►
From YouTube: Kubernetes SIG Node 20180918
Description
No description was provided for this meeting.
If this is YOUR meeting, an easy way to fix this is to add a description to your video, wherever mtngs.io found it (probably YouTube).
A
B
A
A
But
I
guess
what
Louie's
skinny
I
just
wanted.
We
have
to
get
the
release
notes
out
for
112.
I
took
a
stab
at
writing
them
this
morning.
For
sake,
note
do
not
believe
I
missed
anything
but
basically
discussed
that
the
podshare
process
namespace
feature
graduated
from
alpha
to
beta
the
runtime
class.
Alpha
feature
was
introduced
to
support
multiple
runtime
options
per
node.
A
The
custom
CFS
quota
period
was
introduced
as
an
alpha
feature
to
allow
you
to
change
the
CFS
quite
a
period
on
the
node
which
helped
those
who
would
complain
about
latency,
sensitive
workloads
that
still
wanted
to
use
quota,
and
then,
aside
from
that,
it
seems
like
we
mostly
just
pushed
through
a
number
of
bug,
fixes
and
started
airing
out
more
designed
for
future
features.
But
I
just
want
to
make
sure
from
the
group
here
that
I
did
not
miss
any
particular
item
that
they
want
to
call
out
in
the
release
notes.
A
C
C
So
it's
the
same
directory
higher
higher
accurate,
so
the
manager
itself
is
a
pod
admit
handler.
So
it's
consulted
every
time
a
pod
comes
into
cubelet.
It
contains
a
store.
This
is
where
new
Mahane
providers
can
query
new
manager
to
get
back.
A
finish
for
a
particular
pod
in
container.
We
then
have
a
list
of
hin
providers,
which
are
the
the
components
that
tell
Numa
manager
where
to
align
resources.
C
A
new
manager
can
use
what
they
send
back
to
create
an
alignment
for
a
pardon
container
and
then
just
a
remove
pod
to
obviously
remove
pod
from
from
the
store.
So
we
have
a
bit
mask
for
storing
the
numeral
einman.
So
if
I
go
down
here,
it's
easier
to
show
so
a
bit
mask
for
a
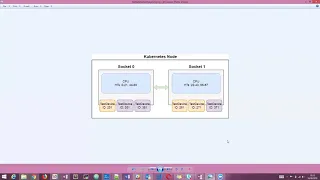
jewel
socket
system
could
look
something
like
this.
So
zero
one
would
donate
the
CPU
manager
I
can
satisfy
the
request
on
socket
one
you
can
satisfy
the
request
in
socket.
Zero
and
I
can
satisfy
the
request
across
sockets.
C
So
they
must.
They
take
in
a
pod
container
and
return
a
mask
of
like
below
and
a
boolean
as
to
whether
there
is
alignment
or
not.
So
this
is
kind
of
the
overall
diagram
of
the
implementation.
So
we
have
two
Hinn
providers
at
the
moment:
CPU
manager
and
device
manager.
So
they
both
implement
that
get
new.
My
hints
method
and
then
new
manager
will
be
called
when
the
admit
handlers
are
called.
C
It
will
ask
each
of
the
hint
providers
to
provide
back
the
the
affinity
for
that
particular
container
and
the
new
manager
will
do
bitwise
end
of
the
masks
that
are
returned
and
or
the
first
positive
result.
So,
as
you
can
see
in
in
this
scenario,
we
did
a
0
1,
1,
0,
1,
1
and
1
0,
so
a
new
manager
with
a
bitwise
and
0
1,
1
0,
1
1,
so
1
0
was
the
first
positive
result.
So
we
restored
that
so
just
a
quick
overview
of
the
flow.
C
So
when
this
is
when
new
manager
is
called
our
window,
managers
added
as
a
hint
I
didn't
miss
handler.
So
during
cubelets
initialization,
it
stores
a
bunch
of
emit
handlers,
and
so
new
manager
is
added
as
one
of
those
there
and
then
for
the
actual
creation
of
a
new
manager
and
the
addition
of
hint
providers
when
the
container
manager
is
created,
a
new
manager
is
also
created
and
then,
when
container
manager
creates
the
hint
providers.
So
in
this
case
device
manager
in
CPU
manager,
it
adds
those
as
hint
providers
to
new
manager.
C
So
new
manager
knows
who
to
contact
when
a
pod
comes
in
and
asks
for
new
alignment,
and
then
this
is
when
the
actual
alignment
of
the
part
is
done.
So
when
cannon
read,
pod
is
called
new
manager,
which
is
animate
handler
is
called.
It
calls
getting
a
my
hints
function
of
each
of
the
hint
providers
it's
aware
of,
and
they
send
back
the
mask
and
it
can
then
store
the
result.
C
So
that's
pretty
much
the
flow
and
then,
when
the
end
providers
actually
make
the
allocation
decisions,
they
query
back
to
new
manager
to
ask
what
is
the
the
best
alignment
for
this
container
and
as
their
hints,
the
commands
can
decide
really
what
to
do.
With
that
information,
so
that's
pretty
much
what
I'll
show
in
the
demo
is
there
any
questions
before
I
go
into
the
demo.
B
I
just
wanted
to
add
one
kind
of
background
note
related
to
kind
of
the
history
behind
this.
This
was
kind
of
a
feature
that
was
not
a
feature
about
a
behavior
that
was
punted
on
kind
of
at
the
beginning
of
or
I
guess
the
end
of
last
year,
because
the
CPU
manager
and
the
device
manager
were
still
you
know.
Basically,
they
were
designed
and
implemented
in
parallel,
and
so
this
kind
of
next
step
of
making
them
coherent
was
always
kind
of
understood
as
something
that
needed
to
happen.
B
C
We're
proposing
an
addition
to
the
device
plug-in
API,
so
the
device
plugins
can
send
back
socket
information
in
some
form
so
that
the
device
manager
can
store
that
and
this
use
it
to
create
the
the
Numa
hints.
So
what
I've
done
in
the
demo
is
I
have
actually
added
a
socket
field
to
the
device
plug-in
API
and
but
that's
a
demo
could
be
be
changed
there,
but
I
send
back
an
integer
value
for
socket,
along
with
the
device
ID
in
the
health.
C
So
the
in
this
scenario,
device
251
will
descend
back
Sokka
0
with
the
ID
and
it's
health.
That's
just
the
overall
system
that
this
demo
learning
on.
So
if
we
go
here
hopefully
that
is
big
enough.
Writing
so
I've
actually
have
the
two
device
plugins
running
so
test
device,
but
one
and
test
my
spoken
to
and
I
can
show
you
the
logs
for
each
so
it'll
just
show
the
devices
they
have
sent
back.
So
here
we
can
see.
So
this
is
two
five
one,
two
six
one
and
two
seven
one
as
in
the
diagram.
C
So
two
five
one
is
on
socket
zero,
two
six
one
and
two
seven
one
around
socket
one
and
that's
how
I've
updated
the
proto
file
for
device
plugins,
so
I've
added
this
additional
field
and
then
I
have
the
second
device
plug
in.
So
that's
three
five
one:
three
six
one
and
three:
seven
one
and
we've
two
and
socket
zero
and
one
and
socket
one.
So
what
I'm
gonna
do
next
is
I.
Have
some
pods.
C
So
this
first
part,
so
what
I've
done
in
this
demo
is
this
to
kind
of
correlate
with
for
how
CPU
manager
works,
new
manager
will
only
align
guaranteed
pods,
because
CPU
manager
would
only
align
guaranteed
pods
that
are
making
integral
CPU
requests.
So,
in
order
to
get
the
alignment
obviously
need
to
use
guaranteed
pods.
C
C
C
So
we
have
planned
for
possibly
two
policies
strict
and
preferred
so
in
this
demo.
I
actually
have
preferred
on
so
it
will
still
admit
the
pod
and
give
you
the
resources
across
sockets
if
it
can't
align
them,
but
it
will
try
and
then
the
strict
one
which
I
also
did
an
implementation
of
it,
fails
the
pod
and
returns
an
uma
finish
the
error.
So
it's
kind
of
it
would
be
probably
a
cubed
flag
to
decide
whether
you
want
stricter
preferred
on.
C
C
And
so
what
I
did
in
the
device
plug-in
just
to
easily
show
what
devices
are
allocated
as
I
just
populated
an
environment
variable
with
the
ID
in
the
socket
that
was
given
to
the
the
container?
So
if
we
just
go
into
the
pod,
we'll
be
able
to
see
what
devices
they
gotta
wash.
Of
course
it
got
so
in
here,
and
so
we
got
two
seven
one
and
three
seven
one
which
are
both
on
socket
one
so
align
those
devices.
And
then,
if
I
check
products
of
status,
I'll
see
what
cores
I
was
given.
C
C
Together
and
then
just
to
show
that
it
will
still
admit
the
Parden
still
are
on,
but
it
will
basically
not
align
the
resources
if
I
can't
have
another
pod,
which
is
no
affinity
pod.
So
if
we
go
back
to
the
diagram,
we
got
aligned
on
socket
one,
and
so
we
got
this
test,
one
of
these
tests
Isis
and
one
of
these
days
this
what
this
device
in
this
device.
So
if
I
ask
for
now.
C
C
So,
oh
and
I
was
actually
able
to
give
me
the
three
on
socket
zero,
so
I
always
had
two
left
on
on
socket
0
for
the
second
device
plugin,
and
so
it
did
work
in
this
case.
So
I
got
the
same
as
well:
I
got
the
three
devices
aligned
and
I
got
the
cores
aligned
as
well,
but
in
the
case
that
I
couldn't
do
it,
it
would
still
run.
It
would
just
give
me
the
devices
across
sockets
and
in
this
preferred
policy
and
that's
pretty
much
the
extent
of
the
demo.
D
C
D
D
Another
question
so
for
the
resource
name,
I
noticed
that
you
actually
put
some
things:
some
special
situations
in
the
resource
name.
But
do
you
still
use
the
standardized
like
own
resource
name
like
a
typical
ebay
inspected,
the
the
resource
name?
It's
just
something
under
specified,
so,
for
example,
for
GPO
the
immediate
GPS
Nvidia
comes
GPU,
but
that
results
can
be
I.
Spotted
I
know
that
mr.
party
Numa
army
now
so
polymer,
but
it's
the
same
resource
name.
You
still
expect
that
to
be
true.
D
A
Why
don't
we
take
their
node
with
the
corresponding
policy?
Then
your
pod
would
have
to
explicitly
tolerate
that
note.
That
said,
I
provide
the
higher
guarantee
or
rector
note
to
it,
like
I
think
the
labels
that
the
resource
name
being
the
same
is
fine
I
mean,
and
you
can
quote
it
separately
with
the
viciously.
This
proposal
I
think.
B
B
I'm,
not
sure
I
mean
that's,
that's
not
part
of
the
proposal.
I
guess
you
could
make
the
same
argument
for
like
the
static
CPU
manager
right
now
we
don't
export
any
labels
or
paints
or
anything
like
that
when
you
change
the
CPU
manager
policy
as
an
operator,
you
might
want
that,
but
it's
kind
of
I
think
out
of
the
scope
that
we
considered
for
this.
This
part.
D
C
Originally
back
way
back
in
summer
created
a
different
POC
for
for
Numa
and
I
did
include
huge
pages
there,
and
one
of
the
I
ran
into
that
see.
Advisor
advertises
them
entirely
for
a
node
as
opposed
to
per
socket.
So
a
change
is
required
there
and
then
there
there
was
with
device
and
CPU
manager.
There
is
managers,
so
there
there
is
a
known
place
to
contact
I.
Guess
there
isn't
the
same
for
huge
pages,
but
I
was
able
in
that
original
POC
to
align
them,
but
it
just.
It
was
a
couple
more
steps.
A
D
C
Yeah
for
sure-
and
we
have
one
use
case-
is
DP
DK
workloads,
so
if
they're
using
an
ester,
I
be
capable,
Nick
and
they're
most
likely
be
using
the
SRA
V
device
plug
in
and
then
they
need
pinned
cores
so
they'll
definitely
benefit
from
new
manager.
Aligning
the
cores
with
the
DSRV
Nick
are
basically
anything
that
requires
device
locality
with
the
the
CPU
will
benefit
from
that.
But
that's
a
major.
We
have
mmm-hmm.
D
A
John
I
think
he
was
just
other
pods
that
are
maybe
not
best
effort,
but
definitely
probably
first
of
all
that
are
providing
cluster
services
themselves
so
that
your
the
ends,
probably
still
beyond
that
I
think
as
a
pop.
Your
monitoring
component
was
still
probably
there
running
as
a
pug,
so
I
would
still
think
you'd
have
other
components
running
on
that
cue
boat
that
are
not
guaranteed.
We've.
B
Seen
use
cases
where,
for
example,
you
may
have
a
Packard
packet
forwarding
application
where
you
have
multiple
containers
in
the
pod,
where
one
is
the
guaranteed
wait-and-see,
sensitive
one
that
you
want
max
performance
out
of,
but
you
may
bundle
the
control
plane
as
a
separate
container
in
the
same
pod.
So
you
have
shared
fate.
Sure
scheduling,
but
you
know
different
kind
of
resource
handling
on
the
node.
D
A
It's
basically
integral
cores
in
a
pod.
That's
an
errant
heed
caused
class,
so
if
your
container
container
can
still
be
in
a
guaranteed
cause
class
and
that
make
integral
call
requests
when
we
start
your
pod
can
be-
or
you
could
have
multiple
containers
in
a
pod
where
one
makes
a
fractional
request
and
the
other
one
makes
an
integral
one
and
I
believe
Connor,
the
integral
would
still
have
gotten
the
CPU
manager
to
get
picked
up,
and
it
can
still
be
in
the
guaranteed
cost
here.
E
E
Let's
say
special
specializations,
and
these
are
basically
at
the
DPD
k
using
theater
playing
records,
but
the
the
same
application
has
also
that
of
OAM
functionality
related
to
add
no
handing
logging
integrating
to
EMS
system,
pushing,
alarms
and
and
performance
contests.
So
usually,
those
kind
of
parts
of
the
application
are
pretty
happy
with
whatever
shed
CPU
sets.
They
are
getting,
but
the
st
part
of
the
same
application.
D
C
A
D
A
A
A
And
then,
as
we
look
to
cube,
113
planning
I
think
we
had
been
trying
to
decide
like
what
would
be
the
right
incremental
thing
to
tackle
next,
where
we
haven't
done
much
in
the
space
during
112
per
se.
But
this
is
to
me
it
looks
like
a
good.
Can
it
for
us
looking
to
tackle
in
113,
so
I
very
much
appreciate
you
sharing
a
POC
in
the
work
from
Intel.
Thank.
C
A
F
B
F
Without
without
that,
we
can't
actually
really
turn
this
on
in
Prague.
Even
the
Newman
manager
like
it
will
have
certain
use
cases
for
IO,
particularly
like
InfiniBand
related
io
and
some
Network
IO
for
Silv.
Of
course,
I
would
ask
Levin
T
the
same
question.
Would
you
turn
on
the
NEMA
manager
without
the
ability
to
partition
the
system,
as
you're
probably
doing.
E
E
Definitely
Revere
turned
it
on,
but
I
have
to
say
that
our
infrastructure,
on
which
I
via
turn
it
on
a
probably
separate
still
these
workloads
on
the
node
level.
Because
of
this
was
just
just
mentioned,
be
probably
my
infrastructure.
We
have
still
some
kind
of
proprietary,
let's
say
hex,
which
will
do
some
CPU
partitioning
outside
of
kubernetes.
So
yes,
and
no
that's
for
the
same
question,
I
mean.
A
So
we
haven't
really
done
a
deed.
That
I
feel
like
only
nice
little
CPU
discussion
in
a
while
and
I'm,
not
even
sure
as
I
think
through
this.
If
we
treat
it
system
reserved
or
cube
reserved
as
a
guaranteed
quads
entity
itself
and
then
set
and
forced
node
allocatable
to
more
than
just
pods,
but
set
it
to
system
or
cube
reserved
as
well.
In
theory,
Jeremy
couldn't
the
key,
but
just
set
the
cpu
isolation
appropriately.
For
that
entire
see
groups
of
hierarchy
without
issue
like
would
you
even
need
ISIL
CPU?
We.
F
Don't
necessarily
need
ISIL
CPUs.
We
also
have
a
system,
the
implementation
that
works
well,
I
can't
say
anyone's
ever
tested.
What
you
just
described
so
I
would
just
say
that
a
ton
of
work
went
into
validating
the
two
settings
that
we
support.
Right
now
never
I
have
supports.
We
would
have
to
just
validate
waiting
like
a
prototype,
yeah.
A
But
just
in
theory
to
me,
like
the
system,
see
group
or
the
Q
bruiser
C
group
is
just
another
pod
bounding
box.
You
know
just
or
similar
to
any
other
bounding
box
and
I
think
it's
worth
talking
through
or
seeing
through
if
that
broke
down
anywhere,
just
so
that
people
don't
have
to
manage
things
outside
of
the
keyboard,
even.
E
These
these
thresholds
explicitly,
instead
of
just
trying
to
figure
it
out
and
always
assume
that
that
these
cube
reserved
and
system
reserved,
let's
say,
resources,
especially
specifically
when
we,
when
it
comes
to
the
CPU,
are
always
coming
like
from
the
from
the
low
number
CPUs.
So
I
think
that
that's
what's
hurting
but
I.
Think,
like
everyone,
is
very
open
to
to
have
any
kind
of
like
optionality
or
or
control
dysfunctionality
in
anywhere.
My
savings
included,
even
though
I
really
tight
order
kept
like
respecting
guys
and
CPUs
I.
E
A
I'm
saying
early
on
IIIi,
don't
know
how
many
cube
hosts
even
actually
put
the
cubelet
and
a
separate
seeker.
Park
resize
from
system
slice
when
you're
running
on
a
system,
D
host,
so
I,
think
probably
99.99999%
of
the
communities
host
in
the
world
are
all
running
cubelet
underneath
system
slice,
and
so,
if
you
treated
system
reserve,
which
mapped
to
system
slice
on
that
topology
as
a
integral
CPU
request
and
made
the
Qiblah
on
startup
assign
everything
under
system
slice
CPU.
A
In
the
same
way,
we
would
have
done
for
any
other
container
that
was
emitted,
that
the
qubit
could
take
ownership
of
the
problem
entirely
and
we
wouldn't
have
to
do
any
configuration
to
the
host
prior
to
just
starting
the
cubelet
and
that
that's
don't
know
where
that
breaks
down.
But
that
seems
to
me
like
break.
F
Down
own
kernel
thread
so
I'm
pretty
sure,
that's
that's
part
of
the
problem,
but
let's
definitely
test
it
because
it
might
guess
a
big
win.
I
agree
in
terms
of
like
the
implementation
details
are
not
really
important,
but
in
the
past
that
kernel
threads
were
the
problem
for
user
space.
Tuning
yeah.
A
I
guess:
yeah
I
don't
like
to
design
right
now
and
so
I
all
I'm
saying
is
I
prefer.
If
we
do
solutions
that
don't
require
you
to
do
much
house
configuration,
have
the
qubit
just
do
the
right
thing
so
for
the
sake
of
following
specimens,
I
guess
at
least
well
I
think
we
should
get
your
your
kept
reviewed
and
and
when
Don
and
I
go
through,
they
want
13
planning.
This
seems
like
a
good.
A
G
Is
Robert
Krulwich,
just
real
quick
I,
updated
the
ephemeral
storage
quota,
PR
and
the
accompanying
cap?
So
if,
if
anybody
else
wants
to
look
at
it,
I
also
appreciate
having
the
code
looked
at
also
I'm
not
going
to
be
here
between
from
Thursday
through
the
following
Friday
and
then
returning
the
being
of
October.
So
don't
expect
any
response
after
tomorrow.
That's
it.