►
From YouTube: Kubernetes SIG Network Bi-Weekly Meeting for 20220526
Description
Kubernetes SIG Network Bi-Weekly Meeting for 20220526
C
F
B
B
H
Absolutely
and
I
got
to
be
on
a
panel
with
tim
and
lockhee
and
folks,
and
probably
the
most
invigorating
part
about
that
was
the
audience
was
full
of
questions
and
they
had
some
good
questions
and
some
good
ideas
and
just
things
about
okay,
cool.
You
have
dual
stack.
Now.
That's
fine!
Now
here's
a
whole
bunch
of
implementation
details
you
might
not
have
considered
yet.
So
it's
like
wow,
okay,
we've
got
our
work
cut
out
for
us.
A
I
I'm
testing
chrome's
ability
to
keep
all
that
anyway,
so
yeah.
We
briefly
started
talking
about
this.
On
the
last
call
and
since
we
barely
got
started,
I
was
asked
to
reserve
30
minutes,
so
I
haven't
actually
myself
paid
any
attention
to
this
or
worked
on
it.
So
there's
a
chance.
I
might
be
forgetting
a
few
things,
but
we'll
bring
it
as
we
go
and
hopefully
we'll
have
enough
to
decide
how
to
go
forward.
I
I
I
Should
the
feature
be
designed
to
cover
both
single
network
and
multiple
network
modes
of
operation,
or
you
know,
various
kinds
of
multi-cluster
operation
modes
and
just
to
briefly
describe
when
we
say
single
network,
we
mean
a
group
of
clusters
which
are
in
the
same
routing
domain.
They
don't
need
to
nat
to
talk
to
each
other.
All
pods
have
unique
ip
addresses
and
parts
to
port
upon
traffic
can
work
without
going
through
any
kind
of
netting
gateway.
I
That's
quote,
unquote
the
single
network
or
flat
network
model
and
multi-network
model
implies
all
pods
are
in
their
own
routing
domain
and
they
typically
not
to
get
out
or
get
in,
and
so
each
of
those
are
their
own
code.
Private
networks
and
pods
have
to
go
through
some
kind
of
multi-cluster
gateway.
I
I
Should
this
policy
be
within
the
scope
of
if
we
are
working
within
the
mcs
api
model?
Should
the
policy
be
within
the
scope
of
a
cluster
set
or
are
we
talking
also
multi-cluster
set?
So
cluster
set,
as
perhaps
you
may
know,
is
a
group
of
clusters
over
which
multi-cluster
services
are
distributed
and
are
within
the
same
administrative
domains
to
have
the
same
set
of
namespaces
and
so
on,
at
least
as
far
as
multi-cluster
services
are
concerned.
I
So
should
the
policy
also
be
within
the
cluster
set,
or
should
the
policy
be
both
within
and
across
cluster
sets
and
class
across
cluster
set?
You
might
call
it
like
a
multi-cluster
set
model
so
which
is
sort
of
one
more
level
of
beyond
just
multi
cluster,
and
if
you
look
at
it
in
istio-like
terminology,
they
sometimes
call
that
as
multi-mesh.
I
The
other
bullet
is.
What
exactly
is
the
admin
model
for
multi-cluster
that
we
want
to
address
with
this
sort
of
features
right?
What
are
we
protecting
against
and
what
is
the
admin
model?
You
know?
Presumably,
we
first
start
with
a
developer
with
a
set
of
apis
that
are
targeted
at
the
developer
user.
I
But
then
you
know
what
is
the
admin
model
and
the
developer
model,
and
also
what
is
the
threat
model
that
we
are
trying
to
solve
and
then,
in
general,
we
just
need
to
continue
to
get
use
cases
from
people
that
are
actually
deploying
multi-cluster
apps
as
to
what
kind
of
segmentation
and
operational
needs
they
have.
So
we've
made
some
cuts
at
some
some
use
cases
but,
as
we
know,
multi-cluster
is
still
a
new
field,
and
then
you
know
things
like
policy
for
multi-cluster
are
also
still
very
you
know
early.
I
B
I
I
just
want
to
put
that
out.
There
agree
yeah.
Maybe
I
should
have
put
that
in
there.
I've
got
some
points
at
the
end,
which
include
you
know.
Should
this
be
just
an
extension
of
regular
network
policy,
so
the
actual
api
details?
Is
it
the
same
kind
or
is
it
a
new
kind?
Is
it
semantically,
exactly
like
network
policy
but
just
describe
yeah
so
agree
with
agreed
with
what
you
just
said.
I
I
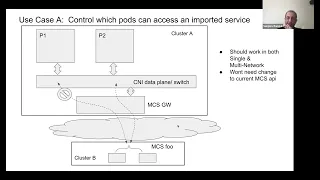
This
particular
picture
implies
the
multi-network
model,
which
we
just
alluded
to
earlier,
which
means
that
these
pods
are
in
their
own
cider.
These
spots
are
in
their
own
side,
as
the
sliders
might
actually
be
the
same,
so
you
have
to
go
through
some
kind
of
gateway
or
netting
operation.
For
now
we
are
calling
it
an
mcs
gateway
after
the
mcs
api,
and
that
is
what
allows
a
pod
in
cluster
a
to
talk
to
a
pod
service
in
cluster
b,
even
though
the
pods
might
actually
have
the
same
ip
address.
I
I
I
I
From
cluster
b
into
cluster
a-
and
here
the
import
refers
to
the
mcs
api
import,
which
is
the
next
explicit
import,
explicit,
export
and
import,
but
once
I
have
imported
it
into
cluster
a
I
don't
want
it
to
be
usable
by
any
port.
I
want
to
decide
that
the
spot
doesn't
get
to
access
the
imported
service
and
this
part
does
get
to
access
it.
So
I
want
to
have
some
kind
of
egress
direction.
I
Multi-Cluster
policy
referring
to
the
imported
service
without
needing
to
know
pod
ips
in
the
remote
cluster,
because,
as
we
said
earlier,
it
has
to
work
both
in
single
network
and
multi-network
mode.
So
we
can't
just
put
a
policy
save
which
you
know
a
cider
based
policy,
for
example,
which
just
looks
for
the
remote
ips.
I
So
that's
the
first
use
case.
So,
as
we
said
earlier,
this
should
work
in
all
topologies
and
from
what
our
initial
look
at
it
looks
like
this
could
be
done
within
the
scope
of
the
current
mcs
api.
So
this
this
sort
of
use
case,
if
we
want
to
address
it,
would
not
require
an
mcs
api,
architectural
change
in
terms
of
feedback
from
the
real
world.
I've
heard
of
some
early
users
of
mcs,
where
this
kind
of
scenario
was
considered.
B
I
So
that's
the
other
use
case.
So
two
comments
on
that.
Yes,
your
point
is
valid
and
the
the
two
comments
are
as
follows:
a
we
have
some
other
use
cases
for
received
site
enforcement
and
b.
One
of
the
core
assumptions
of
the
mcs
api
is
that
the
cluster
set
is
a
consistent
admin
domain,
whether
these
are
separate
admins
or
whether
these
are
admins
that
are
cooperative
admins.
I
They,
let's
just
keep
it
simple
and
say
it's
a
simple
admin,
because
the
additional
requirement
of
the
cluster
set
is
that
namespaces
have
to
mean
the
same
thing
across
all
the
clusters
in
the
cluster
set
and
exports
and
imports
are
being
done
with
an
implied
trust
model.
So
the
assumption
is
that
there
isn't.
I
There
is
a
common
trust
model
across
these
clusters
for
the
case
that
you're,
referring
where
there
is
not
an
implied
common
trust
model
either
we
have
to
decide
that
that
doesn't
fit
into
mcs
or
requires
additional
use
cases,
and
we
have
to
address
it.
So
this
particular
use
case
is
for
the
scenario
where
there
is
an
implied
common
admin
model
and
enforcing
an
egress
is
effectively
also
protecting
the
service
or
because
it's
all
one
admin.
I
Agree
so
we
may
decide
that
just
just
egress
filtering
is
is
not
enough,
but
of
course
this
is
just
one
one
use
case
that
we
can
support,
because
if
you
do
have
the
the
ability
to
enforce
this,
the
benefit
is
that
you
drop
the
packet
early.
You
drop
it
on
the
sending
cluster
rather
than
sending
the
traffic
all
the
way
to
the
receiving
cluster
consume
bandwidth
and
then
drop
it
right.
I
So,
if
you
have
you,
you
may
want
to
additionally
have
receiver
side
filters,
but
to
the
extent
that
sending
side
filters
are
valuable
because
you're
dropping
it
earlier
in
the
sending
cluster
rather
than
the
receiving
cluster,
and
you
actually
get
more
granularity
on
the
sending
side
which
we'll
see
you
know
so
the
short
answer
is
we
probably
need
a
combination
of
both
sending
side
and
receiving
side
clusters
and
different
cases.
Have
you
know
so?
I
I
I
I
The
only
difference
here
is
that
on
the
egress
we've
added
a
service
import
reference
or
just
a
service
input
really
so
that
on
the
sending
cluster,
this
would
have
to
be
an
imported
service
to
access,
and
we
would
say
only
parts
that
satisfy
these
match.
Selectors
and
so
on,
can
send
or
can
not
send
to
this
imported
service,
so
it
could
fit
in
pretty
much
with
a
semantic
like
today's
network
policy,
maybe
the
same
kind
may
be
with
different
kind,
but
with
the
addition
of
additional
selectors
and
filters.
I
A
I
I
So
this
cluster
will
see
a
new
api
resource
show
up
without
the
user
configuring
it.
It
would
be
pushed
by
the
controller
to
members
of
the
cluster
set
and
he
will
see
the
service
import,
so
he
will.
That
is
his
representation
of
a
link
to
the
remote
okay,
and
so
on
his
side.
He
says:
okay,
these
pods
are
allowed
to
send
to
this
service
import
which
shows
up,
and
these
parts
are
not
allowed
to
the
service
import
which
showed
up
and.
I
A
A
I
B
I
mean
yeah
like
for
a
developer
who's,
writing
a
network
policy
who
may
or
may
not
know
whether
they're
going
to
be
running
in
a
multi-cluster
environment.
If
we
were
to
support
something
like
this,
they
have
to
specify
both
because
they
don't
know
whether
they're
allowing
single
cluster
or
multi-cluster
right
like
there
isn't
a
way
to
express
both
unless
we
add
a
slight
shim
in
between
here
that
says,
you
know
a
service,
ref
means
service
or
service
import.
I
Yeah
there
are
some
nuances
about
implicit
versus
explicit
mapping
between
services
and
service
imports.
We
don't
need
to
go
down
that
sort
of
path
in
this
particular
call.
But
you
know,
as
we
go
further,
we
can.
We
can
deal
with
that.
But
yes,
there
is
that
issue
of
potential
similar
synergy
with
regular
sentences.
Yes,.
A
I
I
Here
the
requirement
is:
if
multiple
clusters
are
providing
this
service,
the
client
cluster
should
be
able
to
control
which
providers
of
that
service
can
be
used
by
which
client
pods.
So
in
this
case,
mcs
foo
is
provided
both
by
remote
cluster
b
and
by
remote
cluster
c
they're,
all
in
the
same
cluster
set.
This
is
actually
in
theory
a
cluster.
I
A
client
could
send
to
either
cluster
b
or
cluster
c,
but
for
administrative
reasons,
this
particular
tenant
or
application
should
be
accessing
this
global
service.
Let's
say
only
from
this
cluster
b,
so
the
admin
here
or
even
the
developer.
Here
again,
let's
keep
for
now.
Let's
put
it
as
for
simplicity.
The
developer
persona
has
a
policy
which
says:
okay.
I
These
points
should
first
go
to
should
only
access
the
service
from
cluster
b,
maybe
because
of
geolocation
or
maybe
because
of
latency
or
maybe
because
of
just
administrative
policy,
but
it
is
more
convenient
for
the
enterprise
to
have
multiple
instances
of
the
service
all
over
the
enterprise,
because
this
is
your
let's
say
your
global
directory
service
or
your
global
service,
which
is
instantiated
in
lots
of
locations.
But
you
want
to
administer
the
control
that
I
want
to
get
this
service
only
from
location,
one
and
two,
but
not
from
location
three.
I
I
I
I
If
I
didn't
have
the
filter,
I
could
go
to
any
of
these
back
ends
and
I
could
load
a
bowl
across
load
balance
across
these
four
back
ends.
But
I
need
to
distinguish
that.
Okay,
I
want
to
only
go
to
this
cluster
set
back
ends
represented
by
this
cluster
set
and
not
back
ends
represented
by
this
cluster
set.
So
I
need
the
gateway
comma
cluster
set
ip
to
for
him
to
differentiate.
I
know
that
was
a
little
bit
of
a
detail,
but
so
comments
on
this
use
case.
I
I
B
B
But
if
you
sort
of
zoom
out
and
look
for
a
pattern,
it's
the
same
thing
as
traffic
policy,
local
internal
traffic
policy,
local
right,
it's
just
local
means
same
region
or
same
zone
or
something
else-
and
I
guess
that's
okay.
I
I
I
was
okay
with
internal
traffic
policy,
so
I
don't
have
a
leg
to
stand
on
to
say
no
to
that,
although
it's
not
same
it's,
it's.
B
B
I
Yeah,
so
this
this
use
case
came
up.
I
was
actually
discussing
multi-cluster
scenarios
with
with
your
colleague
nathan
from
google
tim,
so
he
kind
of
suggested
this
kind
of
scenarios
in
a
few
other
discussions
as
well,
where
the
point
was
that
it
is
very
convenient
to
have
global
services
provided
from
different
locations,
different
kinds
of
clusters,
some
on-prem,
some
on.
I
You
should
split
these
into
two
different
kinds
of
global
services
as
an
alternate
way
of
solving
it
right.
So
you
want
to
you
want
to
have
actually
that
same
services
running
the
same
back
end,
but
you
have
various
kinds
of
administrative
scenarios
that
end
up
popping
up
in
practical
scenarios.
Some
of
them
could
be
based
on
geography.
Like
you
were
just
saying.
You
know
these
europe
clusters
should
always
go
to
europe.
I
Of
course
there
are
you
know
geographical
dns.
Also,
you
know
the
cluster
dns
could
also
become
sort
of
jio
aware
and
all
that,
but
but
this
could
be
the
other
way
around.
Also
that
you
know
yes,
I
have
a
cluster
in
europe
that
I
could
talk
to,
but
but
this
application
needs
to
stay
within
my
enterprise
boundaries,
so
I
need
to
only
talk
to
clusters
in
europe
and
within
my
enterprise,
whereas
this
application,
I
can
talk
to
any
cluster
in
europe.
I
It
doesn't
have
to
be
within
my
enterprise,
so
there
can
be
all
kinds
of
administrative
rules
which
we
may
not
always
foresee,
but
the
point
is
that
global
services
are
convenient.
You
still
want
to
decide.
I
want
to
use
these
providers
for
this
application
and
maybe
the
entire
set
of
providers
for
this
other
application.
B
E
No,
I
mean
I
just
wanted
to
ask
what
the
implementation
mechanism
for
this
is.
My
thought
was
that
you're
describing
a
pretty
complicated
routing
scheme,
and
it
feels
like
this
extends
beyond
network
policy.
Right
like
this
sounds
like
something
that
just
if
you
have
mcs
in
general,
you
might
want
to
describe
region,
locking
or
or
stuff
like
that,
like
independent
of
you
know
any
security
contracts,
it
sounds
like
a
problem
that
maybe
network
policy
doesn't
want
to
be
involved
in.
I
So
yeah
we
could
continue
thinking
about
it.
You
know
this.
This
has
some
similarities
to
various
topology,
aware
routing
sort
of
scenarios,
but
but
again
this
is
still
an
early
look
at
the
kinds
of
scenarios
some
of
them
may
be
appropriate
to
tackle,
and
some
of
them
may
require
different
functionality,
we're
just
sort
of
throwing
out
straw,
men
hear
about
scenarios
and
then
picking
the
ones
which
are
more
important
to
tackle
first.
Okay,
we
can
stop
here,
looks
like
so
just
to
show
you
what
was
remaining.
We
won't
go
into
it.
I
So
there's
another
use
kc,
which
is,
which
is
another
kind
of
english
control
use.
Case
d
was
basically
treating
multi-cluster
as
unique
cluster
in
every
possible
way.
So
do
everything
in
multi-cluster
that
you
can
do
in
uni
cluster,
but
that
typically
would
imply
that
it
only
works
in
the
flat
network
model,
not
in
the
multi-network
model.
So
if
we
decide
that,
maybe
this
primarily
only
needs
to
do
the
flat
network
model.
I
There
is
also
that
other
thing,
which
is
you
do
everything
in
multicluster
that
you
can
do
with
your
cluster,
including
cider,
prefix,
and
so
on.
You
know.
That's
one
thing:
I've
got
a
note
on
various
other
use
cases
which
you
know
please
think
about
it
and
yeah.
So,
basically
just
trying
to
get
an
agreement.
What
are
the
use
cases
and
then
decide
the
priority
of.
B
I
F
Yeah,
so
I
think
I've
spoken
to
rob
and
it
kind
of
sounds
like
the
community
in
cygnet
might
already
be
aware
of
these
issues.
There's
also
a
fix
so
just
to
kind
of
catch
everyone
up.
There
was
a
refactor
in
122
that
changed
a
kind
of
pod
life
cycle,
essentially
pod
shutdown
takes
longer
than
before.
F
So
in
situations
like
node
evictions
or
pod
evictions,
what
happens
is
the
pod
doesn't
have
time
to
complete
its
shutdown
and
it
ends
up
that
the
pod
doesn't
report
its
status
and
then
it
goes
away
and
then
cubelet
kind
of
doesn't
know
what
happened
to
the
pod.
But
so
the
pod
goes
into
this
unknown
state,
but
it's
never
deleted
because
of
this.
Our
endpoints
controller
and
endpoint
slice
controller
doesn't
consider
the
pod
as
terminated
and
then
keeps
the
end
point
alive
and
keeps
it
in
the
service
resources.
So.
H
F
C
And
I
have
another
new
for
you.
There
is
another
part
with
the
shutdown
yeah,
but
this
one
is
related
to
probes,
and
I
think
I
mean
I
didn't
have
time
to
address
the
comments.
So,
if
you
can,
I
know
rob
added
some
of
the
comments.
Kraton
added,
I
will
work
tomorrow
or
for
next
week.
It
should
be
ready
and
I
mean
I
think,
that
that
we
should
afford
it
to
122.
right.
F
C
F
I
also
want
to
second
bowie's
point
in
the
chat
that
we
should
probably
improve
our
testing
around
this.
I
know
we
have
some.
I
think
then
we've
I
talked
to
some
folks
in
signet
and
they
pointed
us
to
some
restart
tests
and
reboot
tests,
but
maybe
we
need
to
add
a
little
bit
to
that,
so
we
could
catch
things
like
this.
C
But
the
the
the
main
problem
here
is
is
we
are
consumers
and
the
signal-
and
this
this
signal
should
have
test
for
this.
So
the
the
main
problem
is
that
what
I
understood
for
talking
with
kraton
is
that
until
122
the
life
cycle
was
was
buggy,
so
you
can
have
a
pulse
fade
and
need
return
to
be
ready
and
things
like
that.
C
C
We
should
have
these
guarantees,
I
I
had
to
to
pull
all
the
people
in
in
qcon
to
understand
their
cycle
and
and
that's
just
it,
no
nobody
has
it
clear
and
I
think
that
we,
the
rest
of
the
projects
in
kubernetes,
work
wrong.
We
know
work
around
in
all
these
lifecycle
things.
Everybody
interpreted
one
thing
or
the
other,
and
we
have
this.
I
mean.
K
C
F
K
C
K
C
I
don't
know
right
now.
I
don't
know
in
signal
who's
handling
this,
but
what
we
need
to
do
and
I'm
going
to
fix
this
back
other
a
regression
test.
I
need
to
check
the
other
with
the
probes.
I
need
to
add
another
regression
test.
Andrew
is
on
leap
right,
because
I
do
have
tests
for
the
prettiness
thing
that
we
don't
have.
We
need
to
check
and
we
are
not
tested
too.
C
C
K
F
C
F
So,
as
I
was
debugging
some
of
these
life
cycle
issues,
I
noticed
it's
very
difficult
to
kind
of
isolate
our
controllers
and
when
you're
looking
through
the
logs,
I
wanted
to
see
if
people
would
be
opposed
to
kind
of
adding
some
context-
logging
at
least
to
our
controllers.
So
that
would
be
endpoint
and
point
slice
any
others
that
people
are
interested
in
and
do
we
need
a
formal
kept
for
that
or.
F
Just
to
kind
of
add
like
a
key
on
the
like
logs.
That
way
you
can
filter,
so
you
could
say
like
endpoint
slice,
controller
or
endpoint
controller,
and
you
can
kind
of
filter
that
out
a
lot
easier
right
now
there
is
no
filter.
Once
you
get
into
the
cube
controller
manager,
like
you
get,
I
think
some
data
you
get
is
like
the
line
number
and
then
the
file
number
file
name.
F
C
B
It's
supposed
to
enable
this
so
now,
when,
like
the
idea,
was
early
on
in
the
life
cycle,
when
the
controllers
are
all
spawning
off,
you
can
add
metadata
and
says
this
is
the
logger
for
the
endpoint
slice
controller.
This
is
the
logger
for
the
fubar
controller
and
then
that
gets
annotated
on
every
log
line,
and
that
way
you
can
do
this
sort
of
filtering
so
so
that
I
think
the
short
answer
is
yes,
we
should
totally
look
into
it.
That's
what
the
structured
logging
is
supposed
to
enable
it's.
B
I
think
I
don't
know
if
anybody
else
has
started
on
this
process.
If
not,
I
think
we
can
be
the
pioneers
and
say
hey
we're
going
to
decorate
some
of
our
controllers
to
work
this
way
and
if
it
looks
like
it's
successful,
we
should
encourage
others
to
follow
suit.
If
others
have
already
started
on
this
path,
then
we
can
follow
their
lead.
B
A
H
So
I
apologize
for
not
being
in
the
mix
and
helping
with
that,
but
it
looks
like
we
are
going
to
be
pushing
that
one
forward
to
1.25
or
beyond,
and
I
started
chatting
with
cal
about
what
still
needs
to
happen
and
I
started
looking
at
this.
It
looks
like
there
was
a
draft
pr
to
do
some
of
the
code
work
and
I'm
kind
of
wondering
does
anybody
else
have
this
one
on
their
radar
is
something
that
they're
interested
in
working
on.
It
kind
of
looks
like
the
person
who
wrote
109.
H
Absolutely
so
like
there's
yeah,
so
there's
there's
two
things
there
there's
the
the
docs
and
whatnot
that
needs
to
happen
for
the
original
thing
that
got
kicked
out
of
the
release.
I
can
help
with
that,
but
then
I'm
looking
at
this
stuff
and
thinking
do
we
have
somebody
who
wants
to
work
on
taking
over
that
pr
if
that
person
doesn't
come
back
basically
so.
B
E
E
H
Awesome,
I
think,
we'll
we'll
probably
be
in
a
little
bit
of
a
race
condition
to
if
we're
going
to
try
to
get
this
into
1.25.
You
know
we
might.
We
might
end
up
missing
that
in
terms
of
the
enhancements
deadline,
we
can
try,
but
it
sounds
like
if
we
are
going
to
get
moving
movement
on
it
started
in
early
june,
then
we
might
get
into
window
26,
which
you
know
is
fine.