►
From YouTube: Kubernetes UG VMware 20210805
Description
August 5, 2021 meeting of the Kubernetes VMware User Group. Dan Finneran presented an introduction and deep dive on running kube-vip as a load balancer for Kubernetes to achieve high availability, oriented to on premise Kubernetes deployments on vSphere, but also applicable to generalized on prem deployments, including home labs. Tradeoffs of BGP vs ARP were discussed. The presentation was followed by Q&A.
A
Hi,
welcome
to
the
august
5th
meeting
of
the
kubernetes
vmware
user
group
on
the
agenda
for
today's
meeting
is
a
deep
dive
into
the
cube
vip
load
balancer
for
kubernetes
at
the
meeting
a
month
ago.
Some
of
you,
I
think,
were
there,
some
of
you
perhaps
not,
but
that
meeting
was
recorded.
It
is
up
on
youtube
and
there
are
some
notes
for
it
in
the
agenda
notes,
doc
that
I
put
in
the
chat
we
in
a
month
ago.
A
We
did
kind
of
a
broad
coverage
of
load
balancers
for
kubernetes
and
at
the
end
of
the
meeting
we
did
an
audience
poll,
probably
not
scientific
because
of
sample
bias,
but
cube
vip
came
out
as
a
leader
in
terms
of
what
people
in
this
group
who
attended
the
meeting
are
using
now,
so
we
thought
we'd
invite
dan
to
do
a
deep
dive
into
cube.
It's
an
interesting
project
and
it
looks
like
some
people
are
already
familiar
enough
with
it
to
be
using
it,
but
maybe
others
not,
but
hey.
A
You
can't
beat
going
right
to
the
originator
of
the
project
and
looking
at
the
github
stats,
I
think
he's
still
doing
a
lot
of
the.
What
do
they
call
a
chopping
wood
and
carrying
water,
so
dan
I'll
turn
it
over
to
you.
Maybe
you
can
start
with
we.
We
tried
to
do
a
summary
of
cube
vip
last
month,
but
maybe
we
didn't
do
it
justice.
So
if
you
want
to
just
start
with
an
intro,
because
we've
also
got
some
newcomers
here
sure
and
then
we'll
go
into
deeper
dive
into
whatever
you
want.
B
Okay,
not
a
problem.
Thank
you
very
much
for
for
inviting
me
and
having
me
be
part
of
the
vmware
user
group.
So
I
guess
a
little
bit
of
background.
I
am
currently
at
equinix
metal,
where
I
am
leading
a
team
of
engineers
who
are
focused
on
a
lot
of
kind
of
kubernetes
things:
cluster
api,
a
cluster
api
for
bare
metal
and
a
bunch
of
other
kind
of
automation,
tools
all
around
bare
metal
and
things
like
that,
but
prior
to
equinix
metal
or
what
was
packet.
B
I
was
at
vmware
where
I
was
there
as
part
of
the
heptio
acquisition,
where
I
was
running
kind
of
field,
engineer
engineering
in
a
mayor
and
it
was
kind
of
a
heptio
where
I
had
a
focus
of
bare
metal,
kubernetes
clusters.
So
a
lot
of
the
work
I
was
doing,
whilst
I
was
at
heptio-
was
kind
of
architectural
best
practices
around
getting
kubernetes
stood
up
on
bare
metal
platforms
and
through
that
I
kind
of
hit
a
number
of
issues
that
I
thought.
B
Maybe
I
could
automate
and
maybe
you
know,
there's
a
solution
here
that
can
be
made
and
out
of
you
know,
kind
of
that.
Where
kind
of
cube
vip
came
from
so
I've
got.
I've
got
like
a
bunch
of
slides
that
I've
put
together.
I
can
kind
of
rattle
through
those
quite
quickly.
If
you
do
have
any
questions,
then
please
just
ask
me
them,
as
as
I'm
kind
of
going
through
the
slides,
and
we
can,
you
know
we
can
kind
of
bounce
backwards
and
forwards,
and
things
like
that.
B
So
where
did
it
actually
come
from?
So,
as
I
mentioned
when
I
was
at
heptio,
I
was
doing
a
lot
of
bare
metal
provisioning
and
I
effectively
wrote
a
bunch
of
software
to
automate
the
provisioning
of
of
kubernetes
on
bare
metal
and
this
all
kind
of
came
about,
because
one
customer
that
I
was
working
with
flew
over
to
go
work
with
them.
B
They
kind
of
walked
me
into
a
room,
told
me
what
they
wanted
and
then
just
disappeared,
and
they
effectively
just
asked
me
to
build
basically
a
kubernetes
cloud
on
on
their
bare
metal
servers
that
looked
acted
and
felt
like
they'd,
be
able
to
do
things
in
aws,
which
was
quite
bonkers
at
the
time,
but
effectively
at
the
end
of
like
a
two-week
stint
with
them.
I've
written
loads
of
shell
scripts
and
this
that
the
other
to
automate
all
this.
B
This
work,
and
out
of
that,
I
kind
of
realized
that
maybe
I
could
there's
another
project
that
I
could
do
so
effectively.
I
wrote
a
project
called
plunder,
which
was
a
bear
mel
provisioning
for
kubernetes
and
the
next
step.
For
that,
really
I
thought
of
where
was
using
cluster
api
on
top
of
this
project
for
bare
metal
provisioning
and
it's
kind
of
there,
where
I
started
to
hit
hit
issues.
B
So
if
we
look
at
kind
of
kubernetes
architecture,
it
has
the
control
plane
and
then
it
has
a
number
of
workers
that
will
send
communicate
with
that
that
are
communicated
to
via
the
control
plane.
And
if
you
lose
that
control
plane,
then
effectively
workloads
will
carry
on
running,
but
you
can
no
longer
make
changes
or
manage
or
monitor
or
have
any
real
idea
in
terms
of
what's
actually
happening
inside
your
kubernetes
control
plane.
B
But
then
you
also
need
things
like
a
clustering
technology
which
will
expose
a
third
or
sorry
which
will
expose
a
additional
ip
address,
which
is
effectively
like
a
floating
ip
address
and
then
you'll
need
the
capability
of
load
balancing
between
all
of
those
the
nodes
that
are
in
the
actual
control
plane
and
at
the
moment
you
know
you
can
do
this
today
or
you
could
do
it.
Then
sorry,
but
you
needed
a
number
of
tools
in
order
to
do
that.
B
So
you
could
use
things
like
keeper
live
d
and
h,
a
proxy
and
nginx,
and
things
like
that.
The
problem
that
I
really
had
there
was
that
they
really
did
not
fit
very
well
into
the
cluster
api
model.
You
had
three
then
sets
of
configs
to
manage.
We
had
a
vip
technology,
we
had
a
load
balance
in
technology
and
then
we
had
kind
of
the
management
of
kubernetes
and
the
control
plane,
and
things
like
that.
B
B
However,
it
turned
out
that
it
was
quite
unstable
in
terms
of
the
the
the
way
that
kind
of
cluster
api
does
a
lot
of
the
the
node
upgrades
and
things
like
that
effectively.
You
know
you
require
that
odd
number
of
nodes
in
order
to
do
things,
however,
when
we
would
remove
a
node
as
part
of
the
upgrade
process,
so
typically
with
cluster
api,
you
you'd
have
three
nodes
that
have
version
1.20.
B
You
would
remove
a
node
and
add
in
a
new
node.
That's
version.
1.21
raft
would
basically
just
explode
at
that
point
when
that
third
node
was
removed
and
with
no
leader
in
the
cluster.
At
that
point,
there
was
no
vip
with
no
vip.
There
was
no
way
to
access
the
cluster.
So
whilst
it
worked
for
the
first
time
you
kind
of
got
it
had
it
up
and
running,
the
upgrade
procedure
was
very
unreliable
with
raft.
So
I
opted
to
use
the
technology
that
comes
out
of
the
box
with
with
kubernetes.
B
So
there
is
an
election
api
that
the
kubernetes
api
exposes.
It's
called
the
leader
election
api
and
it's
used
by
a
variety
of
different
things
inside
inside
the
kubernetes
api
and
and
some
of
the
various
other
control
plane
components
make
use
things
like
that.
The
way
that
it
works
is
that
effectively
a
number
of
a
number
of
pods
or
effectively
anything
that's
used
in
the
kubernetes
api
can
say
to
the
kubernetes
api.
B
I
want
to
hold
a
lease.
That's
called
this.
You
know
we
can
call
at
least
cubevip,
for
instance,
and
everything
you
know
we
can
have
a
number
of
pods
or
bits
of
code
saying
I
want
to
hold
this
lease.
The
api
will
select
select
one
of
those
one
of
those
requests
and
say
that
you
actually
have
that
lease.
B
B
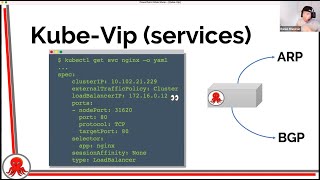
This
is
important
for
arp,
so
there's
a
number
of
technologies
that
kubevip
uses
in
order
to
expose
addresses
to
the
outside
world
arp
bgp
we're
looking
at
ospf
there's
some
others
that
we
can
possibly
look
at
as
well,
but
arp
and
bgp
are
typically
the
most
common
that
we
we're.
Seeing
at
the
moment,
with
cube,
vip
and
arp
effectively
is
how
a
new
ip
address
will
expose
itself
on
a
network
so
effectively
arp
will
we
we
can
apply
an
address
to
a
node.
B
We
can
then
use
arp,
which
is
effectively
a
a
lookup
table,
so
it
effectively
says
to
the
network.
If
you
want
to
get
to
this
ip
address,
it
is
at
this
mac
address
so
effectively.
If
you
want
to
send
traffic
to
this
ip
address,
then
data
should
be
sent
to
this
hardware
address
on
the
network
and
we
use
arp
to
broadcast
and
update
the
network
as
to
where
something
actually
is.
So.
B
This
is
important
as
we
with
a
floating
ip
address
when
that
ip
address
moves
over
due
to
node
failure
or
upgrades,
or
anything
like
that
or
a
new
leader
election.
When
that
new
leader
is
elected,
it
can
do
that
art
broadcast.
The
network
then
knows
that
the
ip
address
is
moved,
so
traffic
should
then
be
sent
to
that
node,
where
the
ip
address
has
actually
happened.
B
One
second,
so,
as
mentioned
when
we
do
that
broadcast
we're
effectively
telling
the
network
which
hardware
to
send
traffic
to
the
other
technology
that
we
use.
Oh
there's
one
other
thing
about
arp,
that's
important
as
well.
Only
one
node
should
be
doing
arp
broadcasts
saying
that
it
has
that
ip
address.
That's
why
we
need
leader
election
with
arp.
B
This
is
because
a
network
gets
very
confused
when
multiple
pieces
of
hardware
share
the
same
ip
address.
You
will
effectively
end
up
with
broken
traffic,
and
things
like
that,
so
only
the
leader
should
be
doing
the
art
broadcast
and
when
it
does
the
art
broadcast.
The
network
then
knows
to
send
traffic
to
that
ip
address.
B
Only
to
that
one
host
bgp
is
slightly
different,
so
bgp
is
a
layer,
3
routing
protocol
and
what
it
effectively
allows
a
node
or
nodes
to
do
is
tell
the
routers
in
the
in
the
in
the
facility
that
if
they
want
to
send
traffic
to
an
ip
address,
then
they
should
root
that
traffic
through
my
ip
address.
So
we
can
see
on
this
diagram
here.
We've
got
four
four
hosts
dot
22.23
effectively
with
bgp.
B
B
B
What
that
means
is
that
our
external
host,
that
the
macbook
at
the
top,
that
is
trying
to
go
to
10.0.2.5
the
traffic,
will
go
to
the
router
and
the
router
then
we'll
forward
that
to
one
of
the
hosts
that
are
advertising,
so
we
get
additional
load
balancing
from
the
top
of
rack
router
itself,
so
arp
versus
bgp
arp
doesn't
require
any
special
equipment.
It's
just
layer,
two,
a
switch.
Has
you
know
these
arp
tables,
so
anything
that
does
that
update?
B
You
need
to
have
some
software
running
that
understands
bgp
peering
and
things
like
that
or
you
need
a
expensive,
router
or
top
of
rack
switch
that
supports
bgp
functionality
negative
for
our
poisoning
can
disrupt
the
network.
We
man
that
we,
you
know
we
negate
that
by
using
cluster
leader
election.
B
B
There's
I've
just
quickly
checked.
The
chat
is
there.
If
there's
anything
in
here
raft
is
a
true
pleasure
to
work
with
that's
in
speech
marks.
So
I'm
assuming
that's
an
ironic
pleasure,
okay
paxos
for
life,
fantastic,
so
I'll,
quickly
kind
of
go
through
the
installation.
As
I
mentioned.
If
anybody
does
have
any
questions,
then
please
kind
of-
let
me
know,
as
I'm
kind
of
stepping
through
this,
but
I'll
I'll
kind
of
go
through
this
bit
quite
quickly
as
well.
B
So
how
do
we
actually
deploy
and
run
cubevip
cubevip
runs
inside
of
kubernetes.
It
needs
to
run
inside
of
kubernetes
because
it
makes
use
of
things
like
the
leader
election.
So
in
order
to
do
that,
it
needs
to
be
able
to
speak
to
the
api
server
and
things
like
that.
The
two
most
common
deployment
methods
are
static,
pods
or
demon
sets,
but
both
of
those
have
quirks
that
you
may
need
to
be
aware
of
in
terms
of
deploying
cube,
vip,
so
static
pods.
B
B
So
what
that
actually
means
is
that,
as
cube
adm
in
it
because
cube
admin,
it
will
basically
put
in
the
the
manifest
folder
a
number
of
other
static
pods.
So
things
like
the
api
server
and
lcd
and
a
few
other
things
they're
actually
all
static.
Pods
that
run
on
nodes
as
well
cube,
adm
init,
will
put
all
of
those
manifests
in
there
where
the
cube,
vip
manifest
will
also
exist.
Those
components
will
all
come
up
together,
so
the
api
server
will
start.
Xcd
will
start,
but
cubevip
will
also
start
along
with
it.
B
What
that
means
is
that
the
vip
will
spring
into
life
as
the
api
server
starts.
Cubevip
can
then
speak
to
the
api
server
and
do
that
leader
election
and
on
the
first
node.
It's
the
first
thing.
That's
actually
up.
It's
the
only
thing
asking
for
that
lease,
so
it
by
default
we'll
get
that
lease
and
become
the
leader
in
the
cluster,
at
which
point
it
will
start
advertising
the
vip
to
the
outside
world.
Cube
adm
in
its
final
step
will
speak
to
that
ip
address
and
hey
presto.
B
We
now
have
our
first
node
of
the
cluster.
Actually
up
and
running
the
next
step,
then,
is
to
join
all
of
the
other,
the
nodes
to
the
cluster
and
add
in
the
static
pods
on
those.
Are
the
control
plane
nodes,
so
that's
effectively
how
it
how
it
stands
itself
up
with
a
demon
set
it's
much
easier,
but
with
a
demon
set,
we
can't
do
cube
adm
in
it
so
for
a
demon
set.
B
So,
with
this
we
can
effectively
do
k3s
server
and
standard
path.
First,
node
we
do
the
tls
san
for
our
vip.
All
that
means
is
that
we
sign
our
api
server
with
that
vip
address
at
that
time,
and
then
we
drop
in
our
daemon
set
for
cube
vip,
at
which
point
then
we
can
add
in
all
of
our
additional
k3s
control,
plane
nodes.
B
So
we
have
cube
vip
either
running
as
a
daemon
set
or
a
static
pods
on
all
of
our
control
plane
nodes,
one
of
the
nodes
from
an
arp
perspective
will
be
the
leader
through
leader
election
in
the
event
that
that
node
goes
through
upgrade
or
node
failure,
or
anything
like
that.
A
new
leader
election
will
take
place,
at
which
point
the
network
will
be
updated
so
that
to
get
to
that
vip.
B
Send
traffic
in
this
instance
to
control
plane,
node
number
three
with
bgp
all
three
of
the
control
plane
nodes
will
effectively
be
advertising
to
the
routers
or
top
of
rack
switches
that
they
have
the
vip
and,
in
the
case
that
any
of
these
nodes
fails.
For
whatever
reason
they
will
stop
advertising
to
the
top
of
rack
switch.
So
here
we
can
see
we're
trying
to
speak
to
the
vip.
B
B
D
B
So
so
the
way
that
so
effectively
for
bgp
to
work.
Let
me
just
pop
back
here
so
I've
not
shown
on
here,
but
we
would
have
a
demon
set
or
a
static
manifest,
which
would
have
the
bgp
peers
in
it
so
effectively.
The
bgp
peers
in
this
example
would
be
normally
there'd,
be
more
than
one
router
here,
but
there's
just
one
router
in
this
diagram,
though
you
know,
those
top
of
rack
switches
are
going
to
be
relatively
static.
B
You
don't
tend
to
replace
your
routers
on
a
regular
basis,
so
those
those
root
appears
would
be
in
the
manifest
whether
a
demon
set
or
a
static
pod.
The
one
thing
that
does
need
to
be
unique
is
the
the
server
id
of
the
bgp
of
the
bgp
client.
So
the
way
that
we
do,
that
is
the
sta
as
the
static
pod
or
the
demon
set
manifest.
B
Node
1,
node,
2
and
node
3
need
this
unique
server
id
to
differentiate
themselves
to
the
router,
to
which
they're
appearing
and
we
can
use
that
ip
address
as
as
kind
of
the
peering
mechanism
to
work
and
it
will.
It
will
look
that
up
as
cube
vip
starts.
It
will
then
connect
to
all
of
the
bgp
peers
in
its
config
and
then,
as
we
advertise
things
it
will,
it
will
notify
those
top
rack
switches,
so
it
would
work.
B
D
A
B
No
so
effectively
as
as
as
a
node,
so
for
control,
plane,
nodes
using
dhcp
or
things
like
that.
They,
the
nodes,
turn
on
get
a
ip
address,
the
process
for
joining
them
to
the
control
plane
or
what
would
happen
it
would
use
that
dhcpi
address
as
its
server
id
and
then
just
start
peering
with
the
top
of
rack
switch.
If
a
node.
A
B
Or
anything
like
that,
it
would
just
stop
peering,
and
that
would
be
the
end
of
it,
so
it
would
all
be
very
dire
it
would.
It
would
be
dynamic
as
things
spring
into
life.
They
would
start
that
appearing
but
cube.
Vip
would
look
up
the
address
on
startup
and
then
use
that
in
order
to
appear
with
the
top
rack
switch.
C
B
B
The
first
is
a
ccm
or
a
cloud
controller
manager
and
then
something
to
actually
do
the
networking,
whether
that's
an
f5
top
rack,
switch
or
cube
vip
inside
your
kubernetes
cluster,
and
things
like
that.
So
you
know
kind
of
what
what
do
they
do?
What's
the
relation
here,
so
a
ccm
is
effectively
the
secret
source
for
your
infrastructure.
B
If
your
infrastructure,
if
you
know
if
you're
aws,
then
your
ccm
or
your
cloud
provider,
its
role
is
effectively
being
able
to
speak
to
the
aws
infrastructure
and
get
information
that
is
relevant
to
the
kubernetes
cluster.
So
if
you
do
a
cube,
ctl
expose
inside
aws,
the
ccm
inside
amazon,
for
instance,
its
role
is
to
get
you
an
elb
address
and
write
that
into
the
kubernetes
api
object.
B
B
So
a
ccm
effectively
is
the
translation
layer
between
a
kubernetes
cluster
and
the
infrastructure
that
it's
actually
running
on
now
with
on-prem
edge,
your
home
environment
and
things
like
that.
You
know
nobody
wants
to
write
a
ccm
for
everybody's
home
lab
that
would
be
a
nightmare
and
they're,
not
the
easiest
of
things,
to
write
so
for
cube.
I've
effectively
written
as
much
of
a
general
purpose,
ccm
as
possible
and
the
ccm
yeah.
So
the
ccm
that
that's
been
written
for
cube
vip
effectively.
Just
manages
simple
ipam.
B
B
B
B
That
is
where
the
ccm
makes
a
change.
This
is
really
one
of
the
only
things
that
the
ccm
should
do,
so
the
ccm
doesn't
load
balance.
It
doesn't
do
anything
other
than
get
you
some
information
that
is
relevant
to
your
infrastructure
and
then
update
the
service
with
that
bit
of
information.
So,
for
instance,
I've
done
that
expose
the
ccm
hasn't
done
anything
quite
yet.
B
We
can
see
that
the
load
balancer
ip
address
hasn't
been
updated.
When
the
ccm
springs
into
life,
it
will
look
in
its
pool,
it
will
take
an
ip
address
from
that
pool
and
it's
the
spec
dot
load
balancer
ip,
that
it
will
update,
and
then
that
is
it.
That
is
the
job
of
the
ccn.
Ccm
then
goes
back
to
sleep
and
has
no
more
work
to
do.
B
B
B
B
This
is
probably
slightly
less
relevant,
but
for
some
edge
deployments
there
has
been
a
request
to
effectively
have
both
everything
all
running
in
the
same
place
so
effectively.
What
that
means
is
we
can
run
cube
vip
on
just
the
control
plane.
Nodes,
providing
high
availability
with
rpgp
to
the
network,
and
also
those
three
nodes
with
the
cubic
pods
running
will
upon
me
will
also
take
care
of
load
balancing
for
the
cluster,
so
we
could
have
no
workers.
We
could
effectively
remove
the
tank
from
the
control
planes.
B
B
Some
of
the
things
that
we're
asked
for
dhcp
load
balancers,
so
on
small
or
edge
networks.
We
might
not
want
to
care
about
the
ip
ranges
or
we
may
not
want
to
have
to
deal
with
those
sorts
of
things
we
can
leverage
the
whatever
devices
are
on
that
network
that
are
using
dhcp
to
give
us
an
ip
address
for
our
service.
So
how
that
works
is
that
if
we
do
a
cube
ctl
expose,
we
need
to
specify
that
the
load
balancer
ip
address
is
0.0.0.0,
which
is
effectively
erroneous
ip
address.
B
B
B
So
it's
it's
effectively,
one
of
the
few
ways
that
we
can
kind
of
share
the
load
when
using
arp
we've
done
a
number
of
bgp
enhancements
to
allow
next
hop
exposing
so
depending
on
your
environment,
you
could
do
a
cube,
ctl
expose
and
expose
directly
to
the
internet
and
have
traffic
route
all
the
way
in
to
your
services.
You
can
kind
of
see
this
in
places
like
equinix
metal,
so
inside
equinix
metal
we
run
cube
vip.
We
run
cube
vip
with
the
equinix
metal.
Ccm.
B
The
equinix
metal
ccm
effectively
will
get
you
an
ip
address
from
the
equinix
metal.
Api
kubevip
will
then
basically
be
able
to
do
bgp
to
tell
equinix
metal
routers
that
go
out
to
the
outside
world
to
send
traffic
in
to
that
address,
and
then
additional
things
I
mentioned:
ospf
improved,
observability
monitoring
and
working
on
improving
the
documentation.
B
This
was
a
little
bit
old,
so
cube
has
been
accepted
into
the
cncs
sandbox,
so
it
is
now
officially
a
cncf
project
and,
as
of
yesterday,
my
talk
on
cubit
was
accepted
at
cubecom.
So
if
I'm
allowed
to
go,
if
the
usa
will
allow
people
from
gb
in,
I
will
be
at
kubecon
to
answer
people's
questions
about
cubevip
as
well.
So
there's
a
lot
of
excitement
going
on
around
it
at
the
moment.
B
B
B
B
B
Bgp
powers,
the
internet,
you
know
you're
effectively
down
to
as
many
routes
as
can
be
added
to
a
router,
so
it's
highly
unlikely
that
you're
going
to
hit
any
issues
when,
when
using
bgp
with
even
the
biggest
clusters,
with
cube
vip
when
deploying
what
are
considerations,
points
of
failure
and
best
practices
for
high
availability,
so
I
mean
high
availability
effectively
comes
out
of
the
box.
It
was
what
I
originally
designed
cubevip
for.
B
B
Are
there
any
metrics
exposed
which
could
be
useful
for
troubleshooting
layer,
4
issues,
not
at
the
moment,
but
there
so
a
colleague
gianluca
implemented
most
of
the
observability
hooks
in
there.
Work
still
needs
to
be
done
in
order
to
do
that,
but
the
the
basic
parts
of
observability
are
all
there.
They,
the
rest
of
it's
just
not
been
fully
implemented
yet.
B
However,
it
does
have
a
lot
of
logging
that
it
can
generate
so
for
troubleshooting.
Typically,
anything
from
a
layer
4
perspective
is,
is
all
going
to
come
out
through
to
the
logs.
If
arp
broadcasts
are
failing,
then
then
you,
you
will
be
made
aware
of
it
and
if
bgp
peer
peering
is
failing,
then
that
will
all
be
reported
as
errors
as
well.
B
B
Depends
on
the
size
of
the
cluster
that
you're
actually
running,
so
I
probably
if
it's
if
it's
not
really
an
edge
cluster.
As
in,
if
you've
got
like
a
number
of
worker
nodes,
I
probably
would
recommend
leaving
cube
vip
to
do
the
and
then
effectively
just
swapping
out
or
if
you
want
to
replace
metal,
albeit
there's
no
reason
to
replace
metal
it'll,
be
if
it's
doing
what
it
needs
you
to
do.
B
Cubevip
doesn't
tie
itself
to
any
config
maps
or
anything
like
that.
It
ties
itself
to
kubernetes
api
objects,
which
means
equinix
metal,
could
write
a
ccm
that
spoke
to
their
api
and
just
updated.
The
services
cubevip
is,
will
only
care
about
kubernetes
api
objects.
It
doesn't
need
to
try
and
pass
a
config
map
or
anything
like
that.
It,
it
just
watches
those
primitives,
so
anybody
could
write
their
own
ccm
that
looks
at
their
own
network.
B
A
Yeah
it
does
dan,
I
I'm
just
checking
the
chat.
It
looks
like
we've
caught
up
and
I've
been
trying
to
transcribe
some
of
that
over
into
the
notes,
but
caught
up
there
now,
but
anybody
else
want
to
have
a
go
or
since
we've
got
dan
here,
any
other
open-ended
things
you'd
like
to
discuss
in
this
whole
field
of
high
availability
or.
A
A
Cancelled
as
a
physical
event,
I'm
a
hundred
percent
on
board
with
being
there
physically
and
I'm
hoping
that
if
any
other
members
of
the
group
managed
to
show
up
physically
we'd,
perhaps
have
a
social
gathering
to
get
together.
It
was
something
that
robert
had
arranged
to
happen
in
the
ill-fated
kubecon
europe
of
2020,
but
maybe
finally
we'll
pull
this
off.
A
A
B
It's
a
number
of
people
running
on
raspberry
pi's,
and
things
like
that,
alex
ellis,
has
been
doing
a
bunch
of
stuff,
with
cube
vip
for
a
variety
of
different
testing
that
he's
that
he's
always
kind
of
doing
with
his
with
his
things
like
that,
qvi
doesn't
require
internet
any
internet
access.
So
as
long
as
the
image
is
either
pre-pre-installed
in
the
container
runtime
cache
or
you
have
a
local
registry.
B
B
Your
control
plane
knows
when
they
start
they
will
power
on
cubelet
will
start
cubelet
will
start
everything.
That's
in
the
manifests
folder,
so
lcd
api
server
scheduler.
It
will
also
find
that
cube
bit
manifest,
so
qbit
will
come
up
along
with
all
of
those
components
as
all
of
those
components.
All
come
back
together,
the
control
plane
will
reconverge,
the
workers
will
be
able
to
speak
back
to
the
the
control
plane
ip
address
and
things
like
that.
A
D
B
It's
one
of
the,
I
guess
one
of
the
weird
problems
I
I'm
slowly
starting
to
get
more
and
more
feedback,
but
for
quite
some
time
I
didn't
really
know
who,
if
anybody
was
actually
kind
of
using
cubevip
and
it's
it's
cropping
up
in
kind
of
all
manner
of
kind
of
quite
crazy
places
at
the
moment.
So
it's
it's
nice
to
get
feedback
that
it's
it's
kind
of
doing
what
it's
it's
meant
to
do.
D
A
Yeah
we
had
an
audience
paul
now
granted
you
can
see
that
this
is
a
limited
number,
but
there
definitely
are
people
using
it
and
I
think
it's
middle
lb
got
an
early
start
for
people
using
it
at
edge,
but
I
think
people
are
discovering
other
things
out
there
and
maybe
challenges
to
trying
to
to
use
metal
lb
for
these
edge
applications.
So
the
trend
is
that
I
think
qvi
usage
is
growing.
B
And
miles
just
just
pointed
out,
it
does
upnp
as
well,
which
is
a
bit
of
a
it's
a
bit
of
a
funny
one,
but
effectively
for
edge
networks.
If
you
do
a
cube,
ctl
expose-
and
you
have
upnp
enabled
on
your
your
home
network,
for
instance,
so
your
your
your
home
router,
your
netgear
router
or
whatever
it
will.
It
will
actually
do
a
upnp
update
to
your
to
your
router,
which
effectively
will
do
port
forwarding
to
the
from
the
outside
world
in
to
your
service.
A
B
B
A
Okay,
well
thanks
dan.
That
was
a
great
presentation
and
I'm
looking
forward
to
your
kubecon
talk
as
well
before
we
go.
If
anybody
in
this
group
has
nominations
for
a
topic
for
next
month's
user
group
meeting
miles
and
myself
are
all
leaders
where
we
like
suggestions
for
topics
that
people
are
interested
in
rather
than
having
to
guess
and
go
get
speakers.
So
please
challenge
us.
A
A
So
it's
have
we
gotten
to
talk
on
andrea
before
I
don't
think
we
have
in
this
group.
We
can
what
we're
trying
to
do
here.
This
group
is
chartered
by
the
cncf
to
be
focused
on
running
kubern
kubernetes
on
vmware
infrastructure.
Technically,
entry
is
associated
with
vmware,
but
it's
not
real.
It
doesn't
have
a
super
solid
tie
to
vsphere
infrastructure.
It
runs
fine
there,
but
it
runs
fine
or
it
should
run
fine
anywhere
else
as
well.
A
A
That
we
might
even
have
a
couple
people
I
see
in
the
attendees
who
could
talk
about
that?
If
you,
if
we
have
any
volunteers
here,
otherwise
I
can
go
out
and
look
for
people
on
the
entry
project,
the
the
things
that
do
relate
to
running
on
vsphere,
I
think,
are
you
know.
One
of
the
issues
with
running
this
is
applies
to
both
storage,
plug-ins
and
network.
Plug-Ins
is
there's
often
a
strong
interest
in
somehow
tying
the
kubernetes
objects
to
the
vsphere
objects.
A
So
I'm
going
to
call
this
meeting
to
a
close,
but
thanks
everybody
for
attending
go
definitely
check
out.
Dan's
talk
at
cubecon.
Also
this
user
group
miles
and
I
will
have
a
talk
at
kubecon
and
we're
going
to
be
talking
about
using
gpu
resources
with
from
kubernetes
workloads
when
kubernetes
is
hosted
on
vsphere.
So
we've
got
a
a
talk,
green
lighted
for
kubecon
on
that
subject
as
well,
and
if
that,
if
that
interests
you
you
know,
the
applications
for
gpus
might
be
machine
learning
or
something
else.