►
From YouTube: Kubernetes WG IoT Edge 20210127
Description
January 27, 2021 meeting of the Kubernetes IoT Edge Working Group. Introduction to Akri an open source project that attempts to define a Kubernetes based approach on representing IoT devices (such as IP cameras and USB devices) found on the edge as native Kubernetes resources (Jiri Appl). Also an Eclipse ioFog update on Kubernetes integration with architecture discussion and open forum. (Serge Radinovich/Todd Papaioannou)
A
A
We
have
a
rather
full
agenda,
so
I'm
tempted
to
have
the
newcomers
introduce
themselves,
but
I'm
afraid
that
these
two
things
might
take
up
the
whole
time.
So
how
about?
If
we
reserve
introductions
and
meet
agree
till
the
end?
If
we
have
time
and
I'll
turn
this
over
right
now
to
jerry
just
a
minute.
While
I
give
you
host.
A
B
Great,
thank
you
thanks.
Everybody
super
excited
to
be
here
with
you
and
share
what
we
have
been
working
on
with
akri,
I'm
here
with
kate,
we're
both
software
engineers
for
microsoft,
and
we
have
been.
We
have
been
working
on
acry
for
a
while.
So
I
create
an
open
source
project
for
building
connected
edge
kubernetes,
and
can
you
know
it
can
be
used
to
expose
heterogeneous
sensors
mcu
class
devices
and
also
like
connected
peripherals
or
brand
field
devices
as
resources
to
the
communities?
B
So
why
did
we
choose
to
go
to
build
background?
When
we
looked
at
kubernetes
on
the
edge,
we
know
that
it
can
run
just
fine
on
a
heavy
edge.
I
can
run
on
the
light
edge.
There
have
been
projects
like
k3s
or
cool
badge
that
runs
just
fine
on
light
edge,
but
when
you
look
at
the
tiny
edge
and
the
device
is
that
many
of
them
are
single
purpose
devices,
they
cannot
run
ordinary
compute.
B
We
wanted
to
simplify
how
you
can
expose
these
connected
lineage
devices
to
kubernetes,
but
we
wanted
to
do
them
in
as
kubernetes
native
way
as
possible
and
I'll
go
into
the
details,
how
we
are
doing
it
on
the
next
few
slides
then
later,
when
these
devices
are
exposed
in
the
cluster.
We
also
wanted
the
cluster
to
kind
of
automatically
take
advantage
of
them
and
also
allow
you
to
automatically
schedule
workloads
based
on
when
the
devices
are
available
and
deschedule
them,
and
they
go
away
now
in
order
to
make
this
useful
for
everybody.
B
We
understand
there
there's
so
many
protocols
and
there's
probably
nobody
who
can
do
all
of
them,
and
so
we
wanted
to
make
it
super
easy
to
extend
it.
So
anybody
can
come
and
bring
you
know
either
their
protocol
discovery
or
bring
down
what
we
call
brokers,
which
is
basically
the
part
that
interacts
directly
with
the
discovered
device
and
I'll
go
into
the
details.
But
the
idea
here
is
it's
it's
easy
to
extend.
B
B
So
with
that,
let's
talk
a
little
bit
about
what
what
accurate
is
before
I
before
I
actually
go
into
the
details.
I
kind
of
wanted
to
do
a
few
more
kind
of
parallels
that
we
are
trying
to
draw
to
really
design
the
kubernetes
native
acrylic
is
designers,
kubernetes,
name
application,
compose
controllers
and
and
crds,
but
we
wanted
to
go
even
further
to
really
feel
native
in
kubernetes
and
when
we
looked
at
kubernetes
we
know
there
are
all
these
interfaces.
Cni,
csi,
cri,
making
kubernetes
is
super
flexible
right.
B
You
can
kind
of
bring
your
own
thing
and
now
kubernetes
can
do
more
than
it
did
before.
Yet,
at
the
same
time,
the
application
developer
doesn't
have
to
worry
about
it.
Then
they
get
a
common
interface,
and
so
we
thought
that
you
know
exposing
allowing
kubernetes
to
react
to
changes
in
the
physical
environment
around
the
kubernetes
cluster.
It
should
also
be
exposed
through
some
sort,
some
interface
like
that.
So
that's
one
part,
the
other
part
where
we
are
kind
of
thinking,
plug-and-play
model,
if
you
will
is
in
in
health
kubernetes,
can
dynamically
change
right.
B
You
can
scale
workloads
based
on
the
the
traffic
coming
to
the
cluster.
You
can
do
auto
scaling,
you
can
do
all
sorts
of
policy
driven,
but
it
makes
sense
to
kind
of
employ
a
similar
concept
for
the
edge
that
when,
when
you
plug
in
a
new
device,
you
don't
have
to
have
an
admin
to
go
reconfigure,
your
workload
so
that
it
can
take
advantage
of
the
device.
B
So
the
second
part
of
that
agree
is
reacting
to
the
changes
so
automatically
deploy
a
workload
based
on
the
available
devices
and
they
go
away
required
can
be
scaled
down
again.
So
now,
how?
How
does
agree
actually
accomplish
this
so
agree
has
four
main
components.
It
starts
with
a
configuration.
So
it's
a
it's
a
crd
and
in
the
configuration
you
specify
what
are
the
set
of
devices
that
you
want
to
expose
into
the
cluster?
B
Here
we
have
a
snippet
which
is
a
very
simplified
one
and
kind
of
generalized,
but
but
in
the
spec
you
basically
specify
what
protocol
you
want
to
use,
and
this
is
used
to
then
run
the
right
code
to
discover
devices
over
that
specific
protocol,
and
you
can
specify
also
you
can
specify
some
filters,
so
you
can
say.
Oh,
I
want
only
cameras
from
this
specific
manufacturer
or
I
want
to
look
for
devices
with
this
specific
product
id.
B
B
B
This
metadata
is
then
later
into
the
broker,
and
that's
basically,
the
bot
that
gets
deployed
to
take
advantage
of
the
device.
So
so
the
broker
is
specified.
You
know
it's
just
another
code
image,
a
container
image,
there's
a
specific
agree
to
it,
and
you
can
you
know
you
can
this
can
be
really
anything
you
can
you
know
you?
Can
you
you
do
your
application
specific
broker?
B
You
can
do
protocol
translation
brokers,
you
can
do
authentication
to
the
devices
you
can
do
firmware
updates.
It's
basically
bring
your
own
thing,
but
it's
easy
to
add
and
and
then
reagent
when,
when
the
broker
is
deployed
plugs
in
that
information
about
how
to
connect
to
the
device
it
either.
It's
an
environment
variable
with
a
connection
string
or
if
it's
a
local
device,
we
directly
mount
it
into
the
container.
B
Now,
how
does
this
broker
get
created?
So
that's
where
the
last
component
comes
in
play
so
after
accuri
agent
discover
the
device
and
registers
in
the
instance
the
control
is
monitoring
the
instances
and
whenever
there
is
a
new
instance,
it
will
look
at
its
associated
configuration
and
if
the
broker
reports
spec
has
been
specified,
we'll
go
and
deploy
the
broker
hold
and
that
kind
of
completes
the
circle.
B
B
We
currently
support
three
protocols,
so
we
support
udef
for
local
devices,
so
you
can
specify
a
generic
linux
based
udef
rule
and
it
will
discover
the
devices
on
the
nodes
where
the
agent
runs
it's
up
on
with
to
discover
ip
based
cameras
and
we
support
opcwa
for
industrial
settings
but
but
and
and
and
the
code
to
do
the
discovery
is
running
within
acreage.
We
do
have
an
extension
that
we
are
working
on
right
now,
so
that
we
allow
to
have
these
discovery
handlers
to
run
as
separate
bots
as
well.
B
So
here
we
have
a
simple
cluster
to
node
cluster.
Not
there
should
not
be
anything
out
of
ordinary
on
this
cluster.
At
the
moment,
so,
let's
deploy
it's
just
a
single-hand
chart
all
these
components
we
talked
about-
I
I
might
not
have
stressed
about
it,
but
accre
agent
runs
on
every
node
and
that
because
it's
leveraging
the
device
plugin.
So
it
is
running
like
a
device
plugin.
We
also
want
to
run
it
on
every
node
in
so
that
we
can
detect
all
the
devices
that
each
individual
node
sees.
B
It
could
be
that
not
all
the
nodes
see
all
these
and
hence
it
needs
to
run
everywhere
and
then,
when
the
devices
are
discovered,
it
also
annotates
inside
the
instant
crd,
which
nodes
can
see
any
specific
device
and
I'll
get
that
get
to
that
in
a
bit.
Why
it's
important
so
after
we
have
agreed,
we
can
deploy
our
application.
B
So
this
is
an
application
that
wants
to
actually
take
advantage
of
the
connected,
discovered
devices
here
for
simplicity,
it's
a
single
boat,
but
conceptually
it
can
be
any
anything
whatever
you
want,
and
this
application
has
nothing
to
do
with
agree.
And
if
you,
you
know,
if
you
didn't
have
three,
you
would
probably
go
and
provision
it
with
some
configuration
which
says.
Oh,
this
is
the
ip
camera
that
you
want
to
go
look
at,
or
you
would
have
to
write
your
discovery
logic
directly
into
that
application
to
go,
discover
and
connect
the
camera.
B
B
So
you
start
with
the
configuration
I
mentioned
in
the
past
here
you
specify
you're
doing
on
with
protocol
discovery
and
we
are
not
specifying
any
filter,
meaning
any
on
the
camera
will
be
exposed
and
we
specify
the
broker
bot.
So
we
want
to
deploy
a
specific
container
to
every
camera
when
we
discover
it
and
we
specify
capacity
of
one,
and
that
means
we
deploy
up
to
one
broker
for
discovered
camera
and
I'll,
explain
how
that
works
later.
B
So
now
that
we
have
configuration
the
acry
agent
react,
reagent
is
basically
listening
for
new
configurations
and
there
is
a
new
configuration
downloads
it
and
it
uses
that
to
initialize
the
search
right.
So
it
invokes
the
right
discovery
handler
look
for
the
set
of
devices,
as
declared
in
the
spec
of
the
configuration,
then
at
any
point
somebody
else
can
come
in
a
plug-in
camera.
This
might
have
happened
before
we
installed
agree,
but
after
you
can
keep
adding
more
cameras
or
removing
them
and
agree.
Will
dynamically
react
to
that.
B
So
if
the
camera
is
meeting
the
expectation,
the
filter
specifying
the
configuration,
the
accre
agent
report
it
into
the
instant
crd
and
register
them
through
device.
Plugin
then
agree
controller
notices
and,
as
we
talked
about
earlier,
it
deploys
this
broker
port.
We
will
deploy
it
into
one
of
the
nodes
that
can
see
the
camera.
In
this
case,
both
of
them
can
see
the
camera,
so
it
picked
one
and
because
we
had
that
capacity
one,
it
deploys
a
single
broker.
B
The
control
also
deploys
several
services.
It
deploys
a
configuration
level
series
which
basically
allows
you
to
load
plants
across
all
devices
that
have
been
discovered.
Given
the
specific
configuration
so
five
cameras,
you
know
you
can
you
will
have
one
service
which
will
balance
across
all
five
cameras
and
it
also
deploys
instance,
level
services
so
that
you
target
a
specific
camera.
If
you
choose
to,
if
you
want
to
have
a
camera
pointing
the
front
door,
you
can
request
that
specific
camera.
B
This
is
also
an
extension
over
device
plugin,
which
kind
of
generate
generates
a
generic
usb
camera,
but
you
cannot
get
a
specific
one.
So
so
now
we
have
a
service.
You
know
our
our
application.
All
it
needs
to
do
is
need
to
be
configured
to
take
advantage
of
this
quantity
service.
So
it's
again
very
cooperative
is
native.
You
don't
have
to
worry
about
the
discovery
you
just
leverage
it
as
any
other
service
in
the
kubernetes
cluster.
B
All
is
good,
we're
you
know,
processing,
you
know
the
broker
bot,
maybe
it's
taking
the
rdsp
stream
into
extra
individual
frames
and
then
exposing
them
or
grpc,
and
this
bot
can
take
advantage
and
start
processing
them.
So
that
example
of
application,
specific
logic
for
the
broker,
slash
protocol
translation,
so
so
so
all
is
great
but
say
to
no
dice.
So
what
happens?
B
Well,
the
pod
doesn't
have
to
be
reconfigured
because
it's
not
pointing
to
a
specific
part
or
a
device,
but
you
know
it's
connected
to
the
service,
but
because
the
service
doesn't
have
any
both
behind.
It
cannot
really
do
anything
now.
Fortunately,
because
we
they
keep
the
information.
Both
nodes
were
able
to
see
the
device.
The
controller
detects
that
the
port
and
the
nodes
are
gone
and
rescheduled
to
a
separate
node,
and
so
now
the
ml
board
can
keep
running
processing
without
any
reconfiguration.
B
Of
course,
there
was
a
downtime
and
so
say,
you're
running
an
industrial
line,
and
you
cannot
afford
any
downtime.
You
know
whatever
until
it
got
detected
and
in
this
case
you
could
have
deployed
the
configuration
with
capacity
of
two
saying,
deploy
up
to
two
brokers
per
discovered
device,
in
which
case
akri
will
schedule
the
as
many
or
up
to
two
brokers.
If
there
are
at
least
two
nodes
that
can
be
the
device
and
if
either
one
of
them
goes
down.
B
C
In
this
demo,
we
will
showcase
an
acry
configuration
that
uses
acry
to
discover
and
interact
with
onvif
cameras.
First,
we
deployed
a
cluster.
It
contains
a
single
node
called
acrydemo
running
on
an
intel
nook
machine,
and
you
can
see
from
the
instance
type
that
we're
running
k3s.
We
went
with
rancher
k3s
as
our
kubernetes
distro,
as
it
fits
our
edge
scenario
and
is
easy
to
deploy.
C
C
The
configuration
is
where
you
specify
what
leaf
devices
should
be
available
to
the
cluster.
You
can
see.
We
have
configured
this
cluster
to
have
access
to
onvif
cameras
in
the
acry
configuration
we
have
specified
onvif
as
the
protocol,
with
nothing
in
our
exclude
list
allowing
any
onvif
camera
to
be
seen
by
the
cluster.
C
C
C
We
can
further
confirm
this
by
looking
at
our
streaming
application,
which
isn't
displaying
any
frames
so
to
get
this
demo
started.
Let's
plug
in
a
camera
to
the
network,
acry
will
discover
the
camera,
deploy
its
broker
pod
and
set
up
two
services,
one
to
access
frames
from
all
cameras
and
one
to
access
frames.
Specifically
from
this
new
camera,
the
streaming
app
is
querying
from
both
services.
The
larger
top
feed
is
pulling
frames
from
all
cameras
in
round
robin
fashion,
and
each
smaller
feed
is
pulling
frames
from
an
individual
camera.
C
You
can
see
this
as
our
streaming
app
reflect
updates
to
reflect
the
new
camera,
both
in
the
all
cameras
feed
above
and
in
the
specific
camera
feed
below.
So
you
can
imagine
what
will
happen
if
we
plug
in
a
third
camera
sure
enough,
yet
again,
acree
will
discover
the
camera
and
enable
our
streaming
app
to
show
us
feed
coming
from
all
cameras
and
individual
feeds
from
each
camera.
C
We
can
go
back
to
our
dashboard
to
see
the
discovered
onvif
cameras
and
beyond
that
we
can
drill
down
into
the
camera
instance
to
see
what
nodes
are
accessing
the
camera
and
the
metadata
that
has
the
connection
information
for
that
specific
camera.
This
metadata
is
inserted
into
the
broker
pods
as
environment
variables.
B
Will
be
for
our
presentation
so
little
kind
of
a
summary
on
the
functionality,
and
please
also,
if
you
have
any
questions,
I
can
also
stop
and
discuss
the
summary
of
the
functionality,
so
agree
works
as
a
resource
interface,
so
so
folks
writing
code
that
want
to
leverage
devices,
don't
have
to
understand
the
logic
how
to
go,
find
and
and
use
them.
This
is
this
is
attractive
made
by
angry.
B
It
does
not
only
device
discovery,
but
it
also
handles
intermittent
connectivity
and
removal
of
the
devices
it
supports.
This
broker-based
deployment
fair,
where
the
device
is
discovered
automatically.
The
branch
is
deployed
to
leverage
the
device
supports
high
value,
the
access,
because
we
can
deploy
multiple
brokers
in
parallel
and
deploys
these
services
that
allow
to
take
advantage
of
the
parallel
brokers,
but
also
target
specific
devices
and
load
balance
across
all
devices
within
a
configuration
we
have
support
for
multiple
programs.
I
mentioned
only
for
cameras,
utep
for
local
devices
or
vca
for
industry.
B
B
It
was
designed
to
be
extensible,
so
it's
super
easy
to
bring
your
own
brokers,
because
it's
just
a
port
spec
and
we
are
looking
even
working
into
extending
the
protocols
handlers,
so
it
can
be
there
on
separate
ports
as
well,
and
then
it
simplifies
multiple
scenarios.
I
think
I
mentioned
this
already.
You
know
the
brokers
can
do
really
anything.
They
can
be
your
application,
specific
logic.
They
can
do
protocol
translation
data,
ingress,
authentication
to
devices
firmware
update.
It's
really
up
to
you.
B
It
actually
gives
you
that
flexibility
to
react
to
devices
that
are
covered
on
the
network,
a
roadmap.
So
so
we
understand
that
you
know
this
is
only
as
useful
as
the
amount
of
protocols
it
supports
and
so
we're
working
on,
adding
more
more
protocols
and
further
simplifying
the
extensibility
in
the
demo.
Here
we
have
shown
a
deployment
strategy
and
specifically
one
where
there
is
a
broker,
deployment
or
discovered
device.
B
B
So
so
we
we
look
at
acry,
rather
as
a
framework,
we
want
to
see
it
more
a
library,
so
we
want
to
enable
other
projects
to
take
advantage
of
reacting
to
the
physical
changes
in
the
environment.
So
say
you
know,
your
application
is
some
sort
of
operator
right.
This
has
its
own
crd,
and
now
it
would
like
to
generate
its
own
custom
objects
based
on
the
changes
in
the
physical
environment,
say.
B
If
you
have
some
ml
ml
application,
it
wants
to
schedule
the
the
its
own
boards
and
when
there
is
a
new
camera,
but
because
it
both
are
represented
as
the
custom
objects
well
now,
accrete
would
not
be
used,
so
we
want
to.
We
want
to
allow
you
to
basically
not
just
generate
pods
through
the
controller
but
also
generate
other
custom
resources,
so
it's
composable
with
other
projects
in
the
kubernetes
community.
B
But
ultimately
we
you
know.
We
think
this
is
only
as
useful
as
it
does
support
and
it
gets
with
requested
amount
of
protocols
and
people
who
use
it,
and
so
we
are,
we
are
reaching
out
to
community
to
kind
of
gather
feedback
and
prioritize
based
on
the
community
needs
to
the
point.
We
have
already
released
it
on
github
all
the
source
code.
B
Then
we
think
it
makes
sense
to
have
this
be
part
of
a
community
current
foundation
so
that
it
there's
no
single
company
which
is
kind
of
saying
what
goes
in
and
what
goes
out,
and
we
will
be
very
happy
if
you
know
if
you
guys
find
it
useful
to
go
that
route
and
that's
about
it,
for
the
presentation
so
be
happy.
I'm
here,
like
I
mentioned
I'm
here
with
kate,
both
developers
on
the
project
so
be
happy
to
answer
any
questions
or
listen
to
the
feedback
that
you
might
have.
A
Well,
thanks
jerry,
that
was
a
great
presentation
and
I
look
forward
to
checking
this
out
myself.
I
know
it's
hard
when
you're
presenting
to
be
watching
the
chat,
but
there
are
some
questions
that
came
in
on
the
chat.
I
can
read
them,
so
they
get
picked
up
in
the
recording,
there's
a
bunch
from
me
and
one
from
barry.
I
don't
want
to
monopolize
it
so
barry.
A
D
B
You
know
the
the
the
most
obvious
ways
you
would
deploy
two
different
configurations
where
you
can
target
you
know
either
two
separate
sets
or
the
same
sets
of
devices,
and
then
you,
you
specifies
two
separate
brokers,
and
so
then
these
are
scheduled
independently.
It
could
be
that
you
know
one
time.
B
One
is
a
firmware
update,
so
it's
kind
of
one-time
job
and
it's
done
the
other
one
could
be
something
which
is
ongoing
and
processing
or
one
is
a
data
plane
they
use
control
plane
they
can
come
completely
separately,
depends
of
course,
on
the
protocol
and
the
device
if
it
allows
simultaneous
success,
but
from
accurate
perspective.
Yes,
no
problem.
B
A
So
a
few
things
I
was
thinking
of
I'm
wondering
if
this
anticipates
deploying
whole
kubernetes
clusters
at
edge
locations
versus
a
scenario
where
your
kubernetes
control
plane
is
say
in
a
public
cloud
or
in
a
regional
center
with
say,
a
hundred
connected
kubernetes
worker
nodes.
When
you
go
to
that
ladder
scenario,
you
often
are
going
to
have
intermittent
connections
can
accurate
handle
that
scenario
where
the
discovery
perhaps
works,
asynchronously,
while
the
control
plane
is
down
and
then
reconnects
to
have
the
right
thing
done
when
communication
gets
back
to
normal.
B
So
yeah
so
right
now
actually
does
take
a
dependency
on
having
the
tightly
connected
control
plane
just
because
the
instances
are
stored
as
part
of
the
crd.
Having
said
that,
I
could
see
that
you
know
as
long
as
you're,
okay
waiting
for
the
updates
until
until
it
reconnects
then
that
logic
could
be
added,
but
it
right
now
we
are.
We
are
expecting
to
have
the
control
plane
running
on
the
on
the
edge
as
well.
A
Then
the
other
thing
I
was
wondering
I
saw
in
the
demo
that
acry
starts
a
broker
pod
to
work
with
the
device,
but
does
it
do
any
cataloging?
You
know
building
some
kind
of
a
queryable
database
that
has
an
inventory
of
these
that
can
be
used
generically
over
time
so
that
maybe
these
pods
have
independent
life
cycles
or
something
like
that.
B
B
It
also
adds
those
instances
in
that
crd,
at
which
point
it's
up
to
the
protocol,
the
discovery
handler
to
any
metadata
that
it
sees
about
that
specific
device,
so
instance
aggregates
all
the
devices
that
are
there.
Now,
if
you
want
to
do
any
some
additional,
like
you
know,
say
you
want
to
do
some
deep
inspection
of
the
device
and
really
understand
what
it
is
it.
B
Our
view
is
that
this
is
not
part
of
the
discovery
handler.
It's
that
individual
brokers
then
do
this
extra
logic,
and
so
then
you
know
you
could
technically
go
and
edit
your
broker,
which
does
further
deeper
inspection
and
it
captures
more
metadata,
but
you
can
easily
create
the
discovery
handler,
which
does
all
this
and
stores
them
in
the
in
the
instance
crd
or
has
its
own
thing
where
it
wants
to
store
it.
A
Okay,
yeah,
it
occurred
to
me
if
you
saw
the
stream
of
my
questions,
I
asked
if
it
would
not
only
catalog
devices
but
also
data
streams
and
event
streams
that
might
come
out
of
this,
but
upon
further
contemplation
going
by
the
principle
of
separation
of
concerns.
It
hit
me
that
it's
probably
best
not
to
build
that
inaccurate,
even
if
you
needed
those
things
build
it
on
another
layer
that
is
triggered
by
the
acry
device
discovery,
and
it
will
be
much
easier
to
maintain
and
much
more
flexible
to
do
it
in
that
kind
of
architecture.
B
A
Oh
one
final
question:
I
forgot:
what
is
there?
Does
it
do
something
to
eliminate
duplication
of
devices?
I'm
thinking
a
scenario
of
a
multi-node
cluster,
discovering
network
attached
cameras,
and
really
all
of
them
would
see
that
camera.
Potentially,
how
do
you
prevent
that
from
appearing
multiple
times
right.
B
So
so
this
was
one
of
the
extensions
on
top
of
pure
device
plug-in.
So
so,
when
the
device
is
disconnected
like,
I
mentioned
it's
called
within
the
configuration,
but
then
we
also
leveraged
the
protocol
discovery
to
basically
find
something
unique
about
the
device,
so
say
a
mac
address,
and
then
we
hash
it
into
the
identifier.
So
then
they
get
they
get
deduplicated.
B
A
F
B
B
There
is
literally
a
lot
less
test
code
that
we
had
to
go
right,
because
a
lot
of
the
edge
cases
are
covered
by
the
compiler
to
begin
with,
so
according
call
quality
and
then
open
speed
was
one
second,
because
this
is
a
kind
of
a
standalone
thing
right
like
it's.
It's
just
interacting
across
a
cube,
client
apis,
we
didn't
necessarily
see,
needs
to
be
directly
tied
with
the
go
link,
because,
as
long
as
we
can,
you
know
access
the
api
server
that
was
abstracted
away.
Also
rust
support
generics.
B
So
so
there
was
a
templated
generated
goal
so
that
that
made
life
a
little
easier
and
then
final,
I
think
what
we
looked
at.
It
did
produce
smaller
yeah.
Well,
it
produced
smaller
binaries,
so
so
being
on
the
edge
trying
to
be
smaller.
That
was
something
we
wanted
to
go
for
and
then
finally,
the
interrupt
with
the
sequel.
So
the
thinking
is
like.
Oh,
if
you
need
to
like
leverage
some,
you
know
devices
and
you
might
want
to
use
some
c
libraries.
B
A
B
Great
question,
so
so
in
our
current
model,
the
discovery
handlers
are
running
in
proc
in
the
edges,
so
that
means
rust,
but
we
already
have
pending
to
basically
extend
this
so
that
you
can
run
these
as
individual
bots,
at
which
point
it's.
You
know
it's
it's
an
interface
very
similar
to
device
plugins,
just
a
grpc
interface
that
you
have
to
expose.
Then
you
can
write
it
in
any
language.
A
A
G
Okay
thanks,
so
my
name
is
serge.
I
work
for
it
works
and
we
maintain
eclipse,
high
fog,
and
so
today,
I'm
going
to
talk
about
ifox
kubernetes
integration,
mainly
with
the
hope
of
yeah,
just
engaging
in
the
community
and
getting
some
feedback,
and
maybe
some
discussion
about
architectural
questions.
We
have
so
I'll
sort
of
canvas
where
we
are
today
where
we
have
been
and
where
we
think
we're
going
and
bring
up
some
questions
at
the
end.
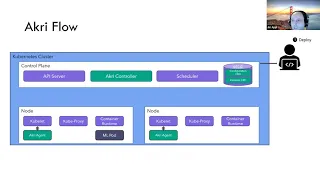
G
Native
types
like
deployments,
things
secrets,
conflict
maps,
etc
and
even
nodes
of
the
platform
layer,
ifoc
has
its
own,
and
so
I've
just
separated
these
into
two
layers
platform
and
application,
so
platform
being
ifrog
itself.
We
have
three
there.
First,
we've
got
the
controller
which
is
sort
of
the
brains
of
the
operation.
That's
the
main
component
of
your
control,
plane
and
I'll
dig
into
the
control
plane.
Soon.
G
Controller
exposes
a
rest
api
for
users
to
manage
ifog
through,
and
then
you
have
your
agents,
so
agents
run
on
their
edge
hosts.
They
are
akin
to
a
cubelet
and
that
they
start
up
and
spin
down
manage
containers
on
the
hosts
we
have
routers
routers
are
implemented
using
amqp's,
sorry
cupid
dispatch
routers,
which
are
mqp
based,
and
so
what
routers?
Let
us
do,
which
is
really
important
for
io
fog.
G
Engage
environments,
is
allow
microservices
running
on
each
host
to
expose
endpoints
for
external
users
through
actually
the
control
planes
network,
rather
than
the
edge
network.
So
in
this
diagram
you
can
see
there's
a
firewall
splitting
up
the
edge
and
the
control
plane,
which
is
a
single
controllers
diagram,
and
we
just
have
a
single
edge
network
in
this
diagram,
but
it
could
be
multiple
edge
networks
firewalls
in
between.
G
So
we've
got
these
edge
routers
talking
to
an
ontario
router,
that's
maybe
somewhere
in
the
cloud
and
they're
able
to
just
connect
to
that
without
requiring
any
inbound
firewall
rules
from
the
interior
router
to
the
edge
router
and
so
on.
The
application
side
of
things
main
workload
concept.
Biofog
is
a
microservice
and
we
have
an
application
type
as
well.
That
groups
them
together.
G
Public
ports
are
a
concept
that
externally
accessible
endpoint
of
edge.
Microservices
I
mentioned
before
we
have
I
o
messages
and
routes.
So
routes
are
unidirectional
communication
channels
for
io
messages
between
microservices
and
we
provide
sdks
for
users
to
do
microservices
and
they
use
io
messages.
We
have
edge
resources
which
are
similar
to
sort
of
accurate
devices.
G
G
So
in
that
sense
its
functionality
is
sort
of
similar
to
ansible
and
view
control
combined
in
the
sense
that
it's
able
to
push
out
to
infrastructure
to
deploy
the
platform
as
you
work
with
ansible,
but
the
user
experience
is
entirely
like
cube
control
and
that
you'd
be
writing.
You're
more
specifications
to
drive
resource
management
of
some
of
those
visuals,
as
I
just
mentioned
before
so
just
below,
I've
got
some
examples
of
the
most
difficult
commands
you
might
do.
G
You
might
be
deploying
control,
planes
and
agents
when
you're
setting
up
the
iphone
platform
and
then
subsequently
you
can
deploy
applications
routes
and
all
that
kind
of
thing
right.
So
right
now
our
kubernetes
integration
is
at
version
two.
So
I'll
talk
about
where
we
are
now
and
then
I'll
talk
about
where
we
were
before
that
and
then
I'll
talk
about
where
we're
going.
G
G
G
So
going
back
in
time
the
version
one
of
the
kubernetes
integration,
what
that
looked
like-
and
I
won't
necessarily
go
into
this
sequence-
diagram
I'll
involved
with
that
briefly,
the
version
one
integration
leveraged
virtual
cubelet.
So
what
that
enabled
was
a
more
kubernetes
native
integration
in
the
sense
that
if
microservices
were
able
to
appear
as
pods,
if
log
agents
appeared
as
nodes,
you
could
deploy
the
kubernetes
deployment
kind
effectively
to
the
edge
and
you
could
leverage
kubernetes
schedulers.
But
we
found
this
to
be
quite
an
awkward
integration.
G
As
I
said
before,
ifog
is
a
standalone
platform
with
its
own
unique
concepts
and
they
don't
necessarily
map
perfectly
to
kubernetes
concepts.
So
this
was
often
unnatural
and
confusing
and
would
ultimately
sort
of
force
eye
fog
to
at
least
down
the
line
become
more
like
kubernetes
and
that
would
sort
of
constrain
us,
particularly
in
edge
use
cases
where
we
might
not
want
to
be
constrained.
G
Instances
so
moving
forward
with
our
kubernetes
integration.
What
we
want
to
improve
on
is
just
to
mainly
enable
cue
control
to
be
a
full
substitute
for
if
control
for
both
platform
and
application
management,
and
naturally
this
means
we
have
to
grow
our
catalog
of
custom
resources
and
custom
controllers
in
the
operator.
G
I
have
a
link
to
an
architecture
document
here,
but
I'll
go
over
the
links
towards
the
end,
particularly
for
the
documents
that
we,
so
you
can
feedback
for
so
just
being
super
obvious
and
drawn
to
your
brains
while
we're
talking
about,
we
would
be
enabling
these
use
cases
essentially
through
cube
control
to
manage
firefog
and
the
edge
applications
and
microservices
so
you'd
be
looking
at
applying
control,
planes,
agents,
routers
and
being
able
to
describe
it
and
so
on
all
those
resources
and
same
with
application
level.
Stuff.
G
G
You
don't
really
enable
that
way,
but
it
does
allow
users
to
deploy
the
entirety
of
io
fog
using
cube
control,
which
yeah,
if
we
think
the
community
really
loves
that
idea,
this
concept
is
definitely
technically
feasible,
so
we
could
look
at
it
but
yeah.
Alternatively,
we
could
rely
on
a
separate
tool
for
provisioning
those
edge
hosts
with
the
iphone
agents
that,
like
rifle
control
or
ansible,
and
so
on.
G
At
some
point,
so
the
user
has
created
an
agent
custom
resource
the
operator
that
picks
that
up
and
either
directly
itself
is
the
stages
into
edge
hosts
to
install
the
software
agent
software
or
creates
a
job
to
do
the
same
thing.
That's
what
that
would
look
like,
but
obviously
you're
going
to
need
to
allow
the
cloud
to
be
going
through
into
your
edge
network,
which
is
probably
not
desirable
and
typically,
you
know
a
platform
before
the
deployments
go
from
a
workstation
within
a
network.
G
G
Then.
Another
question
we
have
is
whether
we
should
enable
ifrog
custom
resources
such
as
microservices
to
map
to
kubernetes
types
like
pods,
and
so
I
kind
of
mentioned.
This
was
somewhat
unnatural.
When
I
was
talking
about
version
one
virtual
publisher,
the
benefit
of
this
would
be
to
allow
iphone
custom
resources
to
be
used
both
for
cloud
and
edge
workloads.
G
So
in
the
sequence,
diagram
I'll
just
go
through.
What's
pretty
small,
you've
got
queue,
control
users
creating
a
microservice
custom
resource.
The
operator
picks
up
on
that
determines
in
this
situation.
The
microservice
has
both
a
cloud
workload
and
an
edge
workload.
So
not
only
does
it
create
a
microservice
against
the
ipod
controller
controller
api,
but
it
also
creates
a
pod
with
the
kubernetes
api.
So
you
know
you
end
up
with
two
containers
running
around
the
cloud
line
on
the
edge
and
then
sort
of
related
to
those
questions
building
sessions.
G
G
A
H
Steve
this
is
todd
pete
thanks
for
setting
this
up
yeah,
just
to
kind
of
add
to
what
search
was
saying.
We're.
Definitely
looking
for
you
know:
user
vendor
community
feedback
on
some
of
the
kind
of
core
questions
specifically
about
the
one
from
kind
of
like
you
know,
should
the
clouds
see
the
edge
see
the
cloud
plane
reach
out
to
the
edge,
or
vice
versa?
A
It's
always
been
a
big
question
of
whether
the
central
reaches
out
to
the
remote
clients,
or
vice
versa,
and
one
of
the
big
issues.
In
my
experience
as
an
engineer
has
been
that
if
the
cloud
reaches
out,
you
have
to
distribute
credentials
out
to
these
edge
locations
to
authenticate
them
and
the
other
way
they
can
kind
of
largely
look
the
same
and
call
in
and
you've
kind
of
pre-installed
them
with
some
means
to
establish
the
authenticity
of
who
they
called.
But
hey.
That's
an
implementation
detail
and
there's.
B
A
B
A
D
D
H
Yeah,
frankly,
that's
that
is
the
kind
of
core
architecture
of
of
eye
for
who
knows
has
been
edging
or
edge
out.
Whichever
way
you
describe
it,
you
know
it's
just
an
interesting
architectural
discussion
with
some
users
who
are
both
kubernetes
users
and
if
users,
who
I
think
you
know,
I
think,
in
how
do
they
build
this.
D
It
seems
to
some
degree,
even
if
you
do
the
ssh
model,
you
have
you're
still
going
to
have
to
configure
that
host
with
an
ssh
server
with
credentials
from
the
cloud.
So
you
already
had
to
do
a
bootstrap.
So
maybe
it's
better
to
do
a
bootstrap
that
doesn't
require
that
inbound
connection.
If
you're
going
to
ready
to
go
through
the
trouble
yeah.
A
A
D
You
also
also
asked
about
being
a
kubernetes
model
versus
io
fog
model,
and
could
you
talk
about
what
you
felt
were
the
things
that
forced
you
to
say?
No,
no.
We
can't
use
the
kubernetes
model
we
have
to,
because
that
was
that's
to
me.
That's
one
of
the
downsides,
I
think,
is
you
know
we
deploy
all
our
services
using
standard,
kubernetes
definitions,
whether
they're
in
the
cloud
or
on
the
edge
and
k3s.
But
now
we
have
to
use
a
whole
new
definition
to
deploy
the
same
services.
D
We
might
run
on
a
device-
that's
a
little
bit
too
small
for
kubernetes,
but
it
just
runs.
Docker
and
we'd
use
io
fog
for
that.
But
now
I
have
to
use
a
whole
different
paradigm
for
defining
it,
deploying
it
so
I'd
be
curious
to
know
why
you
thought
what
was
constraining
you
to
go
down
that
route,
I
mean,
maybe
virtual
cool.
That
was
a
way
to
do
it,
but
just
you
know,
just
the
standard,
crds
and
stuff
are
kind
of
nice.
G
G
A
A
In
my
opinion,
anyway,
that's
a
good
thing,
because
the
kubernetes
scheduler
was
built
on
this
premise
that
you've
got
a
huge
inventory
of
resource
that
is
pretty
much
homogeneous
and
the
scheduler
is
doing
you
a
favor
by
randomly
putting
putting
your
workload
on
one
of
these
out
of
a
big
pool,
yet
at
edge
often
what
you
want
to
run
at
a
particular
edge.
You
location
is
unique
to
that
location
and
arguably
you
can
be
fighting
the
scheduler
rather
than
having
it
do
something
useful
to
you.
A
You
can
you
can
label
the
heck
out
of
it
and
put
all
kinds
of
constraints
to
get
it
to
exactly
the
location
it
needs
to
be,
but
at
the
end
of
the
day
you
have
to
ask
yourself:
did
the
scheduler
actually
work
for
me
or
against
me?
And
if
the
answer
is
that
going
the
route
of
virtual
cubelet
and
making
every
edge
location,
look
just
like
a
pod
ends
up
causing
a
bunch
of
extra
work
with
no
benefits,
maybe
that
wasn't
the
best
way
to
go.
A
B
E
D
E
H
And
that's
definitely
where
we've
arrived,
I
kind
of
like
v2
architecture
go
forward
right.
I
think
a
search
said
you
know
it's
like,
rather
than
trying
to
force
fit
it
it's
just
to
allow.
You
know
kubernetes
and
cube
control,
and
you
know
to
be
able
to
orchestrate
and
make
calls
out
to
our
fork
seamlessly
without
you
changing
your
tooling
or
whatever
we
kind
of
married
the
two
worlds.
I
think
steve.
As
you
said,
you
know
kubernetes,
you
know.
Yes,
you
know
talked
about
as
hey.
D
So
how
so,
and
with
that
model,
how
would
say,
for
example,
a
cloud
service
be
able
to
access
an
edge
service
right?
You
wouldn't
see
it
as
a
kubernetes
service.
In
that
case,
you'd
have
to
like
put
that
in
the
application
layer
of
that
cloud
service
to
say
I
have
to
go,
look
up
something
and
figure
out
what
the
van
is.
You
know
the
router
and
the
cupid
and
flow
down
to
it
is
that.
G
Yeah
so
I
mentioned,
and
that
kubernetes
deployment
of
io
fog,
the
component
called
report
manager,
so
the
port
manager
will
basically
talk
to
the
ifr
controller
to
determine
what
public
ports
have
been
created
for
your
edge,
microservices
and
based
on
that
list
of
public
ports.
It
will
set
up
either
load
balance
or
cluster
ip
services
on
the
cluster,
so
those
edge
microservice
endpoints
are
accessible
through
your
kubernetes
network
by
load,
balancers
or
some
ingress.
D
G
A
A
I
I
know
the
other
issue
to
be
resolved
todd.
I
think
you
threw
out
the
idea
of
whether
this
is
a
central
cloud-hosted
control,
plane
talking
to
some
kind
of
managed
edge
nodes
that
may
or
may
not
be
kubernetes
cluster
nodes
or
whether
each
of
these
edge
nodes
is
like
a
mini,
tiny,
kubernetes
cluster
in
appearance
and
what
you're
doing
is
federating
a
huge
number
of
kubernetes
clusters.
J
Yep
happy
to
happy
to
talk
about.
I
was
thinking.
Maybe
I
should
answer
this
one.
So
the
the
the
concept
that
we're
trying
to
work
with
here
is.
Do
you
do
you
need
to
check
in
with
any
certain
frequency
in
order
to
be
still
an
active,
manageable
device
or
node
in
the
system
and,
if
so,
shouldn't
that
be
flexible
rather
than
saying
that
everyone's
connected
at
the
same
level,
so
at
the
core
in
the
an
io
fog
control
plane?
J
Is
this
notion
that
each
edge
compute
node
should
have
a
parameter
that
says:
when
do
we
expect
it?
And
so,
if
you're
going
to
call
back
on
your
on
your
satellite
backhaul
two
times
per
day,
then
you
really
want
to
give
it
about
maybe
a
day
or
so
before.
You
say
something
seems
to
be
wrong,
because
you
could
definitely
miss
one
shot
and
say
well,
it's
probably
still
alive.
J
So,
given
that
and
given
that
the
edge
nodes
reach
out
to
talk
to
the
control
plane,
that's
that
the
whole
punching
out
or
dialing
out
thing,
that's
a
good
setup,
but
we
have
had
numerous
requests
to
allow
someone
to
use
their
mqtt
message
infrastructure
as
the
way
to
do
all
that
communication,
because
they've
already
got
those
pathways
and,
as
you
mentioned
steve,
that
protocol
is
really
tolerant
of
disconnection.
It's
very
lightweight
low,
low
overhead
for
the
the
packets
right.
J
So
what
we're
thinking
of
doing
is
taking
the
core
thing
we've
got,
which
was
designed
for
this
scenario,
but
allow
you
to
change
which
protocol
you
carry
it
over
and
that
way
you
can
basically
choose.
What's
my
control
plane
network
as
opposed
to,
how
do
I
set
up
the
control
plane
network?
And
what
do
I
allow?
It's
like?
Oh,
if
you've
got
an
mqtt
system
going
already,
then
great,
we'll
just
ride
on
top
of
that,
and
this
also
means
that
anything
that
gives
you
a
managed
pipeline.
You
know
this
is
like
discussions.
J
We've
had
about
like
the
the
hano
project
that
eclipse
you
could
use
that
to
carry
this
traffic
and
so
places
where
you
normally
watch
and
monitor
and
say
what
messages
am
I
piping
through
you'd,
be
like
oh
yeah,
and
that
those
those
are
the
messages
related
to
the
iphone
edge
nodes
talking
to
their
control
plane.
So
the
basis
are,
the
basics
are
already
there,
but
how
do
we
want
to
expand
it,
and
so
I
think
additional
protocols
is
a
way
to
then
give
you
that.
A
Okay,
well,
thanks
for
that
presentation,
search,
I'm
gonna
have
to
go,
take
some
think
time
on
it,
but
it
looks
intriguing
and
it's
a
a
nice
combo
of
handling
kind
of
app
distribution
along
with
the
devices.
In
the
previous
talk,
I
see
I've
some
names
here.
I
know
we're
way
over
limit,
but
if
people
are
interested,
I
think
there
might
be
some
first-time
participants
in
the
meeting.
K
J
C
A
I
had
a
question
for
akri,
ukaid
and
also
jerry.
I
noticed
that
the
repo
is
under
deus
or
it
was
a
dias.
I
don't
know
instead
of
microsoft
did,
and
I
think
that
acquisition
happened
like
wasn't
it
years
ago.
Does
this
date
back
that
long
to
being
a
dais
project,
or
is
microsoft
simply
using
that
github
repo?
B
Yes,
I
just
wanted
to
add
to
that
that
you
know
they.
Our
intent
was
not
to
have
this
as
a
microsoft
governing
project,
and
so
this
is
also
kind
of
the
goals
they
yep.
You
know
we
want
this
to
be
community
driven
just
like
helm
and
other
days
labs
projects.
That's
why
it
was
kind
of
put
into
the
repository.
H
A
There's
also
an
interesting
tie-in,
I'm
aware
of
in
another
kubernetes
user
group.
I
think
in
the
things
I
read
about
in
the
repo
it
talked
about
discovering
gpus
and
fpgas,
and
this
is
more
a
data
center
application
rather
than
edge.
But
there
are
projects
out
there
that
attempt
to
share
pools
of
gpus
for
machine
learning,
applications
that
really
aren't
edge
centric
but
still
use
network
connectivity
to
the
gpus,
and
it
looks
really
interesting
so
I'll
be
looking
into
that.
J
Cool
it's.
We
would
definitely
not
be
probably
sharing
those
privileged
resources
at
the
edge,
but
the
discovery
of
them
we'd
like
to
do
it
the
same
way
as
others
are
doing
it.
There's
no
no
need
to
replicate
that
or
have
it
work
one
way
in
the
cloud
in
a
different
way
at
the
edge
yeah,
so
the
pooling,
probably
not
but
the
discovery.
Yes,
that's
cool.
H
Yeah
and
specifically,
on
top
of
what
kills
and
saying,
I
think,
steve,
what
we're
seeing
is
just
the
explosion
of
kind
of
gpus
vps
tpus,
like
at
the
edge.
You
know
as
embedded
little,
you
know,
solderable
chips
or
you
know,
plug
in
usb
devices
or
m2
form
factors
that
you
know
the
the
majority
of
the
workload
that
we
see
really
driving.
I
think
value
at
the
edge
for
a
lot
of
people
now
from
wallet
share.
Standpoint
is
kind
of
ai
inferencing
running
on
these
small
form,
factor
devices,
and
so
that's
actually
kind
of
cool.
H
A
Yeah
the
use
case
at
the
edge
might
be
something
like
having
a
handful
of
that
gpus
specifically
for
image
recognition,
and
maybe
you
know,
100
cameras
that
are
handled
by
10
gpus
for
doing
face,
recognition
or
license
plate
recognition,
and
I
think
there
there
is
there.
There
are
applications
that
could
be
really
enabled
by
that.
H
Yeah
definitely
or
a
hundred
cameras
with
a
hundred
you
know
dime
size.
You
know
inference
engine
tpus
like
a
google,
coral
just
actually
running
on
the
camera.
That's
actually
you
know
a
compute
board
where
you're
running
the
actual
inferencing
right
there
kind
of
like
on
that
smart
camera,
doing
the
real-time
video
stream
processing.
That's
what
we're
you
know
we're
starting
to
see
a
very
predominant
use
case
out
there.
A
A
Okay,
I'll
start,
I
guess
I'm
steve
wong,
I'm
one
of
the
co-leads
of
this
iot
edge
working
group.
I,
based
in
los
angeles
working
for
vmware,
I
am
assigned
to
work
on
the
kubernetes
project
and
I've
got
a
couple
roles.
I
joined
this
group
not
because
of
my
current
role
at
vmware,
but
prior
job
at
another
startup.
A
I
was
one
of
the
founding
engineers
of
this
company
wonderware
that
did
a
tool
kit
for
factory
automation
and
worked
there
over
a
decade,
so
I've
just
always
been
interested
in
the
space
and
when
I
got
on
board
kubernetes,
I
realized
that
or
I'm
convinced
that
kubernetes
enables
features.
That
would
be
really
useful
in
that
industrial
iot
space.
A
The
discovery
brought
up
opc
ua
and
that
opc
standardization
came
out
in
the
90s
as
a
way
to
unify
the
different
device
interfaces.
So
some
of
the
legacy
stuff
is
still
alive.
Some
of
it
won't
go
away
for
another
20
years
and
needs
things
like
these
gateways
to
continue
to
link
up
to
it.
But
it's
an
interesting
opportunity.
A
F
Yeah,
hey
I'm
engineer
with
redkit,
been
coming
from
the
enterprise
messaging
land
and
then
dive
into
the
iot
and
and
all
this
such
stuff.
Also
one
of
the
co-founders
of
this
group
and
yeah
being
messing
around
mostly
interesting
in
the
in
the
connectivity
and
and
and
messaging
around
these.
These
use
cases
barry.
You
want
to
go
next.
D
D
We
started
mainly
in
factories,
we're
the
ones
that
have
to
deal
with
all
these
30
year,
old,
crap
and
systems,
and
figure
out
how
to
bring
them
into
the
modern
world
so
so
figuring
out
how
to
layer
these
protocols,
on
top
of
all
the
old
hardware,
has
been
one
of
the
things
we've
been
working
on
for
quite
a
while
now
we're
moving
into
other
iot
domains
as
well.
So
all
these
technologies
apply
to
us.
D
H
Thanks
brad
todd
papyrus,
I'm
actually
the
ceo
over
at
edgeworks
been
a
long
time
open
source
developer,
built
greenplum
db.
Back
in
the
day
when
I
was
at
greenplum
and
tr
who
built
hadoop,
there
started
coming
with
hortonworks
and
I've
been,
you
know,
contributed
to
apache
to
eclipse
for
close
to
20
years
now.
B
Hey
folks,
so
my
name
is
dj
apple,
I'm
coming
from
czech
republic.
Hence
the
weirdness
and
I've
been
at
microsoft
for
about
10
years
now,
most
recently
looking
at
kubernetes
and
on
the
edge.
So
microsoft
has
plenty
of
kubernetes
offerings,
but
we
think
that
kubernetes
is
really
interesting
for
the
agent.
So
we
have
multiple
kind
of
thinking
in
that
area.
Agree
being
one
of
them
and
you
know
be
be
happy
to
kind
of
get
in
touch
with
all
of
you
and
and
kind
of
keep
working
on
this
together.
J
All
right
thanks,
hi
kilton
hopkins,
I'm
the
chair
of
the
eclipse,
edge
native
working
group
and
co-founder
of
that
group,
co-founder
of
edgeworks
and
and
currently
cto
of
edgeworks,
and
also
the
original
creator
of
the
eclipse,
io
fog
project,
which
came
out
of
years
of
looking
at
these
types
of
problems.
Like
the
way
barry
describes
like
having
to
be
the
one
to
make
this
crap
work
and
then
saying,
like
you
know
what
I'm
not
seeing
anything
alike,
and
that
was
that
that
originated
back
in
2014.
J
G
Yep,
so
I'm
serge
rodinovic
work
at
edgeworx,
for
I
do
focus
on
our
kubernetes
work,
so
we're
gonna
support
manager
operator,
anything
that
comes
out
of
there
done
a
bunch
of
work
on
the
cli,
ifo
control
and
just
all
the
associated
tooling
and
automation.
With
that
kind
of
stuff.
I've
always
been
interested
in
kubernetes,
since
I
learned
about
it
and
just
realize
how
much
how
much
it
enables
and
distributed
platform
sort
of
situations.
A
Okay,
I'll
take
silence
as
no
and
we've
gone
over,
but
it's
been
fascinating.
So
it's
okay!
If
we
went
over
thanks
everybody,
the
recording
will
be
posted
soon,
may
maybe
not
tomorrow,
but
I
aspire
to
it
sometime
within
the
next
week
and
we'll
see
you
at
the
next
meeting.
Thanks
for
joining
cheers
thanks.