►
Description
Meeting of Kubernetes Storage Special-Interest-Group (SIG) Object Bucket API Review - 27 August 2020
Meeting Notes/Agenda: -
Find out more about the Storage SIG here: https://github.com/kubernetes/community/tree/master/sig-storage
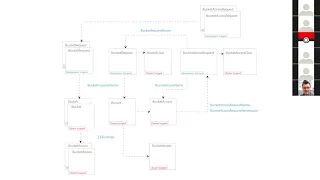
B
The
user
creates
a
bucket
request,
refers
points
it
to
a
bucket
class
and
cosy,
will
use
the
these
two
resources
to
create
a
bucket
and
when
requiring
access
to
the
same
bucket,
a
user
will
create
a
bucket
access
request.
Point
it
to
a
bucket
access
class
and
cosy
will
be
able
to
use
these
two
resources
to
grant
access
for
this
bucket
for
that
user.
B
B
There
were
a
few
problems
with
this
approach.
The
first
one
was
we
were
dealing
with
a
many
to
one
relationship
which
is
in
order
to
be
able
to
delete
all
the
bucket
requests
when
one
of
the
buckets
get
when
one
of
the
bucket
requests
gets
deleted.
We'll
have
to
create
a
many-to-one,
a
two-way
mapping
which
is
complicated
now,
so
in
order,
the
second
actually
there's
another
problem,
which
is
the
second
one.
B
The
second
one
is
portability
when
you,
when
the
user
creates
a
bucket
request,
if
cozy
automatically
creates
a
bucket
corresponding
to
that
request,
there
is
a
uuid
for
that
bucket.
That's
filled
back
into
the
bucket
request
field.
Now,
when
you're
trying
to
port
this
bucket
request
to
the
new
system.
B
B
Yeah
this
is,
this
is
the
same
approach,
but
with
multiple
bucket
access
requests
and
multiple
name
spaces.
Okay,
this
is
the
this
is
the
okay.
This
is
the
second
approach
where,
in
order
to
address
portability
issues,
we
thought
that
we
could
put
the
bucket
name
in
the
bucket
access
class
so
as
far
and
and
have
only
one
bucket
request
for
a
bucket.
B
B
Let's
say:
user
creates
a
bucket
request
to
create
a
bucket.
The
user
will
not
be
able
to
access
this
bucket
until
the
admin
goes
and
creates
a
bucket
access
class.
For
that
bucket.
The
other
issue
is
for
every
bucket,
we'll
need
a
bucket
access
class
and
for
every
bucket
and
for
every
access
pattern.
We'll
need
a
separate
bucket
access
class.
We
mentioned
that
we'd
be
polluting
the
bucket
access
classes
with
a
lot
of
entries.
B
B
If
a
bucket
request
that
point
that
point,
the
points
to
the
bucket
had
the
deletion
policy
of
delete,
we
actually
go
ahead
and
delete
the
back
in
bucket
and
all
the
other
bucket
requests
which
were
utilizing.
This
bucket
will
not
be
able
to
use
it.
So
if
there
are
workloads
using
it
in
other
name
spaces,
they
might
lose
access
to
the
bucket
in
the
middle
of
its
operations.
B
A
There's
not
a
portability
issue,
though
the
point
this
sort
of
bends,
you're,
saying,
multiple
brs
point
and
there's
multiple
b's
and
the
bucket
back
ends.
The
multiple
b
bucket
instances
and
kubernetes
could
all
end
up
pointing
to
the
same
bucket
in
the
back-end
store,
and
the
issue
is
importability.
The
portability
is
sold
because
you
have
bars
referring
to
the
vr
right,
so
you
don't
have
a
uuid
name
in
any
user
defined
spec.
Oh
right,
yeah
portability.
What
you
have
what
you're?
A
Allowing,
though,
is-
and
you
solve
portability-
by
making
no
user
reference
to
a
clustered
resource
that
has
to
have
a
unique
name.
So
since
there's
no
user
reference
to
a
cluster-wide
resource,
it's
portable
by
definition,
however,
it
means
you
can't
delete
use
cases.
You
just
yank
the
rug
out
from
underneath
apps
there's
no
mechanism
to
to
orchestrate
delete
so
that
if
a
pod
was
running
or
a
vr
was
still
active,
any
any
of
these
vrs
could
delete
and
you
could
put
annotations
or
you
could
put
ownership
or
you
track.
C
A
A
You
know
the
ip
path
whatever
of
the
volume
so
that
you
can
have
multiple
pvs
reference,
the
same
back,
end
volume,
but
it's
a
manual
task
by
the
admin
and
the
pvc
that's
going
to
bind
to
that
pv
is
pre-bound
by
a
user,
and
that
means
that
pvc
knows
the
pv
name,
but
the
admin
generated
the
name.
So
we're
going
to
call
that
portable
still,
it
wasn't
a
a
csi
generated,
pv
name
right.
So.
C
We
would
I
so
so
for
for
snapshots
and
for
pvs.
Currently,
you
need
an
admin
to
help.
You
do
that,
there's
no
way
for
user
to
just
import
a
brownfield
snapshot
or
pvc,
but
first
object
buckets.
We
would
like
that
capability.
So
the
question
is:
is
there
a
way
that
we
can
structure
the
bucket
request,
such
that
the
user
can
supply
the
actual
handle
to
the
actual
bucket
in
such
a
way
that
the
provisioner
will
sort
of
import?
It.
B
B
A
E
Yeah
yeah
and
it's
again
like
we
can
use
the
same
application
to
like
to
which,
when
during
deployment
it
goes
through
stages,
right,
staging
environment,
conducting
environment
testing,
environment
right,
we
will
need
to
change
the
name
every
time.
So
it
doesn't
seem
like
that.
That's
why
we
probably
will
lose
portability.
C
C
Oh
okay,
so
so
there
needs
to
be
so
in
order
to
so
so,
if
you
know
the,
if
you
know
the
actual
bucket
name
on
the
on
the
the
the
the
back
end,
you
can
you
can
do
an
import,
but
the
problem
is:
is
that
if
you
just
create
it
through
kubernetes,
you
never
find
out
what
that
is
yeah,
you
can't
do
it.
So.
Can
we
solve
that
problem
so
that,
when
you
create
a
bucket
part
of
its
status,
information
is
its
actual
name
or
is
that
a
security
problem.
B
F
C
B
C
Right,
well,
I
guess
what
I'm
thinking
then
is
so
so
I
create
a
bucket
on
one
kubernetes
cluster
and
now
I
want
to
go
use
it
on
another
kubernetes
cluster,
and
so
I'm
going
to
basically
get
the
name
from
the
first
one
and
then
do
an
import
on
the
second
one.
How
am
I
going
to
get
access
on
the
second
one
like
who's,
going
to
where's
the
power
to
to
sort
of
grant
a
new
access?
B
So
I'm
talking
about
it,
yes
ben
so,
let's
say
I'm
using
min
io.
May
you
set
up
the
object
storage
system
within
kubernetes
itself.
Now,
let's
say
I
move
my
entire
cluster
from
my
on-prem
to
a
different
on-prem
location.
I
set
up
a
whole
new
manio
cluster.
Now
I
won't
be
able
to
reuse
the
resources
that
I
was
using
earlier,
because
the
generated
pocket
name
in
the
first
setup
will
not
be
the
same
as
the
generated
bucket
name
in
the
second
setup.
A
E
C
So
so,
if
part
of
your
workflow
is
to
like
create
brand
new
buckets,
then
then,
as
far
as
I'm
concerned,
like
portability
implies
that
you're,
okay
with
creating
brand
new
buckets
after
you
move
the
new
cluster.
Because
that's
what
would
happen
with
pvcs
right?
Pvc
data
doesn't
magically
move
around
it.
If
you
request
new
pvcs
you're
going
to
get
empty
ones,.
G
C
If
you
want
to
bring
your
data
over
to
another
place
like
it's,
not
just
copying
your
yaml,
it's
actually
saying
okay,
I
need
to
actually
import
the
data
that
existed
in
this
other
place
onto
the
new
cluster
and
then
refer
to
it
with
my
with
my
app
and
the
rest
of
it
should
be
portable,
but
the
data
doesn't
just
magically
move
around.
You
have
to
import
it.
C
E
Guys,
could
you
remind
me
we
used
like
in
the
very
beginning
of
this,
like
cap,
we
used
to
have
different
bucket
class
format
for
brown
and
green
field,
whereas
for
brown
field
bucket
class
class
will
explicitly
say
to
which
bucket
this
bucket
class
belongs.
Is
it
the
case
right
now,
or
we
kind
of
moved
away
from
that.
E
Right,
I
remember
this
specific
idea
was
actually
something
it
wasn't
even
andrews.
It
kind
of
it
was
before
kind
of
I
think,
maybe
even
before
this
cap
and
andrew
maybe
even
know
knew
about
this
problem.
I
think
it
came
from
somewhere
else,
but
I
thought
we
all
of
it,
but
we
don't
follow
yes,
okay,.
G
B
B
C
A
difference
between
portability
in
terms
of
I
can
take
an
app
that
ran
in
one
cluster
and
run
in
another
cluster
where
they,
you
know,
I'm
okay,
with
starting
over
from
from
nothing
and
then
there's
I
want
to
migrate.
I
want
to
actually
share
data
across
multiple
clusters
and
that's
not
what
I
think
we
typically
call
portability.
That's
right!
Actual
data
sharing
so.
B
In
in
the
in
the
option,
one
that
you
mentioned
when
you
say
you
want
to
be
able
to
take
the
ammo
that
you
use
in
cluster
one
and
be
able
to
use
that
in
cluster
two,
should
the
user
be
expected
to
update
whatever
reference
they
have
to
a
bucket
depending
on
where
they
are,
or
should
it
just
work?
No
matter
what.
C
C
C
G
C
Right
so
so,
if
if,
if
the,
if
the
bucket
pre-existed
both
clusters,
then
both
of
them
would
just
basically
import
the
same
bucket
and
start
using
it,
but
if
one
of
the
clusters
created
a
bucket
and
now
the
other
cluster,
and
then
you
want
to
move
your
application
over
to
another
cluster
like
it
would
be
reasonable
to
assume.
It
would
also
create
a
bucket.
That's.
C
C
E
E
Well,
basically,
I
can,
if
bucket
class
itself
will
have
some
information,
for
example,
distinguish
between
green
and
brown
field.
So
in
one
case
for
new
bucket,
I
will
use
bucket
class,
which
will
say:
okay.
If
it's
a
green
field,
you
create
a
new
bucket
and
for
brownfield
case
in
the
new
cluster
bucket
class,
we'll
say:
okay,
I
want
to
reuse
this
specific
bucket
and
my
application
yemo
will
be
absolutely
the
same.
It
will
just
pick
up
a
new
bucket
class
which
will
instruct
provisioner
to
reuse
existing
bucket
instead
of
creating
a
new
one
but
yeah.
C
If
we
look
at
it
that
way,
no,
I
this
is
a
good
example
of
a
of
a
way
that
you
could
work
around
it.
But
but
the
problem
is,
is
that
a
storage
class
could
only
ever
refer
to
one
bucket
right.
I
don't
see
how
you
can
make
a
storage
class.
That
says
this
is
the
brownfield
storage
class
and
it
it
can
deal
with
multiple
buckets
somehow
so
so
you
don't
want
to
end
up
in
a
situation
where
you
need
a
brownfield
storage
class
for
every
bucket.
B
E
B
Yeah
but
then,
if
it's
provisioned-
and
you
know
you
take
the
you-
you
set
the
pv
name
to
say
some
pvc
dash
uuid,
which
is
how
it
looks
if
it's
provisioned
and
then
and
then
you
just
take
the
same
pvc
definition
to
another
cluster.
It
won't
work
for
you
because
here,
when
you
provision
it,
the
uad
will.
A
Be
different
when
we
look
at
portability
and
the
idea
of
brownfield
or
sharing
csi
is
not
portable.
If
I
have
to
do
static
provisioning,
if
I
have
to,
if
we
do
green
csi
and
now
I
have
a
pv
pointing
to
an
nfs
nfs
system
right,
the
nfs
volume,
okay-
and
now
I
want
to
share
that.
I
have
another
pv
that
has
to
get
manually
generated
to
refer
to
the
same
nfs
volume.
A
B
A
C
E
B
I'm
still
don't
quite
understand
why
that
is
a
problem,
so
if
you
dynamically
generate
it
and
the
the
pvc
name,
if
you,
if
you
have
a
pvc,
that's
that
dynamically
generates
the
pv
and
then
you
try
to
just
take
that
pvc
object
and
then
try
to
put
it
in
a
different
yeah.
I
guess
a
cluster.
If
it's
sorry
we
put
in
a
different
cluster.
H
C
C
E
B
E
B
E
Possibilities,
it's
absolutely
one
of
the
possibilities
but
another
possibility
and
which
I
think
even
precludes.
What
you
proposed
is
that
if
there
is
any
pv
with
the
name
with
which
refers
to
p
to
my
pvc
new
pvc,
that
will
match
automatically
even
without
any
further
kind
of
checking
or
maybe
they
will
be
checking
and
if
it
doesn't
match.
Maybe
there
will
be
an
error
in
that
case,
but
basically
they
first
they
try
to
map
by.
If
pv
name
refers
to
pvc
name,
namespace
yeah.
B
B
E
B
The
information
is
not
portable,
that's
exactly
what's
happening
here.
So
instead
of
the
matching
doing
the
referring
we,
the
user
is
expected
to
do
the
referring.
That's
the
one
difference,
and-
and
in
this
case
exactly
like
that,
if
it
already
starts
differing,
then
it's
not
portable
and
I
think
that's.
Okay.
It's
not.
E
A
B
I
have
a
question
here
actually
so
so
how
do
we?
Let's
say
I
create
a
bucket
request
in
one
name
space,
it
ends
up
creating
a
bucket.
Now,
how
do
I
use
that
bucket
from
a
different
name
place?
How
would
that
cloning,
or
whatever
we
want
to
call
it?
How
do
we
import
that
bucket
to
a
different
namespace?
Let's
use
the
word
import,
it
seems
more
intuitive,
at
least
to
me.
C
C
E
So
yeah
just
a
wild
idea
how
it
may
work
you
just
copy
the
source
bucket,
as
is
mostly
but
in
bucket
request
reference
in
the
bucket.
You
change
it
to
a
bucket
request,
like
2b
bucket
request,
a
new
namespace,
a
new
name
of
the
bucket
request.
So
and
then
you
go
ahead
and
read
bucket
request
there
and
again
like
spv
pvc,
it
will
automatically
just
bind.
E
E
E
C
B
B
C
So
the
bucket
is
not
namespace.
You
just
have
a
second
copy
of
it
with
the
different
name
right
that
refers
to
the
same
actual
bucket
and
then
yeah.
So,
but
if
the
admin
creates
that
sure
you
could
sort
of
create
a
pre-bound
bucket
request
that
refers
to
it
and
then
the
buy
and
then
the
provisioner
will
say:
oh,
it's
a
half
bound,
I'm
going
to
complete
the
bind
and,
and
then
it'll
be
done,
but
but
that
requires
the
admins
who
have
basically
cloned
the
bucket
object
in
at
the
cluster
scope.
Well,
what?
If
that?
What.
E
C
Alternative
in
my
imagination,
was
you
have
a
special
field
on
your
bucket
request,
spec,
which
is
optional.
It
says
this
is
a
brownfield.
I
want
to
import
it
and
then,
when
the
provisioner
sees
that
it
says,
oh,
I
should
not
fulfill
this
request
by
creating
a
new
bucket.
I
should
fulfill
this
request
by
cloning,
an
existing
object
and
then
binding
to
that.
C
B
I
C
C
H
G
C
B
B
B
B
I
B
That's
yeah
you're
right
yeah,
so
so,
but
you
know
we
leave
that
up
to
the
driver,
but
but
you
know
generally
a
bucket
accident.
You
know
it
really
represents
one
type
of
access
and
a
separate
service
account
where
not
the
kubernetes
service,
not
separate,
say
cloud
service
account,
that's
actually
accessing
the
bucket
and
and
each
one
you
know
wants
to
access
it
in
its
own
way.
Some
might
just
want
to
write
some
might
want
to
read
and
write
whatever.
I
J
B
If
I
have,
in
this
case
the
the
credential
is
given
per
user,
that
is,
the
access
pattern
is
independent
of
the
buckets
access
mode
so
in
in
pv
and
pvc.
If
you
create
a
read-only
volume,
nobody
can
write
from
right
into
it
in
in
a
buckets
case,
a
bucket
is
just
the
bucket
and
each
user
gets
a
completely
different
type
of
access.
B
G
I
I
And-
and
my
only
question
is,
if
we
are
using
bucket
request
to
represent
even
you
know,
referring
to
an
existing
bucket
referral
to
existing
bucket.
Just
my
question
is:
what
is
the
difference
between
these
two
objects?
Are
they
saying
anything
new
from
the
application
side
about
because
it
seems
like
we
are
asking
for
access
to
bucket
and
an
optional
creation.
I
C
Or
the
other
one,
I
think
I
think
it
is.
I
mean
I
think
andrew
does
a
good
job
of
explaining
why
it's
needed,
I'm
not
good
at
channeling
him.
I
I
will
say
the
difference
with
pvcs
is
that,
with
with
pvcs,
the
hypervisor,
the
node
has
the
ability
to
like
remount
a
volume
read
only
so
if
it
mounts,
if
it's,
if
the
volume
is
exported
to
the
node
writable,
the
volume
you
can
make,
it
read
only
for
just
one
pod
by
remounting
your.
C
C
G
I
C
I
B
C
I
I
think,
maybe
the
other
half
of
it
is
there's
a
life
cycle.
So
if
you
create
a
pod
and
you
attach
it
to
a
bucket,
it's
going
to
need
a
credential,
something
has
to
create
that
credential.
You
could
try
to
do
it
just
in
time.
Maybe,
but
then
the
question
is:
when
is
it
safe
to
delete
it?
I
think
having
the
bucket
access
request
be
a
formal
object
that
gets
deleted
at
some
point
means
you
know
when
it's
safe
to
delete
that
credential.
C
I
B
I
A
B
I
B
I
I
I
just
think
that
the
the
I
mean
the
the
thing
I
don't
have
a
good
junior
time
and
I
have
to
say
first
of
all,
but
I'm
the
problem
that
I
see
whenever
we
are
referring
directly
between
a
bucket
access
request
to
the
bucket,
which
is
what
we
suggested
originally
right
on
that
then
we,
the
bucket
request,
becomes
just
a
creation
facility
right
and
when
we
move
that
back
to
be
the
bucket
request
is
just
an
import
facility.
Right
then,
when
that
is
the
case,
I'm
just
questioning
why?
C
B
I
B
B
It's
still
creation
of
the
bucket
object,
so
I
I
see
where
you're
coming
from.
Actually
I
I
I
know
what
you
mean,
it
is
right
now,
a
bucket
request
for
brownfield
is
really
not
doing
anything
other
than
doing
some
internal
kubernetes
management.
As
far
as
the
user
is
concerned,
why
should
they
do
a
bucket
request
for
a
bucket?
That
already
exists?
That's
a
fair
question,
but,
given
all
the
constraints
we're
dealing
with
this
is
the
model
we're
going
with,
and
I
think
you
know
going
forward.
B
E
Yeah
but,
as
I
mentioned
before,
like
user
may
not
even
know
ahead
of
time
if
they
want
a
new
bucket
or
they
want
an
existing
one,
their
application
should
be
portable
and
maybe
maybe
I'm
making
this
up.
But
it's
just
something
that
comes
to
me.
When
I
have
my
application,
I
really
need
just
storage
to
talk
to
in
some
cases
right,
I
don't
care
if
it's
a
new
one
or
it's
an
existing
one,
and
I
want
to
use
the
same
gmo
kind
of
for
my
application.
B
A
E
Just
imagine,
for
example,
again
like
if
you're
talking
about
application,
which
goes
through
stages
in
test
and
environment,
it's
okay
to
create
a
new
bucket
and
test
against
new
buck
every
time
right.
But
in
my
product
environment
I
can
probably
probably
there
is
an
assumption
that
there
is
already
some
existing
bucket
list,
which
I
should
reuse
yeah.
B
So,
in
that
case,
we
we're
saying
the
bucket
real,
quick,
like
ben,
was
saying:
there's
a
there's,
a
switch
there's
a
there's,
a
field
like
a
brownfield
refill
or
we
could
rather
than
putting
it
that
way.
Let's
have
a
bucket
name
field
if
it's
filled
in
it's
brown
field.
If
it's
not
it's
green
field
and
in
say
test
and
staging
it's
not
filled
in
and
production,
we
fill
it
into
exactly
what
you
want
yeah,
but.
E
E
B
E
B
What
people
do
is
like
in
the
pod,
spec
they'll
have
different
service
account
different
config
maps,
pointing
to
say
environment
variables,
all
that
is
changed
between
prod
and
staging.
That's
how
if
you
see
customize
or
if
you
see
helm
both
of
in
both
cases
in
terms
of
environments,
the
data
and
the
in
the
ammo
changes?
Well,
that's
not
in
the
year
mode
right.
C
Well,
it
does
it
does
so,
but
what
I
hear
is
that
you
want
to
be
able
to
write
an
application
such
that,
whether
it's
a
greenfield
or
a
brownfield
deployment
becomes
a
deployment
time
decision
and
you
don't
have
to
change
the
animal
to
achieve
that
right.
That's
correct,
yes,
and-
and
that
does
make
sense
to
me-
and
so
I
think
we
should.
C
We
should
make
sure
that,
like
the
the
bucket
request
can
be,
can
be
written
in
such
a
way
that
that
it
can
be
a
deployment
time
decision
like
I,
I
think
we
don't.
We
don't
currently
achieve
that
with
csi
snapshots.
I
think
with
csi
snapshots
it
always.
You
can't
request
an
empty
snapshot.
The
snapshot
always
tests.
Oh.
E
Yeah,
I
think
snapshot
is
not
portable.
I
think
snapchat
is
the
yeah,
it's
a
beast
which
is
not
really
portable.
I
I
agree
with
you
totally
but,
for
example,
pvc
right,
I
I
have
the
same
pvc
definition
and
I
don't
care.
What's
the
underlying
storage
right,
it
might
be
in
google
cloud,
it
might
be
pd
and
amazon.
It
will
be
some
ebs
right
or
whatever,
and
so
you
don't
care.
You
have
one
pvc
definition
and
it's
just
it's
portable
through
cloud
providers
or
even
on-prem,.
B
C
B
B
G
A
C
A
lot
depends
on
the
storage
class.
If
the
storage
class
points
to
a
csi
driver,
then
the
external
provisioner
sidecar
gets
to
do
whatever
it
wants
right,
and
so
so
and-
and
I
I
don't
think
with
with
csi
in
particular-
it's
possible
to
do
the
kinds
of
things
you're
talking
about
with
matching,
but
but
we
should.
We
should
find
out
what
the
closest
analog
in
the
pvc
pv
world
is
and
try
to
model
it
after
that,
because
that
seems
like
a
reasonable
thing
to.
B
C
B
B
C
B
A
A
B
E
A
C
A
C
I
J
B
C
B
C
B
E
I
B
Yeah,
okay,
so
yeah.
I
think
I
think
the
open
question
is
to
automate
or
do
we
leave
it
as
it
is.
I
think
one
way
to
discover
it
actually
put
it
out
there
and
see
how
if
people
are
screwing
up
screwing
this
up
a
lot
or
it
works
fine
or
is
it?
Is
there
questions
really
coming
up
about
this?
That
way,
we'll
actually
be
able
to
find
out?
If,
if
we
need
automation
there
or
not,.