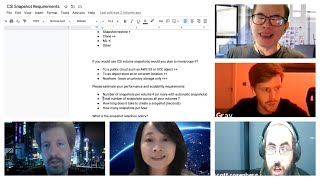
►
From YouTube: Kubernetes UG VMware 20210304
Description
March 4, 2021 meeting of the Kubernetes VMware User Group. Discussion of CSI, snapshots and other topics related to storage, disaster recovery, stateful app management in the context of running Kubernetes on a vSphere platform.
A
Hi
welcome
to
the
march
4th
meeting
of
the
kubernetes
vmware
user
group.
At
today's
meeting.
The
last
I
looked,
we
had
one
item
on
the
agenda
and
that
is
that
we're
having
a
visit
from
a
couple
guest
speakers
who
are
authorities
on
the
subject
of
snapshots,
both
as
reflected
in
the
kubernetes
apis,
the
container
storage
interface
plug-in
system
and,
ultimately,
if
the
storage
plug-in
is
vsphere,
the
csi
plug-in
itself
for
the
in
the
form
of
a
particular
implementation
for
vsphere
supported
storage.
A
B
A
B
B
So
what
do
you?
What
do
you
use
that
for?
Do
you
use
that
as
a
backup
solution?
Are
you
using
a
some
backup
software
that
depends
on
the
snapshot
or
you
are
just
want
to
you?
Create
you
want
to
take
a
snapshot,
and
then
you
want
to
revert
using
that
or
you
want
to
clone
from
that,
or
this
is
just
for
testing
development.
B
A
A
B
A
On
the
subject
of
csi
snapshots.
Is
there
anybody
by
the
way,
who
doesn't
even
know
what
a
csi
snapshot
is
I
mean
I?
I
don't
want
to
assume
that,
but
the
idea
is
that
for
stateful
apps
running
under
kubernetes
they
would
typically
not
use
storage
directly
in
a
docker
container.
These
would
be
volume
mounts.
A
So
the
idea
of
a
snapshot
is
that,
underneath
these
volume
mounts
there's
typically
a
hardware
implementation
and
in
enterprise
it
these
storage
hardware,
implementations
usually
have
acceleration
features
to
create
a
recoverable
point-in-time
snapshot
of
that
volume
that
can
be
recovered
more
or
less
instantaneously,
or
at
least
in
a
matter
of
seconds.
So
csi
has
an
interface
that
would
trigger
these
snapshots
being
captured
so
just
to
keep
just
in
case
somebody
didn't
know
what
we're
talking
about
here.
B
A
And
then,
and
just
as
background,
I
hope
I'm
not
talking
down
to
anybody
here,
but
the
reason
that
you
might
want
to
move.
It
is
certainly,
if
you're
doing
this
for
backup
a
snapshot
by
itself
is
generally
held
in
the
same
primary
storage
that
you've
been
using
in
production,
so
that
if
you
had
a
hardware
failure,
keeping
it
there
is
going
to
lose
both
the
running
copy
as
well
as
the
snapshot.
A
C
Yeah
so,
okay,
so
I
mean
I'm
still,
you
know
pretty
green
on
kubernetes
and
the
customers,
I'm
working
with
they're,
not
they're
not
doing
much
with
kubernetes
yet
so
I
I
I'm
not
I'm.
I
don't
really
see
many
container
native
use
cases
yet
around
these
snapshot
needs
right
now,
a
lot
of
people
just
assuming
you
can't
do
it,
so
they
don't
make
that
assumption
in
in
the
applications,
at
least
what
I've
seen.
C
But
if
I
take
this
back
to
my
experience
from
kind
of
vsphere
admin
stuff,
usually
the
usual
use
case,
I've
seen
for
snapshots
around
vms
is
is
when
people
are
doing
upgrades
it's
it's
it's
not
even
it's
not
even
usually
the
the
data
or
the
the
the
mutability
of
the
data
around
the
application.
They're
worried
about
it's
the
configuration
of
the
application.
C
That's
where
I've
seen
snapshots
used
mostly
when
you're
doing
an
upgrade
of
the
version
of
the
software.
The
software
is
installed
on
the
vms.
You
know
it's
very
easy
to
make
a
snapshot,
because
if
something
goes
wrong
with
the
upgrade
you
simply
roll
back
and
you
have
your
old
version
of
the
application
again,
but
that
entire
way
of
working
is
already
completely
different
with
containers.
Because
you
know
the
version
of
the
software
you're
running
is
controlled
by
the
container
image,
so
so
that
whole
problem
already
went
away
with
containers.
A
Yeah,
so
it
is
a
little
different
and
you're
right
about
that
being
a
very
common
use
case
for
snapshots.
In
fact,
I've
seen
a
lot
of
the
docs,
including
docs,
for
vmware
products,
actually
advise
you
to
take
a
snapshot
before
you
do
the
upgrade
just
so
that
you
can
recover,
and
that's
the
one
where
it
pops
to
the
top.
A
The
data
off
of
volume
could
take
an
hour,
and
maybe
the
beginning
of
the
volume
corresponds
to
a
different
point
in
time
from
the
end
of
the
volume.
By
the
time
you
read
it
and
the
net
result
is
that
backup
would
probably
be
trash,
because
it's
taking
parts
of
that
disk
image
at
a
different
point
in
time
from
others,
and
you
could
have
things
as
ugly
as
the
index
table
on
a
file
system
doesn't
actually
match
the
data.
A
Well,
some
trigger
is
signaled
to
the
back
end
storage
to
say,
make
it
make
a
stable
image
of
all
of
this,
and
then
that
backup
is
taken
from
the
stable
image
not
directly
from
the
running
copy,
so
essentially
every
backup
product.
I'm
aware
of
does
this
under
the
covers,
but
you
might
be
oblivious
to
it,
just
because
the
abstraction
provided
by
the
backup
product
hid
this
so
well
that
you
weren't
even
aware
that
it
was
going
on
now.
A
It
turns
out
that
these
csi
snapshots
are
specifically
made
for
the
container
world,
where
these
volumes
are
a
little
different
from
vms.
In
legacy.
Vsphere
vms,
a
snapshot
was
actually
a
snapshot
of
a
vm
so
that
vm
might
have
three
drives,
but
the
snapshot
process
it's
your
option,
but
it
could
have
even
captured
the
memory
inside
that
vm
as
well
as
all
the
disks
it
was.
You
didn't,
have
individual
atomic
access
to
one
drive
at
a
time.
You
were
doing
the
entire
vm,
whether
you
wanted
everything
or
not.
A
Now
that
said,
there
were
ways
you
could
opt
out
certain
volumes,
but
the
default
in
vsphere
when
you
snap
a
vm.
Is
you
get
everything
with
best
practices
in
the
container
world?
Some
of
these
volumes
might
be
ephemeral,
meaning
you
don't
want
them
recovered
or
they're
not
considered
desirable
to
incorporate.
A
So
the
csi
process
envisions
individual
control,
all
one
volume
at
a
time
and
they're
disassociated
with
vms
and
that's
an
important
concept,
because
the
vm,
if
you're
running
kubernetes,
is
really
a
kubernetes
cluster
node,
it
could
be
running
a
dozen
pods.
At
the
same
time,
you
would
actually
never
want
to
back
up
at
a
vm
level,
because
you'd
be
you'd,
be
touching
storage
associated
with,
I
don't
know
a
dozen
random
pods
and
you're
fishing.
A
Other
thing,
let
me
mention
is
that
I
think
if
you're
going
to
move
stateful
apps
like
sql
database
servers
to
kubernetes
having
this
facility
is
essential.
I
mean,
if
you
don't
have
it,
I
don't
think
you
can
back
them
up,
but
certain
other
stateful
apps
that
are
cluster,
aware
things
like
cassandra
that
have
their
own
cross,
node
replication.
B
D
So
I
I'm
assuming
that's
what
you're
I'm
curious,
what
you
mean
by
backup
use
case
if
you're
just
saying,
if
you're
exactly
what
you
mean
by
that,
but
for
my,
what
I
would
see
is
like
using
it
as
a
backup
there's
a
lot
of
things.
We
keep
in
a
persistent
volume,
that's
more
of
a
cache
not
like
vital
to
have
it
but
it.
But
if
I
can
restore
it
that
means
I
don't
have
to
re
resend
all
the
stuff.
So
that
goes
down
to
like
your.
D
The
kind
of
like
an
opportunistic
store
type
thing
bryson
that
that
would
be
more
like
hey,
so
there's,
there's
kind
of
two
use
cases
for
that,
like
hey,
if
there
was
an
issue
and
with
vsan
and
everything
was
lost,
it'd
be
nice
to
have
it
somewhere
else,
on-prem
to
be
able
to
help
restore,
but
then
most
of
the
time
we
don't
have
issues
like
that.
But
we
may
have
an
issue
where
we
lost
it's
just
easier
to
rebuild
a
cluster.
D
So
I
think
we
probably
like
you
know,
maybe
both
options
there,
yeah
I'd
say
on
on-prem
is
just
because
for
us
we
have
a
lot
of
remote
locations,
and
so
that's
why
that
backing
up
that
cache
matters
because
yeah
we
can
always
re.
We
can
always
create
that
cache
again,
but
that
takes
time
and
bandwidth.
A
B
Yeah,
so
I
think
that
you
can
actually,
if
you're
familiar
with
velara,
you
can
use
valara.
We
do
have
a
velara
vsphere
plugin
that
works
with
velara.
So
the
existing
solution
does
not
use
css
snapshot,
but
it
does
take
a
snapshot
and
then
upload
that
data
to
an
object
store.
But
you
are
talking
about
a
on-prem
solution.
So,
for
example,
we
do
have
integration
with
powerprotect,
so
that
can
actually
get
get
backed
up
to
powerprotect
the
backup
device.
So
that
would
be
on
one
type
of
backup
solution.
B
D
So
one
day,
so,
like
here's,
here's
a
use
case
where
we've-
let's
say
let's
say
we
have
a
lot
of
clusters.
So
let's
say
we
got
several
version
of
kubernetes
behind.
Sometimes
it's
easier
to
just
rebuild
the
cluster
with
the
newest
version
than
to
go
multiple
upgrades,
and
so
what
we've
used?
One
thing
we've
done
in
the
past
with
that
pv,
so
we
don't
have
to
rebuild
that
cache
is
disconnect
the
v,
the
pv
from
the
vm.
So
when
we
tear
it
down
the
pv
stays
existing
in
a
v-stand.
D
B
D
D
A
D
D
B
D
B
D
B
D
B
Because
I
was
talking
about,
we
have
the
power
product
integration,
but
I
was
thinking
if
you
don't
have
that
I
was
going
to
say
we
have
the
like
on
pacific.
We
have
the
position
service
right.
We
have
like
menio
that
type
of
object
store,
that's
kind
of
on-prem,
but
that's
some
specific
right.
If
you're
using
vanilla,
then
that's
not
there.
A
B
A
B
D
B
D
A
Just
a
little
more
background
for
those
who-
I
don't
know,
I've
had
a
long
background
in
this,
because
I
worked
on
backup
appliances
at
multiple
points
in
my
career.
But
the
way
this
goes
on
under
the
covers
is
that
the
snapshots
are
usually
what
they
call
copy
on
right.
Where,
when
you
say
I
want
a
snapshot,
the
disk
is
just
left
intact,
but
they
put
another
layer
saying
that
any
writes
that
occur
after
this
snapshot
has
been
designated.
A
I'm
going
to
start
writing
a
delta
file
and
the
delta
file,
then,
is
viewed
as
a
layer
that
goes
on
top
of
the
original
untouched
data
volume
in
physical
storage,
and
they
can
build
up.
So
you
could
have
three
or
four
or
20
plus
snapshots,
but
there
are,
there
really
is
a
limit
of
how
many
you
want
left
around,
because
each
time
you
create
one
of
these
delta
layers.
A
When
you
do
reads
on
that
volume
in
your
running
copy,
it
has
to
go.
First,
look
whether
any
deltas
exist
see
if
there
has
been
a
change
logged
on
top
of
the
original
base,
level
volume
and
the
bottom
line.
Is
it
slows
down
your
I
o
operations,
you
get
lower,
lower
and
lower
max
iops,
the
more
snapshots
you
have
in
existence
and
that's
the
reason
I
think
in
this
poll
there's
this
question
about.
A
A
The
questions
about
whether
you
want
them
automatic
is
they
are
convenient
because
it's
way
quicker
to
restore
from
a
snapshot
of
fast
primary
storage
than
it
is
to
record.
Even
if
you
operated
your
own
mineo
server.
S3,
like
the
I
o
speed
going
in
and
out
of
that
thing
is
much
lower
than
primary
storage,
which
is
going
to
be
an
ssd
these
days,
so
that
you
maybe
want
a
handful
of
these
snapshots
to
exist
for
rapid
recoveries
of
recent
images,
but
maybe
for
ultimate
dr
purposes.
You
also
want
to
supplement
it
with
a
little
more.
E
A
A
E
The
open
source
one
it
is
it's
using
stat,
mirror
there.
So
I'm
definitely
and
in
those
cases
like
netapp,
has
a
limit
of
over
a
thousand
snapshots
per
copy,
because
there's
differences
when
you're
talking
about
a
volume
versus
the
snapshotting
of
a
vm
in
the
way
that
it
works
and
the
technologies
for
snapshots
are
different.
E
E
I
know
a
lot
of
it
is
also
for
tools
like
valero
cast
in
and
all
that
that's
been
talked
about,
but
what
we
see
by
a
lot
of
our
customers
is
for
both
cloning
and
test
dev,
easily
being
able
to
take
a
snapshot
of
the
production
environment
and
then
restore
that
into
another
namespace
in
order
to
allow
you
to
go
and
debug
an
application
or
to
easily
copy
over
the
data.
Basically,
so
you
can
then
create
a
new
pv
from
that
snapshot
and
start
testing.
D
Shane,
just
on
the
use
cases
I
I
know
this
one
isn't
listed
specifically,
and
maybe
it
falls
under
clone
and
test
dev,
but,
for
example,
customers
that
are
building
ml
models.
The
model
itself
usually
needs
revision
control
and
that
that
is
essentially
your
ip
right
and
generally,
if
you're
spinning
up
something
like
that
for
data
scientists
to
work
on,
you
have
a
model
and
you
want
to
clone
that
particular
version
of
the
model
light
for
them
to
test
on
and
that
kind
of
thing.
D
So
I
I
think,
that's
probably
another
use
case,
that's
worth
calling
out,
but
then
it
raises
another
question
which
is
also
related
to
the
number
of
snapshots
per
volume,
which
is.
Is
this
like
intended
to
be
a
universal
point
in
time
type
thing,
or
this
there's
going
to
be
like
a
finite
number,
and
you
can
only
call
back.
You
know
those
snapshots
in
in
that
tree
rather
than
I
want.
You
know
this
specific
version
and
you
get
that
version
back.
D
B
Well,
you
should
be
able
to
choose
which
one
you
want,
but
there's
just
right
now,
there's
a
limit
on
the
car
there's.
The
current
limit
is
32
for
per
fcd,
but
I
think
we
are
looking
at
whether
to
expand,
expand
that
to
increase
the
limit
yeah.
You
should
be
able
to
use
the
the
ones
in
the
middle.
It's
not
like.
You
can
use
the
last
one
or
something
like
that.
D
Yeah
I
mean
there's
some
specific
solutions
out
there
that
that
cater
exactly
for
that
revision,
control
of
of
the
the
models
and
stuff
like
that
on
the
clone
use
case.
That
would
be
to
pick
a
snapshot
and
do
a
full
clone
from
that
snapshot
into
another
thing,
and
that's
that's
essentially
a
fresh
slate.
So
is
that
my
correct
number
yeah.
B
E
E
A
B
A
Talk
to
it,
one
of
the
things
that
happens
if
snapshots
get
out
of
hand
too,
is
even
suddenly
a
desire
to
catalog
them.
Where
you
discover
that
hey
I've
got
20
of
these
snapshots
here,
I
don't
even
know
who
created
them
and
I'm
afraid
to
delete
it,
because
if
I
don't
know
who
did
it
or
why
I
get
insecure.
A
So
I
don't
know
if
anything
being
proposed
plans
to
address
a
catalog.
But
the
moment
you
allow
more
than
a
handful.
That's
probably
a
valid
ask
that
some
system
be
in
place
to
both
catalog,
the
purpose
and
owner
and
maybe
even
impose
access
control,
because
I've
seen
in
the
backup
world
a
common
scenario.
People
don't
worry
about
initially,
but
sooner
or
later
is
going
to
bite
them
is
that
backups
take
place
of
in
the
old
days.
A
Vms
and
people
unleashed
backup
systems
that
assigned
these
backups
to
individual
users,
but
over
a
long
enough
point
period
of
time
that
user
could
leave
the
organization,
so
a
backup
got
assigned
to
somebody
who
left
the
company.
But
if
the
permissions
were
tied
with
this
now
ghost
person,
you've
got
a
problem.
B
A
Yeah,
so
you
know
the
poll
is
an
attempt
to
sort
of
organize
a
wish
list.
Questions
concerns,
but
if
any
of
you
have
things
that
have
just
been
bugging,
you
lately
or
you've
thought
of
ideas
for
things
that
would
greatly
help
things
out
or
just
even
comments
on,
where
you're,
finding
the
documentation
or
your
ability
to
learn
how
these
things
work
are
difficult.
C
So
so
one
of
one
of
the
things
that's
motivating
my
first.
My
first
question
is:
there
were
very
good
reasons
that
that
in
the
vsphere
world,
you
could
not
rely
on
snapshots
as
being
a
backup
mechanism
in
and
of
itself
the
performance
hit,
the
the
way
they
worked
pretends
to
risk
to
to
the
data,
especially
when
you
know
you've
got
a
lot
of
you
know
deltas.
There
was
a
lot
of
ongoing.
C
I
o
it
was
that
very
reason
that
that,
in
my
experience
you
many
people
stopped
trying
to
make
snapshot
backups
of
things
like
sql
servers
and
oracle
servers,
because
the
continuous
io
was
just
too
much
you'd
get
into
crazy
snapshot
tree
or
delta
situations.
They
would
never
resolve.
You'd
have
to
turn
the
whole
thing
off
to
actually
get
it
to
to
to
merge
all
the
snapshots,
and
that
would
maybe
take
a
day
to
do
now,
as
as
time
has
gone
on
and
storage
has
gotten
faster
and
vsphere
has
improved.
That's
it.
C
That
problem
has
gotten
less
and
less,
but
it
still
exists
today.
So
so
so
my
first
question
when
you,
when
you
make
the
assumption
that
you
can
use
the
csi
snapshot
mechanism
as
a
kind
of
backup
solution
in
and
of
itself,
all
those
questions
come
to
mind
like
how
how
does
it
deal
with
with
deltas?
How
does
it
deal
with
stunning?
How
does
it
deal
with
queueing
of
io?
C
Tell
the
os
I'm
about
to
make
a
snapshot,
so
the
os
would
start
stunning
its
io
streams
to
disk
so
that
you
know
so
you
get
a
clean
state
that
it
could
make
the
snapshot
in
and
then,
if
you
were
microsoft,
you
you
know
running
exchange
on
that
server.
You
made
a
hook
into
that
mechanism,
it's
called
the
vss
mechanism,
then
in
ex
then
you
could
also
give
a
signal
to
exchange
oh
exchange
snapshots
about
to
be
made.
Please
stop
writing.
I
o
in
this
particular
way.
Stun
your
own,
I
o!
C
C
B
So
yeah,
so
the
hook
is
actually
it's.
It
is
not
part
of
the
css
snapshot
feature
itself,
but
we're
actually
working
on.
Another
proposal
in
this
is
in
kubernetes
upstream
called
container
notifier,
which
is
to
allow
you
to
add
some
part
definition
so
that
you
can
actually
say
I
want
to
quiet.
I
want
to
run
this
command
before
taking
a
snapshot,
so
that's
still
ongoing.
Still
in
the
design
phase.
You
know
it
takes
a
long
time
to
do
things
in
your
community,
but
that's
yeah.
B
So,
but
right
now,
if
let's
say,
if
you're
using
lara
lara,
actually
provide
a
way
for
you
to
add
those
kind
of
hooks
so
to
quiet
the
application
before
taking
snapshots,
so
you
can
actually
achieve
that
consistency
that
way
and
yeah
so
yeah
you're
right.
So
I
see
that,
like
your
notes,
right
snapchats
are
not
backups.
It's
correct.
I
think
some
I
think
right
now
there
are
some
people
are
getting
more
confused
because
our
css
snapshot
interface.
B
It's
it's
designed
to
support
all
type
of
storage
systems,
so
that
includes
our
three
systems.
You
know
netapps
pure,
but
also
includes,
like
you
know,
google
gcpd
and
aws
ebs,
those
type
of
storage.
They
behave
very
differently
for
like
aws
evs.
Actually,
when
they,
when
you
take
a
snapshot
there,
it
actually
will
cut
the
snapshot
first
and
then
it
will
actually
upload
that
somewhere
to
to
object,
store
already
just
it's
going
to
take
some
time.
B
Of
course
it's
it's
it's
slow
to
upload,
but
so
for
them
it's
it's
like
this
boundary
between
snapshot
and
backup
got
blurry,
because
their
snapchat
is
actually
backup.
That's
why
many
people
are
confused
after
we
introduce
the
css
snapshot.
They're,
saying
oh,
is
that
what
this
means
to
me,
but
actually,
when
the
css
back,
when
we
introduce
the
cta
snapshot
in
in
the
css
snapshot
spec,
we
mean
to
support
all
types
of
street
systems,
but
that's
why
you
know
we
have
that
question
there.
B
We
don't
know
if
some
people
are
confused.
If
they
are,
you
know,
if
they
want
to
use
it
just
the
same
way
as
aws
dps,
then
they
thought
it's
the
same
way
right.
So
it
looks
like
you
already
know
that
the
vm,
our
our
snapshot
is
local
snapshots.
It's
not
really
a
backup,
it's
actually
yeah,
and
we
know
that
there
are
benefits
for
a
local
snapshot.
It's
quick
when
you,
you
know,
if
you
want
to
revert,
you
want
to
clone
from
it.
D
B
D
A
You
have
to
tell
the
app
hey
flush,
all
this
memory
down
to
disk,
because
I'm
only
making
a
copy
of
the
disk
and
if
you
had
the
latest
data
up
in
memory
only
and
it
hasn't
flushed.
Yet
my
backup
is
no
good,
but
the
there's
a
corollary
to
this.
In
that
many
of
these
apps
like
database
servers,
keep
transaction
logs
and
those
logs,
you
don't
want
them
growing
to
infinity.
You
know
they
for
redundancy.
They
keep
these
logs,
but
the
typical
backup
product
has
always
had
a
secondary
hook
that
takes
place.
A
You
know
the
the
kiosk
is
the
first
stage
you
create
the
volume
snap
you
copy,
the
snapshot
to
external
storage
s3
in
the
old
days,
even
physical
tape,
whatever
then,
once
you
know
and
can
verify
that
this
is
on
tape
or
this
is
on
secondary
storage.
So
I
could
tolerate
a
complete
loss
of
my
storage.
Meteor
comes
from
space
and
obliterates
it
I
can
get
back.
A
Then
you
want
to
signal
to
the
app
saying
it's
safe
to
truncate
your
logs
now,
so
that
your
logs
don't
grow
into
infinity
and
fill
up
all
your
storage
and
so
that
there's
kind
of
a
back
end
signal
too.
Now.
I
believe,
if
you
use
rustic,
that
there's
at
least
the
facility
that
lets
somebody
build
out
both
of
that
initial
and
that
kind
of
finalizer
stuff,
but
it
has
to
be
done
on
an
app
specific
basis.
A
So
nobody
can
kubernetes
itself
doesn't
know
about
the
apps
it's
running,
so
it
actually
doesn't
have
enough
knowledge
to
know
all
the
internal
details
of
where
the
log
files
even
live.
So
that
it
could
truncate
them,
it
doesn't
know
or
even
have
access
to
the
memory
to
cause
it
to
get
flushed
down
to
disk.
So
you
need
these
kinds
of
things
to
be
written
on
an
app-by-app
basis
and
to
have
the
big
picture
implemented.
A
It's
actually
a
tricky
storage
where,
as
a
foundation,
it
has
to
be
enabled
in
the
storage
plug-in
then
in
kubernetes,
but
then
finally,
somebody's
got
to
do
the
actual
work.
That
is
very
much
app
specific
and
that's
probably
going
to
be
the
last
thing
that
ends
up
being
written.
But
so
this
is
a
work
in
progress.
I
suspect.
B
C
B
C
A
I
think
this
will
follow
the
model
that
happened
20
years
ago,
where
that
this
is
exactly
why,
in
the
early
days,
people
thought
you
had
to
run
database
servers
on
bare
metal.
You
couldn't
trust
virtualization,
because
the
snapshot
stuff
wasn't
built
out,
but
eventually
it
got
built
out
to
where
that
became
pretty
much
standard.
99.9
percent
of
the
world
used
it
we're
not
at
that
stage,
yet
in
kubernetes
and
containers.
In
my
personal
opinion,
and
if
you
look
at
the
model
of
how
long
it
took
in
virtualization,
it
didn't
happen
overnight.
A
A
B
There
was
a
proposal
some
time
ago
on
how
to
how
to
take
a
snapshot
of
that
application,
but
right
now
that
one
is
kind
of
unhold,
because
we
also
are
working
on
many
other
things
trying
to
reach
there
so,
including
the
container
notify
that
I
mentioned
earlier.
We
need
to
be
able
to
quiet
the
application
first
and
then
we
can
make
sure
that
we
can
take
snapshot
of
the
application
and
then
that
is
consistent
yeah
so
that
that's
a
kind
of
ongoing
and
then
div
protein.
A
Yeah,
I
think
those
multi-cluster
apps
once
again
are
gonna,
be
ultimately
addressed
on
an
app
by
app
basis.
Some
of
the
apps
even
have
built-in
apis
or
mechanisms
for
doing
backups
and
recovery,
often
going
back
to
the
vm
or
even
bare
metal
worlds.
That
involved
having
a
clustered
app
have
some
number
of
replicas.
You
know,
let's
say
I
don't
know
it's
11
and
a
common
mechanism
was
that
to
do
a
backup
you
throw
a
12th
one
into
the
pool,
either
a
vm
or
a
physical
machine.
A
A
The
concept
is
that
you
extend
your
pool
wider
to
get
some
sacrificial
candidates,
then
you
sever
them
essentially
put
in
place
of
partitioning,
and
no
real
workload
is
being
directed
to
the
partition
now
so
that
it's
stable
and
you
make
a
copy
of
it
and
the
state.
That's
in
with
regard
to
kubernetes,
I
suspect,
is
kind
of
early
days.
C
You
know
you
can
you
can
95
percent
of
backups?
You
can
do
them
using
using
snapshot
mechanism
and
a
standardized
way
of
pulling
their
snapshot
out
using
something
like
valero
or
something
similar.
Then
you'll
always
have
a
bunch
of
apps
that
don't
respond.
Well
to
that
and
same
with
same
with
vms,
you
know,
in
that
case,
you'd
go
back
and
say
well,
look.
C
Does
the
vendor
themselves
have
a
better
backup
solution
for
their
own
product,
and
usually
they
do,
I
think
of
oracle,
for
example,
or
mysql,
or
just
any
database
product
really,
because
those
are
the
ones
that
usually
have
the
issues
with
snapshots,
at
least
from
the
vm
point
of
view.
Of
course
you
know
the
the
entire
necessity
for
doing
snapshots
is
is
a
completely
different
formula
for
kubernetes
apps
anyway,
right
now
the
assumption
isn't
even
there.
C
So
so
the
way
the
you
know,
the
conversations
I'm
having
is
we're
saying
look
just
assume
that
the
data
is,
you
know
that
you
can
save
on
the
primary
storage
could
could
be
lost
if
you
really
have
backup
requirements,
make
sure
to
have
something
in
place
to
offload
it
somewhere
else.
You
know
external
nfs,
external
s3,
something
besides
the
primary
storage,
because
right
now
there's
nothing
on
the
primary
storage
except
you
know
the
the
very
basic
disk
redundancy
it's
going
to
take
care
of
data
availability.
C
B
So
this
is,
I
think,
it's
broader
than
just
building
that
underneath
the
the
the
snapshot
apis,
but
this
could
be
could
be
brought
up
just
we
want
to
get
feedback
and
see
what
do
you
use
or
want
right?
So
I
we
don't
really
have
a
design
for
this
yet,
but
this
is
really
just
together
requirements.
Maybe
we
don't
need
it
that's
quite
possible.
B
C
So
and
that's
been
great
news,
it
simply
simplifies
the
work
of
infrared
and
the
platform
teams
greatly,
because
you
can
make
the
assumption
that
the
that
the
application
developers
and
the
people
running
running
their
application,
architectures
probably
have
a
better
story.
Around
availability
than
you'll
ever
have
for
them.
What's
left
is,
is
those
things
where
they
haven't
thought
about
it.
You
know
and
that's
and
that's
where
you
know
snapshots
become
an
interesting
story
again,
but
but
I
think
the
formula
is
going
to
look.
I
think
the.
A
C
A
A
If
you
think
of
something
or
we
didn't
get
time,
please
throw
it
in
the
slack
channel
or
go
at
the
meeting
agenda,
notes
afterward,
but
I
want
to
thank
everybody
for
attending.
Hopefully,
you
found
this
to
be
useful.
I
also
want
to
reach
out,
for
we
have
these
meetings
every
month.
If
somebody's
got
other
topics,
they
want
to
bring
up-
or
if
you
really
like
this
one
and
want
to
continue
on,
because
you
didn't
think
this
was
granted
enough
time.
We
could
do
that
too,
but
p.
A
B
B
A
And
to
let
you
know
what
you'd
be
getting
into
in
my
experience
I
haven't
been
to
one
for
weeks,
but
those
are
principally
the
actual
developers
and
a
lot
of
vendors
of
backup
and
data
recovery
products,
storage
products.
They
would
love
to
have
more
users.
But
historically,
I
haven't
seen
that
many
users
show
up
at
the.