►
From YouTube: Kubernetes SIG Node 20211102
Description
Meeting Agenda:
https://docs.google.com/document/d/1j3vrG6BgE0hUDs2e-1ZUegKN4W4Adb1B6oJ6j-4kyPU
A
Hey
everyone
and
welcome
to
today's
edition
of
sig
node.
It
is
tuesday
november
2nd
2021.
I
can't
believe
it's
november.
We've
got
a
short
agenda
for
today
in
some
part,
probably
due
to
the
fact
that
the
file
went
read
only
we're
very
sorry
for
that.
The
google
account
that
it
was
stored
on
ran
out
of
disk
space.
Briefly,
so
it's
editable
now
we
figured
it
out
no
cause
for
alarm.
A
Sergey
could
not
make
it
to
the
meeting
today.
So
we
don't
have
the
table
of
what's
going
on
with
various
pull
requests,
but
I
did
take
a
look
at
the
total
number
of
active
pull
requests
and
we're
up
a
few.
I
think
that
people
have
been
somewhat
resource
constrained,
but
I
know
from
last
meeting's
review.
It
looked
like
we
had
done
pretty
well
in
terms
of
our
sort
of
soft
code
freeze
and
making
sure
that
beta
stuff
got
merged,
so
that
was
good.
A
I
have
one
announcement
before
we
jump
into
the
agenda,
which
is
that
code
freeze
is
in
two
weeks
from
now.
It's
sneaking
up
on
us,
so
we
probably
wanna
make
sure
that
alpha
stuff
is
getting
reviewed
and
that
we're
getting
feedback
in
and
whatnot.
So
I'm
certainly
going
to
try
to
prioritize
some
time
on
that
this
week,
other
reviewers,
a
heads
up
to
you
as
well
and
for
authors,
please
make
sure
that
your
thing
is
reviewable.
B
A
Yeah,
that's
a
great
announcement,
so
if
you
haven't
voted
yet
in
the
election
this
year,
they
are
not
sending
out
individual
emails,
you
have
to
go
and
actually
like
click
on
the
link
which
was
sent
to
the
the
dev
mailing
list,
so
I'll
add
a
link
to
that
to
the
agenda.
Thanks
for
the
reminder,
mark.
A
A
C
Cool
because
my
audio
was
not
working
a
few
minutes
ago,
great
so
yeah,
we
opened
a
cap
long
ago
and
we
received
a
lot
of
proposals,
a
lot
of
ideas
and
yeah.
I
created
a
new
proposal
that
incorporated
almost
all
the
feedback
from
the
previous
discussions,
and
I
created
some
slides
that
I
couldn't
add
to
the
agenda
because
it
was
read-only,
but
I
can
maybe
share
share
the
screen
with
you.
I'm
sure,
like
you,
have
like
three
four
slides
to
show
the
high
level
idea
of
the
proposal.
C
A
C
Great
so,
as
I
was
saying,
we
started
a
cap
long
ago
like
about
a
year
ago,
and
there
was
a
lot
of
very
valuable
discussions
and
we
created
a
new
proposal
that
mentioned
in
a
github
comment
in
that
vr.
That
incorporates
all
this
feedback,
and
I
wanted
to
share
this
in
the
next
slides
and
coordinate.
What
are
the
next
steps
to
iterate
this
idea
or
to
agree
or
see
how
to
continue
with
this?
C
C
Me
whenever
you
want,
but
basically
the
idea
is
adding
two
two
two
fields
to
the
bot
spec
one
one
field
is
all
the
names
are
preliminary,
of
course,
but
one
field
would
be
about
using
new
certain
spaces,
yes
or
no
like
a
bull
and
another
field
will
be
to
improve
but
isolation,
and
that
this
will
make
sense
in
the
next
slides
on.
Why
why
we
have
these
two
fields?
C
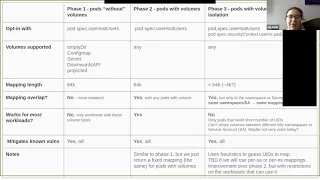
So
basically,
we
have,
for
example,
phase
one
that
it's
basically
username.
Space
is
support
for
parts
without
volume,
and
I
want
to
emphasize
that
without
because
parts
that
have
volumes
but
don't
share
it
with
anyone
else
like
an
empty
deer
or
a
configmap
secret
than
our
cpi
or
projected
can
use
it,
and
the
username
prints
will
have
a
mapping
to
user
ids
in
the
host
and
this
mapping
will
not
overlap
with
any
other
part.
So
this
this
will
give
us
more
isolation
between
pawns.
I.
A
C
A
E
Yeah,
so
the
cubelet
needs
to
be
able
to
start
pods
that
require
root
on
the
host.
So
when
we
explored
running
rootless
cubelet,
you
were
already
running
a
subset
of
valid
pod
specs.
So
I
agree
with
reynold.
This
is
distinct,
but
yeah
good
good
question
to
at
least
clarify,
then
that,
like
a
rootless,
cubelet,
would
not
be
able
to
execute
a
pod
that
requested
the
host's
username
space
or
at
least,
if
the
runtime
it
interacted
with
wasn't
ruthless.
C
Okay,
so
phase
one
will
be
yeah.
All
the
faces
is
creating
a
username
space.
Where
that
the
part
will
use
and
yeah
phase
one
will
the
ideas
to
support
parts
without
volumes,
because
in
parts
with
when
you
don't
share
files,
you
can
use
different
mappings
for
the
user
namespace
that
do
not
overlap
with
other
pods
and
you
have
more
isolation
and,
as
you
don't
have
to
share
files,
you
can
do
that
and
of
course
this
doesn't
work
for
all
the
workloads.
C
E
C
Not
a
particular
use
case,
but
we
have
like
a
lot
of
parts
without
with
only
this
kind
of
volumes
and
having
a
good
level
of
isolation
for
them.
It's
nice
because
yeah,
we
have
a
lot
of
web
applications
and
things
like
that
that
access
a
share
database
and
they
don't
have
a
state
person
on
the
pods
only
the
database
and
that
stuff.
C
D
D
C
No,
no
so,
yes
very
good
question.
The
mappings
in
this
proposal
are
picked
by
the
cubelet,
so
the
queuelet
can
easily
guarantee
that
there
are
no
overlapping
parts
and
there
will
be
some
some
host
some
some
some
oid
space
reserved
for
for
the
host
to
use,
and
the
idea
is
to
also
this.
This
range
given
to
the
cubelet.
The
host
can
guarantee
that
there
is
no
overlap
with
the
file
system
with
the
user
ids
using
the
file
system
and
id
mapped
mounts.
C
C
But
I
think
that's
the
first
way
we
can
start
using
id
pump
mounts
because
we
control
the
partition,
where
the
container
runtime
runs
on
the
host
and
download
the
images.
And
if
that
partition
is
in
a
supported
file
system
and
with
a
new
kernel,
then
we
can
remove
the
storage
and
performance
overhead
of
of
using
username
spaces.
C
F
So
I
I
just
want
to
point
out
the
for
the
container,
the
plus
the
device
or
use
cases.
Then
this
might
be
actually
done
on
the
container
runtime
phase.
So
maybe
ninten
you
can
cheat
me.
Maybe
I
I
remember
cracked
me
here.
So
we
need
a
double
check.
If
this
is
my
ping,
remapping
stung
by
the
kubernetes,
maybe
there's
the
conflict.
F
So
so
the
container
runtime,
I
think,
directly
also
common
here
and
and
the
mapping
actually
done
by
the
container
runtime.
Not
so
right
now,
if
kubernetes
pick
up
this
remapping
things,
and
so
there
might
be
conflict
with
the
container
rental,
so
the
both
container
replaced
the
devices
and
also
cutter
use.
Cases
so
may
might
be
conflict
here.
But
I
need
because
that's
the
couple
years
ago,
when
we
designed
because
that
time
user
naming
space
this
project
haven't
started.
F
C
C
C
You
will
need
to
use
the
the
second
field
that
we
added
to
this
part
spec,
the
mapping
that
will
expose
to
the
container
we
don't
know
yet
because
we
don't
have
the
risk
defined,
but
it
will
be
less
than
sixty
four
thousand
because
because
when
we
want
part
what
to
put
isolation,
we
want
to
give
each
part
a
mapping
according
to
the
namespace
or
service
account
they
are
in,
and
those
are
con
and
those
are
container
scope.
No,
no,
the
scope,
so
we
need
to
warranty
yeah.
C
C
It
might
not
work
for
all
workloads
because
we
need
to
expose
a
short
number
of
user
ids
to
the
container
and
things
like.
If
we
give
a
mapping
per
service
account
or
per
namespace,
you
won't
be
able
to
share
across
service
accounts
or
namespace.
Maybe
it's
not
very
used,
but
it's
a
limitation
by
by
design
of
this
approach.
E
E
E
E
C
Yeah
yeah
and
so
basically
yeah
phase.
One
is
parts
without
volume.
So,
what's
with
volumes
that
are
not
shared
phase,
two
is
just
a
small
twist
over
phase
one
and
phase
three
is
more
particular
isolation
where
we
try
to
not
share
the
mappings.
Unless
we
there
are
some
reasons
that
sharing
might
be
beneficial
like
showing
files
or
things
like
that
between
parts,
but
we
restrict
the
number
of
workloads
that
can
I
can
use
because
we
don't
have
any
other
way
around
it.
C
It's
like
zero
root
in
the
house
is
not
mapped
to
the
container,
and
things
like
that,
and
there
are
several
vulnerabilities
in
coronet-
is
one
very
recent
like
about
the
subpath
volume.
There
are
always
vulnerabilities
with
sub-path
and
usually
mitigation
is
to
not
run
continuous
as
root,
because
root
has
all
the
privileges
on
the
host
and
can
read
any
file
and
have
like
attack
override
and
those
capabilities.
C
G
G
For
example,
in
cryo
we
inspect
the
container
image
and
we
pick
a
range
that
honors
the
ownership
of
the
files
in
the
image,
as
well
as
the
files
the
users
defined,
the
ac
password
for
so
yeah.
This
is
this
will
be
my
only
well
dubbed
at
this
point
if
it
would
make
more
sense
to
have
this
logic
in
the
runtime.
G
One
issue,
though,
is
yeah
is
that
the
range
must
be
picked
at
pod
creation
time
and
they
and
and
still
it's
not
known
what
containers
will
be
added
to
the
pod.
So
at
the
moment,
the
limitation
we
have
in
cryos
that
the
inspection
can
be
done
only
for
the
body
image
which
it's
not
very
helpful,
but
so
yeah.
This
is
one
limitation.
I
yeah.
H
Yeah,
if
I,
if
I
remember
correctly
community,
has
a
different
behavior
so
for
community.
I
remember
the
image,
download
and
unpack
separate
so
for
download
you
just
download
the
content
and
for
unpack
for
actually
creating
a
container.
You
unpack
you
you,
you
create
a
snapshot
and
if
I
remember
correctly,
for
each
container,
you
have
its
own
top
level
snapshot
and
you
can
do
the
uid
mapping
there.
H
So
if
I
remember
correctly
for
kinetic
it
can
be
per
part
and
port
container
and
the
ui,
the
mapping
can
happen
at
runtime
when
you
create
a
container.
So
I
just
want
to
point
out
there.
There
may
be
a
information
difference
for
different
runtime
and
focus.
If
I
remember
correctly,
it
might
be
possible
to
support
per
part
and
per
container.
F
I
think
I
think
the
container
do
you
have
to
do
right.
So
if
you
cannot,
then
how
devices
are
doing
this
one
because
device
actually
supports
power
level,
user
naming
space
and
the
mapping
those
and
the
container
increasing
that
powder.
So
we
have
to
pass
those
things,
but
this
is
why,
earlier
I
reached
that.
H
F
Yeah,
okay,
so
we
need
to
follow
up,
at
least
because
I
also
remember
when
we
proposed
that
for
the
device
that's
a
couple
years
ago,
and
so
the
kata
doing
the
similar
things
using
the
signological,
and
so
that's
why
we
we
need
to
figure
out.
This
is
not
a
crosstalk
regression
for
the
other
use
right,
so
cryo.
I
think
that
may
be
the
signal,
but
it's
not
exactly
the
same,
but
also
we
need
to
avoid
the
regression.
That's
the
only
concern
I
have.
G
I
mean
you
can
specify
the
mapping
to
cryo,
like
the
user
can
specify
the
mappings,
so
this
wouldn't
be
a
like
a
breaking
change
for
the
implementation.
It's
just
what
makes
more
sense
by
default
like
I
see
the
advantage
of
having
in
the
runtime,
because
it
does
access
to
more
information
and
can
inspect
images.
C
No
phase
three
yeah,
I
think
the
the
problem
of
the
runtime
peaking,
but
I
think
it's
not
clear
but
only
relevant.
Sorry.
Let
me
organize
myself.
I
think
it's
not
clear
who
should
be
the
owner
of
the
mapping
for
phase
three,
because
it's
tricky,
but
it's
only
relevant
for
phase
three
right
because
because
for
phase
one
like,
if
we
agree
that
we
want
to
give
parts
without
volumes
different
mappings,
we
can
easily
do
it
today
and
we
don't
need
much
from
the
runtime.
D
C
And
so,
if,
if
there
is
general
agreement
on
on
the
idea
for
phase
one
and
phase
two
and
and
we
can
define
phase
three
on
the
go,
I
think
that
would
be
super
beneficial
because,
like
we
did
a
very
detailed
estimate
of
the
work
needed
to
get
phase
one
and
phase
two,
and
it's
about
six
months,
full
time
working
on
that.
So
it's
like
a
lot
so
yeah.
If
we
can,
if
we
can
split
the
faces
like
if
this
split
makes
sense
for
everyone,
I
think
that
would
be.
E
I
B
A
J
Hi
so
sorry
my
apologies,
I
have
not
been
able
to
once.
I
lost
momentum
on
this
last
around
the
last
lead
in
the
last
release.
I
never
got
it
back,
but
I
spent
the
last
couple
of
weeks
just
catching
up
on
the
code
and
looking
through
some
of
the
key
feedback
that
we
have
that
needed
to
be
addressed.
I
think
the
major
ones
was
from
long
term
and
one
one
from
you
and
I've
ping
lonto.
J
I
think
I
was
looking
to
see
how
we
can
instrument
the
plague
to
when
the
resizing
is
in
progress.
For
a
part,
it
should,
you
know,
call
get
bot
status
and
get
the
latest
from
the
cri
and
then
update
its
cache.
The
problem
is
that,
even
if
we
did
that,
it's
not
helping,
because
if
there
is
a
series
of
updates-
let's
say
the
memory
is
being
updated
and
the
cpu
is
being
updated.
We
break
it
down
so
that
we
are
not
exceeding
the
pod
limits.
J
That's
been
approved
by
the
by
the
fit
when
we
admit
the
resize,
so
we
do
memory
first
and
then
we
do
the
cpu.
But
if
we
have
the
already
successfully
updated
the
memory-
and
we
don't
have
the
latest
from
gitpod
status,
then
the
problem
is
that
we'll
be
writing
back
the
old,
the
previous
memory
values
which
keeps
bouncing
toggling
back
and
forth.
So
the
code
that
I
currently
have
there
in
the
update
content.
J
After
calling
update
container
resources
for
a
resource
type,
we
call
getpod
status
and
then
update
the
cache.
I
think
that
needs
to
stay.
So
I
just
wanted
atlanta
to
take
a
look
at
that
code.
I
did
make
the
change
to
define
a
separate
resource.
We
were.
We
were
using
v1
resource
type
in
the
container
resources
container
status
that
we
have
for
the
queue
container
status.
I
changed
that
I
I
use
I
when
we
query
back
the
when
we
get
something
from
the
cri
we
get
either
windows
or
linux
container
resources.
J
A
H
J
J
Make
sure
that
that
gets
done
so
that
the
pr
is
ready
to
merge
before
world
target
to
merge
it
before
the
code
freeze
happens
and
elena,
I
think
wong
chin
might
need
some
help
from
you
to
figure
out
how
to
run
the
the
e2e
test
that
we
have
in
with
the
feature
gate
enabled
you
mentioned
in.
One
of
the
comments
that
you
had
was
that
the
test
should
be
checked
in
with
feature
gate
enabled
right
now.
If
the
feature
gets
disabled
and
the
tests
are
run,
the
test
will
return.
A
There
is
an
alpha
test,
job
that
runs
everything
with
like
it'll
turn
on
all
alpha
feature
gates,
so
that
should
be
picking
it
up,
but
I
think
that
you
may
have
had
a
selector
in
your
test
that
was
causing
it
to
not
get
picked
up
by
that
job.
So
I
don't
think,
there's
anything
particularly
special
about
this.
That
needs
special
infrastructure
to.
B
A
But
if
you,
if
you
wrote
the
tests
as
node
end-to-end
tests,
as
opposed
to
just
like
standard
core
end-to-end
tests,
then
they
won't
get
picked
up
by
those
jobs.
But
from
what
I
can
see
here,
they
look
like
standard
end-to-end
tests,
so
they
should
get
picked
up.
It
just
depends
on
what
test
selector
that
you
put
on
them.
A
A
Yeah,
so
they
need
to.
We
need
to
ensure
that
they're
actually
running
as
part
of
the
ede
suite,
and
I
don't
think
that
they're
actually
getting
like
picked
up
with
the
jinko
framework
from
what
I
can
see.
There's
a
bunch
of
cases
that
are
like
unit
test
style,
matrix
ones.
But
I
don't
see
where
the
where
the
test
actually
gets
set
up
with.
J
A
J
J
A
A
K
This
was
the
main
goal.
That's
why
we
only
talk
about
forensic
container
checkpointing,
but
it
doesn't
block
us
in
the
future
to
do
anything
more
complicated.
More,
I
don't
know
more
advanced
with
a
checkpoint,
restore
and-
and
the
other
question
was
about-
and
I
I
didn't
understand
it
correctly
from
the
meeting
from
the
meeting
notes.
K
It
was
about
how
networking
storage
is
is
connected
with
containers,
and
I
try
to
answer
it
here
and
in
in
the
in
the
cap
pull
request
that,
basically
all
external
resources
the
container
is
using,
has
to
exist
and
before
the
container
can
be
restored.
That's
all.
I
wanted
to
basically
resolve
the
open
questions
from
last
week.
K
L
Yeah,
so
for
the
other
question
regarding
the
outstanding
I
mean
the
outstanding
questions
about
how
networking
storage
will
work
on
restore
yeah.
I
didn't
post
those
questions,
but
my
I
I
have
the
same
question
because
when
you
okay,
if
you
would
like
to
restore
the
I
mean
the
container
from
the
from
the
checkpoint
right.
If
you
would
like
to
run
that
properly
on
another
server
on
another
node,
then
you
there's
some
uniqueness
easier
that
you
know
need
to
be
taken
care
of.
L
Like
some
also,
some
networking
you
know
issue.
I
guess
that's
the
same.
That's
what
that
those
questions
mean
so
have
you
thought
about
that?
So
I
think
the
point
is,
if
I
just
check
pointing
the
containers-
probably
it's
not
enough
to
to
further
further
for
a
restoration
on
the
nut
to
work
properly
on
another
load.
K
Yeah,
so
so
this,
so
this
sounds
like
one
of
the
the
questions
I
often
get
about
checkpoint
restore
is
is
about
about
networking,
so
the
thing
is
if
there
are
established,
as
so
talking
about
tcp
connections,
because
that's
most
of
the
time
the
most
difficult
thing.
If
there
are
established
tcp
connections,
we
can
migrate
a
container,
but
we
need
to
have
to
have
the
same
ip,
the
container
or
where
the
socket
is
bound
to.
So
we
need
to
have
the
same
ip
address
in
the
container
as
during
checkpointing.
K
K
K
We
accept
that
the
client
has
to
re-establish
the
tcp
connection,
so
tcp
is
most
of
the
time.
The
most
the
thing
where
most
questions
are
asked
because
established
tcp
connections
are
possible
to
restore,
but
because
the
ip
addresses
have
to
stay
the
same,
it's
not
always
really
doable.
If
you
have
a
elaborate
networking
setup,
then
maybe
you
cannot
have
the
same
tcp
ip
address.
L
Yeah
yeah,
yes
yeah,
it's!
I
think
it
answers
the
question
a
bit.
I
I'm
thinking
about
another
uses
scenario,
not
migration.
I
think
it's
a
very
it's
very
it's
very
useful
and,
for
example,
if
we
would
like
to
create
another
container
same
another
container
on
another
node
from
that
checkpoint
image.
It's
not
my
grease.
I
want.
We
would
like
to
create
a
new
container
instance.
Okay,
because
of
scalability
requests.
L
B
K
Okay,
so
yeah
that
that's
that's
an
interesting
questions
and
we
are
already
discussing
this
upstream
there's.
The
same
request
is
coming
from
from
amazon
during
virtual
machine
migration.
Basically,
so,
if
you
have
some,
like,
you
said
unique
numbers
which
create
random
numbers
and
if
you
do
a
checkpoint
from
the
container
and
then
create
multiple
copies
of
the
containers
from
this
point
on
all
they,
they
all
have
been
seeded
all
the
containers
with
the
same
random
seed,
and
so
the
the
random
numbers
will
be
the
same.
K
So
there
is
a
discussion
currently
going
on
on
the
linux
kernel
level.
How
can
we
tell
a
virtual
machine
which
is
migrated,
or
how
can
we
tell
a
process
or
a
container?
That
is
migrated
that
it
has
been
migrated
and
that
it
has
to?
I
don't
know,
reseed
its
random
number
generators
and
and
maybe
drop
its
secrets
so
that
it's
no
longer
in
memory
that
it
needs
to
recreate
keys.
Things
like
that
and
the
problem
is
there
is
currently
no
solution.
K
K
So
currently
no
one
has
a
good
idea
how
to
tell
a
vm
or
a
process
that
it
has
been
migrated
in
in
a
way
that
it's
usable
for
for
everyone.
So
we
would
like
to
have
an
interface
and
to
tell
processes
that
they
have
been
migrated
or
even
virtual
machines,
but
there
is
currently
nothing
which
does
this.
There
was
a
discussion
about
this
on
on
linux
plumber's
conference
a
few
weeks
ago.
There's
there's
even
a
video
if
you,
if
you
want
to
check
it
out.
L
K
L
Yeah,
I
think
that
that's
good
yeah.
Actually
another
question
is,
you
know
like
if
we
use
container
b
right.
So
it's
not.
Everything
is
loaded
into
the
into
the
memory.
So
I'm
not
sure
that
when
you
take
the
checkpoint
of
the
container,
do
you
also
checkpoint
those
files
on
the
disk
or
you
just
checkpoint?
The
memory
yeah.
K
So
my
my
work
is
based
on
on
my
work
on,
so
I
did
this
all
for
podman
and
I
brought
this
all
to
cryo
and
the
the
podman
and
cryo
checkpoints
are
including
the
differences
of
the
file
system.
So
this
needs
to
be
implemented
for
container
d
also
so,
but
no
one
has
done
it
so
far,
but
yeah
we
included
in
the
checkpointing.
I
have
done
so
far.
We
take
the
div
from
the
latest,
read,
write
layer
and
store
it
in
the
checkpoint.
We
take
all
changed
files.
K
K
There
are
this
is
going
on
for
a
long
time.
There
are
a
lot
of
pr's
all
around
and
and
and
but
there
is
a
there's,
a
there's,
a
pr
for
kubernetes
there's
a
big
draft
pr
for
kubernetes
which
implements
it
basically
end
to
end
for
for
the
drain
use
case,
you
say,
cube
ctl
drain
and
on
on
restart
all
containers
are
restored
and
then
there
are
cryo
patches.
K
There
are
cry
control
patches,
so
everything
exists
but
and
it's
all
linked,
but
it's
all
in
in
draft
states,
because
I'm
I'm
waiting
for
the
cri
cri
api
changes,
which
are
which
which
this
cap
tries
to
implement
as
long
as
they
are
not
approved.
I
cannot
do
the
changes
in
the
in
in
in
cryo
and
and
all
the
other
projects,
as
as
long
as
the
cri
api
is
not
updated.
L
K
L
A
L
L
J
I
think
the
pr
most
of
the
pr
is
already
reviewed,
so
I
already
rebased
and
squashed
all
the
changes.
Tim
tim
hawkins
looked
into
the
api
and
he's
good
with
what
we
have.
I
think
the
from
the
next
major
thing
is
for
atlanta
to
look
at
the
note,
and
there
are
a
couple
of
changes
for
elena
and
landau
to
look
at
and
see
if
they
make
sense.
On
the
note
side
scheduler
wanted
just
the
change
is
not
very
big.
J
E
J
B
B
A
J
J
Okay,
so
let
me
do
this
I'll,
take
a
look
at
it
tonight
to
see
if
I
can
split
it
split
it
up.
I
think
I
still
have
enough
context
in
my
mind
to
tell
which
one
goes
where
and
I'll,
essentially
I'll
split
it
into
four
or
five
commits
four
commits.
I
think
at
this
point
one
for
the
note
we
test
and
one
two
for
the
generated,
I
think
there'll
be
two
two
generated
commits
one
from
the
cri
google
side,
one
from
from
the
api
side.
J
So
five
I'll
see,
if
I
can
split
that
up
that
way,
we
can
bring
it
back
so
that
it's
easier
for
everyone
to
review.
It
looks
like
people
want
to
take
another
look
at
this.
I
squashed
it
mainly
because
at
some
point
we
said:
okay,
it's
good
time
to
squash
it
after
a
lot
of
review
last
june
july,
but
we
didn't
make
them.
L
J
I'll
do
it
tonight.
I
think
I
have
enough
context
on
because
previously
api
kept
evolving
on
top
of
the
cubelet
changes,
which
was
making
things
difficult
now,
api
is
not
evolving,
so
I'll
just
take
all
the
api
changes
make
them
put
them
into
I'll.
Just
replace
this.
What
we
currently
have
I'll
first
push
another
one
which
will
have
four
or
five
commits.
I
think
it
should
not
be
more
than.