►
From YouTube: [SIG K8s-Infra] Bi-Weekly meeting for 20230913
Description
[SIG K8s-Infra] Bi-Weekly meeting for 20230913
A
Hi,
everyone
welcome
to
kitchen
for
meeting.
We
have
September
13
and
this
is
the
bi-weekly
meeting
as
usual.
Please
be
mindful
of
anyone
in
this
call,
so
this
car
will
be
recorded
and
Publishing
YouTube,
so
be
careful
about
whatever
you
say
and
be
kind
to.
Anyone
in
this
call,
so
I
don't
see
any
new
people
on
this
call.
So
I'm
just
gonna
go
for
the
building
with
you.
A
A
A
A
B
A
B
A
But
basically
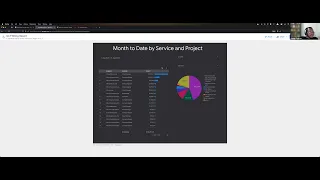
James
posted
a
graph
about
basically
bandwidth
consumption.
So
over
the
last
month
we
I
think
we
capture
half
of
the
traffic
and
it's
kind
of
expressing
like
this
amount
we
spent
for
the
entire
month
of
August.
So
we
we
spend
42k,
which
is
when
I
checked
on
the
platform.
Fuzzy
platform
you
can
check
it
or
I
can
give
you
a
while
to
share.
A
We
I
think
we
bandwidth
from
fastly
was
60
630,
35
terabytes,
which
is
like
not,
which
is
a
good
thing,
but
I
think
we
need
to
basically
be
patient
and
see
how
things
happening.
Once
we
change
the
GCS
bucket.
We
might
basically
see
a
shift
because
I
think
I
was
discussing
with
sick
release
and
yesterday
about
switching
from
kubernetes
is
better
to
commit
your
own
one.
So
we
can
see
change
we
stoppage
there.
We
leave
that
thing.
A
A
B
A
B
A
B
along
the
way
we
had,
we
had
to
adjust
quota
limits
and
API
throttle
limits,
and
things
like
that,
so
we
were
working
with
AWS
support
on
that
in
like
some
internal
AWS
folks
as
well,
so
we
are
at
4200
and
we
are
maxing
out
the
vcpus
that
we've
been
allocated.
So
we've
requested
one
more
increase
from
8
000
vcpus
to
like
1600
bcpus,
so
that
should
cover
us
for
running
at
least
one
CI
job
with
5000
nodes.
B
B
You
know
running
different
jobs
in
different
regions,
so
there
is,
the
cost
is
going
to
increase
so
once
we
have
it
stabilized
at
5K.
I
think
we're
going
to
stop
there
for
129,
because
5K
is
what
what
we
usually
test
on
the
gcp
side
as
well.
But
then,
after
you
know,
we
can
decide
what
to
do
at
Chicago,
so
I
I
did
you
know.
B
B
E
B
B
B
B
So
the
same
thing
is
true
for
one
more
set
of
one
more
account
that
we,
you
know
we
were
just
talking
about
before
the
call.
There
is
an
account
that
is
being
used,
which
is
which
is
which
was
set
up
by
an
Amazon
employee
a
long
time
ago
and
he's
no
longer
with
the
company,
and
it
is
the
it
is
not
very
high
volume
or
anything
like
that.
B
It
is
like
a
1K
per
per
year,
but
it
is
running
like
the
AWS
control
manager,
load
balancer,
the
EVS
CSI
driver
FSX,
CSI
driver,
so
he's
running
jobs
from
all
those
satellite
repositories
that
we
have
for
AWS.
So
we
need
to
switch
them
over
to
an
official
account
because
we
don't
know
what
will
happen
to
that
account
in
the
longer
term.
E
Yeah
I
want
to
add
one
more
thing
to
that.
So
yeah
poscus
isn't
actually
a
good
approach
because
we've
got
a
different
set
of
tests
right.
So
we
run
no
DT
test
is
one
set
of
tests
that
we
run
and
then
there's
the
cloud
provider
AWS,
and
then
these
other
extra
pieces
of
projects
that
are
test
against
AWS
right.
They
can
all
live
in
a
single
account
where
each
work
each
group
of
projects
occupies
a
single
region
with
reasonable
quotas.
It's
on
there
yeah.
B
E
A
B
E
B
E
A
A
D
E
A
Have
a
S3
bracket
when
you
put
everything
into
your
phone
I,
don't
I,
don't
have
a
specific
concern
about
how
you
want
to
handle
that
as
long
as
like
inside
a
remote,
State
accessible,
that's
fine,
I,
don't
I!
Think
I!
Think
for
the
moment.
I
don't
want
to
centralize
remote
state
for
terraform,
because
we
don't
have
SSO.
A
E
A
Yeah
I
think
we're
gonna
be
assuming,
assuming
we
add,
more
I,
think
it's
really
up
to
how
we
want
to
handle
the
skill
test
like
basically,
if
we
say
we're,
gonna
have
5K
notes
test
by
December
other
aspect.
We
wish
1
million
because
there's
a
few
things
we,
because
we
go
down
on
this
yeah,
so
I
don't
really
expect.
We
wish
one
video
but
I.
I
honestly,
don't
know
that
would
depend
on
basically
there's.
A
Thing
so
yeah,
I'm
I
think
it's
not
the
one
thing.
We
need
to
talk
after
all
the
project
by
migrate
to
gcp
and
AWS,
so
we
have
nothing
less
inside
Google
infrastructure,
and
now
we
can
talk
about
instance,
resolution
and
once
we
have
like
a
I
would
say,
a
borrowing
currency
regarding
scaling
tests.
When
we
say
okay,
we
have
5K
there's
no,
we
have
3K,
there's
no
one
kitchen
so
running
smoothly
over
time,
and
we
can
like
say:
okay
for
this.
Second,
we're
doing
is
test
reservation.
B
A
A
That's
why
I
do
I
think
I
think
the
goal
and
thank
you
so
much
Ricky
for
traveling.
This
is
have
all
the
proud
job
inside
the
community
secretary.
If
you
can
have
that
by
end
of
the
year,
that
would
be
great
because
we
can
have
a
projection
the
next
year
and
say:
okay,
this
is
the
one
thing
we
have.
This
is
running
or
like
an
entire
month.
A
We
can
do
a
projection
thanks
here
and
say:
okay
I
will
reserving
fans
in
database
in
JCP
is
not
possible
because
of
how
gcp
builds
stuff,
but
another
device,
I
think
is
possible.
I
have
to
talk
with
about
this,
but
I
think
our
goals
should
be
trying
to
have
every
project
we
want
inside
the
community
infrastructure.
It's
based
on
that
we
can
project
for
2024.
C
F
If
anybody
has
any
thoughts
on
how
to
start
addressing
we've
got
a
little
over,
you
know,
chaos
is,
is
a
big
piece
of
that.
I
know
you're
working
that,
but
you
know
outside
of
chaos
with
God
I,
think
six
or
seven
hundred
jobs
that
I
still
don't
right
now
have
like
a
path
to
to
migrate
or
are
hung
up
on
some.
Some.
D
B
F
A
F
B
B
F
There
there
are
there,
are
there
are
projects
and
and
jobs
that
kind
of,
like
you
said,
are
not
run
very
frequently
right,
like
the
Haskell
clients,
that's
that
hasn't
been
updated
in
probably
a
year
it
was.
Is
there
any
concern
from
your
guys's
part
on?
You
know,
trying
to
make
sure
we
trigger
these
jobs?
If
I.
B
F
B
You
know
make
the
change
make
the
change
like
if
it
breaks
I,
let
people
fix
it.
Okay,
you
know
I'm
resurrecting
the
the
effort
where
we
look
at.
You
know
things
that
are
broken
for
a
long
period
of
time,
so
like
we'll
catch
it
using
that
mechanism
right
and
like
we'll
tell
people
hey
if
you're
not
using
it,
and
it's
broken
all
the
time,
then
you
know
we're
just
gonna
shut
it
down.
If
you
don't
fix
it
right,
yeah.
F
B
A
Yeah
I
think
we
in
the
past.
What
we
did
was
try
to
do
some
adding
games.
They
did
that
last
year
was
live
stream
campaigning
to
the
six,
so
they
basically
take
care
of
the
project
and
because
we
we
I
think
there's
a
firework.
I
can
look
into
that.
Where
basically
collect
the
number
of
day
where
job
is
failing
and
we
are
we
so
jobs
failing
for
like
two
years
and
no
one
care
about
this
right,
so
I
think.
A
I
mean
trying
to
push
from
to
migrated
product
jobs,
and
we
can
refer
it
if,
like
yeah,
it's
critical,
I,
don't
I,
don't
think
any
I
would
say
master
blocking
or
mastering
for
me
are
inside
Google
infrastructure
anymore.
So
the
rush
should
be
straight
for
a
while.
So
right,
people,
the
only
situation
where
I
see
a
river
to
the
Google
infrastructure,
is
where
those
projects
need
specific
credential
or
external
asset
yeah
right
yeah.
If
if
they
don't
need
that,
we
should
just
migrate.
B
Let's
make
sure
that
every
job
has
a
cluster
and
by
you
know,
if
it
doesn't
have
a
cluster,
then
it
should.
You
should
add
the
default
cluster
yeah
that
is
owned
by
you,
know
Kate's
infra,
and
then
you
know
we'll
see
where,
where
Things
fall
right
like
now,
who
is
the
right
time
to
do
it?
Because
you
know
later,
when
we
start
hitting
deadlines,
then
people
are
going
to
yell
more
at
us,
so
the
earlier
we
do
it
in
the
129
cycle,
the
better
it's
going
to
be.
Okay,.
F
C
This
is
jumping
to
my
item
in
the
agenda,
but
it
kind
of
relates
to
this
I've
talked
to
like
Ben
and
a
few
others
about
this,
but
I
think
it's
coming
time
where
we
actually
set
a
policy
that
we
will
not
execute.
We
will
not
use.
Ci
will
not
use
external
resources
unless
they
are
owned
by
the
community
into
a
point
where
we
can
support
them
things
like
any
of
the
Microsoft
tests.
C
This
is
also
to
kind
of
like
serve
as
a
forcing
function
to
like
hey
it's
time
you
bring
people
to
the
table.
To
do
this,
we
can't
just
you
know
hey.
This
is
broken.
Let's
poke
some
internal
person
at
Microsoft
to
fix,
yeah
and,
with
you
know,
a
lot
of
things
getting
out
of
the
the
you
know
we're
at
a
good
pace
for
getting
out
of
all
the
Google
own
specific
stuff.
C
B
And
like
making,
actually
people
can
do
whatever
they
want
in
their
opposed?
We
can't
stop
them
from
doing
that,
but
you
know
they
can't
be
release
informing
or
release
blocking
from
you
know
from
a
policy
perspective
right,
like
those
other,
you
know
you
can't
stop.
So
you
know
some
specific
group
of
people
in
a
specific
repository
to
like
add
CA
jobs
on
whatever.
B
So
the
knobs
that
we
have
is
it
can't
be
a
release
informing
or
a
release
blocking
job
right.
That
is
what
we
can
mandate
and
we
can
mandate
that
it's
not
going
to
show
up
and
test
grade.
You
can't
I,
you
can't
add
it
to
test
info.
Basically
right,
you
know
go
nuts,
but
you
know
it
just
can't
come
to
us
so.
C
C
C
A
Got
it
yeah,
I,
I,
I,
think
I
think,
because
we
we
don't
want
to
basically
spend
the
I
would
say
the
consensus
is
like
we
should
draft
a
policy
we
need
to
embed
in
the
chart
of
the
seek,
so
we
can
clarify
How,
We
Do
ownership
of
the
structure.
Again,
do
you
have
that
have
a
conversation
about
it
in
kubecon
and
try
to
put
that
in
the
chatter
I
think.
That's
the
overall
call
in
term
modification.
A
A
B
C
Crow
notes
are
okay,
so
yeah
yeah,
the
the
main
thing
like
I've
I've,
talked
to
some
of
the
various
vendors
and
it's
just
been
like.
If
there
is
something
that
they
can
a
policy
or
something
they
can
just
like,
hey
look,
this
is
gonna
happen.
We
need
to
take
action,
yeah
that
that
is
the
that
is
the
forcing
function
yeah.
E
A
A
A
It's
not
because,
if
render
real
product
around
kubernetes,
they
have
reward
and
say
they
are
basically
have
something
to
say
about
how
we
handle
the
different
assets.
We
we
basically
have
all
policy
is
to
ensure
we
maintain
sustainability
of
the
project
long
term,
because
we
are
very
young
project.
We
target
30-year
life
cycle
like.
A
A
A
B
D
B
A
A
So
I'm
gonna
open
a
Umbra
issue
and
try
to
track
down
and
try
to
shut
down
things
like
so
from
taking
up
a
sub
perspective.
A
shutdown
of
an
account
is
90
days
operation.
So
at
the
moment
you
trigger
that
you
have
90
days
until
the
account
is
gone,
so
revert
that
action
should
be
fine.
If
you,
if
somehow
always
notice,
a
critical
Pro
job
is
failing
because
the
air
conditioned
down
so
I
think.
A
Basically,
this
is
more
like
open
in
different
issue
about
that
and
try
to
investigate
basically
outline
the
account
I
want
to
shut
down
and
shut
out
over
time
slowly.
So
we
can
buy
end
of
the
year.
Have
a
cleanup
of
the
organization
because
there's
a
lot
of
things
we
migrate,
but
no
one
ever
used
those
things
it
just
I
think
not
Gateway
is
doing
nothing
and
been
there
for
like
two
years
so
I'm
like
interest
to
do
that.
Cleanup.
C
A
A
Oci
artifact
inside
GitHub
content
repo
because
I
see
so
the
idea
is
like
for
a
long
time.
People
were
reaching
out
about
this
like
where,
if
it's
possible
for
the
community
to
if
it's
possible
for
Community,
to
provide
a
platform
where
they
can
host
oci
artifacts,
so
basically
not
only
control
images
but
also
M
chart
and
so
on.
The
oci
specification
evolved
to
the
point
like
we
can
store
non-commissioned.
A
So
my
question
is
how
we
want
to
handle
this
because
I
don't
want
I,
don't
want
the
suppression
come
to
us
and
ask
about
this.
So
basically
the
privilege
change
through
the
registry,
so
I
would
like
to
be
independent.
So
today
you
will
get
our
service
to
all
to
basically
all
stay
on
yeah
we
packages.
C
A
I
did
my
my
I
wanted
to
get
a
conversation
between
kids
and
foreign,
so
I
think
the
one
thing
is
like
because
over
time,
obviously
authorization
on
GitHub
basically
is
like
is
evolving
to
the
point
we
can
deal
it.
We
can
I
would
say
delegate,
but
there's
also
some
kind
of
race
become
delegation
to
and
Jerry
Jones,
basically
I
would
say,
not
increase
the
surface
attack
because
you
can
have
an
individual
accidentally,
releasing
something
with
a
high
CPA
and
that's
impact.
That's
impact.
A
C
A
Yeah,
and
also
if
it's
I,
don't
want
to
say,
talk
to
guitar
and
see
what's
doable
and
what's
not
doable,
remember,
I
would
say
authorization
perspective
so
can
simplify,
might
be
a
future
request
to
the
entire
GitHub
platform
or
might
be
basically
something
we
are
not
aware.
So
we
can
simplify
delegation,
but
the
idea
is
to
stop
basically,
basically
stop
selling
to
sub-project
to
use
the
version
3
the
project,
because
some
of
them
are
basically
clad,
Cloud,
specific
I'm,
not
sure
we
want
to
do
that.
E
E
A
D
Yeah,
so
I
don't
think
that
we
really
care
about
what's
being
published
if
it
is
also
comfortable,
it
works
for
us.
If
you
publish
health
chart,
that's
fine
and
the
problematic
part
is
that
right
now
everything
goes
through
the
Google
Cloud
build.
So
you
can't
really
push
images
on
your
own,
like
you
can
put
it
in
the
even
with
Pro.
We
usually
run
the
Google
Cloud
build
job,
so
that
might
be
trickier
to
get
working
with
him.
D
A
Of
that,
but
I
would
say,
I
would
say
it's
it's
a
matter
of
technical
implementation,
because
we
don't
need
to
use
care
of
that.
We
can.
At
the
moment
we
basically
say
we
can
have
a
different
tooling
that
do
the
promotion,
because
all
sorts
of
stroke
will
be
the
staging
repo.
We
have
a
tooling
exercise.
Promotion
to
the
private
person
doesn't
need
to
be
careful.
It
could
be
another
tool,
that's
doable,
but
the
problem
is
at
the
moment
we
say
we
use
registry
or
any
oci
artifact.
A
A
B
A
A
Exactly
directly
I
think
GitHub
can.
Basically,
if
you
apply
there
used
to
be
a
registry,
a
project
that
basically
serve
mshot
directly
for
kids.
So
the
the
problem
is
not
technical
in
the
sense
like
we
can,
we
basically
cannot.
We
cannot
cannot
serve
food.
The
problem
is
like
the
cost
impact
of
it.
If
you
become
a
central
registry
for
the
M
shot
of
sub
project,
there's
a
cost
increase
the.
E
E
D
Like
we
have
to
take
a
consideration
that
help
charts
are
not
disclosed
in
sizes,
real
container
images
right,
so
they
are
basically
manifests.
That's
here,
I'm
going
to
apply
so
that
is
pretty
much
I,
don't
know
how
much
exactly
it
can
be,
but
I
don't
anticipate
it
to
be
or
a
few
Mega
ways.
Maybe
even
that
is
a
lot,
and
this
is
something
where
me
we
could
potentially
utilize
CDN
as
well.