►
From YouTube: 20220921 SIG Arch Prod Readiness
Description
No description was provided for this meeting.
If this is YOUR meeting, an easy way to fix this is to add a description to your video, wherever mtngs.io found it (probably YouTube).
B
A
A
A
Sorry
couldn't
hear
me,
zoom
always
does
that
when
I
share
I'm
sure
there's
some
setting,
I
can
fix.
So
thank
you
just
wanted
to
welcome
our
shadows.
We
have
a
great
good
crew
of
shadows.
We,
which
is
great
we've,
been
doing
pr
now
for
several
releases
and
the
team
kind
of
started
with
three
went
to
four
and
then
went
back
to
three
and
then
at
least
for
this
cycle.
A
B
Let's
try
that
without
being
on
mute
all
right,
so
you
guys
are
all
fairly
new
here.
I'm
probably
wondering
why
on
earth
would
you
bother
to
do
this
every
year
for
the
past
three
years
we
have
run
a
survey
of
of
whoever
wanted
to
answer,
but
we
get
demographic
data.
It
was
largely
people
who
administer
cube
and
or
run
it
as
a
platform
as
a
service,
and
I'm
trying
to
find
the
share
button.
John,
it
tells
me
the
host
disabled
participant
screen
sharing.
Can
you
yeah?
A
B
Okay,
let's
let
us
let
me
close
this
window
just
in
case
I
get
that
wrong
and
you
guys
should
be
seeing
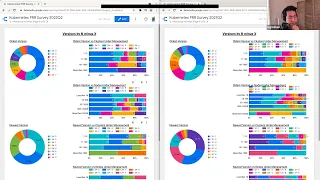
two
survey
results
left
and
a
right.
Do
you
see
a
little
report?
Excellent
so
on
the
left
is
the
one
we
did
this
year
on.
The
right
is
the
one
that
we
did
last
year.
You
can
see
right
away.
We
got
a
lot
less
participation,
this
time,
not
sure
why,
but
we
have
about
two-thirds
of
the
results
of
last
year.
B
B
We
added
a
new
question
this
year
and
the
question
we
added
was
is
cube
more
reliable
than
a
year
ago,
and
I
was
very
satisfied
with
his
answers.
75
said:
yes,
there
were
a
bunch
of
people
who
didn't
answer
or
went
not
sure
about
20,
and
only
3
percent
said
that
we
were
not
more
reliable
than
last
year,
and
so
one
possible
claim
out
of
this
is
that
prr
is
useful
to
do
to
help
improve
this
or
to
help
keep
cube
reliable.
B
B
B
The
reason
why
we
drew
that
line
in
the
first
place
was
that
we
figured
people
who
are
at
the
very
large
numbers
of
clusters
and
very
large
numbers
of
nodes.
They
already
paid
specialized
people
to
run
cube,
they're
very
familiar
with
it.
They
appreciated
our
help,
but
they
didn't
really
need
it
in
the
same
way
the
chart
for
clusters
versus
nose
under
management.
It's
shifting
slightly.
You
can
see
it
most
in
the.
I
don't
know
if
you
can
see
where
my
pointer
is
going.
Hopefully
you
can
but
the
excellent.
B
B
The
version
breakdown
is
significantly
different.
This
release.
This
is
the
raw
version
numbers.
If
you
recall
john
last
time,
we
did
this,
we
said
g.
I
wish
we
had
a
thing
that
showed
us
version
level
minus.
However
many
versions
back
you
were
so,
do
you
want
to
try
that
chart
this
time?
That's
what
this
page
is.
This
is
this
is
124
most
current
release
when
we
released
the
survey
and
it
is
124
minus
3
releases,
and
then
you
can
compare
it
against
121,
which
was
last
year.
B
A
B
B
So
that's
that's.
My
takeaway
from
the
the
top
part
of
this
chart
is
that
we
are
stuck
here
on
the
oldest
versions.
The
newest
versions
show
a
little
bit
of
shuffling.
I
think
I
think
it's
more
noteworthy
to
me
that
if
you
add
up
n
minus
one
n
minus
two
n
minus
three
we're
we
have
a
larger
portion
of
it
taken
taken
up
by
those
releases
versus
the
ones
that
are
even
older,
so
yeah.
B
B
Yeah,
but
this
this
portion
of
the
chart
is
actually
pretty
small,
so
people
are
are
staying
current
with
their
newest
clusters
and
when
you
start
breaking
it
down
by
how
many
clusters
you
have
it's
the
same
as
we've
seen
every
year.
If
you
have
a
lot
of
clusters,
you
have
all
the
versions,
you
have
things
that
are
really
old,
and
then
you
have
things
that
are
really
new.
You
just
get
enough
clusters,
that's
what
happens.
B
So
this
chart
surprised
me
it.
It
surprised
me,
because
people
had
answered
that
they
thought
cube
was
more
stable
than
it
was
before
a
year
ago,
but
we
actually
had
a
fair
number,
a
slight
increase
in
the
percentage
of
clusters
that
had
rolled
back
minor
releases
in
production,
not
huge
overall,
it's
very
similar
to
the
previous
year,
but
it.
A
B
But
the
the
reasons
it
failed
were,
I
think,
slightly
better.
We
did
not
have
as
many
cluster
failures
now
users
get
to
self-select.
I
I
realize
that
the
shadows
here
did
not
see
the
survey
questions,
but
users
get
to
select
if
you
rolled
back
there's
a
time
frame.
If
you
roll
back,
I
think
in
the
past
year,
did
you
roll
back
for
these
reasons
check
the
ones
that
apply
and
they
get
to
select?
Was
it
a
bad
feature?
Was
it
a
bad
component?
Did
my
entire
cluster
fail?
B
Was
I
just
testing,
or
was
it
a
scalability
problem
and
in
previous
years
and
including
last
year,
one
of
the
reasons
that
people
checked
was
because
my
cluster
failed
and
they
get
to
decide
right.
Was
it
a
feature?
Was
it
a
component?
Was
it
a
cluster?
They
probably
don't
know
exactly
what
each
of
those
is,
but
this
release
we
didn't
see
people
choosing
cluster
failed.
It
was
odd
enough
that
I
actually
feel
a
need
to
go
back
and
look
at
the
data
to
see
if
I
have
parsed
it
incorrectly.
B
But
since
I
finished
building
the
first
cut
of
of
all
these
graphs
yesterday,
I
haven't
gone
back
to
double
check
to
see
if
we
changed
some
kind
of
phrasing
somewhere
and
broke
it,
but
that
could
at
least
explain
the
result.
So
does
the
next
page.
So
the
next
page
is
about.
Did
you
roll
back
a
patch
version,
and
this
year
so
few
people
in
absolute
numbers
rolled
back
patch
versions?
I
don't
even
know
if
this
page
is
useful
right
and
for
comparison.
B
A
B
A
B
A
B
B
B
B
B
B
I
guess
half
glass,
half
empty
kind
of
guy
could
look
at
that
and
say
the
alpha
features
are
so
bad.
No
one
has
the
guts
to
turn
them
on
in
production
anymore,
but
I
am
definitely
a
glass
half
full
guy,
so
I'm
going
to
go
with.
We
have
finally
cleared
enough
features
out
of
alpha
that
people
are
able
to
to
run
their
clusters
without
needing
plus
this
one
more
thing,
that's
an
alpha
that
I
haven't
gotten
finished
yet.
B
So
this
is
a
breakdown
of
the
people
who
answer
a
question
that
says:
have
you
used
metrics
to
debug
a
problem
in
the
past
month,
quarter
year
or
never,
and
then
people
pick
one
from
a
couple
different
categories.
We
asked
them
for
events,
we
asked
them
for
metrics
and
we
asked
them
for
logs
and
consistently.
As
you
would
expect
the
the
fewer
clusters
you
have,
the
more
likely
you
are
to
use
something
like
or
I
guess
this
is
nodes.
B
Those
are
the
clusters
is
the
next
page,
the
more
likely
you
are
to
use
something
like
metrics,
if
you're,
big
and
logs,
if
you're,
small
and
events,
if
you're
somewhere
in
between,
but
at
the
lower
end
of
the
scale,
we
did
seem
to
see
higher
percentages
of
people
actually
using
metrics,
which
I
took
to
be
a
a
good
thing.
You
can
stand.
B
A
B
So
it's
it's
similar
to
what
we've
had
in
the
past.
No,
no
huge
difference
by
cluster,
I
think
by
node.
I
did
see
the
little
improvement,
but
it
does
show
us
that
metrics
are
by
far
the
for
this
category.
They
are
very
valuable
and
we
should
continue
our
focus
on
them,
and
that
is
that
is
all
I've
got
any
questions.
I
can
click
through
to
any
page
here.
B
The
survey
results
you
know
as
before.
We
have
there's
the
last
question
with
email
addresses,
so
I
don't
want
to
project
that
I
should
make
a
data
set
that
removes
those
so
now
I
should
anyway,
there
are
a
couple
of
freeform
text
fields.
There
are
some
fields
about
what
other
debugging
tools
you
use
and
I've
been
meaning
to
slice
the.
What
other
tools
do
you
use
to
debug
your
cluster,
but
I
haven't
gotten
to
it
yet.
A
All
right
so
yeah,
I
think
that
we
may
want
to
present
a
summary
of
this
to
this
arch
meeting.
I
don't
know
if
you
can
do
it
tomorrow,
but
I
don't
know
what's
on
the
agenda
tomorrow,
there,
probably
nothing.
So
if
you
are
up
for
that,
we
can
present.
I
don't
know
if
we
want
to
do
the
whole
thing,
but
if
there's
highlights
you
want
to
present
and
then
share
the
the
two
reports.
B
A
A
B
B
B
A
A
B
A
B
So
one
of
the
reasons
that
we
well
the
primary
reason
that
we
did
it
was
because
of
difficulty
during
upgrade
and
freeform
comments
about,
like
he
pulled
my
apis,
and
so
I
think
the
way
we
would
see
that
manifest
is
that
we
don't
see
as
many
version
cliffs.
So
in
that
presentation
I
just
gave
it
said,
people
are
stuck
on
121
and
it's
noteworthy
like
it
was
a
big
difference
between
where
we
were
when
we
did
this
in
121
and
the
previous
level
was
118..
A
All
right
thanks
yeah,
so
I
was
I
was
actually
talking
about
again
when
I
share
so
you
mean
it's
me
so
yes,
so
so,
you've
probably
all
seen
the
new
sheet,
that's
being
used
for
enhancements
tracking.
This
replaces
or
the
new
project
board,
which
replaces
the
sheet
that
we
used
to
use
and
we
have
a
pr
tab
on
there.
So
in
the
pr
tab,
there's
an
assignee
and
there's
a
shadow,
and
you
everybody
here
except
for
han,
will
be
in
that
list.
So
I
will
add
han
to
the
list
too.
A
A
You
to
do
is
as
you,
what
we'll
be
doing
is
going
through
and
assigning
ourselves,
and
you
can
just
look
over
the
caps
and
decide
we,
I
don't.
We
can
decide
how
to
do
this.
I
was
thinking
people
would
just
self
select,
but
I
would
be
happy
to
get
together
with
people
who
are
like
shadowing
some
of
mine.
It
might
be
it
might.
Well,
as
I
go
and
do
pr
reviews,
we
can
maybe
do
a
live
meeting
and
just
go
through
it.
It's
pretty.
A
A
The
main
thing
we
ask
about
is:
can
we
turn
this
thing
off
without
breaking
the
cluster
and
and
when
we
turn
it
back
on,
will
it
still
work
and
not
break
the
cluster?
So
that's
almost
all
we
ask
at
alpha
very,
very
minimal
and
then
the
the
the
sort
of
requirements
ramp
up.
So
I
didn't
like
prepare
going
through
the
questionnaire.
Maybe
we
should
maybe
I
should
have.
We
could
probably
do
that
still,
but
you
know
I
guess,
as
you
shadow,
we
have
two
ways.
A
A
B
A
B
B
I
will
forewarn
you
that
I
do
spend
a
fair
amount
of
my
time
when
I'm
reviewing
these
actually
going
through
and
reading
the
kept,
because
a
lot
of
times
it's
something
new
for
me
and
so
like
if
you're
expecting
an
amazing
presentation
like
I
just
gave,
and
that
you
were
all
enthralled
by
this.
This
will
be
even
less
interesting
for
at
least
part
of
it,
because
a
lot
of
it
is
is
especially
when
you
go
to
beta.
The
questions
become
things
like.
If
this
starts
failing
in
my
cluster.
B
How
will
I
know
as
a
cluster
admin?
This
is
failing.
How
would
I
know
as
a
user
that
this
is
failing,
so
that
I
could
complain
to
my
cluster
admin
and
then
what
as
a
cluster
admin,
should
I
try
to
do
to
either
fix
it
or
gather
the
data
for
the
person
who's
going
to
fix
it,
and
that
takes
a
fair
amount
of
time
reading
the
kept
to
understand
what
it's
doing?
B
A
Yeah
that
that's
a
great
point
david.
So
a
lot
of
this
is
actually
yeah.
Familiarizing
yourself
with
the
cap,
which
sitting
and
doing
it,
live
with.
Somebody
isn't
probably
all
that
interesting,
but
we
could
try
it
and
see
how
it
goes
when
I
read
them
like
like
when
I
read
the
kept
through.
Sometimes
it
can
become
an
almost
overall
design
review,
because.
A
Because
it's
hard
not
to
but
but
there's
also
time
constraints
so
last
cycle,
I
think
what
were
there
david,
80,
caps
and
and
so
somebody's
lines
went
up,
and
so
you
know
at
some
point
like
yeah.
There's
a
judgment
call
as
to
how
much
time-
and
you
know
how
much
depth
to
go
into
the
design
pieces.
But
often
the
design
pieces
dictate
things
especially
around
scalability
or
things
like
that.
So
so
I
guess
maybe
the
the
first
step.
I
also
will
probably
start
next
week
and
to
give
a
time
frame.
A
Please
try
to
get
your
your
things
ready
for
prr
to
give
us
time
to
review
them
before
the
cutoff,
but
we
make
the
best
effort
to
get
everybody's
pr
done
and
thus
far
have,
I
believe,
gotten
everybody's
done
and
not
dropped
anybody
because
of
the
soft
deadline,
but
it's
just
kind
of
to
create
a
little
extra
urgency
for
people
to
try
and
make
our
lives
easier,
not
too
crammed
in
the
last
week.
But
what
tends
to
happen
is
that
last
week
gets
pretty
hectic
and
it's
a
it's
a
pole
and
weight
cycle.
A
A
Tab
thing
project
board,
so
we
had
them.
Have
this
notes?
Column
you'll
see
so
in
the
past.
What
I've
done
is
I've
had
just
a
spreadsheet
or
I
have
all
of
them
listed,
and
I
have
a
notes,
column
that
says,
when
I
last
like
pulled
that
one
and
what
the
current
status
is
effectively
like
what
I'm
waiting
on
typically
and
so
that
way,
it
makes
it
easy.
A
A
A
B
A
A
No,
he
volunteered
for
several
of
them,
and
I
think
that
was
not
okay,
that
was
not
mine.
Yeah,
say
something
on
slack
that
he
was
going
to
go
through.
I
mean
you
know
so
I
mean
that'd
be
awesome.
I
don't
want
him
to
do
stuff
when
he's
supposed
to
be
not
doing
stuff,
but
you
know
definitely
there's
enough
work,
but
I'm
very
encouraged
having
all
of
you
here
to
help
out.
A
A
A
A
A
A
A
Okay,
so
partly
this
serves
not
just
as
you
know,
like
I
said
in
the
beginning,
like
we
want
to
make
people
think,
but
we
also
want
to
document
so
partly
where,
where
this
puts
into
the
cap,
documentation,
okay,
here's
how
you
enable
or
disable
it
and
there's
a
feature
date
gate
to
do
that.
We
keep
this
in
the
kept
ammo.
The
theory
was
at
the
time
that
you
know
we
can
do
some
tooling
around
it.
No,
no
that's
happened,
but
we're
not
changing
the
process.
A
A
A
A
A
I
think
we're
still
in
in
the
alpha
section
here
featuring
that's
three
bars
three
hashes
okay,
so
here
we
get
finally
to
beta.
So
here
we're
starting
to
talk
about
okay.
How
do
we
roll
out
this
feature?
Often
these
features
have
both
an
api
server
and
say
a
cubelet
component,
and
so,
like
you
know,
we
want
to
make
sure
people
have
thought
through.
A
A
A
How
do
we
know
that
as
we're
rolling
out
this
feature
enablement
or
the
feature
if
on
upgrade,
especially
now
that
data
features
are
disabled
by
default?
I
guess
an
upgrade
is
not
as
much
of
an
issue
except
when
they're
going
to
ga,
but
in
any
case
you
know
how
do
you
roll
back?
Do
you
know
when,
when
you
need
to
roll
back,
how
do
you
know
it's
failing.
B
These
commands
look
at
the
proc
file
system
and
you
figure
out
what's
broken
there
and
you
go
into
the
journals
and
you
can
fix
the
problem
and
that
doesn't
work
well
at
scale
when
you
are
trying
to
decide
whether
you
need
to
roll
a
thing
back
and
that's
where
the
question
about
metrics
comes
in
and
I
think
there's
more
questions
as
john
gets
to
later.
Sections
and
pressing
back
on
that
is
is
important
because
even
if
they
only
update
reference
implementation,
maybe
they
only
update
whatever
standard
fleecer
there
is
to
expose
the
data.
A
Yeah,
some
of
that
comes
up
in
later
questions
like
around
the
monitoring.
I
think
in
the
next
section,
like
it's
very
common,
to
get
the
answer.
Like
david
said
of
ssh
in
it's
also
very
common,
that's
at
a
node
level,
but
even
at
a
cluster
level,
it's
very
common
to
get
the
answer
up
from
this
q
control
and
if
you've
got
10
000
clusters
or
a
hundred
thousand
clusters
that
many
people
around
a
thousand.
A
A
A
Okay,
so
where
was
I
yeah?
Upgrading
rollback
tested
upgrade
downgrade
upgrade?
This
is
similar
to
enable
disable
enable,
like
those
are
multi-stage
sequences
of
events
that
people
don't
always
think
through,
and
if
you
leave
detritus,
you
know
after
downgrade
you
leave
you
move
crap
around.
Then,
when
you
upgrade
again,
you
know
it
might
cause
confusion,
so
you
just
want
to
make
sure
that
those
things
are
tested.
Typically,
that's
going
to
be
manually
tested
because
we
don't
have
any
any
anything
to
do.
A
And
then
we
just
call
out
especially
you
know:
are
you
changing
any
interfaces
that
it's
gonna
kind
of
surprise
people
all
right
monitoring
requirements?
As
I
said,
how
can
it
be
see?
How
can
we
tell
if
it's
in
use
by
workloads
now
some
of
these
questions
apply
to
certain
types
of
features
and
not
other
types
of
features
so
that
that'll
often
come
up
to
you?
A
This
doesn't
apply
to
my
feature,
and
I
mean
you
have
to
make
a
judgment
call
about
that,
whether
it's
true
or
not-
but
this
is
like
just
because
I've
enabled
you
know,
network
policy.
It
doesn't
mean
that
anybody's
using
network
policy,
so
we
have
to
have
a
way
to
tell
whether
somebody's
using
it.
This
is
where
I
often
get
run
this
cube
control
command
and
I
think
david
didn't.
We
have
a
discussion
at
one
point
like
do.
We
have
metrics
around
like
counts
of
individual
resources
or
anything
like
that.
A
A
B
For
the
majority
of
features
that
I've
seen
coming
through,
they
end
up
adding
things
like
error
counts
and
success
counts.
Overall,
so
you
add
something
for
storage.
They
have
an
error,
count
a
latency
and
a
success
count.
So
the
cardinality
is
fairly
small,
but
if
they
look
and
see
that
any
of
those
are
greater
than
zero
someone's
using
it.
A
B
A
Okay,
yeah,
I
think
I've
been
okay
with
the
keep
state
metrics
as
well
yeah
all
right.
How
do
you
know
it's
working
for
your
instance,
so
this
is
more
user
oriented
as
opposed
to
operator
fleet
oriented,
but
we
we
added
this
at
one
point,
because
we
felt
from
a
documentation
standpoint.
It's
it's
super
useful,
so
this
is
more
like
looking
at
a
specific
cluster,
you
look
at
the
events
or
the
status,
so
this
is
one
where
you're,
not
thinking
in
that
global
scale.
B
A
A
What
are
my
slos
that
I
should
be
able
to
say
this
feature
is
healthy,
sometimes
there's
a
reason
not
to
add
a
feature,
a
metric,
but
we
try
to
document
it
here.
Sorry,
I
guess
I'm
not
reading
the
questions.
Maybe
I
should
be
okay
dependencies,
so
this
is
where
we
start
to
talk
about,
like
other
things
within
the
cluster
that
this
might
rely
upon.
A
A
Service
going
to
create
load,
balancers
or
whatever
in
the
cloud
provider,
so
there
may
be
scalability
issues
there.
Here
we
go
the
sizer
count.
I
guess
we
yeah,
we
had
it
there
and
then
what
is
the
impact
on
other
sli
nestle?
So,
if
you're
adding
some
feature
that
you
know,
that
adds
a
20-minute
sleep
and
cubelet
startup,
we
would
want
to
know
about
that.
A
A
How
do
you
you
know?
How
does
it
this
we
already
asked
about
failures,
but
we
want
to
make
sure
people
specifically
think
about
this
other
known
failure
modes
and
that's
it
like
so
really
like,
I
said
the
the
idea
is,
make
people
document
and
think
through
the
failure
scenarios,
make
people
document
and
think
through
as
a
operator
with
thousands
of
clusters.
B
B
People
have
gotten
used
to
answering
it,
so
things
have
gotten
significantly
easier.
One
final
note,
john:
I
have
gone
through
and
everything
that
was
graduating
or
that
already
had
one
of
us
assigned
either
you
or
I
I've
gone
ahead
and
added
it
to
the
assignee
column,
awesome
and
there's
a
bunch
of
net
new
stuff.
We're
gonna
have
to
split
up
so
fantastic,
okay.