►
From YouTube: Kubernetes SIG Multicluster 2020 August 11
Description
No description was provided for this meeting.
If this is YOUR meeting, an easy way to fix this is to add a description to your video, wherever mtngs.io found it (probably YouTube).
A
C
C
A
A
D
Definitely
I
only
learned
about
a
sig
multi-cluster
a
couple
weeks
ago,
so
we've
been
hard
at
work,
reading
up
on
on
your
documentation
and
your
position
statements-
and
I
thought
this
would
be
a
great
opportunity
to
share
our
notes
as
it
you
know,
as
we
come
across
it.
So
that's
fantastic!
Thank
you.
D
D
His
and
configurability
historically
has
been
sort
of
a
struggle
for
us.
We
need
mtls
between
clusters
and
workloads,
and
I
know
that
this
this
sig,
isn't,
you
know
specifically,
for
you
know,
meshes
or
whatever.
I
saw
tim's
comment
on
on
how
we're
trying
to
build
building
blocks
for
these
meshes
but
sort
of
just
you
know
a
point
there
single
we're
working
off
of
a
single
region,
container
native
routable
solution
and
also
we
are
using
istio
as
a
service
mesh.
D
So
that
is
our
main
method
of
ingress,
after
all,
like
the
firewall
stuff
and
the
north
south
stack.
So
the
main
problem
statement
that
we
wanted
to
solve
was
that
upgrades
on
a
cluster-wide
basis
is
very
terrifying
if
all
of
your
workloads
are
on
that
same
cluster,
so
anything
that
requires
a
control
plane.
Anything
that
requires
custom
resource
definitions
right
when
you
touch
that
resource
definition,
inherently
the
whole
cluster
gets
impacted
by
that.
So
you
know
we
thought
about.
D
How
can
we
limit
that
blast
radius
of
a
of
a
of
a
tool,
or
you
know
istio
or
any
of
the
other
platform
tools
that
we
rely
on,
and
so
we
thought
about?
You
know
what,
if
we
blew
green
the
cluster,
and
so
this
was
a
a
little
bit
of
a
road
map
or
sort
of
the
the
algorithm
that
we
wanted
to
follow.
As
we
went
ahead
and
blue
blue-greened,
our
clusters,
you
know
obviously
phase
zero.
D
Is
creation
of
the
green
cluster
make
sure
that
the
the
clusters
can
connect
and
then
make
sure
that
services
are
discoverable
and
then
finally,
a
north
south
switchover
on
the
on
the
ilb
and
then
finally
decommissioning
of
the
blue
cluster.
That's
a
lot
of
points,
so
I
sort
of
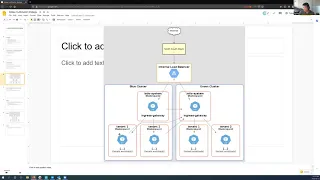
drew
a
diagram
to
help.
Everybody
understand
what
I
mean
by
that.
So
we
have
blue
clusters
and
green
clusters,
and-
and
I
especially
appreciated
your
your
statements
on
you-
know-
name,
space
sameness
right
where
tenant
one
and
tenant
one
here.
D
I,
as
I
said
before,
the
only
service
that
that
we
need
to
be
discoverable
between
two
clusters
is
the
ingress
gateway,
and
so
we
actually
ended
up
writing
our
own
service,
that
watches
service
and
endpoint
events
and
then
takes
the
definitions
and
reapplies
them
to
another
cluster.
It's
you
know
relatively
quick
and
dirty
solution.
D
I
have
also
made
the
the
source
code
available,
but
I
would
be
really
interested
in
you
know,
and
I've
already
started
a
little
bit
of
it,
comparing
the
two
approaches
and
seeing
how
how
similar
or
how
different
they
are
and
here's.
I
guess
one
of
the
questions
that
I
wanted
to
discuss
today
is
like
I
I
don't
know
if
I'm
missing
something
in
the
documentation,
but
I
couldn't
figure
out
how
clusters
were
actually
registered
with
each
other,
because.
A
I
was
just
gonna
say:
that's,
that's
a
really
good
question
and
the
the
thesis
of
our
sig
multi-cluster
intro
is
that
cluster
registry
is
easy
to
describe
like
as
a
thought
right
in
practice.
It's
been
super
difficult
to
to
build
something
that
that
makes
that
idea
real
in
software
and
one
of
the
things
that
characterizes
our
approach
that
we're
taking
in
the
sig
right
now
is
that
there
is
an
existing
project
out.
A
And
we
have
two
things
happening
right
now.
One
is
a
that
were
we
have
a
worldwideable
document
where
we're
trying
to
collect
specific
use
cases
that
people
have
for
registration
as
part
of
like
a
rethink
of
the
concept
and
the
other
one
is
that
in
multi-cluster
services-
and
I
think
you
kind
of
happened
on
to
this
dimension,
but
it's
also
in
the
the
the
work
that
we've
been
doing
on
the
work
api.
Is
that
we're
trying
to
avoid
prematurely
characterizing
a
registry
and
overfitting
to
the
problems
that
are
directly
in
front
of
us.
D
Right,
I
think,
just
in
terms
of
thinking
about
the
the
problem
set
of
mcs
api.
First
of
all,
I
guess
I'm
interested
in
how
the
sort
of
implementation
right
now
does
it.
I
know
I
I
was
able
to
find
that
you
know
declaring
a
service
import
does
indeed
import
a
cluster,
I'm
just
a
little
bit
confused
as
to
where
it
sources
that
information
right
now
as
it
stands
in
the
in
the
github
right,
jeremy.
B
Yeah,
so
this
kind
of
goes
in
the
you
know:
building
blocks
first
approach,
but
basically,
like
we've
hand,
waved
away
the
cluster
registry
for
now,
with
with
mcs
we've
also
hand
waved
away
the
actual
implementation,
so
we've
created
the
crds
on
both
sides.
Then
we've
defined
the
behavioral
spec
for
how
you
map
service
export
to
service
import,
but
there
is
no
canonical
implementation
for
how
that
actually
happens.
B
So
there's
there's
a
spec
for
what
an
implementation
should
do
when
it
sees
service
exports
in
in
your
clusters
that
are
attached
to
your
imaginary
cluster
registry,
that
we
will
have
also
one
day
and
and
the
service
imports
that
should
be
created,
but
yeah.
We
that
canonical
implementation
doesn't
exist.
But
I
know
that
like
submariner
has
been
looking
into
this
and
what
that
would
look
like-
and
I
know
that
there's
a
bunch
of
issues
open
to
implement
the
api
and
there's
actually
so.
B
This
is
something
that
is
probably
even
more
relevant
to
you,
but
I
know
that
istio's
been
interested
in
implementing
this
the
api
as
well
right.
So
I
don't
know
if
you've
talked
to
the
networking
working
group
or
anything
with
istio,
but
but
yeah.
So
there
is
no.
There
is
no
implementation
today
for
how
it's
done,
but
the
the
assumption
and
and
hope
is
that
there
will
be
multiple
right,
but
that
they
will
behave
in
similar
ways
right.
According
to
this
fact,.
D
Yeah,
I
mean
so
I'll
sort
of
go
over
briefly
how
we
decided
to
solve
the
problem,
and
I
don't
think
it
is
the
best
way,
but
it
was
sort
of
the
first
to
to
mine
was
basically
when
we
install
the
service
we
target
another
cluster,
and
that
was
sort
of
our
our
quick
and
dirty
method,
and
one
of
our
thoughts
going
behind
that
is
like
a
service
registry
is
another
sort
of
moving
part
to
it.
It
seemed
to
fit
our.
D
A
D
Right
so
it
would
be
a
service
primarily
on
the
on
the
green
cluster
that
would
copy
its
services
into
the
blue
one,
because
primarily,
we
wanted
to
touch
the
blue
one
as
little
as
possible
during
the
the
changeover,
obviously
for
rollback
purposes,
if
we
could
just
kill
the
green
cluster
and
leave
our
blue
running
in
production,
that'd
be
amazing
right.
So
we
wanted
to
install
as
little
as
possible
in
terms
of
services
on
a
blue
cluster,
but
still
have
it
routable
over
to
the
green.
If
that
makes
sense,.
A
A
D
Right
exactly
yeah,
okay,
that's
good
good
characterisation,
yeah
and
the
other
part
I
wanted
to
touch
today
was
the
sort
of
the
the
phase
three
of
it,
which
is
the
the
internal
load
balancing
the
the
top
from
the
north
south
traffic.
The
other
question
I
want
to
ask
was
you
know?
Obviously,
the
the
specifics
of
how
the
load
balancers
are
are
handled
is
up
to
the
cloud
provider
or
or
external
load
balancing
software.
B
This
is
a
really
good
question.
I
think
I've
certainly
had
some
thoughts.
I
don't
think
we've
gotten
there
yet
with
ncs,
and
I
think
this
is
probably
a
good
time
to
start
this
conversation.
Actually,
it's
also
a
good
segue,
because
I
think
then
one
of
the
next
items
on
the
agenda
for
today
andrew
brought
up
the
idea
of
node
port
multicluster
service
types
and
what
that
could
look
like,
but
I
think
I
think
we
need
to
have
a
conversation
about
what
what
other
service
types
might
look
like.
B
So
what
is
a
a
multi-cluster
service
type
load
balancer
like
I
think
it
seems
reasonable
that
there
might
be
one
single
load,
balancer
ip,
that
routes
to
the
multi-cluster
service
across
the
cluster
set,
and
then
the
mechanics
would
hopefully
then
be
similar
to
to
a
service
type
load
balancer
within
a
single
cluster.
But
I
think
there's
with
any
of
these
external
routing
concepts.
I
think
we
have
to
figure
out.
How
do
we
actually
describe
that
like?
B
B
D
A
C
A
What
do
we
want
to
do
with
like
primitives
around
registration,
if
we
should
have
like
a
similar,
open
call
for
use
cases
for
cluster
sets
so
that
we
can
we've
got
a
name
and-
and
probably
people
have
different
ideas
about
what
do
they
mean,
and
maybe
it's
time
to
start
writing
down?
What
do
we
actually
want
them
to
do
and
allow
us
to
express.
A
D
D
A
Thanks
a
lot
for
the
presentation
this,
this
was
super
interesting
to
me,
so
I
really
appreciate
you
coming
and
sharing
your
experiences
with
us.
That's
that's
the
kind
of
input
that
we
really
need
to
to
find
the
things
that
are
going
to
be
useful
to
provide
from
the
community.
So
it's
really
appreciated
thanks
a
lot
richard
yeah.
Thank
you.
This
is.
This
is
great.
B
Yeah
and
I
think
I'll
go
quickly
because
andrew
added
a
couple
bullets
that
I
think
are
probably
more
interesting,
so
I
just
wanted
to
let
everybody
know-
and
I
linked
it
in
the
notes,
but
we
actually
have
a
sigs
repo
now
for
the
alpha
implementation,
which
means
we
can
take
pr's,
so
there's
some
work
to
do
before
we
can
get
to
beta
quite
a
bit
of
work.
Obviously
we
need
some
implementations
for
one.
So
that's
that's
a
good
place
to
start
so
that
we
can
answer
hey.
B
Is
there
a
canonical
implementation?
Yes,
maybe
or
multiple,
so
we
have
somewhere
to
point.
Dns
is
a
big
open
question
that
I
think
we've
alluded
to
in
the
in
the
cap.
I
think
at
a
high
level
it
doesn't
seem
too
controversial,
but
let's,
let's
see
about
implementing
it
and
see.
If
that
holds
true,
I
think
I
think
we'll
uncover
some
surprises
there.
B
D
Yeah,
so
as
we're
talking
about
like
implementations
like
I
don't
know
what
folks
here
think
about
cluster
api
and
and
whatnot,
but
like
yeah
like
I
can
see
a
cluster
api
implementation
being
kind
of
like
the
maybe
like
an
obvious
candidate
for
this,
because
everything
everything
related
to
clusters
is
represented
as
crds
in
in
like
what
what
they
call
the
management
cluster.
So
it'd
be
kind
of
pretty
trivial
to
just.
You
know,
use
that
crd
as
like
the
cluster
registry
and
then
and
then
go
from
there.
So.
A
I
I'm
wary
of
attaching
to
any
provisioning
thing
with
the
hard
dependency
because,
for
example,
we
have
a
provisioning
api-
that's
not
part
of
cluster
registry
that
we
use
for
openshift.
As
I
understand
it,
also
like
the
thing
that
is
called
cluster
register.
Sorry
cluster
api
in
our
upstream
is
not
directly
supported
by
any
vendors,
so
I
think
vendors
put
additional
apis
in
front
of
that
in
order
to
use
it.
A
D
So
I
agree
with
that.
I
think
cluster
api
is
a
little
weird
in
that
it
is
a
provisioning
api,
but
because
everything's
you
know
in
crds,
like
you
can
layer
anything
you
want.
On
top
of
that.
So,
like
I,
don't
see
a
cluster
api
implementation
kind
of
violating
that
principle,
because
it's
it's
not
like
it's
not
strictly
provisioning,
I
guess
but
yeah.
I
think
in
general,
like
I
tend
to
agree
with
that
that
we
shouldn't
couple
to
provisioning
it
guys
too
much.
B
B
A
D
From
my
perspective,
it
was
mostly
just
like
there's
a
project
that
implements
clusters
as
crds,
and
so
it
would
be
an
easy
like
first
implementation
or
like
we
could
use
it
as
a
reference
implementation
to
actually
go
through
the
cycles
of
like
implementing
the
entire
mcs
api
and
figuring
out,
like
you
know
what
parts
of
the
api
feel
awkward,
what
parts
of
it
do
we
like.
So
that
was
really
the
angle
I
was
coming
from.
D
A
A
So,
let's
is
it
cool
if
we
maybe
zoom
in
on
what
the
registration
use
case
is
here,
so
it
sounds,
it
sounds
like
there
is
like
we're
we're
having
this
conversation,
because
there's
a
registration
use
case
is
the
use
case.
Is
it
that
we
just
need
to
have
a
record
of
like
endpoints?
Is
it
something
deeper
than
that?
Is
it
that
we
want
to
run
a
reconciler
that
will
watch
the
list
of
clusters
exactly
what
use
case?
Are
we
looking
for
from
registration
here.
D
D
Go
ahead:
sorry,
yeah,
but
yeah.
Basically,
what
I'm
saying
is
like
yeah
like
if,
if
a
client,
if
a
controller
was
implementing
like
the
api,
that
like
reads
the
service
import
and
creates
a
service
export
and
all
that
stuff
like
you,
would
need
to
be
aware
of,
like
yeah
the
list
of
clusters
and
then
based
on
that
list,
it
should
be
able
to
like
generate
a
keep
config
or
a
way
to
access
and
talk
to
each
cluster
and
pull
information
out
of
it.
D
And
so
like,
like
cluster
api,
seems
like
a
good
starting
point
because,
basically,
like
any
cluster
resource,
represents
a
cluster
and
there's
a
matching
secret
with
this
like
admin,
key
config
and
so
like.
That
is
an
already
good
starting
point,
but
we
can
use
that
pull
in
all
the
service
exports
and
then
reapply
the
service
imports
based
on
that.
D
E
B
Thinking
about
these
things
is
is
really
good
like
it.
I
think,
out
of
that,
it
sounds
like
we've
come
up
with
a
couple
use
cases
for
that
cluster
registry
doc,
and
we
good
to
to
think
about
that
over
the
next
week
and
really
get
them
down
at
the
next
meeting,
and
then
also
you
know,
node
port
and
then
load
balancer
type.
Two,
I
think
it's
we
should
start
thinking
about
what
those
service
types
could
look
like
in
a
multi-cluster
world.
A
B
A
As
just
for
my
own
subjective
thoughts
like
I
find
the
term
single
point
of
failure,
often
times
to
just
be
confusing,
and
to
eliminate
details
and
nuance
where
they're
usually
very
important.
So
I
am
more
relaying
that
as
something
that
people
have
told
to
me
rather
than
an
articulation
of
my
own
personal
opinion.
But
it
does
seem
to
be
a
concern
that
people
have
the
the
other.
One
is
that
there
are
many
environments
that
users
have
where
push
doesn't
work
for
them
for
whatever
reason,
because
it
crosses
a
an
addressability
boundary.
A
B
Yeah-
and
I
think
we
we
made
a
strong
point
of
including
that
in
the
mcs
cap
as
well,
the
idea
push
versus
pull
and
centralized
versus
decentralized
are
like
that
was.
That
was
a
key
conversation.
I
think
it's
important
whatever
we,
whatever
direction,
we
we
go.
We
should
make
sure
that
we're
accommodating
both.
D
I
actually
might
have
a
a
another
viewpoint
on
this
push
and
pull
primarily
based
on
sort
of
even
deployments
and
and
how
we
approach.
Our
ci
is
very
much
pull-based,
because
we
found
that
a
pull-based
method
of
of
sort
of
artifact,
retrieval
and
and
other
things.
They
just
tend
to
be
more
controllable
right
having
credentials
on
another
on
on
something
that
can
push
seems
very
dangerous
to
just
to
us
right,
and
so
we
prefer
a
pole-based
methodology
as
well.
A
And
that's
a
that's
another
piece
of
feedback
that
we
heard
around
previous
efforts
in
federation
is
that
if
you've
got
a
place
in
the
control
plane
that
holds
admin
credentials
or
cluster
route
credentials
for
a
bunch
of
clusters,
one.
That's
a
really
really
high
value
target
that
you've
added
to
your
api
surface
in
that
cluster
and
related
to.
A
So
we
need
to,
I
think,
be
careful
to
account
for
subtlety,
nuance
and
decomposition,
in
terms
of
which
service
accounts
are
doing
what
for
which
use
cases,
and
it's
very
likely
that,
if
we're
running
an
agent
that
is
programming
network
stuff,
that
that
needs
a
really
really
different
level
of
permission
on
particular
resources
within
the
cluster
besides
or
other
different
than
what
I
might
need.
If
my
job
is
to
deploy
helm,
charts
or
if
my
job
is
to
enforce
a
policy.
B
C
A
Any
other
perspectives
people
want
to
present
about
that.
We're
we're
nearing
the
end
of
our
time,
so
maybe
we're
talked
through
and
and
I
will
as
an
action
item
besides
getting
all
the
videos
uploaded,
which
I
guess
there's
a
bit
of
a
backlog-
it's
surprisingly
difficult
to
get
them
uploaded
and
put
into
the
playlist,
but
I
that
is
supposed
to
change
soon.
Now,
aside
from
that,
I
will
open
up
a
use
case
document,
for
what
do
we
think
cluster
sets
should
mean
and
what
should
they
do.