that
that
brought
the
that
brought
the
network
up
so
easy
animals
have
the
secrets
for
all
the
certificates
that
are
required.
It
has,
you
know
the
deployments
for
the
router.
It
has.
You
know
the
routes
that
are
needed
if
necessary
and
all
the
things
that
that
need
to
be
put
in
place.
So
not
only
do
we
do
not
do
anything
fancy
with
networking
here
we
also
don't
choir,
elevated
or
admin
privileges.
E
D
D
E
Yeah,
we
don't
provide
tooling
for
setting
up
clusters,
there's
lots
of
people
working
on
that
and
that's
not
really
our.
We
all
consider
our
responsibility,
but
what
we're
doing
is
we're
saying
that
once
you
have
the
clusters
or
the
name
spaces
in
the
clusters,
we
will
make
it
easier
for
you
to
connect
them
together.
E
So
having
done
that
that
we
now
have
this
overlay
network
and
and
what
we,
what
I
have
running
down
on
rdu
is
it's
it's
a
it's
a
it's
a
simple
web
service.
Actually,
so
it's
just
a
website
that
that
when
you
asked
us
that
it
echoes
back
the
arguments
that
you
sent
to
it
and
it
also
tags
on
an
indication
of
what
the
name
of
the
pod
is
that
serviced
it.
So
you
know.
F
E
Look
at
you
know
this
is
the
console
on
on
my
rdu
system.
If
I
say
you
know,
see,
get
pods
I'll
see
that
I
have
a
number
of
things
running
but
be
the
HTTP
simple
service
is
the
one
that
we
deployed.
This
is
just
a
very
simple
web
service.
There
are
two
of
them
deployed,
so
there's
this
jnt'
pn1
and
there's
the
LC
LC
RC
version
of
us.
It's
scaled
up
to
two.
F
E
If
I
say
OC
guess
service
here,
I've
got
a
service
for
my
service
and
I've
got
a
service
for
Echo,
and
this
is
what
I
would
use
then
to
connect
in
these
are
actually
proxy
endpoints
I,
don't
have
any
services
running
locally
if
I
say
OC
get
pods
I
have
had
only
the
router
and
these
proxies,
but
those
the
HTTP
service
is
not
running
locally.
On
my
laptop,
it's
only
running
here
at
our
do
you
and
to
reach
it
it's
a
two
hop.
E
You
know:
I
have
to
go
out
to
the
public
and
come
back
into
the
other
edge
to
reach
it.
So
if
I
were
to
do
a
curl
access
to
that
service,
where
I
would
you
know
apply
some
sort
of
you
know,
you
know
args,
you
know
for
the
application
or
whatever
it
might
be.
Then
you'll
see
that
I
get
a
response
back.
They
said
it
got
to
get.
It
was
handled
by
the
J
and
TP
n
pod
and
I.
Do
it
again,
you'll
see
that
it'll
balance
to
the
other
one
so
I
can
you
know?
E
I
can
run
these
and
it'll
round-robin
locally
because
they're
of
equal
cost
down
here.
So
what
is
happening
here
is-
and
you
can
figure
this
sort
of
an
edge,
consider
H
case
where
you
know.
Perhaps
this
is
an
edge
device
or
an
edge
present
end
point
that
requires
some
form
of
direct
command
and
control,
and
this.
E
E
E
G
That
way,
yes
yeah
well,
especially
when
you
start
talking
about
edge
right
elation,
right
I
mean
you
kind
of
alluded
to
that
fact.
So
it's
really
okay.
Does
that
mean
I
can't
talk
to
that
edge
device,
and
it
can
only
talk
to
me
so
ingressing
into
the
clusters
or
relying
on
the
ability
to
press
out
to
the
edge
so.
E
G
E
And
there's
actually
a
couple
of
different
security
models
that
you
can
do
here.
You
could,
you
could
have
you
know
a
trusted
edge
where
the
edge
is
like
a
full
member
of
this
network
and
it
could
apply
its
own.
You
know
policy
because
we
do
have
the
ability
to
apply
access
policy,
but
you
could
also
have
the
trip
yeah.
The
edges
are
being
untrusted
where
they
makes
a
connection
in
you
know,
there's
where
this
connection
in
is.
E
G
E
E
You
hear
the
TCP
echo
and
just
for
completeness
sake,
I'll
I'll
demonstrate
with
it
with
a
should.
I
should
be
using
netcat
I'm
using
telnet
in
this
case.
If
I
tell
that
to
this
service
locally,
and
then
you
know
send
a
line,
it
cannot
go
back
and
tell
me
which
in
fact,
the
pod
that's
on
the
Rd,
so
I'm
able
to
access
not
just
web
based
applications
that
also
make
connections
across
this
network
and
I
can
also
do
more
complex
things
at
the
ATP
level,
like
multicast,
anycast,
balances,
traffic,
etc.
G
G
E
G
E
Networking
was
really
done,
you
know,
without
any
knowledge
of
how
networking
is
done
in
the
networking
world.
Well,
you
know
with
with
you
know,
manually
created
routing
tables
and
such
so.
What
we
did
is
was
be
separated.
The
brokering
and
queuing
of
messages
from
the
routing
of
messages
and
keep
a
dispatch.
Router
is
the
routing
part,
so
it
doesn't
do
any
storage.
It
doesn't
do
any
brokering,
it
doesn't
do
any
queuing.
All
it
does
is
get
messages
from
places
where
they're
produced
to
where
they're
being
consumed,
I
can't
be
on
a
broker.
E
C
C
E
The
relationship
we
get
this
question
a
lot
like
you
know:
how
does
this
relate
to
things
like
sto
or
or
you
know,
other
kinds
of
service
mesh
technologies,
and
it
it
overlaps
them
quite
a
bit.
You
know,
SCO
is
a
different
way
of
dealing
with.
You
know
how
am
point,
how
micro
services,
locate
and
balance
across
different
micro
services
sto
is
very
edge
centric
and
puts
the
intelligence
at
the
edge
and
I'm
talking
about
the
edge
a
little
differently
than
in
the
context
of
this
meeting.
Is
it's
really
at
the
you
know
at
the
application?
E
Each
application
knows
where
all
its
or
possible
services
are
and
then
does
its
own
load.
Balancing,
whereas
and
community
can
actually
little
bit
more
of
a
smarter
network
where
you
know
it
doesn't
you
know
the
endpoints
are
just
talking
to
an
address
and
they
don't
need
to
know
where
the
where
the,
where
the
destinations
are
it,
but
they
know
that
they'll
their
messages
or
their
traffic
abhi
routed
there
by
the
network
and
network,
will
then
take
care
of
getting
things
to
the
places
where
they're
being
serviced
most
quickly,
because.
E
Knowledge
of
you
know
what
is
the
backlog?
How
many?
How
many
unacknowledged
messages
I
sent
to
each
particular
server
and
I
can
actually
pick
the
server.
That
is
acknowledging
messages
more
quickly
and
use
that
you
know
as
a
more
live
type
of
load
balancing.
But
it's
there
are
there's
some
overlap
to
what
we're
doing
and
what
is
going
on.
The
service
measure,
world
I
think
that
overlap
will
become
bigger,
as
we
continue
on,
because
we
are
actually
interested
in
doing
a
lot
of
the
traffic
management
and
instrumentation
that
you
would
find
in
one
of
those.
E
Because
again
we
are
natively
multi
cluster,
whereas
something
like
envoy
or
sto
is
every
single
cluster
and
they're
trying
to
now
get
get
it
to
work
in
multiple
clusters
and
a
lot
of
the
multi
cluster
work
is
just
trying
to
get
two
clusters
or
a
star
topology
or
a
mesh
topology
to
work
and
and
we're
doing
we're
supporting
pretty
much
arbitrary,
topologies,
even
multi-hop
and
again
in
hybrid
cloud
or
an
edge
cloud.
I.
Think
it's
very
important
because,
with
edge
you're,
almost
you're
very
often
going
from
private
to
public
to
private.
E
B
Would
perhaps
another
way
to
look
at
this?
Be
that
you're
at
a
different
level
of
the
networking
stack?
You
know
what
my
perception
in
this
deal
with
envoy
is
very
app
centric
and
the
whole
concept
of
having
the
sidecar
bonded
to
a
specific
app
makes
itself,
whereas
this
is
really
dealing
with
the
underlay,
the
a
lower
level
of
the
energy.
So
you
know
they're
different
use
cases.
Otherwise
you
could
almost
say
that
conceptually
you
could
use
both
at
once,
because
there
are
different
layers
of
the
stack.
It's.
E
Possible
you
could
even
layer
one
over
the
other
I'm,
not
sure
that
makes
sense,
but
yet
but
I
think
what
you're
saying
is
correct,
because
what
we're
doing
is
we
are
actually
doing
routing
at
layer
7.
So
if
you
think
about
the
history
of
what
you
know,
what
happened
in
data
networking,
you
know
look
Larry
and
networks
at
layer
2,
you
know
with
MAC
addresses
existed
and
they
couldn't
scale.
So
they
basically
went
to
an
overlay
of
IP,
which
is
a.
E
So
where
everything
was
now
addressed
by
a
different
kind
of
address,
but
then
we
were
able
to
go
across
routers
in
wide
area
networks
and
be
able
to
individually
address
things
across
the
world,
and
the
problem
then
became
that
we
ran
out
of
addresses
and
instead
of
going
up
another
layer,
would
they
the
the
industry
kind
of
took
advantage
of
our
client-server
orientation
and
said
well,
we'll
just
say
that
you
know
the
server
we'll
be
limited
to
the.
It
will
stick
the
public
servers
in
this.
E
Space
but
then
we'll
use
network,
address
translation
and
create
huge
networks
of
private
networks
where
we
can
proliferate
as
many
endpoints
of
clients,
as
we
want
problem
now,
is
they
multi-cloud
were
no
longer
client-server,
so
we're
we're
in
the
case
where
we're
now
we
really
want
individual
services
in
all
locations
to
be
able
to
address
other
individual
services
in
other
locations,
and
the
the
makeup
of
the
network
isn't
conducive
to
that.
It's
not
even
built
for
that.
So
what
we've
done
with
this?
G
E
E
E
Or
a
software
development
kit,
an
SDK
for
you
before
the
actual
routing
is
we
do
not
the
the
the
way
that
is
interface
to
is
using
the
AMQP
protocol.
So
if
you
create
a
listener
or
create
a
sender
for
a
particular
address
that
becomes
propagated
through
the
network
and
accessible
through
the
network,
but
there
isn't
an
SDK
specifically
for
setting
up
routes
or
anything
like
that.
The
routes
are
automatic,
I'm,
not
sure.
If
I
fully
answered
your
question.
E
C
We
I
think
yeah
well,
I'm,
looking
forward
to
you,
know,
setting
up
the
website
and
more
work
there
and
I
think
maybe
selfishly
I
would
like
to
see
another
presentation
in
you
know
you
know
months
or
so
to
see
you
know,
maybe
a
bigger
deep
dive
on
on.
You
know
how
to
sing
said,
set
things
up,
how
you
know
llamo
look
like
and
all
the
new
things
did
not
come
up
in
Indy
space,
I
think
yeah.
G
G
E
E
Are
yes?
Yes,
in
fact
the
metrics
said
is
actually
quite
rich
because
the
the
counts
are
at
the
application
address
level.
So
you
can
get
good
information
about.
You
know
what
specific
addresses
specific
services
are
doing,
but,
yes,
it
is
exposed
by
Prometheus
and
it's
exposed
other
ways
as
well.
That's.
D
Can
see
it?
Okay,
let
me
let
me
really
fly
over
it,
just
to
give
you
a
glimpse
and
an
idea
so
that
we
can
better
discuss
whether
it's
fit
for
and
the
cube
core
North
America
not,
and
maybe
we
can
have
a
deep
dive
later
in
a
later
session
that
okay
yeah
sounds
good
okay.
So
what
what
I'm
talking
about
is
the
one
aspect
of
what
we
call
seamless
computing?
D
Maybe
some
of
you
remember:
I
gave
a
short
presentation
demo,
maybe
in
my
months
ago,
in
this
working
group,
and
today,
I
would
like
to
talk
about
network
aware
scheduling,
so
so,
just
the
overall
idea
that
we
wanna
solve
is
or
the
vision
that
we
have.
So
if
you
consider
an
infrastructure
where
ever
you
have
compute
nodes
that
are
in
different
places,
so
there
are
some
that
are
in
the
cloud.
D
There
are
some
in
the
edge,
maybe
some
even
on
the
embedded
devices
and
on
the
other
hand
you
have
you
have
a
distributed
application
that
consists
of
several
workloads
that
are
interacting
with
each
other.
So
so
the
dashed
lines
here
is
communication
between
those
workloads
where
they
exchange
data.
D
Maybe
in
one
direction,
maybe
in
both
directions
with
with
different
characteristics
and
now
what
we
want
to
have
is
we
want
to
have
a
system
that
does
the
scheduling
so
in
the
kubernetes
terminology,
the
scheduling
so
the
the
allocation
of
these
workloads
to
the
compute
nodes
in
these
different
domains
done
automatic
and
and
based
on
the
requirements
of
the
workloads
and
the
communication
between
them,
so
that
that's
the
overall
idea.
So
we
recall
it
here,
it's
a
constraint
based
and
may
be
optimized
allocation
of
workloads.
D
D
Actually,
our
model
of
how
this
we
want
to
make
this
happen
is
that
we
have
some
model
that
describes
the
requirements
of
the
applications.
We
have
a
model
that
describes
the
capabilities
of
the
infrastructure.
So,
and
this
is
the
compute
nodes,
yes,
but
it's
also
the
connectivity
between
the
compute
nodes
and
then
we
have
something
in
the
middle
that
we
also
call
the
scheduler.
That
does
the
mapping
so
that
map's
all
these
workloads
to
the
infrastructure,
considering
all
of
the
requirements
and
fulfilling
all
of
the
requirements.
D
So
that's
that's
the
basic
idea
and
now
comes
the
link
to
kubernetes.
Of
course,
kubernetes
can
do
such
a
thing.
So
if
we
think
about
these
workloads,
each
of
them
would
be
placed
in
a
container
and
we
kubernetes
does
the
scheduling
of
these
containers.
So
that's
that's
how
we
can
use
it.
So
then
our
compute
nodes
are
just
kubernetes
nodes
and
we
can
map
is
at
least
some
of
these
application
requirements
to
the
kubernetes
manifests
or
the
deployment
files.
D
We
can
map
some
of
the
infrastructure
capabilities,
maybe
to
think
that
could
the
dew
blood
reads
out
of
the
compute
nodes
itself,
or
that
is
configured
in
the
in
the
cube,
config
cubelet
config
files.
So
there
is
some
some
mapping
to
to
this
architecture
even
in
kubernetes
today,
and
but
if
we
look
at
and
we
have
done
there
so
so
we
have
analyzed
what
is
possible
with
kubernetes
today
and
the
different
scheduling
features
that
it
that
it
provides.
D
So
you
can
do
already
some
of
the
tasks
that
you
wanted
to
do,
but
there
are
also
some
limitations
and
the
most
prominent
limitations
are
that
today,
kubernetes
has
no
knowledge
about
how
the
cluster
nodes
are
networked.
So
so
it
has
no
network
awareness,
and
so
it
cannot
consider
anything
requirement
like
you
want
to
have
a
bound
bounded
latency
between
two
two
of
these
workloads
when
they
exchange
data
or
or
such
such
things.
Also,
what
kubernetes
cannot
do
is
it
cannot
optimize
the
scheduling.
D
So
actually
let
let
me
jump
over
this
also
jump
over
this.
So
this
is
much
more
detail.
We
have
gone
gone
that
path,
quite
some
some
distance
of
what
we
did
so
far.
We
have
you
find
an
application
model
in
sort
of
a
mathematical
way,
so
we
have
described
these
workloads
and
the
interfaces
we
call
them
between
the
workloads
in
a
mathematical
way.
D
We
have
also
described
the
infrastructure
in
a
similar
way
so
again,
consisting
of
compute
nodes
of
network
links
and
of
network
nodes
that
connect
these
links,
and
each
of
these
component
has
has
parameters
so
the
workloads,
for
example.
They
have
things
that
describe,
for
example,
the
compute
requirements.
The
memory
requires,
but
also
requirements
like
latency
or
bandwidth,
characteristics
of
the
data
that
are
exchanged
and
the
same
for
the
for
the
infrastructure
components,
and
if
we
do
that-
and
we
have
done
that.
D
So
if
you
have
a
mathematical
model
of
both
the
application
and
the
infrastructure,
you
can
describe
the
scheduler
as
a
constraint,
solver
or
an
optimization
problem
with
constraints,
and
we
did
that
as
well.
So
you
see
here
some
some
formulas
that
represent
that
we
have
a
sort
of
complete
description
of
this
and
what
we
also
have
done
is
we
entered
this
optimization
problem
into
into
some
tools
and
we
played
it
through
for
some
examples.
So
what
you
see
here,
it's
very
small,
but
we
become
beginning
in
a
minute-
is
an
example
from
a
funded
project.
D
It's
actually
it's
a
wind
park
problem
that
is
soft
and
I.
Give
you
the
whole
picture
and
what
you
see
or
let's
first
concentrate
on
the
infrastructure.
So
so
we
have
compute
nodes
that
are
on
these
different
levels.
So
it's
exactly
the
kind
of
problem
that
we
and
every
one
is
also.
We
have
things
that
are
very
close
to
the
wind
turbine,
so
these
are
actually
embedded
nodes,
most
of
them
very
close
to
the
wind
turbine
that
that
where
sensors
are
attached,
but
they
also
have
some
generic
compute
capacity.
D
We
have
a
small
on
premise
cloud
so
to
say
so
private
cloud
that
has
some
virtual
machines
running
there,
which
are
higher
capacity.
We
have
some
nodes
in
the
cloud,
also
virtual
machines,
and
we
have
a
full
network
connectivity
network
between
this
with
different
characteristics.
So
we
entered
that
into
the
model
and
we
also
have
an
application
that
runs
or
shall
run
on
this
infrastructure,
and
we
have
put
that
into
these
components
here
that
I,
interconnected
and-
and
you
see
also
the
blue
ones.
D
Those
are
components
that
are
bound
to
specific
compute
nodes
because
they
sort
of
should
take
one
of
those
here
at
the
bottom
and
they
read
censors.
So
this
only
makes
sense
on
a
very
specific
node,
where
this
sensor
is
attached,
the
other
one.
So
this
this
yellow
green
greenish
ones
they
they
can
be
located
wherever
they
fit.
So
there
are
some
flexibility
in
the
deployment
that
that
we
also
want
to
exploit,
and
you
also
see
the
connectivity
between
these
nodes.
D
So
each
of
these
components,
when
you
place
it
somewhere,
it's
sort
of
like
connected
to
rubber
bands
and-
and
you,
when
you
put
it
somewhere
else,
these
rubber
bands
will
follow.
So
there
is
it's
not
an
independent
scheduling
decision
per
one
workload,
but
it's
also
depending
on
the
other
workloads
that
are
connected
to
it,
and
now
you
yeah
I,
think
it
becomes
clear
that
the
current
scheduling
mechanism
of
kubernetes,
which
treats
only
a
single
part
at
a
time,
does
not
do
the
job
currently.
So
we
have
run
through
this,
so
we
have
completely
modeled
this.
D
This
example-
and
this
is
the
tool
that
we
used.
We
were
currently
using
yet
another
tool
which
has
a
better
optimization
library
behind
it,
but
this
is
called
Minisink.
Maybe
you
know
it's
open
source.
You
see
here
the
description
of
the
problem.
There
is
a
more
detail
to
that.
Of
course,
you
see
here
one
one
solution
that
the
solver
found
where
I
placed
the
workloads.
D
Also
it
comes
with
this
core,
so
this
thing
really
optimizes
the
score
that
you
see
here.
It
maximizes
the
total
score
that
is
defined
somewhere
else
and
on
the
right-hand
side
you
see
the
the
optimal
solution.
That
is
the
output
of
this.
Of
this
optimization
run.
You
see
here
the
infrastructure
with
the
compute
nodes
and
the
connectivity
between
them.
So
you
see
the
links
they
they
are
color
and
that's
the
colors.
D
According
to
the
bandwidth
utilization
on
these
links,
you
see
this
one
link
here,
which
is
in
our
example,
at
DSL
link
that
that's
pretty
much
loaded
with
with
between
40
and
60%,
and
this
these
bars
indicate
how
much
of
the
RAM
and
how
much
of
the
CPU
of
those
nodes
is
actually
used.
That's
normalized!
So
if
the
bar
goes
totally
to
the
right
side,
it's
a
100%
usage
on
that
node.
D
So,
actually,
that's
where
we
are
standing
and
now
there's
a
couple
of
questions,
because
we
have
now
I
think
a
model
we
have.
We
have
shown
that
this
model
also
works.
If
you
use
this
this
optimizer
and
now
the
question
is:
how
do
we
bring
that
or
how
could
do
we
bring
that
together
with
a
kubernetes
scheduler?
D
So
that's
the
the
basic
question.
So
what
would
be
the
best
way
to
implement
the
mechanisms
that
we
need
for
seamless
computing
with
with
kubernetes?
Is
it
a
custom
scheduler
or
are
there
other
ways
that
there
is
one
thing
that
we
need
for
this
is
to
treat
several
order,
treat
dependencies
between
parts
when
scheduling
so
and
that's
totally
different
to
how
kubernetes
scheduler
currently
works.
Well,
so
that's
also
an
interesting
problem
that
that
we
need
to
solve
and
there's
a
couple
of
other
questions
that
come
up
with
with
our
ideas
here.
D
F
Very
cool,
Harold
and,
and
your
first
question
there
is
so
I
know,
you've
seen
you
know
a
bit
of
stuff
regarding
eclipse,
I/o
fog
and
the
work
we're
starting
to
do
in
the
in
the
newly
forming.
You
know
clip
such
a
working
group.
The
answer
to
this
is
yes,
and
so
far
we've
been
working
with
a
custom
scheduler
for
kubernetes
to
deal
with
things.
In
addition
to
the
stuff
that
you're
illustrating
around
you
know,
very
particular
hardware
availability
on
edge
nodes
doesn't
have
an
rs-485
capable
serial
port.
F
F
Aware,
and
so
we've
been
calling
it
edge
aware
scheduling
on
this,
so
I
think
the
answer
is
yes
and
from
what
I'm
seeing
in
the
market,
there
are
so
many
organizations
asking
these
same
questions
about
how
to
do
this
stuff,
but
not
having
a
standard
approach,
so
I'm,
not
sure
to
what
extent
of
Siemens
is
looking
to.
You
know
kind
of
branch
out
this.
This
knowledge
that
you
have
but
I'd
say
it's
a
really
high
value.
F
B
Harold
on
your
slide
here,
asking
about:
are
there
any
proposals
activities
with
a
single,
similar
objective?
Yes,
in
the
storage
saying
this
has
been
discussed
for
years
in
fact,
and
they
do
have
solutions
here
and
in
many
ways
the
restrictions
on
storage
generally
are
related
to
networking.
Anyway,
it's
really
common
to
have
a
dedicated
network
for
storage,
because
you
don't
want
nosy
neighbor
problems
where
heavy
heavy
use
of
networking
for
network
connected
storage
impacts,
compute
workloads,
so
they've
already
come
up
with
mechanisms
to
support
this
in
the
storage
arena.
B
B
The
modern
way
of
getting
these
things
into
the
kubernetes
scheduling
is
to
write
up
a
cap,
a
proposal,
it's
reviewed
by
the
architectural
committee,
but
storage
kind
of
predated
that
as
a
mandate,
so
they
went
down.
If
you
go
look
at
the
historical
documents,
you
might
not
be
able
to
pull
it
off
the
same
way
they
did.
F
B
I
assume
since
you're,
with
Siemens
I'm,
guessing
you're
in
Germany
and
if
so
I
know,
there's
somebody
Michael
with
my
company
VMware,
who
is
very
familiar
with
what
happened
in
the
context
of
storage
related
to
scheduling.
So
if
you
would
have
an
opportunity
perhaps
to
meet
with
him,
you
too
might
have
a
really
interesting
conversation.
Okay,
they
probably
planning
on
going
to
cue
con
North
America.
D
B
B
D
G
C
C
C
C
F
C
F
F
Twenty-Eight
right,
oh,
that
one's
that
one
actually
I'm
out
on
on
holiday.
So,
okay,
let's
do
it
this
way.
Let's
have
Harold,
let's
have
a
side
discussion
and
then
we'll
bring
some
some
discussion
into
this
working
group
and
schedule
a
timeslot
for
it.
That
way,
we
can
have
a
recording
of
what
we're
discussing
between
the
edge
compute
workloads
and
scheduling
and
the
network's
aware
scheduling.
So,
let's
plan
for
that
yeah.
B
We
were
going
to
discuss
the
proposal
for
Cuba
and
North
America.
There's
a
couple
line
items
in
the
meeting
notes.
One
I
added
in
of
course
heralds
I
think
they're.
Actually,
arguably
the
same
thing.
My
proposal
was
that,
as
part
of
our
proposal,
we
do
a
survey
of
IOT
edge
protocols
and
that's
not
just
you
know
like
all
of
them
like
mqtt
AMQP,
there's
a
number
of
them
might
be
relevant
and
you
know
you
can
already
find
surveys
of
everything
out
there.
B
Management
and
dashboards
for
observability
part
of
that
would
seem
to
be
perfectly
aligned
with
the
presentation
we
just
got
today
on
the
scupper
project,
and
if
we
make
this
a
survey,
we
can't
go
deeply
into
each
one
but
I'm
thinking
just
like
we
did
in
China
where
we
could
go
one
to
a
max
of
three
slides
on
these
different
things.
I
think
that
would
be
a
really
interesting
presentation
and
related
to
these
protocols
would
be
the
subject
Carol
just
brought
up
of
you
know
what
are
the.
B
You
try
to
combine
that
with
actual
workloads.
You
are
dispatching
with
the
kubernetes
scheduler,
how
you
know
it's
not
just
to
get
the
networking
in
place,
but
they
use
it
with
the
applications.
I'd
like
to
see
that
specific
to
Laura
as
one
example
yeah.
Maybe
if
others
can
open
this
dock
and
put
you
know
as
a
survey,
you
could
help
out
a
lot
by
just
putting
the
list
of
things
that
you
don't
covered
yeah
and
maybe
I'll
hit
you
up
to
do.
All
we
have
to
do
by
Friday
is
to.
F
B
Restricted
you're
only
allowed
900
characters,
so
some
we,
we
might
have
to
abbreviate
this
a
lot
and
then,
when
it
comes
time,
if
they
accept
this
proposal,
we're
basically
asking
the
CNC
F
for
permission
for
them
to
grant
us
a
session
and
I
might
ask
you
for
some
follow-up
help
on
putting
together
a
slide
or
two.
If
you
nominate
something
as
appropriate,
great.