►
From YouTube: Kubernetes SIG Testing - 2021-07-27
Description
A
Look
up
and
check
the
date
on
each
of
these.
It's
not
like
I'm
highly
thinking.
I
just
realized
that
today
is
tuesday
july
27th.
You
were
at
the
kubernetes
sync
testing
bi-weekly
meeting.
I
am
your
host
aaron,
krickenberger
or
aaron
of
sig
beard
or
sniff
xp.
In
all
the
places
this
meeting
is
being
recorded
and
will
be
posted
to
youtube
later,
where
you
can
all
watch
yourselves
adhere
to
the
kubernetes
code
of
conduct.
B
A
As
you
know,
the
kubernetes
release
team
has
decided
to
move
from
four
releases
a
year
to
three
releases
a
year,
so
I'm
using
v123
I
mean
we
traditionally
try
to
pin
our
our
planning
to
the
next
release,
which
meant
that
it
was
basically
quarterly.
But
at
this
point
we're
talking
about
basically
what's
going
to
get
us
to
the
end
of
the
year.
A
So
I'm
viewing
this
with
the
context
that
we
shouldn't
do
anything
super
crazy
disruptive
this
week,
and
then
we
have
kind
of
two
to
three
weeks.
If
there's
any
kind
of
annoying
shuffling
around
of
stuff,
that
would
cause
pain
to
the
ongoing
operations
of
the
project,
these
would
be
the
weeks
to
push
on
that
stuff.
A
And
then
then
the
next
dates
on,
mindful
of
which
are
not
yet
pinned,
would
be
things
like
enhancement
sprees.
If
we
have
any
capsules
to
talk
about
or
code
freeze,
if
there's
any
code
changes
that
need
to
land
in
kubernetes,
specifically,
and
also
just
thinking
of
that
as
the
date
at
which
we
historically
have
experienced
the
most
capacity
pain
for
ci
testing
of
kubernetes.
A
A
We'll
muddle
through
some
all
right,
so
I
tried
to
link
the
main
board,
which
is
in
the
kubernetes
board.
I
will
share
my
screen
for
that,
but
I
am
primarily
going
to
be
looking
at
the
meeting
notes
as
I
try
to
stumble
through
and
find
the
issues
that
line
up
with
this,
because
we
have
a
lot
of
issues
on
our
board.
A
The
columns
are
basically
blocked
if,
for
whatever
reason,
we're
just
kind
of
like
waiting
or
there's
something
that's
preventing
us
from
moving
forward
in
progress.
If
I
know
that
somebody
is
working
on
it
backlog,
if
I
think
it
would
be
a
good
idea
for
us
if
we
need
to
pick
something
up
and
work
on
it,
this
would
be
the
place
to
pull
from
health.
A
Wanted
are
issues
that
we
regularly
go
through
and
make
sure
are
still
relevant
and
important
and
good
places
for
beginning
or
intermediate
contributors
to
help
out
and
then
to
triage
is
everything
else
that
we
haven't
really
looked
at
yet
there's
no
ordering
to
these
columns.
The
goal
would
be
to
try
and
consistently
apply
priority
labels.
So
you
can
see
some
of
these
have
priority
importance
soon.
A
So
I
was
thinking
we
might
start
to
consider,
adding
using
the
full
rainbow
here
and
using
labels
like
priority
backlog
or
priority
awaiting
more
evidence
or
having
forbid
priority
critical
urgent
for
the
stuff.
That's
that's
really
like
the
most
important
step.
First,
the
way
I
tend
to
navigate
this
board
is
by
milestone.
So
I'm
first
going
to
look
at
everything.
That's
in
the
122.
A
A
A
A
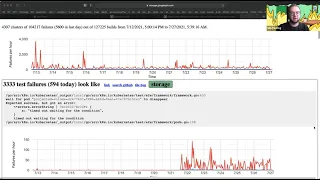
So
there
are,
you
know
it's
kind
of
difficult
to
tell
if
perhaps
a
gigabyte
of
data
is
an
unreasonable
amount
of
data
to
expect
a
browser
to
handle,
and
it
could
mean
that
we
need
to
like
drastically
reconsider
the
design
of
this
to
work
in
a
way
that
doesn't
involve
so
much
data
being
on
the
front
end.
It
could
also
be
that
we've
just
been
getting
a
whole
bunch
more
data
than
we
used
to
this
graph.
A
So
refresher
for
those
of
you
who
aren't
familiar,
we
store
all
all
of
our
test
results
in
a
big
query
database
using
a
tool
called
cattle,
and
then
we
have
something
that
periodically
pulls
the
last
two
weeks
of
results
out
of
that
database
and
then
attempts
to
cluster
it
together.
So
that's
the
triage
job
and
that's
what
we're
looking
at
here
and
I
know
it's
really
really
tiny,
maybe
I'll
blow
it
up
a
little
bit
more.
A
A
B
A
Long-Winded
way
of
saying,
I'm
not
sure
that
there's
an
easy
fix
to
make
triage
go
better.
We
could
all
right
after
having
said
that
out
loud,
that
we
could
cut
it
back
to
looking
at
one
week's
worth
of
results
instead
of
two
weeks
worth
of
results
just
to
see.
If
that
gives
us
some
breathing
room,
I
see
a
hand.
C
C
We
do
actually
have
separate
data
source-
that's
not
the
complete
data
source,
that's
like
in
slices,
if
you
view
like
a
cluster
that
still
works.
Fine,
because
that
loads
that
data,
so
we
we
could
try
to
like,
we
could
do
more
server
side
to
decide
like
which
data
you'd
want
in
the
default
page
instead
of
loading.
All
of
it
like
we
just
have
like
a
huge
scroll
window
here
with
all
the
with,
like
all
the
clusters
we
could
show
like
the
top
end
or
something
and
load
the
miniature
scroll
or
something.
C
C
A
It's
also
not
lost
on
me
that
I
see
a
bunch
of
things
that
look
like
this,
which
I
just
don't
know
about
this
package.
Api's
core
validation
thing.
That's
interesting,
maybe
go
ask
api
missionary
about
that,
but
I've
always
had
this
suspicion
that
the
integration
tests
end
up,
giving
us
way
more
data
than
we
need
that
may
not
cluster,
because
there
are
so
many
things
going
on
the
project.
B
A
E
A
The
next
one
I
spoke
about
this
a
bunch
last
week.
This
is
about
deprecating
and
migrating
away
from
this
gcs
bucket,
and
this
gcr
repository
for
all
of
the
ci
artifacts
that
are
built
for
kubernetes
kubernetes.
So
this
is
all
the
binaries
and
all
the
container
images
you
might
use
to
stand
up
the
cluster
for
e2
testing.
A
B
A
I
did
this
while
cleaning
up
all
the
kubernetes
ci
related
things
we'll
also
start
looking
at
doing
this
for
all
of
the
release
artifacts
as
well,
because
we
have
a
lot
more
control
on
the
redirector
about
where
we
send
traffic
and
how
much
of
it.
But
at
the
moment
the
redirector
is
fully
flipped
for
ci
artifacts,
so
they
all
come
from
community-owned
buckets.
A
I
don't
have
a
pretty
graph
to
show
you
today,
but
I
will
post
one
on
this
issue
later,
but
I
think
basically
the
only
remaining
thing
is
to
clean
up
all
the
docs
on
the
kubernetes
sig
release
repo
and
make
sure
that
everything
looks
good.
So
I
anticipate
having
this
work
all
closed
out
by
the
end
of
the
week.
A
The
next
one
I'm
just
going
to
kind
of
bucket
both
of
these
issues,
they're
related
to
migrating
away
from
the
google.com
specific
projects
for
the
scalability
jobs.
These
would
be
two
thousand
and
five
thousand
note
jobs
that
are
run
to
help
inform
whether
or
not
the
release
that's
being
worked
on
still
meets
scalability
requirements.
E
E
I
think
you
basically
can
see
them
at
the
end
of
the
issue,
if
oh,
no,
not
this
one,
so
okay,
so
I
I
went
to
see
scalabit
last
week
to
give
my
report
and
we
I
noticed
that
they
used
a
custom,
brilliant
or
golang
for
the
for
the
test,
but
running
a
community
infrastructure
is
not
building
anymore,
so
they
need
to
work
on
this
before
I
move
forward,
but
I
think
some
of
those
jobs
are
running
fine
on
caterpillar,
so
yeah.
I
think
this
is
basically
the.
E
Okay,
there
is
an
issue:
okay
increase
for
that.
Next
one
is
basically
the
the
issuer
basically
increase
for
this
project.
There
also
searches.
We
can
basically
increase
the
number
of
nodes
for
the
for
their
pre
summit-
it's
optional,
but
we
can
increase
from
2
000
nodes
to
5000
nodes.
So
I
added
a
new
canary
job
for
that
and
I'm
just
babysitting
the
job,
and
so
they
fix
the
issue
with
the
go
long
builds.
A
A
A
B
E
E
E
Kids
in
for
discussion
later,
let's
go
for
it,
so
I
have
kind
of
an
issue
with
resource
discovery,
because
over
the
last
six
months
I
I
discovered
a
lot
of
buckets
or
basically,
google
and
gcp
resources
create,
but
I
can
find
address
on
that
yeah
we
make
things
very
complicated
to
basically
say
to
the
community.
You
should
move
your
jobs
together,
so
I'm
trying
to
find
a
easy
way
to
discover
that
or
are
we
basically
pushing?
E
Are
we
asking
to
the
community
to?
I
press
identify
what's
needed
to
be
back
with,
because
I
found
over
maybe
six
to
seven
bucket
and
I
can
access
them.
I
don't
know
which
browser
in
which
project
they
are
create,
which
means
I
don't
know
if
I
need
to
recreate
them
and
migrate,
the
existing
one
or
just
create
empty
bracket
that
can
be
reused
when
we
migrate
for
kids
and.
A
I
think
largely
this
is
a
problem
we're
going
to
end
up
hunting
to
all
of
the
individual
six.
Just
like
we
don't
really
write
their
tests
for
them.
We
don't
really
write
their
jobs
for
them
either.
I
think
in
going
what
you're
going
through
with
six
scalability,
you
are
uncovering
certain
patterns
of
usage
and
what
we
could
probably
provide
is,
if
you're,
using
a
gcs
bucket
for
this,
you
should
do
this.
A
It
might
end
up
that
we're
provisioning
a
bunch
of
extra
gcs
buckets
over
in
kate
temperland.
It
might
be
that
we
tell
them
stop
it.
It
could
be
that
we
say
use
this
already
created.
Gcs
bucket
it'll
store
your
artifacts
at
this
pack,
but
I
think
it's
gonna
need
to
happen
on
a
case-by-case
basis,
and
I
think
it's
unfair
to
expect
one
central
sig
to
go.
Do
all
of
that
chasing
down
so
like
I
appreciate
that
you've
been
doing
all
of
this
to
move
the
scalability
stuff,
but
I
think
the
model.
A
What
we're
going
to
want
going
forward
is
to
ask
the
sigs
to
do.
I
think
fleshing
out
what
that
process
looks
like
is
part
of
the
crowd.
Migration
plan
that
I
plan
on
more
fully
fleshing
out
as
part
of
23..
We
can
talk
more
about
that
when
we
get
to
that.
So
the
two
other
things
real,
quick
that
are
in
progress,
one
of
them.
B
A
About
migrating
away
from
kubernetes
ci
images-
I
just
talked
about
this,
but
there's
a
whole
separate
issue
for
it,
so
I
think
I'm
basically
going
to
close
this
out.
If
I
remember
right,
yes,
there
were
a
few
references
to
this
that
I
did
not
catch
yet.
Once
I
update
those
references,
I
will
close
this
issue
out.
A
A
So
here's
an
example
of
how
you
can
hit
cs.kates.io
as
an
api
and
then
use
jq
to
consume
the
results,
and
using
this
I
was
able
to
generate
a
checklist
of
which
repos
still
have
references
to
the
old
things.
Some
contributors
have
then
helpfully
opened
up
full
requests
to
all
those
things.
Many
of
the
closed
ones
were
from
csi
saying
they
have
a
pattern
where
there's
a
central
place
that
then
gets
cloned
or
copied
to
the
other
repos
via
some
trees.
A
A
A
A
Something
like
that.
We
can
also
go
by
counting
by
kubernetes
releases
but
like
I
think
it
should
have
the
same
level
of
visibility
and
communication
as
we
communicate
for
the
deprecation
of
apis,
like
the
fact
that
a
bunch
of
apis
are
a
bunch
of
beta
apis
are
going
away
in,
122
is
being
widely
communicated.
A
A
And
actually,
as
I'm
talking,
I
realized
this
was
one
of
the
specific
things
about,
let's
just
click,
the
switch
on
dl.kates.io,
which
I've
had
a
bit
of
a
I've
kind
of
stepped
back
a
bit
from
that,
and
I
think
yeah
all
right.
This
is
the
one
that
always
happens.
I
think
we
should
consider
not
just
flipping
a
switch
on
dl.kates.io
like
we
shouldn't
just
send
all
the
traffic
all
at
once
to
the
new
bucket.
I
think
it
would
be
wise
to
consider
like
migrating
specific
pads
or
specific
uris.
A
So,
like
first,
we
serve
the
most
recent
versions
of
kubernetes
from
the
release
bucket
and
then
we
sort
of
gradually
serve
other
things.
That
way
we
can
just
kind
of
roll
up
the
traffic.
Hopefully-
and
I
guess
part
of
my
concern-
comes
from
making
sure
we
don't
immediately
eat
all
of
our
budget,
because
my
my
gut
tells
me
based
on
graphs.
A
I
will
find
some
way
to
share
later
that
the
volume
of
traffic
we
receive
for
container
images
as
a
community
is
an
order
of
magnitude
less
than
the
traffic
we
receive
for
arbitrary
libraries,
and
you
know
we're
working
on
understanding.
How
much
of
that
traffic
comes
from
the
project
itself
versus
other
clouds?
D
A
The
next
one
is
a
much
lighter
lift.
I
think
this
is
migrating
away
from
the
google
project
called
kate's
test
images,
so
pretty
much.
Every
single
job
like
by
an
order
of
magnitude,
most
jobs
that
run
in
kubernetes
like
run
on
proud
updates.I,
o
use
everybody's
favorite
image,
cookin's
e2e
lives
in
a
google.com
repository
called
kate's
test
images.
A
So
the
goal
would
be
to
take
everything
every
image
that
is
pushed
here
and
push
it
to
a
community
owned
repository
which
are
now
hopefully
set
up
somewhere
down
here
yeah.
So
arnold
set
up
a
case
test
infra
staging
repository
and
much
as
we
have
moved
other
parts
of
the
project
over
to
community-owned
staging
repositories.
A
Do
the
same
thing
here
in
fact:
there's
nothing
stopping
us
from
just
going
ahead
and
pushing
things
over
to
the
staging
repository
right
now.
I
just
don't
want
to
flip
all
the
jobs
while
we're
waiting
for
the
122
release
to
go
out
the
door.
That
might
be
slightly
disruptive,
but
I
think
this
would
be
a
great
example
of
one
of
the
changes
that
we
could
do
in
the
lull
before
123,
because
it's
basically
going
to
be
a
bunch
of
search
replays.
A
A
E
E
Two
or
three
weeks
ago.
Someone
suggests
we
should
we
could
cut
the
traffic
to
pro
quesadilla
and
during
a
maintenance
window
of
four
to
six
hours.
We
can
redeploy
pro
in
the
community
on
the
infrastructure
and
we
done
with
that
and
alvaro
say
they
did
something
like
that
in
reddit
that
he
was
supposed
to
find
some
document.
That
is
so.
This
is
like
I'm
trying.
The
question
is:
is
it
possible
to
get
the
traffic
for
a
specific
amount
of
hour
and
shift
everything.
A
A
So
I
would
feel
a
lot
more
comfortable
if
we
definitely
knew
what
rollback
looked
like
and
what
sort
of
mitigation
procedures
would
look
like
if,
for
whatever
reason,
standing
up
the
new
instance
or
not
quite
having
a
clean
enough
cut
between
old
and
new
caused.
A
bunch
of
this
is
called
bad
data
to
get
generated,
but
I
think
it
is
very
true
that
the
engineering
and
coordination
overhead
of
attempting
to
do
some
zero
downtime
migration
from
one
instance
to
another,
is
probably
more
trouble
than
it's
worth.
A
B
D
D
A
Yeah
cutting
the
build
cluster
stuff
over,
like
I
feel
confident
enough
having
done
that
with
release
blocking
merge
blocking
jobs.
Aside
from
the
complication
that
arnold
is
talking
about,
where
the
community
build
clusters
don't
and
should
not
have
rights
to
be
able
privileges
to
be
able
to
write
to
google.com
of
assets.
It's
a
pretty
straightforward
process
of
changing
like
adding
the
cluster
field
and
then
seeing
if
it
breaks.
A
However,
like
I'm
so
much
more
excited
about
running
the
control
plane,
because
I
want
all
of
you
to
be
capable
of
helping
run
it
like,
frankly,
it's
it's
kind
of
what
I've
wanted
to
do
since
I
started
working
on
kubernetes
before
I
worked
for
google
so
to
honor.
The
other
thing
that
arno's
question
is
reminding
me
of
is
so
the
testing
for.
B
A
Kong
team
that
currently
manages
kate's
crowd
has
like
a
bunch
of
scripts
and
stuff
that
they
use
that,
I
believe,
rely
on
the
fact
that
it's
a
google.com
project.
This
is
not
the
only
instance
of
crowd
that
they
manage.
There
are
many,
and
so
it
is
not
clear
to
me
that
it
could
be
just
a
straight
copy
paste
and
then
all
of
their
stuff
would
continue
to
work.
A
A
B
A
A
A
But
like
I
think,
it's
totally
fair
and
reasonable
to
have
prow
up
and
running
and
managing
a
few
repos.
I
think
the
stretch
the
longer
stretch
goal
will
be
have
prowl
in
k-tempra.
Managing
everything
and
potentially
somewhere
in
the
middle
is
like
rao
and
kate.
Infra
is
responsible
for
managing
one
org
or
it's
responsible
for
managing
everything.
That's
involved
in
the
kubernetes
release
process,
and
then
we
could
say
like
all
the
kubernetes
projects
and
stuff
they
are
responsible
for
kind
of
cutting
over
to
the
new
one.
A
A
A
Get
his
full
name
c
pinato
a
number
of
other
people
have
really
helped
get
us
so
very
close
to
the
line
making
sure
that
every
image
that
is
used
for
end-to-end
tests
of
kubernetes,
whether
it
be
in
the
end
and
tests
themselves
or
in
manifests
that
are
stored
in
there
or
whatever
all
come
from
community
repos
they're.
Just
a
few
last
things
that
didn't
quite
make
the
test
freeze
deadline.
A
A
Let's
see
I've
bucketed
a
whole
bunch
of
stuff
under
this,
but
since
I
just
gave
an
overview
of
kettle
and
big
query
and
triage
and
all
that
stuff
like
those
are
all
different
individual
components,
but
most
of
them
run
in
the
same
gcp
project
called
kate
scuberger,
and
I
would
like
I
would
like
to
see
us
have
migrated.
At
the
very
least.
The
historical
data
set
like
that
big
query.
Data
set
should
live
in
the
community
of
infrastructure
and
stretch
goal
would
be
everything
so
end
to
end.
A
We
hit
quota
issues
all
the
time
and
the
I
think
the
correct
way
to
solve
this
is
for
them
to
use
a
service
account
that
is
in
the
project
that
they
are
trying
to
push
their
images
to
it's
a
lot
of
boilerplate,
but
it
shards
things
out
a
lot
more
cleanly
and
concisely.
If
we
do
that,
I
think
most
everybody's
flaky
problems,
pushing
images,
goes
away.
A
B
Yeah,
I
can
give
a
quick
update,
so
we've
been
making
some
good
progress
on
that
cap.
I
don't
have
it
handy
here,
but
the
thing
that
we
were
targeting
at
least
for
this
release,
was
to
get
get
testability
like
enable
being
able
to
test
skill,
scale
tests
and
node
tests
with
cube
test2,
and
we
already
have
the
cluster
loader
tester
working
and
we've
we're
still
working
with
signal
to
figure
out
the
details
on
how
the
node
tester
will
finally
and
who
will
own
it
and
details
around
that.
B
I
guess
once
code
freeze
and
like
all
the
craziness
ends,
we
can
start
creating
shadow
jobs
for
the
pre
submits,
really
pre-submit,
docking
jobs,
which
would
be
one
node
test
and
one
scale
test,
and
we
already
have
a
shadow
job
for
pull
communities
into
egcc,
so
yeah.
I
guess
we
we'll
be
unblocked
to
start
migrating.
B
Some
of
the
resumes
we
already
had
good
success
with
one
of
the
jobs,
one
of
the
release
blocking
jobs
that
we
migrated
in
the
last
release,
which
is
the
gc
conformance
job
and
that's
been
the
default
for
122,
and
we
haven't
seen
any
delta
between
the
old
cube
desktop
and
the
new
crypto
job.
So
yeah.
A
B
Yeah
so
good
point,
we
actually
have
made
progress
in
in
the
way
that
cubase
two
binaries
are
now
built
into
the
kubecon's
image,
and
we
no
longer
need
to
pull
like
you.
We
no
longer
need
to
go,
get
cube
test
from
like
directly
from
the
repo
and
so
cube.
Test2
is
actually
the
entry
point
for
the
jobs
that
we
have
already
migrated,
which
means
the
goal
of
being
able
to
reproduce
it
locally
is
much
cleaner
now
and
you
don't
need
to
go.
Get
like
at
run.
Time
are.
B
B
A
A
A
A
A
Why
are
these
tests
in
this
job?
Because
you
know
it's
a
code
base,
the
number
of
tests
that
people
add
to
it
just
kind
of
monotonically
increase
over
time,
which
means,
unless
we
change,
how
we're
running
the
tests,
the
amount
of
time
we're
going
to
wait,
is
going
to
grow
over
time
too.
So
we
need
a
forcing
function
to
kind
of
keep
things
smaller,
lower,
faster.
A
A
B
A
A
A
A
Joining
in
and
helping
out
is
the
best
way
to
make
that
happen.
If
you
think
what
we've
discussed
here
is
less
important
than
something
you
think
would
benefit
the
community
more.
Let's
have
a
discussion
about
that
for
sure,
because
you
know
ultimately,
whoever
shows
up
and
does
the
work
gets
to
decide
what
work
gets
done.