►
From YouTube: KEP Review: Object Bucket API (28MAY2020)
Description
No description was provided for this meeting.
If this is YOUR meeting, an easy way to fix this is to add a description to your video, wherever mtngs.io found it (probably YouTube).
A
A
A
B
A
Okay,
this
is
just
this
is
just
for
my
notes
anyway,
but
so
before
we
get
into
the
the
expanding
API
is
I
spent
some
time
kind
of
ballparking
mapping
out
what
policy
and
identity
might
look
like.
I
dropped
a
reply
to
Andrews
post
in
the
Google
group
to
kind
of
expand
on
on
what
I
might
think
those
api's
look
like
and
I've
got
a
doc
here
that
is
linked.
A
So
if
you
go
to
this
link,
not
that
pull
row,
sorry,
this
link
that's
kind
of
sort
of
put
like
a
map
and
a
kind
of
a
write-up
of
the
api's.
Before
we
get
into
that
I'd
like
to
propose
something
or
address
some
process.
Real
quick
I'd
like
to
propose
a
additional
weekly
kind
of
stand-up
meeting,
maybe
on
Mondays,
if
that
works
for
for
the
main
contributors.
A
On
top
of
that
like
to
smooth
that
process
out
and
make
the
the
process
a
lot
more
collaborative
because,
right
now,
it
really
is
just
our
team.
That's
kind
of
spit
ball
on
the
ideas
and
bringing
them
back.
I
would
like
to
get
more
input
throughout
the
week
and
mostly
for
the
purpose
of
one
making
sure
that
the
input
we
got
and
that
we're
working
against
is
and
then
the
changes
were
generating
from
that
are
on
point
before
the
meetings,
because
there
been
times
we
got
the
information,
we
went
off
awesome,
the
back.
A
It
wasn't
what
you
know.
We
didn't
interpret
it
in
the
same
way
that
people
had
thought
we
had,
and
so
you
know,
Lee's
system
in
efficiencies
we
feel
you'd
be
more
productive,
more
collaborative
if
we
could
all
get
together
once
during
the
week,
make
sure
that
we're
on
track
so
that
the
reviews
go
a
lot
smoother
would
Monday
work
for
for
those
who
are
interested
sometime,
Monday,
yeah.
A
A
B
A
B
A
I
was
thinking
it
should
be
no
more
than
30
minutes
we're
not
trying
to
incorporate
new
ideas,
we're
just
trying
to
make
sure
that
the
changes
we're
making
is
the
kept
are
on
track
from
the
previous
review.
You
know
what
I'm
saying
so
that
what
we're
all
on
the
same
page
come
the
the
next
review,
so
it
shouldn't
be
long.
It
should
just
be
like
this
is
what
we're
doing
yeah.
D
D
B
B
D
A
Yeah,
so
well
all
should
an
email
out
we
can.
We
can
get
that
in
the
calendar,
hopefully,
okay
and
then
the
the
other
part
I
want
to
talk
a
little
bit
about
division
of
labor
like
I
said
it's
thus
far
hasn't
been
super
collaborative
in
terms
of
you
know,
just
the
red
hat
guys
going
off
coming
up
with
an
idea
and
bringing
it
back
so
we'd
like
to
get
a
lot
more.
A
You
know
input
and
distribute
distribution
of
work
from
the
community,
and
so
I
was
gonna
suggest
in,
given
that
we,
so
we
thus
far
have
been
working
mostly
on
the
storage
stuff.
If
someone
could
pick
up,
we
have
less
expertise
on
the
identity
and
the
access
policy
stuff.
So
if
someone
feels
like
they
could
contribute
there
we'd
appreciate
them.
You
know
picking
up
the
ball
on
that
and
working
with
us
throughout
the
week
to
kind
of
make
make
up
these
api's
line
up
when.
A
E
D
C
A
A
C
C
C
A
A
Get
into
the
meat
of
the
conversation
here,
zoom
this
end
and
again
this
link.
The
link
to
this
is
posted
in
the
kept
notes
for
this
week.
So
having
read
Andrews
yeah,
that
was
a
really
good
write-up
that
you
post
in
the
Google,
Group
and
I.
Really
she
ate
that
so
the
the
takeaway
I
had
from
that
was
initially
thinking
that
so
you
know
it
was
mentioned.
Last
week,
three
columns
three
separate
portions
to
this
entire
system.
A
We
have
the
storage,
we
have
identity
and
we
have
policy
to
those
on
their
own,
are
pretty
straightforward,
I
think,
particularly
for
you
know
minted
credentials.
That's
a
a
pretty
ubiquitous
process.
There's
some
nuance!
For
you
know:
GCP
uses
private
keys,
which
are
a
kind
of
a
JWT
formatted
key
rather
than
the
AWS.
You
know
access
Quinto,
a
secret
key,
but
beyond
that
the
API
isn't
I,
don't
think
incredibly
complicated
the
the
thing
that
I
wanted
to
really
talk
about.
A
The
most
right
now
was
service
account
integration
and
having
read
through
Doc's
on
on
the
three
major
providers.
My
sense
is
that
they
all
do
it
differently
enough,
that
it
makes
it
difficult
to
wrap
and
it
wrap
it
all
with
an
API
and
so
on
the
the
left
hand
side
here.
Let
me
just
make
sure
this
is
very
visible.
A
You
know
resource
so
service
accounts.
The
the
kind
of
high-level
summer
is
Google,
has
a
one-to-one
mapping
as
I
understand
it
through
a
workload
identity
so
that
a
kubernetes
service
account
is
mapped
to
a
Google
service
account
when
that
cube
service
account,
carry
out
an
action
against
the
you
know
the
Google
platform,
it
doesn't
do
it
directly
to
map
to
that
Google
service
account
which
has
its
own
I,
am
role
and
policies,
and
then
that's
how
its
determine
whether
or
not
it's
authorized
to
carry
out
those
actions
so
that
that's
pretty
clean.
A
That
would
be
relatively
easy
to
automate
and
as
easy
represent
AWS.
On
the
other
hand,
kind
of
short-circuits
that
a
little
bit
instead
of
representing
or
binding
a
service
account
to
an
AWS
service
account
they
assign
an
iamb
role
in
AWS
directly
to
a
kubernetes
service
account,
so
there's
no
need
to
generate
or
bind
an
AWS
service
account
that
that's
not
part
of
the
process
now.
So
we
have
two
distinct
ways
of
integrating
service
accounts
and
then
Anna
sure.
C
A
A
When
you
deploy
an
eks
cluster,
you
have
the
option
to
turn
on
service
account
integration,
so
the
cks
cluster
will
deploy
with
some
controllers
that
are
capable
and-
and
it
will
also
part
of
it,
part
of
the
process
of
that
the
API
calls
from
within
the
pod
to
the
AWS
API
will
be
proxy
through
part
of
this
infrastructure
in
the
cluster.
The
surface
account
that
is
making
that
is
associated
with
this
pod
will
be
annotated
with
a
AWS
define
annotation
that
associates
it
to
a
role
I
believe
by
an
AR
n
number
good.
F
A
C
A
Cube
networking,
okay,
yeah,
makes
sense
right,
so
so
those
are
the
two
that's
how
the
two
processes
are
distinct,
meaning
that
if
I
were
to
have
an
API
to
bind
a
service
account
individually.
You
know,
in
addition
to.
Rather
so
we
have
the
identity
request
for
minting
credentials.
If
we
had
a
a
secondary
set,
our
secondary
pair
of
api's
for
binding
service
accounts,
the
logic
wouldn't
be
the
same
between
the
two
and
the
workflow
wouldn't
be
the
same.
A
One
of
them
would
be
generating
a
service
account
and
binding
it,
which
is
a
distinct
process
from
creating
policy
all
right,
because
we're
we've
divided
this
into
identity
policy
and
storage
counts.
So
for
creating
an
identity,
that's
relatively
straightforward
on
the
Google
platform,
but
in
AWS
we
wouldn't
be
creating
a
we
wouldn't
be
binding,
a
service
count
to
anything
because
that's
already
a
policy
operation.
So
the
access
policy
request
instead
of
saying,
create
a
policy
for
this
ID
or
this
user.
It
would
be
create
a
policy
for
this
kubernetes
service
account
right.
So
we
have.
A
D
B
Agree
that
that,
in
principle,
that
would
be
really
hard
to
do
and
I'm
not
and
I'm,
not
completely
sure
it's
necessary,
because
these
systems,
both
of
those
systems,
live
already
today
right.
So
there
are
already
mechanisms
for
to
automate
that
binding.
If
you
will
between
service
account
in
kubernetes
and
whatever
the
host
I
am
infrastructure
is
so
it
strikes
me.
This
is
mostly
a
problem
of
two
things.
B
One
of
them
is
indicating
in
the
provisioning
of
the
of
the
access
credentials
piece
of
the
policy,
whatever
you
can't
quite
read
it
here,
but
the
middle
middle
out.
Sorry,
let
me
explain
basically
being
able
to
to
say
you
know:
hey
here's.
My
kubernetes
service
account
now
you
mister
driver
on
the
other
end.
I
expect
you
to
understand
how
possibly,
with
the
help
of
a
flag,
to
understand
how
to
figure
out
who
I
am
on
the
other
end,
and
that
may
be.
B
Oh
I've
got
a
mint
somebody
on
the
other
end
right,
so
it
becomes
a
credential
minting
problem,
but
I
hide
it
underneath
the
access
piece
right.
In
other
words,
if
you
give
it
to
the
driver
and
basically
say
well,
here's
a
flag
and
here's.
My
current
kubernetes
service
account
and
I
want
this
kind
of
access
to
this
bucket.
Then
the
driver
is
free
to
mint
a
new
I
am
user
if
necessary,
or
just
figure
out
who
the
car
I
am
equivalent,
is
and
just
meant
the
policy.
You
see
what
I'm
saying.
A
A
Yes,
I
I
thought
about
that
too.
I'd
had
the
same.
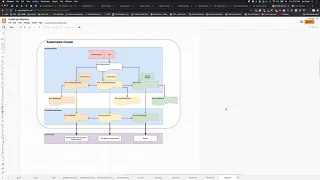
I
have
a
lot
of
diagram,
so
it
look
like
this
have
been
spitballing
his
ideas,
the
that
works
well
in
Google,
because
you
do
have
an
entity,
an
identity
and
the
Google
platform
that
you
would
create
right
so
either
creating
key
or
creating
a
service
account
Google,
but
I
think.
The
issue
is
that
that
workflow
doesn't
work
on
AWS
yeah,
because
there's
no
identity
to
create
in
the
cloud
platform,
but.
B
But
no,
you
don't
have
to
create
an
identity
right.
Yes,
that's
my
point.
My
point:
is
you?
Could
you,
if
you
know
the
kubernetes
service
account,
you
can
write
the
rule
against
that?
In
other
words,
you
leave
it
up
to
the
driver
to
decide
whether
it
needs
to
mint
an
identity
or
not,
but
chances
are
in
both
the
google
in
AWS
cases,
where
we're
relying
on
this
that
that
identity
is
already
minted
and
so
you're
really
only
looking
it
up
and
in
the
in
the
AWS
case
it
sounds
like
it's
a
trivial
lookup.
A
B
But
the
all
refers
to
the
kubernetes
service
account
right
right.
In
other
words,
if
you
know
the
kubernetes
service
account,
then
the
driver
not
not
the
piece
in
not
the
kubernetes
code,
but
the
the
code
that
is
interacting
with
the
cloud
provider
knows
if
it's
the
AWS
version
of
this
it
says:
okay,
I'm,
just
gonna.
Look
for
the
policy
against
this
account
and
modify
the
policy
against
this
service
account
in
the
Google
side.
B
B
B
And
possibly
also
this
has
been
done
and
oh
by
the
way
you
need
to
to
set
these
credentials
back.
So
in
the
case
where
there
isn't
a
mapping
and
what
you've
had
to
do
is
actually
mint
a
user,
then
you
have
to
then
you're
gonna
have
to
do
the
old,
credential
minting
and
secret
mounting
things
to
make
those
credentials
available
to
the
API.
So
I'm
saying
I
could
do
that
new
models.
B
What
does
that
mean?
Okay?
So
if
you
think
about
this,
there
is
a
piece
that
has
to
happen
in
the
cloud
and
I'm
saying
that
for
the
most
part
for
this
access
stuff,
it
is
a
sort
of
trust
me
I.
Did
it
right,
you
don't
get
handed
back
any
kind
of
identifier
or
whatever
right,
but
there
is
one
case
where
you
do
need
something
handed
back
and
I'm
talking
about
the
middle,
the
middle
part
of
the
graph
here
and
that's
the
case
where
I
actually
minted
a
user.
B
That
is,
for
the
use
of
this
particular
access
to
this
bucket,
so
I'm
minting
a
user
per
access
request
in
this
case
and
I,
maybe
I'm
not
using
the
service
account
information.
You
sent
me
at
all:
it's
effectively,
not
not
relevant
in
this
case
I,
just
minted
a
user,
and
so
now
the
pod
needs
to
actually
explicitly
act
as
that
user,
instead
of
implicitly
through
the
kubernetes
service
accounts
run.
So
in
the
explicit
case,
it
needs
to
do
that
by
plugging
those
recorded
credential
parameters
into
their
API.
B
D
C
C
A
So,
and
really,
let
me
say
back
to
you
what
I
think
you're
saying
said:
I
know
that
I'm
tracking
here
so
we're
essentially
saying
that
this,
the
API,
the
user
side
API
for
an
identity
request,
if
it's
in
this
case
we're
not
minting
credentials
assuming
that
we're
only
associating
service
accounts
in
the
case
of
Google.
This
ends
up
going
straight
here
right.
If
you
guys
can
see
that
arrow
there.
B
B
A
B
Well,
given
this
these
parameters
from
the
class
and
given
what
you've
told
me
about
the
service
account
and
given
what
I
find
when
I
look
in
my
cloud,
I'm
going
to
do
and
and
the
only
thing
that's
a
little
bit
squirrely
about
this-
is
that
sort
of
maybe
I'm
going
to
give
you
credentials
to
record,
maybe
I'm
not
and
and
I,
don't
know
how
squarely
that
is,
but
it
that's
the
only
part
about
this
process.
That
leaves
me
with
a
little
bit
of
a
bad
taste
is.
B
A
Told
I've
been
down
this,
this
train
of
thought
as
well.
That's
actually
why
I
ended
up
settling
on
if
you
can
read
the
name,
its
identity
key
request
here,
and
the
idea
for
this
was
that
this
is
strictly
for
minting
credentials.
Nothing
to
do
with
service
accounts.
Access
policy,
on
the
other
hand,
could
be
a
lot
more
flexible
if
the
service
account
needs
to
be
created
in
Google,
it
just
creates
and
associates
the
role
in
AWS
it
already.
It
would
just
associate
the
role.
C
B
Is
that
if
you,
if
you
think
of
layering
the
access
policy
request
over
the
bucket,
you
know,
one
of
the
interesting
questions
is
what
do
you
exposed
to
the
pod?
Do
you
expose
to
different
things?
The
bucket
and
the
access
policy
request,
or
since
the
access
policy
request
implicitly
has
to
depend
on
a
bucket
anyway?
B
A
Yes,
that's
I
think
that's
probably
not
the
optimal
way
to
go
here
that
it's
not
shown
in
the
graph,
but
pretending
for
a
moment
that
the
pod
also
has
a
secret
attached
to
it.
Then
yeah
I
think
that's
right
way
and
it
would
it
works
better
for
scale
too
I
think
otherwise.
You're
gonna
have
a
you
know
to
to
to
in
API
objects
for
every
bucket.
You
create.
C
A
Which,
actually
so
we've
been
going
back
and
forth
between
how
we
deliver
the
info
to
the
pod
and
there
we're
kind
of
living
on
this
optimistic
assumption
that
the
pod
would,
you
know,
will
be
modified.
We
will
have
an
update
to
the
qulet
somewhere
down
the
road,
so
that
we'll
be
aware
of
this
new.
You
know
bucket
api
and
the
same
way
ages.
Four
volumes
it
where
right
now,
when
we're
designing
this
api,
where
should
we
be
coming
at
it
from?
A
B
Well,
so
you
missed
some
of
the
earlier
conversation
where
sada
felt
pretty
strongly
that
this
ought
to
be
its
own
first-class
thing,
and
my
only
caution
there
would
be
stepping
into
that
space
is
likely
to
increase
the
cycle
time
on
this
I
think
considerably
so
I
would
view
it,
as
we
should
sticks,
put
a
stake
in
the
ground.
That
says
we
start
with
secrets,
and
then
we
also
proposed
this
other
thing
and
when
it
gets
through,
maybe
we
can
switch
over
or
something
well.
G
B
A
C
A
B
B
This
is
a
very
specific
kind
of
thing
that
you
might
want
to
have
different
kinds
of
policy
and
I
am
around
and
different
kinds
of
levels
of
protections,
and
things
like
that,
like
like
secrets,
for
example,
you
generally
have
your
own
mechanism
for
provisioning
them
might
be
out-of-band
for
the
rest
of
this,
and
so
this
sort
of
automatic
provisioning
of
secrets
as
something
that's
done
by
controllers.
It's
just
a
little
enough
different,
but
I
think
you
felt
like
you
know.
This
deserves
its
own
first-class
thing.
That
gives
me
an.
C
C
E
A
Me
see
if
I
can
repeat
it,
so
my
question
was:
should
we
assume
right
now
that
we
are
going
to
be
able
to
make
its
first
class
citizens
and
such
that
pods
can
define
them
as
part
of
their
specification?
And
you
know
we
get
all
the
scheduling,
benefits
out
of
that
and
versus
that
alternative
being
versus
leaning
on
secrets
to
do
as
the
delivery
mechanism
for
the
endpoint
and
credentials.
We.
E
I
think
this
was
I
mean
my
opinion
was
most
really
mostly
around
separation
of
concerns.
There
is
sensitive
information
that
should
go
into
secrets,
but
not
all
information
is
sensitive
and
there's
connection
information
that
is
independent
of
the
sensitive
information
that
deserves
to
go
with
the
bucket
itself.
What
is
the
name
of
the
bucket
and
etc?
E
And
exactly
so
in
the
distant
future,
we
can,
you
know,
have
couplet
directly
understand
the
bucket
access,
API
object
and
you
know
hold
off
on
mounting
until
all
of
steam
from
requisite
information
is
populated
at
the
right
places.
In
the
short
term,
we
could
use
a
CSI
driver
to
effectively
do
the
same
meet
here.
E
So
the
reason
I'm
thinking
a
CSI
driver
is
that
a
CSI
driver
naturally
has
the
ability
to
hold
off
a
pod
from
starting
so
until
a
CSI
driver,
that's
being
referenced
by
a
pod,
says
that
it
has
completed
mounting.
The
pod
will
refuse
to
start,
and
so
you
can
imagine
if
we
had
kind
of
an
adapter,
a
cosy,
adapter
CSI
driver,
the
CSI
driver
can
look
at
a
pod
and
say:
oh
I,
see
that
you
want
to.
You
know
this
bucket
access
a.
B
B
E
D
E
C
The
cozier
after
done
on
every
node,
yes,
it
has
to
something
that
might
be
easiest
to
vanilla,
there's
a
bucket
or
something
we
might.
We
could
use
an
admission
controller
to
paint
the
part
and
then
remove
the
taint
manned
by
the
quasi
controller,
and
everything
is
filled
out.
All
the
requisite
information.
E
C
B
It's
like:
do
you
do
environment
variables,
or
do
you
like
what
he's
suggesting?
Is
you
actually
put
a
well-known
file
in
a
well-known
location?
That's
specified
in
the
pod
spec,
and
so
it
knows
that
it's
going
to
be
looking
for
its
information
at
that
location
in
the
file
system
could
be
a
config
map
secret,
yeah.
E
Yeah,
so
that
is
a
possibility
if
you
use
a
config
map
or
a
secret,
but
the
problem
with
that
approach
is
now.
You
have
to
kind
of
deviate
from
the
kind
of
the
way
that
we
want
this
to
work.
We
don't
want
the
user
to
have
to
worry
about,
like
oh,
this
magic
config
map
or
this
magic
secret
is
going
to
contain
right.
Your
bucket
access
information
right.
We
don't
want
them,
you
have
to
modify
their
workloads
in
that
way.
Ideally,
that's.
C
H
D
H
I
think
a
file
can
be
a
great
interface,
because
that
really
releases
the
sort
of
another
step
of
unnecessary
documentation
and
to
understand
that
how
the
result
is
coming
to
the
pod
and
just
by
just
by
sort
of
binding
to
the
pod,
a
bucket
access.
It
makes
it
very
natural
to
just
get
the
information
in
some
requested
location
right
just
mounting
that
to
a
file.
That's
where
I
want
this.
In
my
pod,
for
example,
the.
A
H
A
A
H
I
I
didn't
really
grasp
what
was
the
intent
in
when
I
create
an
access
policy
request
right.
So
that's
that's!
A
user
kind
of
created
object,
yeah,
sorry!
So
what
it
will?
What
is
it?
What
are
you
the
meaning
of
it?
What
does
that
cut
to
say?
I
would
like
to
access
or
I
would
like
to
create
to
define
a
policy
or
which
one
of
these
a.
H
A
D
H
Okay,
so
I'm
still
missing.
One
piece
here,
I
think,
is
when
I,
when
I
provision
a
new
bucket
right
and
I
use
a
bucket
access
in
order
to
do
that
on
top
and
I
also
refer
to
a
access
policy
requests
right.
So
if
I
refer
to
one
request
versus
another
request,
that
I
mean
that
one
access
policy
versus
another
access
policy
that
let's
say
I
have
to
my
name-
is
based
at
a
pre
created
and
I
refer
to
each
one.
Is
that
affecting
then
the
new
bucket
in
the
cloud
in
some
way?
H
H
A
So
I
think
so
distinguishing
greenfield
from
realm
feeling
is
is
what
what
we're
saying
so,
the
in
the
case
of
a
new
bucket,
a
bucket
request
or
a
bucket
API
for
greenfield,
generates
a
new
bucket,
but
no
one
has
access
funky.
Yet
you
know,
besides
the
administrative
level
credentials
which
no
one
should
have,
then
the
access
is
created
for
that
bucket
and
provides
you
access
to
that
bucket.
Now
that
gets
into
the
territory
of
how
do
we
distinguish?
H
And
that's
that's
the
top
one
right!
That's
the
bucket
access
API
right,
but
the
access
policy
request
is
is
sort
of.
It
seemed
to
me
originally
that
you
were
trying
to
apply
that
only
for
new
buckets
only
when
I'm
actually
provisioning
a
new
bucket
I
would
also
want
to
set
that
policy
which
is
will
be
applied
to
others.
Trying
to
access
this
bucket
right.
That
would
be
sort
of
a
user
provided
policy.
H
A
This
is
something
we
I
feel
like.
We
need
to
discuss,
cuz
they
in
both
screenful
and
brown
field.
The
way
I
envisioned
it
at
least
is
that
should
act
pretty
much.
The
same
I
should
ask
for
policies
defined
in
a
policy
class
for
a
specific
bucket,
either
I
created
that
bucket
or
the
bucket
already
existed.
If
the
bucket
already
existed,
the
policies
are
applied,
you
know
either
to
the
bucket
policy
or
to
my
I
am
role
and
then
the
same
for
green
field.
A
H
B
H
H
B
H
So
it's
my
request
for
an
access
which
is
the
bucket
access,
I
presume,
unlike
the
white
structure
on
the
top,
but
then
the
other
is
specifying
access
for
anybody
else
in
the
world
right,
so
that
I'm
I
have
an
overview
of
of
access,
I'm,
providing
it
saying
this
should
be.
How
other
people
see
this
access
policy
and
I
think
these
are
different
roles.
We
can
merge
them
for
the
owner,
of
course,
but
does
it
really
make
sense
that
somebody
who's,
not
the
owner
or
you
know,
doesn't
have
other
permission
to
specify?
A
H
A
Of
the
way
we
can
control
it.
First
I
guess
answer
your
question:
is
I
I've
seen
it
as
a
singular
system
where
I
always
have
to
request
access
to
buckets,
even
if
I've
generated
the
bucket.
The
distinction,
though,
is
that-
and
this
came
out
of
a
previous
meeting
I
believe
that
so
the
Bucky
content
object.
A
H
H
B
H
A
B
B
H
B
H
So,
just
on
that
I
think
it
still
makes
more
sense
to
me
in
terms
of
the
terminology
that
was
used
here,
that
we
sort
of
drop
the
access
policy
request,
because
we
are
essentially
not
requesting
a
policy
we're
just
requesting
access
to
ourselves
right.
That's
the
intention
of
what
we
were
saying
here,
so
it
makes
more
sense
that
just
a
terminology
back
in
a
bucket
access
will
be
that
that
glue.
That
says
me
and
that
bucket
right,
saying
it's.
A
H
B
C
B
A
So
speaking
about
bucket
access
for
a
moment
kind
of
given
what
we
decided
on
secrets
versus
you
know
the
long-term
implementation.
Do
we
want
to
keep
the
bucket
access
around
right
now?
Cuz,
it
doesn't
mean
that
we
have
a
bucket
access
and
a
secret
the
bucket
access.
It's
gonna,
be
this
kind
of
just
appendix
hanging
off
and
not
actually
useful
to
the
pod
yet
well,.
H
How
the
connection
is,
how
do
you
do
that?
Either
we
talked
about
aligning
that
in
the
inside
of
the
pod
yeah
or
having
it
externally
representable.
As
some
you
know,
CR
API
that
can
specify
that
or
of
course
we
can
piggyback
the
bucket,
which
is
was
what
Obi
sees
did
of
course
in
some
way
right,
so
no
will
be
just
use
bucket.
Chats
now.
A
John
I
we
could,
it
does
mean
that
the
bucket
class
is
gonna,
contain
C
I,
don't
necessarily
know
if
we
want
to
do
that.
The
bucket
class
should
contain
information
pertinent
to
provisioning
a
bucket
region,
max
objects,
etc.
If
we
type
policy
into
that
means
every
bucket
I
provision
off
of
that.
It's
gonna
have
this
this
way.
Essentially
you
have
policy
and
then
provisioning
parameters
at
that
point,
which
means
that
you're
gonna
have
you
know
end
times.
I
am
bucket
classes
for
every
permutation
of
policy
and
and
provision.
B
D
B
I
think
I.
Let
me
see
if
I
can
understand
what
the
the
current
issue
is.
There's
there's
two
problems
here:
one
is
that
how
do
I
initiate
the
provisioning
activity
to
provision
access
to
a
bucket
right,
so
what
controller
picks
up?
What
piece
of
thing
I've
been
thinking
of
it
as
a
CR
right,
like
an
in
this
case,
access
policy
request
or
bucket
access,
whatever
you
want
to
call
it.
B
So
there
is
a
thing
that
you
define
that
would
create
the
access,
then
there's
a
slightly
different
problem,
which
is
that
thing
may
result
in
some
credentials,
and
you
also
have
storage
endpoint
from
the
bucket
information
itself,
so
that
set
of
stuff,
the
storage,
endpoint
and
possibly
the
credentials
have
to
be
provided
to
the
pot.
And
since
we
don't
expect
pods
to
be
able
to
understand
and
Buckett,
you
know
access
policy
requests
or
will,
if
we
rename
that
whatever
we
call
it,
we
need
another
entity.
B
That
is
the
thing
that
conveys
that
information
to
the
pot
and,
right
now
it
sounds
like
the
proposal
was
very
nerve.
Could
it
be
secret
nearer
turn,
but
not
super
near-term
would
be
to
do
a
CSI
driver
with
one
of
these
in
line
femoral
volumes
and
then
longer
term,
maybe
is
actually
these
one
of
these
access
policy
requests
is
directly
understood.
Does
that
make
sense.