►
From YouTube: WG Network Policy API Bi-Weekly Meeting For 20220627
Description
WG Network Policy API Bi-Weekly Meeting For 20220627
A
Awesome
hello:
everybody
today
is
june
27th
2022.
This
is
a
meeting
of
the
sig
network
policy,
subgroup,
2
sig
network
and
today
we're
going
to
be
discussing
a
lot
about
multi-cluster
network
policy.
Just
as
a
note,
this
is
a
kind
of
off
date
for
us
because
we're
working
around
some
public
holidays
that
have
been
cancelling
our
meetings
that
are
bi-weekly
so
we're
on
an
off
week,
but
yeah
not
too
much
to
talk
about
today,
except
for
multi-cluster
network
policy,
so
I
will
hand
the
floor
over
to
sanjeev.
C
C
Okay,
you
just
move
the
cursor
and
it
seems
to
jump
slides
so
just
watch
out
for
that.
So
this
is
a
topic
which
kind
of
straddles,
sig
networks,
network
policy
and
sig
multi
cluster,
and
we
it
so
happens.
We
have
representatives
from
all
those
and
all
of
we've
had
at
least
one
discussion
in
each
of
these
groups.
So
far.
C
Okay,
I
thought
I'd
just
mention
one
thing
right
off
the
bat,
which
is
that
we
don't
exactly
have
agreed
upon
multi-cluster
network
model.
Yet
to
the
best
of
my
understanding,
correct
me.
If
I'm
missing
something
so
one
basic
question
would
be
do
we
first
need
to
even
define
a
reference
model,
yeah
didn't.
B
You
had
a
hand
yeah.
No,
I
wanted
to
agree
with
you.
We
haven't
really
pinned
that
down.
There
was
a
pr
open
against
the
caps
and
there
was
some
feedback.
I
don't
think
we
closed
the
pr
or
merged
it
or
got
all
the
feedback
together.
So
I
know
that
we
need
to
block
this
on
that,
but
I
do
think
it
is
definitely
relevant
and
we
definitely
do
need
to
describe
what
we
expect
to
happen
in
a
multi-network
model.
B
Yeah,
we
don't
really
have
a
I
mean.
Kubernetes
cncf
doesn't
really
have
a
product
marketing
wing.
What
we
can
do
is
go
to
our
respective
field
teams,
which
I
assume
you've
already
done,
and
we've
certainly
got
some
context
from
ours,
but
we
can
also
go
out
to
the
broader
community
in
the
form
of
surveys
or
questionnaires
which
we've
done
in
the
past
to
you
know
moderately
success,
okay,
yeah!
Maybe
that's
a
good
idea.
Maybe
we'll
initiate
a
small
community
poll
on
requirements.
B
C
Okay
point
taken,
I
think,
maybe
we'll
initiate
some
community
poll
in
in
the
coming
day
or
two,
so
just
two
levels
that
everybody
I'm
sure
most
people
know
this,
but
just
to
level
set
at
a
very
high
level,
there's
basically
two
models:
there's
either
a
flat
or
a
single
network
model.
Sometimes
it's
called,
which
means
that
all
the
clusters,
every
part
in
every
cluster,
can
talk
to
every
other
part
in
every
other
cluster
without
going
through
any
kind
of
matting
operation,
so
in
some
sense
they're
all
in
a
consistent
writing
routing
domain.
C
So
that's
the
flat
or
single
network
model
and
a
multi-network
model
is
where
ips
are
not
necessarily
unique
across
the
set
of
clusters
we're
talking
about.
So
there
is
an
adding
involved,
which
is
typically
some
kind
of
egress
gateway
or
eagle
snack
function,
combined
with
possibly
an
ingressnet
function
on
the
other
cluster
right.
So
there
are
these
two
models.
One
is
you've
got
a
bunch
of
clusters
that
can
all
freely
communicate
to
each
other.
C
C
C
One
could
potentially
conceive
of
no
models
that
need
not
be
aligned
with
the
mcs
api
which
the
sig
multi-cluster
team
has
been
defining
or
we
could
sort
of
ensure
we
could
maybe
decide
that.
No,
that
is,
that
is
the
reference
model
which
we
want
to
operate
within
and
then
there's
also
control
plane
models
which
define
the
level
of
global
information
sharing.
C
But
should
we
even
assume
that,
because
some
of
these
policy
options
could
depend
upon
whether
you
know
about
labels
in
other
clusters
and
the
istio
community
has
done
some
a
reasonable
amount
of
work
here,
actually
quite
a
bit
more
than
the
kubernetes
community
in
terms
of
defining
various
kinds
of
multi-cluster
models
which
are
based
along
these
lines?
So
there's
a
single
network
versus
multi-network
there's
you
know
single
primary
versus
remote
primary
and
all
these
others.
So
can
we
should
we
maybe
adopt
those
kinds
of
models?
C
The
initial
draft
of
this
document
we
tried
to
straddle
both
the
single
network
and
the
multi-network
model,
but
that
comes
with
a
cost.
Then
sometimes
you
have
to
work
with
the
lowest
common
denominator,
because
you
want
to
have
a
policy
that
works
on
both
these
models,
whether
you're
netting
or
not.
C
C
So
we
have
to
decide
whether
we
want
to
do
that
or
we
want
to
sort
of
do
that
as
the
first
phase
of
an
eventual
model
that
covers
all
these
cases,
so
not
sure
how
much
time
to
spend
on
this
network
modeling
thing
any
quick
cards
here
before
we
talk
about
policy.
I
have
a
couple
of
pictures
here
as
well.
I
might
as
well
share
those
so
this
is
actually
something
that
laura
lorenz
and
I
have
been
working
on
as
part
of
a
multi-cluster
service.
C
C
Sorry,
I
should
not
move
my
mouse,
I
suppose,
which
is
sort
of
the
a
multi-cluster
domain.
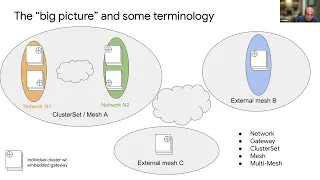
So
on
the
left,
you
have
mesh
a
which
is
a
collection
of
clusters
within
that
mesh.
Slash
cluster
set,
there's
actually
multiple
networks
right.
So
these
networks
are,
as
we
defined
earlier
regions
where
within
a
network
you
don't
need
to
not,
and
when
you
go
in
and
out
of
a
network
you
need
to
not
so
you
see
that
there
is
the
orange
network
and
the
green
network.
C
There's
two
clusters,
each
in
orange
and
green,
so
clusters
in
an
orange
network,
don't
need
a
gateway
when
talking
to
each
other,
but
they
do
need
in
a
gateway
when
talking
to
clusters
in
network
into
but
they're
all
part
of
the
same
mesh.
So
this
is
a
multi-network
mesh
right,
slash
cluster
set,
and
they
also
sometimes
need
to
talk
to
other
meshes.
So
our
cluster
sets.
So
that's
what
b
and
c
are
they're
effectively
external
clusters,
measures
and
and
and
so
on,
and
so
terms
like
network
and
gateway
cluster
set
mesh
and
multi
mesh.
C
D
E
Yeah,
it's
a
bit
more
basic,
I'm
still
trying
to
catch
up,
so
I
mean
we.
I
know
we
call
it.
Network
policy
is
the
is
the
goal
to
provide
a
security
policy
irrespective
of
the
network
model?
I
mean
what
I'm
trying
to
get
to
is
that,
should
it
matter
whether
there
is
ipam
overlap,
I
mean
I'll
be
trying
to
say
that
part.
One
is
able
to
talk
to
part
two
with
respect
to
how
they
are
able
to
communicate
with
each
other,
or
is
that
communication
path
important
for
defining
security
policies?
E
C
So
that
is
exactly
the
topic
that
is
being
listed
here,
which
is
that
one
could
define
a
policy
model
that
works
with
or
without
netting,
and
that
is
actually
what
we
have
assumed
in
the
slides
that
we
will
be
going
into
in
the
next
few
slides,
but
because
you're
trying
to
work
the
same
api
has
to
work
in
all
these
models.
It.
C
B
Something
so
I
don't
think
we
should
build
anything
that
can't
possibly
work
in
multiple
models
that
that
seems
like
a
premature
dead
end,
but
I
also
don't
think
we
need
to
assume
the
lowest
common
denominator.
What
we
need
to
find
is
that
middle
ground,
where
we
describe
what
we
really
want
in
the
richest
possible
terms
that
we
believe
is
practically
implementable
in
multiple
ways
and
that's
a
that's
a
mouthful.
You
should
print
on
a
t-shirt,
but
what
I,
what
I
mean
is
like
sanji.
B
We
talked
about
this
a
little
bit
a
couple
weeks
ago,
right
like
if
you
were
to
do
service
account.
I
can
imagine
three
or
four
different
ways
that
you
would
transport
service
account
information
around,
whether
it's
through
control,
plane
or
through
data
plane,
and
to
me
that
satisfies
the
sort
of
plausibly
implementable,
at
least
for
now,
until
we
go
ahead
and
try
to
implement
them
right.
E
C
C
Okay.
But
this
is
laying
out
the
fact
that
there
are
proprietary
solutions
that
only
address
some
models
and
I've.
Given
one
example
here
this
silly
multi-cluster
mesh
that
assumes
it's
a
flat
network
only
model,
and
then
it
can
actually
assume
global
sharing
of
labels,
and
things
like
that
which
we
cannot
assume
if
there's
an
acting
involved.
B
Hold
on
a
second,
though,
I'm
not
sure
I
buy
the.
I
agree
with
the
predicate,
I'm
not
sure
I
agree
with
the
conclusion
abstractly
there
could
be
a
control
plane
that
understands
the
different
clusters
and
figures
out
how
to
translate
from
one
to
another
at
the
edge
they're
not
doing
that,
but
their
api
could
do
that
right.
Nothing
about
the
way,
I'm
not
super
familiar
with
their
network
policy
api,
but
the
way
I
understood
it
was
nothing
about
the
api
says
it.
It
can't
be
done
that
way.
It's
just
not
done
that
way.
B
B
But
like
psyllium
in
particular,
since
we're
picking
on
them,
they
they
do
something
like
they
have
an
ipsec
layer
below
and
in
some
of
the
extra
space
in
the
headers
there
they're
embedding
an
identifier
which
they
can
use
to
identify,
not
a
unique
pod,
but
a
unique
set
of
pods
that
satisfies
the
policy
constraint
right.
So
in
theory,
the
other
end
of
that
ipsec
layer
could
either
have
a
unified
id
space
across
all
the
networks
or
could
map
ids
from
one
to
another
at
the
edges
right
right.
So.
C
B
You
know
installs
their
ebpf
programs,
and
so
I
don't
think
it's
reasonable
to
say
everything
must
work,
mix
and
match
with
any
combination
of
things
it's
great
if
they
do.
But
I
think
that
there
is
some
responsibility
in
assembling
a
set
of
clusters
that
you're
assembling
components
that
actually
do
work
together
and
that
very
often
that
will
mean
they
run
the
same
cni
or
it
will
mean
that
they
stick
something
at
the
edge
that
converts
from
one
language
to
another
language
right.
C
So
these
are
all
essentially
aspects
of
a
certain
model.
One
would
need
to
agree
upon
for
multi-cluster
policy
and
for
this
initial
draft
we
kind
of
wanted
to
make
it
minimal
assumptions.
So
there
are
no
assumptions
that
the
cni
is
the
same
or
even
has
similar
capability
across
two
different
clusters
in
the
same
multi-cluster
group,
nor
that
there
is
any
tagging
and
we
will
come
to
that
and
also
it
addresses
both
the
flat
model
and
the
multi-network
model.
C
B
C
Okay,
let's
keep
going.
I
think
these
are
all
valid
points
and
hopefully,
as
we
iterate
over,
it
it'll
become
a
little
bit
clear.
So
again,
this
was
sort
of
the
architecture
picture.
For
now
do
we
tentatively
agree
that
we're
talking
about
policy
within
one
cluster
set
mesh?
We're
not
really
talking
about
multi-mesh
kinds
of
policies
like
this
picture
is
alluding
to
or.
B
Maybe
we
want
to
come
back
to
that
later,
but
I'm
I'm
happy
to
come
back
to
it,
but
my
initial
inclination
is,
we
have
enough
to
chew
on
by
just
solving
it
within
a
within
a
cluster
set,
and
the
sorts
of
policies
that
you
would
typically
want
to
express
between
cluster
sets
feels
like
an
order
of
magnitude
more
intentional,
more
cautious
than
you
would
do
within
right
right.
At
least
this
is
the
way
we've
historically
thought
about
it.
Right.
C
Again,
just
we're
just
laying
out
the
fact
that
this
there's
in
general,
an
entire
enterprise
is
never
just
one
cluster
set,
so
be
aware
of
that.
But
for
now
we'll
concentrate
on
one
plus
to
say-
and
this
is
just
another
way
of
representing
that
a
more
generic
picture,
which
is
that
you
can
have
a
cluster
set
of
four
clusters.
C
B
A
F
Yeah
I
mean
we're
going
to
need
to
be
able
to
set
policy
for
talking
to
things
that
aren't
kubernetes
clusters,
so
maybe
we
don't
need
to
solve
every
problem
you
could
have
with
the
kubernetes
cluster
like
at
a
certain
point.
If
it
gets
too
complicated,
you
could
just
treat
the
other
cluster
like
it
was.
B
Network
yeah,
I
want
to
be
real
careful
that
we
don't
literally
try
to
reinvent
like
istio
here
right
like
there.
There
are
problems
that
we
can
say
are
are
above
what
kubernetes
is
trying
to
solve.
We
just
need
to
figure
out
where
that
edge
is
and
honestly,
like.
I'm,
not
super
confident.
I
know
where
it
is,
but
I
feel
like
we'll
know
once
we've
crossed
it
and
then
we'll
have
to
go
back
and
figure
out
where
it
was.
C
Okay,
so
I'll
skip
this
slide,
but
there's
a
bunch
of
text
here
about
sort
of
the
kinds
of
requirements
you
can
look
at
it
later.
Let's
just
go
on
and
there's
put
some
notes
on
the
kinds
of
factors
we
need
to
think
about
like
how
much
dependent
on
the
mcs
api
the
trust
model
across
clusters
right
the
the
and
sort
of
the
threat
model
that
we
are
actually
trying
to
protect.
C
Sorry
and
a
few
more
other
things
there.
Okay.
So
let's
look
at
some
pictures
now
about
the
use
cases.
So,
first
you
again,
we've
gone
through
this
in
a
couple
of
previous,
so
I'll,
try
to
maybe
run
through
it
a
little
fast
but
feel
free
to
stop
me,
okay,
so
the
first
use
case
is
for
now
all
these
use
cases
we
are
assuming.
We
are
trying
to
operate
within
the
mcs
api
to
the
extent
possible
and
we
are
trying
to
make
it
work
both
in
the
flat
network
and
the
multi-network
model.
C
C
So
this
one
is,
I
have
two
parts
here:
they
have
imported
remote
service
foo
from
another
cluster,
but
on
cluster
a
we
want
to
say
part
p1
gets
to
use
this
imported
service,
but
p2
does
not
get
to
use
the
supported
service
today
there
is
no
direct
way
of
doing
that
other
than
having
a
cider
based
policy,
which
also
doesn't
quite
work
because,
ideally
well.
Cider
based
policies
are.
C
At
the
pod
level,
right
I
mean
one
could
sort
of
have
an
egress
policy
here
which
treats
the
cluster
set
ip
of
the
remote
as
the
destination
ip.
However,
that
implementation
is
likely
to
break
in
many
cases,
because
in
most
cases,
egress
policies
are
applied
in
the
cni
after
the
service
load.
Balancing
has
already
been
done,
so
it's
applied
against
from
source
pod
to
destination
pod,
whereas
if
we
wanted
to
work
in
multi-network,
we
don't
know
the
destination
port
ips,
so
we
have
only
the
cluster
set
ip
to
go
by.
C
G
A
question
sanji
yeah
go
ahead
yeah.
What
does
it
mean
to
not
be
able
to
access
the
service,
given
that
the
service
is
really
just
a
loose
abstraction
over
a
group
of
endpoints
right?
Can
they
still
access
the
underlying
endpoints
directly
if
they
go?
Look
at
the
endpoint
slice,
for
example,
or
what
happens
if
there's
multiple
services,
exposing
a
single
workload.
G
Right,
I
guess
my
concern:
is
it's
not
even
really
a
multi-cluster
concern
like
if
you
were
to
say
in
single
cluster
network
policy
that
you
were
going
to
add
a
policy
for
a
service
rather
than
for
specific
pods?
Then
you
get
into
problematic
behavior
right
because,
for
example,
I
don't
actually
have
to
send
through
a
service
ip
to
reach
it.
I
can
go
and
access
the
the
pod.
I
use
directly
right.
Well,
you
would
have
you.
G
Like
you
can
say
that
you
like
do
the
indirection,
but
then
what
happens?
If
I
have
two
services
backing
one
pod
and
one's
allowed
and
one's
denied?
What
do
you
do
right?
This
is
an
issue
we
hit
early
on
in
ego
many
years
ago
and
kind
of
caused
us
to
completely
redo
our
api,
because
we
initially
had
our
authorization
policy
at
a
service
level
and
that
caused
a
number
of
issues
like
this.
So
we
moved
it
to
a
workload
level.
B
It
is
sort
of
more
ergonomic
and
I'm
not
even
inherently
against
it,
but
it
does
have
some
real
drawbacks
that
if
we
want
to
do
if
we
want
to
make
m.c
serve
mc
policy
based
around
services,
we
should
probably
make
single
cluster
services
policy
first
and
then
define
them.
In
the
same
terms,
sorry,
I
jumped
the
line.
I
think.
B
B
Sort
of
api
I
mean,
if
we're
defining
it
in
terms
of
services,
then
we
can
define
whatever
semantics
we
want
to
define
and
argue
about
whether
those
semantics
are
correct
right.
We
don't
have
a
services,
oriented
network
policy
so
we're
we
are
all
automatically
being
sidetracked
into
arguing
about
that.
Instead
of
the
multicultural
problem
right
so.
C
If
we
look
at
what
is
the
functionality
we
want
to
achieve,
we
want
pod,
we
want
there.
We
want
part
p1
to
not
be
able
to
talk
either
to
the
service
whip
or
directly
to
the
pod
whips
if
it
happened
to
be
a
flat
network
and
part
p,
once
somehow
figured
out
the
back
end
pod
ip.
Both
those
cases
have
to
be
blocked
right.
So
this
is
just
our
starting
point
here.
C
What
we
need
to
first
degree
is
whether
this
functionality
needs
needs
to
be
addressed,
and
if
we
agree
that
the
functionality
needs
to
be
addressed,
then
it
needs
to
cover
both
the
cases
where
you're
talking
to
the
service
whip,
which
is
what
you
would
normally
do
in
an
mcs
environment
or
whether
it
happens
to
be
a
flat
network,
and
you
have
somehow
backdoor
figured
out
the
back
and
forth
ip
and
are
trying
to
reach
the
port
ip
directly.
Both
those
cases
need
to
be
blocked.
If,
if
we
agree
that
this
functionality
needs
to
be
met,.
A
And
rewinding
to
like,
if
we
did
this
in
network
policy,
I
I
maybe
I'm
not
even
and
tim
had
some
more
background
on
this
when
they
first
designed
it.
But
if
we
had
a
service,
selector
or
network
policy
like
if
you
select
a
service,
it
means
a
workload,
cannot
reach
that
service's
vip,
so
call
it
the
dns
name
whatever.
If
you
want
to
stop
both
a
pod
talking
to
a
service
whip
and
a
pod
talking
to
those
other
backend
pods,
then
in
my
mind
you
need
to
have
two
policies.
You
don't
have
one
like.
A
B
B
I
mean
already,
I
see
a
bump
there,
which
is
we
have
customers.
I
know
lots
of
people
who
are
doing
this
sort
of
hybrid
island
where
the
vms
all
share
network,
but
the
pods
in
each
cluster,
don't,
and
so
in
theory,
it's
possible
for
a
pod
to
egress
its
cluster
and
hit
a
node
port
on
a
different
cluster
right,
which
means
you,
then
have
to
talk
about
multi-cluster
network
policy
at
that
level
or
decide
not
to
right.
Because
again,
we
don't
have
a
spec
for
this
because
we
have
inspected.
C
That
we
have
to
consider
yeah
and
then,
as
far
as
the
other
service
types
we
will
come
back
to
that
I
didn't
want
to
complicate.
You
know
all
of
the
note
port
and
the
service
type
load
balance,
and
all
that,
let's
for
now
think
of
these
just
as
cluster
set
ips
or
cluster
ips
and
we'll
come
back
to
node
port
as
well.
But
for
the
moment
to
keep
our
discussion
simple
everything
is
every
service
is
a
cluster
ip
service
and
some
of
them
are
multi-cluster
cluster
ip
services.
So
let's
just
kind
of
focus
on
that.
C
C
Services
are
anything
you
do
to
a
service
does
not
automatically
imply
to
a
multi-cluster
service,
because
you
have
to
opt
in
specifically
for
a
multi-cluster
service,
but
we
could
choose
not
to
follow
that
model,
in
which
case
a
service
is
equivalent
to
a
multi-cluster
service
which
also,
by
the
way
happens
to
be
what
the
hto
control
plane
does
and
his
two
control
plane
just
joins
two
services
in
two
different
clusters,
which
have
the
same
name.
Space
and
same
it
implicitly
treats.
B
C
There's
some
ambiguity
in
the
definition,
because
I
know
of
implementations
which
explicitly
treat
the
single
cluster
service
differently
from
multi-class
service,
for
example.
Well,
we
know
that
the
application
has
to
specifically
do
a
dns
query
with
a
different
fqdn
to
find
out
the
the
multi-cluster
flavor
of
that
service
and
there's
a
different
fqdn.
B
C
All
valuable
threads
that
that
need
to
be
chased
down
at
some
point
we're
just
going
to
keep
things
simple,
so
yeah,
but
one
last
point
about
this
use
case
based
on
discussions
with
a
couple
of
solutions
architect.
They
they
identified
this
use
case
as
probably
the
most
important
one
okay
for
from
from
the
field
perspective.
C
Okay,
so
if
we
wanted
to
do
it,
one
way
to
do
it,
and
if
we
wanted
to
keep
multi-cluster
services
separate
from
services
again,
we
could
unify
them
as
well.
One
one
sample
yaml
would
be
you
simply
have
another
destination
select
destination
identifier,
so
you
know
as
an
example
here
a
service
import
reference.
C
C
C
C
This
is
what
we've
heard
in
some
discussions
about
wanting
administrative
or
geographical
constraints
on
where
you're
able
to
access
a
global
service
from
so
who
here
happens
to
be
a
global
enterprise
service,
it's
available
in
lots
of
clusters
and
regions,
but
the
admin
for
enterprise
cluster,
a
or
even
the
devops
for
cluster.
A
wants
application
p2
to
only
access
the
service
from
cluster
b,
but
not
access
that
same
service
from
cluster
c.
C
B
So
I'm
on
record
in
cignet
calls
and
I'll
be
on
record
again.
I
think
when
we
talk
about
multi-cluster
and
cluster
sets,
we
should
really
discourage
expressions
of
individual
clusters
you're
either
talking
about
this
cluster,
the
cluster
that
I'm
in
or
you're
talking
about
all
the
clusters
as
subjected
to
the
idea
of
sameness
as
governed
by
the
control
plane,
which
is
a
whole
lot
of
implementation.
Freedom
that
I
just
threw
in
there.
H
It
yeah
just
emphasizing
like
from
signal
type
cluster.
This
is
sort
of
the
case
that
is
like
contradictory
to
how
we've
wanted
to
position
that
if
these
are,
if
these
need
to
be
addressed
differently
for
some
reason,
then
they're
actually
different
services.
They
shouldn't
be
merged
together,
like
one
of
them
is
whatever
west
fu
and
east
foo,
or
one
of
them
is
super
secure.
C
I
hear
you
and
I'm
not
disagreeing
I'll.
Just
add
one
one
point
here
about
this.
If
you
look
at
the
multiple
clusters
within
a
cluster
set
sort
of
like
namespaces
within
a
single
cluster
or
or
even
a
single
namespace,
I
mean
today
we
have
policy
that
blocks
pod
a
in
the
same
name,
space
from
sending
to
part
b
in
the
same
name
space.
C
C
C
B
C
C
We
are
necessarily
sometimes
going
down
to
the
lowest
common
denominator
or
or
to
a
coarser
grain
level
than
we
would
like.
So
this
is
one
this
exact.
This
use
case
is
one
such
example,
so
the
first
two
use
cases
were
egress
policies
right.
The
sending
cluster
was
blocking
certain
traffic.
This
one
is
an
ingress
policy
right,
so
the
receiving
cluster
is
dropping
certain
categories
of
traffic
right,
so
cluster
c
is
receiving
both
from
cluster
a
and
cluster
b
here,
and
it
wants
to
drop
as
fine
grained
as
possible.
C
Okay,
however,
because
this
is
constrained
to
work
both
in
single
network
and
flat
network,
it
has
no
visibility
to
the
individual
pods
inside
cluster
a
so.
The
only
granularity
it
can
do
is
either
at
the
gateway
level
or
the
egress
ip
level
right
so
because
there
is
an
mcs
gateway
here
from
cluster
a
netting
all
traffic
before
it
gets
to
cluster
c.
C
Cluster
c
has
no
visibility
of
the
source
port
ips,
so
the
only
granularity
it
can
do
if
it
wants
to
work
in
every
topology,
is
by
sending
cluster
or
sending
gateway
entity
or
even
sending
eagles
gateway
ipr
entity.
Okay.
So
if
we
want
to
have
an
egress
policy
without
taking
the
next
step
of
adding
metadata
into
the
packet
which
we'll
talk
about
next,
okay,
so
here
so
far,
we
have
all
the
use.
Cases
are
in
theory,
working
with
all
common
cni's
of
today
right.
We
have
not
assumed
any
special
cni
capability.
C
C
So
this
goes
back
to
you
know
a
similar
discussion
that
sig
network
had
for
network
policy,
which
is
like
today's
network
policy.
One
of
the
questions
for
cider
based
policies
was
well.
Ciders
are
interpreted
differently,
especially
for
not
south
traffic
right,
because
if
you
have
an
english
policy
based
on
an
ip
cider,
some
cni's
or
some
knots
out
gateways
preserve
the
source
ip.
So
they
can
do
a
source,
ip
based
cider
policy,
but
not
all.
C
D
E
C
Is
part
of
the
debate?
How
much
do
we
want
to
assume
how
much
source
granularity
should
we
assume
like?
If
we
don't
assume
any
granularity,
then
it
is
the
cluster
or
egress
ipv?
If
we
assume
tagging,
then
we
can
assume
more
fine,
grained
planner.
So
it's
a
I'm
sort
of
teeing
up
these
questions
as
how
much?
How
much
do
we
want
to
assume?
Okay,
I'm
not
sort
of
being
opinionated
on?
C
B
B
B
C
If
the
policy
works
depending
upon
the
deployment
infra
but
doesn't
work
on
some
other
deployment
intra,
then
the
namespace
user
has
is
becoming
aware
of
the
deployment
infrared
he
has
to
know.
Is
this
application
getting
deployed
in
a
flat
multi-cluster
or
a
non-flat
multi-cluster?
That's
right!
I
would
consider
that
a
fail
right.
So
that's
why?
If
we
have
to
go
back
to
the
lowest
common
denominator,
you
have
to
assume
the
minimum
abilities
and
then
the.
C
B
Like
I
I'm
all
for
meeting
implementations
where
they
are
when
where
they
are
make
sense,
but
I
don't
think
we
should
make
a
lowest
common
denominator
api
on
something,
that's
as
important
as
this.
That
just
gives
all
the
implementations
a
pass
and
says
you
don't
have
to
do
anything
we'll
meet
you
it's
okay.
I
think
this
is
a
place
where
we
need.
C
B
I'm
saying
we
define
an
api
that
is
rich
enough
to
satisfy
what
we
need,
considering
that
like
going
back
to
the
ingress
gateway
example
like
the
difference
in
sophistication
between
those
two
is,
is
huge.
I'm
not
talking
about
that.
Like
network
policy
is
itself
not
a
very
sophisticated
api.
I
don't
want
this
to
become
a
hyper-sophisticated
api.
B
I
don't
think
we
need
it,
but
I
do
think
we
need
it
to
be
able
to
express
what
users
would
naturally
want
to
express
in
with
the
consideration
that
they
shouldn't
need
to
be
aware
of
the
network
topology.
So,
let's
rather
than
thinking
about
well,
this
is
all
the
lowest
implementation
can
possibly
do
so.
That's
it
we're
going
to
limit
it
to
that.
Let's
think
about
what
we
would
really
like
for
users
to
be
able
to
express
right
and
sorry
cindy.
B
C
Yes,
why
is
this
thing
bouncing
around?
Okay,
the
the
use
case
d
was
okay.
You
assume
that
this
is
truly.
You
have
a
policy
that
truly
assumes
flat
network,
and
it's
a
do
everything
policy,
anything
that
you
can
do
in
a
single
cluster.
You
can
do
in
a
multi-cluster
that
assumes
the
control
plane
has
global
knowledge
that
there
is.
C
There
is
an
agent
running
on
each
cluster
that
can
query
labels
and
everything
from
every
other
cluster
sort
of
they're
it's
a
tightly
coupled
almost
like
a
single
control
plane
and
that
can
then
do
very,
very
fine-grained,
multiness
multi-cluster
network
policies.
That
is
also
by
the
way
what
cilium
does,
because
they
have
actually
a
shared
control
plane
with
global
knowledge.
So
that
could
be
another
thing
I'll
stop
here.
E
C
It's
either
flat
or
at
a
minimum
it
assumes
there's
a
globe
controller.
Centralized
there
is
a
control
plane
which
has
global
knowledge.
Yes,
that's
requirement.
Number
one
and
requirement
number
two:
is
that
you've
got
tagging
capability
in
the
data
plane
that
any
kind
of
source
classification
can
be
conveyed
to
the
destination
cluster
through
some
metadata?
E
Right
and
the
control
plane
requirement.
I
guess
when
you
say
global
control
plane
it's
I
mean
it
could
be
a
mesh
and
whatnot,
but
it's
just
one
option
you
mean
right.
I
mean
you
have
a
cluster
set,
which
means
that
you
know
all
the
control
planes
in
the
cluster
set
and
not
necessarily
need
to
be
like
a
hub
and
spoke
thing
right.
C
B
Okay,
tim,
you,
you
wanted
to
add
something
go
ahead.
Please
I
mean
I
guess
I
wanted
to
talk
mostly
to
your
to
your
option
d
there,
which
is,
I
would
like
to
explore
and
consider
a
model
where
we
assume
that
the
same
network
policy
api
works
for
a
single
cluster
and
multi-cluster
there's
no
new
api.
B
Maybe
we
extend
that
api
to
make
it
easier
to
cover
right
so
like
one
of
the
things
we
had
suggested
was
what,
if
we
defined
this
in
terms
of
service
accounts
right
like
would
that
make
life
easier?
At
least
service
accounts
have
the
nice
property
that
they
don't
change
over
time
right
for
a
given
workload?
Is
that
a
simplifying
assumption?
B
Maybe
we
don't
need
it,
but
maybe
it
would
help
right
and
can
we
make
the
same
api
work
for
both
cases
so,
like
specifically
focused
on
the
multi-cluster
sig
work
right,
so
every
cluster
exists
in
a
cluster
set,
whether
it's
actually
defined
that
way
or
whether
it's
just
like
a
virtual
cluster
set.
That
happens
to
be
exactly
this
one
cluster
like
it
does
exist
in
a
cluster
set
and
within
that
cluster
set.
B
It
has
there's
some
implementation
freedom
there
and
then,
when
I
write
a
policy
write
a
network
policy
that
says
to
this
set
of
workloads
from
namespace
fubar.
When
I
say
fubar,
I
really
mean
the
cluster
sets
fubar
right.
If
it's
enabled
right
and
the
way
I
get
that
policy
across
my
entire
set.
Is
I
copy
the
same
policy
into
each
cluster
right?
B
They
could
be
theoretically
running
on
istio
and
istio
could
be
sticking
a
sidecar
proxy
and
capturing
the
traffic
and
doing
whatever
its
own
gateway
mechanisms
do
to
get
the
traffic
across
between
the
clusters,
like
all
of
those,
are
valid
implementations,
and
then
I
would
like
to
see
like
what
doesn't
work
about
that.
What
what
breaks
down
right,
the
obviously
the
naive
implementation
in
flat
mode
would
be
to
just
copy
information
from
all
clusters
to
all
other
clusters,
and
you
know
what
honestly.
I
bet
that
works
for
a
large
body
of
users.
B
It
won't
work
at
scale,
but
I
bet
for
those
you
know
90
of
kubernetes
users
who
have
less
than
20
nodes
in
their
cluster.
I
bet
it
would
work
or
20
less
than
20
clusters.
I
bet
it
would
work,
but
it
also
gives
us
a
lot
of
freedom
to
implement
creatively
right
and
I
want.
I
want
to
give
implementers
the
opportunity
to
show
their
stuff.
B
We
are
again
no,
not
necessarily
right.
There
is
a
control,
plane,
I'm
hand
waving
a
lot
like.
Actually
I
don't
know
if
you
can
see
it
because
your
slides
are
up,
but
I'm
actually
waving
my
hands
around,
because
there's
a
control
plane
and
that
control
plane
needs
access,
that
control
plane
might
be
one
cluster
or
it
might
be
a
cluster
with
a
failover
or
it
might
be
all
of
your
clusters.
That
is
an
implementation
choice
that
I
don't
feel
equipped
to
decide
here
or
it
might
exist
outside
of
any
of
your
clusters
right.
C
C
B
Thesis,
I'm
I'm
hoping
and
I'm
willing
to
go.
Well,
I
mean
I
see
andrew
laughing,
but
like
this
is
the
r
part
of
r
d
right.
We
we
need
to
go
tr
prove
that
the
simple
thing
doesn't
work
before
we
engage
in
the
complex
thing,
and
I
have
this
this
nagging
feeling
that
I
think
it
does
work
or
that
it
can
be
made
to
work
the
the
sorry
sanjiv
I
lost
the.
I
lost
the
question,
so
it
is.
A
And
prove
that
it's
possible-
I
mean,
I
guess
it's
that
question
of
how
much
are
we
hand
holding
or
thinking
we're
handling
cni's
in
api
development
or
how
much
are
we
generating
something
that
we
think
solves
all
the
needs
and
is
possible,
possibly
is
possible
to
implement
and
then
give
it
to
the
cni?
It's
very
give
it
to
the
implementers,
which
I
think
it's
better
to
do
the
latter,
but.
C
A
B
Look
if
I
have,
if
I
have
this
island
mode,
multi-network
thing,
and
I
want
to
teach
it
about
multi-cluster
networking,
a
multi-cluster
policy
like
maybe
I
have
to
encapsulate
the
packet
when
it
leaves
the
cluster,
because
that's
the
only
way
I
can
carry
information
to
the
other
cluster.
Like
that's
a
valid
implementation
choice.
Yes,
we're
putting
some
hardship
on
the
implementations,
but
it's
better
than
putting
the
hardship
on
the
users.
B
C
We
we
don't,
I
think,
the
current
network
policy
api
does
things
that
we
we
don't
actually
need.
I
mean
it's
it.
Firstly,
it's
everything
is
brought
to
participate
to
power
right
and
I
think
that's
not
an
ideal
model
in
every
case
like,
for
example,
if
we
wanted
to
implement
multi-cluster
network
exactly
like
you
know,
today's
single
cluster
policies,
it's
basically
a
full
cross
product
between
every
every
part
that
matches
the
source
selector
and
every
part
that
matches
the
destination
selector.
C
B
That's
right,
a
really
naive
implementation
here
goes
to
each
cluster
and
it
says:
okay,
give
me
all
the
pods
that
match
this
service
account
for
each
for
each
cluster.
For
each
policy
give
me
the
pods
that
match
this
service
account
in
other
clusters,
compile
an
ip
set
of
those
ip
addresses
and
install
some
ip
tables
rules
right,
and
that
sounds
great
when
you're
talking
small
numbers-
and
it
will
obviously
blow
up
in
your
face
when
you're
talking
about
big
numbers
right,
but
it's
like
demonstrably
doable.
C
B
B
I
would
put
let's
figure
out
if
the
existing
network
policy
can
be
made
to
work
first,
because,
like
ergonomically,
it
feels
better
to
me
and
I'm
totally
happy
for
people
to
argue
with
me
right
in
parallel
or
in
sequence,
we
could
explore
what
would
a
service
oriented
policy
api,
look
like
both
for
single
cluster
and
for
multi-cluster
right
and
if
we
can
agree
on
what
the
semantics
of
that
are
and
if
it
turns
out
that
that's
actually
way
easier
to
do.
Multi-Cluster
with
okay,
I'm
cool
with
that.
B
C
Dan,
let's
try
to
wrap
this
up.
Y'all!
Okay,
so
is
the
takeaway
here
that
and
definitely
all
points
are
perfectly
valid
and
good
points
thanks
everybody
if
we
can
make
something
like
use
case
d,
work
or
d
d,
prime
whatever,
which
is
reuse.
The
existing
network
policy
api
figure
out
what
it
takes
in
terms
of
a
quote:
unquote:
global
control
plane
or
how
much
do
we
need
to
define
or
not
define
how
each
cluster
knows
about
each
other
cluster
and
then
just
throw
some.
B
B
If
we
said
here's
a
subset
of
what
of
the
regular
network
policy
api
that
was
known
to
work
across
clusters
right,
I
think
that's
an
okay
starting
point.
In
fact,
I
think
it's
worth
doing,
because
I
think
revisiting
network
policy
as
an
api
is
worthwhile
anyway
right,
because
we've
learned
a
lot
of
lessons
since
then.
C
B
I'd
like
to
I'd
like
to
know
that
it
with
confidence
that
it
is
implementable
and
to
do
that
really
means
we
must
implement
it
at
least
one
time
right,
but
I
feel
like
at
small
scale.
This
is
not
a
very
complicated
program
that
I
could
write
against.
My
local
cube,
config,
just
to
say,
like
here,
is
a
demonstration
that
this
idea
of
a
control
plane
works,
but
also.
I
think
that
if
we
look
at
like
istio
and
the
way
istio
works,
we
already
kind
of
have
a
demonstration
of
it.
B
It's
not
exactly
mapping
and
it
doesn't
consume
this
api.
But
its
semantics,
I
think,
are
pretty
similar
right,
which
I
count
as
actually
a
point
in
favor
like.
If
this
can
be
a
step
on
the
way
towards
something
bigger
and
richer.
Then
that's
a
win
right
because
I
know
I
don't
know
you
guys,
but
I
talk
to
a
lot
of
customers
who
want
istio
but
are
intimidated
by
the
adoption
curve
of
it
and
so
giving
somebody
a
step
towards
that.
B
C
C
D
C
But
at
a
minimum
you
need
to
know
how
much
context
can
be
sent
from
a
source
cluster
to
a
destination
cluster
like?
Is
it
a
32-bit
worth
of
context?
And
how
does
that
translate
into
the
api?
Because,
like
today's
today's
network
policy,
api
doesn't
have
a
notion
of
a
cluster
id
right.
So
if
we
say
that
we
want
to
use
the
semantics
exactly
like
today's
network
policy
api
but
say
I
want
to
drop
traffic
coming
from
clusters
with
label
a
and
namespaces
with
label
b,
that's
a
new
semantic
that
is
not
there.
B
Have
to
have
so
that's
true,
there's
no
there's
no
cluster
object,
and
so,
if
that
does
turn
out
to
be
a
requirement-
and
I
will
fight
hard
against
it.
But
if
it
does
turn
out
to
be
a
requirement,
then
we
you're
right.
We
need
to
answer:
where
does
that
information
come
from
and
how
does
it
get
sort
of
cooked
down
into
something
that
a
data
plane
knows
how
to
use.
C
B
C
H
B
An
establishment
I
just
feel
like,
I
need
to
repeat
like
if
somebody
wants
to
explore
what
service
policy
would
look
like.
Maybe
it's
an
entirely
distinct
api
from
network
policy
like
let's
cut
cut
bait
when
we
have
to
right
as
an
entirely
distinct
api.
What
would
the
semantics
of
a
service
policy
api
look
like
and
how
do
we
handle
those
corner
cases
of
multiple
conflicting
service
policies?
A
B
B
A
A
Sure,
on
that
too,
I
I
would
like
to
wrap
it
up.
I
know
everyone's
super
busy
and
we're
18
minutes
over
so
but
thanks
so
much
for
coming,
everyone
really
appreciate
it.
It
was
some
good
conversation
yeah.
We
can
keep
doing
this
in
this
meeting
slot.
If
we
would
like
happy
to
happy
to
keep
it
running,
yeah.