►
From YouTube: 20200114 Kubernetes WG Multi-tenancy
Description
Regular WG Meeting
- Kubeflow & Multi-tenancy
- Update on secure benchmarks
A
Hi
everybody
and
welcome
to
the
first
multi-tenancy
working
group
for
kubernetes
meeting
of
2020.
Today,
edita
is
going
to
be
going
over
a
cupola
and
the
multi-tenancy
model
from
cupola
and
then,
as
time
permits,
Jim
is
going
to
go
over
some
updates
from
our
multi
from
our
benchmarking
work.
So
I
did
that.
Take
it
away,
hey.
B
So
in
firstly,
introducing
what
queue
flow
is
key
flow
is
an
ml
toolkit
for
kubernetes.
The
goal
is
to
provide
a
platform
for
portable
scale,
machine
learning,
so
most
of
cloud
natives
problem
space
is
similar
to
what
you
solve
for
an
ml
system
ml
platform
as
a
service.
So
suppose
you
have
a
team
of
data
scientists
in
your
company
and
you
want
to
provide
them
with
the
platform
to
use
the
or
get
the
maximum
out
of
the
infrastructure
at
your
company.
B
The
way
you'd
go
for
with
app
development
is
to
go
for
companies
and
for
data
science,
you'd
go
for
cube
flow,
and
so
what
are
the
advantages
that
we
have
with
queue
flow?
Is
that
you
can
kind
of
go
from
local
to
your
cloud
environment
without
any
changes
in
your
work
flow,
so
we'd
have
the
same.
Reproducible
work
flow
from
your
local
machine
to
the
cloud
and
then
and
across
environment
as
well.
B
So
if
you
go
in
from
development
of
a
model
and
you're
experimenting
with
different
model
types
with
different
accuracies
and
different
frameworks,
and
then
you
can
once
you
finalize
the
particular
workflow,
you
can
go
from
your
development
to
your
production
seamlessly
and
currently
there's
a
lot
of
ad
hoc
pipelines
and
stuff
I
use
that
companies
and
keyframes
to
provide
a
standardized
way
of
deploying
models
and
developing
models.
For
that
and
another
thing.
Kubernetes
helps
with
this
scale,
so
yeah.
B
B
Initially,
queue
flow
until
right,
now,
key
flows
at
a
point,
7
release,
initially
till
the
point
3
release,
we
had
went
for
a
single
tenant
model
wherein
each
each
data
scientist
gets
their
own
queue
for
cluster
and
when
we
started
adding
components
like
sto
on
to
the
cluster
we
kind
of
it
didn't
like.
We
didn't
want
to
have
a
lot
of
operational
complexity.
B
So
we
went
for
a
model
in
which
you
have
a
single
cluster
with
the
control
plane
installed
on
it,
and
then
you
have
tenants
sharing
that
control
plane
from
within
that
cluster,
and
you
can
also
have
restricted
resource
sharing.
You
can
enforce
resource
courtesan,
single
users
and
then
kind
of
have
a
cap
on
users,
GPU
usage
and
and
conversely,
you
can
put
a
cap
on
the
use,
billing
and
resource
usage
from
that,
and
then
another
reason
was
to
kind
of
have
separating
new
user
experiments
and
workflows.
So.
B
So
the
admins
access
the
cubicle
entry
points
and
then
the
data
scientist
sack
use
the
east,
your
ingress
gateway
and
directly
connect
to
the
queue
flow
UI
through
that
at
the
history
of
ingress
gateway.
You
have
a
non-void
filter
that
kind
of
redirects
to
whatever
authentication
provider
the
vendor
has
we
used
x4
on
Prem
and
non
vendor
distributions
and
Google
uses.
I
ap
and
a
service
account
based,
authentication
and
then
AWS
uses
Cognito
and
there
I
am
based
authentication.
B
So
we
have
different
workflows
for
different
vendors
and
then
our
actually
handles
this
is
once
in
new
user
comes
in
and
you
get
a
new
token
from
a
user.
You
have
a
profile
CRD,
which
is
a
custom
resource
that
creates
a
new
namespace
for
that
particular
new
user
and
roll
roll
and
roll
bindings
to
access
the
cue
flow
services
and
then
create
resources
within
that
namespace
and
a
nice
new
service
role
and
service
role
binding
for
accessing
the
cue
flow
services
which
is
which
would
be
coming
under
the
sto
ingress
media.
B
So
the
way
cue
flow
works
is
that
you
have
multiple
services
within
the
eschewing
recipe
area
and
then
the
east,
you
you
have
certain
services,
like
the
databases
and
stuff,
would
be
locked
on
for
the
data
scientists,
and
you
want
to
have
different
models
for
different
user
personas
per
se.
And
then
it
follows
a
soft
multi-tenancy
model
which
is
from
Jesse
Francis
document.
So
it's
like
you
assume
that
all
users
are
kind
of
trusted
and
you
don't
have
you
don't
have
hard
differentiations
or
you
assume
that
most
people
are
within.
C
C
B
So
it's
a
UI,
so
you'd
directly
access
it
through
the
browser
and
then
you'd
have
a
you
can
like.
You'd
have
a
login
page
where
and
you
can
like,
enter
your
new
namespace
or
user
ID
that
you
want
and
then
you'd
have
the
profiles,
controller,
which
would
take
over
from
that
and
then
create
the
associated
cluster
resources
for
you.
How.
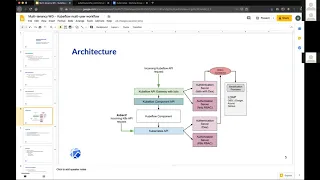
D
The
first
thing
is
that
what
you're
calling
the
cue
flow
Q
flow,
API
gateway
here,
is
essentially
the
is-2
ingress
gateway.
We
get
outs
for
the
cue
flow
app
for
the
chemical
dashboard
right.
Yes,
this
the
Green
Square
is
essentially
steel,
ingress
gateway,
yeah
programmed
to
forward
to
cube
flow
dashboard,
app
yeah.
B
You
have
the
sto
virtual
services
for
each
and
every
micro
service
associated
with
cue
flow.
You
have
the
cue
flow
central
dashboard
and
then
you
have
Jupiter
web
app
and
for
sewing
creating
notebooks
and
stuff
like
that.
So
you
also
have
the
pipeline
bonus
like
that.
So
you
have
different
micro
services
with
each
with
its
own
history
of
virtual
service
and
you,
the
user
or
the
data
scientist,
hits
the
history
of
ingress
gateway
and
then
once
they
are
authenticated
and
you
have
a
Associated
profile
created
for
them.
D
B
So
each
the
central
dashboard
kind
of
has
even
like
for
accessing
the
different
services
within
the
central
dashboard.
You
you'd
need
to
have
sto
virtual
services.
We
previously
used
Ambassador
API
gateway
for
that,
but
we
wanted
authentication
and
stuff.
So
we
kind
of
shifted
to
a
store
from
over
6
yeah.
B
D
B
D
This
is
essentially
a
set
of
namespace
configured
right.
Yes,
a
namespace
with
its
number
of
capes
roll
bindings
and
my
number
of
sto
service
role
is
there
anything
in
the
profile
which,
which
is
which
is
kind
of
like
any
sq
based
app,
would
need
this
sort
of
thing.
This
is
really
not
the
leg.
P/Q
flow
specific,
it's
a
reference
for
cue
flow,
but
it's
still
based
app
in
a
namespace
would
kind
of
be
doing
similar
stuff,
yeah.
B
Yeah
and
there's
two
things
here:
one
is
for
the
sto
related
services
and
then
for
the
kubernetes
related
services.
You
have
the
role
and
the
role
bindings,
so
most
of
the
cue
flow
workflows
are
dependent
on
another
set
of
operators.
Those
are
like,
for
example,
the
TF
operator
creates
TF
jobs,
which
is
the
tensor
flow
operator.
So
if
a
user
or
a
data
scientist
wants
to
train
or
serve
using
care
serving
which
is
again
another
custom
resource,
so
you
need
role
and
role
bindings
to
tie
into
kubernetes
resources
and
create
those
resources.
B
B
B
B
Multiple
profiles,
Oh
suppose
a
user
wants
to
share
a
namespace
with
suppose
you
have
a
single
user
data
scientist
using
their
own
namespace
and
suppose
you
have
a
team
name
space
with
which
is
shared
between
a
bunch
of
users.
So
in
that
case
you
would
want
to
have
a
separate
profile
for
the
individual
namespace
and
then
another
namespace,
which
is
shared
between
a
team.
So.
B
So
you
can
you
deploy
a
set
of
the
control.
Plane
is
shared
with
the
namespace,
so
the
control
plane
consists
of
a
bunch
of
services
and
CRTs,
and
you
can
sort
of
I
have
separate
like
the
volumes
and
volume
planes
are
restricted
to
a
single
namespace
and
resource
kata
if
it
exists,
that
would
be
restricted
to
the
namespace
and
anything
that
is
user.
Specific
would
be
restricted
to
that
interface
and
anything
that
is
global.
C
A
B
Yeah
sure
this
is
the
workflow
that
I
describe
like
you,
have
the
API
gateway,
which
is
really
the
history
link,
rest
gateway.
And
then
you
have
a
self-serve
model
wherein
a
user
logs
in
to
the
endpoint,
and
then
here
they
are
redirected
to
the
authentication
connective
and
then
they
fetch
their
authentication
like
identification
credentials
from
whatever
identity
provider
that
connector
uses.
And
then
you
sort
of
you
have
that
token
attached
as
a
header
for
each
and
every
request
that
the
user
sends
through
the
ingress
gateway.
So.
D
B
B
E
B
E
B
D
B
No,
we
don't
have
a
CLI
for
accessing
the
yeah.
There
is
no
CLI.
You
just
have
the
UI
for
accessing
the
different
services,
but
you
can
use
the
cue
cuddle
axis
for
creating
custom
resources
and
stuff
like
that.
But,
like
you
can
do
everything
that
you
do
with
with
the
UI
with
cue
card,
but
it
it's
more
user
friendly
for
data
scientists
to
not
your
skill,
cube
shuttle.
B
B
B
Yeah,
so
that
was
that
and
then
regarding
future
work
and
roadmap.
So
currently
you
have
a
restricted
set
of
things
that
profile
CR
installs
with
the
initial
workflow.
So
the
future
roadmap
is
to
kind
of
have
a
plug-in
model
which
can
inject
any
set
of
resources.
For
example
right
now
you
each
a
user
gets
a
blank
namespace
with
nothing
on
it.
B
For
example,
if
you
are
in
a
WD
using
EPS
volumes
or
something
like
that,
and
then
it
depends
on
the
cloud
environment
that
you're
in
and
then
so.
If
you
have
a
plug-in
model,
then
you
can
sort
of
have
a
model
where,
in
a
user,
when
they
login
and
a
profile
is
created,
you
automatically
get
standard
volume
that
you
can
use
and
you
have
a
automatic
injection
of
resources
like,
for
example,
you'd
need
to
authenticate
to
different
cloud
services,
or
something
like
that.
B
In
that
case,
you
can
automatically
inject
those
credentials
inside
the
namespace
so
that
you
can
use
those
credentials
and
authenticate
and
use
those
cloud
services
and
then
currently
the
for
the
on-prem
model
since
we're
using
dex.
We
need
to
modify
the
APS
or
flags
in
order
to
enable
like
Dex,
and
this
needs
gates
master
node
access.
So
this
is
not
possible
in
AWS
AWS.
They
initially
wanted
to
go
with
the
upstream
implementation,
but
they
had
to
choose
a
vendor
specific
one
because
of
this,
so
it
like.
B
We
have
different
solutions
for
different
vendors,
or
so
it
would
be
easier
if
we
can
avoid
modifying
the
ASL
flags.
For
that
particular
thing,
then,
and
another
thing
is
to
have
a
CID
similar
to
the
profiles.
So
we
went
with
the
profile
CRD,
because
at
that
time
the
multi-tenancy
working
group
they
there
was
no
notion
of
a
tenant
CRD
at
that
time,
so
we
had
to
like
create
the
community
had
to
create
their
own.
A
B
D
B
D
B
D
C
A
D
C
I
guess
yeah
I
feel
like
to
do
something
like
this.
You
could
have
a
combination
of
of
agency
which
allows
self-service,
namespace
creation,
because
then
you
could,
you
could
put
cube
flow.
I
heard
this
I
heard
a
couple
of
people
mentioned
this
at
cube,
Con
in
San
Diego
that
they
have
a
cluster
specifically
for
cube
flow
because
it
doesn't
play
as
well
with
others.
It
needs
cluster
level,
privileges
and
stuff
like
that,
yeah
with
H
and
C
I.
Don't
know
if
you've
looked
at
that
at
each
other.
We
could
talk
about
it
afterwards.
C
A
C
A
C
B
F
F
A
C
F
G
F
Yeah
and
so
one
of
the
kind
of
workarounds
I've
kind
of
looked
I've,
never
actually
fully
tested
this
from
a
from
a
security
perspective
to
break
it.
But
you
could
potentially
do
a
new
storage
class
for
each
tenant
because
then
the
persistent
volume
can
only
be
mounted
by
somebody
with
access
to
the
storage
class,
and
you
can
do
our
normal,
our
vac
for
users
for
source
classes.
So
you
can
at
least
limit
you
know,
tenant
taking
in
Korean
PVC
for
an
unclaimed
pvu
of
somebody
else.
E
A
A
F
A
F
E
H
From
completely
so
now
we
establish
a
network
isolations
through
its
two
parties.
So,
okay,
you,
like
I,
chose
to
turn
the
tunnel
features
and
all
the
networks,
the
network
requests,
are
only
all
the
services.
First
of
all,
all
the
services
are
with
SEO
sidecars,
so
talking
to
other
services
are
three
cycles
only
and
secondly,
by
default,
only
the
traffic
from
within
the
same
name,
Swit,
pass
from
the
ingress
is
allowed
so
cross
name,
traced,
traffic,
so
ingress.
I
H
We
cannot
with
him
it's
very
hard,
like
a
customized
like
two
patches
of
the
network
policies
following
users
like
like
practice,
so
we
decided
ok
with
gonna,
set
up
a
global
area.
Where
is
the
namespace
as
a
boundary
like
a
cross?
Nemesis
is
allowed
or
disallowed
at
fit
only
the
request
from
the
u.s.
is
allowed,
but
the
requester
in
West
yeah.
We
have
been
checked
against
the
used
to
rob
a
grocery
shopping
is
controlled
by
the
for
power
controllers.
So
we
have
some
kind
of
control.
H
D
E
Yes,
so
just
thinking
more
from
the
multi-tenancy
perspective
right,
so
there
are
natural
policies,
obviously
dual-layer
for
isolation.
So
there's
some
value
there.
So
one
option
could
be
to
have
a
default
network
policy
for
each
namespace,
but
then
I
understand
that
it
would
be
easier
to
automate
the
sto
policies.
So
maybe
then,
for
each
application
or
each
service,
the
data
scientist
needs.
You
could
still
have
then
a
history
of
policy
to
manage
the
routes,
and
you
know
what
that
can
communicate
with
and
coming.
D
Back
to
our
multi-tenancy
work
here,
so
there's
several
areas
of
sort
of
overlap
and
and
and
and
reuse
here,
and
we
should
probably
cover
those
in
a
follow-up
call.
But
that
also
suggests
to
us
that
we
need
to
allow
for
sto
based
network
eyes,
which
has
been
in
the
back
of
our
minds.
But
we
have
an
explicit
only
about
it.
Yet.
E
B
Right
right
now
suggested,
like
usage
policies,
to
kind
of
have
an
exclusive
cluster
for
our
cube
flow
because
of
the
restrictions
that
we,
because
of
this
unique
way
in
which
we
deploy
it
and
kind
of
configure
services
within
chip
flow.
But
it
will
be
ideal
to
have
it
kind
of
play
well
with
other
applications
as
well.
I
guess.
D
F
B
F
A
Think
we
will
hand
it
over
to
Jim,
since
we
we
have
20
minutes
left
and
if
people
have
additional
follow-up
questions
for
Editha
he'll
be
in
the
slack
channel
or
you
can
hit
up
the
mailing
list,
whatever
works,
and
we
can
always
have
you
back
for
a
follow-up
to
there's
a
lot
of
questions.
So
thank
you
so
much
yep.
E
Alright,
so
what
we
wanted
to
cover
in
this
next
section
was
really
just
a
quick
update
on
multi-tenancy
benchmarks
and
in
fact
some
of
the
topics
we
touched
on
are
very
relevant
to
the
discussion
here.
So
just
for
those
of
you
who
might
not
be
familiar
with
the
benchmarking
effort
and
what
goals
and
purpose
are-
and
there
are
some
links
in
this
document-
I
shared
the
goal
here
was
really
to
focus
on.
E
You
know,
focus
on
the
what
end
and
results
we
want
to
achieve
from
multi-tenancy
and
provide
a
way
for
users
to
validate
that
in
their
cluster
and
that's
what
we
wanted
to
define
as
a
set
of
benchmarks.
Of
course,
as
soon
as
you
start
thinking
of
things.
From
that
perspective,
it
became
apparent.
There
are
several
different
layers
or
levels
of
multi-tenancy,
so
one
way
of
categorizing
is,
of
course
hard
and
soft
multi-tenancy,
but
the
approach
we
wanted
to
take
was
go
a
little
bit
more
granular
than
that
right.
E
So
I
have
some
links
here
to
what's
already
also
in
the
github
repo,
with
in
terms
of
the
definitions
that
we're
using
the
benchmark
types
we
defined
and
relates
this
to
two
types
of
checks:
behavioral
as
well
as
configuration
and
then
categories
that
we
define
I,
know
there's
about
seven
or
eight
different
categories
that
we
listed
and
that's
shown
in
the
table
below
we'll
go
through
two.
So
the
goal
was
to
try
and
define
you
know
the
first
level,
so
there's
profile
level,
1,
2,
&,
3
and
just
very
briefly,
the
way
these
are
defined.
E
E
So
this
would
be,
you
know
you
could
think
of
it
as
self
multi-tenancy,
but
we're
still
requiring
in
the
best
practices,
for
example,
things
you
would
find
in
the
pod
security
policy
and
we're
not
mandating
that
you
use
what
security
policies
anything
like
that,
but
that
you
would
still
secure.
You
know
your
configurations,
for
example,
do
not
allow
root
user
access
within
a
container
to
not
allow
shared
resources
like
host
resources.
Things
like
that.
E
E
So
I
think
what
we
wanted
to
focus
on
from
our
you
know
from
the
work-in-progress
perspective
was
agreed
to
what
would
constitute
a
good
set
of
checks
for
profile
level
one,
and
once
we
have
the
definitions,
we
have
a
prototype
of
automating.
Some
of
these
so
using
the
anterior
end
validation
to
what
we're
shown
as
it's
possible
to
automate
both
configuration
as
well
as
behavioral
checks.
So
then
we
can
go
ahead
and
you
know
implement
a
set
of
validation,
tests
or
profile
level.
One
and
I
think
if
you
look
at
the
the
overall
table.
E
What's
interesting
here
is
so
the
categories
are
listed,
of
course,
in
the
first
column,
so
a
lot
of
focus
in
profile
level.
One
is
isolating
the
control
plane,
making
sure
each
namespace
as
the
proper
isolation.
It's
not
allowing
a
single
tenant
to,
for
example,
just
arbitrarily
increase
their
resource
quarters
or
access,
of
course,
other
tenant
resources
having
some
level
of
network
security,
and
this
kind
of
ties
back
to
the
our
discussion
of.
Should
we
mandate
you
know,
should
it
be
a
configuration
check
with
network
policies
or
our
sto
policies,
good
enough
for
profile
level?
E
E
Also
on
the
host
isolation,
there's
about
five
different
checks
defined
to
make
sure
that
we're
not
using
host
resources,
which
obviously
the
could
lead
to
some
security
concerns,
and
especially,
if
other
you
know,
if
other
security
best
practices
are
missed.
So,
for
example,
not
using
host
networking
not
using
the
whole
storage
things
things
to
that
nature,
a
bind
mounts
which
would
be
the
host
pad
type
of
volumes
and
then
for
fairness.
E
You
know
just
kind
of
thinking
of
it
from
this
table
structure
so
level,
one
would
focus
on
again
manual
configuration
no
namespace
level,
automation
like
since
you
put
it
required,
but
something
that
could
be
also
set
up
just
using
good
cuddle
and
following
the
best
practices
it
would
be
tedious
and
difficult
to
manage,
but
could
be
done
level.
Two
is
where
we're
requiring
self
service
namespaces.
So
attendance
should
be
able
to
create
additional
namespaces
and
should
be
able
to
do
other
self
service
operations,
the
most
common
being.
E
You
know,
creating
users
for
therefore
that
sub
tenant
or
for
the
tenant,
and
also
allowing
you
know
things
like
network
policies,
etc.
You
know,
like
was
mentioned
or
goop
flow
of
being
able
to
create
ingress
or
egress
rules
for
user
level.
Services
would
be
allowed
in
level
2
and
level.
3
is
where
we're
thinking
of
the
I
guess,
that's
the
hard
multi-tenancy
or
moving
towards
that,
where
you
would
use
things
like
virtual
cluster,
etc.
E
Right
and
that's
where
I
think
some
open
questions
are
related
to
the
networking
and
storage
discussion
we
just
had
even
for
storage,
we
need
to
decide
what
would
constitute
you
know
being
sufficient
for
level
1,
for
example,
as
the
Ryan
suggestion
should
we
require
that
each
each
tenant
have
their
own
storage
controllers
or
as
long
as
there's
no
unclaimed.
Pbs,
however,
that's
implemented.
Is
that
what
we
should
check
for
an
audit
for
it's.
C
E
For
example,
if
I
just
what
was
mentioned
in
the
coop
flow
discussion,
a
data
scientist
has
a
new
application
or
you
know,
anytime,
you
run
a
new
application
in
a
namespace.
You
want
to
expose
the
route
to
that
or
you
know,
have
a
port
or
allow
that
application
to
talk
to
other
services
they
either
ingress
or
egress.
You
would
want
to
do
this
per
app.
I
could
also
imagine,
though,.
F
C
Guess,
yeah
I,
guess
so
make
sense
and
I
guess
I'm
wondering
why
we're
calling
that
one
out
like
it
doesn't
say
here,
like
you
know,
create
deployments
or
services
or
stuff
like
that
right,
I
think
those
are
just
more
or
less
assumed.
Yeah
I
mean
create.
Namespaces
is
interesting
because
is
usually
a
cluster-level
privileged
operation,
and
so
allowing
that
in
some
context,
is,
is
quite
interesting,
but
maybe
but
yeah
sorry
wasn't
suggesting
that
you
add
it
there,
but
I
would
guess.
C
C
E
E
Same
thing,
that
role
by
names,
you
know
if
a
cluster
is
misconfigured,
where
you
have
certain
over
privileged
roles
exposed.
Even
at
the
cluster
level,
you
could
create
a
role
binding
to
that
in
the
namespace,
and
then
you
could
potentially
delete
other
multi-tenancy
configuration
in
that
namespace,
which
gives
you
greater
privileges.
G
I
have
a
question,
so
what
is
faith?
Can
you
go
to
the
hostess
section
host
host
isolation,
yep
so
I
think
the
by
nominal
cost
so
is
ya
useful
IP
security
that
has
reasonable
owning
the
number
three
use
of
the
host
networking
and
part
I'm,
not
sure.
So
if
it
is
allowed
to
use
a
host
networking,
it
may
be
possible
that
some
corporate
features
may
not
work
like
before
the
health
check
kind
of
thing.
G
So
it's
depending
the
use
case
some
people
may
insist
they
want
to
make
sure
they
pass
the
complement
test.
So
so
you
mean
you
do
this
hon
emergency.
They
want
to
make
sure
some
common
kubernetes
features
skill
work
in
every
regard.
Sometimes
we
probably
have
to
compromise
with
some
solution
that
need
to
access
house
networking,
but
you
know
very
carefully
way
this.
G
E
E
E
All
right,
so
it's
really
the
yeah
the
Gold's
here
as
a
certain
feel
free
to
comment,
and
you
know
it
so
this
table
I
kind
of
put
it
in
a
different
form
here.
If
you
go
to
the
github
repo
there's
just
a
list
of
and
I
can
just
quickly
pull
that
up
in
I
can
take
a
look.
So
everything
that's
in
this
document
is
also
and
github,
so
you
can
either
you
know,
create
PRS
or
issues
or
questions,
or
you
can
just
comment
on
any
of
these,
but
really
yeah.
E
E
Seven
concerns
storage,
isolation,
I
think
we
already
discussed
this
a
little
bit,
but
there's
some
interesting
questions
there
too,
and
we
need
to
come
up
with
the
right
right
solution,
which
constitutes
the
first
level
of
multi-tenancy,
and
then
you
know,
I
think
talking
about
data
plane,
isolation,
so
sandbox
saying
we
and
I
think
there
was
a
question
dasha
admin
Center
mentioned
also
coop
cons.
Somebody
was
asking
about
this
where
that
would
fit
so
I
think
it.
E
It's
absolutely
necessary
at
one
of
the
levels
we
need
to
decide
at
what
level
and
the
other
interesting
question
there
is.
How
do
we
verify
that
all
right?
How
do
you
is
there
a
way
to
test
the
sandboxing
interaction
working
and
you
know
I-
think
we'd
have
to
talk
to
somebody
who
understands
sandboxing
and
let
a
lot
better
than
I
do
to
be
able
to
come
up
with
the
right
check
or
test
for
that
almost.
C
A
E
So
those
were
some
of
the
open
questions
that
I
had,
and
certainly
you
know,
if
there's
any
other
comments
questions
happy
to
do.
We
could
we
have
five
more
minutes
left,
so
we
could
either
do
a
little
bit
right
now,
but
maybe
then
we,
you
know,
set
up
offline
discussions
on
these
topics
if
someone's
interested
again
and
please
do
review
their
definitions
and
off
the
benchmarks
themselves,
and
if
there
is
any
suggestions
etc,
we
could
just
collaborate
on
those
on
github
and
then
for
the
automation
tasks.
E
If
folks
are
interested
in
contributing
and
writing
those
automation
tests.
That
would
be
the
next
a
set
of
things
we
start
looking
at,
and
there
are
some
examples
there
already.
So
there's
a
starting
point
and
it's
fairly
easy
using
the
e2e
test
tool
and
cooker
all
type
commands
to
to
do
most
of
these
tests.
E
C
A
A
Well,
thank
you
for
a
great
presentation.
As
you
mentioned,
if
anyone
has
further
questions
Jim,
we
can
schedule
Jim
for
another
diet
as
the
work
progresses
and
also
we
have
slack.
We
have
a
mailing
list,
so
don't
be
shy.
Well,
thanks.
Everybody,
a
good
first
meeting
for
the
year
for
sure
I
think
we're
gonna,
get
some
good
stuff
done
in
2020
and
have
a
good
Tuesday.