►
Description
Kubernetes Storage Special-Interest-Group (SIG) Object Bucket Review Meeting - 29 October 2020
Meeting Notes/Agenda: -
Find out more about the Storage SIG here: https://github.com/kubernetes/community/tree/master/sig-storage
A
B
Okay,
so
good
morning,
everyone
I
want
to
start
by
talking
about
our
next
milestone,
that
we've
decided
on
and
where
we
are
in
terms
of
the
milestones
progress,
and
there
was
one
issue
that
we
were
discussing
last
week
and
we
wanted
to
go
back.
Do
some
research
come
back
with
more
data
to
continue
the
discussion?
I
want
to
continue
the
discussion
now
that
we've
done
the
research.
B
B
So
one
of
the
one
of
the
properties
I
wanted
for
this
demo
was
that
the
the
quality
of
code
and
the
quality
of
demo
would
would
be
as
close
to
you
know,
production
quality
as
possible.
At
this
stage.
What
I
mean
by
that
is,
we
want
to
follow
the
best
coding
practices
and
have
unit
tests
integration
tests
in
place
before
we
show
the
demo
so
that
when
we
do
show
the
demo,
we
know
that
this
feature
is
actually
in
place
and
people
can
start
trying
it
out
music.
B
So
for
those
who
are
looking
to
go
through
the
code
or
would
like
to
subscribe
to
updates
in
terms
of
the
coding
progress,
these
are
the
repo
names
they
all
fall
under
the
kubernetes
dash
six
github
organization,
all
right.
Moving
on
to
the
next
step,
so
the
issue
we
were
discussing
last
week
was
about
credential
minting.
B
D
D
B
Yeah
that
too
yeah
I
was
going
to
bring
that
up
in
the
context
of
multiple
buckets
and
bucket
discovery.
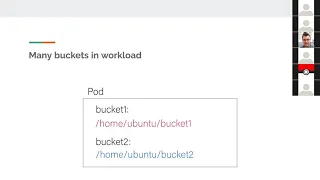
But
yes,
so
even
if
you
have
this
credential
file,
there
needs
to
be
a
mechanism
to
let
the
workload
know
the
name
of
the
bucket,
because
when
the
workload
starts,
there
is
no
guarantee
that
the
bucket
already
exists
and
if
the
bucket
doesn't
already
exist
and
cosy
is
creating
it.
The
name
of
the
bucket
is
not
known
upfront.
It
can't
possibly
be
specified
in
the
parts.
D
D
D
B
D
B
D
B
B
So
in
this
case
there
is
no
conflict
of
paths
and
each
bucket
the
client
for
each
of
the
each
of
the
providers
would
look
for
their
their
individual
configurations
or
credential
information
in
their
default
paths.
We
expect
it
to
just
work
now
going
to.
The
next
scenario
is:
if
we
have
two
different
buckets
for
the
same
provider.
B
B
B
E
E
It's
just
partial,
and
even
we
even
chose
to
follow
a
model
where
every
bucket
access
request
has
its
own
credentials,
where
which
means
that
it's
not,
that
we
assign
a
single
identity
per
pod
and
then
use
that
somehow.
But
you
know
we,
we
kind
of
delegate
to
the
pod,
multiple
identities
per
every
connection.
It
needs
to
make
so
and
aws
credentials.
That
has
a
model
for
that.
It's
called
profiles,
but
I'm
not
really
sure
most
applications
use
it.
This
way
today,
so.
B
B
E
B
E
B
C
B
B
E
E
B
B
B
So
there
are
use
cases
where
I
still
realize
in
client
search.
So
there's
something
called
aws
snowball,
so
aws
snowball
is
something
I've
used.
So
what
they
do
is
if
you
want
to
transfer
a
lot
of
data
from
s3
to
outside
of
s3,
say
a
single
petabyte
one
petabyte,
then
you
know
you
couldn't
do
it
over
the
internet.
You
can
get
a
maximum
of
a
gigabit
link
to
s3
and
it
takes
a
really
long
time
to
transfer
a
petabyte
of
data.
B
B
B
You
know
ec2
instances
and
and
creating
s3
buckets,
and
you
can
connect
your
own
100
gigabit
link
physical
link
from
from
that
box
to
your
data
center
and
transfer
the
data
out
and
this
box
gets
shipped
within
the
week
and
you
can
you
can
ship
it
back
to
them.
They
send
it
to
the
label
and
everything
so.
B
D
B
D
B
D
Well,
my
only
assertion
was
if
a
client
search
is
necessary
to
to
authenticate
to
the
server,
then
it
it's
implicitly
part
of
your
credentials,
and
it
sounds
like
in
the
case
of
this
snowball
thing,
there's
a
modified
version
of
s3
that
involves
a
client
cert,
and
so
we
should
conceptualize
that,
as
like
a
separate
protocol
where
the
client's
cert
is
part
of
the
credential,
it
feels
like
that
to
me.
I
again,
I
don't
know
the
details
and
I
don't
know
how
how
common
that
is,
or
how
many
other
changes
they've
made.
I.
D
F
C
B
D
D
E
E
F
C
A
A
D
D
The
ca
cert
needs
to
be
passed
down
so
that
the
client
knows
that
they
can
trust
it,
but
the
I'm-
and
I
think
almost
any
client
in
the
world
would
know
how
to
deal
with
that.
But
but
this
this,
like
you,
have
to
install
you
have
to
use
a
specific
client
cert.
I
would
imagine
most
sdks
and
stuff,
don't
know
how
to
just
take
in
a
client
search
and
use
it
for
all
of
their
http
operations.
B
D
D
E
B
B
D
A
D
E
E
B
E
E
I
mean,
but
I
think
it's
it's
all
possible
configurations
for
the
client
sdk
that
the
provider
can
provide
and
that,
of
course,
the
application
can
override.
But
it's
a
configuration
based
configuration
and
there's
something
else.
So
you're
saying
that
the
rest
will
be
in
a
bucket
json.
Is
that
so
the
information
that
every
application
needs
to
read
about
the
bucket
name
and
endpoint
will
be
in
that
bucket
json.
B
C
C
D
D
B
C
It
sounds
like
there's
definitely
existing
api
that
you're
trying
to
fit
into,
but
there's
potentially
going
to
be
kind
of
some
customizations
for
cozy
or
like
additional
pieces
of
information
right
and
so
for
that
reason,
what
are
those
differences
and
that
kind
of
stuff
definitely
needs
to
be
captured.
So
if
I'm
a
workload-
and
I
say
I
select
s3
or
I
select
gcs
through
cozy-
what
what
is
my
expectation?
What
is
the
contract
that
I
should
depend
on
right?
I
think
that's
what.
B
B
D
But
to
address
the
concern
about
existing
applications
and
fitting
into
an
ecosystem
that
already
exists
like
that's,
why
we
should
do
things
like
call
the
credentials
file
credentials
if
it's
s3
and
format
it
like
an
s3
credentials.
File
is
formatted
today,
so
so
so
that
minimal
change
of
existing
applications
is
needed,
but,
like
you're
not
going
to
get
around
having
to
read
a
bucket.json,
nobody
reads
that
today
because
it
doesn't
exist.
It's
like
that's
just
going
to
be
a
thing
that
you'd
have
to
start
doing
in
your.
I.
B
Mean
I
mean
so,
we
did
make
an
assumption
last
time
when
we
spoke
about
it.
So
if
there
is
a
workload
that
that
we
want
to
port
over
to
cozy
that
we
expect
that
there
is
no
developer
to
change
the
application
itself,
we're
saying
that
is
possible
in
case
of
brownfield
buckets,
because
we
know
the
name
of
the
buckets
up
front.
B
B
So
so
it's
still
possible
for
the
brownfield
use
case.
The
static
brownfield
use
case,
and
what
do
you
all
think
is
that
I
mean
that's:
that's
the
one
one
sort
of
turnkey
porting
that
we
that
we
support
where
without
changing
the
application,
you
can
simply
switch
to
cosy
if
it's
brownfields,
statically
provisioned
bucket
yeah.
That.
D
B
C
C
B
E
E
B
E
E
B
D
G
D
B
E
I
think
the
structure
we
defined
for
for
it
was
that
we
we
we
have
like
an
archetype
like
this
is
the
protocol,
and
then
we
have
a
flat.
You
know
keys
for,
for
how
the
protocol
would
parse
the
the
parameters
right.
We
didn't
stack
everything
we
didn't
move
everything
down
below
the
protocol
because
we
said
okay,
this
is
like
a
type
and
then
we,
the
protocol
itself,
knows
how
to
use
the
information
there
right.
E
E
D
E
D
E
B
D
B
D
D
D
B
So
so
when
you
say
a
union
struct,
so
we
already
have
a
structure.
We
already
have
a
definition
for
for
the
individual
protocols.
Why
don't
we
just
mirror
that
here
and
we
can
have
a
conflict,
a
type
like
a
kubernetes
bucket
config
or
some
type
like
that?
That's
that's
common
for
all
the
different
protocols.
So
so,
as
far
as
the
type
definition
is
concerned,
this
protocol
field
would
be
just
the
same
as
what's
defined
in
the
other
bucket
apis.
D
E
D
E
B
D
E
B
F
E
E
B
E
B
D
B
E
E
D
Can
validate
and
say
it
must
be.
One
of
you
know
these
known
values
for
it
that
are
s3
specific
and
then,
if
it's
not
one
of
those
three
one
of
those
supported
values,
you
can
check
it
out
if
you
leave
it
at
the
higher
layer.
Validation
gets
a
lot
trickier
so
because
s3
versions
might
be
like
s3
v2
and
s3
v4
and
s3,
v9
or
whatever,
but
like
gcs,
might
have
a
totally
different
versioning
scheme
with
a
different
algorithm
so
like
it
just
feels
that
it's
it's
it's.
B
Clear
so
yeah
version
is
kind
of
a
confusing
field,
actually
because
how
we
were
thinking
of
it
and
and
a
few
other
civils,
and
you
know
we
also
had
this
same
question
here.
Sometimes
we
don't,
they
use
like
the
version
field,
if
it
is
not
specified
by
the
user.
Cosy
would
fill
it
for
you,
because
the
provisioner,
we
assume
you
know,
chooses
one
of
the
protocols
as
the
versions
as
a
default
like
s3v4
and
then
and
then
fills
it.
E
E
B
E
B
E
E
E
E
B
Okay,
locking
up
your
versions
if
you're
using
numbers
to
keep
track
of
api
compatibility.
Okay
again,
this
is
not
for
s3.
Yes,
of
course,
it
is
so
current
api
version.
First
three
is
that
we
recommend
locking
the
api
version
for
a
service.
You
rely
on
for
production
code.
This
can
isolate
the
applications.
Okay
to
lock
the
api.
E
D
D
D
D
B
B
E
B
F
F
E
E
So
as
flick
probably
can,
and
so
in
one
way
or
another,
you
can
separate
between
aws
and
s3,
but
you
know
it
might
maybe
might
feel
artificial
to
some.
But
for
me
it
makes
more
sense
to
separate
between
the
ones
that
are
services
like
gs,
aws
and
azure
blob
versus
the
ones
who
will
have
to
have
an
end
point,
and
you
know
things
which
otherwise
they
don't
work
and
in
this
case,
s3
at
the
endpoint
under
s3,
with
aws,
doesn't
have
to
provide
an
endpoint.
Actually
just
only
has
to
provide
a
region
so
yeah.
B
E
Yeah
and
that's
what
I'm
saying
so,
s3
compatibles
will
have
to
have
an
endpoint,
but
will
not
have
to
have
a
region
and
aws
will
have
to
have
a
region,
but
does
not,
but
it
has
an
optional
endpoint
right.
So
it's
I
think
it's.
It
might
make
sense
in
some
ways
to
separate
between
what
is
aws
service
that
you'd
like
to
have
here
like
google
and
s3,
but
I'm
not
sure
if
you
kind
of
feel
the
same.
B
I
think
region
is,
you
know
all
the
implementations
of
s3
support
region
and
they
also
like
all
the
sdks
of
s3
support.
Giving
an
empty
region
assumes
default
region
endpoint
again,
even
with
s3
sdk
endpoint
is
optional,
because
if
you're
using
garb
cloud,
for
instance,
you
have
to
provide
the
endpoint.
E
D
E
D
D
B
E
E
A
E
But
we
are
a
marketplace
between
providers
and
applications.
Here
I
mean
if
we
define
that
this
is
a
good
structure
for
the
provider
to
provide
the
information
through.
Isn't
it
I
mean,
should
we
recompile
it
differently?
Now
I
mean
I'm
just
trying
to
find
what
what
are
we
trying
to
do
by
creating
another
api
which
replicates
the
entire
structure,
then.
B
C
B
Absolutely
yes,
so
so
the
workload
the
contract
between
the
workload
and
cosy
itself
is
not
directly
tied
to
the
bucket.
It
is
in
a
sense,
it's
indirectly
tied,
but
not
directly.
What
I
mean
by
that
is,
there
should
be
a
version
here
which,
which
should
which
should
exist
as
a
contract
between
the
workload
and
cosy.
Just
just
that.
A
B
Right
so
so,
take
the
take
this
example
of
porting
between
two
club
providers,
I'm
moving
from
gcs
or
to
aws-
and
let's
say
let's
say
the
admin
creates
buckets
and
in
gcs,
first,
the
old
old
old
infrastructure,
and
they
use
this.
This
definition
of,
let's
say
both
support,
s3,
hypothetical
studio
and
and
let's
say
gcs.
E
E
C
C
But
if
we
have
yet
another
object,
what
would
the
difference
between
that
bucket
access
object
and
that
new
object
be,
and
if
the
new
object
evolves
or
the
bucket
access
evolves?
Is
there
ever
a
case
that
they
would
evolve
in
two
different
ways?
And
it
sounds
like
probably
not
because
the
purpose
of
the
bucket
access
object
is
to
be
this
intermediate
api.
E
It's
actually
spread
yeah,
but
I
I'm
saying
that,
but
I
think
it's
it's
a
little
bit
spread
out
and
I'm
not
sure
how
that
would
how
that's
convenient,
because
there's
multiple
things
here.
There's
the
protocol
comes
from
the
bucket
in
the
bucket
access
there's
a
reference
to
the
secret,
where
we
need
to
pull
in
the
credentials
right.
So
there's
either
way
that
this
api
will
not
be.
E
D
I
think
that
that
if
there
were
any
evolution
of
this
object
with
these
fields,
like
say,
for
example,
we
I
don't
know
wanted
to
change
the
spelling
of
one
of
the
words
for
some
reason
like
you'd
have
to
you
know,
in
order
for
clients
and
servers
to
clients
and
providers
to
both
be
compatible
like
something
would
have
to
do
translation
at
some
point
right
like
like.
If
let's
say
you,
you
misspelled
the
word
bucket,
so
we
gotta
add
a
new
field
with
the
correct
spelling
of
bucket
like
well
for
backwards
compatibility
reasons.
D
D
E
E
What
will
we
say?
Will
we
say
that
this
structure
comes?
I
mean
because
I
understand
where
you
came
from
city.
You
wanted
to
have
a
crd
with
a
spec
that
I
can
always
inspect
and
understand
what
I
expect
to
see
in
that
file
right
or
something
like
that.
Json,
that's
exactly
yeah,
but
now
like
when
I'm
saying
this
is
the
same.
Maybe
maybe
even
if
it's
the
same,
we
need
to
share
it
in
the
in
the
kind
of
go
types
yeah
system,
but
yeah,
but
eventually
still
create.
E
E
E
I'm
not
sure
if
it's
very
important,
but
how
do
you
you
can
just
put
it
in
documentation
and
generate
it
or
something,
but
then
we
probably
want
this
to
be
somehow
tied
to
to
these
structures
saying
this
protocol
comes
from
the
bucket
and
this
you
know
if
there's
something
else,
that
we
need
to
bring
like
the
bucket.
Well,
actually,
we
said
that
the
bucket
name
is
is
inside
already
for
the
protocol,
so
maybe
that's
the
entire
information.
We
need
just
the
protocol
information
from
the
bucket
and
the
credentials
like
another.