►
From YouTube: Kubernetes WG LTS 20190430
Description
https://git.k8s.io/community/wg-lts
Meeting agenda / minutes:
https://docs.google.com/document/d/1J2CJ-q9WlvCnIVkoEo9tAo19h08kOgUJAS3HxaSMsLA/edit#bookmark=kix.sjfs9xag9ogy
A
A
A
A
All
right,
I'm
gonna
go
ahead
and
get
things
rolling
here.
Welcome.
Everybody
today
is
the
Tuesday
April
30th
2019
working
group
LTS
meeting.
We
are
recording
this
meeting
and
we'll
be
posting
it
to
YouTube
afterwards.
So
please
remember
the
community
of
conduct
and
behave
appropriately,
because
the
world's
can
see
everything
you
do.
I
just
pasted
the
agenda
minutes
document
into
the
zoom
chat
for
those
who
don't
have
it.
If
folks
could
do
as
Jordans
typing
in
there
right
now
put
your
name
on
the
attendance
I
would
appreciate
it.
A
A
Claire
to
talk
about
his
proposal
document
and
then
we've
talked
about
having
some
sort
of
experience
reports
from
users
of
the
project,
and
we
have
Michael
Larson
here
today
from
Zalando
to
talk
about
their
experiences
and
then
there's
a
couple
other
things
time
permitting
that
we
could
touch
on
hopefully
quickly
as
well.
So
Tim
just
pasted
in
his
document
link.
It
looks
like
yes
so
I'm
gonna
hand
it
over
to
you
Tim.
Maybe
do
you
think
15
20
tops
for
this
sure.
Okay,.
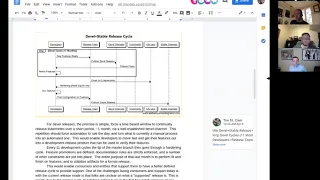
B
Great,
let
me
share
my
screen
to
just
walk
through
it,
so
we
talked
I,
don't
know.
Was
it
a
month
ago,
where
I
kind
of
outlined
some
of
the
initial
frameworks
with
this
and
basically
at
all
I
did
was
add,
verbage
and
sort
of
a
sequence
diagram
around
sort
of
the
proposed
model
that
I
discussed
like
a
month
ago.
B
The
one
thing
about
this
document
to
take
into
mind
or
take
into
account
when
reading
it
is
that
there's
a
bunch
of
open-ended
questions
that
will
resolve
that
will
come
up
as
you
read
them,
and
there
is
an
explicit
punt
in
this
document
to
not
to
define
a
set
of
policies
right,
there's
a
bunch
of
ways
you
could
define
policy
or
implementation
details
with
regards
to
a
specific
way
of
doing
something.
So
this
is
more
of
a
model
right.
B
This
is
a
proposal
on
the
baseline
of
a
model
and
then
there's
a
bunch
of
Forks
in
the
road
that
will
occur
in
this
model
and
those
are
policy
decisions
that
could
be
their
own
camps
right.
It's
a
question
of
whether
or
not
this
model
makes
sense
for
the
community
and
also
one
of
the
things
I
don't
know.
If
I
actually
wrote
that
in
this
stock-
and
we
talked
about
it-
is
that
there
are
so
there
are
some
preconditions
that
we
wanted
to
apply
to
this
model
like
I.
B
Yeah,
so
the
question
is
whether
or
not
this
is
good
for
the
community
and
if
it
makes
sense
so
I'll
talk
through
sort
of
the
model
that
we
discussed
last
time,
and
now
it's
got
more
verbage
and
diagrams
to
support
it.
So
the
basic
idea
is
that
you
release
an
actual
stable
release
every
12
months,
but
you're
continuously
published
and
develop
release
on
a
monthly
cadence,
by
hook
or
by
crook,
in
the
purpose
of
getting
that
developer
lease
out.
B
There
is
to
get
you
early
signal
back
on
features
and
changes
that
you
are
making
across
that
lease
process.
One
of
the
things
that
we
talked
about
before
is
that
we
don't
actually
have
alpha
and
beta
releases
currently
being
published
and
a
lot
of
times
our
dot
zero
releases,
never
a
stable
release.
Those
are
common
threads
that
have
occurred
throughout
the
history
of
communities.
So
the
purpose
of
this
is
to
get
that
early
signal
out
and
to
promote
people
along
the
way
to
try
and
use
those
features
you
can
do.
Promotion
via
several
means.
B
That
means,
like
all
new
features,
are
documented.
You
know
all
all
the
other
accoutrement
user
stories
are
in
place.
You
have
your
test
apparatus
in
place
to
test
the
features
and
by
forcing
a
hard
audit
that
allows
no
new
code
to
get
in
so
incentive
incentive,
eise's
the
use
the
developer
base
to
actually
make
sure
that
they're
doing
the
right
things
I.
Think
right
now
we
have
a
problem
in
the
community
of
Karen
vs.
stick
and
we
have
no
stick.
B
B
It
allies
here
the
idea
of
develop
channels
and
stable
channels
having
them
totally
distinct
and
separate.
That's
very
common!
You
see
that
across
a
number
of
different
distributions,
you
can
think
fedora.
Well,
you
could
think
whatever
you
wanted
to
just
having
the
two
separate
channels,
so
it's
it's
impossible
for
folks
to
get
mixed
up
from
where
they're
pulling
their
sources
from.
B
It
also
allows
folks
to
to
you
a
little
bit
more
mindful
publications
for
features
that
are
coming
up,
because
you
have
a
long
lead
time
of
what
will
be
in
a
series
to
know
that
these
are
all
the
feature
enhancements
that
are
coming
up
before
you're
actually
do
a
release.
It
also
gives
you
a
long
lead
time
to
do
a
bunch
of
notifications
to
the
community
to
let
them
know
that
you
are
going
to
have
this
you're
going
to
go
through
a
deprecation
cycle
for
your
old,
stable
series
releases.
B
B
B
C
B
Did
get
content
yeah
so,
like
you
have
12
months
to
plan
a
release
and
if
you
can't
determine
whether
or
not
a
feature
is
ready
to
go
in
that
12-month
cycle
like
they
kicked
out
and
it's
up
to
arc
and
the
rest
of
the
people
who
are
doing
the
release
to
determine
the
criteria
for
feature.
Promotion
right.
B
B
C
B
This
is
just
a
model
right
in
and
there
are
so
many
different
aspects
to
the
policy
enforcement
and
the
processes
around
it
that
I
couldn't
possibly
dictate
all
of
them,
because
each
one
is
its
own,
its
own
way
of
dealing
with
it
right
so
like
how
do
you
deal
with
backboard
features?
What's
the
criteria
that
you
want
to
enable
you.
C
B
Well,
my
part
of
the
preconditions
which
I
need
to
blast
out
is
that
if
you
have
v1
api's,
the
idea
of
adding
major
features
into
communities
should
go
down
over
time.
That's
the
whole
purpose
of
having
the
sierra
de
CRD
based
extension
mechanisms,
as
well
as
all
the
other
accoutrements
for
extensions.
B
Around
kubernetes,
like
the
tinkling
along,
comes
from
the
binary
releases
of
the
primary
kubernetes
components,
exactly
like
I'm,
hoping
that
in
the
next
two
years
timeframe
like
we
just
start
to
attenuate
down
and
down
to
the
point
where,
like
it's
just
it's
a
release
and
there's
nothing
really
special
about
it.
Other
than
there's
a
bunch
of
fixes.
Mm-Hmm.
B
We're
still
in
that
weird
state
where,
like
we
haven't,
really
defined
the
boundary
lines
of
what's
in,
is
out
very
well,
and
we
still
have
this
weird
crossover
and
I
think
until
the
api's
have
been
promoted
and
it's
how
the
boundary
lines
are
a
little
more
crisp,
I
think
well,
I,
don't
think
we
can
pull
off
this
model.
To
be
honest,
yeah.
C
C
As
we
talked
about
revving
those
if
the
stable
channel
has
lifetimes
measured
in
years-
and
we
have
to
have
at
least
one
release
overlap
where
you
support
both
the
old
and
the
new
version
like
when
we
bump
from
alpha
to
beta
our
beta
2
GA,
we're
talking
about
carrying
api's
for
order
of
years.
At
this
point
before
we
can
drop
them,
which
we
might
have
to
do
anyway,
but
a
lot
of
the
documentation
around
like
how
long
does
it
take
to
roll
out
a
revision
and
how
many
things
you
have
to
overlap
support?
B
C
Get
me
back
it's
great,
but
we
still
have
the
kind
of
the
absolute
like
someone
who
doesn't
take
the
time
to
set
of
all
clusters
and
only
goes
from
stable
to
stable
to
stable,
like
we
have
to
support
and
overlaps
at
least
two
overlapping
releases.
If
the
time
frame
is
longer
it
might,
we
might
be
able
to
drop
the
requirement
to
have
three
releases,
but
yeah.
C
B
I
agree:
it
wouldn't
make
any
sense,
like
a
person
who
wanted
to
use
a
feature
would
not
be
able
to
I.
Think
there's
also
I,
think
vendors
in
their
efforts
to
try
and
enable
kubernetes
for
other
type
of
workload.
Scenarios
may
have
inadvertently
caused
some
weird
gravity
problems
with
kubernetes
as
well.
Kubernetes
would
be
much
more
ephemeral
had
we
not
sort
of
enabled
some
of
the
other
user
stories
inside
of
kaykai
core
and
it
might
be
beneficial
for
us
to
evaluate
some
of
those
features,
namely
the
stuff.
B
A
D
A
B
There's
two
parts
so
like
so
Condor
grabbed
it
originally
from
the
kernel
and
then
modified
it
like
years
and
years
and
years
ago.
The
Condor
project
is
a
30
year
old
grid
project
and
they
grabbed
it
from
the
kernel
and
then
they
modified
it
and
there's
different
layers
of
distribution
channels
that
exist
to
distribute
it
in
part,
because
it's
installed
inside
large
gov
facilities
all
over
the
world
in
large
science
laboratories.
B
So
if
you
look
at
CERN
or
if
you
look
at
you
know
any
national
do-e
based
lab,
it
basically
covers
the
engine
that's
running
across
all
their
nuclear
simulations
and
the
the
upstream
had
a
distribution
model
of
this.
This
very
analogous
distribution
model
of
a
develop
stable
series
labs
that
will
wanted
to
use
certain
features
to
get
ahead
of
the
curve
would
always
sort
of
have
these
separate
pools.
B
B
B
But
there's
all
this
extra
tooling
around
how
to
federate
across
these
different
grid
systems
across
the
entire
globe,
so
that
way,
like
a
job
submitted
from
CERN,
could
be
federated
out
to
tier
one
size
that
tier
two
sites,
and
they
would
go
all
the
way
down.
So
here,
you're.
Looking
at
particle
physics
collisions,
you
know
in
some
lab
and
Nebraska,
even
though
it
originally
started
at
CERN,
so
that
that's
like
the
layered
distribution
model
in
the
use
case
behind
it.
B
So
the
nice
thing
about
having
the
core
have
this
model
versus
a
distributor.
Have
this
model
is
that
it
forces
distributors
to
change
and
also
allows
them
to
it
has
better
support
characteristics
for
them
there.
It
actually
helps
them
because
it
makes
their
life
a
little
bit
easier
for
back
porting
features
or
not
back.
B
Pairing
features
back
burning
bugs
because
then
they
can
get
it
into
their
distribution
channels
is
here,
so
it
incentivizes
distributors,
but
then
it
also
like
allows
the
community
to
have
a
baseline
for
for
people
to
adopt
something,
that's
stable
and
feel
comfortable
adopting
it,
because
I
think
one
of
the
biggest
problems
with
communities
distributions
is
like
especially
today
is:
there
hasn't
been
a
lot
of
collapsing
of
the
ecosystem.
Yet
in
fact
it's
still
growing.
So,
like
you
get
kubernetes
from
everywhere,
everything
I
don't
even
know
how
many
distributions
there
are.
B
That's
kind
of
crazy,
if
you
think
about
it,
but
if
said
KK
was
stable,
easy
to
consume,
you
could
collapse
a
lot
of
that
so
that
that
way
like
we
get
out
of
the
distribution
as
a
product
business
and
get
more
into
the.
This
is
a
core
fundamental
piece
that
everyone
needs.
Then
you
can
layer
on
your
other
things,
the
top
of
it
sure
and
that
that
could
be
an
extra
distribution.
B
It's
kind
of
it
gets
back
into
the
sort
of
like
kernel,
ish
type
of
model
where
the
Linux
distribution
is
all
the
accouterments
and
everything
else
around
it
that
make
it
more
fully
featured,
but
that
the
core
is
pretty.
You
have
some
expectations
around
what
you're
getting
in
a
given
time
frame,
I.
B
You
know
they
had
to
be
up
all
the
time
running
these
things
all
the
time
and
you
have
certain
out
of
wit,
outage
windows
that
you
can
plan
so
swapping
kernels,
you
know,
making
the
kernel
move
to
a
single
release
model
was
actually
not
a
bad
idea,
but
for
for
a
government
lab,
they
can
only
have
this
published
a
time
period
to
get
an
update
in
and
they
had
to
be
able
to
do
it.
You
know,
knowing
that
they
had
certain
guarantees
or
on
the
stable
release.
A
E
E
Yeah,
why
I'm
asking
that,
as
when
we
were
trying
to
do
this
in
OpenStack,
we
ended
up
finding
like
two
distinct
sets
of
users.
One
set
we
wanted
like
they
wanted
to
pick
a
specific
version
of
OpenStack,
and
then
they
would
be
to
upgrade
after
two
years
or
something.
But
then
there
was
a
whole
another
set
of
people
from
telecom
who
wanted
like
every
three
months
on
a
clockwork,
so
it
was
trying
to
fit
a
single
model
to
both
was
going
to
be
a
problem.
E
A
E
B
B
E
C
Mean
a
lot
of
those
preconditions
boil
down
to
do
less
so
that
there's
less
churn
that,
like
every
three
months,
someone
is
dying
for
some
feature
or
enhancement
like
the
more
you
do,
the
more
surface
area
there
is
where
people
are
gonna
legitimately
need
lots
of
different
enhancements
and
changes
and
features.
If
you
do
less
and
build
more
on
top
as
extensions
or
add-ons,
then
a
lot
of
the
urgency
hopefully
goes
away
from
this.
You
know
desperate
need
for
a
new
thing
in
three
months.
E
Right
but
Jordan,
there
is
a
balance
here
too
right.
What
seems
to
be
happening
is
when
we
are
pushing
people
out
by
saying
do
extension
on
top,
then
they
don't
want
to
come
work
on
the
core
stuff.
You
know,
that's
the
other
thing
that
we
have
seen.
Definitely
in
OpenStack,
where
we
told
people
to
go
away,
do
their
own
thing
and
then
they
have
less
and
less
time
to
contribute
to
the
comments
so
to
say:
yeah.
C
I
I
think
a
question
worth
asking,
maybe
more
than
the
like.
The
effort
on
contribution
towards
core
is
if
these
things
are
built
on
top
today,
even
the
things
that
are
built
on
top
kind
of
as
add-ons
add-ons
are
still
bundled
into
a
single
release.
You
know
tar
with
manifests
and
things
at
least
for
some
consumers
and
they're
tested
together,
like
it's
kind
of
this
huge
here's
all
the
add-ons.
C
And
so,
if
we're
talking
about
lengthening
slowing
down
the
kubernetes
release
train
because
a
lot
of
the
functions
of
people
are
using
is
in
these
add-ons
or
layers
built
on
top,
we
would
probably
need
to
rethink
how
we
distribute
those
add-ons
and
how
those
add-ons
can
release
more
rapidly
to
add
features.
Independent
of
a
that
has.
E
Definitely
worked
as
well,
and
the
different
projects
can
have
different
release
cycles.
They
don't
have
to
be
tied
into
the
you
know,
death
march
of
three
month
release
cycle.
Then
people
were
actually
doing
better
because
what
they
were
also
doing
was
they
were
testing
their
components
against
multiple
different
versions
sets
of
other
things.
So
you
know
that's
definitely
helpful
if
we
are
able
to
decouple
releases
of
the
individual
components
so.
A
F
F
A
F
Story,
oh
so,
a
little
bit
about
what
solando
is.
We
are
in
Europe
the
biggest
fashion
online
fashion
retailer.
So
we
basically
you
go
online.
You
pick
some
shoes
or
some
dress
you
like
or
whatever,
and
then
you
buy
it
and
we
ship
it
to
you
within
a
few
days
and
you
don't
pay
for
the
shipping
and
so
on
and
we
deal
only
with
fashion.
F
So
we
don't
do
what
Amazon
does
with
all
kinds
of
different
things
and
we
sell
mostly
that,
like
we
have
all
day
all
the
articles
we
buy
in
from
the
clothing
providers
of
the
producers
and
then
we
we
saw
that
and
for
the
technical
side
we
use
we're
trying
to
move
everyone
to
communities.
Basically,
we
have
118
clusters
right
now
that
our
team
is
managing.
We,
our
team
of
8,
online
people
and
and
the
idea
is
that
we
want
to
run
like
any
kind
of
workload
there.
F
Right
now
we
have
everything
from
like
simple
web
applications
for
internal
spooling
of
external
website
and
so
on,
and
we
have
a
lot
of
like
back
the
back-end
services,
processing
services
and
so
on,
and
one
of
the
reason
things
we
did
was
move
search,
functionality,
witches
and
elasticsearch
cluster,
roughly
200
notes
through
kubernetes,
and
it's
we
implement
that
an
operator
that
can
scale
it
up
and
down
and
so
on
and-
and
we
also
run
a
lot
of
posters
clusters.
So
each
team
can
basically
deploy
their
own
posters
cluster.
F
We
have
a
push
push
operator,
also
developed
and
that
that
manages
this
I,
don't
know
how
many
professors
we
have,
but
it
is
a
lot
and
out
of
these
118
clusters
of
roughly
half
of
them
are
production
and
the
other
half
is
test
clusters
and
we
try
to
like
segregate
the
clusters
into
product
or
Department
of
what
you
want
to
call
it
and
basically,
for
the
reason.
One
reason
is
the
compliance.
Why,
as
we
want
to
isolate,
who
has
access
to
what
we
don't
do
like
multi-tenancy
within
communities?
F
Commission's
also
tries
to
date
who
can
access
what
and
and
then
we
have
one
production
on
one
test
justify
each
of
these
products
are
departments
and
and
the
test
last
us,
the
users
have
full
access
to
would
keep
detail,
can
delete
and
great
stuff,
but
in
production
they
have
to
go
through
a
ste
ICD
pipeline
to
actually
deploy
something
and
another
reason
for
also
limiting.
It
is
also
to
reduce
the
blast
radio.
F
So
if,
if
something
goes
wrong
in
a
cluster,
we
don't
take
out
the
whole
thing,
but
we
can
manage
it
on
like
a
limited
set
of
services.
It
still
can
be
a
lot
of
cause
if,
like
the
elastic
stretch,
classic
go
down
and
then
we
lose
our
edge
functionality
so,
but
we
cannot
really
hansik.
We
grade
that
that
more
and
we
have
yeah
build
a
lot
of
tooling
around
to
Menace
these
many
clusters.
So
we
have,
for
instance,
there
was
a
question
about
conformance
testing.
F
Our
configuration
is
it's
in
trend
tested,
basically
by
spinning
up
a
cluster
and
upgrading
it
from
the
previous
configuration
and
then
running
the
entrance
test.
So
we
have
pretty
confident
that
if
this
works
then
then
yeah
at
least
the
clusters
conform
and
then
add
tested
a
bunch
of
of
the
things,
and
we
also
have
like
different
channels
for
the
clusters.
We
call
them
where
we
basically
have
def
some
def
cluster
switches
like
a
handful
of
clusters
that
is
not
so
under
test
and
that
we
first
rolled
changes
out.
F
So
we
can
not
only
rely
on
into
interesting
but
also
rely
on
people
running
some
stuff,
then
and
notifying
us.
If
they
see
problems
or
if
we
see
how
alerting
go
off
or
something
and
once
we
move
from
death,
then
we
move
to
an
alpha
Channel
and
debates
and
all
the
way
to
stable
and
this
kind
of
interest
us
that
we
have
some
time
for
teams
to
discover
problems
that
we
haven't
discovered.
F
You
know
into
interesting
and
we
have
like
the
the
test
clusters
on
the
beta
channel
and
the
production
trust
us
on
the
on
the
stable
channel.
So
teams
have
some
time
in
the
test
clusters
before
they
get
this
they
update
in
the
production
and
which
also
allowed
them
to
update
I.
Don't
think
we
really
have
issues
with
like
my
creating
API
versions
or
something
that
is
usually
it's
possible
within
the
same
version
of
kubernetes,
to
have
two
versions
running.
F
So
we
often
have
enough
time
to
let
people
just
operators
or
ask
them
to
do
it
or
enforce
it
somehow.
But
it's
not
really
an
issue
for
us
and
we
try
to
keep
up
to
date
with
kubernetes.
So
in
the
beginning,
we
were
faster
I
think
we
started
around
1.4,
but
the
first
cluster,
and
then
we
have
upgraded
them
continuously
and
added
more
and
more
clusters.
And
now
we
are
on
twelve
eight
and
we
are
working
on
rolling
out
113.
F
So
this
is
only
in
our
dev
Channel
right
now
and
basically,
what
what
keeps
us
not
on
on
114
or
something
is
just
like
the
urgency.
It's
basically
a
trade-off
between
how
many
features
are
there
and
how
many
box
are
fixed,
that
that
we
need
and
it
for
113.
We
haven't
really
like
needed
it.
We
just
want
to
keep
up,
so
we
don't
lag
behind
when
there's
a
115
and
then
suddenly.
112
is
not
supported
anymore,
as
I
understand.
It's
like
three
persons
behind
the
thing
that
so
this
is
like
the
main
motivation.
F
F
Yeah
one
thing
that
is
also
kind
of
holding
us
back
on
113
is
that
we
don't
see
any
other
clump
of
headers
actually
there,
so
we
were
rolling
out
112
before
decay.
We
realized
when
we
were
rolling
it
out
and
we
discovered
a
major
part
in
our
setup.
Oh
and
with
the
way
we
ran,
the
couplet
was
basically
a
memory
leak
and-
and-
and
this
was
a
bit
of
a
surprise
to
us
and
makes
a
bit
scare
of
going
further
because
we
feel
that
these
versions
are
not
pretty
tested.
F
F
Yeah
so
so
they're
testing,
like
performance
of
components
where
you
have
to
run
it
for
a
longer
time
to
see
if
there's
a
memory
and
so
on.
These
are
like
the
they're
hotter
parts
I'm
not
now
I'm,
just
mentoring
memory,
because
this
was
the
reason
once
not
like
it
happens
every
time
but
testing
they
like
the.
If
things
work
from
the
conformance
test.
Point
of
yours
is
easy
fast,
but
testing.
F
F
So
we,
like
our
classes,
is
like
you
can
deploy
any
easy
few
instances
you
can
and,
and
they
all
look
the
same
so
there's
no
special
cluster
for
this
type
of
workload
or
it's
just.
You
can
have
different
instance
types,
and
this
is
basically
what
the
team
wants.
We
don't
like
help
them
so
much.
They
just
requests
and
no
pool
of
a
certain
instance
type,
and
then
we
provision
that
and
they
can
deploy
whatever
no
I
think
this
was
my
initial
thing.
E
F
E
F
The
time
it
was
still
early
enough
that
we
didn't
have
so
much
production
notes,
we
were
able
to
like
just
have
a
downtime,
but
it
was
the
same
cluster.
We
didn't
spin
up
anyone.
We
also
run
a
CD
outside
of
the
masternode,
so
we
have
like
own.
So
if
we
don't
use
cube
Adam
or
something
like
this,
we
develop
this
swing
before
it's
basically
just
easy,
two
instances
with
all
the
things
installed
or
we
use
Korres
right
now
and
just
define
all
the
things
that
we
run
as
system
D
units.
F
D
D
F
Five,
okay,
yeah
and
I
think
it's
that
the
test
clusters
is
pulling
this
average
down
there,
there's,
usually
not
so
much
and
there's
only
one
master
and
so
on.
So
we
have
two
masters
in
production
which
obviously
doesn't
matter
so
much
in
terms
of
how
big
they
are,
but
just
for
you
to
get
an
idea
and
they
the
normal
production
like
the
heavy
used
ones
or
maybe
between
20
and
40,
notes,
I,
think
and
like
when
we
start
to
scale
beyond
200
note.
F
Then
we
start
to
see
problems
in
all
kinds
of
places,
because
then
our
monitoring
start
to
be
automatic.
The
high
service
needs
to
be
scaled
up,
of
course,
and
the
number
of
diamond
set
parts
that
we're
running
is
quite
huge
in
that
case
and
yeah.
So
this
interesting
challenges.
That's
also
why
I
think
having
one
big
cluster
in
our
case
would
like
be
on
impossible,
I
think
it's
it's
too
much.
F
E
F
F
Like
we
have,
we
have
a
team
of
eight
people
to
manage
this
and
yeah,
and,
and
we
need
to
use
it's
not
because
it
take
a
lot
of
time
through
to
test
it.
We
have
everything
automated,
but
it
takes
time
to
like,
like
a
like,
a
minor
release.
Rollout
probably
takes
roughly
a
month
just
because
we
want
to
be
safe
and
we
want
to
let
people
run
the
things
in
test
before
first
for
at
least
a
week
or
something
and
sometimes
longer
on.
A
F
Yeah,
it
is
like
a
major
release.
I
will
agree
that
yeah
yep,
so
I
think
that
that,
like
the
pace
of
that
is,
is
maybe
maybe
once
every
half
year
would
be
better
than
quarterly
in
terms
of
just
catching
up,
and-
and
this
is
more
like
this
feeling
that
you
we
don't
want
to
get
behind
because
we
see
it
all
so
like
it's
as
a
technical
depth,
if
we
suddenly
have
to
upgrade
from
several
versions
behind,
because
there
is
some
feature
that
we
really
want
or
something
like
this.
That
is
not
back
for
it.
F
So
therefore,
we
also
aim
from
the
very
beginning
to
be
able
to
update
quickly.
So
we
are
not
going
to
that
behind,
but
it's
as
we
get
bigger
and
bigger
and
have
more
users.
We,
we
are
getting
slower
this.
We
can
feel
not
because
our
touring
is
not
there,
but
just
because
we
have
to
be
a
little
bit
more
careful
and
things
like
when
we,
when
we
move
to
112
I,
think
we
wait
until
12.5
or
something
before
all
the
boxes
and
that
were
introduced
were
fixed
and
all.
E
F
F
G
You
sign
my
:,
it's
fair
that
it's
fair
aside
that
a
lot
of
this
has
just
been.
You
know,
you've
had
you
got
burned
by
specific
issues,
and
now
that's
sort
of
my
job
be
more
gun-shy
as
you've
yeah
as
you've
run
this
for
longer.
There's
like
we
had
this
issue,
or
this
upgrade
and
this
issue
of
this
acquire
this
issue
this
upgrade,
and
so
now
we've
got
to
sort
of
do
some
searching
to
make
sure
that
we
don't
have
some
more
issues
again.
Is
that
do
you
think
that's
the
way
you
would
say.
F
It
yeah
I,
think
so
I
mean
I'm
bringing
this
up
like
it's
a
big
thing,
but
it's
just
the
most
reason
that
is
not
like.
We
have
huge
issues
all
the
time,
but
it
is
it's
more.
This
fact
that
why?
Why
is
no
one
else
of
the
major
cloud
providers
on
this
version
is?
Is
this
may
be
an
indication
that
this
is
not
tested?
This
is
what
you
worry
about.
A
thing
do.
B
You
do
you
have
like
a
larger
set
of
qualification
procedures
and
that
might
be
more
beneficial
to
the
community,
even
if
they're,
like
workload
enablement
so
like,
if
you
had,
like
example,
plug-in
style
things
that
the
community
could
use
for
verification
for
like
different
types
of
workload,
environments,
it
doesn't
need
to
be
in
KK
like
that.
This
sort
of
way
extension
mechanism
is
a
way
for
people
to
validate
their
environments.
Do
you
have
like
a
set
of
extra
tests
or
verification
procedures
that
you
create.
F
Yeah
so,
basically,
like
I
said,
we
use
the
intro
and
test
the
conformance
test
of
part
of
the
KK
repository.
We
basically
pull
this
out
into
our
own
at
our
image
and
run
this,
and
then
we
have
extended
this
with
some
of
our
own
tests,
which
is
like
setting
up
an
ingress
and
testing
that
I
mean
ingress
infrastructure
works.
These
are
very
like
yeah.
F
B
F
B
F
That
all
the
things
that
we
have
running
currently
in
the
clusters
would
still
work
it
just
tests
that
the
cluster
still
works,
all
the
things
that
we
expect
to
work.
So
obviously
we
don't
cover
everything
but
as
much
as
possible,
and
we
also
like
enabled
stateful
set
tests
there
and
in
kubernetes,
which
tests
like
that
you
can
attach
a
volume
and
so
on.
There's
also
very
helpful
for
us
to
preceeded
everything,
still
works
and
mission
didn't
get
lost
or
whatever
yeah,
and
this
we
have
also
over.
F
C
F
Know
I
mean
we
don't
really
have
tests
and
of
that
kind,
like
really
testing
performance.
I
think
this
is
mostly
a
trade-off
of
like
how,
because
it
is
it's
like
a
mold
test,
it
takes
longer
probably
to
run
it
and
and
then
it's
like
a
trade-off
between
how
long
do
we
want
to
run
tests
between
merging
changes
and
so
on,
and
and
also
like,
also
more
difficult
to
write,
I
think
so
we
don't
really
have
that
it's
more
like
right
now.
What
we
have
is
just
checking.
F
Does
it
does
this
function,
work
correctly,
if
I
create
an
ingress,
do
I
get
the
DNS
name
and
everything
in
analysis
or
does
PSP
work
as
we
expected,
as
we
also
have
tests
for
actually,
which
is
now
on
corneas,
I
think
which
we
started
earlier
with,
but
we
don't
really
have
like
performance
tests
that
really
like
exercise
within
that
way.
We
have
some
with
our.
We
have
our
auto
scaling
for
HPA.
We
have
a
custom
adapter
this
one
we
test,
but
is
also
not
it's
based
on
the
testing
company.
F
C
B
It
just
served
for
edification
that
that's
the
whole
reason
why
we
built
suitably
was
that
we
wanted
all
the
data
we
could
grab.
So
he
created
like
a
plugin
for
a
verification
that
gives
that
gives
developers
and
administrators
and
operators,
not
information,
to
know
the
shape
and
the
knobs
and
the
details
of
your
cluster.
So
we
can
actually
reproduce
it
because
the
sheer
number
of
knobs
as
a
developer
is
fantastic.
Oh
no,.
D
E
D
A
F
I
think
that
the
only
difference
really
is
that
we
are
more
confident
that
less
things
are
changed
in
the
in
the
patch
upgrade,
so
they
are
great.
The
upgrade
process
is
basically
the
same,
but
we
maybe
just
do
it
faster.
So
we
we
just
like
make
a
change
to
our
repository
run.
The
intern
test
merge
it
into
the
first
Channel,
and
then
we
maybe
only
went
wait
like
one
day
or
maybe
in
half
a
day.
F
If
we
see
that
nothing
is
really
problematic
with
a
patch
release,
and
so
it's
just
a
matter
of
how
fast
we
do
it
other
than
that
is
the
same
flow
that
we
follow
and
we'd.
Also
to
like
you
know,
if
there's
no
new
features,
we
don't
like
right
announcement
emails
to
our
users
and
so
on,
so
it
so.
This
just
means
that
it's
a
little
bit
faster
us
and
we
are
I,
think
it's
just
a
matter
of
feeling
more
confident
that
okay,
this
change
is
very
small.
It
fixes
a
specific
problem.
F
We
have
so,
let's
just
roll
it
out
or
if
it's
like
a
security
incident,
then
it's
clear
that
okay,
we
need
to
roll.
This
out
and
we
also
try
if
it's
a
security
incident
and
it's
only
affecting
the
Masters,
for
instance,
they
may
only
change
the
masters
and
roll
it
out
fast,
and
then
the
workers
can
follow
afterwards.
A
A
G
It's
only
relevant,
for
some
small
reasons
are,
is
that
today's
today,
in
Australia
is
my
last
day
at
Atlassian,
I'll
be
moving
to
VMware
I
mentioned
in
this,
only
because
it
as
one
of
the
co-chairs,
it
means
that
VMware
will
now
have
three
of
the
of
the
co-chair
slots.
So
we
will
need
to
talk
about.
You
know
what
we
do
about
that
going
forward
at
some
stage
in
the
future.
H
A
Should
talk
about
this
I
think
it
is
important
when
we
we
brought
in
the
set
of
initial
leads.
We
were
deliberately
looking
for
a
broad
set
of
exposure
and
experience
and
we
don't
want
to
have
too
much
weight
and
one
particular
company
or
entity,
and
then
also
we
want
to
span
like
the
types
of
user
scenarios.
Users
versus
vendors,
and
all
of
that
too,
so
is
something
we
should
chat
about
more
in
the
future.