►
From YouTube: 20200527 Cluster API Office Hours
Description
No description was provided for this meeting.
If this is YOUR meeting, an easy way to fix this is to add a description to your video, wherever mtngs.io found it (probably YouTube).
A
All
right
welcome.
Everyone
today
is
Wednesday
May
27th.
This
is
the
cluster
API
office
hours.
As
always,
please
follow
the
scenes
they
have
code
of
conduct
and
the
meeting
etiquette
I
use
the
raise
hand,
feature
zoom
if
you'd
like
to
speak
and
feel
free
to
add
any
agenda
items
that
you
may
have
in
the
discussion
topics
or
if
you
have
any
general
questions
for
the
group.
There
is
a
section
right
here
to
do
so
and
then
also,
please
add
your
name
to
the
attendance
to
the
attendee
lists
right
here.
A
Okay,
so,
as
always,
we
usually
start
with
a
little
welcome
introduction
for
anyone
who's
new
and
who
wants
to
introduce
themselves
to
the
group.
So
if
this
is
your
first
time
joining
or
if
you
haven't
been
here
in
a
while-
and
you
just
want
to
say
who
you
are
and
what
you
do,
why
you're
interested
in
cluster
API
now's
your
chance
to
do
so.
I'll
go
ahead
and
mute
myself
and
she'll
Fergus
pick
up.
A
A
A
B
B
Yeah,
the
first
one
is
BSA
slash
shout
out
to
do
you
know
it
folks,
we
have
merged
k,
CP
adoption
functionality.
What
this
will
allow
you
to
do.
It
is,
if
you
have
v1
out
for
two
machines,
for
example,
there
are
controlling
machines.
Now
you
can
create
a
case.
Ep
reference
in
case
EP
will
adopt
those
machines.
This
is
a
tldr,
of
course.
But
yes,
if
you
have
you
know,
that's
this
functionality
like.
B
B
We
come
up
with
like
pretty
reasonable
solutions
for
the
short
term,
which
is
to
use
the
patch
with
a
resource
version
attached
to
it,
which
will
use
optimistic
locking
to
like
to
make
sure
that,
like
you
always
on
the
latest
resource
version,
before
applying
or
like
adding
a
new
condition
or
up
to
anyone
on
this,
like
the
next
point,
is
actually
the
Machine
health
checkup
also
has
an
amendment
PRI,
which
is
almost
ready
to
go.
So
if
you're
interested
there
is
the
PR
link
here,
it's
pretty
short
and
sweet.
B
A
A
This
is
more
like
if
you
have
any
questions
about
like
cluster
API
and
anything
at
all
that
you
know,
people
here
could
help
answer
filter
to
add
them
throughout
the
meeting,
and
we
won't
necessarily
spend
too
much
time
discussing
them,
but
we'll
come
back
at
the
end
and
make
sure
all
the
questions
are
answered,
or
at
least
written
down,
but
for
now
I'll
just
move
on
to
discussion
topics
which
is
the
only
thing
with
items
in
there
for
now
so
I
think
Andy.
You
had
the
first
one.
Why
thank.
C
You
so
Justin
since
you're
here
I,
wanted
to
ask
about
this
one
and
see
if
there's
anybody
from
Google
who's
got
some
time
to
work
on
this.
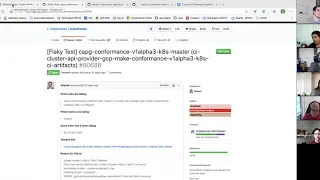
The
summary
on
this
flake
is
that,
based
on
the
machine
name
and
the
GCP
project,
name
of
which
there
is
a
pool
of
projects
that
prowl
uses,
if
the
combination
of
the
machine
name
and
the
project
name
in
gzp
is
greater
than
63
characters,
then
we
can't
spin
up
instances
or
we
can.
C
D
E
D
C
Yeah,
ideally,
the
only
thing
that
we
potentially
control
could
control
would
be
the
instance
name,
since
the
project
name
is
just
from
that
pool
of
available
projects
that
prow
has
access
to.
So
maybe
we
could
hash
that,
but
anyways
I
wanted
to
bring
this
up
just
to
see
like
I
did
see
that
someone
got
assigned
five
days
ago,
but
I
don't
know,
I,
don't
know
this
person
and
just
wasn't
sure
if
there
was
any
movement
here.
D
C
Which
so
what
happens?
Is
we
have
cloud
in
it
for
bootstrapping
configured
to
use
the
local
hostname
value
from
the
instance
metadata
when
registering
the
node
local
host
name
is
the
combination
of
the
instances,
name,
dot
c
dot
project
name,
dot,
internal,
and
so,
if
that
total
string
is
more
than
63
characters,
then
you
end
up
with
the
node
being
unable
to
register,
because
we
store
the
host
name
of
the
node
in
a
label.
So
we
could
potentially
find
a
way
to
get
GCP
to
do
different
host
names.
But
I
that's
gonna
happen.
D
Yes,
that
is
like
the
ones
that
would
normally
happen
normally
happen.
Are
the
the
kubernetes
sorry
that
GCP
resources,
for
example,
being
too
long
or
like
you
know
like
on
AWS,
the
auto
scaling
group,
or
something
main
being
too
long?
But
yes,
this
is
I'll.
Take
a
look
at
this.
This
is
a
little
different
from
what
I
thought
it
was
okay.
Thank
you.
F
So
today,
I
started
playing
a
bit
with
failure,
reasons
and
failure,
messages
on
the
cat,
V
side
and
with
machine
hull
checks,
and
we
do
have
certain
conditions
where
we
are
on
some
terminal
states
where
we
we
won't
need
any
specific
remediation
or
at
least
automatically
mediation,
and
we
mostly
need
the
operator
to
go
and
figure
things
out.
Things
like
the
operator
needs
to
free
some
space
before
being
able
to
create
the
machines.
So
I
wanted
to
ask
this
group
if
this
is
something
that
makes
sense
for
other
providers
to
have.
F
B
G
So
from
what
you've
just
described,
I
actually
think
I've
seen
a
scenario
that
might
be
similar
before.
Maybe
you
confirm
this,
but
when
I've
been
playing
with
like
spot
instances,
there's
certain
scenarios
like
the
spot
price
being
two
though,
where
Amazon
won't
give
you
a
new
instance.
So
if
that
instance
comes
up,
it
will
try
to
go
spelled
the
Machine
Health
Check
deletes
it,
and
then
you
end
up
in
a
hot
loop
of
creations.
Is
that
the
same
sort
of
scenario.
H
H
The
other
thing
is
it
almost
feels
like
we
would
want
to
make
m8c
decide
whether
or
not
to
delete
the
machine
based
on
a
condition
of
the
machine
set
as
a
whole.
So
maybe
you
can
set
like
in
under
discs
and
all
under
this
condition
and
the
Machine
set,
because
the
data
store
is
full
spot
price
is
too
low,
but
don't
do
remediation
I,
don't.
F
G
I
was
thinking
that
it
would
have
I,
don't
know
how
the
back
office
work
but
I
know
that's
like
a
key,
so
you
could
put
like
the
Machine
health
checks,
namespace
name
in
as
a
key,
and
then,
if
it's
for
the
same
machine
health
check
deleting
machines
in
a
hot
loop,
it
would
back
off
and
eventually
only
be
deleting
machines
for
that
like
every
15
minutes.
That
would
then
stop
the
machines
from
going
and
users
will
see.
You
know
what
the
error
was.
Do
you
think
that
would
be
a
solution
that
would
be
suitable
or.
A
A
C
A
A
All
right,
everyone
is
feeling
shy
today,
okay,
so
let's
move
on
to
the
triage
I
had
this
time
open
and
it's
gonna
be
really
short,
because
there's
only
one
issue.
Actually
that
is
not
triaged.
Can
you
all
see
the
my
screen
with
that
issue?
Yeah,
yeah,
okay,
so
there's
only
one
that
doesn't
have
a
milestone
assigned,
and
it's
this
one
well
I!
Think
you're
in
here.
Do
you
want
to
talk
about
this?
A
little
bit.
J
B
Yeah,
so
I
can
see
either
way
like
when
we
released
your
tweet
do
with
the
time
not
to
tag
any
cup.
The
images
mostly
because
we
don't
want
users
to
use
them
like
in
production
or
like
theirs,
and
we
should
make
sure
that,
like
folks,
understand
like
there
are
no
guarantees
on
this
code
and
it's
only
used
for
development
in
testing
I'm,
fine,
adding
them
to
the
staging
repo.