►
From YouTube: Kubernetes SIG CLI 02282018
Description
No description was provided for this meeting.
If this is YOUR meeting, an easy way to fix this is to add a description to your video, wherever mtngs.io found it (probably YouTube).
A
B
Let's
say:
try
to
bound
yourself
to
20
minutes:
Daniel,
Wow,
okay,
that'll
be
that'll,
be
tough,
but
we'll
try
it
okay.
So
a
week
or
two
ago,
I
sent
around
a
yeah
thanks.
Jeremy
good
luck.
Oh
week
or
two
has
sent
around
a
document
with
it
is
designed
for
moving
cube
control
up
to
a
to
be
a
control
plane
function
rather
than
a
client
function.
B
Okay,
so
this
is
sig
CLI,
so
I
have
a
background
section
here,
but
I'm
guessing
many.
If
not
most
of
you
already
know
what
cute
control
apply
does
stop.
Please
please
stop
me
if
that's
not
true,
so
I'm
gonna
skip
right
to.
Why
is
cute
control,
apply
a
good
thing
to
have
in
the
system,
and
this
is
I
have
I,
have
I
have
three
of
three
reasons
for
this.
B
Allowing
users
to
operate
on
and
edit
directly
the
the
types
that
submit
are
submitted
to
the
API
system.
It
lets
them
develop,
familiarity
with
the
API
system.
It
prevents
them
from
having
to
go
through
like
a
two-step
process,
where
first,
you
have
to
learn
how
to
operate
your
config
system
and
then
once
you
figure
out
how
to
get
that
to
admit
the
the
config
you
want,
then
you
have
to
figure
out
how
to
get
the
the
config
to
produce
the
object
you
want.
B
B
Instead
of
having
to
integrate
with
an
api
per
resource
per
operation
on
that
resource,
they
just
have
to
learn
one
API,
so
you
can
imagine
if,
if
like,
if
this
were
written
in
g
RPC,
for
example,
you'd
be
you'd,
have
a
you
know,
set
replicas
call
which,
like
you,
have
to
go
out
and
and
build
a
client
call.
This
several
except
replicas
method:
here
you
can
apply
a
manifest
that
only
has
the
the
the
replicas
field
or
you
can
use
the
the
sub
resource.
B
The
idea
is,
integrators
have
to
learn,
I
have
to
make
one
integration
point,
and,
and
finally
it's
this
is
the
building
block
that
enables
Brian's
declarative,
app
management,
which
I'll
send
these
slides
around
later.
You
can
click
on
that
link.
It's
a
long
document,
but
primarily
it
describes
a
workflow
where
there's
a
about-
maybe
not
primarily,
but
the
main
workflow
is.
Is
users
are
using
a
source
control
management
system?
B
B
B
B
So
so
what
is
what
is
it
not
good,
for
it
is
not
good
for
imperative
commands.
You
should
not
use
declarative
principles
to
charge
credit
cards.
You
should
not
use
them
to
launch
missiles.
You
should
not
use
them
to
open
the
pod
bay
doors.
However,
some
imperative
commands
have
reasonable
declarative
formulations,
like
you,
can
imagine
a
API
object
with
neo
pod,
a
pod
bay
door
position
equals
and
it
accepts
either
open
or
closed.
Like
that,
that's
a
reasonable!
That's
a
reasonable
thing!
You
should
not
have
a
launch
missiles
true/false
right.
B
So
why
is
it
hard
it's
hard
because
we
are
deducing
user
intent
from
the
last
thing
they
wanted
and
the
thing
they
want
now
I
think.
Actually,
you
need
an
entire
human
brain
to
do
this
in
the
general
case,
so
our
API
system
is
restrict
is,
is
and
possibly
should
be,
more
restricted
in
some
areas
to
enable
this
to
be
done
correctly
for
our
API
objects
and
I
am
not
aware
of
any
other
system
out
there.
That
does
this
particular
thing.
B
So,
that's
why
that's
that's
an
overview
of
why
it's
hard
a
lot
more
specifics
in
a
minute,
so
why?
What?
What
is
this?
What
are
we
trying
to
accomplish
apply?
The
goal
of
the
function
of
the
feature
is
to
allow
users
and
systems
to
cooperatively
determine
the
desired.
The
desired
state
of
an
object
and
the
goal
for
this
design
is
that
the
the
control
plane
solves
as
many
of
the
problems,
and
it
is
reasonable
for
the
control
plane
to
solve.
B
Specifically,
some
non
goals:
I
am
NOT,
focusing
on
multi-object
apply
that
has
to
be
implemented
with
a
client-side
loop.
For
now
it
may
be
possible
to
move
parts
of
that
into
the
server
in
the
future,
but
that's
left
for
future
work.
For
so
today's
proposal
is
just
about
the
single
object
case
and
honestly,
you
need
a
working
single
object
case
before
you
can
think
about.
B
The
multi
cog
object
cases
anyway,
I'm
not
providing
an
API
that
only
performs
merges
I
think
that
we
definitely
need
that
in
the
future
and
both
potentially
both
to
weigh
in
three-way
merges
and
I
think
that
it
is
proper
for
the
control
plane
to
do
that
and
offer
that
as
an
API.
But
that's
future
work
is
not
what
I'm
solving
here
and
finally,
there's
some
sources
of
user
confusion
that
really
can't
be
fixed
with
code,
or
at
least
not
with
control,
plane
code
and
so
two
examples.
B
B
This
is
sort
of
working
as
intended,
so
we
need
to
figure
out
how
to
have
a
document
and
and
help
users
do
the
right
thing
and
there's
also
some
user
confusion
where
our
API
is
unclear
or
maybe
under
validated
like.
If
you
change
the
service.
The
the
example
I've
got
here
is:
maybe
you
change
the
service
type
from
load,
balancer
from
a
node
port
to
load
balancer?
Does
that
really
work?
B
I'm,
not
sure?
Ok,
so
I
have
two
chapters
here:
chapter
one
is
about
the
first
document
I
sent
around,
which
is
sort
of
the
the
half
of
the
problem
that
I
didn't
really
see
people
attempting
to
solve-
and
this
is
I've
called
it
user
intent.
Lifecycle
management
sounds
fancy
so
and-
and
so
some
examples
of
this
of
this,
this
category
of
problem
user
posts
changes
something
a
prize.
You
could
have
surprised
because
the
post
didn't
record
your
last
applied
state.
You
do
an
apply.
You
do
an
edit
or
get
edit
put
cycle
and
apply
again.
B
B
You
take
over
a
bunch
of
fields
that
were
defaulted
and
you
didn't
really
intend
to
own.
Well
now
you
own
them.
You
tweak
some
annotations
like
say
the
last
applied
state,
annotation
and
very
strange
things
happen.
And
lastly,
if
one
user
apply
something,
and
then
another
user
applies
something
else,
that's
unrelated
to
the
first
thing.
Very
strange
things
will
happen,
because
the
last
applied
state
is
not
related
to
the
thing
that
the
second
user
is
applying.
B
So
why
is
it
hard?
We
know
it
must
be
hard
because
there's
a
bunch
of
smart
people
that
have
been
working
on
it
for
the
past
two
years
and
yet
there's
still
a
bunch
of
bugs.
So
I
came
up
with
two
sort
of
primary
reasons
that
are
preventing
us
as
a
group
from
from
solving
it.
I
think
the
the
practical
reason
is
that
there's
just
too
much
stuff
out
there,
you
have
to
change
to
get
a
fix
in
you
have
to
change
the
client.
You
have
to
change
the
schema.
B
B
B
B
Don't
have
a
slide
on
that,
so
it
is
not
a.
It
is
not
a
security.
Boundary
concept,
it
is
a
maybe
be
better,
is
a
like
a
work
denta
fire
key
right.
So,
if
you're
applying
something
that's
tracked
in
your
source
control,
no
matter
who
applies
it
that
all
needs
to
work
off
the
same
last
applied
annotation.
If
yeah,
maybe
actors
isn't
okay
term,
it
sounds.
C
B
Provided
by
a
client
is
it
provided
by
a
server
yeah?
If
you
read
the
doc,
there's
actually
three
places
which
the
I
mean.
Obviously
it's
subject
to
change,
but
there's
three
places
that
this
can
be
derived
from
I
I
suggest
allowing
people
to
just
set
it
directly
in
as
a
field
in
metadata,
so
that
if
you
want
to
ensure
that
everyone
working
out
to
the
same
source
control
system
uses
the
same
client
ID,
you
can
accomplish
that
just
by
putting
it
in
I
suggest
further,
allowing
it
to
be
a
query
parameter.
B
D
So
it's
the
reason
why
I
suggested
actor
David
is
because
the
canonical
example
here
is.
You
know
you
have
multiple
actors
that
are
coming
together
to
put
together
as
both
this
back
in
the
status
of
a
particular
resource.
So
it
could
be
the
the
person
with
cube
control,
that's
actually
putting
some
stuff
out
there.
You
could
have
auto
scaling,
that's
actually
going
through
and
acting
on
it.
D
You
have
somebody
doing
defaults,
you
have
a
you
know
a
mutating
webhook,
that's
going
through
and
adding
a
bunch
of
stuff
to
a
particular
pod
template
that
type
of
thing,
and
so
you
can
see
how
like
there's
multiple
actors
that
are
all
going
through
to
construct
the
final
form
of
the
resource,
and
so
that's
really.
What
client
ID
is
is
which
person
is
actually
doing
which
part
of
the
you
know
certain
certain
layers,
yeah.
B
D
B
D
B
Like
apply
key
or
something
like
that,
yeah
yeah,
I,
don't
know
anyway,
we
can
debate
that
in
the
document
and
and
so
the
future
the
future
of
this
is
on.
My
various
zoom
windows
are
covering
up
this
part
of
my
slide.
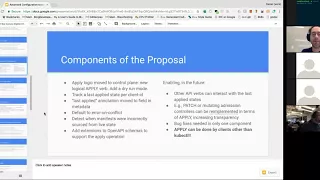
Other
API
verbs
can
interact
with
applied
States.
This
is
because
we
track
them
in
the
control
plane,
so
we
can
make
say
patch
or
get
put
produce
warnings
when
you're
setting
fields
that
somebody
else
thinks
they're
managing.
B
B
B
I
I,
don't
foresee
the
patch
verb
going
away,
but
I
do
think
that
most
people
who
are
currently
calling
strategic
merge
patch
will
be
better
off
if
they
were
calling
apply
now.
But
they
can't
right
now,
because
we
don't
track
multiple
appliers
and
and
primarily
it's
controllers,
calling
strategic,
merge
patch,
so
benefits
of
moving
it.
All
in
one
place
is
bug,
fixes
are
like
98%
server-side
and
you
don't
have
to
worry
about
clients
nearly
as
much
and
and
lastly,
and
it's
bolded.
B
B
B
B
Yeah,
so
it
would
be
basically
a
map
from
the
client,
ID
or
user
key
or
actor
or
workflow
identifier,
whatever
we
want
to
call
it
to
the
actual
object
that
they
sent.
If
you
read
my
doc,
I
argue
that
this
should
roughly
double
the
size
of
our
objects,
because
the
case
where
people
were
multiple
people,
this
the
same
field
should
be
rare.
B
C
B
C
B
B
F
Okay,
some
questions
like.
Why
would
be
we
actually
keep
the
last
applied
state
and
the
metadata
which
will
be
sent
back
and
forth
to
users
and
to
the
server
when
only
the
actual
actor
that
cares
about
the
last
applied
state
is
the
apply
method
on
the
server
I
know
that
a
client
will
be
today
I'm.
Seeing
oh
there's
like
this
many
I.
B
Have
to
I
have
two
reasons
for
I
have
two
answers
for
that.
One
is
checking
it
in
metadata.
It's
a
first-class
citizen
makes
it
easier
more
straightforward
for
server
other
server
verbs
to
use
that
information
to
provide
like
warnings
or
helpful
helpful
error
messages.
The
other
is
that,
without
supplying
the
state
as
a
visible
object,
the
apply
operation
becomes
dependent
on
hidden
state
like
what
you'd
apply
to
will
do
different
things
depending
on
what
is
in
that
last
applied
annotation.
B
B
Replicas
field:
you
can
look
at
the
object
and
see
if
there's
a
see,
if
there's
a
thing
in
there
it
also
if
a
user
tries
to
apply
an
object
which
has
to
has
this
field
set,
then
we
know
that
the
user
must
have
done
a
get
and
edited
something
in
andrea
and
we
can
tell
them
hey.
It
looks
like
you
use
this
wrong
workflow.
You
can't
do
that.
D
So
the
question
was
asking:
is
you
know,
that's
a
map?
Why
is
it
not
a
list
and
I
think
there's
two
models
is:
maybe
it
could
be
a
list?
It
is
it's
not
an
important
distinction
at
this?
No
because,
because
a
list
in
place
a
list
implies
order
and
that
order
could
act.
So
the
question
is
actually
an
hour.
We
prevent
two
things
from
having
this:
where
do
we?
Let
them
have
the
same
field
and
we
have
a
deterministic
way
to
actually
determine
you
know
who
overrides
him.
Yeah.
B
We
we
allow
people
to
both
mention
the
same
field.
If
you
look
in
the
doc,
there's
a
fairly
precise
set
of
rules
for
who
wins
and
and
there's
I
have
the
concept
of
a
field
manager
and
when
you
make
a
change,
and
somebody
else
has
it
in
their
lives.
Under
what
circumstances
do
you
become
the
manager
and
under
what
circumstances
do
you
not
become
the
manager
after
read,
more
yeah
yeah?
B
So
I
think
one
important
thing
to
to
catch
here
is
I'm
I'm,
not
trying
to
manage
a
series
of
patches
that
are
applied
in
a
certain
order
to
construct
the
live,
State
I'm,
not
trying
to
do
that.
The
last
applied
state
is
historical
record
of
what
various
workflows
have
attempted
to
do.
So,
though,
whenever
a
new
one
comes
in
at
that
point,
the
live
State
is
modified
accordingly,
but
we
don't
like
reconstruct
the
live
State
from
first
principles
by
adding
up
all
the
all
the
all
the
things
in
this
list.
B
Don't
think
you
can,
because
the
true
state
of
the
object
is
going
to
depend
on
the
order
in
which
the
patches
were
applied
and
there's
also
until
I
I
think
eventually
will
probably
take
like
stuff
from
defaults
and
mutating
webhooks
and
put
that
in
as
its
own
records
just
just
for
visibility,
but
until
we
do
that,
like
there's,
there's
sources
of
changes
that
wouldn't
come
through
the
apply
system.
So
that
smells
bad
to
me.
B
I
think
yeah,
I
think
the
like
built.
The
stack
of
patches
that
add
up
to
a
certain
thing
is
order
dependent,
and
then
you
have
a
problem
where
what?
If
you
want
to
change
the
one
in
the
middle
and
the
other
actors
that
produce
later
ones,
aren't
online
to
see
if
they
need
to
change
their
thing.
In
response
to
your
thing,
so
I'm,
just
not
trying
to
solve
that
problem.
B
B
Super
ambitious
goal
alpha
and
111
I
think
I.
This
is
this
is
a
large
change
that
affects
a
lot
of
the
system.
I'm
thinking,
maybe
a
feature
branch-
is
going
to
be
a
good
idea
for
something
on
this
order.
Otherwise,
I
don't
know
how
we're
gonna
be
able
to
work
together
to
put
it
together,
but
it
has
ideas.
Let
me
know
so.
C
C
C
F
B
F
B
E
B
E
E
B
Okay,
so
there
is
a
second
half
of
this
slide
deck
which
I
won't
go
through
now,
but
I
will
circulate
the
second
design,
and
these
slides
around
the
cig
later
today,
I
hope
to
represent
these
slides
at
sig
API
machinery
in
a
couple
hours.
That'll
be
my
third
time
doing
this
yeah.
So
look
at
the
design
Docs,
please
give
me
feedback
yeah.
F
F
We
that
will
work
with
the
server-side
printing
will
return,
hopefully
the
same
exactly
saying:
values
ie
as
you
would
normally
with
cube
CD
I'll
get
I'm
currently
working
on
adding
more
tests
that
will
ensure
that
whatever
we
defined
for
the
service,
a
printing
is
actually
working
properly
on
the
client.
I
have
a
PR
open,
adding
this
test
and
fixing
several
places
life
that
I've
already
identified
when
writing
the
tests.
G
So
basically,
like
not
just
said,
we
did
a
label
or
we
did
add
a
an
experimental
flag
for
users
to
test
service
at
printing.
It
is
off
by
default
and
some
issues
we
found
while
implementing
this
on
the
client
side
was
that
sorting,
wouldn't
work.
The
way
it's
currently
implemented
with
a
tabular
response
from
the
server,
so
I
have
pasted
a
link
to
a
Google
Doc
detailing
this
further,
so
I'll
skim
over
it,
but
basically
with
sorting
we
are
proposing.
Creating
a
new
sorter
specifically
knows
how
to
sort
people
responses
from
the
server.
G
C
Well,
let's
write
there:
do
we
consider
that
a
feature
or
a
book?
So
if
I
request
services
and
pods
and
I
want
to
sort
my
name
do
I
expect
to
get
all
my
paws
sorted
by
name
and
then
all
my
services
sort
of
my
name
or
do
I-
expect
an
interleaved
list.
Currently
you're
gonna
get
attorney.
Please
list,
that's
what
it
currently
does.
Yes,
you
should
decide
whether
that's
a
feature
or
a
book.
The.
E
D
E
Like
so
one
one
reason
to
select
multiple
things
is,
if
you
want
to
get
all
your
deployments,
your
staple
sets
they
replica
sets
and
your
demon
sets
right
because
you
want
to
know
like
what
are
all
the
workloads
out
running
and
what
are
all
my
applications
right,
and
so
the
application
cap
is
really
about
like
unifying
multiple
pieces
or
providing
abstractions
that
are
higher
level
right.
So
in
that
case,
you
no
longer
need
to
select
deployments
and
staple
sets
to
figure
out
your
things.
You
just
ask
for
the
applications
right.
D
Yeah
I
think
I'm.
Just
in
my
mind,
you
know
an
application
is
a
higher
level
concept
that
really
isn't
part
of
kubernetes
core
and
so
that
I
like
seeing
the
applications,
be
a
you
know,
a
CRD
that
sort
of
a
layered
concept
on
top
of
Corker
Burnett
ease,
but
the
idea
of
hey
I
want
to
be
able
to
like
extract
a
bunch
of
information
and
display
it.
Whether
it
be
like
show
me
all
the
objects
that
have
this
latest
setter
or
whatever
I,
don't
think
it
I,
don't
think
we
want.
E
E
D
E
D
Right
now,
I
do
cute
control
get
all
and
I
don't
get
all,
but
what
I
do
get
actually
shows
me,
multiple
things
or
I'm
doing
something.
I'm
like
I
want
to
show
a
deployment,
plus
all
the
downstream
objects
from
that.
So
I
know
that
okay
I,
want
to
show
the
deployment
plus
the
the
replica
sets,
plus
the
pods
that
all
have
the
same
label.
So
there's
two.
C
C
F
F
E
E
F
There's
there's
additional
problem
to
that
which
goes
into
do
we
honor
in
case
of
a
server
site
printing.
We
return
a
certain
amount
of
data
for
every
single
resource,
and
then
we
can
additionally
include
the
entire
object.
So
this
complicates
the
sorting
up
to
a
point
where
you
can
either
specify
the
column
name,
because
currently,
if
you
want
to
sort
by
something,
you
have
to
specify
JSON
path
to
the
field
that
you're
seeing
which
is
not
not.
And
it's
not.
You
can't
come
up
with
this
idea
easily.
F
You
need
to
know
the
fields
JSON
path
to
get
the
name.
If,
with
the
service
type
printing
we
could
go,
we
can
simplify
the
sorting
by
allowing
the
user
to
specify
the
name
of
the
columns
that
are
being
printed
and
only
full
back
to
the
JSON
path.
If
he
cares
more
about
it,
but
we
could
actually
entirely
get
rid
of
the
JSON
path
and
only
sorted
by
the
default
columns
or
a
returned
by
DM.
The
server-side
critic,
which
there.
C
Are
I
think
the
first
question
answer
is:
are
we
willing
to
restrict
what
sort
I
can
do?
It
can
do
a
certain
number
of
things
today?
We
willing
to
restrict
it
in
the
next
release
or
the
release
after
that,
in
a
way
that
some
users
may
be
unhappy
with
that's
going
to
be
one
question
for
us
to
answer
and
then
once
you've
decided
on
that
deciding
whether
sorting
is
a
client-side
activity
or
a
server-side
activity
is
an
important
next
step.
There
are
arguments
to
be
had
both
ways
right.
C
Returning
the
correct
order
from
the
server
makes
it
easier
on
clients.
However,
it
limits
that
client
right.
If
custom
columns
are
computed
at
client
side
based
on
the
return
of
the
data,
then
it
becomes
natural
to
want
to
sort
on
your
custom
columns
if
we
are
not
going
to
restrict
people.
So
are
we
prepared
to
answer
those
questions
now
or
does
it
need
to
go
to
the
mailing
list
so.
F
Here's
the
here's,
the
proposed
solution
to
that
I'm,
hoping
to
enable
the
server
start
printing
by
default
in
112
with
the
server-side
printing.
We
need
to
use
the
new
sorting
mechanisms,
but
we
will
still
provide
the
fallback
for
I,
don't
know,
probably
even
up
to
two
releases
for
friendly-looking
all
pretty
in
that
clear.
Do
we
have
to
use
server-side.
C
C
C
F
F
Yeah
and
I
agree
with
what
Joe
said.
Many
cleanings
clients
will
end
up
doing
their
own
sort
and
regardless,
although
in
case
of
of
the
Pekka
nation,
you
still
need.
You
still
expect
that
you're
gonna
get
I,
don't
know
fifty
first
parts
and
that
randomly
return
values
from
four
pots.
So
pagination
and
sorting
those
Houston
I.
D
C
Items
that
still
I
can
change.
They're
gonna
want
to
people
with
all
that
paginations
just
waited
to
me.
I
happen
to
many
of
these
implemented.
They're
not
me
play
nice
with
an
attempt
to
sort
pagination
works
by
leveraging
Etsy
first
and
don't
have
at
least
my
knowledge
a
way
to
introspect
the
actual
items.
So
you
may
be
able
to
sort
based
on
keyed
there's
no
way,
you'd
be
able
summation.
D
C
D
B
D
So
the
other
question
is:
is
that
there's
this?
The
previous
question
was
like:
what
do
you
do?
I
mean
it's
like:
how
do
you
do
sorting
when
you
have
a
query
that
covers
multiple
types
right?
Do
we
need
to
have
a
single
query
cover
multiple
types?
Would
it
be
easier
because,
again
there
now,
the
question
is
with
pagination?
How
do
you
play
as
you
do
one
type
and
then
paginating
that
give
the
next
type
and
you're
in
early?
What
the
hell
zq
does
server-side
get
support.
Multiple
types
at
the
moment
doesn't.
C
C
C
C
G
C
D
I
said
I
mean
there
might
be
a
scenario.
This
is
something
worthwhile
of
document,
at
least
being
clear
of
like
hey.
If
you
do
a
cute
control
get
of
a
certain
form,
you'll
get
pagination
and
you'll
get
streaming
behavior,
so
that
I
think
there's
a
difference
between
sort
of
a
a
pretty
good
versus
a
streaming
yet,
and
we
may
want
to
tease
that
apart
and
be
more
clear
about
that,
because
there
are
gonna
be
sooner.
That's
where
people
want
to
list
up
with,
like
you
know,
gazillion
things
they
want
true
paging
right.
F
No
more
topics
actually
but
I'm
I
doubt
we
are
able
to
discuss
it
totally.
Today,
it's
a
little
bit
longer
topic
and
the
testing
and
the
generators
are
another
topic.
I
think
we
can
leave
it
off
for
the
next
six
UI.
It's
a
bigger
topic
that
I
want
to
discuss
same
advice
phone
for
the
for
the
printers
and
the
cube
CDL
bits
that
I
need
updates.
F
F
E
That's
that
sounds
good
to
me.
If
you
want
to
just
start
taking
on
the
responsibilities,
maybe
you
can
leave
the
next
big
CLI
meeting,
okay
and
then
yeah,
we'll
figure
out
for
the
remaining
stuff,
I
think
for
the
next
release.
Once
once
the
we
hit
close
to
release,
you
can
help
with
some
of
the
responsibilities
right
that.