►
From YouTube: Service APIs Office Hours 20200520
Description
No description was provided for this meeting.
If this is YOUR meeting, an easy way to fix this is to add a description to your video, wherever mtngs.io found it (probably YouTube).
A
A
D
E
C
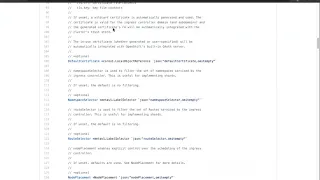
Using
custom
resources
instead
of
ingress
and
so
I
put
a
link
there
for
OpenShift
because
and
we
use
a
route
custom
resource
we
have.
We
have
a
controller
that
converts
an
ingress
object
to
a
route
object,
and
one
of
the
things
here
is
that
we
support
either
what
you
see
here
on
the
screen
or
you
can
create
a
route
and
specify
the
termination
type
like
re-encrypt
here
or
edge,
where
edge
would
be
righted.
The
TLS
connection
gets
terminated
at
the
ingress
controller
and
then
is
just
TCP
between
the
ingress
controller
in
the
backend.
C
E
C
I
think
it's
it's
going
to
be
the
combination
of
the
two,
so
what
we
use
as
an
ingress
controller
would
be
the
combination
of
the
Gateway
and
the
Gateway
class
and
certain
issues
that
we've
created,
where
we've
gotten
feedback
on
things
like
replicas
or
ISA.
You
know
it's
really
an
implementation
specific!
That's
where
we'd
pass
pass,
that
into
daily
classes,
parameters.
C
But
you
can
see
the
domains
is
used
for
things
like
a
load,
balancer
service
and
publishing
strategy
used
for
generating
the
default
certificate
because
we
generate
a
wild
card
default
certificate
for
the
domain.
You
specifying
and
again
that's
used
so
that
if
a
Rob
doesn't
specify
a
certificate,
this
is
kind
of
a
fallback
certificate.
If
the
route
specifies
a
TLS
config
without
I
should
providing
the
cert
number
replicas
endpoint
publishing
strategy
right
because
we
run
the
ingress
controller.
C
It's
an
H,
a
proxy
implementation
and
we
run
it
as
a
deployment
and
based
on
what
the
environment
is,
that
it
that
it's
being
deployed
in
we're
gonna
have
different
endpoint
publishing
strategies
right.
So
if
it's,
if
the
clusters
on
bare
metal
we're
gonna
expose
the
ingress
controller
differently
than
what
we
do
on
a
cloud
provider,
I
already
talked
about
the
default
certificate,
so.
C
H
approximate
yeah
all
right,
so
how
do
we
want?
And
so
if
we
create
an
ingress
controller
or
we
say
replicas
we're
gonna
spin
up
a
deployment
for
H
a
proxy
consisting
of
you
know
two
pods
and
how
we
expose
the
you
know.
The
networking
for
those
pods
will
depend
on
the
endpoint
and
publishing
strategy
and
an
endpoint
publishing
strategy
is
set
based
on
the
environment,
that
the
cluster
is
being
run
in
I.
B
B
F
E
C
We
do
a
bunch
of
stuff
by
default.
One
of
the
things
we
do
is
say:
okay,
we're
gonna
set
up
in
Brett's
for
you,
so
we
have
an
ingress
controller
named
default
and
the
attributes
of
that
default.
Ingress
controller
Argo
are
going
to
be
based
on
some
of
the
other
cluster
configuration
parameters
and
one
of
the
big
ones
is:
will
what
kind
of
cluster?
Where
is
this
cluster
running?
Is
it
on
a
cloud
provider?
Is
it
on
bare
metal?
Is
it
on
Limbert,
so
on
and
so
forth?
C
And
so
our
ingress
operator
is
going
to
look
at
some
of
those
other
resources
to
go
ahead
and
say:
okay,
let's
go
ahead
and
create
this
default
ingress
controller
with
certain
attributes,
and
you
can
create
multiple
ingress
controllers
right.
So,
if
you
want,
you
know,
you
get
a
a
new
group
that
says:
oh,
we
don't
want
to
use
the
default
ingress
controller,
okay,
we'll
create
in
Grips
controller
foo
and
look
at
all
the
things
you
can
set
via
the
spec
of
the
ingress
controller
to
meet
your
needs.
C
If
you
want
to
continue
to
use
a
default
ingress
controller
or
no
matter
what
the
ingress
controller
is,
you
know,
typically
developers
are
going
to
be
just
interfacing
with
the
with
the
route
API
creating
a
route
setting.
You
know
the
host,
so
this
is
you
know
when
we
say
the
host
of
a
route
right.
This
is
analogous
to
what
we're
doing
with
with
ingress.
You
know
hostname
or
service.
Api
is
the
HTTP
route
host.
C
C
Yes,
so
if
a
user
created
a
conflict
under
on
you
know
you
got
route,
foo,
that's
is
created.
You
then
check
the
status,
and
you
see
that
it's
been
admitted
by
being
Brest
controller.
You'd,
see
that
it's
let's
say
it's
admitted
by
Ingres
controller
default,
say:
okay
now
it
should
be
functional.
Right
and
I
should
be
able
to
hit
that
host
if
I
create
route
bar,
and
it
has
a
conflict
with
the
hostname.
C
F
So
when
you
created
route,
if
you
have
multiple
ingress
controllers,
they'll
all
show
up
in
this
slice
here
in
the
route
status,
a
slice
ingress
and
that
slice
will
report
for
each
ingress
controller,
whether
the
route
has
been
admitted
by
that
ingress
controller
and
if
so,
the
host
that
host
of
the
route
and
the
canonical
name
for
the
ingress
controller,
so
that
you
know
where
to
point
your
cname.
If
your
route
is
exposed
under
multiple
load,
balancers.
F
E
F
Right
yeah,
if
you
have
two
routes
and
they
try
to
claim
the
same
route
same
path
or
if
you
have,
for
example,
say
a
pass-through
route
that
claims
a
host
and
then
you
have
an
edge
route
that
tries
to
claim
a
path
on
that
host.
Well,
that
that's
not
possible
to
realize,
and
so
we'll
say
that's
this
conflict.
F
You
can't
you
know
if
you
have
a
pass-through
for
the
host,
then
we're
not
even
looking
at
the
the
request,
we're
just
passing
through
the
TLS
connection,
so
you
can't
create
an
edge
route
that
uses
the
same
host
in
the
past.
That's
a
conflict
or
if
you
have
two
edge
to
edge
routes,
both
claiming
the
past
/foo
on
the
same
host.
That's
a
conflict
and
we'll
report
it
in
the
status
and
only
admit
the
the
older
of
the
two
routes.
So.
G
G
H
E
F
Theoretically,
yeah
yeah
I,
don't
think,
there's
any
guarantee
that
the
thing
the
older
one
will
have
a
lower
UID.
Generally,
that's
the
case
but
yeah
there
there's.
You
know
the
potential,
but
if
you've
created
a
route
and
then
some
significant
amount
of
time
later
say
a
day
later,
someone
else
creates
a
route.
It's
extremely
unlikely
that
the
second
route
will
have
a
lower
UID.
It's
just
if,
according
to
at
about
the
same
time,
you
may
have
you
you
can't
say
for
sure
which
one
will
end
up
with
the
lower
UID
Oh.
F
G
Yeah
I
think
Mission
Control
is
the
right
solution
they're
like,
but
it
does
add
a
lot
of
implementation,
because
then
you're
also
stopped
dealing
with
emission
control
and
all
of
the
things
that
come
along
with
it
like
yeah.
If
you
need,
if
you
want
to
uninstall
your
having
a
broken
admission,
controller,
can
break
your
cluster
and
stuff
like
that.
B
D
I
G
They
do
to
to
do
the
sorts
of
things
that
we
want
the
service
opiods
to
do
in
that
way
by
the
idea
being
by
having
problem
or
concrete
examples
to
give
us
more
to
bring
us
all
to
bring
us
all
closer
to
the
same
model.
You
know
heads
of
how
all
this
stuff
works
so
that
then,
when
we're
talking
about
it,
we
can
make
sure
that
we're
doing
so
in
a
non
impedance
mismatch
kind
of
like
I,
do
on.
E
C
I'm,
seeing
right
now
Bowie
is
is
again
if
we
go
back
to
that.
First
link,
which
is
kind
of
the
web
kind
of
user
facing
instructions,
is
right
now
we're
kind
of
providing
the
best
of
both
worlds,
where
I
think
most
developers
are
just
gonna,
create
a
route
and
then
go
ahead
and
say:
yep
I
wanted
to
tell
us
config
the
termination
type
and
here's
my
certificate
information
right,
but
we
also
have
the
ability
to
say:
okay,
I'm
flying
using
the
wildcard
certificate
of
the
ingress
controller.
C
That
is
responsible
for
my
routes,
so
I'm
just
gonna
go
ahead
and
and
say
here's
a
route,
create
the
route.
There's
a
TLS
config
and
not
actually
provide
you
know,
say
the
termination
type
is
edge
or
re-encrypt,
but
not
actually
provide
any
of
the
TLS
assets
and
I
think
that's
kind
of
the
gap
that
I'm
still
trying
to
figure
out
how
we
resolve.
B
Yeah
in
service
api's
because
of
the
split
between
the
Gateway
and
routes,
one
of
the
things
I've
seen
struggled
with
there
is-
is
not
really
a
good
way
for
the
application
owner
to
express
intent.
So
you
have
your
routes
and
say:
oh
he's
here
they
are,
but
you
it's
hard
to
see
where
an
application
and
her
expresses
Harriet
like
intent
for
this
I
want
this
to
be
encrypted.
Is
this
this
assumption
of
some
kind
of
a
depend
communication
which
isn't
very,
very
cool?
It's
just
assumed
I,
guess.
F
Didn't
remember
just
now
one
other
thing
with
our
API
that
maybe
you
can
learn
from
is
we
realized
having
the
this.
The
host
in
the
spec
is
not
ideal,
sometimes
for
some
use
cases
when
it
comes,
for
example,
to
sharding,
and
we
considered
adding
instead
of
host
or
as
an
alternative,
to
specifying
host,
allowing
you
to
specify
sub
domain.
And
then,
if
you
have
your
route
under
multiple
shards
that
have
different
domains,
you
get
a
host
based
on
the
routes,
sub
domain,
plus
the
ingress
controllers
domain.
F
Yeah
I
think
that's
sort
of
how
isn't
that,
how
contours,
HTTP
proxy
D
resource
works?
You
can
specify
well
what
we
were
thinking
for
openshift
was.
We
would
let
you
specify
a
subdomain
and
yeah.
It
would
be
a
domain
under
the
ingress
controllers
domain
and
if
your
route
is
under
multiple
ingress
controllers,
you
end
up
with
a
hostname
that
is
a
common
subdomain
and
then
your
ingress
controllers
domain,
which
will
vary
across
different
ingress
controllers.
Different
shards,
what-have-you.
F
I'm
not
sure
what
you
mean,
yeah,
the
well
usually
with
openshift
you
specify-
or
you
often
you'll,
just
let
the
api
default
the
host
and
it
will
default
a
host.
That's
under
the
clusters
ingress
domain
and
then
that
will
be
underneath
the
ingress
controllers
domain
and
we
have
we
set
up
a
wild-card,
DNS
and
wildcard
certificate
to
handle
anything
under
that
domain.
So
any
route
where
you
don't
specify
a
host.
You
get
default
host
that
matches
the
ingress.
The
default,
ingress,
controller's
certificate
and
dns
configuration.
E
E
F
E
A
This
has
been
really
helpful.
Is
it
worth
planning
on
doing
one
of
these
every
office
hours
until
we
run
out
of
implementations,
or
it's
that
too
much
of
a
commitment
that
sounds
good
delay
and
any
volunteers
I
know
we
have
plenty
of
implementations
represented
here.
Anyone
want
to
volunteer
for
next
week.
C
A
Alright
well
I
think
I.
You
know
I
added
something
to
be
agenda
to
talk
about
multi,
cluster
and
traffic
splitting,
but
before
we
get
into
that,
I
wanted
to
give
a
bit
of
an
opening
here.
If
anyone
had
issues
or
pull
requests
that
could
use
some
attention,
any
requests
to
go
over
one
er.
If
you
want
yeah
I.
C
A
A
C
A
B
Yeah
I
updated
it
yesterday
we're
going
to
try
to
address
some
concerns
that
people
raised
I
still
need
to
go
through
and
write.
Some
examples,
I
thought
that
was
a
great
suggestion
and
because
I
need
to
go
through
and
try
and
actually
write
some
configurations
using
using
this
scheme
and
I
think
that'll
give
people
a
pretty
good
idea
about
how
it
would
play
out
in
practice.
But
the
main
change
here
is
that
in
the
you
listener
definition,
the
hostname
is
now
a
match
structure.
B
So,
instead
of
just
being
a
string,
it's
now
you
now
have
a
match
type
and
a
match.
Valley
and
the
match
type
is
either
exact
or
domain.
If
it's
exact
its
full
hostname
match
of
its
domain,
then
a
wild
card
match,
and
if
that
match
is
absent,
then
it's
a
default
like
thing
the
rules
of
how
you
collapse,
the
rules
to
collapse.
This
thing
into
virtual
services
then
become
a
little
bit
more
verbose,
but
it's
still,
they
can
still
be
explained.
H
B
B
There's
no
I
could
do
that.
You
can't
do
SN
I
pass
through
there's
no
way
to
specify
that
yeah
I
think
eventually
there
will
I
mean
eventually
we
obviously
need
that,
but
yeah
well
I
think
there's
a
way
to
kind
of
do
that
you
service,
api's,
now
and
I-
haven't
tried
to
tackle
that
in
this
particular
PR.
Okay,.
G
A
A
J
Was
it
officers
yeah
in
the
last
officers
we
discussed
around
I
think
it
was
one
of
Binion's
PR,
but
if
we
discussed
around
how
retries
and
know
some
connection,
timeout
logic
was
being
put
inside
the
route
object
like
object.
Me
I
mean
the
HTTP
around
object.
So
that's
part
the
discussion
and
the
call
like
you
know
these
are
all
service
level
properties
and
how
multiple
proxies
define.
H
J
Things
inside
ingress,
like
resources
or
another
case
chickipedia
out
or
or
nan,
ok,
natives,
implementation
or
any
other
implementation.
So
the
reason
everyone
does.
That
is
because
there
is
no
place
to
put
these
configurations
around
dual
balancing.
You
know:
health
shaking
from
a
reverse
proxy
or
a
load
balancing
perspective
and
the
timeout
or
retry
behaviors
or
even
protocol
protocol
is
a
little
bit
solved
with
a
protocol
being
introduced
in
1.80.
J
So
so
this
issue
sort
of
buoy
us,
like
let's
document
this
in
one
issue
and
then
track
it.
This
probably
will
help.
You
know,
as
we
are
three
factoring
the
service
it
said,
so
the
sort
of
tracks
all
all
issues
around
configuration,
which
should
be
a
poor
service
configuration,
but
we
currently
do
not
have
any
location
to
place
it
so
it
it
is
not
exhaustive
currently,
but
it
provides.
You
know
some
at
least
three
or
four
buckets
you
know
of.
E
J
Yes,
because
so
you
know,
while
implementing
the
control
Kong,
what
we
realizes,
we
want
to
represent
a
service
in
Cuba
notice
as
a
service
in
Hong.
Kong
is
also
the
concept
of
service,
which
is
very
similar
to
sort
of
an
upstream
and
nginx
at
an
upstream
pool.
Now
what
happens
is
if
you
define
these
configurations
in
multiple
ingress
resources?
J
What
you
have
what
you
run
into
is
conflict,
so
what
is
one
ingress
resource
defines
an
upstream
timeout
of
the
five-second
find
the
other
one
define
for
one
second
like
which
one
do
you
satisfy,
and
it
gets
very
hard
to
signal
to
the
user
like
which
properties
take
effect
either.
You
do
that
or
the
way
I
think
nginx
ingress
currently
does.
That
is.
It
creates
an
upstream
pool
for
each
route.
So
now
each
route
gets
an
upstream
pool
which
sort
of
defeats
the
purpose
of
having
that
service
abstraction.
E
Yeah
I
think
it's.
This
is
definitely
worth
thinking
about.
If,
like
we
have
a
one-to-one
sidecar
named
map
to
service
entity
that
somehow
contains
this.
If
that
makes
sense,
I
would
right
now
it
feels
wrong
to
just
shove
it
into
like
the
foreword
to
section
that
feels
like
we're.
Gonna
get
into
major
problems
there,
but
that
was
one
thing
that
came
to
mind
is
sort
of
extending
service,
but
on
the
side.
G
It
looks
great
Harry.
The
one
thing
I
did
want
to
mention
was
the
thing
that
I
have
found
when
contour
is
that
before
I
started,
being
a
maintainer
for
an
English
controller
and
which
is
also
a
proxy
I,
didn't
realize
the
extent
to
which
lots
of
people
use
the
proxy
as
the
point
to
fix
up
things.
Timeouts
is
a
great
example
of
that,
but
there
are
other
things:
the
retry
behavior
and
a
lot
of
the
other
stuff
you've
talked
about.
G
A
lot
of
people
will
will
use
the
proxy
as
the
place
where
you
fix
that
up
and
you
you
know
you
and
some
people
want
to
be
able
to
enforce
things
there.
Some
contour
you
disease,
although
we
allow
people
to
set
infinite
request.
Timeout
some
contour
user,
specifically
don't
want
their
users
to
be
able
to
set,
to
other
said
that,
and
some
other
things
like
that,
so
that
there
is
a
lot
of
there's
a
surprising
amount
of
feed
Lina
some
answers,
I
guess
the
thing
I'm
trying
to
say.
J
Yeah
but
I
think
yes,
I,
agree
with
that.
I
think
that
definitely
needs
to
be
at
the
proxy
layer.
But
it's
what
it's
about
you
know,
path,
handling
and
party.
Writing
is
a
little
tricky
because
some
people
want
to
do
that
at
the
matching
layer,
and
some
people
want
to
do
at
the
service
layer,
but
so
who
are
back
model
is
a
whole
separate
issue
that
I
think
that
is
not
discussed
in
this
is
in
this
issue.
Yes,
sorry,
but
but
I
do
not
get
your.
What
you're
trying
to
say
here.
G
G
G
The
I
can't
remember,
which
we
called
cluster
admin
or
the
the
Gateway
I
mean
you
sometimes
has
different
different
wants
and
what
the
application
developer
does
sometimes
the
Gateway
and
then
wants
to
like
rein
in
what
the
application
developer
can
do,
because,
if
you're
running
a
sort
of
centralized
proxy,
maybe
you
don't
want
people
to
have.
For
example,
you
don't
want
people
to
have
to
allow
infinite
request.
G
E
Do
you
think
it's
more
of
like
here's,
some
basic
policies
and
then
you
have
to
sort
of
if
you
fall
outside
these
bounds?
We're
gonna
sort
of
take
you
back
in
or
you
think
people
are
also
using
it
as
a
tour
sort
of
like
a
AOP
programming
kind
of
thing
where
they
just
want
to
inject
rules
from
the
side,
because
it's
easier.
G
In
again,
this
is
only
in
some
cases,
but
the
people
who
need
it.
They
really
need
it
like
they're
running
in
some
constrained
environment,
no
regulatory
constrained
or
some
other
constraint
that
the
application
developers
may
not
you
know,
will
care
about.
But
the
the
centralized
team
does
no
one
care
about
them
and
needs
to
be
able
to
make
a
way
that
the
application
developers
can't
inadvertently
break
things
yeah.
And
that's
that's
what
I'm
trying
to
say
here.
Sorry
I've,
derailed
the
conversation
a
bit
I'm.
Sorry.
E
E
G
You
know
timeouts
retry,
behavior
and
limits
on
open
connections
in
the
quest,
those
like
resource
management.
Basically,
it's
a
centralized
proxy
resource
management.
Is
that
other
things
are
the
main
things
where
you
where,
where
the
centralized
operator
will
want
to
override
what
the
application
developers
can
do
or
put
or
put
limits
around
what
the
application
developers
can
do,
they
might,
you
might
say
you
can
have
it
from
you
know
X
to
Y,
but
anything
outside
those
bounds
is
not
valid.
G
B
Is
for
anyone
who's
doing
some
sort
of
multi
tenant
cluster?
So
anyway,
anytime,
you
have
an
organization
which
is
built
around
having
like
a
platform
team
that
operates
the
cluster
and
then
a
then
application
teams
which
deploy
to
the
cluster
the
platform
teams.
You
know
going
to
need
these
sorts
of
policy
controls,
yeah.
G
And,
and
and
and
to
go
back
to
what
the,
where
I
started
this
from
the
other
thing
that
that
platform
team
will
need
a
lot
of
the
time
is
that
they
will
need
the
ability
to
fix
things
that
that
application
teams
have
done
in
a
you
know,
let's
be
real,
let's
say
a
broken
way.
You
know,
sometimes
people
move
applications
onto
a
platform
and
you
can't
and
they
don't
have
the
roadmap
or
the
resources
to
fix
some
broken
behavior
and
the
proxy
is
the
place
where
that
gets,
fixed
or
or
mitigated
in
some
other
way.
J
Yeah,
that's
a
that's
a
very
common
ask
and
we
also
haven't
built
that
out
yet
in
conquer
right
now.
The
wavy
advice-
and
this
does
not
float
very
well
always
but
is
using
something
like
an
open
policy
agent
and
like
going
that
route
and
that
flutes.
Sometimes
while
other
times,
people
have
big
like
custom
controllers
to
actually
work
around.
That.
E
Yeah,
it
seems
hard
to
solve
it
generally,
because
that's
what
open
policy
agent
will
do
for
you,
but
we
can
definitely
sort
of
take
in
at
least
some
small
amount
of
stuff
to
get.
You
know
some
like
eighty
percent
or
something
seventy
percent,
but
like
if
you
like
in
all
generality,
it's
probably
very
hard
to
solve
it.
That's
where.
G
Yeah,
okay,
okay,
it's
just
the
the
point
I
was
trying
to
make
was
that
it's
important
to
keep
that
in
mind
that
it
is
a
thing
that
we,
even
if
we
don't
give
people
the
if
it's
not
included
in
the
spec
specifically,
it
needs
to
not
be
excluded.
If
you
understand
what
I'm
saying
it
needs
to
not
be
made
impossible
by
the
spec,
but
we
don't
have
to
make
it
required,
it
needs
to
be
in
the
optional.
You
know
possible
space
at
least.
E
A
Great
thanks,
I
think
we
have
one
last
issue
here
to
cover,
and
this
is
actually
one
that
plays
nicely
into
work.
That's
already
underway,
but
John
raised
an
issue
earlier
today
that
I
think
we've
talked
about
this
in
various
ways,
but
that
the
current
state
of
our
route
selector
makes
it
very
unclear
what
kind
of
routes
it
should
select
and
I
believe
we
have
at
least
one
PR
that
addresses
this
partially,
but
just
just
a
heads
up,
I
think
that's
the
disco
of
this
really
and
I
think
we're
already
dealing
with
this
any
additional
thoughts.
B
A
E
Think,
like
the
standard
ones
like
HTTP
like
the
ones
that
we're
defining
in
the
repo,
we
can
definitely
give
very
specific
guidance
and
then
leaving
some
room
for
people
to
create
their
own.
You
know
SCTP
routing
or
something
like
that
or
some
custom
and
was
it
MQ
protocol
is
something
like
tip
or
experimentation.
A
Yeah
and
I
think
this
also
came
up
with
the
elf
for
work
that
Jeremy
and
Andrew
had
proposal
on,
and
that
included
a
type
reference
that
I
can't
remember
where
it
was
defined.
But
it
has
specifically
said
what
kind
of
resource
this
selector
was
intended
for.
So
that
did
rule
out
the
possibility
of
selected
selecting
multiple
kinds
of
resources
with
a
single
route
slicker.
But
to
me
that
seems
reasonable.
B
I'm
not
sure
that
specifying
the
resource
name
fundamentally
helps
when
you're
flipping
between
gateway
classes,
because
if
you
had
the
gateway
class
which
supports
the
virtual
service,
then
you
would
have
put
the
virtual
service
resource
in
there
selector
and
then
you
flip
the
Gateway
class
that
doesn't
make
it
valid
it.
Just
you're
gonna
get
the
same.
You're
gonna
have
the
the
Gateway
class
that
now
doesn't
support
virtual
service.
It's
still
going
to
have
to
you
know,
raise.
A
A
Yeah
yeah,
what
it
what
it
does
avoid,
though,
is
is
ambiguity
on
what
the
user
intended
to
be
selected,
but
especially
if
there
are
controllers
or
implementations
that
support
variety
of
different
route
types.
This.
This
specifically
came
up
in
the
idea
of
elf
or
potentially
TCL
gateways
being
able
to
reference
its
for
services
or
TCP
routes.
A
E
E
B
Devil's
advocate
a
little
bit,
you
can
provide
guidance
in
the
spec,
but
the
resources
that
the
gateway
class
can
consume
in
the
way
we
build.
It
now
is
up
to
the
gateway
class,
so
you
don't
actually
need
a
spec
change
to
say
that
you
can
put
service
resources
here.
The
gateway
class
can
just
implement
that
right.
E
G
G
If
you
don't,
if
the
feel
is
optional
in
or
something
like,
then
then,
then
it's
up
to
the
as
James
says
it's
up
to
that
the
the
controller
implementer,
whether
or
how
they
how
they
treat
the
field
to
some
extent.
I,
don't
know
like
the
your
the
I
do,
think
it.
It
does
feel
weird
I
agree
with
him
that
it
does
feel
weird
to
to
have
our
label
selectively
operates
across
multiple
coins.
G
I
B
I
wonder
if
it
there
historical
basis
for
this
in
communities
is
that
it's
annoying
to
write
code
to
hit
all
the
resource
types.
So
when
you
have
a
selector
which
specifies
a
label,
but
no
resource
type
is
super
annoying
because
you
have
to
poke
the
API
server
for
all
those
four
source
types
and
set
up
multiple
Watchers,
and
it's
just
a
bunch
of
yeah.
B
G
B
G
F
E
A
A
A
E
E
G
Yeah
I
agree
with
that.
The
the
I
guess
the
question
that
I
would
ask
is
which
way
is
easier
to
go.
If
we
change
our
mind,
if
we
put
the
listing,
is
it
easy
to
go
from
a
list
and
not
a
list
or
is
it
easier
to
go
like?
Is
there
a
cost?
Is
there
is
there
an
asymmetric
cost
between
of
changing
from
one
way
to
the
other.
G
B
J
G
Yeah
yeah
the
feel
I
heard
up
down.
Yeah
I
get
it
there
is
a
path
and
is
there
a
path?
The
other
way
to
go
from
singular
to
plural
I
mean
Rob
yo.
The
Wonder
has
had
recent
experience
with
messing
with
moving
API.
Oh
so
this
is
what
I
mean
like
yeah.
If
I
like
we
don't
know,
then
it
feels
to
me
like
the
obvious
thing
to
do
is
to
look
at
how
hard
the
change
would
be
to
make
and
and
do
the
thing.
If
we're
not
sure,
then
you
do
the
thing.
H
F
F
B
Think
it
depends
it
on
the
listener
model
a
bit.
So
in
the
current
model
that's
committed,
you
know
you
just
have
routes
on
address
more
or
less
and
I.
Think
in
that
world,
maybe
having
different
kind,
selecting
different
kinds
of
routes
makes
makes
more
sense,
and
you
might
say:
okay,
I
want
to
select
I,
do
want
to
select
an
HTTP
proxy
where
and
a
HTTP
route
and
openshift
in
there
with
the
listener
proposal.
B
Arguably
that
makes
less
sense,
because
then
the
routes
can
be
bound
to
a
hostname
or
a
domain,
and
in
that
case
you
know,
because
you
have
that,
because
you
have
that
binding
up
front
I
think
it
probably
makes
less
sense
because
you'd
probably
say
well
for
this
name.
You
know
at
that
point
you're
more
likely
to
know
that
a
name
is
configured
with
HTTP
route
or
a
name.
It's
a
TCP
route,
and
you
have
you
have
name
binding
to
make
the
routing
more
concrete.
A
I,
keep
on
thinking
back
to
the
elf,
for
example.
Right
now,
yeah
yeah,
we
yeah
we're
at
time,
but
I
just
want
one
last
thing:
I
thinking
of
they
help,
for
example,
of
wanting
to
reference
a
service
directly
and
alternatively,
wanting
to
reference
a
TCP
route
for
traffic
sledding
or
any
other
functionality.
I
could
see
that
being
a
thing
you
might
want
to
do
within
the
same
gateway
or
Gateway
listener,
but
it
seems
like
there's
lots
more
discussion
to
be
had
here.
So
maybe
we
can
follow
up
on
that
issue.