►
From YouTube: Kubernetes Sig Docs 20181030
Description
Meeting notes: https://docs.google.com/document/d/1Ds87eRiNZeXwRBEbFr6Z7ukjbTow5RQcNZLaSvWWQsE/
The Kubernetes special interest group for documentation (SIG Docs) meets weekly to discuss improving Kubernetes documentation. This video is the meeting for 30 October 2018.
https://github.com/kubernetes/website
A
A
A
And
while
we're
on
the
topic
of
scary
things,
let's
talk
about
the
state
of
our
content,
but
first,
let's
introduce
new
contributors.
I
see
someone
named
Tiger,
just
maybe
yes,
maybe
the
best
name
we've
had
in
here
in
a
long
time.
So
hello
tiger,
not
a
long
I
thought
I'd
be
saying
in
a
cig,
dad's
meeting.
A
A
Cody
is
really
close
to
being
at
the
threshold
for
PRS
for
an
approver
and
I
figure.
Two
weeks
of
wrangling
PRS
will
give
Cody
all
the
comfort
and
then
some
to
be
able
to
act
successfully
as
an
approver
for
4k
website.
So
Thank
You
Cody,
please
feel
free
to
ask
questions,
but
you
seem
like
you,
got
it
pretty
locked
down,
so
any
other
updates
or
reminders
before
we
move
on
to
the
agenda.
A
C
Yeah
so,
and
we
put
together
a
blog
post
but
I
think
this
will
be
a
presentation
on
on
that
content
and
then
we'd
like
to
get
your
feedback
and
I
think
it
will
all
sort
of
complement
the
the
containers
presentation
that
Steve
did
I
think
internally,
but
yeah
so
Steve.
We
would
love
your
feedback
to.
D
D
Just
give
me
a
quick
thumbs
up
if
you
can
see
it,
alright,
cool.
Thank
you.
So,
as
Andrew
already
said,
this
is
the
presentation
for
the
blog
post
we
just
released
last
week.
What
the
hell
is,
a
pond
anyways
as
usually
interactive,
don't
be
shy.
If
you
have
any
questions
or
comments,
please
interrupt
at
any
point
in
time,
and
then
we
jump
in
right
with
the
definition
of
what
a
pod
is.
D
We
decided
on
the
definition.
A
pod
represents
a
request
to
execute
one
or
more
containers
on
the
same
note,
but
colloquially
the
term
impart
may
either
refer
to
the
request,
or
also
to
the
set
of
containers
that
are
executed
in
response
to
that
request.
We
use
the
term
pod
when
we
mean
the
request,
we
will
use
the
term
container
set
when
we
actually
talk
about
the
containers
that
are
executed
in
response
to
that
request.
D
So
one
important
tip
is
that
pods
are
considered
the
fundamental
building
block
of
kubernetes,
because
all
kubernetes
workloads,
whether
it's
a
deployment,
the
replica
set
or
a
job,
are
eventually
expressed
in
terms
of
parts.
This
is
this
little
diagram
you
see
here
where
a
deployment
results
in
a
replica
set
which
in
turn,
results
in
pods,
which
return
results
in
containers.
So
the
important
part
here
is
that
pods
are
the
one
and
only
objects
in
kubernetes
that
we
cite
in
the
execution
of
containers.
So
on
one
statement,
no
pod
no
container
at
that
point.
D
I
would
also
like
to
add
a
bit
of
a
critique
to
the
kubernetes
IO
website,
where
the
definition
states
that
the
pod
is
smallest
scalable,
and/or
executable
unit
on
kubernetes.
That
is
incorrect
for
two
reasons:
number
one
when
you
say
smallest,
that
implies
an
order
relationship
between
the
other
objects
like
deployment
replicas
set
in
port.
That
is
not
there,
but
you
need
the
order
relationship
in
order
to
say
smallest,
and
it
is
actually
the
only
scalable
and
executable
units
on
kubernetes.
D
So
the
pod
in
the
context
of
kubernetes,
is
highlighted
here
in
kubernetes
architecture
diagram.
The
pod
is
represented
as
a
pod
object
in
the
kubernetes
object
store.
It
has
accompanying
objects
that
are
important
for
its
lifecycle,
mainly
the
binding
and
the
node
object,
and
it
is
the
object
of
interest
for
the
scheduler
and
the
cubelet.
D
Here
we
got
the
diagram
that
reflects
the
data
structure
of
a
pod,
the
binding
and
the
node.
This
is
indeed
a
reflection
of
the
golang
data
structures,
so
the
pod
in
its
pod
spec
specifies
the
containers
that
are
to
be
executed
and
the
desired
restart
policy
in
case
of
a
container
failure
and
import
status
text
status
of
the
pods
execution.
A
binding
object
then
binds
a
pod
object
to
a
node
object.
D
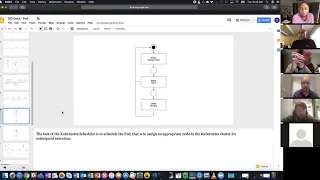
The
kubernetes
scheduler
is
a
classical
kubernetes
controller
in
the
sense
of
conceptually
following
the
control
loop.
The
tasks
of
the
crew
terminated
scheduler
is
to
schedule
the
pod,
that
is
to
assign
an
appropriate
nod.
Note,
I'm
sorry,
I'm
sign
an
appropriate
node
in
the
kubernetes
cluster
for
execution.
That
is
obviously
a
in
itself
complex
tasks.
Now
the
scheduler
is
a
policy
rich
component
that
takes
lots
of
constraints
into
account.
Yet
the
end
result
is
the
same.
It
finds
a
node
and
binds
the
node
to
the
pot
or
it
just
keeps
trying.
D
D
During
the
initialization
phase,
the
cubelet
sequentially
executes
containers
according
to
the
unit
container
specification
in
order
they
are
specified
in
the
list
and
during
the
main
phase,
the
cubed
cubelet
concurrently
executes
containers.
According
to
the
pods
containers
specification,
the
execution
highlighted
here,
the
execution
of
both
cases
follows
the
same
process.
It
will
call
the
create
and
run
action
on
the
CRI,
the
runtime
interface
mapping,
that
whatever
container
engine
you
are
actually
using
for
its
on
Kodaka
waiting
for
the
terminate
event
and
in
case
of
termination,
the
cubelet
will
apply
a
restart
policy.
D
D
That
is
whether
the
restart
policy
is
always
or
on
failure
both
map
to
the
same
behavior.
That
is,
if
a
container
fails,
it
will
be
restarted.
However,
if
it
executes,
if
it
terminates
successfully,
will
not
be
restarted.
That
is
different
from
the
main
face
where
oil
base
also
restarts
a
container.
Even
if
that
container,
exit
and
exited
successfully
hey.
D
We
can
so
the
the
difference
is
basically
not
there,
so
the
specification
of
a
container
or
of
an
init
container
and
main
container
is
the
same.
So
the
cubelet
assigns
well
a
pod,
/and
or
cubed
assigns
the
semantics
to
init
and
main
containers.
Init
container,
as
I
said,
are
meant
to
run
to
completion.
They
are
used,
for
example,
for
preparing
the
directory
structure
and
files,
any
initialization
tasks
that
are
then
necessary
for
the
main
containers
to
run
successfully
and
the
main
container
is
basically
the
most
important.
Even
so.
D
That
is
not
necessarily
a
strict
definition,
but
it's
what
we
usually
think
as
most
important
container
in
the
pot
and
also
sometimes
as
an
interesting
tidbit.
When
we
say
pot,
we
refer
to
the
container
set,
but
sometimes
more
specifically
to
the
main
containers
or
even
more
specifically,
to
the
most
important
container
oftentimes.
In
our
mind,
there
is
a
mind
there
is
a
one-to-one
mapping
of
the
pod
to
its
most
important
container,
but
that
is
that
is,
strictly
speaking,
accurate,
but
colloquially
speaking,
that
that
is
what
happened.
E
D
C
So
they're
the
main
containers
are
just
what
you
normally
think
of
as
containers.
It's
anything,
that's
not
the
in
it
containers
right,
they're,
the
ones
that
are
run
concurrently
when
you're
executing
the
pod,
the
in
the
containers
are
just
run
in
the
beginning
to
initialize
the
pod,
but
people
usually
don't
think
about
those
okay.
E
F
They're,
like
hidden
containers,
it's
a
little
more
than
that
Andrea
I.
Think
because
even
after
the
Anette
containers
have
finished,
you
could
have
two
containers
that
run
continuously
and
one
of
them
might
be
considered
to
be
doing
the
main
job
and
the
other
might
be
doing
some
side
task.
You
know
factors
sometimes
even
called
sidecar
containers,
but.
E
D
So
the
way
I
like
to
think
about
it
is
strictly
on
execution
semantics
that
is,
the
inner
container
run
sequentially
one
by
one
and
the
containers.
It
is
just
called
containers,
but
to
differentiate
I
call
it
main
containers.
The
main
containers
are
run
concurrently.
Now
how
you
use
all
of
this
is
completely
up
to
you.
D
It
is
actually
a
good
idea
to
introduce
a
short,
like
paragraph
mention
sentence
of
how
the
main
containers
how
multiple
main
containers
may
be
used,
but
just
to
just
one
one
word
of
caution:
write
the
port
and
the
execution
semantics.
Do
not
tell
you
at
all
how
to
use
these
containers
right.
Some
patterns
emerge
sidecar,
very
popular
pattern,
unit
containers
to
prep
the
volume,
so
the
directories
and
files
very
popular
pattern,
however
kubernetes
does
not
dictate,
or
the
pod
does
not
dictate
at
all
how
the
individual
containers
needs
to
be
used.
E
E
They
are
able
to
communicate
via
IPC
and
they
share
a
port
space
and
there's
also
the
sort
of
the
higher-level
concept
of
you
put
containers
in
a
pod
because
they're
probably
related
and
need
to
run
on
the
same
node.
So
from
what
I
recall
if
your
definition
was
like.
Oh,
these
are
containers
on
the
node.
It
didn't
seem
like
all
those
key
critical
features
when
I
think
of
what
a
pod
is
were
captured
by
a
definition
that.
D
Is
correct,
so
the
blog
post
states
shortly
that,
in
addition
to
this
definition,
that
pods
share
resources
like,
for
example,
volumes
and
network
sticks-
and
it
is
correct-
this
is
an
important
feature
of
a
pod.
I
have
been
mulling,
my
head
for
quite
a
while
and
eventually
came
to
the
conclusion
that
I
don't
think
that
these
properties
are
properties
of
the
definition
but
properties
of
the
implementation.
So
you
are
absolutely
right.
E
I
mean
as
long
as
your
blog
post
captures
those
key
critical
features,
because
again
the
end
result
is
not
to
have
an
elegant
model.
The
end
results
have
an
elegant
model
that
also
properly
captures
all
that
you
want
to
capture
so
that
somebody
can
take
away
a
really
solid
understanding
of
what
a
pod
is.
So
as
long
as
you
cover
it,
somehow,
maybe
out
of
bandwidth
from
the
model.
That's
fine,
but
I
mean
you
just
want
to
make.
D
C
A
C
A
Just
going
to
ask
Andrew
going
back
to
the
this
definition
of
a
pod,
the
the
distinction
that
you
make
Dominic
between
the
requests
in
the
container
set.
I,
wonder
whether
that's
a
distinction
that
we
currently
use
meaningfully
and
consistently
throughout
our
Docs,
or
whether
that's
something
that
we'll
have
to
update
in
the
scope
of
of
adding
this
modeling
in.
D
Yeah
so
so
far,
this
distinction
is
not
made
in
the
in
the
documentation.
However,
I
do
believe
that
the
distinction
is
an
important
one,
because
the
request
is
what
gives
the
pot
the
identity,
not
the
container
set
if
I
submit
an
identical,
two
identical
parts,
basically,
two
identical
requests.
They
may
very
well
result
in
two
different
container
sets
being
executed
due
to
failures
and
restart
policies.
That
is
why,
for
the
for
the
same
part,
like
semantically,
equal
port
for
the
same
part,
two
different
container
sets
may
emerge
over
time.
D
C
Thank
you
yeah,
because
the
container
set
is
sort
of
the
consequence
of
the
request
and
a
lot
of
stuff
that
you
need
to
deal
with
is
in
the
request
so
like
if
everybody's
kind
of
mental
models
are
on
like
the
the
result.
Like
the
executed,
you
know
containers
on
the
node.
That's
it's
sort
of
missing
a
lot
of
area
where
they
need
to
to
understand.
What's
going
on
right.
A
F
F
E
D
D
Also
later
on,
you
will
see
or
actually
not
seeing
the
presentation,
but
in
the
blog
post,
the
formal
definitions
on
how
the
phases
pending
running
successful
failure
are
actually
rolled
up,
so,
whether
you
wanna
you
want
to
go
to
that
level
of
detail
in
the
documentation,
of
course,
is
absolutely
up
to
you.
But
it
is
definitely
true
that
this
material
is
not
a
beginner's
material
when
it
is
aimed
to
really
tell
you
everything
you
need
or
everything
you
could
know
everything
about
the
nature
of
the
pod.
D
Whether
you
need
to
know
that
by
just
using
a
pod
or
even
just
a
replica
set
or
deployment
is
a
different
is
a
different
question,
but
this
states
the
nature
of
the
pod.
Only
if
you
want
that
level
of
detail
and
documentation
or
more
focus
on
how
do
you
use
it
instead
of
what
it
really
is,
is
totally
fair
and
it's
a
totally
fair
discussion.
Yeah.
C
Because
I
think
we're
going
to
decide
how
to
split
up
the
material
like
to
me.
This
is
our
source
material
that
we
can
use,
but
then
we
have
to
figure
out.
You
know
what
is
appropriate
for
like
the
novice
users
that
are
onboarding
and
then
what
we
need
also
more
intermediate
advanced
material
as
well
for
people
that
want
to
understand
it
more
in-depth,
so
I
don't
think
we
have
to
stick
this
all
in
the
same
topic.
C
E
I'm
way
more
flexible
and
what
goes
into
the
blog
post,
because
I
think
it's
an
incredibly
interesting
exercise
to
look
and
investigate
the
modeling
and
see
what
can
be
ascertained
from
the
modeling
and
put
it
together
to
me.
That's
a
at
least
a
separate
discussion
from
what
you
go
in
the
docs
I
think
I'd
love
to
see
the
blog
post
first
and
very
cool
about
you,
know
the
model
and
what
we
put
in
there
and
then
look
at
that
and
decide
as
a
separate
discussion.
Well,
what
is
appropriate
to
go
in
the
docs?
E
E
G
I'm
thinking
that
it
is
useful
for
our
Docs
contributors
as
well,
even
if
I
at
this
point,
I'm
inclined
to
agree
with
Steve's
comments
I'm,
but
with
a
stress
on
I'm,
not
sure
I'm
right.
How
useful
this
level
of
content
is.
I
mean
our
audience
for
the
docs,
for
people
who
are
trying
to
get
clusters
up
and
running,
not
necessarily
contribute
to
the
code
unless
like
driven
to
it
by
desperation
or
whatever,
or
the
lure
of
the
github
contribution
graph.
G
G
C
My
hope
for
this
project
is
that
it's
sort
of
a
rosetta
stone
to
get
like
the
engineers
and
the
tech
writers
on
the
same
page,
and
then
you
know
that
we
can
then
decide
how
to
present
it
to
the
users,
but
then
at
least
like
we
as
the
writers,
have
a
firm
understanding
and
can
be
more.
You
know
authority
of
about
like
when
we're
writing
the
content.
I
will
just.
D
Add,
as
I
said,
the
docs
are.
Obviously
this
is
your
boy
park,
but
I
would
just
caution.
It's
like
I
understand
that
a
high
level
of
detail
is
sometimes
uncomfortable
and
right
now,
I
only
have
anecdotal
evidence
by
browsing
the
issues
on
the
github
kubernetes
repository,
but
there
are
quite
some
issues
where
people
either
file
bugs
or
have
questions,
because
they
do
not
like
possess
the
correct
mental
model
to
assess
that
the
behavior
that
kubernetes
is
actually
displaying
is
by
design
right.
D
So
they
do
have
trouble
like
assessing
or
reason
about
the
behavior
kubernetes
shows
and
then
file
bugs
or
questions
as
github
issues,
and
then
some
of
the
engineers
usually
jump
in
sometimes
reply
with
a
few
lines
of
code
or
with
a
link
to
the
source
file
and
with
an
ad-hoc
explanation
of
by
this
behavior
is
correctly
haveá--,
which
points
in
the
in
the
direction
that
they
do
not
have.
The
tools
to
reason
about
the
actual
behavior
of
kubernetes.
D
A
Everything
that
I'm
hearing
is
pointing
to
not
whether
the
material
is
suitable
for
the
documentation
just
how
to
implement
it
and
how
to
implement
it
sensibly,
as
as
an
introduction
as
an
intermediate
step
and
then
for
advanced
knowledge.
But
ultimately,
that
comes
down
to
like
Andrew,
said
our
ability
to
authoritative,
lis,
understand
and
communicate
and
make
decisions
based
on
a
better
and
more
thorough
understanding
and
and
refactor
content
based
on
a
deeper,
a
deeper
level
of
knowledge
all
around
from
from
box
contributors,
because
I
mean
Dominic's.
Absolutely
right.
A
I
see
the
same
thing
in
our
issue:
blog
of
questions
about
function
that
aren't
transparent
in
our
documentation,
engineers,
who
will
respond,
and
that's
great
for
that.
One
person
who
had
that
question,
but
no
preservation
of
that
log
or
of
that
shattered
exchange
for
the
the
wider
documentation,
so
I
mean
I'm.
Super
excited
about
this
I
think
it's
awesome,
I
think
we
will
Brad
and
Steve's
point
have
to
be
judicious
about
how
to
introduce
the
material
in
stages.
But
I
mean
that's
what
we
do
so
and.
D
Let
me
let
me
use
an
analogy,
probably
loose
a
little
bit,
but
still
so.
This
is
definitely
not
material
in
the
sense
of
teaching
somebody
to
drive,
as
they
put
the
put
the
key
in
the
ignition
and
turn
it
and
if
it
starts
it
starts.
This
is
more
material
of
quality
of
alright.
Let's
take
the
car
apart
piece
by
piece
and
then
put
it
together
piece
by
piece:
is
it
necessary
for
the
one
who
needs
to
drive?
No,
is
it
helpful
if
things
don't
go
right?
D
D
It
if
kubernetes
doesn't
behave
like
it
yet
like
you
think
it
should
behave
right
if,
if
kubernetes
is
happily
doing
what
you
asked
it
to
do,
you
probably
don't
need
to
know
so
for
for
this,
for
this
slide,
that
is
shared
right
now.
That
shows
a
example,
execution
timeline
of
a
part
with
two
image
containers
and
two
main
containers.
You
see
the
image
containers
are
executed,
sequentially
and
they
have
to
terminate
successfully.
Otherwise
the
pod
will
not
continue
I'm,
sorry,
otherwise
kubernetes
will
not
continue
to
execute
the
containers
at
the
part.
D
In
this
case,
you
also
see
that
the
main
container
1.1
experience
is
a
failure
illustrated
by
the
red
dot,
and
this
then,
because
of
the
restart
policy
on
failure,
is
we
started
that
actually
brings
us
to
another
triplet
in
kubernetes.
We
say
a
lot
that
a
container
is
we
started.
This
very
much
depends
on
the
definition
of
restart
the
container
by
the
identity
of
the
container
is
never
restarted
right,
cubelet
does
not
restart
a
container.
D
Cubed
creates
a
new
container
according
to
the
same
specification.
This
is
what
is
defined
as
we
start,
then
the
term
restart
is
correct,
since
it
is
not
strictly
defined,
it
actually
may
spark
the
the
wrong
mental
model,
and
this
is
also
when
the
container
set
does
actually
not
match
one-to-one
to
the
specification.
Since,
in
the
specification
and
the
container
status,
you
have
actually
one
container
the
main
container
one.
D
D
Now
during
the
execution
right,
the
cubelet
reads:
the
specification
for
the
containers
communicates
with
the
container
runtime
and
has
a
container
unten
execute
the
containers
on
its
behalf.
But
of
course,
it
also
takes
into
account
the
current
status
of
the
containers
and
updates
the
status
of
the
part.
Accordingly
here
and
in
the
blog
post,
we
are
only
looking
at
the
most
high
level
roll-up
the
pod
phase.
There
are
also
multiple
port
conditions
that
the
port
goes
through
through
its
lifetime.
That
is
not
illustrated
here
or
in
the
blog
post.
D
The
pod
phases
are
pending
running
success
in
failure
and
their
their
definition
of
what
pending
actually
means
or
what
running
actually
means.
The
formal
definition
can
be
found
in
the
blog
post,
for
example,
running
means
that
all
image
containers
are
terminated
successfully
and
at
least
one
of
the
main
containers
already
started
execution,
but
not
necessarily
all
of
them,
and
last
but
not
least,
at
the
end
of
a
long
hard
day,
we
have
the
kubernetes
pod
garbage
collector
another
controller,
another
kubernetes
controller.
This
one
is
responsible
for
deleting
the
kubernetes
object
store.
D
It
takes
only
terminated
thoughts
into
account
and,
after
a
certain
time
span,
will
remove
that
object
from
the
kubernetes
object
store
why,
after
a
certain
time,
stem
a
timespan
that
is
because
a
terminated
pod
also
acts
as
a
tombstone
for
other
entities
in
the
system
like,
for
example,
a
kubernetes
job
needs
to
know
that
a
pod
terminated
successfully,
otherwise
recreate
reschedule.
We
execute
that
pod.
That
is
why
there
is
a
time
span
in
there,
so
that
the
job
gets
a
chance
to
look
at
thought.
D
It
started
check
out
its
termination
status,
checks
out
success
and
then
record
its
own
success
in
its
own
object
status
field,
and
after
this,
after
this
time
spent,
then
the
kubernetes
Garbett,
the
pod
garbage
collector
controller,
goes
ahead.
Fools
that
oil,
the
necessary
objects,
had
a
chance
to
look
at
the
tombstone
and
will
then
basically
remove
the
object,
therefore,
removing
the
tombstone
from
the
system
and
that,
basically,
it's
the
day
of
a
life
in
a
pod.
C
Thank
you
very
much.
I
should
also
mention
we're
looking
Tamaki
didn't
really.
You
can
mention
the
unknown
state,
which
is
one
of
the
things
we're
looking
into
yet
like
yesterday,
we
were
just
interviewed
Don
Chen,
one
of
the
engineers
on
node
and
Nord,
trying
to
find
out
more
about
like
what
communities
does
in
that
state,
so
we're
hoping
to
have
a
blog
post
later
on.
C
D
A
A
So
let's
move
on
and
thank
you
very
much,
dominic
and
andrew
for
that
that
was
really
good
content
and
really
discussion
that
came
from
it.
So
thank
you.
Thank
you.
So
I
want
to
touch
briefly
on
github
project
cleanup.
We
talked
about
this
in
the
APEC
friendly
time
meeting
last
week,
but
just
to
review
4k
website
that
repository
Steve
Perry
went
in
and
did
cleanup
and
right
now
there
are
two
projects
in
the
K
website.
Repository
and
I.
A
Think
it's
a
good
idea
to
keep
only
two
right.
Now
we
have
a
project
for
work
in
progress
and
we
have
a
project
for
Docs
prints
and
for
work
in
project
work
in
progress,
I
think
if
we
can
automate
those
triage
columns,
we
can
let's
we
can
start
moving
from
there
towards
an
automated
model
of
the
work
that
we
agree
to
prioritize
as
a
sig
for
content.
A
I
want
to
there's
more
to
discuss
here,
obviously,
but
I
want
to
simply
note
that
the
cleanup
work
for
projects
is
done
and
we
can
move
next
week
into
talking
about
what
we
want:
the
specifics
of
prioritizing
content
and
tracking
it
to
look
like
so,
let's
revisit
this
next
week
and
talk
more
about
projects.
I
know
Steve
mentioned
that
his
power
might
die.
Otherwise
we
might
devote
a
little
time.
A
A
Don't
think
that
six
months
is
frequently
enough
to
be
honest,
may
feels
like
another
lifetime
ago,
so
I
would
like
to
start
moving
to
a
quarterly
cadence
for
setting
our
priorities
as
a
sig
and
being
intentional
more
frequently
about
the
work
that
we
agreed
to
do
so
that
we
aren't,
quite
so
blindsided
or
sort
of
pulled
around
by
projects
that
arise
suddenly,
and
that
we
can
also
have
a
better
sense
of
priorities
that
we
can
take
to
our
respective
employers
and
say
hey.
These
are
the
these
are
the
things
that
we
agree
to
work
on.
A
Also
get
in
the
habit
of
deciding
where
we'll
need
to
decide
where
to
meet
again
but
start
moving
towards
a
quarterly
cadence
of
a
project
planning
I'd
also
like
to
do
a
retrospective.
It
feels
sometimes
like
we
don't
get.
We
don't
take
enough
time
to
recognize
the
work
that
we've
done
and
when
you
think
about
the
course
of
the
past
year,
if
you
stop
and
think
about
it,
we
have
done
some
really
remarkable
things.
A
A
But
it
also
things
like
who
bring
gold
the
most
PRS
over
the
course
of
the
year.
You
know
whether
what
is
the
most
you
know
is
that
there's
simply
number
of
PRS
number
of
lines
of
PRS,
reviewed
and
wrangled,
so
the
different
different
awards
and
and
different
recognitions
of
service,
so
I'd
like
to
spend
some
time
recognizing
note.
The
work
that
we've
done
this
year
has
been
has
been
pretty
incredible,
because
this
is
a
pretty
incredible
bunch
of
folks.
A
All
right,
I
think
that's
it
for
our
agenda,
so
I
noticed
based
based
on
today
that
the
content
discussions,
which
are
awesome,
also
tend
to
eat
a
lot
of
time.
So
I'm
wondering
if
it
might
make
sense
next
week
to
put
more
business
stuff
to
front-load
business
at
the
beginning
of
the
meeting
and
then
allocate
more
time
to
content
discussion
so
that
we
don't
have
to
worry
about
keeping
the
keeping
the
train
on
the
tracks.
Quite
so
much
does
that
make
sense
to
folks
cool
all
right
I.