►
Description
No description was provided for this meeting.
If this is YOUR meeting, an easy way to fix this is to add a description to your video, wherever mtngs.io found it (probably YouTube).
A
I'll,
come
on
to
the
second
kickoff
meeting
of
control,
plane,
lifecycle
management,
but
extreme
the
cluster
API
and
laughing.
We
discussed
that,
after
going
through
the
initial
set
of
points,
we
decided
that
we
should
probably
start
with
three
main
proposals:
that
how
can
we
basically
manage
the
control
planes
in
a
different
ways
that
so
I
could
quickly
draft
a
proposal
on
one
of
the
approaches?
So,
first
of
all,
what
were
the
three
approaches?
A
So
one
approach
was
that
how
can
we
host
the
control
plane
on
a
management
cluster
which
are
hosted
on
the
management
cluster
was
when
I
first
won
their
approaches?
What
we
are
doing
right
now,
where
we
have
a
dedicated
master
machine
for
the
control
center
hosted
on
this
dedicated
muscle
machines
always,
and
the
third
approach
was
that
we
wanted
to
check
the
possibility
that
which
is
possible
that
by
a
cluster
API,
we
can
also
make
use
of
many
children-
disabilities,
for
example,
the
cliche
controller.
A
It
can
talk
to
G,
ke
e
K
s
and
so
on,
and
we
can
alter
the
control
claims
from
there.
Then
we
managed
this
triple
stack.
So
out
of
this
three
proposals,
I
have
already
provided
a
link
in
the
document
to
the
first
proposal,
which
is
basically
for
the
control
plane
posted
on
the
management
cluster.
So
if
you
guys
have
any
other
agenda
items
or
something
please
feel
free
to
add
already,
and
if
it's
not
the
case,
I
can
quickly
go
through
the
proposals.
A
Okay
and
start
already
so
in
this
proposal
and
please
feel
free
to
ask
questions
and
open
between.
Otherwise
we
have.
We
have
seen
this
pattern
that
it
becomes
one
directional
and
then
we
end
up
with
we
end
up
with
only
one
way
through,
and
this
is
definitely
a
thing
Cronus.
It
would
be
very
nice,
as
you
can
later
on,
go
through
it
and
provide
questions
with
this
one
from
so.
First
of
all
in
this
approach,
what
we
wanted
to
do
is
that
motivation
is
already
what
I
talked
about
for
them.
A
So
motivation,
more
or
less
is
that
we
wanted
to
check
these
possibility
as
well.
Where
is
it
really
possible
that
we
can
make
use
of
the
control
plane
or
we
can
treat
the
control
plane
in
terms
of
the
kubernetes
primitives?
So
you
know
cuban,
it
is,
does
a
great
job
of
managing
the
workload
of
the
applications,
the
containerized
workload,
and
what
is
this
control
plane?
Components
itself
can
become
the
workload
of
one
other
criminal
discussed,
which
we
are
referring
now
as
the
management
cluster
here.
A
A
Now,
ok,
so
the
first
goal
here
is
that,
as
I
said,
can
we
really
use
the
goal
is
to
provide
a
mechanism
where
the
deployment
instead
fuels
and
so
on
can
be
made
use
of
to
describe
the
control,
plane
components
of
the
kubernetes?
The
other
goal
we
could
quickly
think
of
was
how
to
optimize
the
cost
of
this
control
plane
component.
A
So,
for
instance,
in
certain
ways,
if
I
note
that
the
key
one
WordPress
going
to
be
very
small
and
I
might
want
to
really
be
willing
to
give
very
small
amount
of
CPU
and
memory
to
this
particular
control.
Pen
and
that's
all
I
can
say
one
certain
computational.
This
was
this
becomes
very
important
goal
specifically
for
the
large
skill
providers,
where
we
want
to
manage
hundreds
or
skip
my
disclosures
for
you
from
outside.
A
So
that's
one
of
the
goal
here
then,
in
terms
of
the
availability
of
the
control
plane,
so
here
I
want
to
do
put
it
in
a
way
that
we
should
be
able
to
it's
not
highly
available,
but
you
should
be
able
to
make
provide
a
mechanism
where
the
control
plane
pods
are
lists
affected
in
the
scenarios
or
descriptions
where
the
given
machines
machinery
starts
upon
and
so
on.
So
we
will
see
ahead
that
how
this
can
be
achieved
with
the
given
proposal,
then
the
third.
The
fourth
goal
is
little
interesting.
So
here
this
becomes.
A
This
is
actually
very
important
in
cases
where
the
providers
are
intentionally
willing
to
not
offer
the
control
plane
of
civil
protester
to
the
end-users.
So,
for
example,
gke
kind
of
experience
where
you
basically
talk.
You
are
talking
to
the
api
server,
but
when
you
do
the
cat,
you
probably
don't
see
it
is
your
scheduler
and
Ingle
control
manager,
running
and
so
on.
A
So
this
becomes
very,
very
interesting
specifically
when
the
admin
of
the
multi
cluster
operator
of
the
multi
cluster
or
the
admin
of
the
multiplier
is
essentially
willing
to
offer
a
better,
basically
willing
to
offer
the
reliable
offerings
so
where
you
should
not
just
go
ahead
and
try
to
mess
with
the
controller
manager
or
the
scheduler
and
so
on.
So
we
can
hide
certain
things.
A
If
you
want
to
achieve
that
kind
of
situations,
that
kind
of
scenarios,
then
probably
this
kind
of
things
that
would
be
one
of
people
think
off
here
and
the
last
one
is
more
or
less
try
to
provide
a
clear
picture
of
this
architecture
so
that
we
can
judge
it
really
make
sense
to
accommodate
this
kind
of
approach
or
not
and
non
goals.
So
in
the
Mongols
first
of
all,
I
guess.
We
should
strictly
avoid
to
check
the
life
cycle
of
pre
management
cluster
as
such,
because
there
that
goes
into
the
completely
different
thread.
A
So
this
kind
of
this
question
can
be
addressed
with
probably
in
a
completely
separate
proposal,
in
a
similar
way,
how
to
upgrade
the
Cuban
artists
versions
of
these
control
planes
on
the
management
cluster.
So
the
version
of
build
of
the
workload
clusters
is
completely
separate,
topic
and
I
think
there
is
already
some
discussions
going
on
in
that
direction.
So
we
will
expect
that
those
discussions
should
be
generous
enough
to
work
on
different
architectures
that
we
might
discuss
here
and
the
last
one
is
the
auto
scaling
of
the
control
plane.
A
So
this
is
something
also
we
discussed
lasting
and
later
felt
that
probably
we
can
just
have
a
touch
point
on
it,
but
the
details,
auto
scaling-
should
only
be
the
little
one
sees
of
the
auto
scaling
of
the
control
plane.
Components
would
be
nice
to
be
discussed
separately
than
this
suppose.
Otherwise
you
will
end
up
retaining
a
lot
of
things
as
in
one
place,
I
have.
A
C
A
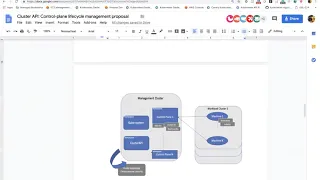
Strictly
check,
the
diagram
is
more
or
less
known
because
it
was
also
offered
quite
in
this
use
case
document,
but
I
tried
to
put
it
here
again.
So
what
you
are
seeing
is
on
the
left
is
a
management
cluster,
so
management
cluster.
Of
course,
as
this
one
it
system
namespace,
which
is
anything
with
that
cluster
itself,
then
you
can
see
that
we
can
dedicate
it.
We
can
dedicate
it
main
species
which
is
which
I
am
referring
else.
A
Let's
say,
of
control
plane
one,
so
this
control
plane
namespace
will
basically
be
hosting
all
of
the
control
plane
pods
of
picky,
one
particular
cluster.
So
for
a
for
instance,
if
I
want
to
create
a
cluster
with
foobar
and
it
will
have
its
own
API
server,
scalable,
Control,
Manager
and
core
control
plane,
components
plus
it
might
have
its
own
few
add-ons,
which
might
be
optional
or
core
add-ons
like
people.
A
You
might
want
to
offer
diploma
cases
and
whatnot,
and
in
this
mini
space
itself
we
could
also
host
the
cool
custom
resources,
like
the
customer
assistance,
which
are
being
offered
as
part
of
the
cluster
API,
which
is
specially
clustered
CLB,
and
the
machine
deployment
machine
side
missions
here
these
and
so
on.
So
in
way,
you
will
be
able
to
see
that
when
you
are
talking
to
the
management
clusters
API
server,
when
you
do
the
kept
machine
deployments
in
a
particular
namespace
of
people
upload
cluster,
you
should
be
able
to
see
all
of
the
customers.
A
First
definition
defines
all
that
forever
cluster.
That's
how
one
at
one
layer
we
can
define
the
separations
for
different
water
clusters
running
in
same
one,
big
management,
mustard,
right
so
and
of
course,
the
here.
The
workload
cluster
will
only
be
the
worker
machines
where
worker
machines
will
have
their
own
Q,
proc
freq,
you
blew
it
and
so
on,
which
are
properly
directed
to
the
API
server,
which
is
running
in
their
own
dedicated
namespace
in
the
mustard
management
cluster.
So
so
we.
A
To
make
sure
that
in
any
case,
the
worker
machine
should
not
be
really
be
able
to
get
access
to
any
other
control
planes
and
so
on
so
boost
X
will
probably
be
discussing
this
proposal
later.
How
about
you
in
the
implementation
details
and
then
we
can
dedicate
one
more
namespace
here
with
the
management
clusters.
A
We
can
call
and
you
some
good
names
for
now,
I
thought
of
specifically
in
States
and
so
on,
where
we
can
run
one
central
cluster
API
controller,
which
is
basically
the
controller
which
is
going
to
process
the
necessary
cluster
CR
these
for
us.
So
it's
the
or
deceit
are
being
created
in
different
namespaces
and
basically
be
managed
by
this
Central
Pacific
a
controller.
A
There
is
also
question
that
how
to
basically
manage
it
properly
in
a
way
that
whether
we
should
have
only
one
such
controller
because
for
machine
API
controllers
will
literacy
that
I
thought
may
make
more
sense
to
have
one
machine,
EP
controller
per
namespace,
probably
and
having
one
central
machine,
API
controller
that
we
will
see
later
in
the
text,
then
more
or
less
what
I?
What
I
just
said.
So
the
management
cluster?
What
are
the
components
that
we
can?
A
Think
of
so,
as
I
said,
when
the
decree
blank
space
for
the
workload
cluster
then
necessary,
cool
core
core
control,
plane
pods
will
decide
in
that
control,
plane,
plus
the
core
add-ons
additional
add-ons
could
reside
in
this
dedicated
namespace.
Here
we
can
also
offer
the
first-order
scalar
depend
of
additional
add-ons.
So
all
the
accounts
which
are
customized
for
this
UN
workload,
cluster
I-
think
for
them,
dedicated
mini
space,
would
be
a
good
place
right.
A
Well,
we
can
explicitly
customize
that
which
workload
cluster
one,
what
kind
of
facilities
at
the
end
is
being
one
central
place,
managing
them
all
so
and
then,
at
the
end,
the
Machine
API
controller.
So
here
is,
if
you
are
already
aware
of
what
we
are
doing
in
the
cluster
a
play
at
the
moment
right,
so
we
have
basically
two
main
set.
A
Basically,
we
have
two
separate
containers
when,
when
is
taken,
as
there
is
machine
that
is
for
the
machine
API
can
production
inside
emotionally
pay
controllers,
we
have
machine
deployment,
machine
set
machine
and
so
on
controllers.
Inside
aside,
so
this
particular
component,
now
we
have
to
decide
which
is
more
of
a
open
patient,
whether
we
journeyed
for
work
load
cluster
in
the
dedicated
namespace
or
we
don't
need
to
at
one
single
place
where
this
one
machine,
API
controller,
looks
over
all
the
namespaces
and
manages
the
machine
of
all
different
namespaces.
A
So
for
now
this
proposal
I
thought
of
having
one
per
name
space
or
one
portable
protester,
but
there
is
still
an
open
question
and
you
can
discuss
in
the
similar
way
in
terms
of
CR
DS
says,
as
I
said,
we
can
always
name
space
to
see
if
s
well
in
terms
of
on
whichever
workload
foster
they
belong
to.
Then,
as
I
said,
in
the
facility
name
space
we
have
Pacifica
so
API
controller,
which
is
already
responsible
for
processing
the
cluster
cluster
dot,
a
message-
and
we
might
also
we
are
yet
to
think
that
very
excited.
A
When
the
providers
of
different
controller
RSVP
I,
particularly
the
provider,
could
run
in
a
central
place
and
put
emotional
API
providers
could
run
on
different,
dedicated
name
species
or
we
could
club
all
of
them
into
the
one
cluster
a
plane.
In
space
and
all
the
providers,
this
one
at
once,
it's
prone
to
be
a
possible
I,
sketched.
A
Well,
but
the
deal
worker
machines
are
deploying
video
worker
machines.
So
then
I
try
to
give
quick
thought
on
pros
and
cons.
So,
as
he
already
said,
this,
this
kind
of
approach
would
help
more
or
less
in
optimizing
the
resource
cost.
So
in
general
you
can
find
rain
it
in
a
way
that
first
model
Prasad,
you
already
defined
the
very
so
you
already
provide
a
very
small
CPU
and
memory
to
those
particular
parts.
A
For
example,
if
your
API
servers
deployment
created,
then
we
can
basically
is
a
very
small,
CPU
and
memory
given
to
that
API
service
deployment
and
for
the
larger
clusters
you
can
either
dynamically
or
initially
said,
become
a
cloud,
the
CPU
and
memory.
That's
how
we
can
fit
the
optimizations
of
the
resource,
then
control,
plane,
availability,
so
she'll.
You
can
leverage
and
an
interesting
case.
Well,
it
is
basically
proportional
to
how
large
is
your
management
cluster?
A
So,
given
a
management
cluster
of
10
machines,
when,
if
you
have
real
control
depending
on
X
machine,
then
we
still
have
rest
of
the
machines
available
for
your
control,
plane,
pods
to
migrate
and
gentle.
If
that
particular
machine
holding
the
control
plane
dies
all
the
starch
or
so
on
right.
So
in
that
way,
this
is
not
in
terms
of
the
hive
ability
in
terms
of
migration
so
on,
but
this
is
more
about
what
what
can
we
offer,
which
can
least
effect
the
control
plane
when
such
disruptions
happen?
A
So
that's
one
point,
then,
in
term
auto-scaling,
so
we
already
see
that
there
are
good
of
the
skilling
solutions
available
if
you
enter
so
we
know,
HP
is
already
there.
We
know
vertical
power
of
the
skill
is
even
the
momentum,
so
those
kind
of
components
can
then
be
easily
utilized
if
you'd
known
that
control
plane
off
worker
cluster
is
nothing
but
just
another
application,
nothing,
but
just
another
deployment
or
stateful
said
and
so
on.
A
Right
then
we
can
in
future,
when
we
are
at
the
stage
where
we
actually
want
to
do
the
dynamic
or
the
scaling
of
the
workload
we
can
basically
just
attach
the
necessary
VP
or
HPA
to
the
pods
can
achieve.
Hence
we
can
achieve
the
auto
scaling
only
using
the
cuban
of
this
primitives,
then
the
last
benefit
for
many
providers
who
are
exclusively
willing
to
help
such
this
case,
where
you
want
to
basically
control
the
visibility
of
Eakin
protein.
So
for
us
it's
very
it's
very
important
in
this
case
where
the
end-user
might
not.
A
Really,
you
might
not
really
be
willing
to
let
the
end-user
check
the
chip,
controller
manager,
pod
or
API
server,
pod
and
so
on.
You
want
to
control
it
no
way
that
we
can
offer
a
good
SLA.
If
user
gets
access
to
those
spots,
then
we
can
basically
offer
literally
nothing
like
mess
with
expressions.
There
are
also
drawback.
So
if
there
is
any
questions,
any
doubts
please
feel
free
to
ask
already
I
mean
anyway,
we
can
also
collaborate,
a
synchronously
on
the
dock.
A
Then
there
are
also
drawback.
So
there's
there
is
an
open
security
concern
do
not
known,
but
it
gives
a
fair
vibes
that
you
know
that
there
are
multiple
users
control
planes
running
on
the
same
one
management
cluster.
So
it
could
be
a
patient
coming
that
is
it
ever
possible
that
one
user
can
really
get
access
to
the
other
users
pods
or
intent?
That
is
a
fair
concern,
but
we
can
feed
as
the
one
drawback.
A
The
other
drawback
is,
of
course,
the
field
of
the
entire
architecture
is
the
management
cluster,
which
basically
means
that
we
have
one
central
point
which
is
just
managing
managing
your
hundred
clusters.
So
we
need
to
come
up
with
the
good
way
of
making
sure
that
this
one
cluster
is
properly
highly
available.
Make
sure
that
the
posters
are
properly
all
the
workload
clusters
are
also
maintained
properly.
So
that's
the
second
drawback
I
could
think
of
in
this
architecture.
Then
I
wanted
to
add.
A
She
wore
a
cloak
points
here
that
when
you,
when
we
really
deploy
the
workload
cluster,
what
are
the
steps?
What
are
the
necessary
steps
we
should
probably
think
of
or
when
we
try
to
be
late
it?
What
are
the
steps
we
should
think
of
and
other
really
insist
Dell
while
deploying
or
getting
the
postures?
Well,
you
get
a
better
clarity,
but
still
open
and
get
to
work
on
it
and
will
be
nice
if
someone
else
can
also
force
here.
User
stories
is
something
which
I
tried
to
take
from
there
Christine.
A
This
document
saying
this
document
I
could
see
that
out.
There
were
stories
for
different
types
of
clusters,
so
here
I
see.
Few
of
them
were
relatable
to
this
to
this
particular
proposal,
but
I'm
get
to
refine
these
set
of
users,
so
we
can
come
up
with
better
exact
set
of
problems
which
makes
more
sense
for
our
purposes
and
rest
of
the
points
are
yet
to
be
properly
finalized.
I
guess
the
design,
details,
participant
and
so
on
will
come
later,
not
immediately
and
implementation.
A
Details
I
will
try
to
probably
work
on
it
in
a
way
that
what
kind
of
cuban
artists
primitives
makes
more
sense
for
what
kind
of
control
plan
components
and
for
more
low-level
details
come
here
little,
but
that's
more
or
less.
What
I'd
like
is
what
I
could
quickly
just
and
are
there
any
questions
in
this
edition
mean
nothing
to
talk
about.
A
So
providing
highly
there's,
also
very
good
interesting,
is
do
the
study
on
it.
So
the
management
cluster
is
something
just
to
answer
your
question.
It
might
not
be
directly
so
unless
that
cluster
is
created
by
the
cluster
APA,
so
that's
that's
how
I
see
so
if,
if
we
know
a
way
where
the
sleepy
I
can
also
provision
such
management
clusters,
then
we
might
want
to
consider
the
fact
that
how
can
we
make
it
as
good
as
possible
and
give
it.
B
D
Whether
that's
something
that
that
we
have
to
something
that
we
have
to
work
on
as
a
project
or
whether
it's
something
that
you
know
delegate
we
just
say
look
here
is
you
know
here:
is
the
cluster
API
control
plane?
It
has
these
characteristics
right.
Here's
here's
where
it
stores
its
state
and
you
know
it's
up
to
the
end-user,
to
you
know,
figure
out.
I
guess
you
know
either
high
availability
or
disaster
recovery
for
the
you
know
for
the
capi
control
plan
itself.
Not-Not-Not,
you
know
the
cluster,
the
workload
cluster,
that's
dope.
B
B
A
Yeah,
but
if,
if
plication
is
also
that
this
fault,
if
this
falls
under
the
cluster
api
in
general,
then
if
we
know
probably
a
very
feature
well,
we
can
deploy
the
management
cluster
cells
via
facility,
a
primitives.
Then
probably
we
can
think
of
such
cases
right
that
we
might
want
to
offer
the
highly
available
management
management.
B
B
B
Yes,
so
I
asked
that
earlier
this
work
stream
as
a
whole
is
responsible
for
talking
about
upgrade
and
control
plane,
and
her
next
point
was
that
this
specific
proposal
is
just
about
running
the
control
plane
as
pods
in
the
management
cluster,
and
that
there
is
some
other
aspect
of
this
work
stream
related
to
control,
plane
upgrades
and
that
this
particular
pod
base
proposal
can
take
advantage
of
that.
But
the
purpose
of
this
proposal
is
not
to
deal
with
upgrades.
E
Mean
Andy
I
do
hear
that
original
question
as
well.
I.
Think
part
of
my
my
reason
for
asking
is
that
I've
heard
upgrade
come
up
in
a
couple
different
contexts
in
cluster
API
meetings
and
it's
kind
of
just
been
persistently
punted
to
the
next
thing
and
I
understand.
There's
definitely
desire
for
some
foundation
before
upgrade
is
really
hammered
out.
I'm,
just
curious
where
that
exactly
will
be
I
guess.
B
F
So,
while
artx
proposal
currently
doesn't
address,
update
upgrades
before
I
think
before
we
accept
any
particular
kind
of
proposal
for
implementations
of
control
planes,
we
would
also
need
to
have
an
equivalent
either
an
upgrade
and
equivalent
upgrade
proposal,
or
the
proposal
would
have
to
be
extended
to
also
include
upgrades
as
well
and
I
know.
I
have
an
outstanding
action
item
to
start
proposals
for
the
other
two
proposed
control,
plane,
implementations
as
well,
and
for
each
of
those
I'll,
probably
attempt
to
at
least
capture
high-level
topics
around
upgrades
in
in
those
proposals
and.
B
B
A
B
A
lot
of
the
mechanics
are
similar
in
terms
like
the
the
functional
things
that
you
need
to
do,
or
the
logical
thing.
So
it's
like
I
need
a
new
member
for
if
I'm
doing,
a
minor
version
upgrade
or
even
a
patch
upgrade
like
I
need
a
new
entity
that
represents
running
control.
Plane
containers
which
could
be
in
pods
could
be
a
pot
only
or
pods
on
machines,
so
I
mean.
B
F
Don't
necessarily
know
if
I
agree
with
that
approach,
Andy,
because,
for
example,
for
the
machine
based
approach,
we
would
have
to
do
a
lot
of
orchestration
for
the
pod
based
approach.
We
could
leverage
kubernetes
deployments
to
handle
that
kind
of
orchestration
implicitly
and
give
us
the
ability
to
rollback
using
that
mechanism.
So,
while
I
think
there
are
some
like,
if
you
break
it
down
into
like
the
individual
component
pieces,
I
agree
that
a
lot
of
the
steps
are
similar
but
I.
F
B
G
G
I
mean
if
even
not
the
the
workflow
can
be.
You
ready
I
understand
that
the
implementation
for
it
in
the
permutation
between
a
code
base
and
a
machine
based
could
probably
the
workflow
within
any
mortal
proposal
is
similar,
but
if
we
need
to
do
this
other
moles
and
that
workflow
is
no
longer
common
I,
what
what
what
is
going
to
be
common
I
mean
what
do
possess
a
scope
with
this
video
just
evaluate
alternative
o1
implementation.
I
just
forgot,
if
I
saw
RIA,
have
been
having
deep.
My
first
meeting
in
this
world
ream.
F
We
discussed
in
the
previous
meeting
that
we
were
gonna
actually
have
three
proposals
come
out
of
this
meeting,
one
for
each
of
the
different
implementations
for
control
planes.
One
is
the
the
pod
based
proposal
that
hardik
already
did,
but
there
will
be
two
other
proposals,
one
for
the
machine
based
and
then
one
for
kind
of
managed
service
provider
based.
So
we
have
those
three
individual
proposals,
but
then
we
also
have
the
higher
level
requirements
they
need
to
feed
into.
F
So
thank
you,
but
before
we
take
off
our
take,
I
think
it
might
be
good
if
we
try
to
schedule
another
follow-up
meeting,
but
I
think
we
should
probably
target
after
cube
con,
because
you
know
cube
comes
only
in
two
weeks
here
and
I.
Don't
know
about
other
people
but
I'm
traveling
part
of
next
week
as
well.
Oh.
A
Okay,
that
makes
sense
you
can
have
a
follow-up
meeting
after
they
keep
gone,
and
that
also
brings
in
nice
point
which
I
completely
forgot
so
I
guess
we
also
wanted
to
discuss
that.
What
should
we
be
probable
deadlines
for
the
work
we're
doing,
I
think
this
was
raised
in
the
last
class
VP.
A
meeting
like
that
which
works
in
has
to
decide
the
tentative
milestones
and
deadlines,
and
so
on.
So
do
something.
I
haven't
thought
it
through,
but
are
there
any
physicians
from
anyone?
How
should
we
target
it?
B
It
be
completely
independent.
We
don't
have
any
release
dates
for
any
future
releases
of
close
to
API,
so
the
work
streams
and
their
deadlines
are
in
the
driver's
seat
here
at
this
point,
I'm
just
looking
at
the
calendar,
today's
May
7th-
we
have
the
rest
of
this
week
and
next
week,
pre
kuk
on
the
week
of
the
20th,
is
cube
con
there's
another
week
in
May
afterwards,
so
like.
If
you
said
like
a
month
from
now,
I'm
just
looking
at
the
calendar,
June
seventh
would
be
Friday,
which
is
two
full
weeks
after
cube
con
I.