►
From YouTube: KEP Review: Object Bucket API (14May2020)
Description
No description was provided for this meeting.
If this is YOUR meeting, an easy way to fix this is to add a description to your video, wherever mtngs.io found it (probably YouTube).
A
Okay,
we
are
recording
now
I
believe
at
least
indicates
that
so
welcome
everybody.
This
is
the
May
14th
review
of
the
object
bucket
API
kept
I'm
gonna
be
going
over
changes
that
we've
made
since
the
last
meeting
last
week,
and
then
I've
got
a
couple
more
points
in
the
agenda
at
any
moment
feel
free
to
interject.
Ask
questions.
Interrupt
me
I
like
to
have
conversations
as
a
as
they
evolve
throughout
the
the
discussion
here.
A
So
firstly,
the
most
significant
change
that
came
out
of
the
last
meeting
is
a
transition
from
a
one-to-one
model
to
a
many-to-one
design,
where
we
have
many
bucket
objects
that
will
connect
to
a
single
bucket
content.
So
this
is
most
pertinent
in
sharing
of
buckets.
We
feel
that
this
more
closely
represents
the
actual
lifecycle
of
buckets
in
the
way
they're
consumed
buckets
are
generally
excessed
by
many
many
separate
clients,
or
at
least
a
handful,
almost
always
more
than
one.
A
A
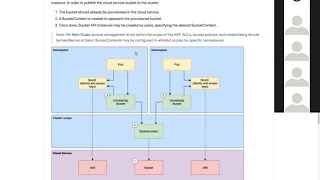
So
in
this
case
here,
this
diagram
depicts
the
first
a
user
creating
a
bucket
on
the
left
hand
side
here.
The
Creator
namespace
creates
the
bucket
by
referencing
the
Bucky
class,
a
Bucky
content
object
is
created,
the
bucket
gets
provisioned
and
then
a
another
user
in
another
namespace
can
create
a
bucket
in
the
same
mode
of
if
you
think,
I
like
pv
to
PVC
static,
binding.
The
bucket
will
reference
this
bucket
content
by
name
and
through
that
workloads.
Can
then
access
that
back-end
storage,
endpoint.
B
Is
Andrew
yeah
I
so
that,
of
course,
that
opens
up
a
huge
number
of
questions
that
the
doc
in
many
cases
just
punts
on
and
so
I
suspect
that
you
have
answers
to
some
of
those
but
but
didn't
want
to
make
them
normative.
But
I'll
just
mention
a
couple
which
is
you
know
how
do
I
as
a
user
when
I'm
requesting
my
first
bucket
keep
anybody
else
from
accessing
it,
since
I
won't
have
presumably
rights
to
the
managing
the
content
piece
of
it
and
then
there's
all
the
questions
about
how
do
we
manage
life
cycles?
A
Right
so
the
the
first
question
we
didn't
really
go
over
last
week
and
I
haven't
yet
documented
it
because
I
wanted
to
pitch
it
to
the
group,
so
I'm
glad
you
brought
it
up
and
the
case
where
I've
created
a
bucket
dynamic,
are
had
created
a
bucket
dynamically
I
should
not
have
write
access
to
that
bucket
content
right.
So
our
thinking
has
been
well
a
filled
in
the
bucket
object.
A
A
And
I
only
have
access
to
it.
This
is
reflected
in
something
that
we
talked
about
last
week
and
has
since
been
added
to
the
API
a
list
of
I've
used
the
word
bindable
namespaces.
That
may
not
be
the
most
descriptive,
but
a
list
of
the
namespaces
that
the
cluster
will
uses
a
white
list
for
namespace
access
right.
So
if
at
a
bare
minimum
the
originator
should
appear
in
this
list,
are
the
originators,
namespace
and
expanding
on
that?
Maybe
something
in
the
bucket
could
also
allow
other
namespaces
I,
don't
know.
B
A
B
A
B
A
Automate
at
at
the
bucket
level-
and
that
is
the
object,
storage,
Ackles
and
access
policies
right.
So
there
there's
a
difference
between
saying
this
is
private
to
this
set
of
credentials,
because
that's
a
object,
store
layer,
access
policy
and
I.
Don't
think
that
at
the
moment
anyway,
we've
really
touched
on
how
we
want
to
handle
that
or
if
we
do
I
think.
C
Add
to
what
you
see
that
we
we
wanted
to
have
some
exposure
of
this
feature
to
the
user,
but
most
of
it
would
be
exposed,
I
guess
to
an
admin
that
can
change
it.
So,
just
like
a
network
policies
that
you
can
set
a
name,
a
school
saying
this
name,
namespace
selectors-
can
access
me
example
right,
so
I
think
it's
similar
to
what
an
admin
would
set
for
a
namespace
as
a
policy.
D
That's
that's
a
good
question,
because
one
of
the
core
aspects
of
object-
storage
that
no
one
owns
a
bucket
itself,
it's
more
like
which
policy
does
these
set
of
credentials
have
which
enables
it
to
access
certain
objects
or
pockets.
So
these
are
graham
that
you'd
have
on
the
screen
right
now
you
point
out
that
the
secret
it's
been
provided
by
by
the
pot
so
I,
don't
know.
A
Me
touch
on
that
real
quick,
so
the
to
your
question
of
like
is
the
pod,
creating
it
or
is
it
being
brought
in.
Firstly,
the
solid
lines
here
just
represent
references,
not
creation
or
ownership,
and
the
expectation
is
that
cozy
and
cozy
animation
will
not
mint
credentials
and
will
not
create
users,
which
is
separate.
So
I
am
here
I'm
trying
to
represent
separately
because
we're
not
expecting
to
hand
out
credentials
and
the
brown
field
case.
There
is
room
for,
as
you
mentioned,
the
the
bucket
policies
that
that
bridge
credentials,
two
buckets
and
defined
permissions
right.
B
A
Yes,
that's
been
something
sorry,
I
know:
it's
been
a
few
meetings.
The
consensus
has
been
up
till
now.
That
cozy
should
be
more
concern
or
exclusively
concerned
with
bucket
operations
and
because
I
am
differs.
I
am
is
a
different
interface
and
there's
many
different
implementations
of
it
between
cloud
services,
and
so
we
would
effectively
have
to
define
a
separate
set
of
interface
or
separate
interface,
rather
for
I
am
operations
and
for
bucket
operations,
which
is
something.
B
A
F
One
question
we
got
in
this
picture:
maybe
not
this
picture
brown
field,
but
more
dynamic,
I'm,
more
concerned
that
in
the
user
names
base,
we
have
a
secret
which
refers
to
the
cloud
service.
I
am,
and
basically
this
secret
allows
users
to
create
new
buckets
in
cloud
service
seems
like
we
allow
users
too
much
here
like
to
grant
users
permission
to
create
new
buckets.
It's
really
like
I
write
so.
A
I'm
glad
you
brought
that
up
so
there's
a
whole
section
down
here
on
this,
and
we
are.
This
is
a
kind
of
brief,
a
paraphrasing
of
how
secrets
are
documented
in
CSI
and
the
the
way
it
breaks
down
is
provisioners
should
have
if
the
secret
is
going
to
be
used
for
the
lifetime
of
that
provision
or
if
it's
going
to
have
higher
level
privileges
that
secret
for
the
provisioner
should
be
directly
attached
to
the
provision
or
share
the
namespace
not
be
available
to
users.
A
If
operations
are
per
class,
there
are
provisions
for
begins,
similar
CSI,
specific
naming
of
a
secret
for
that
class
to
be
used
and
then,
as
well
as
a
per
bucket
operations,
leaving
room
for
if
a
user
has
permissions
permission
to
create
buckets,
they
can
provide
the
secret.
Now
we
lean
on
the
IMO
policy
here,
because
if
that
user
provides
a
secret
and
that's
secret,
the
credentials
don't
have
permission
to
get
buckets,
then
they
don't
get
a
bucket
and
we
return
an
error.
You
know
appropriately
I'm.
B
I'm
still
not
a
hundred
percent
clear
on
this.
Are
you
suggesting
that
that,
if
I
want
to
dynamically,
if
I
want
to
do
a
greenfield
bucket
class,
a
bucket
if
I
want
to
do
a
greenfield
bucket,
that
involves
I
have
to
communicate
credentials
to
the
application
that
are
going
to
access
the
resulting
bucket
and
I
also
need
a
set
of
credentials
necessary
for
creating
that
resulting
bucket
right?
Yes,
I
reach,
which
set
of
credentials?
Are
you
referring
to,
or
are
they
the
same
right.
A
Now
that
that's
a
really
good
question
actually,
because
that
can
they
can
be
different
and
they
can
be
the
same.
I
can
have
a
set
of
credentials
with
permissions
to
create
and
audit
and
delete
buckets
supper
sector.
Dentals
only
permission
for
specific
bucket
only
allowed
to
read
objects
for
even
specific
objects
in
that
single
bucket.
B
A
A
B
D
G
You
know
some
of
those
additional
options
can
be.
You
know
defined
in
the
bucket
class
to
be
specific
to
a
provisioner,
and
so
we
can
punt
on
some
pieces
of
it.
But
I
think
that
we
have
to
have
all
right,
I
would
say
like
in
order
to
be
really
useful.
We
have
to
have
some
cross
compatibility
for
both
credentials
in
buckets.
So
what.
H
Would
that
look
like
I
mean
I
guess
the
idea
was
that
we
seem
to
be
going
down
this
rabbit
hole
with
skills
that
was
cooking.
So
the
idea
what
you're
us
to
like
pump
the
brakes
step
back
and
say
what
is
like
minimal
functionality
for
portability?
That
was
the
original
intent
of
this
without
being
opinionated
about
AI
M,
because
it
isn't
consistent
and
provider
to
provider.
So
right,
we
I,
guess
I'd
like
to
know
people's
opinions
about.
Is
there
a
common
set
that
makes
sense,
that's
minimal
enough
or
is
it
something
but
the
protocol?
H
B
The
thing
you
know
where
we
were
at
one
point
was
to
say:
look:
we've
got
three
sort
of
standard
api's
here.
Each
of
them
expects
to
have
handles
two
credentials
in
a
particular
way.
Now
what
those
credentials
can
do,
or
anything
else
yes
could
be
handled
with
opaque
parameters
in
the
bucket
class
for
the
case,
where
you're
minting
credentials,
and
so
those
could
be
passed
through
and
do
you
have
many
more
than
three
different
iam
systems?
B
Unfortunately,
right
you,
you
with
there's
a
whole
bunch
of
on-premise
s3
compliant
systems
that
have
completely
different
user
management
approaches,
but
they
necessity.
They
all
meant
what
looked
like
s3
credentials
at
the
end
for
accessing.
So
the
idea
was
that
you
could
hide
the
details
of
what
it
would
take
to
create
a
set
of
accesses
around
a
bucket
along
with
creating
the
bucket
and
then
just
provide
the
credentials
to
that
through
this.
B
I
The
direction
that
this
is
actually
going
with
the
separation
of
provisioning
of
bucket
from
minting
you
know,
I,
am
credentials
and
policy,
because
overloading
all
of
that
into
a
single
API
was
getting
very,
very
messy,
but
I
also
hear
the
feedback,
which
is
not
having
a
way
to
automate
being
able
to
mint
identities
and
policy
around.
That
is
going
to
leave
this
overall,
not
very
useful
for
end-users.
I
A
B
C
D
Think
we
can
actually,
because,
like
you,
brought
a
valid
point
that
on
premise,
there's
different
s3
providers
that
have
different
ways
of
managing
access.
So
if
we,
if
we
remember
thinking
that
every
each
one
of
these
providers
will
have
build
their
own
cozy
trident,
then
that
means
we
can
actually
delegate
the
responsibility
of
managing
access
to
the
driver
itself
right
so
I.
Don't
think
it
will
actually
take
away
responsibility
from
the
user.
D
B
G
Hey
I,
you
know
I'm
fine.
If
there's
you
know,
there's
separate
resources
and
separate
controllers
and
and
maybe
even
separate
provisioners
like
that's
all
fine
but
I,
but
I
do
feel
like
it
has.
It
all
has
to
be
in
in
cozy,
because
you
know
you,
you
don't
gain
any
compatibility
benefit.
If,
if
you
have
the
data
and
not
be
access
to
it,
you
know
both
in
the
both
in
the
same
set
of
standards
that.
G
I
That's
okay!
As
long
as
we're
talking
about
a
you
know,
strictly
separate
set
of
api's
for
minting
credentials
and
identities,
and
all
of
that
from
accessing
the
bucket
that
seems.
Okay
to
me,
you
can
say
it's
part
of
cosy
sure
that
that's
okay
as
well,
but
I.
Let's
separate
the
minting
of
identity
and
credentials
and
policy
separate
from
accessing
the
bucket
and
provisioning
the
bucket,
and
that
was.
B
I
B
Think
there
might
be
an
intermediate
here,
but
let
me
suggest
where
I
the
reason,
why
I
think
that
you
know,
though,
you've
got
identities,
you've
got
roles
or
the
equivalent.
You
know,
you've
got
access
and
the
is
you
know,
depending
on
your
system,
that
access
may
not
be
granted
until
the
object
that
you
create
exists
right.
So
you
you
know
you
might
want
to
mint
credentials
that
only
have
access
to
the
bucket
that
you're
about
to
create.
So
it
isn't
that
you
can
separately
provision
one
and
the
other.
B
Would
be
okay
argues,
they
need
to
be
in
the
same
system
and
they
have
to
be
some
awareness
that
has
to
exist.
Okay,
I
am
suppose
a
separate
stuff
after
bucket
stuff
sure
I.
The
separation
of
concerns.
I
agree,
has
some
value
and
allows
you
to
have
different
kinds
of
cardinalities
in
the
relationship.
G
G
But
then
you
could
also
say
you
know,
potentially,
okay,
that
here's
a
bucket
and
it's
accessible
to
all
of
the
namespaces
or
here's
a
bucket
and
it's
accessible
to
these
specific.
So
it's
like
a
it's.
You
know
either
there's
a
splat
field
in
there
like
in
in
our
back
or
there's
a
enumerated
list
of
namespaces
and
and
we
can
use
that
same
list
for
both
the
bucket
content
resources
which
which
equate
with,
like
you
know,
amount
and
then,
and
they
also,
we
use
that
same
list.
F
A
generic
if
I
may
wonder
generic
quit.
So
at
the
time
again,
like
a
couple
of
weeks
back
when
I
was
at
the
meeting,
we
there
was
no
possibility
for
dynamic
case
to
specify
the
bucket
name.
So
now
we
change
that.
So
we
can
specify
this
like
specific
bucket
name.
We
want
to
dynamically
provision.
Is
that
right.
B
Question
it
looked
like
you
know
you,
we
you
and
I
had
a
discussion
a
while
back
about.
Should
we
be
for
the
Greenfield
case.
Should
we
provide
explicit
bucket
name
or
should
we
effectively
leave
that
as
a
problem
you
could
specify
prefix,
but
if
you're
minting
a
bucket,
you
can't
guarantee
bucket
name
he's
saying
he
thinks
that
he
sees
in
here
that
you've
reverted
and
there's
back
to
providing
explicit
ID
right.
No
just.
A
To
clarify,
we
don't
yet
that
was
something
we
pulled
out
and
we
only
provide
for
a
bucket
prefix
and
if
the
chart
is
leading
to
that,
that
leads
me
to
another
point
about
the
names
of
these
api's
and
we
feel
that
calling
this
the
bucket
and
this
the
bucket
content
has
led
to
a
lot
of
confusion.
There's
been
comments
in
github,
there's
been
a
lot
of
a
lot
of
inks
within
our
own
team,
so
I
do
want
to
touch
on
that
now.
C
Yeah
I
want
to
understand
what
you
guys
were
suggesting
with
a
separate
API
versus
like
an
integrated
API,
so
I
understand
that
the
desire
for
sort
of
an
application
attached
to
bucket
right,
which
is
being
provisioned
and
the
lifecycle
is
attached
to
the
application
is,
is
something
that
is
leading
in
the
green
field
case
right.
So
we
make
it
like
provision.
Everything
like
credentials
and
everything
out
of
the
box.
I
mean
that's
that's
great,
but
can't
have
another
like
entity,
saying
like
a
bucket
user
or
something
like
on
those
lines
that
yeah.
B
A
bucket
would
be
directly
related
to
an
underlying
bucket
and
a
bucket
access
would
represent
a
particular
pods
access
to
a
bucket.
And
so,
if
you
wanted
a
green
field
in
case,
you
would
need
a
2
step.
You
would
need
to
provision
the
bucket
and
you'd
need
to
provision
the
access
to
it.
But
if
it's
in
the
brown
field
case,
all
you
would
need
to
do
is
provision
access
to
an
existing
button
and
so
yeah.
It
would
suggest
that
bucket
is
not
the
thing
that
a
pod
has
that
the
pod
has
a
bucket
access.
B
C
I
really
this.
This
is
a
key
thing
in
intamin
gene.
What
I
think
Don
will
also
be
safe
to
propose
here,
which
sort
of
highlights
what
what
does
where's
the
lines
cross
between
bucket
and
the
crap
scope
bucket
content,
and
what
is
h1
do
right
and
we're
trying
to
put
some
rules
on
them,
and
so
the
bucket
is
a
sort
of
a
intention
of
the
namespace
to
use
a
certain
bucket
resource
right,
the
orchid
content.
So
the
response
that
by
the
cluster
saying
that's
the
resource
we
should
use
or
I'm
referring
to
binding
existing
one.
C
G
So
the
model
that
that
that
I
would
kind
of
like
to
see
and
I
want
to
explain
kind
of
what
you
know
this.
This
actually
fixes
some
sins
created
and
Service
Catalog.
That
I've
been
that
I've
lived
through,
because
or
so
the
model
that
I
that
I
think
would
be
good
here
would
be
similar
to
roles
role.
Bindings
and
resources
in
the
turbinates
are
back
and
end
users.
G
So
to
you,
would
you
know
I
would
see
you
could
create
a
set
of
credentials.
You
know
we
call
that
whatever
we
want,
object,
users
or
credential
set
or
something
along
those
lines
and
and
then
the
bucket
content
you
know
could
be
you
know
it
can
it
can
do
a
little
bit
do
a
role.
This
bucket
is
mountable
and
maybe
also
it.
It
is
a
binding
between
a
bucket
and
the
credential
or
maybe
those
two
things
are
separate.
G
The
the
reason
why
I
kind
of
you
know,
or
one
of
the
things
that
that
we
solve
a
Service
Catalog,
is
in
Service
Catalog.
We
kind
of
conflated
a
binding
together
with
the
credential
set,
and
so
that
meant
that
anytime,
you
removed
a
binding.
You
list,
you
also
removed
a
credential
set
and
when
you
REBOUND
it,
you
REBOUND
with
a
different
credentials
which
leads
to
all
kinds
of
like
Akal,
thrashing
or
or
bucket
policy,
thrashing
potentially
on
the
user
side,
where
you
have
to
go
Reaper
mission
or
reapply
a
bucket
policy
on
the
buckets.
C
Yeah
I
agree:
I
think
this
is
a
good
point
in
detaching
that
credential
occasion
from
the
intention
to
use
a
bucket.
So
they
might,
they
might
go
together
in
many
cases,
but
they
might
not
as
well,
but
we
just
think
we
want
to
have
some
flag
that
automates
creation
of
there
were
that
the
credential
request,
as
well
just
by
reading
a
example
so
that
it's
one
less
EML
to
create
I,
think.
D
That
that
that
comment,
the
about
the
credential
thrashing
I,
mean
yeah,
generate
our
credentials
with
embrace
brought
a
very
important
point.
That
is
a
little
bit
going
into
security
if
all
the
applications
are
showing
the
same
set
of
credentials
and
each
application
might
be
vulnerable
at
different
levels.
Right
that
means
I,
don't
know
these
conditions
that
are
going
to
be
seeded
are
going
to
have
to
have
a
wider
scope
of
access
or,
if
we're
still
gonna,
be
relying
on
users
creating
like
specific
application
credentials
right.
B
Yeah,
if
I
can
I'm
gonna,
try
to
repeat
back
what
I
thought
I
heard
you
say
and
see
if
you
think
I
caught
the
gist.
The
the
problem
with
sort
of
what
I
heard
is
the
earlier
suggestion
is,
rather
than
thinking
about
access
to
a
bucket
as
something
that
you
meant
every
time
you
think
of
access
to
a
bucket
ie.
B
The
credentials
for
accessing
the
bucket
is
having
its
own
identity,
and
then
there
is
a
binding
process
that
gives
a
particular
pod
the
the
access
to
that,
and
that
implies
a
desire
to
be
able
to
reuse
a
set
of
credentials
for
accessing
the
bucket
yeah.
That
flies
in
the
face
of
generally
good
security
approach,
where
you
really
do
want,
uniquely
minted
access
for
every
pod,
that's
going
to
access
something
so
that
you
can
revoke
credentials
and
only
impact
the
scope
of
the
particular
thing
that
you're
trying
to
revoke.
Let.
D
Well,
you
know
that
he
may
have
total
applications.
I
would
think,
but
I
mean
if
we
were
to
use
that
location
and
what
I
say
application
it
could
be
the
port,
the
deployment
the
stateful
said:
that's
using
this
as
the
identity
of
the
thing
requesting
access,
and
then
we
type
that
access
to
that
application
identity.
C
Service
accounts
omission
me
unpleasantly
something
coherent,
I
guess
in
the
design,
but
we
we
did
look
for
some
natural
empty.
That
represents
I,
want
to
be
sort
of
a
an
account
or
represent
an
identity
within
kubernetes
was
the
only
one
we
we
annotate
for
maybe
requesting
credentials.
Something
like
that.
B
C
B
C
C
The
bucket
may
still
need
to
be
mounted
like
a
volume,
but
giving
cozy
credentials
to
a
part
is,
like
you
know,
sort
of
using
service
account
of
that
alright,
so
we
can
annotate
like
we
can
take
the
surface.
I
can
annotate
it
for
cozy
credentials
and
cozies
and
provide
credentials
without
for
the
pods
that
use
that.
D
Yeah
yeah
still
not
clear
to
me
if
we,
if
you
will
have
to
have
that
miss
trader,
then
having
somehow
attaching
these
credentials
to
a
service
account
like
if
we
were
to
look
at
stopping
the
program
from
service
accounts.
That
will
be
I
mean
then,
along
with
managing
service
accounts,
which
is
probably
like
already
like
a
common
thing
for
administrators.
They
will
have
to
additionally
attach
these
service
accounts
so
much
as
some
cozy
kind
of
like
a
notation
to
indicate
that
there
are
some
credentials
that
are
suited
for
quads
under
the
service
account
right
right.
D
To
some
extent
versus
cuz,
if
it's
a
rig
like
common
practice
to
do
service
accounts
to
scope,
the
access
and
application
casts
on
your
cluster
and
that's
like
a
really
good
security
practice.
Then
that's
also
the
place
where
our
initial
cool
buying
some
credentials
and
then
it
gets
at
me
sure
thinking
about
whatever
they
access
needs
for
these
credentials,
but
that
he
needs
to
ensure
that
those
crenshaw
staff
right.
So
if
he
says,
is
a
service
account
for
two
applications.
I
need
to
ensure
that
those
two
applications
have
which
have
four
pockets.
C
B
Yeah
I
guess
the
one
thing
that
that
I
have
to
see
the
model
fit.
So
this
is
this
makes
sense
for
providing
for
saying
this.
Particular
service
account
has
access
to
a
predefined
set
of
detailed
access
policy,
so
there's
another
entity
that
still
has
to
be
provisioned
and
created
there
and
we
can
and
then
we
can
separately
deal
with
okay
once
we
provision
this
other
entity,
how
does
a
pod
get
to
it
right
but
that
other
entity
I
think
still
needs
a
a
driver
for
provisioning.
F
B
Service
account
so
I
think
that's
I.
Think
that's
the
the
point
is
that
then,
if
you
have
those
entities
as
sort
of
first-class
things
that
are
independent
of
how
they
are
used,
then
you
have
a
separate
thing
that
binds
them
in
right
a
separate
thing
and
that
that's
what's
not
super
clear,
I
understand
the
desire
to
do
service
accounts,
but
I
think
you
still
need
something
of
controller
can
operate.
Yes
to
figure
out.
It
needs
to
provision
secrets
to
the
file
that
doesn't.
C
It's
just
a
natural,
it
may
be
just
a
natural
identity.
You
can
certainly
create
a
bucket
secret
account
or
a
bucket
user
for
that
matter,
but
it
is
the
question
that
I
think
was
originally
why
you
know
why
do
we
need
another
at
all
right,
so
the
service
can
doesn't
solve
that.
We
still
need
to
handle
it,
so
it
doesn't
really
change
the
fact
that
you
need
something
more
than
just
getting
your
attention
to
get
a
bucket
and
credentials
right
or.
G
Or
yeah
I
guess
the
question
is:
how
many
annotations
do
we
need
on
the
service
account
in
order
to
mint
credentials
right?
Because
if
it's,
if
it's
three,
then
then
it's
too
many,
and
so
you
we
should
have
a
CRT
for
it.
And
if
it's
too,
like
like
the
way
that
load,
balancers,
get
annotated
or
ingress
is
getting
annotated,
then
maybe
that's
enough.
C
C
G
D
Know
that
validation
could
be
on
at
the
pocket
class
itself
or
whatever
restricting
access
that
way,
you
don't
need
annotations
and
service
account.
There
was
an
interesting
point
where
we're
asking
about
how
many
fields
need
to
be
added,
because
you
know
the
protocols
may
have
different
requirements
right.
We
think
about
the
extra
protocol.
That's
yeah.
We
only
made
like
endpoint
bucket
name
access
and
secret,
but
they
were
technology.
D
I
So
can
I
try
to
summarize
where
we
think
we
are
right
now.
I
think
it
sounds
to
me,
like
the
proposal
currently
focuses
only
on
provisioning
and
accessing
the
bucket
independent
of
ackles
and
I
am
and
I
think
the
feedback
has
been
a
complete
design
cannot
exclude
those
things,
so
we
need
to
figure
out
how
to
incorporate
those
into
the
design
and
I
think
from
what
I've
seen
it
sounds
like
we
can
probably
add
in
additional
api's
at
the
Kazi
layer,
as
well
as
potentially
new
kubernetes
objects
to
assist
in
provisioning,
I
am
and
apples.
I
What
that
would
look
like
remains
to
be
determined,
and
the
key
question
will
be:
how
will
it
integrate
with
this
design
once
we
figure
that
out
and
there
seems
to
be
kind
of
another
question
around
well,
I
am
and
Ackles
for
any
given
storage
back-end
are
going
to
be
different
from
storage
system
to
storage
system.
Kubernetes
has
its
own
ecosystem.
I
Is
there
a
way
that
we
could
find
to
map
those
somehow,
and
that
seems
like
a
challenge.
People
are
talking
about
using
a
kubernetes
pod
service
account
and
potentially
finding
a
way
to
map
that
this
sounds
like
a
larger
discussion,
but
does
it
summarize
where
we
are?
It
points
us
at
a
kind
of
problem
that
we
need
to
solve
yeah.
H
I
May
be
that
as
we
figure
out
the
design
for
that,
there
may
be
changes
here,
but
I
think
this
is
nicely
obstructed
by
saying:
hey
all
I
want
is
a
secret
object?
How
that
secret
object
comes
to
be
I,
don't
care
now
it's
the
responsibility
of
a
secondary
system
to
create
that
secret
object
and
that's
the
contract
between
the
two
so.
I
It
sounds
like
what
you're
saying
is
if
we
scope
the
problem
down
to
just
provisioning
a
bucket.
That
means
that
most
of
what's
proposed
here
is
not
necessary,
because
a
lot
of
it
is
around
how
a
pond
is
going
to
access
a
bucket
and
how
akkad
is
going
to
access
a
bucket
is
way
too
intertwined
with
Ackles
and
I
am
to
kind
of
decouple
it
in
this
way.
Is
that
writing
well.
A
On
that
a
little
bit
and
the
reason
being
that
I
am
is
like
clearly
a
separate
system
from
bucket
management,
but
there
there's
two
sides
to
this
coin:
one
is
I,
am
roles,
I
am
permissions,
the
other
is
the
the
ackles
and
the
axles
exists
through
the
storage
system
and
would
be
handled
through
storage.
You
know
like
a
bucket
drivers
and
it's
like
in
the
case
of
s3,
for
instance,
a
bucket
policy
is
a
substructure
of
a
bucket.
A
B
Let
me
see
if
I,
if
I
can
see,
if
I
can
dig
it,
what
what
you're
suggesting
and
and
so
there
so
one
way
to
look
at
this
is
to
say
I
am
effectively
going
to
just
manifest
the
identity
that
I
have
in
the
cluster
into
an
identity
that
I
have
in
the
backend
system.
So
I'm
just
going
to
do
an
identity,
mapping
service
account,
X
or
quad
X
or
whatever
is
this
person
on
the
other
end.
B
C
B
B
C
A
A
A
B
D
D
D
D
So
we
can
I
mean
this
diagram,
saying
oh
no
they're
on
the
PR
for
enhancements,
but
you
can
move
them
on
that
repo
and
then
we
can
keep
the
distortion
there
and
and
say
well,
if
we're
going
off-topic
on
a
CLS
open,
an
issue
for
issues
and
stuff
it
over
there
and
how
we
discuss
green
field
versus
brown
field,
cetera
and
rather
issue
and
just
keep
a
conversation
going.
There
I
think.
D
That's
I,
don't
know
who
has
access
today
and
that
Koontz
seeks
already
has
like
a
bunch
of
products
and
I.
Think
ballistics
has
mostly
CSI
drivers
right,
mundane,
I
couldn't
esteem
so
because
this
is
an
enhancement.
A
nice
I
hope
these
to
be
transmitted
at
some
point.
This
becomes
official
and
then
we
just
keep
going
and
but
then,
where
we
we
keep
that
going
right.