►
From YouTube: Secrets Store CSI Community Meeting - 2021-04-15
Description
No description was provided for this meeting.
If this is YOUR meeting, an easy way to fix this is to add a description to your video, wherever mtngs.io found it (probably YouTube).
A
All
right
welcome.
Everyone
today
is
april
15th,
which
is
typically
tax
day
in
the
states,
but
I
think
we
got.
I
think
we
got
an
extra
month.
Welcome
to
our
csi
secrets,
call
just
fyi
for
those
who
are
new.
This
call
is
governed
by
the
cncf
code
of
conduct,
so
I
always
say
if
you're,
nice
and
kind
to
each
other
you'll
be
fine.
A
We
got
a
quick
agenda
here,
but
what
we'd
like
to
do,
if
you're
new,
to
the
call,
if
you
want
to
introduce
yourself
and
maybe
talk
about
what
interests
you
in
the
project
and
maybe
anything
that
you
like
to
talk
about
or
what
would
like
to
work
with
so
we'll
we'll
kick
that
off
dan.
You
want
to
I'm
sorry
dane.
B
A
Oh
awesome,
great
all
right
with
that.
Let's
go
ahead
and
go
down
the
agenda
items
I
will
moderate.
I
think
I
can
do
double
duty.
The
list
is
short
here,
so
I'll
put
myself
on
the
hook
for
notes
and
with
that
we
will
kick
it
off
the
niche.
I
think
europe
first
we're
going
to
talk
about
making
the
filtered
watch
default
after
current
plus
3
releases.
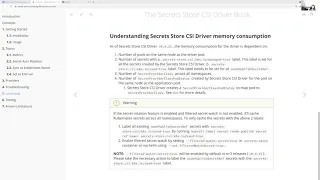
C
C
Yeah
so
inside
the
warning
right,
so
we
tell
them
that
after
the
last
release,
if
they
want
to
have
the
csi
driver
using
as
less
memory
as
possible,
then
we
have
enabled
filtered
watch
everywhere.
We
can,
and
the
only
last
piece
is
for
the
note
published
secret
ref
and
for
that
it
requires
user
action
where
they
need
to
label
their
existing
secrets.
To
say
this
secret
is
being
used
by
csi
driver
and
then
they
can
enable
the
filtered
watch
on
those
secrets
as
well
using
the
feature
flag.
C
So
the
idea
is
in
the
docs.
We
added
that
we
want
to
enable
by
this
by
default
after
n
plus
three
releases,
so
that
it
gives
enough
time
for
all
existing
users
to
start
labeling
their
application.
This
is
this
secret.
Is
he
used
heavily
at
least
in
azure
provider,
from
what
I've
seen,
because
if
they
want
your
service
principle,
they
use
it
with
that
and
also
for
gcp.
It
is
possible,
but
it
is
not
documented
yet.
C
D
C
D
C
Yeah,
I
think,
like
I
mean
for
now,
I'm
thinking
we
could.
We
usually
add
warning
and
release
notes
right
like
when
we're
deprecating,
something
we
add
warnings.
So
like
every
release,
note
we're
going
to
say:
please
take
this
necessary
action.
This
is
going
to
be
enabled
by
default,
so
coming
soon
right
and
then
I
zero
to
0.25.
We
probably
make
it
default
so
that
out
of
the
box,
we
have
the
least
memory
consumption.
C
I
mean,
I
think
there
might
be
still
some
users
who
will
hit
the
issue
where
they
say
the
secret
is
not
found
because
they
haven't
labeled
it
yet.
But
I
think
that
is
still
better
than
having
issues
where
users
come
up
with
a
high
memory
consumption,
and
then
we
tell
them
that
go,
take
all
these
actions
and
then
go
enable
the
fleet
and
then
take
all
the
necessary
precautions
before
you
do
anything.
B
One
thing
I
was
thinking
is,
we
could
add
a
check
in
like
the
next
release
to
at
least
do
like
an
error
warning
log.
If
we
know
this
that
the
secret
doesn't
have
the
label
that
might
just
make
it
easier
on
the
upgrade
to
like
search
through
logs
to
find
out,
you
know
more
quickly,
like
the
other
action
you
need
to
take
yeah.
That's
a
really
good
idea.
C
D
C
C
We
have
to
mark
what
the
cube
did
does,
but
I
I
like
the
warning
stuff
because
I
mean
the
rotation
reconciler
anyways
gets
the
secret,
so
it
can
actually
check
if
the
label
doesn't
exist
and
then
it
can
generate
warning
for
each
node
published
secret
riff
and
that
way
when
the
user
sees
in
the
logs.
They
see
this
generated.
So
they
know
that
they
have
to
take
the
action.
B
C
Yeah,
we,
I
think,
we've
been
doing
warnings
on
the
release,
note
for
anything,
that's
deprecated
or
going
to
be
deprecated.
So
so
we
can
add
that
for
all
the
next
release
notes
and
then
0
to
0
25,
we
can
say
that
this
is
a
breaking
change.
This
has
changed
so
before
you
upgrade,
follow
all
these
actions
and
then
do.
D
It
all
right.
Can
I
ask
a
quick
question
about
this.
I
didn't
quite
follow
why
the
labels
needed
so
when
you're
saying
it's
only
for
secret
refreshers,
but
does
the
secret?
Does
the
csi
driver
not
store
the
the
metadata
about
what
secrets
are
referred
to
by
no
published
secret
ref,
so
it
needs
to
kind
of
be
using.
It
needs
to
reconstruct
the
original
request.
D
C
Not
probably
secret
ref
is
usually
just
used
to
provide
the
credentials
for
the
amount
right.
So
when
we,
when
the
user
provides
that
as
part
of
their
volume,
spec
cubelet
gets
the
secret
and
gives
it
to
us
as
part
of
note
publish
so
that
time
we
already
have
it,
and
then
we
pass
it
on
to
the
providers
right
and
then
for
rotation
purposes.
C
We
need
to
enable
filtered
watch
as
much
as
possible
so
that
we
don't
catch
all
the
secrets
in
memory.
So
if
we
do
a
filtered
watch
where
the
user
says,
if
they're
using
10
not
published
secret
riff
and
they
go
ahead
and
label
all
of
those,
then
when
they
enable
the
filtered
watch,
we
only
cache
those
10
secrets
in
memory
and
all
new,
not
public
secrets
in
memory.
We
won't
catch
the
entire
secrets
in
the
cluster
because
we
don't
need
that
by
default.
C
C
No,
I
think
we
have
an
action
plan
right
like
so.
The
first
thing
is:
are
we
gonna
add
a
warning
in
the
logs
so
in
the
rotation
reconciler?
Every
time
we
see
the
secret
without
the
label,
we'll
add
a
warning
message,
so
that's
we'll
get
that
next
release
and
also
we'll
make
sure
that
in
all
the
subsequent
releases,
until
this
is
made
default,
we'll
add
it
to
the
release
notes
as
a
warning
for
the
necessary
user
actions.
A
B
This
is
a
deviation
from
like
kubernetes
secrets,
where,
if
you
change
the
keys
in
the
kubernetes
secret,
like
they
will
be
removed
in
the
mail
so
one
I
want
to
first
check
that
we
we
thought
that
the
correct
behavior
is
to
match
kubernetes
secrets,
behavior
and
then
discuss
some
difficulties
in
actually
implementing
that.
I
think
it's
probably
true
that
we
would
want
it
to
clean
up
files
that
shouldn't
be
there,
but
if
there
were
any
objections
to
that,
I
wanted
to
bring
it
to
the
call.
C
D
No
objections
for
me.
I
think
that
sounds
sounds
like
the
right
behavior
to
go
and
delete
it.
Presumably
yeah.
The
only
way
that
secrets
do
get
cleaned
up
right
now
is
if
the
whole
secret
provider
class
gets
deleted
or
that
like
yeah,
essentially,
the
whole
amount
has
to
get
deleted
for
secret
to
get
cleaned
up.
B
Yeah
and
so
then
like,
given
that
there
was
in
the
original
rotation
proposal
kind
of
this
idea
of
an
optimization
where,
if
the
provider
knew
that
the
secret,
like
hadn't,
changed,
somehow
it
wouldn't
re-fetch
or
rewrite
the
file,
but
looking
into
like
how
that
would
be
expressed
of
like
hey,
the
file
should
exist.
But
there
is
no
change
to
it.
B
B
Doing
that,
though,
would
make
it
easier
to
reuse
logic
with
kubernetes
secrets
in
this
atomic
writer
package
they
have,
but
then
looking
at
the
providers.
I
don't
believe
any
of
them
actually
perform
that
in
optimizations
around
that.
So
I
wanted
to
bring
it
to
the
group
of
whether
or
not
we
wanted
to
leave
in
kind
of
a
a.
C
Yeah,
at
least
in
terms
of
the
azure
provider-
for
that
optimization,
there
is
no
way
we
can
actually
skip
the
call
to
the
external
secret
store,
even
if
we
knew
the
version,
so
the
only
possibility
is
either.
We
cache
that
in
memory
and
say
we
compare
with
that,
but
there
is
no
way
for
us
to
know
if
there
is
a
newer
version
available
until
we
make
a
call
to
azure
keyword.
C
So
I
think
the
optimization,
at
least
for
azure
provider,
would
have
only
been
around
skipping
writing
the
file.
If
the
version
that
we
currently
have
the
newer
version
that's
available,
both
are
exactly
the
same,
so
the
only
optimization
was
only
around
that
edge
right
like
that.
It
wouldn't
have
been
around
the
number
of
calls
that
we
generate.
C
But
yeah
I
mean
the
interesting
part
around
this.
Like
I
mean
tom,
you've
been
discussing
a
little
bit
of
on
slack
like
this
is
similar
to
a
put
versus
patch
right
like
what
does
the
provider
do?
We
always
think
what
the
provider
gives
us
is
that
the
source
of
truth
and
then
just
write
everything
from
that
or
when
the
provider
only
sends
a
subset
of
files.
Do
we
consider
it
a
patch
and
then
just
go
patch
the
existing
files,
but
don't
touch
the
old
files.
E
I
have
I
have
a
two
questions
here.
The
first
question
is
I
I
didn't
get
it
like
when
you
mention
the
patch,
how
did
you,
how
did
you
do
that
patch
who
gonna
do
the
patch
and
another
one
is
like
your
mission,
like
reload
the,
when
we
do
the
secrets
rotation.
Imagine
like
a
reload.
How?
How
could
we
do
reload?
Are
we
sending
some
signal
to
the
to
the
container
or
right,
or
you
simply
update
the
file?
If
you
just
make
the
file,
the
running
process
will
not
fetch
the
lattice
file
right.
B
C
Yeah
in
terms
of
usage,
we,
if
you
look
at
the
docs,
we
split
it
in
three
different
scenarios.
Right,
like
one,
is
part
relying
on
the
files.
They
could
have
a
file
watcher,
so
they
automatically
get
triggered
when
the
mouse
content
gets
updated
and
then
the
other
scenario
is
for
pods,
using
sync
as
kubernetes
secret
and
they're,
using
it
with
certificates.
C
Then,
when
the
kubernetes
secret
gets
rotated
by
the
csi
driver,
then
ingress
controllers
are
smart
enough
to
pick
up
the
chain,
so
they
automatically
pick
it
up
and
then
the
third
scenario
is,
if
they're,
using
the
sync
to
actually
use
environment
variables.
So
in
that
case
it
would
require
a
part
restart.
So
we
have
references
to
like
third
party
object.
C
B
Yeah,
I
think
that
supporting
a
patch
or
some
sort
of
like
diff
in
the
provider
would
complicate
writing
a
provider
and
complicate
the
interface
between
the
driver
and
the
provider
and
like
it
may
allow
for
some
optimization.
But
I'm
I'm
trying
to
weigh
whether
or
not
that
optimization
is
worth
it
or
realistic
or
kind
of
premature.
D
D
But
then,
if
someone
edits,
I
guess
basically
there's
there's
deleting
files
and
there's
adding
files
to
an
svc
and
if
we
add
files,
then
we're
gonna
need
amount
request
provider
and
if
we
have
like
a
whole
new
volume
request,
we'll
make
mountain
requests
to
the
provider
and
if
we
need
to
refresh
secrets
we'll
make
a
mountain
request.
Are
those
the
the
main
three
scenarios
in
which
we're
gonna
be
be
fetching
from
the
provider.
B
D
A
D
D
There's
a
lot
of
complexity
and
kind
of
provide
a
specific
logic
to
be
had
in
in
whether
or
not
you
want
to
refret
re-fetch
secrets
each
time,
and
so
it
makes
more
sense
to
defer
that
to
each
provider.
To
me
and
yeah,
like
makes
kind
of
recovery
and
errors
kind
of
much
simpler
and
cleaner
to
recover.
B
A
C
Yeah
so
the
for
the
security
order
they
received
another
rfp
this
week
and
then
so.
There
are
two
right
now
that
the
third
party
audit
team
is
evaluating
so,
but
they
are
also
planning
to
extend
it
until
they
can
get
four
rfps.
So
there
is
more
room
to
compare
across
the
different
vendors
and
score
that
and
decide
which
one
they
want
to
go
with.
But
that's
the
update
that
I
have
security.
A
D
C
I
synced
up
with
shane
last
evening,
so
the
we
just
wanted
to
see
what
is
the
best
possible
approach
right
today.
We
have
a
pr,
that's
actually
pretty
big
and
it
hasn't
received
a
lot
of
changes
or
anything.
Yet
so
the
plan
that
we
decided
was
we
want
to
do
it
first
thing
is
we
want
to
do
it
in
a
couple
of
phases,
so
we
want
to
add,
like
an
initial
framework
and
then
start
moving
each
provider
individually.
So
I
think
it's
easier
in
terms
of
implementation.
C
It
also
helps
more
contributors,
help
out
with
the
migration
and
then
also
in
terms
of
review.
It
makes
it
easier,
so
the
idea
is
the
for
as
a
first
pr.
We
want
to
add
a
framework
and
then
also
common
uterus
that
could
be
used
by
all
the
providers
so
like
creating
a
secret
provider
class
deleting
a
sql
provider
class
and
also
helpful
functions
like
helm
or
cube,
ctl
and
stuff
flow
applicant,
and
then
the
next
thing
is
today.
C
C
So
one
thing
that
came
out
of
the
discussion
yesterday
was
how
do
we
mandate
or
how
do
we
serialize?
What
kind
of
tests
need
to
be
run
right?
So
I
think
we
need
to
make
a
slight
change
on
how
the
tests
are
defined.
So,
instead
of
having
each
individual
provider
define
the
set
of
tests
that
they
can
run,
the
driver
needs
to
define
what
tests
it
want
to
run
so,
basically
what
all
tests
it
wants
to
test
for
the
features
or
like
the
feature
flags
and
then
like
backward
compatibility.
C
So
the
driver
defines
the
entire
test
suite
and
then
for
running
the
test.
It
would
just
call
some
of
the
provider
functions
to
get
like
secret
provider
class
for
that
provider,
because
the
only
difference
that
we
have
today
is
around
what
is
defined
in
the
secret
provider
class,
but
the
work
part
spec
and
everything
else
is
remains
the
same
right.
So
that's
why
we
also
talk
about
our
project.
We
say
the
only
difference
is
in
the
secret
provider
class.
C
So
the
idea
is,
we
want
to
have
the
driver,
define
the
set
of
tests
and
then
the
driver
just
based
on
which
provider
it's
running
the
test,
for
it
would
call
that
provider
util
function
to
say
give
me
a
secret
provider
class
object
for
this
test
and
then
the
second
provider
class
will
be
used
and
then
created,
and
then
it
will
just
run
so
that
allows
the
driver
to
define
it.
If
providers
haven't
implemented
that
util,
yet
they
can
do
a
ginkgo
skip
with
it
until
it's
implemented.