►
From YouTube: Kubernetes UG VMware 20201105
Description
November 5 meeting of the Kubernetes VMware User Group. vSphere 7.0 Update 1 release - what’s new - speaker Gopala Suryanarayana
A
So
welcome
to
the
november
5th
2020
meeting
of
the
kubernetes
vmware
user
group
today
on
the
agenda.
We
have
a
presentation
by
gopala
on
the
new
features
related
to
the
7.0
update,
one
release
of
the
vsphere
hypervisor
and
how
that
might
relate
to
running
kubernetes.
On
top
of
that
infrastructure,
I've
put
a
link
to
the
agenda
doc
and
just
in
case
gopala's
presentation
doesn't
last
the
full
hour.
We
may
have
time
to
open
this
up
to
birds
of
feather
discussions
on
any
topic
that
people
might
like.
A
So
I'd
invite
you
to
go
ahead
and
add
some
whatever
you
like
to
that
agenda
for
open
discussion.
If
we
don't
have
time
for
it
in
this
meeting,
we'll
just
roll
it
over
into
the
next
one.
So
with
that
said,
I'm
going
to
turn
it
over
to
you
gopala.
I
think
I
made
you
a
co-host,
so
you
should
be
able
to
share
a
screen
if
you've
got
anything
to
present.
Yes,
yes,.
B
Thank
you,
steve
and
thank
you
for
having
me
today
good
to
meet
you
all.
My
name
is
gopala.
I'm
the
product
manager
in
vmware
and
my
my
main
focus
is
a
cloud
native
storage.
I
own
the
cloud
native
storage
parts,
the
roadmap
in
vmware,
and
I
also
focus
on
onboarding,
modern
stateful
services
like
object
stores
like
mongodb,
like
cassandra,
kafka,
etc
on
the
on
the
vsphere
platform.
Right,
so
that's
been
my
focus
as
well.
B
So
what
I'll
be
talking
about
today
is
I'll
be
presenting
the
the
deck
that
we
shared
in
vmworld,
which
is
essentially
the
the
newer
features
that
we
are
offering
in
vsphere
7,
as
well
as
7.2
update
one
right.
So
the
majority
of
the
content
here
is
this
is
mostly
on
the
the
container
support
the
community
support
in
both
seven
and
seven
update.
B
One
I'll
also
talk
about
some
of
the
some
of
one
of
the
new
features
that
we
offered
called
vsan
data
persistence
platform,
which
is
essentially
making
it
easy
for
customers
to
run
object,
stores,
kafka,
central,
such
applications.
The
the
the
primary
reason
is
the
communities
applications
that
we
see,
customers
running
frequently
depend
on
these
types
of
services
right,
so
I
want
to
talk
about
how
we
are
doing
making
it
easy
for
customers
and
developers
to
get
that
access
on
on
vsphere.
B
So
I
also
have
miles
with
me
who's
who's
in
my
team.
So
here's
so
please
feel
free
to
ask
us
any
questions.
Stop
me,
anytime,
we'll
be
happy
to
take
your
questions
all
right.
So
before
we
talk
about
what
we
have
done
and
vsphere
7
and
7
update
1
for
kubernetes
and
containers,
a
very
quick
refresher
on
why
vmware
is
embarking
on
this
journey.
B
We
clearly
see
that
the
industry
is
changing
when
it
comes
to
applications.
We
are
seeing
a
shift
from
monolithic
applications
to
microservices
these
these
these
applications.
The
modern
applications,
are
frequently
designed
as
a
set
of
many
different
micro
services,
each
of
which
could
be
independently
developed
independently
scaled
independently
life
cycle
managed,
and
each
of
them
could
use
it
to
separate
technology.
B
So
it
makes
it
much
easier
for
customers
to
write
scalable
geographically
distributed
applications,
and
it
turns
out
that
containers
microservice
containers
lend
themselves
very
well
to
microservices
because
of
the
nature
of
these
containers.
They
are
able
to
quickly
be
developed,
instantiated,
updated
provisioned,
so
containers
lend
themselves
very
well
to
these
micro
service
based
applications,
but
what
they
offer
is
they
offer
a
management
challenge,
as
the
number
of
containers
increases
number
of
microservices
increases
for
for
a
for
a
customer,
it
becomes,
it
becomes
problematic
to
manage
them.
B
So
that's
where
kubernetes
comes
in
and
solves
that
management
challenge
for
for
our
for
our
customers
and
and
these
communities
started
off
with
supporting
status,
applications
and
state
used
to
be
generally
managed
outside
of
these
kubernetes
applications.
But
then
customers
realized
the
benefits
and
power
of
kubernetes
and
wanted
to
also
bring
in
kubernetes
into
that
mix
for
stateful
applications
and
along
the
way
kubernetes
has
evolved
and
offered
more
and
more
support
for
stateful
applications
and
of
late.
B
We
are
seeing
this
evolution
to
even
support
highly
distributed,
complex
distributed,
stateful
applications
like
distributed
databases,
object
stores,
so
we'll
talk
about
it.
So
we
see
the
shift
and
kubernetes
is
becoming
a
mainstream
in
the
in
the
enterprise.
So
that's
the
reason.
Vmware
has
invested
a
lot
of
effort
in
supporting
these
applications
for
our
for
our
customers,
so
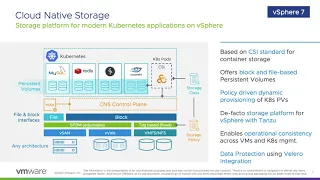
cloud
native
storage.
This
is
what
we
introduced
in
67
update
3,
which
was
last
last
year.
Vmworld
around
september,
we
introduced
our
first
version
this
year.
B
We
have
expanded
that
capability
and
we
are
offering
more
enhancements
to
this
platform.
But
in
a
nutshell,
what
we
have
is
we
have
the
csi
driver,
which
is
the
out
of
tree
kubernetes
storage
driver
with
with
the
vsphere
csi
driver,
and
with
this
we
are
offering
block
and
file
based
persistent
volumes.
B
The
the
secret
sauce
that
as
cloud
native
storage
offers,
is
that
you
know
bringing
the
two
worlds:
the
vsphere
vsphere
world
with
the
kubernetes
world
and
we
are
merging
the
two
worlds
here
when
it
comes
to
deployment
when
it
comes
to
operations.
All
of
that
we
are
making
it
easy
for
customers
developers
to
write
their
applications
on
kubernetes
that
runs
on
vsphere
right
and
we
bridge
the
two
to
constructs
here.
B
Valero
is
a
data
protection,
backup
orchestrator
for
modern
applications,
so
it
it
goes
through
the
different
name
spaces
that
are
that
are
deployed
on
the
on
the
cluster
and
goes
through
the
different
volumes
in
those
name,
spaces
and
orchestrates
those
backup
for
these
different
volumes,
and
we
have
the
integration
of
valero
with
the
cns
right
starting
from
7.0.
We
have
that
capability
so
with
this
customers
can
use
valero
to
take
backups
of
their
kubernetes
clusters
that
are
running
on
any
of
the
vanilla
communities.
Distributions.
A
A
B
Yeah,
oh
yeah,
so
steven
thank
you
for
bringing
that
up.
Yes,
I
had
another
slide
where
and
I
wanted
to
talk
about
it.
But
yes,
it's
a
great
point
that
you
bring
up
all
right.
The
independent
volume
life
cycle
management
is
one
of
the
key
benefits
of
cns.
So
here
the
persistent
volume
has
a
complete
life
cycle
of
its
own.
B
B
So
what
we
are
showing
here
is
a
dynamic
provisioning
of
a
read,
write,
many
persistent
volume
in
kubernetes
and
how
it
translates
into
an
actual
actual
object
on
the
underlying
storage
layer
and
what
is
involved
in
this
in
this
operation
here.
So
what
you
are
seeing
here
is
there
is
a
cns
component.
There
is
a
cns
driver
that
runs
within
the
vcenter
right
and
we
have
spbm,
which
is
our
policy
based
management
engine
that
is
also
running
within
vcenter
right.
So
this
is
the
engine
that
understands
policies.
B
Now
in
kubernetes
we
have
the
the
csi
provisioner
for
vsphere
right,
which,
which
talks
to
cns
for
all
its
control
operations
right,
create
update,
delete
life
cycle
management
of
the
the
persistent
volume
itself.
So
let's
take
an
application
that
is
interested
in
interested
in
and
read,
write
many
persistent
volume
right,
so
we
have
the
the
storage
classes.
B
So
let's
say
there
is
an
spbm
policy
on
vcenter
that
says:
hey
create
this
rewrite
many
persistent
volume
with
two-way
replication,
and
let's
say
there
is
a
policy
for
that
and
what
the
devops
admin
does
is.
He
creates
an
storage
class
that
mimics
that
particular
storage
policy
on
vsphere
right.
So
it
simply
points
to
that
storage
policy.
The
storage
class
points
to
that
and
then,
once
you
have
this
storage
class
that
is
now
pointing
to
the
underlying
sbbm
policy.
B
You
can
now
instantiate
an
application
and
refer
to
that
particular
storage
class
right,
so
the
storage
class,
when
it's
referred
to
it
and
when
the
application
is
actually
instantiated.
What
happens
is
now
the
storage
class
is
given
to
the
csi
provisioner
within
kubernetes
and
csi
talks
to
the
cns
plugin
within
vcenter
and
cns
is
now
going
to
interpret
this
particular
policy
that
is
associated
with
this
particular
storage
class
and
hands
it
off
to
the
spbm
policy
engine.
This
sppm
policy
engine
here
now
interprets
the
actual
policy
and
then
creates
a
read,
write.
B
Many
persistent
volume,
which
is
now
backed
by
a
vsan
file,
share
on
the
underlying
storage,
with
two-way
replication
and
on
the
way
back,
it
is
going
to
then
associate
this
particular
file
share.
It's
going
to
create
a
persistent
volume
and
then
hand
it
all
the
way
back
to
this
application
right.
So
now
you
have
an
application
that
is
now
has
a
persistent
volume
claim
persistent
volume
attached
to
it.
That
is
now
deployed
on
a
vsan
with
that
replication
right.
So
so.
B
The
summary
is
that,
with
this
spbm
policy
to
storage
class
integration,
the
the
provisioning
is
is
seamless
and
with
this
dynamic
provisioning
customers
do
not
need
to
worry
about.
Having
that
persistent
volume
be
created
up
front,
so
they
they
get
that
dynamic
provisioning
with
the
the
storage
class
and
administrators
again
just
deal
with
policies
and
developers
continue
to
deal
with
the
storage
classes.
B
So
so
the
other
other
feature
that
we
released
in
vsphere
7,
which
was
not
there
as
part
of
vsphere
67
update
3,
was
the
support
for
retract
many
persistent
volumes
right.
This
enables
customers
to
share
data
between
the
different
parts.
Using
the
read
write,
many
persistent
volumes
and
as
of
vsphere
7,
we
have
this
support
available
on
vsan
right,
so
vsan
file
services
is
also
something
that
we
launched
in
vcr7,
which
was
april
of
this
year,
which
allows
applications
to
now
consume
vsan
storage
using
file
shares.
B
B
B
A
B
What
we,
what
we
are
showing
here
is
how
customers
can
monitor
the
capacity
that
is
consumed
for
both
their
traditional
applications,
as
well
as
modern
applications
using
a
single
pane
of
glass.
We
show
the
space
that
is
taken
for
both
the
attached,
as
well
as
detached
volumes
on
on
vsan
here,
which
lets
customers
plan
for
their
capacity
right
for
their
modern
and
traditional
applications
on
the
clusters.
B
This
is
another
dashboard
that
we
have
introduced
this.
This
was
introduced
as
part
of
67
update,
3
itself,
including
the
previous
one
capacity
monitoring
screens.
What
we're
showing
here
is.
We
show
the
different
persistent
volumes
across
multiple
different
kubernetes
clusters.
We
show
the
block
volumes
the
file
volumes.
B
More
importantly,
we
also
show
the
different
application
labels
that
are
associated
with
these
persistent
volumes
so
that
developers,
if
they
are
seeing
any
issues
they
can
talk
to
their
it
teams
and
have
these
be
notable
short
or
monitored.
Using
these
application
labels
here
right
and
along
the
way,
we
also
show
the
health
capacity
etc
in
this
in
this
particular
screen.
So
this
screen
is
an
extension
to
the
previous
one.
So
when
you
click
on
the
on
the
persistent
volume,
we
also
show
the
actual
kubernetes
related
details.
B
Here
we
show
the
name
of
the
persistent
volume
claim
persistent
volume,
which
are
the
different
parts
that
have
these
volumes
mounted
the
name
space
associated
with
this
volume.
All
of
that
detail
is
available
right
within
a
vcenter
and
the
other
tab.
The
basics
tab
here
also
shows
the
the
storage
related
information
here,
which
is
extremely
useful
for
customers,
because
if
you
have
hundreds
of
these
persistent
volumes
and
if
you
are
seeing
performance
or
any
com
availability
issues
with
these
persistent
volumes,
it
becomes
very
simple
for
customers
to
look
at
which
data
store.
B
These
are
deployed
on
what
is
the
associated
v
sphere
policy?
What
is
the
compliance
and
health
status?
What
type
of
volume
it
is
all
of
that
information
is
available
as
part
of
this
tab
going
further.
If
a
data
store
supports
the
the
underlying
placement
details
to
be,
you
know
known,
we
also,
we
also
show
the
how
we
also
show
the
placement
of
this
volume
on
the
storage
layer
right.
B
What's
the
health
and
capacity
of
each
of
these,
these
disks
and
such
details
that
is
relevant
to
the
the
placement
right,
and
this
is
very
useful
to
our
customers
in
an
actual
customer
court.
One
of
our
customers
told
us
that
you
know
this
shaved
off
a
few
weeks
from
his
monitoring
and
troubleshooting
experience
for
modern
applications
right.
So
this
is
this,
is
this
is
useful.
B
B
Essentially,
the
the
promise
here
is
that
it
lets
customers
developers
consume
the
underlying
vsphere
resources
using
native
kubernetes
constructs
right,
so
they
are
now
able
to
get
access
to
the
different
vsphere
resources
directly
within
kubernetes,
without
having
to
actually
understand
a
vsphere
right,
and
the
other
important
aspect
is
now
communities.
Applications
get
the
benefit
of
the
underlying
hypervisor
when
it
comes
to
security
performance
or
what
have
you
and
they
can
get
that
native
hypervisor
capabilities
that
were
that
are
not
possible
before
before
before
tanzu.
A
B
So
steven,
that's
a
great
point
right.
So
basically,
this
slide
here.
This
slide
here
all
of
the
the
features
we
talked
about
right
that
is
available
for
all
types
of
communities
distributions
right.
So
this
is
available
for
vanilla,
kubernetes,
openshift,
pks
and
those
all
of
the
distributions
get
the
support
that
we
are
talking
about
here
right.
Our
csi
is
an
open
source,
csi
driver
and
it
is
available
for
all
the
communities
distributions
now
and
in
fact,
six
seven
update
three.
B
We
did
not
even
have
tanzu
and
we
supported
only
our
ecosystem
communities
distributions
now,
with
tanzu
support.
We
are
also
extending
those
capabilities
to
tanzu
with
the
the
part
service
and
the
tkg
service.
We
are
even
extending
those
distribution
support
other
distributions
that
we
had
support
for
to
the
tanzu
platform
here.
In
fact,
we
are
ahead
on
the
on
the
other
ecosystem
distributions
when
it
comes
to
cns
support
and
we
are
catching
up
on
the
tan
zoo
side
right.
B
B
So
tanjo
offers
two
types
of
kubernetes
offerings:
the
the
first
one
is.
This
thing
called
tkg
service,
which
is
going
to
be
compelling
for
developers
who
are
looking
to
use
conformant
kubernetes
distributions,
vanilla,
kubernetes
distributions
on
the
on
the
vsphere
platform,
the
use
case
there
is
they
are
developing
these
applications
on
either
public
clouds
or
other
types
of
communities
distributions,
and
they
want
these
on-demand
communities
clusters
deployed
for
them
similar
to
the
public
clouds,
but
they
want
that
enterprise.
B
Compliance
of
the
enterprise
grade
platform
that
virtanzu
offers
right.
So
that
is
the
the
tkg
service
and
the
part
service
is,
is
the
kubernetes
that
runs
on
the
hypervisor
directly
right-
and
here
you
you,
you,
you
get
all
the
the
hypervisor
benefits
of
performance,
efficiency,
etc
for
applications
that
are
running
directly
on
the
on
the
hypervisor
right.
So
this
is
the
other
distribution
that
we
that
we
offer
we.
We
believe
that
a
majority
of
the
applications
will
land
on
the
tkg
service
because
of
the
conformant
nature
of
this
particular
service.
B
Here
it's
also
attractive,
because
administrators
will
be
able
to
hold
the
control
when
it
comes
to
policies
when
it
comes
to
permissions,
quotas,
etc.
They're
still
able
to
get
all
of
that
benefit
with
the
tkg
service,
and
we
have
a
concept
of
a
namespace
for
vsphere
vitanzu,
which
which
lets
customers
and
admins
allot
a
particular
quota
under
policy
for
that
particular
namespace,
which
gets
translated
into
things
like
storage
classes
automatically
for
these
for
these
namespaces
right.
B
And
what
we're
seeing
here
is
you
attach
the
cpu
memory
limits?
The
storage
quotas
and,
in
fact,
quotas
per
policy
right,
so
you
are
able
to
attach
all
of
that,
and
we
are
also
able
to
assign
specific
storage
policies
to
this
particular
namespace
here,
and
the
storage
policies
will
be
automatically
translated
into
storage
classes
in
the
in
the
underlying
name
space.
B
B
We
have
made
the
support
available
as
well
on
the
tanzo
side,
so
the
volume
extension
is
is
another
important
aspect
that
we
offered.
So
we
we
support
offline,
persistent
volume,
extensions
right
and
the
the
one
other
feature
support
we
did
was
for
static
provisioning.
We
are
able
to
now
migrate
workloads
from
the
other
communities
distributions
to
tansu
using
the
static
provisioning
support
that
we
have
in
savino
update
one.
B
So
this
is
just
a
v-ball
integration
slide.
So
v-ball
support
was
not
there
in
seven
now
vsphere
7.
We
have
offered
that
support
in
seven
update
one.
So
with
this,
we
believe
that
external
storage
is
an
important
aspect
for
modern
applications
as
well,
and
we
see
a
lot
of
requests
for
external
storage
deployments.
A
B
A
In
gopala,
I've
we've
got
audience
members
of
all
flavors
here
and
I
just
want
to
sometimes
these
acronyms
get
get
out
there
and
they're
not
sure
what
they
are.
So
the
vival
is
a
storage
interface
for
vsphere
that
lets
you
attach.
I
don't
know
what
vmware
calls
third-party
storage
any
vendor,
who
wants
can
write
a
vival
compliant
driver
so
that
you
could
use.
A
The
vsan
implementation
is
something
where
putting
software
defined
storage
on
the
vsphere
compute
nodes
themselves,
so
it
starts
out
with
a
hardware
implementation
that
is
more
like
direct
attached,
storage
and
converts
it
into
resilient
software-defined
storage,
whereas
the
v-vol
is
typically
seen
in
a
multi-vendor
environment.
So
correct
me:
if
I
got
that
wrong
gopaller,
if
you
can
do
a
better
job,
but
I
just
wanted
to
make
sure
that
this
vvol
acronym
was
something
everybody
understood.
B
Right,
I
think
you
captured
it
very
well,
stephen,
so
we've
all
says
we
will
stand
for
vsphere
volumes,
which
is
a
way
in
which
external
storage
providers
can
expose
the
volumes
to
vsphere
and
the
the
granularity
of
management
is
at
a
volume
level
right.
So
you
can
assign
policies.
You
can
attach
these
volumes
to
the
virtual
machines
and
there's
a
per
volume
policy
that
can
be
assigned
right.
B
So
it
gives
us
a
very
clean
way
to
manage
volumes
on
the
external
storage
arrays
and
we
have
the
same
concept
for
vsan
right.
So
everything
is
a
visa,
an
object
that
translates
or
maps
to
the
volumes
and
the
policy
is
assigned
at
a
object
level
within
vsan
vsan
stands
for
virtual
san,
which
is
the
hyper-converged
storage
offering
from
vmware.
B
So
now
we
have
integrated
both
vsan
as
well
as
v-walls
in
into
this
into
this
mix
for
modern
applications,
and
that
was
the
storage
policy
management
that
I
talked
about
earlier,
which
now
is
also
extended
to
the
storage
classes.
So
it
gives
it
it
it
blends
pretty
well,
because
kubernetes
is
all
about
volume
management
right
it
all.
The
management
happens
at
the
individual
volume
level,
so
it
lends
itself
well
to
the
way
that
we
manage
volumes
on
vsan
and
vsphere
as
well
right.
B
B
B
I
want
to
again
motivate
this
by
talking
a
little
bit
about
why
we
are
doing
this
right,
so
the
applications
that
we
are
seeing
in
the
enterprise
is
they
are
changing
right.
So
what
used
to
be
applications
that
depended
on
a
few
database
instances
quickly?
They
are
transforming
into
these
modern
applications.
That
now
depend
on
not
just
one
database
instance,
but
a
variety
of
stateful
services
right.
B
So
so,
when
we,
when
we
double
click
on
what
these
stateful
services
are,
what
clearly
comes
up
is
object,
stores
becoming
one
of
the
main
mechanisms
in
which
these
modern
applications
consume.
Storage
developers
would
like
to
have
an
s3
endpoint
given
to
them
using
self-service
right
and
frequently
object.
Stores
are
almost
a
default
way
in
which
storage
is
consumed
right
and
the
other
good
aspect
of
object
stores
is
that
it
lends
itself
extremely
well
to
different
types
of
applications.
B
So,
on
the
one
hand,
you
see
high
performance
analytics
big
data
type
of
applications
that
that
use
object,
stores
all
the
way
to
applications
that
need
cheap
and
deep,
dense
storage,
and
they
depend
on
object
stores
as
well
and
not
to
not
to
forget
the
the
the
regular
application
that
just
uses
object
store
as
a
storage,
storage,
back-end
right.
So
they
to
all
of
these
types
of
applications.
Object
stores
have
become
extremely
important
and
that's
the
reason
we
are
seeing
it
becoming
a
mainstay
in
the
in
the
enterprise
and
almost
always.
B
We
also
see
the
other
services
like
kafka
readers,
cassandra
that
show
up
primarily
because
the
applications,
these
newer
applications
are
highly
distributed,
they're
geographically
deployed,
and
they
also
want
their
associated
data
services
to
be
distributed
and
to
scale
to
multiple
geographies
like
the
applications
themselves.
And
all
of
these
databases
that
we
see
here
fit
the
bill
and
they
are
also
becoming
quite
popular
in
the
in
the
modern
application
world.
B
So,
basically,
if
we,
if
we
ask
ourselves
the
question
as
to
why
why
these
are
any
different
customers
have
been
dealing
with
databases
and
stateful
applications
forever.
Some
of
the
some
of
the
things
that
come
up
is
these
are
architected
differently.
These
newer
services
are
activated
differently.
They
are
the
so-called
shade.
Nothing
applications
right
that
manage
data
availability
within
their
own
layer.
They
don't
need
the
underlying
storage
layer
to
provide
that
replication
and
availability
for
them
and
they're
all
highly
distributed
applications
right.
B
So
management
is
a
challenge
for
for
customers
and
that's
another
aspect
that
comes
up
and
the
the
next
aspect
is
that
these
are
all
consumed
using
the
cloud.
Consumption
models
right,
they're
all
self-service
based
they
depend
on
these
community
crds
for
their
consumption
developers
want
to
create
instances
on
demand.
They
do
not
want
to
open
a
ticket
and
wait
for
an
instance
to
be
created
for
them.
B
So
these
are
all
things
that
come
up
as
differentiators
for
these
newer
types
of
services
that
we
see
in
the
enterprise
and
lastly,
these
are
used
by
a
lot
of
these
and
newer
applications.
So,
almost
always
when
we
see
modern
applications,
we
see
these
services
right,
and
this
is
just
a
number
slide
that
talks
about
the
number
of
these
applications
significantly
increasing
in
the
near
future.
B
By
some
accounts,
we
see
that
we
will
have
around
half
a
billion
applications
in
the
next
few
years,
and
the
the
I.t
spending
is
more
skewed
towards
the
individual
application
teams
right
and
they
have
a
higher
say
in
what
type
of
platform
is
deployed.
So
vmware
recognizes
this
trend
and
we
have
both
organically
and
inorganically
invested
in
making
the
modern
application,
development,
kubernetes
application,
development,
easier
and
seamless
on
on
our
platform
right.
B
So
this
is
just
a
slight
talk
about
what
the
challenges
are,
so
what
we
see
is
developers
would
like
to
use
their
existing
knowledge,
their
toolkits.
They
would
like
to
use
kubernetes
concepts
to
consume
storage,
deploy
storage
without
having
to
without
having
to
do
it.
Do
it,
in
a
manual
fashion,
deploy
virtual
machines
for
these
services
right
and
the
challenges
that
they
face
today?
Is
that
you
know
all
of
this
is
manual.
B
They
have
to
rely
on
virtualized
instances
of
these
applications
and
deploy
and
manage
that
themselves
right,
which
leads
to
an
increased
development
life
cycle
and
for
administrators.
The
problem
is,
they
are
not
able
to
offer
that
cheaper
tco
for
operating
object
stores
or
any
such
applications
on
on
our
platform,
right,
primarily
because
we
require
the
replication
to
be
turned
on
on
the
on
the
storage
layer,
as
well
as
the
service
layer,
even
though
the
services
offer
availability
themselves
right
so
that
that
is
that
is.
B
So
when
we,
when
we
look
at
how
an
ideal
solution
would
look
like
what
comes
up
is
we
require
that
a
self-service
for
developers
similar
to
the
to
the
public
clouds?
We
need
a
quorum
set
of
services
to
be
available
for
a
development.
Like
object,
stores,
cassandra
and
a
few
other
services
that
are
critically
needed
by
these
application
developers,
they
need
that
to
be
available
on
the
on
the
vsphere
platform
as
well,
and
they
require
that
support
from
the
it
teams.
B
On
the
on
the
vsphere
admin
side,
they
would
like
to
leverage
their
existing
skill
sets
to
monitor
and
manage
newer
applications,
and
it's
all
about
unified
management
right,
so
utilize.
Your
existing
clusters
to
also
manage
newer
services,
and
when
it
comes
to
the
platform,
we
would
like
to
extend
all
of
the
existing
security
performance
availability
of
the
vsphere
platform
to
these
modern
services
as
well
and
last,
but
not
the
least.
B
B
B
We
need
that
introspection
into
the
different
vsphere
operations
and
vc
with
tanzo
gives
us
that
capability
right
and
data
persistence
platform
which
we
launched
is
bringing
these
two
worlds.
Together.
We
are
integrating
the
kubernetes
operators
on
the
tanzo
framework,
but,
more
importantly,
this
is
a
key
piece
of
ip
that
we
offer,
which
is
that
optimal
tco
for
services
when
they
run
on
the
platform.
B
The
the
idea
here
is.
We
are
now
waiving
the
requirement
to
replicate
on
the
storage
layer
if
the
service
is
already
offering
the
data
availability
in
its
layer
right
so
object,
stores
and
all
of
these
other
services
offer
erasure
coding
and
other
availability
schemes
which
are
more,
you
know,
suited
to
the
application
requirement
closer
to
the
application
requirement
than
the
cookie
cutter
availability
model.
A
Want
to
be
careful
here
because,
given
this
is
the
cncf
user
group
that
we
avoid
turning
this
into
a
vmware
product
pitch
if
people
deployed
these
scale
out
applications
using
standard
pure
upstream,
open
source
tools,
you
know
there
are.
There
are
the
standard
operators
that
get
bundled
with
these
packages,
as
well
as
held
charts
and
maybe
higher
form
things
like
the
open
source
cube
apps.
Can
you
point
out
what
level
of
visibility
that
gets
delivered
here
for
discovering?
B
Sure
sure
I
can
I
can
talk
about
it
right,
so
so
the
vsphere
with
tanzo
today
you
can
run
any
communities
application
on
panzo
right,
so
that
is
that
is,
that
is
that
is
possible
today.
So
the
what
we
are
doing
here
is
again
to
be
very
honest
and
clear.
We
do
not
support
the
open
source
on
this
platform
as
of
7.
update
one,
so
this
is
only
for
the
the
enterprise
operators.
All
of
these,
so
we
are
announcing
partnerships
with
all
of
these
partners
who
have
a
communities
operator.
B
B
Yes
right,
but
yes,
steven,
I
think
you
bring
up
a
good
point
right.
So
this
is
my
my
point
in
talking
about
data
persistence
platform
is
more
to
say
that
you
know
if
you
have
modern
applications
that
are
running
on
any
kubernetes
distribution
and
they
have
a
need
for
an
object,
store
or
any
other
cassandra
kafka
application.
B
We
have
now
provided
a
way
for
these
modern
applications
to
consume
them
on
vsphere
right,
so
it
was.
It
was
in
that
context
that
I
wanted
to
talk
about
data
persistence
platform
and
not
not
as
a
product
pitch
honestly.
That
was
not
what
I
had
in
mind,
but
what
we
are
doing
to
offer
object,
stores
or
other
applications
to
such
applications.
That
was
my
intent
here.
Right.
D
So
are
what
are
the
are
there
plans
to
also
allow
this
configuration
in,
like
just
the
open
source?
You
talked
about
even
even
those
open
source
products.
You
talked
about
it's
their
enterprise
configuration
that's
supported
like
where,
where
are
we
looking
from
the
open
source
side
of
supporting
those
features.
E
B
Actually,
just
to
clarify
on
that
point
there
we
require
the
data
persistence
platform
requires
the
visual
with
tanzu
part
service,
which
requires
in
turn
requires
nsx
right,
and
the
reason
we
are
showing
vcf
here
is
that
vcf
brings
in
all
of
it
together
very
seamlessly.
So
it
has,
we
said
with
tanzo
visa
enterprise
and
nsx.
That
is
packaged
very
well
with
vcf,
but
nothing
stops
anybody
from
taking
these
individual
components
and
deploying
it
and
getting
getting
part
service
right.
So
we
don't
mandatory,
require
it,
but
it
gives
us
a
good
packaging.
B
G
This
is
from
a
technical
perspective,
maybe
just
a
little
step
back,
I'm
just
I'm
just
wondering
what
the
kind
of
data
management
scenarios
exist
that
that
you're
trying
to
address
with
this.
So
you
spoke
a
few
slides
earlier
about
data
data
replication
scenarios
that
the
cookie
cutter
model
of
vsan
might
not
be
ideal
for
in
a
modern
apps
context.
G
A
Well,
hopefully,
this
isn't
too
simplistic,
but
as
an
example,
there
are
some
of
these.
Let
me
call
them
software
defined
stateful
services
like
us,
cassandra
that
already
implement
some
form
of
redundancy
for
resiliency
up
at
the
software
layer
and
if
you
layer,
those
on
top
of
storage
that
assumed
that
it
also
had
to
implement
redundancy
you're
sort
of
paying
the
cost
of
dual
layers
of
redundancy,
which
might
be
overkill
so
by
by
kind
of
enabling
visibility
that
this
upper
layer
is
already
willing
to
buy
off
resiliency
redundancy
replication
across
nodes.
A
You
can
perhaps
send
the
signal
to
the
underlying
storage
that
hey,
maybe
I
know
your
default
way
of
operation-
is
to
store
things
in
at
least
three
places,
but
you
don't
have
to
for
this
now
go
paulo.
Maybe
you
can
address
whether
I'm
going
the
right
direction
there,
but
I
think
that's
what
we're
getting
at
yeah.
B
So
so
yeah,
so
all
of
these
services
that
we
talked
about
right
all
of
these
services,
like
kafka,
cassandra
object
stores
they
all
are
offering
their
own
availability.
There
is
a
reason
we
call
them
shade
nothing
services
and
specifically,
for
instance,
erasure
coding
right,
so
customers
can
turn
on
different
modes
of
initial
coding.
That
is,
that
is
good
for
them.
From
a
from
a
performance
and
a
cost
standpoint,
they
can
choose
one
of
the
erasure
coding
methods
and
also
from
how
many
failures
they
want
to
tolerate
right.
B
So
it's
very
prescriptive
when
it
comes
to
using
these
different
erasure
codes
and
when,
when
they
have
chosen
minor
or
when
they
have
chosen
any
such
service,
they
want
to
use
their
azure
coding
and
that's
why
they
go
with
a
particular
object
store
and
what
we
are
doing
with
this
is.
We
are
just
giving
the
ability
for
min
io
to
say,
hey
look.
This
is
this
is
the
instance.
B
My
instance
runs
on
this
particular
node,
and
I
want
storage
to
be
coming
in
from
that
same
node,
right
that
storage,
compute
locality,
is
what
we
are
providing
with
this
platform,
and
that
is
it
right.
So
we
do
not
expect
anything
else.
We
just
give
them
that
storage,
compute,
locality
and
those
services
are
now
free
to
go
and
provision
storage
as
they
please,
as
they
see
fit
right
and
all
of
the
resiliency
availability
comes
from
the
service
and
not
from
the
underlying
storage.
G
Okay,
so
just
to
to
double
up
on
my
understanding
of
it.
If
that's
okay,
what
I
would
normally
do,
I
mean
we
run
mineo
right
now,
but
we
don't
have
vsan
under
under
it.
If
I
were
to
have
vsan
under
under
our
minion
clusters,
I
would
set
a
storage
policy.
That
said,
look
you
don't
need
to
do
erasure
coding,
you
don't
need
to
do
mirroring
on
these
volumes.
G
A
Exactly
or
I
think
maybe
what
we're
getting
at
is
you
don't
you
don't
have
to
do
a
manual
override
or
configuration
that
it
might
just
happen
automatically
that
the
operator
is
aware
of
it
and
does
the
right
thing?
You
know
it's
not
it's
not
that
it
wouldn't
work.
If
you
didn't
do
double
encoding,
but
maybe
you're
throwing
money
away
that
you
don't
have
to
there.
C
Is
more
to
it
as
well
robert
in
that,
if
you
just
set
a
vsan
policy,
for
example,
to
ftt
0,
you
turn
off
replication,
but
you
don't
necessarily
get
compute
storage
locality.
They
aren't
necessarily
on
the
same
hosts.
So
you
end
up
with
uncertain
failure.
Domains
and
another
part
of
this
additionally,
is
the
operators
are
actually
tied
into
vsphere
operations.
So
if
you
put
a
host
into
maintenance
mode,
it
will
tell
the
application.
This
host
is
going
away.
There's
one
copy
of
data.
C
There
move
the
data
off
that
particular
disk
off
that
host,
do
whatever
you
need
to
do
with
the
app
player.
So
there
is
a
much
more
integrated
level
of
interaction
between
vsphere
and
the
app
in
these
cases,
and
while,
yes,
you
might
be
able
to
get
away
with
it
just
doing
ft20
and
telling
it
to
turn
off
the
replication,
you
don't
get
the
locality,
which
is
really
critical
from
like
a
failure.
B
And
that's
right
so
that
vsan
sma
mode
will
now
allow
all
of
these
benefits,
or
rather
configuration
like
miles
mentioned
in
a
completely
automated
fashion.
Right
and
I
pinged
the
link
to
our
vmworld
talk,
wherein
we
actually
show
minio
being
deployed
on
vsan
by
turning
off
the
replication
and
how
we
automate
a
lot
of
these
deployment
management
and
life
cycle
tasks.
Right.
B
B
To
paula,
maybe
a
time
limit
about
five
minutes:
yeah
I'll
just
take
two
minutes
for
this,
so
so
so
vcenter
configuration
alongside
vsan
sna,
which
is
turning
off
the
replication
and
providing
the
placement
control,
also
lets.
Now,
customers
directly
go
and
deploy
these
services
to
the
underlying
direct,
attach
hardware
like
cheap
and
deep
hard
disks
or
performance,
ssds,
etc
right.
So
the
idea
here
is
like
we
discussed
when
you
do
not
have
the
need
to
replicate
on
the
on
the
storage
layer.
B
B
We
still
have
this
vmfs
file
system,
which
is
vmware's
a
file
system
for
for
local
devices
vmfsl.
So
we
still
have
that
file
system
deployed
on
these
devices.
But
now
we
extend
all
of
the
management
benefits
that
simplified
deployment,
cloud,
consumption
models,
operations
etc
to
these
direct
attached
devices
as
well.
So,
from
a
from
a
deployment
standpoint,
now
you
have
a
choice
of
either
using
visa
and
sna.
B
Where
you
turn
off
the
application,
you
get
the
placement,
control
or
vsan
direct,
and
you
can
get
that
tco
and
storage
efficiency
of
of
the
underlying
hardware
devices
so
yeah.
So
that
was
the
other
option
that
we
have
introduced
here
so
yeah.
So
that
brings
me
almost
to
the
end
of
my
presentation.
Like
I
mentioned,
this
was
a
high
level,
so
please
feel
free
to
reach
out
to
me
I'll,
provide
my
email
address
for
any
further
discussions.
D
C
Yeah
go
ahead
copy
yeah.
So
with
regard
to
like
the
pure,
open
source,
vanilla,
csi,
we
added
a
lot
of
stuff
in
prep
for
migrations,
so
vcp
to
csi.
Migration
was
added
in
there
it's
in
beta
state
at
the
minute.
So
if
you
have
1.19
or
above
and
the
new
version
of
the
csi
driver,
then
you
can
try
the
vcp
to
csi
volume
migration,
which
will
do
it
both
at
the
platform
level,
as
well
as
the
kubernetes
level.
C
So
we'll
insert
the
web
hook,
shim
that
we
were
talking
about
in
a
previous
meeting
to
translate
all
the
calls
that
would
go
to
vcp
and
make
some
work
through
csi,
but
it'll
also
take
the
existing
volumes
and
convert
them
from
standard
vmdks
into
these
first
class
disks
and
sort
of
adopt
them
into
cns.
So
that
requires
some
code
changes,
so
that
was
in
7.0
u1
and
the
new
version
of
the
csi
driver.
So
that's
that's
what
we
added
from
a
vanilla,
open,
source
perspective.
A
D
Okay,
so
for
those
of
everyone,
that's
out
there,
that's
currently
using
the
cloud
providers,
you
kind
of
need.
Both
I
mean
you
need
to
get
first,
get
your
vsphere
version
updated
and
then
you
can
then
work
to
get
your
kubernetes
version
upgraded
and
then
is.
Is
there
a
documented
process
on
that
conversion.
C
Yeah,
it's
it's
on
the
csi
github!
There's
a
dock!
That's
in
there!
That's
like
a
work
in
progress
dock
and
it
gives
an
example
of
how
you
would
move
the
volumes
over
you.
Essentially
you
give
them
an
annotation
and
then
you
kick
off
flow
and
away.
It
goes,
and
it
does
its
thing,
but
yeah
you're
right.
You
would
go
to
7.0
u1.
First,
you
get
your
kubernetes
distributions
up
to
119,
make
sure
you're
on
the
new
csi
driver,
and
then
you
can
follow
the
process.
That's
in
there.
C
Yeah
we've
been
chatting
with
google
on
that
as
well,
and
basically
they
don't
want
to
remove
the
vcp
until
such
a
time
that
they
and
we
agree
that
the
migration
path
is
indeed
stable.
It
is
something
that
is
fully
supportable
has
no
bugs
whatever
you
know
the
way
that
we
do
things
in
kubernetes.
We
don't
want
to
deprecate
stuff
and
not
leave
and
leave
anyone
stranded.
So
it
looks
like
currently,
if
we're
tracking
stable
for
1.21
something
like
that.
It's
probably
going
to
be
1.22
if
it
is
indeed
stable
by
1.21.
D
A
Yeah,
there's
probably
still
time
to
voice
your
opinion,
which
I
realize
you're
doing
now
and
on
your
behalf,
at
a
cloud
provider
meeting
I'll,
certainly
pass
that
along.
It
isn't
just
our
decision.
There's
a
cloud
provider
sig
and
they're
kind
of
doing
this
as
a
blanket
effort
across
all
the
cloud
providers,
not
just
the
vsphere
one.
A
So
you
might
be
safe,
but
I
can't
guarantee
it.
I
can
pass
along
word
and
I
think
you
know
there's
differences
of
opinion
where
enterprises
tend
to
face
more
of
these
issues,
but
sometimes
some
of
these
thinner
organizations
can
move
more
quickly
but
yeah.
It's
it's
tough.
The
I
think
the
official
rule
on
kubernetes
is
that
they
do
promise
to
give
a
deprecation
warning
of
at
least
a
year,
but
I
think
they
view
that
they've
already,
given
the
warning
that
something's.
D
F
I
think
steven
kind
of
hit
hit
it
on
the
head.
Walmart's
scale
is
completely
different
than
any
other
one
that
you'll
find
in
the
environment
with
all
the
different
things
and
pieces.
We
have
running
that
when
and
basically
going
with
what
bryson
said.
I
think
two
versions
would
be
better
than
just
one
after
having
a
stable
path.
D
A
Let
me
make
this
commitment
miles
and
I
will
be
advocates
for
that
position,
but
we
don't
have
solid
control
over
this
I
mean
it.
There
are
others
involved
in
the
decision,
so
I
think
that
we
appreciate
the
the
the
need
to
allow
time
for
people
to
migrate,
but
since
it
isn't
under
my
direct
control,
I
can't
make
it.
I
can't
make
a
promise.
C
F
In
the
store
environment,
we
are
running
67u3,
so
that
would
be
feasible,
but
we're
not.
We
don't
have
that
running
everywhere.
Wayne
yeah
that
that's
the
thing
in
the
store
environment
we
do
in
the
dc
environment
in
the
home
office,
environment
and
I'm
not
sure
what
they're
running
in
the
the
ecom
environment,
but
in
all
those
other
areas,
if
they're
not
on
it,
then
it
wouldn't
be
because
each
of
the
different
areas
we
have
our
own
teams
that
are
basically
dedicated
to
it.
I
personally
am
on
the
store
team.
F
C
F
B
B
C
A
C
A
A
We
just
want
to
be
open
and
also
provide
a
venue
for
feedback
so
that
the
right
thing
happens
here,
but
we're
hearing
what
you're
saying
we'll
be
advocates
for
supporting
people
on
kubernetes
on
our
platforms,
both
within
vmware
product
planning
and
because
we
have
people
sitting
inside
the
kubernetes
sig.
So
we'll
we'll
do
our
best
and
we'll
keep
you
advised
of
how
it's
going.
I
guess
that's
the
that's
the
commitment
it
can
make.
A
Okay,
I'll
take
silence
as
nothing
but
as
always
on
the
slack
channel
feel
free
to
do
any
late
ads
gopala.
If
you
can
provide
me
a
link
to
this
deck,
I
will
put
it
into
the
agenda
notes
document,
so
people
can
have
access
to
it
and,
with
that
said
I'll
close
the
meeting
thanks
everybody
for
attending.