►
From YouTube: 20211117 SIG Arch Prod Readiness
Description
No description was provided for this meeting.
If this is YOUR meeting, an easy way to fix this is to add a description to your video, wherever mtngs.io found it (probably YouTube).
C
David
sure,
so
we
issued
a
survey
back
in
q2.
It's
taken
a
little
while
to
collect
the
responses
and
then
analyze
them.
We
can
now
compare
those
results.
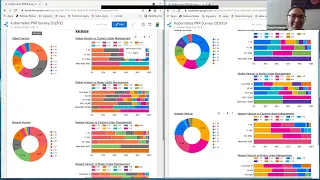
What
you're
seeing
here
on
the
left
is
the
survey
from
2021
trying
to
tie
it
as
closely
as
I
can
to
the
survey
from
2020
so
that
we
can
look
at
what
has
changed
over
the
course
of
the
last
year.
We
couldn't
do
that
with
last
survey
results
and
I'm
not
clever
enough
to
put
them
on
one
page.
C
C
The
number
of
clusters
that
are
are
under
management
actually
went
up.
So
the
we
have
a
lot
more
in
the
11
to
100
range
and
in
the
100
to
1000
range
than
we
did
last
year,
and
you
can
see
the
number
who
are
managing
relatively
few
clusters.
We
don't
have
as
many
of
those
anymore,
which
you
know,
I
think
supports
the
arc
that
we're
on.
We
saw
huge
growth
in
the
number
of
nodes
that
are
under
management.
C
D
C
C
E
C
A
C
On
the
situation,
but
they're
excluded
from
some
of
the
views,
so
there
are
some
views
where
we
say
for
the
people
that
answered
what
was
the
reason?
Why
and
I'll
call
them
out
as
we
get
to
them
so
like
for
the
case
of
doing
a
rollback.
For
instance,
the
percentages
are
based
on
people
who
responded.
C
E
C
E
E
C
A
C
A
A
Yeah
exactly,
I
think
we
should
note
these
potential
changes
like
the
n
minus
one
minus
two.
It
also
might
be
helpful
to
do
it
as
a
cumulative
thing
percentage
of
clusters
that
are
on
you
know,
n
n,
minus
one
or
greater
n
minus
two
or
greater,
or
maybe
even
the
reverse,
inverse
right
like
try
to
see
get
an
idea
of
like
in
the
past
how
what
percentage
have
advanced
quickly
versus
you
know
in
the
current
times
that
might
be
useful
as
opposed
to
individual
versions.
It's
sort
of
like.
C
F
A
I
think
that,
and
I
think
that
from
the
point
of
view
of
like
trying
to
determine
if
we're,
making
kubernetes
more
reliable,
which
this
is
a
very
much
a
proxy
measure.
But
if
people
are
more
willing
to
upgrade,
then
we're
probably
doing
a
better
job
of
of
making
it
things
more
reliable.
From
the
start.
A
C
All
right,
so
this
is
a
chart
of
minor
version.
Rollbacks
did
you
roll
back?
Did
you
roll
back
in
production
or
in
stage
or
in
prod?
And
if
you
rolled
back,
why
did
you
do
so?
Okay,
minor
version
rollbacks
appear
to
have
gotten
more
common
in
prod
in
dev.
I
think
it's
actually
good
to
have
the
minor
reversion
rollbacks.
It
means
people
are
likely
trying
them.
There's
a
survey
question
about
that
later
in
stage
I
could
believe
the
same
minor
version
rollbacks
in
prod.
E
A
C
C
C
E
C
C
G
C
G
C
A
C
A
The
other
thing
we
we
have
to
think
not
not
to
be
totally
self-serving
in
this,
but
like
from
the
point
of
view
of
the
prr
program
like
when
did
we
institute
actual
prr,
it
was
like
119
was
like
the
first,
the
pilot,
I
think.
Wasn't
it
was
it
yes,
it
was
so
almost
none
of
these
actually,
like,
I
guess
well.
C
B
C
E
I
think
the
real
test
is
going
to
be
when
we
run
this
next
year,
because
that'll
be
after
we've
had
like
a
full
year
of
mandatory
prr,
and
I
think
that
we'll
also
see
more
people
upgrading
two
versions
that
had
prr,
because
right
now,
there's
so
much
lag
that
the
vast
majority
of
the
clusters
on
both
of
these
surveys
never
had
any
features
touched
by
prr.
So.
A
C
C
So
the
patch
upgrades
actually
looked
a
lot
better.
It's
no
surprise
that
patches
are
more
stable
than
miners
right
I
mean
you
would
just
sort
of
expect
that
they're
also
easier
to
roll
back,
though
so
you
know
that
was
a
little
bit
odd.
So
overall
rollbacks
were
fairly
low
on
patch
versions
across
the
board.
I
think
that
most
of
this
is
reporting
and
and
they're
squished
slightly
differently.
C
C
You
recall
disabling
beta
features.
Are
you
allowed
to
use?
Do
we
disallow
some
beta?
Do
we
disallow
some
ga
and
the
answers
here?
They
look
to
my
eye
to
be
almost
identical
and
they
basically
support
a
hypothesis
of
people
just
use
whatever
the
defaults.
Are
it's
too
much
trouble
to
change
something
off
of
the
defaults
yep
so.
C
Is
almost
a
ga
it
does
and
that
chart?
Well,
we
don't
allow
disabling
g.
I
just
forgot
to
remove
that
so
yeah.
I
think
this
basically
tells
us
whatever
we
choose
as
defaults
is
going
to
have
a
tremendous
impact
on
what
ends
up
being
allowed
in
clusters.
I
actually
want
to
come
back
to
this
after
we
present
the
rest,
because
I
have
I
have
some
thoughts
on
what
this
means
for
how
we
need
to
approach.
Turning
that
on.
C
C
E
B
A
C
A
C
So
so
this
one
stood
out,
it
seems
to
be
persistent
over
time.
It
doesn't
seem
to
be
getting
worse.
It
does
seem
to
be
getting
more
fairly
distributed
when
you
compare
it
like,
you
know,
cluster,
no
matter
how
many
nodes
you
end
up
having
or
about
how
many
clusters
you
end
up
having
they're
starting
to
level
out,
there's
not
like
a
if
you
have
a
lot
you
turn
on
like
if
you
look
before
it
was
not
evenly
distributed
and
it's
starting
to
get
more
evenly
distributed.
Now,.
C
So
maybe
maybe
we're
leveling
out
the
troubleshooting
methods
was
pretty
cool.
You
recall
before
we
were
looking
at
it
trying
to
figure
out.
Why
don't
people
use
metrics
and
it
turns
out.
People
are
now
starting
to
use
metrics,
it's
catching
on,
which
which
is
good,
and
I
say
that
because
it's
the
smaller
categories,
you
know
when
you
get
to
lots
of
clusters,
everybody
uses
metrics,
but
when
you
only
have
a
few
we're
seeing
more
people
using
them
more
frequently
now.
B
C
I
think
is
good,
and
you
know
if
you're
trying
to
tie
it
back
to
prr
prr
is
where
we
started
requiring
those.
So
there
are
things
to
watch
now
that
used
to
be
the
case
that
there
might
not
even
have
been
something
to
watch
right.
There
may
not
have
even
been
a
metric
for
exactly
the
usage
of
events
becoming
slightly
less
frequent.
Surprised
me
pink
is
more
than
a
year
and
a
quarter
is
the
turquoise
color
and
the
use
of
events
becoming
less
frequent,
surprised
me,
but
it
doesn't.
I.
E
Mean
I
think,
that's
a
good
thing,
because
events
can
in
theory
be
lossy
and
some
people
even
will
split
their
events
like
into
a
separate
fcd
depending
on
load.
So
I
don't
think
that's
a
terrible
thing.
I
think
that's
actually
probably
a
good
thing
from
a
scalability
point
of
view
like
if
you
need
to
be
absolutely
correct.
Events
can
be
somewhat
unreliable.
D
C
C
C
I've
actually
been
wondering
whether
we
want
to
consider
trying
to
make
our
default
one
where
only
the
ga
apis
are
on
by
default,
and
we
require
effort
to
turn
on
new
beta
apis.
I
want
to.
I
want
to
take
away
the
beta
apis
that
already
exist,
because
that
would
cause
tremendous
problems
but
introducing
new
beta
apis.
C
A
It
is,
and
it
isn't
right
because
we've
already
just
done
this
exercise
in
the
last
half
a
dozen
releases,
where
we've
moved
a
lot
of
things,
long-standing
beta
things
into
ga,
but
so
in
that
sense
it's
not
as
much
of
a
if
you'd
said
that
two
years
ago.
I
think
that
would
have
been
like
you
know,
a
non-starter
but
anyway,
something
like
which
had
something
to
say.
C
Beta
apis
are
the
first
ones
that
stand
out
in
my
mind
in
some
ways
in
most
ways,
because
they
are
easier
to
exert
control
over.
We
already
have
all
the
mechanisms
in
place
to
do
it
it.
It
is
also
the
case
that
we
know
that
beta
apis
are
going
to
have
a
migration
involved
right,
because
because
we
enforce
that
right,
a
beta
api
from
the
api
perspective
is
still
beta
and-
and
that
is
different
than
a
beta
feature
that
may
not
have
a
new
api
service.
C
If
there
is
general
agreement
that
it's
a
thing
worth
pursuing,
we
could
consider
trying
to
write
a
cap
for
124
sort
of
time
frame.
Yep
yeah,
there's
some
benefit
to
trying
to
agree
to
it
before
the
next
beta
api
gets
added
because,
like
I
said
I
I
don't
want
to
stop
serving
any
of
the
beta
apis
that
are
already
served.
Imagine
the
destruction
that
would
happen
if
we
stop
serving
pdbs
early
right.
C
F
D
D
We
probably
won't
manage
to
do
that
on
time
for
123,
but
so
I
didn't
really
have
time
to
to
to
go
to
to
to
this
group
or
to
open
source
in
general
and
and
propose
it,
but
so
yeah.
I
don't
have
anything
anything
written
or
anything
like
really
that
I'm
ready
to
share,
but
but
I'm
definitely
supportive.
C
Okay,
I'll
think
about
I'll
see
if
I
have
time
to
write
up
some
rough
notes
before
our
next
meetings
talk
about
to
see
if
we
have
the
same
vision
in
our
heads
and
then
try
to
figure
out
where
to
take
it
from
there
did
anyone
else
I
stopped
sharing.
Maybe
early
did
anyone
else
have
any
questions
about
the
survey
or
anything
else.
They
wanted
to
dig
into
deeper.
A
In
this
release,
it'll
tell
us
more
in
this
survey.
It'll
tell
us
more
in
the
next
survey.
If
that
you
know
if
it's
the
same
versions
that
keep
getting
rolled
back
after
survey,
I
mean
obviously
age
out
eventually
so,
and
I
think
there's
probably
some
other
notes
too.
We
should
do
a
readout
with
the
broader
sega
architecture
which
we
could
do
tomorrow
or,
if
you're
not
prepared
to
do
that.
A
A
C
A
E
D
C
There
was
one
other
thing
that
I
wanted
to
make
sure
before
we
sort
of
tucked
the
survey
away
and
called
it
finished.
I
wanted
to
be
sure
that
we
felt
like
we
had
asked
the
right
questions
this
time
around
to
review
for
next
time.
Technically,
we
can't
like
change
the
questions
that
we
asked,
but
I
was
feeling
pretty
good
when
I
was
looking
through
what
we
had
collected
that
these
were
the
questions
that
I
would
want
answered
to
decide
whether
this
group
was
effective
or
not.
A
So
before
we
do,
the
next
survey
obviously
we'll
we'll
revisit
that
question
david,
but
I
think
that
let's
this
was
our
second
refinement
of
it
and-
and
you
did
the
analysis
and
that's
where
sometimes
you
you
start
to
realize.
Oh,
we
should
ask
this.
We
should
ask
that,
let's
do
the
comparative
analysis
against
the
two.
A
I'll
guess
I'll
say
that
first,
but
I
think
once
we
do
the
comparative
analysis
and
we
look
at
the
versions
I
mean
by
comparative
analysis.
I
mean
like
if
we
put
the
the
2020
and
the
2021
data
in
the
same
in
the
same
bigquery
data
store,
then
you
know
we
can
actually
do
direct
comparisons
where
the
questions
are
the
same
and
and
maybe
get
instead
of
eyeballing
it
from
one
to
the
other.
A
C
Yeah-
and
you
know
just
like
last
time-
we
went
through
to
refine
the
survey
before
we
sent
it
out.
I
think
this
time
we
used
just
about
all
the
fields
and
that
the
results
that
I
was
looking
at
I
felt
like
I
was
able
to
tell
a
story
about
this
is
how
people
go
about
debugging
problems.
This
is
how
prr
could
have
impacted
that
does
the
survey
support
or
not,
that
hypothesis
and
similar
things
for
the
rollbacks.
D
F
C
A
E
If
I
enabled
or
disabled
feature
the
only
things
that
would
possibly
be
affected
by,
that
would
be
the
things
using
that
feature.
So
as
a
reviewer,
I
said,
I
think
this
is
blocking.
I
don't
think
we
can
do
it.
This
way
like
we
need
to
be
able
to
isolate
out
the
changes,
whether
we're
using
the
feature
or
not,
and
so
the
feature
did
not
did
not
land
this
cycle.
E
As
far
as
I'm
aware,
I
mean
I
haven't
gone
back,
but
that
was
blocking
feedback
where
I
left
that-
and
I
just
wanted
to
like
make
sure
that
I
am
sharing
the
right
information
here,
because
I
got
a
little
bit
of
pushback.
That
was
something
along
the
lines
of
well.
You
know
when
you're
making
an
omelet,
sometimes
you
got
to
break
a
few
eggs
and
it's
like
well.
E
A
If
I'm
going
to
try
out
this
feature
on
this
node,
like
I
don't
want
anything
else,
scheduling
on
this
right
I
need
to
like
have.
I
need
to
be
careful
that
I'm
not
breaking
workloads
if
I'm
playing
with
a
new
feature,
but
I
mean
that
seems
like
a
reasonable
assertion.
In
my
mind,
I
don't
know
if
others
have
that
other
thoughts.
C
Unexpected
fan
out
from
setting
this
some
node
features
a
lot
of
some
that
I've
seen
appear
to
have
an
impact
on
the
way
that
say,
volume
mounts
happen
and
I
think
those
can
actually
interact
with
all
content.
Like
some
some
things,
I've
read
have
said,
and
then
you
reboot
the
node
and
when
that
is
a
requirement
for
making
whatever
switch
it
is
I
mean
sometimes
that
is
what
it
is
right.
I
don't
know.
I
doubt
yours
was
that
case,
because
you
would
have
noticed
that
and
understood
like
okay
to
turn
this
on.
E
Well
specifically,
says:
does
it
require
a
component
to
be
restarted,
and
so
I
got
a
little
bit
of
pushback
there,
because
our
documentation
says
that
the
way
that
you
set
a
feature
gate
is
with
a
command
line,
flag,
toggle,
and
so
it's
not
possible
to
like
turn
off
assuming
you're
doing
it.
That
way,
it's
not
possible
to
set
a
feature,
get
gate
without
like
restarting
the
component,
because
you
can't
change
its
command
line.
While
it's
running
now
the
tests
set
on
and
off
feature
gates
in
components.
E
E
Cool,
okay,
that's
great
feedback.
I
just
wanted
to
confirm
both
of
those
things,
because
I
know
that
we
previously,
like
the
the
prr
survey,
says
you
know:
can
you
disable
this
sort
of
like
without
restarting?
But
it's
not
that
you
don't
restart
the
particular
component
in
order
to
enable
or
disable
it
that
you
don't
have
to
restart
the
whole
machine.
A
The
whole
machine,
or,
for
example,
you,
if
you,
if
you
change
it
on
the
api
server,
it's
not
going
to
require
you
to
restart
the
cubelet
right
like
like,
let's,
okay,
right,
like
between
components,
right
kind
of
things.
So
it
sounds
like
maybe
a
little
tweak
to
the
guidance
might
be
in
in
order
there
to
make
that
explicit.
More
explicit.
E
C
E
E
Yeah
yeah
so
yeah
and
that
that
documentation
came
into
existence
in
response
to
me
asking
a
question
as
to
whether
or
not
it
existed,
and
the
answer
was
no.
So
it
sounds
to
me
like.
Potentially,
there
is
a
follow-up
action
here
to
further
document
expectations,
possibly
in
that
document
of
behavior
for
a
feature
flag.
For
example
like
we
expect
that
if
you
toggle
the
feature
flag,
it
won't
affect
things
that
are
not
using
that
feature.
Typically.
A
Okay,
thank
you
so
much
I
will.
I
will
try
before
I
leave
this
week
to
get
the
data
exported
from
my
private
bigquery
that
I
couldn't
figure
out
how
to
share
and
then
import
it
into
the
into
the
one
we
have
now
for
the
project
for
2020
survey,
and
then
we
can
hopefully
soon
go
through
and
do
that
a
little
bit
of
comparison
and
have
access
to
that
data
too,
and.