►
From YouTube: Kubernetes SIG Multicluster 2022 May 3
Description
No description was provided for this meeting.
If this is YOUR meeting, an easy way to fix this is to add a description to your video, wherever mtngs.io found it (probably YouTube).
B
D
D
D
A
A
A
centralized
api
server
to
a
spoke
managed
cluster,
a
workcr
on
the
hub
cluster
means
that
the
resources
defined
in
the
work
will
be
applied
on
a
spoke
or
managed
cluster.
That
was
just
a
quick
overview.
You
can
visit
the
project
website
for
more
details,
for
this
pull
request.
Enhancement,
it's
about
the
resource
status,
sync.
A
So
in
most
cases
the
user
on
the
hub
cluster
wants
to
know
the
real-time
status
of
an
applied
workload.
That's
done
on
the
spoken
manage
cluster,
so
this
proposal
is
to
provide
a
common
approach
for
the
users
on
the
hub
cluster
to
collect
those
workloads,
resource
statuses
that
was
applied
by
the
work
api.
A
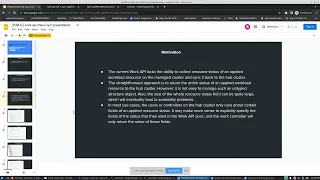
The
motivation
for
this
api
enhancement
is
the
the
current
work.
Api
lacks
the
ability
to
collect
those
visual
status.
It
only
shows
that
oh,
your
workload's
been
applied
and
that's
it.
So
the
straightforward
approach
is
just
to
return
the
entire
status
of
the
applied
workload,
but
it's
not
easy
to
manage
these
type
of
untyped
structure
object,
because
each
each
resource
status
might
be
different
and
it's
also
the
size
of
the
resource
status
might
be
quite
large
and
it
will
lead
to
scalability
problems.
A
A
So
the
spec,
the
spec
enhancement
that
we're
proposing,
is
under
the
spec,
we
add
a
workload
config
and
then
under
the
workload
configs
might
be
main
different
types
of
configuration
for
workload
so
in
in
this
instance,
we
create-
and
we
add,
a
new
spec
called
manifest
configs,
and
this
manifest
configs
contain
the
resource
identifier,
which
identifies
the
manifest
that
you're
trying
to
configure
and
then
the
status
sync
rules
that
we've
been
discussing
in
the
status.
Sync
rules,
there's
the
sync
type
and
then
there's
the
json
path
for
the
sync
type.
A
A
So
if
you
say
that
you
want
the
type
common
fields
and
then
it
will
just
return
those
results
and
then
the
spec
enhancement
example.
Here
this
is
the
before
what
we
currently
have
under
workload
and
under
workload.
Config
is
what
we're
proposing
of
adding
we're
we're,
adding
a
resource
identifier
which
represents
the
manifesting
here
up
here
and
then
the
the
static
single.
A
D
A
A
E
A
Okay,
I'm
gonna
continue
onward,
so
that
was
the
spec
enhancement
which
tells
which
fields
to
which
resource
which
manifests
and
which
fields
to
sync
and
in
the
status
is
to
capture
the
status.
Sync
return
data,
so
we're
planning
to
add
a
status
sync
field.
It
contains
the
sync
values
and
then
the
name
and
the
value
are.
The
name
is
the
alias
to
the
field
that
you
you're
trying
to
capture
on
the
resource
and
the
value
and
the
field
value.
A
Currently,
it
only
showed
that
the
apply
manifest
is
has
been
applied
and
completed,
and
then
we're
planning
to
add
that
to
show
that
the
resources
is
available
or
not
available
depends
on
the
the
sync
status
and
then,
if
the
status
is
synced
or
not
so
right.
Underneath
this
there's
the
identifier
to
tell
okay,
which,
which
manifest
is
it
this
status
sync,
is
for
and
this
these
conditions
are
for,
and
then
this
is
status.
Sync
value
represent
the
the
values
that
were
sent
over
from
the
spoke
cluster
to
the
managed
cluster.
C
B
Okay,
I'm
oh
go
ahead.
Yes,
I
have
a
question:
can
we
go
back
to
slide
six,
though
I
think
it
is
back
within
the
status
sync
rule
just
wondering
if
an
apologies,
if
this
was
already
discussed
on
the
proposal,
but
this
form
where
each
workload
knows
its
own
rules
and
the
common
fields
type
is
kind
of,
like
seems
like
a
way
to
help
out
with
some
good
defaults.
B
A
No,
that
is
an
excellent
suggestion
and
that
there
have
been
similar
suggestions
in
the
proposal
as
well,
where
we
don't
specify
each
the
rules
in
each
spec,
because
it
is
quite
cumbersome
to
do
so,
but
we
haven't
heard
so
the
the
rules
we
feel
like
the
rules
need
to
be
supplied
somewhere
in
the
api.
If
it's
not
in
this
api,
then
it
needs
to
be.
We
feel
like
it
needs
to
be
somewhere
else
like
a
policy
type
of
api.
A
So
we
haven't
had
any
good
ideas
yet,
and
I
think
hong
kai
and
others
also
suggested
something
similar,
and
I
think
I
suggested-
maybe
maybe
the
rules
here,
spec
rules
here.
Maybe
we
shouldn't
be
applied
to
this
this
api
proposal
and
then
we
just
leave
it
up
for
either
implementation
detail
so
another
or
another
spec
api.
Another
api
proposal
change,
but
we
just
haven't
come
to
a
conclusion
or
any
good
idea
how
to
do
that.
Yet,
but
definitely
that's
that's
a
really
good
suggestion
and
good
feedback.
C
A
B
Just
another
way
of
thinking
of
these
different
strategies,
I
guess
it
seems
like
it
depends
how
much
convenience
you
expect
someone
to
need
to
apply
across
multiple
types
of
work.
Api
crs
versus
like
how
unique
they
all
really
truly
are,
and
I
don't
know
if,
if
we
have
a
really
good
sense
on
that
or
not,
but
that
just
might
be
another
way
to
consider
all
of
these
different
strategies
for
abstracting
the
rule
set
into
a
more
broadly
applicable
or
less
broadly
applicable
package.
B
A
A
A
Are
there
any
more
topic
before
I
moved
on?
Okay,
I'm
gonna
get
to
the
going
back
to.
I
think
this
slide
the
alternative
one.
So
this
alternative
strategy
actually
took
it
from
hong
kong's
suggestion
he
went.
He
mentioned
that
we
can
do
a
simpler,
user-friendly
approach
first,
where
the
status
data
and
the
work
is
the
same
as
the
applied
resource
status.
So
the
main
concern
we
have
here
is
the
scalability
and
the
in
a
potentially
large
payload.
C
A
C
A
A
Okay,
I'm
gonna
talk
about
another
alternative
quickly,
so
another
alternative
to.
Instead
of
doing
this
proposal
is
directly
access
the
api
server
using
proxy
to
fetch
the
resource
status,
but
it
requires
the
hub
to
watch
multiple
api
servers
on
the
spoken
manage
clusters,
and
then
the
hub
also
needs
to
maintain
credential
for
each
of
them
and
watching
across
cluster
might
be
quite
expensive.
A
A
D
A
B
This
week
and
signet
is
meeting
next
week
to
talk
about
that.
So
just
wanted
to
give
the
heads
up
here
that
that's
when
that
is
scheduled,
and
that's
the
that's
the
news
on
that
and
then
the
other
item
here
is
to
talk
about
some
of
the
beta
blockers
for
both
mcs
api
and
cluster
id,
including
a
follow-up
from
the
last
meeting.
B
So,
regarding
the
e2e
tests
I
and
really
for
both
of
these,
I
went
and
dug
up
some
of
our
prior
conversations,
since
we
haven't
revisited
either
of
these
in
a
while.
So
last
time
we
talked
about
this
was
actually
last
december,
and
what
we
wanted
to
do
then
was
actually
to
either
reword
this
graduation
criteria
or
separate
the
idea
out.
B
I
did
also
dig
in
directly
and
just
confirmed
that
of
the
tests
required
that
are
listed
in
the
test
plan
for
the
kep
one
exists
and
two
of
them
don't
yet,
but
since
we're
discussing,
how
could
this
instead
be
used
for
conformance
or
like?
Should
this
really
be
you
to
e-test
directly
against
the
mcs
api
reference
controller
implementation
right
now
or
you
know,
be
more
useful
for
the
providers?
B
D
D
B
Right
right,
no,
that
does
make
sense
and
I
think,
there's
also
kind
of
a
seed
of
like
there
is
this
reference
implementation.
At
this
point,
there's
now
like
real,
I
guess
out
in
the
world
implementations
which
was
the
the
direction
and
purpose
of
the
cup
in
the
first
place.
So
yeah,
I
think
there's
some
about
like
what
is
that
implementations
like
utility
and
like
testing
burden
on
it
on
only
itself
versus
something
that
we
can
provide
and
or
enforce
question
mark
to
the
implementation
providers,
which
that
is
more
hazy
to
me.
B
But
that
seems
like
that's
more
the
direction
that
that
is
valuable
and
also
just
to
emphasize
again
what
you
said
in
the
mcs
api
repo
and
even
it
sort
of
talks
a
little
bit
about
like
this
is
like
just
the
crd
part,
but
like
this
is
a
crd
you
can
install
directly
from
here.
So
you
can
like
test
your
implementations
against
like
the
the
api,
but
the
tests,
the
end-to-end
tests,
don't
you
know,
provide
a
similar
service.
D
I
guess
one
one
other
dimension
is
that
if,
if
we
think
of
the
the
test
that
you're
writing
as
effectively
a
new
conformance
suite
like
there
is
the
question
of
what
assumptions
will
that
suite
make
about
the
topology
of
the
environment
where
they're
being
tested?
Have
you
thought
about?
Have
you
thought
about
trying
to
characterize
that
that,
like,
for
example,
one
one
such
set
of
assumptions
could
be
that
you
have
exactly
n
number
of
clusters
as
a
starting
point
like
so
that
you
can
write
tests
expecting
that
there
are
n
available?
As
one
example?
D
D
B
Yeah
that
does
make
sense
and
there's
probably
some
I'm
not
super
up
on
the
e2e
framework.
But
I
imagine
there's
you
know
we
could
provide
some
sort
of
test
suite
generic
utility
that
provides
some
setup
guardrails
and
even
does
some
of
the
work.
But
I
don't
know
how
useful
that
will
be
to
every
implementer.
D
Yeah,
I
guess
one
one
test
like
sometimes
it's
useful,
to
take
an
example
for
these
kind
of,
like
nebulous
things,
like
start
with
a
very
concrete
example,
and
see
what
you
can
learn
from
that.
So,
for
example,
if
you
started
with
a
test
that
established
that
service
exported
from
cluster
a
is
imported
in
cluster
b,
like
what
does
what
does
the
body
of
that
test?
D
Look
like
what
does
what
assumptions
are
like
like
present,
if
you
do
an
exercise
where
you,
where
you
just
don't
bother
thinking
that
hard
about
those
kinds
of
things,
and
you
just
try
to
maybe
even
write
pseudocode
for
an
e
to
e
that
establishes
that
service
important
service
export
work
correctly?
What
can
you
learn
from
that?
What
assumptions
were
present
after
you
do
that?
First
draft
of
maybe
even
that
pseudo
code?
What
assumptions
can
you
tease
out
that
you
may
not
have
been
conscious
of
when
you
wrote
the
tests?
D
How
do
those
affect
how
to
frame
the
the
prereq
requisites
to
run
the
suite
that,
if
you
want
to
have
a
test
suite
that
is
runnable
against
any
implementation
of
mcs,
that
you
would
need
to
frame
for
the
purposes
of
constructing
an
environment,
to
apply
a
test
to
that's
going
to
fit
the
assumptions
embedded
in
the
suite?
If
that
makes
sense,.
B
Okay-
so
I
think
maybe
you're
talking
about
if
we
can
provide,
like
the
middle
part,
the
actual
like
test
and
then
provide
the
you
know
the
environment
variable,
that's
like
cluster,
a
cluster
b
or
whatever,
and
then
people
can
set
it
up.
However
they
want,
then
we
are
giving
them
something
useful
that
they
can
run
to
determine
that
they
can
form
that
they
can
run
in
a
like
sort
of
agnostic
way
to
their
infrastructure
that
they
conform
to
mcs
api.
Maybe
these
three
things:
yeah,
okay
and
then.
B
D
I
do
think
that
that
might
be
worth
like
that
last
part
about
the
reference
implementation
is
worth
paying
a
little
bit
attention
of
attention
to.
So
I
would
say
that,
in
the
presence
of
in
the
presence
of
an
like
api
spec
level,
conformance
suite
it,
I'm
not
exactly
sure
how
to
word
it,
but
like
something
that
would
be
good
to
collect,
is
to
do
or
or
to.
D
D
B
Okay,
but
I
think
if
I
reorganize
this
live
my
this
is
how
my
brain
is
reorganizing
right
now.
I
think
these
specific
end-to-end
tests
directly
on
the
reference
implementation
may,
what
I'm
hearing
is
they're
still
worth
pursuing,
since
that
implementation
should
still
exist
and
should
conform
to
this
suite
and
those
those
are
potentially
the
basis
of
any
conformance
suite.
We
provide
itself
anyways.
D
Yeah,
I
think
that
makes
sense.
There's
there's
certainly
like
individuals
that
you
could
speak
to
in
our
community
that
have
experience
working
through
the
challenges
of
doing
that
last
nested
breakpoint
under
levels
of
conformance
suite
options.
There's
there's
certainly
plenty
to
learn
about
how
and
to
what
extent
that
is
achieved
in
kk
for
kubernetes
level
conformance.
I
think
I
think
the
one
last
thing
that
I
would
say
is
like
when
we
say
provide,
you
know
a
way
to
configure
the
test
to
me.
B
Yeah,
I
think,
that's
fundamentally
what
for
even
all
the
tests
that
we've
already
identified,
that's
the
minimum
and
yeah.
I
think
that's
the
format
that
we
would
basically
require.
I
guess
that
we
need
two
coupe
configs
for
clusters
that
are
enabled
with
your
version
of
mcs
whatever.
However,
you
turn
that
on
on
your
side,
you
know.
D
B
B
B
B
Yeah,
those
are
the
two
main
blockers
that
I
wanted
to
get
a
confirmation.
Slash
conversation
going
with
everybody
here
feel
free
to
comment
on
or
talk
in
the
stock
to,
if
there's
anything
else,
I'm
missing
or
if
you
have
any
other
comments.
But
this
is
this-
is
the
status
today
and
the
mini
nitty
gritty
details
of
the
last
bits.
D
D
If
you
have
anything
you'd
like
to
share
with
the
group-
and
you
know
I'll,
just
reiterate
what
we
say
in
the
kubecon
deep
dive,
which
is,
it
is
wonderful
to
share
problems
that
you
have
no
solutions
for
we'd
love
to
know
what
you're
struggling
with
we'd
love
to
know
what
you're
doing
about
it,
but
you
don't
need
to
tell
us
what
you're
doing
about
it
or
even
know
what
to
do
about
it
to
share
it.
We'd,
just
love
to
know.
Thank
you.
Everybody
have
a
great
day,
see
you
next
time.