►
From YouTube: Meshery Development Meeting - April 22nd, 2020
Description
25 attendees to the @mayadata_inc presentation of @LitmusChaos this week. Thank you @ksatchit and @rajdas98!
B
Thank
you
before
I
tell
you
what
I
just
I
think
I
tried
to
make
a
little
joke
the
other
day
about
this,
and
that
is
that
there's
like
there's
I,
don't
know
there.
I'm
gonna
make
up
that.
There's
like
some
30-second
rule,
if
you're
only
if
you're
talking
to
yourself
for
less
than
30
seconds,
you
are
not
a
narcissist,
but
if
it
goes
on
longer
than
that,
and
maybe
maybe
you've
got
some
issues
so
I
was
well
within
the
30-second
mark
of
that
of
that
issue.
B
D
B
B
Good,
oh
all,
right
I'm,
looking
at
the
participants
list,
oh
thank
you
should
buy
and
yep
it
is
I
am
in
the
earliest
time
zone,
so
I'm
the
one
with
coffee
in
their
hand,
I'm
the
one
that
gets
to
talk
to
themselves
on
a
mute
this
morning.
I
guess
so.
Nice
new
pour
shared
the
meeting
minutes.
Please
everyone
jump
into
the
meeting
minutes.
If
you
don't
have
access,
please
request
it
I
think
everyone
here
should
I
see
all
familiar
names.
There
are
a
couple
of
us
that
are
I'm
new
to
the
call
today.
B
There's
we
have
one
topic
lined
up
today
and
then
I,
thought
or
I
know.
We
also
have
a
number
of
other
things
to
discuss,
but
I
don't
know
that
they're
listed
in
the
topics.
So,
if
you
have
something
to
discuss,
please
be
sure
to
put
it
into
the
topic
list
today,
given
that
there's
an
even
if
there's
a
few
of
its
time,
you
let
me
introduce
this
call
a
little
bit
and
say
that
this
is
our
weekly
development
call.
This
call
ends
up
being.
B
B
Sorry,
let
me
let
me
freighter
it
like
this:
hey
welcome
everyone.
We've
got
a
great
couple
of
topics
set
up,
the
first
of
which
is
a
presentation
and
discussion
of
littmus
chaos.
Where
we're
we
had
a
small
one
in
the
past
from
from
garage
and-
and
we
actually
gave
him
more
than
a
five
minutes
heads
up
this
time
to
maybe
come
in
and
spend
some
time
explaining
the
project
to
us
for
fortunate
that
we've
got
a
few
new
faces
this
morning.
B
F
C
I
mean
pretty
excited
to
join
your
meeting
today.
You
know
I
mean
I
have
been
following
your
the
the
workshop
that
you
gave
in
O'reilly
and
then
I,
you
know
like
I
can
say
it
is
because
of
you.
I
got
introduced
to
service
smashed
and
then
yeah,
so
I'm
working
for
Ericsson
as
a
cloud
architect
and
I'm
working
for
my
client
AT&T.
So
I
am,
you
know
completely
devoted
towards
the
cloud
design
architecture
in
AT&T
and
the
reason
for
getting
involved
in
service
mesh
is.
C
We
are
thinking
about
introducing
service
mess
in
AT&T
and
we
want
to
introduce
it
firstly,
for
the
telecommunication,
you
know
network
functions,
so
they
used
to
be
like
virtual
network
function
on
top
of
OpenStack,
and
then
we
are
thinking
about
converting
all
of
those
into
micro
services.
And
now,
when
we
are
making
it
into
micro
services,
then
you
know
the
requirement
to
use
service
mesh
that
is
coming
up,
but
obviously
there
is
lot
of
challenge
to
convince
because
there
are
a
lot
of
people
like
in
operations,
security,
the
tenants
themselves
and
also
the
development
team.
C
So
there's
lot
of
challenge
to
convince
why
we
should
implement
service
mess
considering
there
are
a
lot
of
you
know,
lot
of
overheads,
which
is
associated
with
introducing
service
mesh
like
the
latency
and
the
additional
resource,
CPU
memory.
All
these,
so
you
know
I'm
like
trying
to
understand
what
I
can
do
to
you
know,
convince
them
and
also
introduce
it
to
our
organization.
Sorry
for
taking
lot
of
time,
but
I
think
he'll
stop
yeah.
You.
B
Know
we
you've
been
being
talked
about
a
couple
of
times.
We're
excited
that
you're.
You
are
involved
here
in
the
community
here,
I'm
gonna
I
have
I,
have
a
bunch
more
things
to
say
about
what
you
just
said,
but
I'm
gonna
bite
my
tongue
because
we're
gonna,
I'm,
gonna,
I'm
gonna
circle
back
to
you,
Sudeep
we're
gonna.
We're
gonna
spend
some
time
very
good
very
quickly.
Here.
A
G
Hi
Lee
hi
everyone,
I,
am
Karthik
I'm
core
contributor
to
the
ellipse
chaos
project
and
just
pairing
up
with
Raj.
Today,
let's
talk
about
Rick,
miss
and
also
very
excited
to
join
the
community
in
general.
I
think
there's
a
lot
that
we
can
do
to
work
together
in
terms
of
how
service,
which
can
be
integrated
with
chaos
in
general.
H
A
lead
over
yeah,
you
don't
know:
okay,
all
right,
yeah
nice
to
meet
you.
Everyone
and
I
mean
I.
Just
join
him.
I
walk
together
with
Anton
Anton
vice,
as
I
mentioned
in
no
scientist
cycle,
yeah,
I
work
for
natural
intelligence
and
DevOps
engineer.
We
are
doing
it's
a
company
that
make
a
comparison
site
like
we
have
the
blend
of
top
10,
so
we
like,
comparing
mortgage
insurance,
all
the
sides
and
giving
a
the
best
vertical
for
the
user.
H
So
yes,
because
the
Kawana,
a
lot
of
things
happening
now,
I
mean-
and
it's
influenced,
and
also
my
company
yeah
I'm,
still
walking
down
and
yeah
I
want
to
give
my
game
my
skills
and
to
see
how
can
I
contribute
to
to
measuring
in
the
way
5
and
yeah
I
work
a
lot
with
kubernetes
I
lunch
couple
of
cluster
and
building
lots
of
CIC.
Be
writing
some
blogs
and
I
hope
to
give
from
my
experience,
torso
to
level
5
and
now
to
get
into
their
service.
I
Minimal
fault
I'd
like
to
chime
in
and
say
that
I'm
very
happy
to
see
a
lead,
orator
and
he's
you
know,
he's
being
modest.
He
is
a
newcomer
to
the
mesh,
but
I've
been
working
with
him
for
the
last
year
and
he's
an
avid
learner
and
I'm
sure
very
fast
in
starting
things.
Actually
I
already
suggested
a
very
nice
but
genius
in
its
simplicity,
solution
for.
B
B
J
J
B
B
Okay,
very
good.
Let
me
let's,
let's
jump
right
in
quick
check
on
the
meeting
minutes.
Hopefully
everyone
has
access
to
those
I
suspect
we're
missing
a
couple
of
names
in
the
attendees
list.
So
please
don't
be
shy.
It
looks
like.
Hopefully
what
we
can
do
is
in
the
next
40
minutes
two
topics.
Hopefully
the
first
one
is
do
hear
more
about
missus
chaos,
project
that
we
had
been
very
briefly
kind
of
demoed
and
and
updated
about
through
garage
in
the
past
and
so
excited
to
have
Karthik
and
Raj.
A
G
G
L
G
Okay,
yeah
so
I
do
say:
petting
thanks
Lee
for
giving
us
this
opportunity
to
speak
about
lateness,
so
the
first
couple
of
slides
are
more
about
why
the
Cillian
C
is
important
and
I.
Think
a
lot
of
us
are
already
aware
of
the
needs
of
chaos.
Engineering,
I,
think
people
are
already
adopting
chaos.
Engineering
in
a
big
way.
G
Resiliency
is
something
that
you
want
to
achieve
to
keep
your
always
available
and
there's
this
slide
that
I
picked
from
an
event
that
took
place
last.
It
called
as
it
lab
commit.
So
this
is
Dan
from
the
scene
see
if
explaining
how
your
code
is
most
promptly
going
to
be
deployed,
and
you
can
see
in
this
pyramid
I'm
sure
it's
a
little
bit
grainy,
but
added
me
for
that.
G
So
when
you
deploy
this
say
you
have
the
URL
next
VM
you
have
kubernetes
on
top
of
that,
and
then
you
have
your
application
platform
and
then
your
actual
code,
so
there's
a
lot
that
can
go
wrong
in
the
long
run.
So
there
is
some
systems
that
need
to
be
put
in
place
to
ensure
that
your
resiliency
is
well
tested,
and
one
of
those
things
is
to
have
chaos.
Engineering,
I
think
there
is
a
paradigm
shift.
That's
happened
in
the
last
few
years,
I
think
since
Netflix
and
others
have
really
started
it.
G
So,
apart
from
the
integration
tests
that
you
would
do
in
your
pipelines,
you
probably
go
ahead
and
do
some
chaos
testing,
which
can
be
considered
like
an
extended
e2b.
Some
part
of
it
in
your
pipelines,
OCD
or
people
are
actually
doing
it
on
staging
and
production
is
so.
The
usual
engineering
loop
is
like
this
there's
a
lot
of
firefighting
involved,
but
with
chaos,
engineering,
you're,
sort
of
vaccinating
yourself.
You
are
trying
to
inject
faults
from
time
to
time
to
see
how
your
system
behaves.
G
There
are
a
lot
of
practices
around
case
engineering
people
who
gamedays
people
are
doing
continuous
or
background
chaos
in
their
staging.
So
you
keep
analyzing
your
system,
you
keep
injecting
faults
and
then
probably
going
ahead
and
fixing
them.
So
this
is
generally
an
introduction
to
chaos.
Engineering.
It
really
don't
want
to
tell
too
much
into
that.
G
G
So
when
we
started
open
abyss,
we
needed
a
way
to
ensure
the
reliability
of
the
container
a
storage
platform,
and
then
we
got
started
with
some
failure,
testing
which
slowly
slowly
evolved
into
an
actual
chaos
framework,
and
then
we
thought
that
something
that's
going
to
be
useful
to
the
community
at
large,
not
just
for
opening
peers.
That's
when
we
sort
of
put
it
out
as
litmus
chaos.
Sumaya
data
is
the
primary
sponsor,
but
there
is
there
are
contributions
coming
in
from
other
organizations
as
well
and
the
communities
seeing
slow
but
steady
increase.
G
Just
this
light
is
just
talking
about
what
the
principles
of
cloud
native
chaos,
engineering,
I
think
when
it's
the
course
of
chaos,
engineering
itself
is
a
pretty
famous
age
and
a
pretty
famous
concept.
So
we
just
wanted
to
insert
the
cloud
natives
there.
So
a
lot
of
us
are
on
kubernetes
I.
Think
the
world
is
moving
towards
Kuban,
it
is,
and
if
you
have
to
define
cloud
native
clay,
you
are
actually
intending
to
say
it
is
Cuban.
It
is
native.
G
What
is
popularly
known
today
as
customer
resources
and
communities
which
are
also
exposed
as
AP
ice,
and
it
should
be
a
framework
into
which
you
can
integrate
other
chaos
tools
or
other
video
testing
mechanisms,
instead
of
being
something
in
its
silo
that
you
can
use
them
in
a
separate
stack
is
something
that
should
be
allowed
to
integrate
with
other
tools
that
are
not
ready
bit.
So
this
is
how
we
thought
about
RIT
--mess
and
the
framework
sort
of
has
come
up
following
these
principles,
and
this
slide
is
just
representing
what
people
are
already
used
to.
G
Let's
say
you
have
a
pod,
you
have
an
application
and
then
you
are
having
a
position
to.
Are
you
manned?
You
have
a
lot
of
such
Native
communities.
Resources
scope
is
a
which
is
describing
your
deployment,
and
then
you
want
to
go
and
inject
chaos
on
this
application
right
and
you
would
want
an
interface,
a
user
interface,
that's
very
similar
to
what
you
already
have.
G
You
want
chaos,
definitions
to
be
declarative,
you
want
it
to
be
something
that's
reconciled
or
we
want
to
have
a
controller
associated
associated
with
this
source,
which
is
actually
helping
you
inject
defaults.
You
want
to
trying
to
give
you
the
visualization
of
what
happened
to
an
experiment.
All
that
needs
to
be
controlled,
so
we
came
up
with
a
custom
resource
and
that
is
trying
to
follow
the
same.
You
know
format
or
the
same
interfaces
as
the
other
kubernetes
resources
do
for
chaos,
so
this
chaos
engine
is
one
such
example.
G
It
is
basically,
we
are
going
to
speak
in
a
moment
about
what
chaos
engine
is
and
what
are
the
other
customer
resources
associated
with
Ditmas,
but
this
is
generally
trying
to
make
a
point
about
how
people
it
is
native
chaos.
Engineering
should
look
like
so
the
next
one
is
just
trying
to
dig
into
water
uses.
Experience
would
be
with
litmus
and
not
going
to
the
architecture
upfront.
Rather,
they
would
just
want
to
introduce
what
users
interaction
of
flow
would
be
with
witness.
G
So
you
have
for
your
applications
and
then
you
have
a
hub
just
like
the
hell
hub
or
the
artifact
tab.
What
would
you
would
like
to
call
it
the
operator
hub,
so
you
have
a
set
of
off-the-shelf
chaos,
experiments
that
you
can
actually
use.
You
could
write
your
own,
but
there
are
a
lot
of
experiments
which
you
could
use
straight
away.
So
a
user
typically
I
read
a
sorry
who
is
the
prime
user
of
such
chaos
frameworks?
G
One
would
say
they
are
the
person
of
being
the
developers,
so
an
SRE
would
actually
go
looking
for
a
set
of
experiments
which
he
or
she
would
find
most
apt
for
his
deployment
environments
would
actually
pull
those
experiments
er's
and
these
experiments
ears
are
nothing
but
low
level.
Definitions
of
an
experiment
of
chaos
injection
it
talks
about
what
are
the
two
devils
of
parameters
would
like
to
pass
in
order
to
actually
successfully
run
a
chaos
experiment.
G
So
once
these
experiments
years
are
pulled,
you
would
like
to
tune
them
for
some
parameters,
which
is
specific
to
your
cluster
or
your
deployments,
and
then
you
create
another
resource
called
as
chaos,
engine
which
is
actually
time
together.
Chaos,
experiment,
low
level,
chaos
definition
to
an
existing
instance
of
your
application.
So
you
might
use
the
same
chaos
experiment
in
a
different
way
against
two
different
applications
on
your
cluster.
G
So
you
have
the
flexibility
if
you
nee
in
the
chaos
engine
which
basically
ties
together,
it
experiment
with
your
app
instance,
and
then
there
is
a
host
of
things
that
happen
afterwards.
That
is
mostly
taken
care
by
litmus.
It
will
actually
execute
it
and
show
some
results
and
for
some
metrics
in
case
of
a
developer's
experience,
it's
largely
similar
to
how
an
SRE
would
do
it,
but
you
associate
developers
tests
with
pipelines
with
lab
pipelines
or
you
might
have
your
github
actions,
for
example.
G
So
you
typically
add
a
chaos
stage
to
your
pipelines,
which
are
already
doing
let's
say
some
mitigation
on
unit
tests.
So
these
chaos
stages
implement
litmus
chaos,
experiments
and
these
experiments
could
be
something
that
you
wrote
yourself
for
your
application,
business
logic
and
something
that
is
very
specific
to
your
application
and
may
not
really
be
there
on
the
hub,
for
example,
or
you
could
take
what's
in
the
hub,
develop
over
it.
Ultimately,
it's
your
own
version
of
the
experiment
and
you
could
actually
go
ahead
and
put
that
back
to
the
chaos
once
an
open-source
karma.
G
For
example,
let's
say
you
have
an
application
which
is
pretty
popular
and
a
lot
of
people
are
using
it
and
as
a
developer,
you
wrote
some
resiliency
tests
to
test
in
that
application,
and
you
feel
it's
going
to
be
useful
for
the
community
at
large
for
them
to
verify.
You
know
deployments
of
this
particular
application
in
their
clusters,
so
you
could
say,
set
put
there
push
them
back
into
the
chaos
from
under
a
specific
category
and
little.
He
was
it.
G
So
this
is
about
the
experience
how
a
user
would
interact
with
witness,
depending
on
what
person
he
is
in
just
to
explain
the
custom
resources
a
little
bit
and
also
probably
explain
why
they
would
be
this
way.
So
today,
like
I,
think
someone
mentioned
in
the
beginning
of
this
call
that
everything
is
a
micro
service.
G
So
the
chaos
experiment,
er,
is
the
first
custom
resource
associated
with
lateness
and,
like
it's
mentioned
here,
it's
something
that's
available
already
it's
built
and
it's
it
could
be
in
the
hub
or
it
could
be
in
your
own
repositories
and
it
contains
in
granular
definition
of
your
chaos.
Intent
so
when
you
say
chaos
intent
in
that
translates
into
what
is
the
image
that
you're
going
to
run
your
your
your
tests
or
your
chaos?
Actions
are
typically
containerized.
G
So
what
is
the
container
image,
and
sometimes
that
particular
image
has
the
option
to
choose
to
inject
chaos
in
one
or
many
ways
you
can
choose
a
library
and
what
are
the
permissions
associated
to
run
a
given
experiment,
so
each
experiment
can
be
associated
with
the
strict
set
of
permissions.
If
you
are
a
developer,
who
is
using
a
staging
cluster
that
many
others
are
using,
and
you
want
to
control
the
blast
radius
and
really
want
to
stick
to
minimum
set
of
permissions?
G
You
could
do
that
and
all
that
is
defined,
and
then
there
are
some
experiments,
specific
characteristics
like,
for
example.
If
it's
a
network,
chaos
experiment,
you
talk
about
packet,
loss,
percentages
or
network
delay
or
corruption
percentages,
something
that's
much
different
from.
Let's
say
you
poor
delete
test
for
like
how
many
times
you
would
like
to
kill
the
power
of
how
many
pods
ago,
you
would
want
to
kill
etcetera.
So
these
are
all
there
in
the
queue
experiment.
The
chaos
engine
is
basically
the
user
facing
CR.
G
It's
not
something
that
the
chaos
experiment
is
something
like
a
skeletal
piece
which
you
put
into
your
cluster.
The
engine
allows
you
to
bridge
a
given
experiment
with
an
instance
of
your
application
in
a
particular
namespace,
and
you
can
choose
to
override
certain
defaults
that
you've
already
set
in
the
experiment
here,
and
we
can
also
define
some
run
characteristics
like
whatever
resources
or
pods.
You
used
to
you
launched
to
run
the
chaos
whether
you
want
to
retain
them.
We
want
to
lead
them.
G
You
want
exposed,
matrix,
permeate
this
matrix
or
you
don't
really
want
to
monitor
you
to
Chios
instances.
All
that
run
characteristics
can
be
specified
here.
Sometimes
you
would
like
to
specify
some
annotation
checks
on
your
apps
to
filter
only
a
particular
app
to
do
chaos-
sometimes
you
want,
would
want
it
to
be
very
broad
based
on
some
label
selections.
So
all
that
kind
of
filtering
logic
and
overrides
and
run
properties
can
be
provided
in
the
engine.
G
That's
really
what
the
user
is
generally
sees
and
the
chaos
result
is
another
resource
which
is
mostly
used
for
holding
results
of
your
experiment.
So
we
wanted
to
keep
it
separate
from
the
other
resources,
because
this
resource
has
a
life
cycle
or
you
know
a
scope
of
its
own.
It
can
really
grow
in
the
time
to
come
a
lot
of
lot
of
times.
The
results
of
an
experiment
is
not
binary,
it's
not
just
a
pass
or
fail.
There's
a
lot
of
characteristics
are
a
lot
of
application-specific
information.
G
Information
that
you
would
like
to
push
out
this
bar
is
that
you
might
want
to
sue.
They
might
be
key
performance
indicators
for
each
application
that
you
might
want
to
package
in
your
result
to
give
more
information
to
the
Saudis.
So
the
chaos
result
is
something
that
we
are
developing
over
a
period
of
time
to
hold
that
kind
of
information.
G
G
This
is
a
very
simple
view
of
the
architecture,
so
there
are
some
applications
under
test,
so
we've
got
some
chaos
charts
specifically
for
Kafka
opening,
based
which
happens
to
be
the
main
motivation
behind
this
project
and
then
some
general
kubernetes,
charts
and
etcetera,
and
this
these
they
could
be
different
instances
of
this
applications
running
on
your
cluster
and
then
you
have
lot
of
case
experiments
on
the
hub.
So
you
pull
these
together
to
form
the
chaos
engine.
G
A
lot
of
granular
control
and
the
litmus
chaos
operator
is
the
controller
which
reconciles
the
engine
and
it's
probably
the
brain
behind
rapist.
So
when
you
create
the
chaos
engine,
it
launches
some
resources,
it
has
a
umbrella
executor
called
chaos
runner.
So
you
could
choose
to
actually
specify
one
particular
experiment
in
your
engine
or
you
could
even
define
flow.
G
For
example,
you
might
want
to
do
a
pod,
kill
and
then,
after
some
time
you
might
want
to
basically
drain
a
node
or
you
might
want
to
define
your
own
sequence
to
see
what
happens
because
Kaos
generally
doesn't
happen
in
isolation.
It's
not
like
this
one
fault
occurs
in
your
system
is
alright
for,
for
next
50
knots
like
that
to
misfortune
can
occur.
Yeah
yeah.
C
C
G
A
great
question,
so
you
can
see
that
there
is
this
genetic
chaos,
so
most
of
the
experiments
here
are
all
very
humility
specific,
so
you
could
do
all
these
experiments
again
against
any
application.
That's
one
use
case,
so
you
could
be
inject
this
chaos
and
you
could
have
your
own
monitoring
systems
in
place
to
see
what
has
happened.
The
other
view
or
the
other
charts
that
you
have
here
is
the
each
application
has
standard
set
of
application.
G
Lightness
parameters,
for
example
in
case
of
Cassandra,
might
want
to
see
how
your
ring
is
behaving
after
you've
done
a
particular
bodily
it
you
might
want
to
check
data
is
getting
redistributed
in
case
of
Kafka.
You
might
want
to
see
if
your
message
queue
is
basically
not
broken
even
after
you
kill
your
controller
brokers,
etc,
might
want
to
say
if
your
latency
is
between
your
producer
and
consumer
is
set
to
a
is
already
set
to
a
certain
value,
and
it
is
honoring
that
or
no
so
these
kind
of
lightness
checks.
G
That's
the
term
we
we
are
using
it.
These
are
some
post
and
pre
chaos.
Health
checks
that
you
can
do,
which
are
all
application-specific.
There
are
some
standard
ones
that
are
associated
with
the
application,
so
the
experiments
for
these
apps
actually
include
those
checks,
so
that
is
how
they
from
a
vanilla,
chaos,
experiment
which
is
basically
going
into
injecting
the
fault
and
then
taking
care
of
all
the
other
checks
by
yourself.
C
G
That's
a
great
question:
I
think
we
are
going
to
do
that,
probably
problem.
There
is
an
issue
that
we've
created
to
do
that.
There
are
two
ways
of
doing
it:
service
mesh
as
a
as
a
framework.
You
might
want
to
go
inject
chaos
into
it.
That's
one
use
case.
The
other
use
case
is
leveraging
service
which
to
actually
provide
a
visualization
platform
for
what
is
happening
with
your
chaos,
I
think
in
the
demo
that
Raj
is
going
to
show-
probably
this
much
a
small
hint
of
that.
G
C
G
G
Typically,
it
involves
creating
of
a
chaos
runner,
which
is
an
umbrella
executor
which
will
execute
one
or
more
experiments
defined
in
the
engine
and
how
it
does
that
is
it
launches
an
experiment,
job
for
each
experiment,
that's
listed
in
the
engine
and
and
it
basically,
the
experiment,
actually
creates
chaos,
result
which
again
is
monitored,
whether
owner
who
patch
it
back
into
the
engine.
So
the
engine
is
more
or
less
a
single
source
of
truth.
G
G
G
So
this
is
probably
just
expanded
illustration
of
what
we
discussed
is
this
Lane
diagram
describing
the
same
things
probably
skip
that
for
now
the
slides
will
be
made
available.
I
think
you
can
always
take
a
look
at
that,
so
one
other
thing
about
litmus
which
I
would
like
to
mention
is
so
one
of
the
things
we
sort
of
saw
as
we
built
out
the
framework
is.
G
So
we
wanted
to
sort
of
extend
the
ability
for
them
to
use
litmus
to
not
just
execute
the
chaos
experiment
bit
sort
of
orchestrated
one
of
the
use
cases
that
sort
of
we
saw
that
happening.
We
saw
that
not
being
resonated
with
into
it
with
basically
using
the
experiments
from
chaos
toolkit
which
they've
already
pre
created,
but
they
want
to
use
lateness
to
orchestrate
that
that's
one
of
the
use
cases,
and
then
there
are
some
who
are
using
the
native
litmus
experiments
itself.
So
there
are
a
couple
of
integration
approaches.
G
G
Example
powerful
see
they
could
actually
go
ahead
and
create
you
know
containerized
version
of
the
same
tool,
or
it
could
be
even
custom
logic
that
you've
been
writing
in
your
80
by
plans
contain
race
there,
and
it
was
sort
of
create
a
job
test
it
out
to
see
whether
it
that
translates
as
a
job,
then
you
could
create
very
light
to
rapper
and
I'll
just
share
how
we
could
do
this
over
this.
This
chaos
Lib
is
nothing
but
a
wrapper
that
is
able
to
invoke
this
K.
G
It
is
resource
that
is
going
to
use
this
particular
tool
to
inject
chaos
and
also
manage
that
particular
deployment,
and
this
Lib
is
just
added
on
into
your
chaos
experiment.
So
that's
going
to
look
something
like
this
I'm
just
so
in
your
engine.
You
might
probably
just
to
use
a
powerful
seal
as
live,
whereas
you
could
use
litmus
also.
So
that's
one
of
the
things.
G
G
So
you
could
contain
race
that
you
could
as
a
job
very
similar
to
the
previous
type
one
case,
and
what
you
could
do
is
you
could
add
some
instrumentation
into
your
experiment,
logic,
to
create
some
extra
artifacts,
like
the
chaos
results
here,
and
then
you
could
create
chaos,
experiments,
ER
the
chaos,
the
chaos
experiments
here,
which
is
the
one
which
is
going
to
be
pushed
into
this
up.
You
can
create
your
own
category
in
push
it
and
yeah
that
can
be
leveraged
into
your
staging
set.
You
can
be.
G
You
can
give
you
an
SRE
as
an
app
developer.
Who
knows
that
there
are
certain
scenarios.
You
really
want
to
try.
You
could
create
your
own
experiment
in
Oscar,
a
sorry
to
use
it.
So
this
is
about
the
same
thing
that
I've
mentioned
earlier,
so
you
run
something
new
development
pipelines
to
convert
it
into
experiments,
so
push
it
back.
So
this
is
roughly
about
it.
G
This
is
just
a
slide
to
mention
some
details
around
the
community.
We
have
a
monthly
community
sink
up
call
which
happens
every
third
witness
day,
and
they
also
on
slack
capability
slack
in
the
channel
called
as
witness
the
there
is.
The
channel
is
getting
increasingly
chatty
nowadays,
which
is
a
great
sign,
and
there
are
more
issues
flowing
in
into
that
up,
o
where
people
are
asking
for
features
and
sort
of
collaborating
and
even
contributing.
G
We've
got
some
good
contributions
from
other
organizations,
really
looking
forward
to
mentoring
and
working
with
Lee
and
others
in
these
business
community
to
see
their
chaos
as
a
concept
can
fit
in
one
of
the
areas
it
could
be.
You
know
these
service
missions
have
a
great
way
to
enforce
Bluegreen
deployments
a
be
testing
and
have
a
great
way
to
actually
visualize,
what's
happening
when
you're
doing
upgrades,
etc.
G
So
litmus
or
any
other
chaos
tool
for
that
matter
can
be
used
as
some
kind
of
a
gated
check,
some
kind
of
a
quality
gate
that
you
could
be
used
to
say
that
this
upgrade
is
really
going
well
or
we
would
want
to
go
back
to
your
older
applicational
instance,
etcetera.
That's
one
of
the
use
cases,
I
would
say,
but
there
could
be
others
as
well.
It
could
be
chaos
for
the
service
mission.
Rack
form
itself
to
see
how
it
is
behaving
so
yeah.
G
So
this
is
a
general
description
that
I
would
want
that
I
wanted
to
give
I
can
take
some
questions
now
before
Raj
jumps
on
to
his
demo.
It's
a
simple
pod
delete
it's
like
the
hollow
world
of
the
chaos
world,
so
we
just
trying
to
show
what
litmus
helps
you
with
that's.
What
Raj
is
probably
going
to
show.
B
G
Right
yeah,
so
let
me
just
share
it
with
you.
My
screen
continues
to
be
visible
right
and
yes,
oh
thanks
yeah,
so
we
are
actually
in
the
process
of
building
out.
What
is
a
formal
is
begin.
What
we
have
now
is
a
set
of
steps
in
the
contributor
guide,
so
the
litmus
experiments
themselves
we're
written
in
ansible.
That's
one
of
the
choices
we
made
early
on
to
sort
of
engage
the
community
most
of
the
s
are
in
divorce.
G
Folks
are
pretty
comfortable
because
they
use,
and
so
will
in
day
to
day
lives,
but
as
the
project
sort
of
grew,
we've
created
some
experiment
repositories
which
can
hold
experiments
written
in,
go
or
do
experiments
written
in
Python
etcetera.
So
we
are
in
the
process
of
adding
the
scaffold
tools
so
to
say
they
slike
for
actually
bootstrapping
their
experiments
in
python
and
modes.
It's
not
for
now.
What
we
have
is
is
for
the
ansible
experiments,
so
you
could
actually
use
this
very
simple
script.
G
What
the
script
does
is
allows
you
to
create
all
the
artifacts
that
is
necessary
for
providing
a
case
experiment.
So
the
experiment
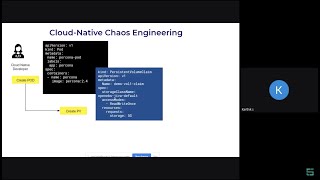
example
experiment,
engine
the
are
back
or
the
permissions
that
are
necessary
to
run
your
experiment.
You
could
have
a
attributes
file,
which
is
looking
like
this
with
some
metadata
about
what
you
want
in
your
experiment
and
what
are
the
permissions
you
wanted
on
it
with
etcetera
and
you
could
use
a
script
to
actually
generate
all
the
artifacts
that
are
necessary.
It
would.
G
It
also
creates
a
folder
structure
within
the
litmus
repo
and
creates
all
the
necessary
artifacts
to
run
an
experiment.
So
a
lot
of
these
are
optional
as
they're
not
really
mandatory
and,
for
example,
the
chart
service
version
is
something
that's
economical
representation
of
what
appears
here
on
the
pods
and
the
actual
business
logic
is
placed
inside
of
the
ansible
logic.
Yaman
prerequisites.
G
Job
again
is
an
optional
thing
in
general
is
a
sample
representation
of
how
you
would
tie
this
particular
experiment
with
the
experiments
here
with
an
application.
So
you
could
sort
of
generate
this,
and
then
you
could
go
fill
out.
This
particular
Yaman
with
your
logic,
whatever
P
chaos,
post
chaos,
chicks
that
you
have
it's
written
in
a
very
simplistic
manner.
I
could
take
the
example
of
the
what
it
experiment
itself,
something
that's
very
basic.
It
would
consider
all
of
these
as
something
that
you
can
build
upon.
G
For
example,
you
have
a
section
which
is
basically
trying
to
do
some
pre
chaos
checks,
and
there
are
some
events
that
we're
generating
as
part
of
the
experiment.
This
section
is
the
one
which
is
actually
calling
the
chaos
injection,
and
this
is
something
that
you
could
write
yourself
or
use
depending
upon
what
tools
you
already
have.
For
example,
there
is
some
templating
that
we
have,
which
uses
you
know
different
type
duties.
You
could
choose
to
call
different
libraries
there.
So
that's
followed
by
your
post.
G
Chaos
checks
to
see
whether
things
are
running
fine
and
then
you
go
ahead
and
patch
your
results
here
with
what
is
the
verdict
of
your
experiment?
So
this
is
basically
a
skeletal
structure,
a
lot
of
business
logic
and
go
into
the
utils
that
are
being
called
here.
We
will
have
equivalence
of
this
in
the
other
platforms
or
go
Python,
etc.
Where
you
will,
there
is
an
issue
created
about
it,
which
you
could
probably
see
that
that
would
end
up
with.
L
G
Yes,
yeah
this
a
great
question:
li
the
chaos
run
was
execute
ansible.
If
you
are
using
the
native
native
litmus
Li
example,
there
are
Python
based
experiments
which
you
could
use.
Let
me
just
share
the
structure
which
was
here
so
you
could
see
this
type
2
engine,
so
the
the
this
this
particular
one
has
its
own
en
V's
and
talks
about
an
experiment
called
escape
or
delete
in
this
gate.
G
What
the
rate
is
actually
a
Python
script:
it's
not
an
answerable
experiment,
so
you
have
a
chaos
pool
k1,
which
is
basically
this,
and
this
experiment
ml
is
actually
having
a
different
entry
point.
You
have
a
different
Python
script
and
you
have
the
image
which
is
actually
having
this
particular
experiment,
business
logic.
So
you
just
push
what
you
want
the
tuna
bills
that
can
be
accepted
by
this
particular
script
and
it's
going
to
be
similar
with
other.
G
G
L
Thank
you
Karthik,
so
Lee
do
we
have
some
time
I
can
cover
up
within
five
minutes.
Please
so
I
have
one
video
recording
so
as
practical
side,
so
we
are
going
to
run.
One
coordinate
experiment
which
is
called
a
hello
world
like
goes
to
the
the
chaos
engineering.
So
this
is
the
generic
support.
This
comes
under
the
general
category,
so
the
my
target
application
is
the
sto
application.
So
I
have
one
set
up
running
in
my
cluster.
This
cluster.
L
Three
notes:
I
will
probably
play
one
video
I
have
recorded,
so
I
can
explain
properly.
So
this
is
the
application.
Okay,
that
is
representing
all
the
traffic
between
the
product
page
two
and
split
it
up
into
different
categories.
So
I
will
going
to
inject
chaos
on
this
product.
Page
I
am
going
to
delete
this
with
the
pod.
Delete
experiment
and
see
is
how
it
will
litigate
in
the
dashboard,
so
I
am
going
to
do
it
in
a
zk
cluster.
We
have
three
nodes
like
you
can
see.
L
L
D
L
It
will
install
some
C
IDs
and
some
resource
permissions
are
back
and
you
can
verify
the
installation
it's
in
the
turning
state,
and
you
can
also
verify
the
see
artists
as
Karthik
site.
We
are
using
custom
resource
definitions,
so
they
are
three
main
see.
Are
these
at
your
sins
in
your
experiment
and
sausages?
Right.
L
G
Sorry
to
interrupt
sorry,
just
a
pointer
here.
One
of
the
reasons
why
we
sort
of
started
supporting
this
is
their
who
use
cases
we
saw
some
of
the
developers
want
to
use
chaos
with
very
less
blast
radius
and
would
like
to
deepen
their
own
Snuggies
accounts.
But
there
is
another
use
case
where
in
Essaouira
typically
has
control
over
the
entire
cluster
and
once
some
kind
of
centralized
management
this
needs
one
our
back
doesn't
want
to
keep
creating.
No
difference
of
is
a
constant
different
namespaces.
L
Yeah-
and
the
second
part
is
the
chaos
engine.
This
will
have
the
all
the
two
neighbors
you
can
mention
like
you
can
see.
We
are
going
to
delete
the
pod,
which
is
in
the
default
new
space,
which
is
a
deployment
resource
and
the
label
is
the
app
equals
to
product
page,
and
these
are
some
cleaning
bills
like
sanitation
checks,
you
can
make
it
go
or
false,
and
this
Indian
state
you
can
hold
to
experiment
between
the
execution.
A
few
more
tuna
milks.
Are
there
like.
L
L
Upwards,
creating
this
beginning,
so
the
our
Ana
will
automatically
triggered
so
cooperator
will
reconcile
and
see
the
chaos
engine
automatically
triggered
the
tunnel,
so
after
tagging
run
is
creating
one
resource
for
your
spot.
So
you
can
see
the
events.
What
is
happening
so
after
a
few
seconds
you
can
see
it
will
goes
to
red.
G
B
G
G
G
B
G
L
B
G
That
yeah,
that's
a
good
question.
I
think
Maya
data
is
probably
being
the
primary
sponsor
of
the
project
as
far
Lee,
because
we're
seeing
that
this
was
the
natural
extension
of
the
open
amis
project.
But,
having
said
that,
there
are
some
contributors
were
coming
in,
which
is
really
pleasing.
For
example,
Intuit
has
been
contributing
they've.
G
Both
the
infrastructure
changes
to
the
operator,
as
well
as
new
experiments
and
they've
got
to
be
pro
and
are
going
I
as
some
of
the
other
contributors
so
also
trying
to
work
with
Intuit
folks
to
integrate
Lippman's
with
the
argo
project,
to
define
probably
workflows,
scenarios
that
you
might
want
to
do
parallel
experiments
and
things
like
that.
So
let's
read
it,
that
is
heading
nice.
A
M
A
M
L
G
Yeah
thank
same
I.
Sorry
for
not
noticing
the
question
on
chat.
Yes,
you're
right,
the
litmus
you
saw
the
genetic
experiments
where
the
network
chaos
experiments.
Where
listed,
you
could
be
used
that
for
standard
network
chaos,
but
if
you
are
looking
at
Network
waves
on
specific
applications,
that
is
also
possible
with
the
line
mystics
that
we
mentioned.
Ab
specific
line
districts.
B
Is
great
is
this
is
much
needed,
we'll
wrap
abruptly
with
thanks
to
Roger
and
they
wanna
make
sure
that
everybody
that
we're
not
holding
anyone
up
so
fantastic
Rajan
Kartha
we've
got
more
questions.
No
doubts
will
will
either
catch
you,
you
don't
Friday's
call
or
just
kind
of
it
in
slack,
and
but
this
has
been
really
informative.
This
is
nice
yeah.