►
From YouTube: Kubernetes SIG Node 20180717
Description
No description was provided for this meeting.
If this is YOUR meeting, an easy way to fix this is to add a description to your video, wherever mtngs.io found it (probably YouTube).
C
So
I'm
David
from
Google
and
today
I'm
going
to
talk
about
my
device
assignment
proposal,
which
I
think
I
linked
in
the
meeting
notes,
but
I
want
to
give
kind
of
an
overview.
So
you
understand
one
can
understand
the
rationale
behind
it
and
hopefully
I
can
get
some
feedback
on
the
use
cases,
as
well
as
the
overall
design.
C
So
currently
there
isn't
a
way.
So
imagine
for
a
second
that
we
have
the
cubelet
and
it's
running
a
number
of
devices
on
the
node,
and
you
want
to
monitor
those
devices
with
a
daemon
set,
that's
specific
to
your
device.
The
problem
today
is
that
there
isn't
a
way
for
such
a
monitoring
daemon
set
to
discover
the
relationship
between
devices
and
containers.
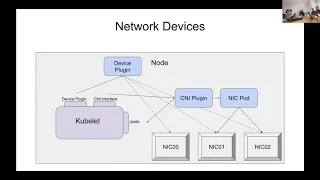
C
The
second
is
that
supporting
network
devices
currently
has
a
coordination
problem,
and
that's
because
the
advertisement
of
devices
needs
to
be
done
by
the
device
plug-in,
because
that's
the
plug-in,
that's
the
place
where
you
can
advertise
devices,
however,
network
devices
need
to
be
set
up
in
the
pods
network
namespace,
and
that
portion
is
done
by
CNI
that
container
network
interface.
So
right
now,
there's
a
coordination
problem,
because
we
have
designed
the
device
plug-in
interface
to
deal
with
with
advertising
devices
and
plumbing
devices
through
that
a
representative
is
mouths.
C
The
device
assignment
is
internal
to
the
cubelet.
Obviously,
then,
only
the
cubelet
has
the
ability
to
the
assigned
devices,
and
this
proposal
opens
the
door
for
other
components,
namely
say
a
custom
scheduler
to
assign
devices
in
the
future
to
meet
some
of
the
more
advanced
use
cases
that
we've
heard
of,
but
that's
not
necessarily
as
concrete
of
the
use
case
as
the
first
and
I'm
going
to
focus
today,
mostly
on
the
first
two
use
cases.
Are
there
any
questions
about
those
okay,
I'll
keep
going.
C
You
would
have
the
Nvidia
resource
name
and
then
it
would
map
to
the
string
device
IDs
that
are
assigned
to
that
container
and
I'll
go
into
how
this
can
be
populated
later,
but
for
the
moment
assume
that
the
cubelet
is
able
to
populate
these
devices
before
it
runs
the
pod,
so
that
what
we
end
up
with
is
a
scheduling
decision
made
by
the
cubelet
prior
to
the
pods
running.
That
is
observable
by
other
kubernetes
components,
and
that
is
permanent,
so
for
device
monitoring
the
way
that
this
proposal
solves.
C
That
is
that
imagine
for
a
second,
we
have
one
pod,
that's
consuming
two
GPUs
and
you
are
also
running
a
monitoring.
Daemon
set.
The
monitoring
daemon
set
needs
to
do
two
things.
It
needs
to
one
discover
which
GPUs
are
actually
in
use
so
that
it
knows
to
collect
and
expose
metrics
for
them,
and
then
it
also
needs
to
know
the
container
and
pod
and
namespace
information
about
the
container,
that's
actually
using
it,
and
so
in
this
case,
the
way
that
the
monitoring
daemon
set
would
do.
C
C
This
should
I
go
over
that
again
or
that
people
understand
sort
of
it.
It
isn't
trying
to
solve
everything
about
network
devices.
We've
encountered
a
number
of
other
challenges
that
we
have
with
network
devices
such
as
device
programming,
but
one
thing
this
does
solve.
Is
it
solves
the
coordination
problem
between
these
two
plugging
interfaces
that
we
have,
and
it
does
that
by
exposing
a
public
relationship
between
devices
and
containers
that
these
two
different
plugins
can
act
on.
F
E
F
C
F
C
Okay
and
then
lastly,
I
just
want
to
dive
a
little
bit
deeper
into
how
device
assignment
actually
works,
just
to
give
people
a
picture
of
how
we
would
implement
this
and
how
it
could
possibly
be
possibly
be
used
as
an
extension
point
in
the
future.
So
if
the
qubit
is
performing
assignment,
which
is
what
we
expect,
the
vast
vast
vast
majority
of
to
be
the
majority
case,
the
cubit
receives
the
pod,
just
as
it
does
today.
C
Without
this
field,
assign
the
cubit
then
decides
which
devices
it's
going
to
assign
to
each
container
and
record
sentence
in
the
pod
spec
and
writes
that
back
to
the
API
server,
and
only
after
that's
written
then
does
the
cubit
actually
run
the
pod
and
expose
the
updated
pods
back
on
the
pods
anyway.
And
then,
if
the,
if
you're
running
a
custom,
scheduler
for
example,
then
you
actually
need
to
assign
both
the
node
and
the
devices
at
the
same
time
as
it
were.
C
And
then
the
cubelet
receives
the
pod
and
runs
it,
and
the
reason
why
you
couldn't,
for
example,
have
one
thing:
scheduling
devices
and
another
thing
assigning
nodes
is
because
you
can't
assign
devices
until
you
know
what
note
it's
on,
but
at
the
same
time,
if
you
assign
a
node
before
you
assign
the
devices,
then
the
cubed
is
just
going
to
run
it
first
and
then
there's
a
race
there.
So
you
would
actually
have
to
have
a
custom
scheduler,
be
both
in
order
for
this
to
work.
G
C
F
Young
people
they've
known
by
the
particularly
something
own
by
itself-
it's
an
old
memory.
It's
not
all
accessories
right,
like
a
class
and
every
saucer
so
currently
in
events
manager
of
the
trike
of
what
the
result
a
circulator
note
and
basically
attach
that
information,
and
we
also
check
part
of
that
information
for
the
user
to
type
on
it
does
have
certain
limitation
and
the
possible
extension.
Today's
recruit
I
have
some
oh,
no
peyote
in
that
structure
to
indicate
whether
it's
another
level.
These
are
always
a
cranberry
sauce.
F
C
Yes,
so
I
guess,
if
I
go
back
to
when
the
qubit
performs
assignment
before
the
cubelet
finishes
admission,
so
between
two
and/or
number.
Two
here
is
actually
part
of
cubelet
admission.
Where
the
qubit
will
first
receive
the
pod,
then
it
will
decide.
Ok,
I'm
going
to
give
it
this
set
of
devices
and
after
that
has
to
perform
an
allocate
call
in
order
for
the
pod
to
finish
admission,
and
only
at
that
point
does
the
key,
but
no
a
that
the
set
of
devices
is
valid
and
be
that
it
knows
how
to
actually
perform
to
plumb.
C
C
It's
not
always
possible
to
make
a
perfect
decision
from
the
node
standpoint,
because
some
devices
may
already
be
consumed
and
those
may
not
necessarily
be
in
the
formation
that
you're
looking
for
them
in,
and
so,
if
you
require
specific
properties
about,
say
the
topology
of
your
devices,
for
example,
that
maybe
they're
linked
together.
If
they're,
GPUs
or
some
other
things,
then
you
don't
you're,
not
okay,
necessarily
with
getting
devices
that
are
spread
out
on
new
anodes
or
or
other
things
like
that
and
using
a
custom.
F
I
feel
like
a
party
on
our
sky
to
do.
We
are
still
at
very
early
stage
that
we
don't
know
how
to
represent
pathology
across
different
CPUs
are
like
devices
and
how
we
can
do
this
very
advanced
by
scheduling,
so
a
single
right
now,
it's
it's
not
the
main
focus
but
I
think
have
imagined
it,
enable
some
experiments
and
done
that
the
community
on
this
space,
but
I
single
they
still
category
to
know
which
model
is
that
these
are
the
model.
F
I
I
C
J
That
again,
so
today,
it's
not
all
fields
in
a
spec
are
updatable,
there's
just
a
few
fields
that
can
be
updated
and
specifically
for
the
node
name,
for
example,
there's
a
special
verb
which
lets
you
a
custom
verb
that
lets.
You
update
the
node
name
in
the
paths
back.
So
if
you're
making
this
power
of
the
spec,
then
there
needs
to
be
on
as
a
special
verb
that
lets
you
update
it
and
then
the
semantics
of
that
verb
have
to
be
fine.
Okay,.
J
Make
it
part
of
the
status
it's
much
more
straightforward,
which
should,
in
theory
like
satisfy
the
monitoring
use
case,
but
if
you're
making
it
part
of
the
spec,
then
probably
or
have
to
like
think
a
little
bit
more
because
for
network
devices
we
might
be
having
odd
level
devices.
In
addition
to
container
level
devices,
I,
don't.
F
K
J
C
I
agree:
I
think
that
the
representation
of
network
devices
is
pod
level
is
useful
in
and
of
itself
and
probably
a
separate
discussion.
I
assume
that
if
we
decided
to,
for
example,
request
these
devices
at
the
pod
level,
but
then
we
would
need
to
also
have
a
similar
field
essentially
listing
the
pod
level
devices
that
are
assigned,
but
I
think
we
can
hopefully
make
those
changes
at
the
same
time
and
I
think
we
can
think
of
that
somewhat
tangential
to
this.
C
C
J
C
Are
all
based
on
the
resource
name
or
the
if
I
go
back
to
the
change,
its
a
map
from
resource
name
to
devices,
and
so
you
could
assign
a
device
with
the
same
but
belonging
to
a
different
resource
to
the
same
pot.
So
I
could
get
device
number
one
from
a
whole
bunch
of
different
resources,
each
which
is
known
by
a
different
plugin.
C
C
I
C
J
C
Right
so
first
I
think
I
should
write
this
up
as
a
cap
and
we
should
come
up
with
a
number
of
very
concrete
use
cases.
My
hope
is
that
I
can
enlist
the
help
of
some
of
the
folks
that
are
building
network
or
building
the
POCs
for
network
device
plugins
to
implement
a
POC
using
this
model
and
demonstrate
that
it
works
and
I
also
hope
that
I
can
enlist
the
help
of
some
of
the
Nvidia
folks
to
do
a
POC
for
an
Nvidia
monitoring.
C
Daemon
set
just
to
demonstrate
that
that
works,
and
then,
if
we
have
consensus
on
the
cap,
I
will
probably
I
guess
then
the
next
part
is
to
go
to
have
this
under
go
API
review,
which
I'm
sure
will
be
loads
of
fun
and
then,
after
that,
I
suppose
we
start
building
it.
I
haven't
decided
if
we
should
do
a
feature,
branch
or
not,
I
think
that
can
be
decided
later.
F
C
F
L
L
B
B
G
F
F
F
Like
currently,
when
this
case
we
won't
be
neighborhood,
we
want
to
allow
people
to
manage
now
crime
crime
related
responses.
They
are
more
easily
and
the
consumed
only
inconsistent
way
that
they
consume
primary
resources
like
CPU
and
memory.
Today
we
mentioned
that
you
know
last
meeting
those
history.
Resources
are
like
non.
Primary
resources,
usually
have
very
different
of
performance
and
the
characteristics
even
for
the
same
type
of
resources
at
CPU,
but
different
types
like,
for
example,
for
GPO.
F
We
have
okay,
a
few
100
there
behind
other
their
performance
and
sizes
are
very
different
and
the
administrators
all
belong
to
different
ACOTA
are
those
are
different
types
of
gpo's,
and
currently
we
don't
have
a
way
to
allow
people
to
essentially
amount
or
quote
out
to
different
of
GPO
types
and
the
way
we've
had
other
errors
in
like
high
performance,
Naik's
and
also
like
pga.
They
also
have
very
similar
requirements,
for
example
fpga.
F
F
They
choose
to
manager,
gluco
war
resources
and
the
like
a
temple,
different
attacks,
the
GTOs
I'd
time
codes
and
the
mall
GPO
devices.
I
introduced
multiple
people,
GPS
devices
I'd
introduced
it's
not
a
flexible
or
like
snot,
or
very
easy
to
manages
the
article
in
terms
of
GPUs
and
grata,
but
illustrators
actually
want
to
group
them
in
small
categories
in
smaller
numbers
for
third
grade
and
that
they
can
hike
to
the
underlying
operation
details
from
their
auntie
Otis,
which
also
has
not
called
vanity
on
the
workload
level,
and
we
also
want
to
belong.
F
Workload
portability
across
different
environments,
whether
it's
on
crime
or
whether
it's
across
different
providers,
if
similar
concepts,
are
similar
motivation
at
the
storage
class,
where
we
allow
people
to
had
the
antlion
configuration
details
that
match
the
unmanly
hardware
confirmation,
but
the
workload
that
itself
can
just
use
the
pod
for
ease
of
name,
to
request
our
results
and
also
we
want
to
enable
device.
Vendors
are
empowered
them
to
to
export
their
missiles
and
the
dirt
one
feature
to
our
communities.
F
Currently,
they
don't
have
a
good
way
to
allow
people
to
ispotter,
but
even
the
top
tato
device,
and
also
to
make
a
schedule,
a
decision
based
on
the
different
countries
and
also
we
don't
have
way
to
allow
people
to
to
discover
the
project
and
use
the
italy
to
affect
their
workload.
Obama's
allowed.
F
And
another
use
case
aids
are
like.
Oh,
we
have
seen
some
requirement
tool
to
be
able
to
request
a
group
or
devices
like,
for
example,
I've
seen.
People
want
to
be
able
to
say,
I
want
a
GPU
and
also
a
CPU
on
the
same
Numa,
and
also
maybe
a
bit
some
amount
of
memory
together
and
currently
we
do
have
a
true
to
this
price.
This
is
scheduling
requirements.
F
F
We
already
have
seen
some
like
no
absolute,
no
upstream
solutions,
developer,
documentation,
bad
people,
and
we
already
have
seen
some
documentation
in
the
community
in
this
space,
and
we
also
want
to
allow
crosstalk
return
to
configure
and
manage
different
kinds
of
non-native.
Computers
are
sitting
in
black
support,
also
multiple
ways
and.
F
And
also,
we
want
to
provide
a
unified
interface
to
integrate
computer
resources
across
the
various
system.
Components
like
Kota,
internally,
suspect
and
also
have
seen
maker
plus
the
other
energy,
also
want
a
consistent
way
to
evaluate
whether
no
status
by
a
powder
resource
requirement.
You
know
consistent
way
as
a
scheduler
evaluate
this.
F
And
the
in
the
longer
term,
we
want
to
support
and
not
novel
resource,
as
well
as
a
Class
A
level
results
I'm.
Currently
we
don't
have
a
good
way
to
differentiate
national
level.
It's
also
was
known
that
worries
us
I,
think
in
the
past
couple
realization,
where
I
did
some
the
walk
around
on
a
plate
and
also
in
class
the
autoscaler.
Those
solutions
are
not
very
ideal
and
we
already
have
seen
some
requests
that
way.
These
are
some
longer-term
solution.
F
F
There
are
several
reasons.
So,
of
course,
the
reason
is
mostly
for
the
scaling
concern
because
they
evaluating
the
park,
like
a
special
label
matching
and
evaluate
such
people
matching
for
every
pod
and
for
our
in
order
to
result
is
very
expensive
and
the
the
reason
we
want
to
introduce
the
result
has
about
the
reason
why
we
want
to
introduce
a
resource
classes
so
that
the
scheduler
can
catch.
The
matching
matching
information
from
mrs.
class
to
computers,
us
and
the
the
fetching
updater
it's
done
when
there
are
new
nodes
are
introduced.
F
All
the
resource
class
modifications
which
are
respected
to
be
much
less
Ingram
printer
than
like
evaluating
every
powder,
whether
accessor
I
Reno,
is
a
silicon
resource
available.
So
that's
the
founder
main
reason
and
they're
not
originated
with
a
were
allowing
people
to
directly
specify
the
metadata
requirements
in
the
containers.
Back,
although
its
provide
some
of
the
convenience,
it
could
also
hurt
the
workload
or
anything
in
the
longer
term
and
I
think
that's
also.
F
F
So
it's
kinda
hard
to
unify
the
two
so
at
this
type
of
which
we
don't
plan
to
unify
the
two
and
also
in
the
initial
phase.
Maybe
another
address
results
over
commitment.
Actually,
no
mrs.
the
requirements
are
make
official
results,
although
our
design
does
leave
room
to
support
them
in
the
future
and
I
think
we
have
talked
about
the
future
extensions.
We
may
consider
to
support
them.
It's
Jack,
not
our
focus
in
the
initial
design.
F
A
simple
way:
I
will
mention
the
major
components
either
not
19
and
the
from
next
meeting.
They
also
updated
that
we
send
out
to
to
make
sure
it's
up
to
date
and
reflect
our
current
design,
and
basically
we
propose
we
introduce
a
business
class
like
the
object
and
that
we
want
to
start
doing
the
very
basic
spike.
It's
basically
just
a
specified
in
the
already
soft
name,
but
the
example
here
when
you
say,
like
a
big
adult
conversation
GPU.
This
has
been
the
the
RSS
name,
videos
about
GPO
currently,
and
we
can
see
it.
F
Doesn't
it's
a
very
high
level.
It
doesn't
allow
people
to
specify
what
types
of
GPIOs
I
mean
metadata
like
the
amount
of
jakku
memory
are
like
the
cycles
of
the
GPU,
but
the
metadata
requirement
says
that
the
the
key
field
that
we
want
to
allow
people
to
to
specify
any
medical
data
constraint.
It
comes
me
either.
Gpo
type
of
all,
like
a
the
zoom,
are
like
a
GPU
memory.
F
And
the
data
we
discussed
some
of
the
fields
we
may
consider
to
include
later,
like,
for
example,
we
can
introduce
a
scope,
failed
to
declare
where
there
is
no
level
results.
Are
it's
crafted
level
results
and
we
can
provide
some
auto
provisioning
can
take
title.
Perhaps
the
results
out
of
provisioning
and
we
may
also
consider
to
idols
and
resource
requests.
Crime
occurs.
F
So
so,
I
think
away
from
the
comments
in
the
P
are
a
lot
of
questions
or
related
to
the
use
cases
and
also
codes
and
non
goes
yeah.
So
we
would
like
to
hear
some
of
the
feedbacks
to
hear
feedback
from
folks
here.
Like
do
you
think
we
have
a
good
balance
and
on
the
goes
and
non
goes,
and
also
the
the
user
stories
part.
A
One
question
too:
jarring
is
the
first
use
case,
which
is
saying
the
cluster
has
a
different
type
of
GPU,
which
is
a
heterogeneous
set
up.
So
the
question:
is
this
a
common
use
case
or
oh,
maybe
it's
easier
for
for
administrator
to
manage
that
make
sure
they
are
using
the
same
type
of
chips
you
in
the
same
cluster.
A
F
F
F
Also
saw
some
feedback
from
highway
from
eBay.
He
managed
like
eBay
last
I
can
imagine
that
he
had
many
different
types
of
GTOs
and
I
traditionally
expressed
the
like
the
use
case
and
I
go.
He
also
want
to
group
a
different
types
of
cheap
Union
to
pack
different
type
queries
like
smaller
number
of
categories
so
that
he
doesn't.
He
doesn't
need
to
like
it
out
the
workload
developer.
How
a
neogeo
available!
Please
modify
your
post
I
peruse.
The
new
package
of
you.
A
M
When
we
talk
to
customers
about
the
concepts
that
are
that
Jen
just
laid
out
a
few
minutes
ago,
most
of
them
see
it
as
very
logical
and
and
mostly
a
requirement
for
their
particular
environments
and
without
it
essentially
assuming
homogeneity
is
not
an
option
for
for
a
good,
a
good
amount
of
environments.
I
would
say
some
some
are
more
flexible
than
others,
particularly
when
they
look
up.
Look
to
you
like
bring
kubernetes
in
to
a
Greenfield
environment
and
there's
more
flexibility.
M
But
when
you
get
a
year
or
two
down
the
line,
you
start
seeing
these
use
cases
pop
up.
When
you
talk
with
folks
from
established
industries.
This
is
you
know.
Almost
100
percent
of
their
environments
need
something
that
allows
for
much
more
granular,
polished,
apology,
awareness
or
hardware
awareness.
Is
that
what
you're
looking
to
hear?
Yes,.
K
M
A
By
the
way,
I
also
can
share
a
little
bit.
I
also
talked
to
the
user
and
one
of
their
company
or
the
user
lists.
They
want
to
start
with
these
GPU
capability,
I
think
because
they
are
early
so
they're
looking
for
make
make
sure
every
cluster
has
same
GPU
time
so
I
agree,
maybe
maybe
one
two
years
down
the
road.
The
difference
may
got
this
situation
and
have
to
manage
different
coverage.
If
you
know
same
cluster.
F
F
Yeah
I
think
like
currently
that
may
be
still
doable,
but
if
we
think
about
like
in
the
town
home,
when
you
want
to
introduce
any
old
GPO
type-
and
you
just
need
to
create
a
new
class
that
doesn't
seem
to
be
quite
feasible,
equates
into
lecture.
In
this
case.
Wow
or
the
extended
resources.
Resources
will
be
introduced
in
the
future,
and
it's
that
may
not
fit
about
FPGA.
At
least.
B
F
So
I
think
we
can
go
to
the
schedule,
a
attention
so
pokey
they
updated
the
the
type
to
reflect
the
current
pure
art
design
model
and
basically,
the
theory
proposed
to
I'd
need
a
penis
Bank
to
to
include
the
Bene
information
from
the
subscribe,
quicker
results.
It
require
to
advocate
a
resource
list
and
basically
it
well.
We
also
use
map
here,
but
we
may
want
to
change
it
to
a
structure
and
we,
but
the
basically
it
makes
from
the
research
class
name
to
a
located
in
the
southeast,
and
here
are
the
K
theories.
F
At
least
there
is
computers
of
name
as
count,
so
that
means
basically
on
the
scheduler.
We
will
cache
the
information.
The
matching
information
from
results
on
us
through
computer
resource
that
means
scheduler
need
to
update,
is
cached
information.
The
new
nodes
I
did
but
that
facility
to
match
the
computers
as
I,
Spotify
and
you'll
note
throughout
the
in
system
resource
class,
and
also
a
need
to
update
the
hygiene
information
there.
Any
such
crisis
mode
I
did
LED
tape.
N
That's
fine
but
the
biggest
problem,
I
guess
in
the
at
least
in
the
previous
design
I
just
this
is
a
new
part,
but
in
the
previous
design,
I
guess
you
were
proposing
to
support
union
of
some
resources,
racing
this
union
of
some
compute
resources
and
expose
them
as
a
new
computer
source
if
I
not
mistaken.
An
example
was,
for
example,
a
few
GPU,
a
few
GPUs
connected
by
an
interval
link
and
exposing
all
of
those
as
a
single
unit,
and
that
was
causing.
N
G
F
So
somehow
the
group,
precisely
it's
not
in
the
initial
phase
of
the
design,
although
I
think
we
can
handle
that
in
a
similar
way,
so
basically
in
a
similar
way,
as
we
support
multiple
machine.
So
basically
a
computer
result
can
merge.
Multiple
results,
classes
and
all
Profoto
is
like
a
scheduler
tastes
like
a
computer.
Salsa
is
a
standard
to
satisfy
a
resource
class
request.
It
will
include,
it
will
increase
the.
F
N
An
issue
in
my
opinion
because
it
becomes
hard
to
create
like
Maps
from
one
side
to
the
other
one
too
many
we
can
handle
one
to
one,
of
course,
is
easy
to
handle,
but
many
many
becomes
a
little
harder
to
handle.
What's
your
take
on
that
I
mean
we
probably
need
to
have
a
lot
of
maps,
especially
if
the
number
of
computers,
large.
F
B
F
B
B
F
B
F
Now
how
you
can
see
so
we
will
waste
a
powder
than
to
mine
when
too
many
might
be
from
computer
to
research
class,
but
I.
Think
Bobby's
question
is
whether
we
want
to
support
many
to
mind
emerging
from
computers
to
research
class
and
that
I
think
that's
not
our
current
focus
and
we
definitely
need
some
performance.
The
data
to
make
the
decision,
whether
we
want
to
support
that
model
or
not
in
the
future.
Okay,.
F
N
One
quick
thing
you
know:
I
I've
already
told
you
this
but
metaphor
for
the
information
of
other
people
in
the
room.
You
know.
One
thing
today,
for
example,
got
informed
off
in
last.
Q.
Con
is
that
people
are
asking
me
how
why
scheduler
is
slow
when
they
have
like
thousands
of
resources
in
a
cluster
and
I
told
them
what
what
houses
of
resources?
We
don't
have
that
many
research
types
in
the
world.
N
How
could
you
have
like
thousands
of
research
types
and
they
say
that,
for
example,
they
create
IP
ranges
and
expose
those
IP
ranges
as
extended
resources.
When
you
give
people
the
ability
to
define
new
things,
they
could
become
creative
in
a
way,
and
this
this
is
also
having
the
same
problem.
In
my
opinion,
yeah.
F
Definitely
agree
and
I
see
like
a
witness
Apollo
his
tendon
results.
We
are
already
like
allow
people
to
die
and
we'll
hook
like
it's
the
release.
Walker
we
had
Eastern
killed
people,
some
warning
when
they
critically
subscribe,
when
the
crane
from
any
resource
class
is
out
when
they
create
a
resource
classes
that
have
much
too
many
computers,
awesome,
weather,
yeah.
Thankfully,
I
think
about
you,
something
we
need
to
take
a
special
edition.
Yeah,
sorry.