►
From YouTube: Summit 2022: Live Migration Policies
Description
No description was provided for this meeting.
If this is YOUR meeting, an easy way to fix this is to add a description to your video, wherever mtngs.io found it (probably YouTube).
A
Thank
you
thank
you,
and
with
this
I'm
entering
the
moderation
over
just
you
that's
true
yeah.
Thank
you
very
much.
Thank
you
all
right,
everybody
with
that.
We
are
three
minutes
into
the
next
session,
so
we'll
just
roll
on
ahead
no
break.
This
will
be
a
60
minute
session
and
itamar
holder
is
our
presenter,
so
I'll
turn
it
over
to
you.
Go
ahead.
B
B
Okay,
that's
great
so
hello,
everyone,
itamar
holder
and
I'm
working
for
reddit.
As
a
software
engineer
and
in
this
lecture
I'll
talk
about
live
migration
policies
and
live
migrations
in
general,
I'll
have
a
general
recap
so
that
everyone
can
understand
why
we
need
this
and
what's
the
motivation
for
it.
So
let's
go
so.
This
is
the
general
agenda
I'll
be
talking
about
what
are
live
migrations?
B
Why
do
we
need
them?
Why
are
they
important?
How
do
they
work
in
general
and
the
challenges
be
behind
like
migrations?
How
do
we
solve
the
challenges
by
certain
configurations
that
we
have
in
cuber,
then
I'll
talk
about
the
problems
with
the
current
way
of
configuring
and
tuning
this
those
migrations
and
finally
I'll
get
into
the
the
solution
which
is
live,
migration
policies,
I'll
be
talking
about
policy
hierarchies
and
deterministic
matching
and
the
current
state
and
future
state
of
live
migration
policies?
B
B
B
This
is
this
might
be
a
problem
in
a
distributed
environment
with
many
moving
parts
that
are
all
dependent
on
one
another.
So
we
need
something
better,
which
is
almost
zero
downtime
and
that's
why
all
of
our
migrations
are
live
migrations,
so
basically
the
with
the
live
migrations.
There
are
two
things
that
are
happening
simultaneously.
B
The
first
one
is
that
we're
transferring
memory,
storage,
connectivity
and
all
everything
that
needs
to
be
transferred
from
the
source,
physical
machine
to
the
target
virtual
machine,
but
at
the
same
time
the
workload
keeps
running.
Therefore,
it's
changing
the
memory
and
storage
and
all
of
that,
so
so,
okay,
so
why
are
migrations
so
important
to
us
so
basically,
in
a
regular
kubernetes
environment,
we're
using
containers,
not
vms
and
containers,
are
designed
to
have
several
characteristics.
B
They
first
of
all
they're
small
they're
ephemeral,
which
means
that
their
state
is
very,
very
small
and
basically
they're
meant
to
be
moved
around
easily,
which
also
means
they
have
very
fast
initialization
time.
So
these
are
all
container
characteristics
and
the
every
container,
generally
speaking,
should
have
now
one
of
cubert's,
most
important
design
principles
is
to
be
kubernetes
native.
In
other
words,
our
goal
is
to
have
vms
and
containers
living
similar
seamlessly
together
on
the
same
platform,
which
means
that
basically
vms
need
to.
B
They
are
harder
to
move
around,
they
do
have
significant
state.
These
states
can
be
open
files
or
the
state
of
the
kernel
of
the
state
of
of
the
vm's
hardware
and
and
all
and
and
and
among
other
stuff.
So
basically,
it
has
a
huge
state
comparing
to
a
container
and
it's
not
ephemeral
and
lastly
they're
large
and
which
means
that
their
boot
time
is
much
bigger.
A
B
So
when
we're
speaking
about
containers,
basically
all
of
the
containers
are
being
moved
out
of
the
drain
node
and
that
basically
means
that
we're
deleting
all
of
them
and
starting
new
instances
in
other
places,
which
is
a
pretty
easy
task
with
containers.
So
this
is
how
it
looks
like
let's
say
you
have
node
one
and
node
two,
so
basically
we're
deleting
all
of
the
containers
in
the
first
node
and
recreating
them
in
a
second
of
course,
with
in
reality
it
it
generally
happens
gradually.
B
A
B
B
So,
basically,
first
of
all
I'll
show
the
three
steps
which
are
common
to
every
migration
that
we're
going
to
have
so.
First
of
all,
the
first
step
is
to
basically
create
another
vm
instance
at
the
target
node,
which
is
pretty
similar
to
the
to
the
first
step.
We're
doing
with
containers
simply
create
the
metal
sword.
The
second
part,
which
is
very
different
from
regular
containers,
is
that
we
have
to
move
the
state
around
from
the
first
vm
to
the
other
one.
B
So
in
kubert
we
basically
establish
a
communication
between
two
of
those
vm
instances
and
where
the
state
is
being
transferred
from
the
source
vm
to
the
target
field
and,
finally,
again
like
containers,
we
simply
remove
the
source
vm
and
let
the
target
vm
run.
So
this
brings
up
a
few
challenges.
So
the
fundamental
challenge
with
migrations
is
that
basically,
that
memory
keeps
changing.
B
B
Is
that
the
mem,
this
whole
process
will
never
converge
and
this,
and
this
can
be
caused
by
frequent
rights
to
the
memory,
but
first,
let's
be
optimistic
and
show
the
happy
path.
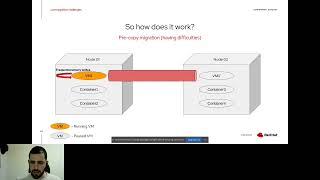
So
this
is
a
pre-copy
migration.
This
is
a
the
default
migration
and
basically,
if
nothing
wrong
happens,
so
this
migration
should
be
converted
successfully.
B
So
what
we're
doing
here
is
basically
we're
creating
the
target
vm
instance
on
the
target
node
and
we're
running
on
the
source
vm
and
now
what
hap
what's
happening
is
that
we're
transferring
all
of
the
state
to
the
target
node
where
the
state
is
transferred
completely?
And
so
we
we
start
the
running
on
the
target
vm
and
delete
the
source
view,
and
this
is
all
great
but
again
with
frequent
rights.
B
Migrations
can
be
stuck,
and
the
main
problem
is
that
while
we
transfer
a
memory
block
from
the
source
to
the
target,
it
can
be
mutated
at
the
time
we're
transferring
it.
This
means
we
have
to
copy
the
block
again
and
the
scenario
can
occur
over
and
over
causing
migrations
to
hack,
which
is
basically
a
problem.
B
B
So
the
source
vm
starts
running
with
100
the
cpu
and
over
time
we
decrease
the
cpu
or
throttle
it
to
the
point
that
it
can
converge
and
all
of
the
memory
state
is
being
transferred
into
the
target.
And
then
we
are
running
on
the
target.
We
can
remove
the
source
vm
and
the
migration
is
done,
so
it
has
a
pros
and
cons.
So
the
pro
is
that
basically,
convergence
is
guaranteed.
B
Eventually,
if
we
throttle
the
cpu
enough,
we
guarantee
that
the
rights
aren't
that
frequent,
and
that
means
that,
basically,
eventually
the
migration
will
will
end,
it
will
never
hang
forever.
Another
pro
is
that
it
it's
completely
safe,
we
don't
risk
anything
and
another
pro
is
that
if
the
migration
is
fast
enough,
we
don't
throttle
the
cpu
and
the
migration
is
basically
acting
as
a
as
a
regular
pre-copy
migration.
B
So
we
have
another
way
to
deal
with
this,
which
is
a
pulse
copy.
Migration
and
a
possible
copy.
Migration
basically
means
that
we're
as
we
create
the
new
the
target
vm
we're
start
start
running
on
it
right
away.
The
idea
is
that
if
the
vm
tries
to
access
a
page,
it
does
not
own,
which
is
basically
a
page
fault.
It
asks
for
the
source
vm
to
transfer
it
explicitly.
B
If
the
target
vm
does
not
ask
for
pages
explicitly,
which
means
that
it
runs
on
the
memory
blocks
it
already
have,
then
other
pages
are
being
transferred
in
the
background
until
all
the
memory
is
transferred.
So
let's
do
look
at
on
on
how
it's
done.
So,
basically,
we
create
another
instance
at
the
target
node
and
this
instance
starts
running
immediately
once
this
that
the
target
vm
tries
to
access
a
memory
does
not
own.
There
is
a
page
fault.
B
B
So
the
pros
here
is
that
again,
every
page
is
transferred
only
once
because,
unlike
pre-copy
migrations
what's
happening
is
that
if
the
page
is
being
mutated,
we
don't
care,
we
don't
have
to
transfer
it
again,
because
it's
being
mutated
at
the
vm
that
that
is
actually
running
the
workload
now.
Another
advantage
is
that
the
migration
always
never
hangs
and
we
are
using
less
network
bandwidth,
but
we
have
serious
cons
here.
The
first
one
is
that
it's
pretty
dangerous
to
do
so.
B
That's
because
we
don't
have
any
vm
instance
that
has
the
full
desired
state.
So,
for
example,
what
happens
if
one
node
crashes,
we
can't
recover
the
vm,
because
every
vm
instance
holds
only
a
partial
state
of
the
of
the
vm.
Another
con
is
is
a
slow
warm-up
at
first.
Basically,
when
the
then,
when
the
target
vm
just
starts
running,
we
will
most
centrally
hit
a
page
fault,
because
we
don't
have
any
memory.
B
So
at
the
beginning
there
will
be
a
lot
of
page
faults
which
basically
will
is
a
blocking
operation.
We
will
stop
the
workload
because
it
cannot
continue
and
the
it
will
wait
for
the
the
block
to
be
transferred,
and
another
con
is
that
in
general,
in
the
average
use
case,
it's
it's
a
slower,
it's
a
slower
mode,
it's
lower
migration
mode.
A
B
There
is
no
best
configuration
for
all
use
cases,
so,
to
sum
up
everything,
I've
just
said
so
with
three
rules
of
thumb
that
are
not
really
100
accurate,
but
if
the
vm
is
running
it
is
not
performing
frequent
rights
to
the
memory
we
might
use,
we
might
be
prefer
using
pre-copy
migration,
which
is
the
safest
and
fastest
in
the
average
use
case.
If
we
are
having
a
frequent
rights
to
the
memory
and
we're
okay
to
risk,
the
workload
post
copy
sounds
great.
B
B
So,
in
order
to
tune
these
configurations
properly,
one
needs
to
understand
the
priorities
of
the
vms
that
are
running
in
the
clusters
and
what
the
vms
are
doing.
What
are
the
exact
workloads
that
are
occurring
inside
these
vms,
and
what
is
the
environment
is
the
network
strong
is,
is
the
network
fast
so
basically
to
tune?
All
of
these?
You
pretty
much
have
to
be
an
expert.
You
have
to
understand
the
environment,
you
have
to
understand
the
different
configurations
and
not
everyone
can
do
so.
B
So
what
is
what
do
we
have
today
and
by
today
I
mean
before
live
migration
policies,
so
cooperate
allows
to
tune
migration
configs,
but
only
cluster
wide
through
qpcr,
so
basically
kubrick
cr
for
the
ones
that
don't
know
is,
is
the
place
when
you
can
have
the
the
specifications
cluster
right
for
kubrick.
So
this
means
that
you
cannot
specify
different
configurations
for
different
vms,
and
this
is
very
probably
problematic,
because
the
configurations,
as
we
just
saw,
are
very
tied
up
to
the
workload
that's
running
inside
of
the
vm.
B
So
what
do
we?
What
do
we
need?
What
what
do
we
want
to
have?
So,
on
the
other
hand,
we
don't
want
vm
creations
or
vm
migrations
to
be
very
complicated,
so
we
don't
want
somebody
to
to
consider
all
of
this
in
order
to
create
a
vm
or
to
migrate
again,
and
it
would
be
best
if
somebody
some
expert
system
would
mean-
or
somebody
will
basically
tune
the
the
the
right
configurations
and
when
someone
creates
a
vm
and
tries
to
migrate
it.
B
What
will
happen
is
that
magically
the
best
configuration
will
be
matched
to
the
vm
migration
to
me,
specifically,
it
reminds
a
bit
of
security
policies
like
I
see
linux,
so,
for
example,
if
I
open
up
my
fedora
and
start
editing
files
or
creating
folders
or
whatever,
I
am
bound
up
to
a
certain
security
policies,
I'm
not
aware
of
them.
I
don't
care
about
them,
but
I
I
am
matched
to
some
security
policy
that
somebody
that
is
more
expert
than
me
on
the
matter
defined
beforehand.
B
B
Maybe
under
the
production
we
have
back-end
components
and
front-end,
we
should
use
what
dedicated
network
and
not
to
use
dedicated
network
inside
of
them.
We
could
have
different
apps
or
microservices.
That
would
also
be
using
different
configurations.
So,
as
you
can
see,
the
the
the
nice
thing
about
here
is
the
hierarchy,
so
the
the
vms,
just
a
vm,
regular
vm
under
production,
would
have
unlimited
bandwidth,
but
a
vm
under
production.
It's
also
an
engine
vm
would
have
post
copy.
B
B
So,
as
I
said,
the
most
detailed
policy
has
the
highest
precedence.
This
means
that
it's
possible
to
have
more
confined
policies
for
more
specific
scenarios
and
the
detail
level
is
simply
the
number
of
required
labels
and
again
they
all
have
to
be
matched.
If
one
label
does
not
match
the
policy
is
not
matched,
and
maybe
the
name.
Space
and
and
vmi
labels
have
the
same
weight.
They're.
B
So
if
we
have
two
policies
with
the
same
detail
level
that
are
matching
to
the
to
to
a
migration,
we
simply
sort
the
the
matching
migrations
by
lexicographic
order
of
the
name
and
choose
the
first
one.
This
is,
of
course,
somewhat
of
an
arbitrary
decision,
but
it
does
guarantee
that
the
matching
mechanism
is
deterministic,
so
the
current
state
is
that
law
migration
policies
are
implemented
and
merged
and
are
part
of
keyword
for
49
release.
B
A
B
B
After
that
there
is
a
another
policy
that
is
supposed
to
match
a
db
vm,
which
is
basically
again
more
detailed
than
the
first
policy.
We
will
see
that
these
configurations
apply
and
again
the
ones
that
are
not
listed
here
are
applied
from
the
keyboard
cr
and
just
a
quick
word
about
this
configuration
which
I
didn't
mention
is
basically
the
amount
of
time.
We
have
to
wait
per
gigabyte
until
we're
transferring
into
postcopy
migration,
basically
for
the
demo
purposes.
We
can
just
accept
it
as
it
is
okay.
B
So,
let's
begin
so,
first
of
all,
we'll
post
them
their
production
name
namespace.
This
is
a
regular
kubernetes
namespace
and,
as
you
can
see,
we
have
a
label
that
says
type
production.
The
name
of
the
namespace
is
intentionally
different
to
emphasize
the
fact
that
the
policies
aren't
being
matched
to
namespaces
by
names
or
anything
they're
only
being
matched
by
labels.
B
B
B
Okay,
so,
first
of
all
we're
turning
on
the
live
migration
feature
gate.
This
is
just
because
we
want
to
use
like
migrations,
and
we
have
to
enable
the
feature
gate
in
order
to
use
them.
And
finally,
this
is
the
migration
configuration
so
first
of
all
we're
making
a
pre-copy
mode
as
the
configuration
here.
B
This
is
being
done
by
simply
turning
off
auto
conversion
post
copy.
If
they're
both
turned
off
then
the
default
one
is,
is
a
pre-copy
migration
and
also
as
as
I
showed
in
the
presentation,
we
have
another
two,
which
is
the
bandwidth
on
migration,
which
is
100
gigabytes
and
the
completion
timer
per
gigabyte,
which
is
one
and
a
half
k.
B
B
Okay,
so
now
taking
a
look
at
the
actual
policies,
so
we
have
again
a
policy
for
the
dbvm
and
a
policy
for
the
production
namespace.
So
let's
have
a
look
so
the
production
policy.
Basically,
as
we
saw
earlier,
there
are
two
sections.
The
first
one
is
the
the
configuration
itself,
which
is
that
the
bandwidth
is
20
just
like
show
here
and
now
we're
matching
it
only
to
a
namespace
by
the
type
reduction,
as
we
saw
earlier.
That.
B
A
B
B
B
A
B
B
B
B
So,
as
you
can
see,
the
vm
is
now
in
node,
two,
not
node
one,
which
means
that
the
migration
is
is
done
and
we
can
have
a
look
on
what
configuration
actually
applied.
So,
let's
take
a
look
on
the
section
here,
so
basically,
the
migration
state
shows
us
all
of
the
different
configurations
that
were
used.
So
as
we
can
see
the
auto
convergence,
the
pulse
copy
are
both
false
as
we
expected
from
the
keyboard
cr
which,
because
we
wanted
to
use
pulse
copy,
it's
pre-copy.
Sorry.
B
B
B
A
B
A
Hi
adam
there
were
a
few
questions
in
chat,
but
because
the
chat
will
not
be
part
of
the
recording,
please
allow
me
to
recap
real
quickly.
The
discussion
that's
gone
on
andre
had
asked
if
it's
possible
to
live
migrate,
a
vp,
a
vm
when
using
a
vgp
or
excuse
me
a
gpu
and
the
the
general
answer.
There
is
no
because
we
cannot
copy
the
memory
of
the
device.
It's
not
possible
to
do.
The
the
migration
itself
follow
on
question.
Was
it
the
same?
B
B
I'm
not
sure
what
you
mean
by
that,
because
in
a
drain,
where
basically
moving
all
of
the
vms
out
of
the
node,
but
maybe
maybe
the
question
is
which
vms
to
to
drain
first,
but
either
way,
we
don't
support
it
right
now,
but
again
this
this.
This
feature
is
in
very
early
stages,
so
we'll
be
happy
to
to
have
new
ideas
from
the
community
so
you're
more
than
welcome
to
participate
in
this.