►
From YouTube: Magento Architectural Discussion -- September 19, 2018
Description
Topics:
- Extended Configuration for ElasticSearch Analyzer (Volodymyr Kublytskyi)
- Proposal for GraphQL API for cross-platform rich content (James Zetlen)
Meeting minutes: https://github.com/magento/architecture/wiki/September-19,-2018
A
A
Proposals
have
in
March
and
I
can
go
to
some
of
them,
so
the
puzzle
for
expansion,
budget
structure,
yeah,
basically
imagine
developed
extensions-
are
actually
the
same.
It's
the
same
modules
or
packages
which
are
developed
between
Magento
and
are
included
as
part
of
the
Magento
meta
package,
which
is
the
product,
but
they
are
developed
in
a
separate
repository.
So
we
need
the
specific
procedure
for
that.
A
Okay-
and
we
have
page
builder,
which
is
part
of
which
will
be
part
of
where
I
go.
Magenta
commerce
and
both
of
them
are
developed
in
separate
repositories.
So
we
wanted
to
unify
the
file
structure,
and
here
we
this
here
Alex
to
describe
how
exactly
those
repositories
can
be
combined
in
order
to
like
develop.
If
you
want
to
work
on
post,
magenta
or
and
would
say
msi
as
a
developer,
for
example
as
a
contributor
or
for
magenta
developer.
So
what
do
you
do
now?
A
The
solution
is
that,
like
a
recommended
solution
is
to
use
fast
type
repository
in
composer,
so
you
can.
You
can
have,
for
example,
MSI
in
a
separate
folder
staying
somewhere
near
magenta
right
now
as
a
workaround,
it
should
be
inside
of
the
magenta
root
folder,
because
there
is
one
issue
with
templates
which
do
not
allow
you
do
not
allow
files
being
outside
of
magenta
folder.
So
right
now
you
put
MSI
inside
magenta
and
then
in
composer.
A
The
Jason
specify
repository
flight
path
pointing
to
that
directory
and
then
just
require
the
MSI
and
then
composer
will
be
able
to
just
install
this.
It's
still
MSI
as
a
package,
and
then
you
can
so
as
far
as
I
know
under
Linux
systems
or
mark
I
think
as
well.
All
the
files
will
be
sick
links,
so
you
can
basically
develop
in
your
project
and
then
Japan
because
just
push
your
changes,
anything
anything.
A
Okay,
that's
one
of
the
requests
that
emerge
them.
Another
one
is
it's
more
related
to
just
organizational
organization
of
this
repository
strange
okay,
it
was
March,
nothing
changed.
You
need
to
review.
So
basically,
the
idea
of
this
Buddha
question
is
to
remove
the
proposals
folder
exalt,
so
it
should
have
only
design
documents
and
I.
Think
this
is
described
here.
I
will
remove.
Is.
A
Mm-Hm,
so
I
don't
think
this
one
imports
imports
anybody,
but
the
idea
is
to
have
three
I'm
moving
towards
actually
having
tests
inside
modules
and
then
I'm
ftfs,
for
example,
with
Magento
release.
Pipeline
tests
will
be
extracted
into
separate
packages,
and
they
will
be
here
that
this
proposal
document
describes
how
which
means
this
versioning
for
the
tests
select
details
on
different
XML
and.
A
A
So
right
now,
one
of
them
is
marked
with
an
API,
abstract,
extensible
motorized
thing
right
now
object
right,
abstract,
extensible
objects.
So,
as
there
were
not
many
commenced
into
why
this
should
change,
we
keep
it
disease.
So
this
this
plus,
is
an
API
public
API.
So
you
should
use
this
one
and
it
has
a
fewer
methods.
So
you're
going
to
hear
it
too
much
too
many
things
that
you
actually
may
not
need.
Yeah.
B
I
would
like
to
add
a
little
bit
to
pull
requests
so
right
now,
I'm
still
talking
to
some
community
members
and
discussion,
how
they
actually
using
these
classes
and
what
used
for
inheritance
and
it
seems
like
most
people
either.
Don't
know
about
the
existence
of
objects
or
they
just
use
what
basically,
they
use
them
so
for
now,
I'm,
leaning
towards
just
duplicate
an
existing
model
and
keeping
objects
as
API.
But
there
is
still
an
undergoing
discussion
and
most
likely
there
will
be
no
CPR
and
coming
weeks.
A
A
C
C
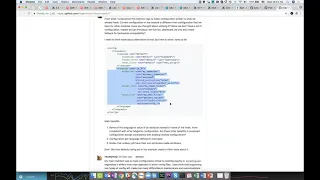
The
main
concern
is
approach:
how
configuration
describe
it
/
language
so
for
now,
elastic
search
configuration
introduced,
not
standard,
not
strictly
required
elements
for
each
lacayo.
The
default
element
is
it
called
the
default
configuration
and,
and
those
elements
bind
it
to
the
Lacaille
calls
it
configuration
of
everything
else,
all
other
properties.
D
A
C
A
C
C
Actually,
no
because
each
ticket
technology
may
have
own
properties,
and
it's
like
it's
hard
to
do-
to
declare
with
these
attributes.
So
it
we
will
need
to
introduce
some
some
general
element
like
Aram
parameter
option
or
something
like
this
and
who
described
describe
it
for
for
each
possible
parameter,
because
we
will.
You
will
not
be
able
to
describe
all
possible
tokens
and
filters
and
their
parameters
for
elasticsearch.
So.
A
It's
just
from
it
doesn't
matter
what
the
scheme
will
be
used
to
cannot
make
it
strict,
very
strict,
doesn't
matter
whether
it
will
be
attributes
or
from
like
what
I
understand.
You
said,
okay,
so
I,
guess
you
only
talk
into
details,
so
you
discuss
it
with
Ziegler,
Monica,
Wright
and
he'll
probably
be
discussing
this.
You
know.
E
C
E
F
C
Yes,
we
need
configuration
that
configure.
Stop
course
list
is
at
configure
steamer,
but
for
another
community
project.
We
also
works
and
features
to
configure
recognizer
and
token
fuel
filters
and
sheriff
filters,
because
the
default
is
not
suitable
for
Japanese
language
or,
for
example,
for
Chinese
language.
They
need
to
use
a
specific
recognizer
in
analyzers.
E
C
E
C
Like
more
widened,
complex
question
and
in
my
proposal
and
just
trying
to
solve
particular
particular
issue
with
inability
to
configure
recognizer
and
token
and
share
filters
and
provide
this
possibility
with
us,
less
changes
as
possible:
okay,
I,
don't
think
we
before
for
this
task.
We
the
don't,
get
some
reason
to
review
they've
caused
the
whole
principles.
How
we
work
with.
E
C
E
A
Okay,
so
it's
grass
here
and
I
guess
it's
in
progress,
so
I
think
we
were
discussing
with
Alex
that
we
can
merge
this
at
some
point
right
at
some
point
soon
and
then,
like
closed-down,
going
discussion
should
merge
this
pull
request
and
then
create
smaller
pull
requests
to
update
the
document.
So
we
don't
have
just
one
full
request
and
stays
for
a
long
time
here,
but
you
have
a
set
of
smaller
requests
from
date.
It
right.
Yes,.
B
B
F
B
H
A
A
I
This
is
a
brief
summary,
the
the
need
that
we're
identifying
them
as
we
speak
with
the
adobe
experience
manager
and
CIF
people
and
the
spider
people
is
that
there
is
some
duplication
of
features
in
their
systems
that
they
want
us
to
integrate
with
and
in
our
page
builder
system
and
I.
Don't
anticipate
that
one
system
will
be
deprecated
in
favor
of
the
other,
but
in
clients
that
might
consume
data
from
multiple
systems.
We
want
to
avoid
having
those
clients
need
to
have
multiple
fetching
and
display
strategies
for
them.
I
So
manure,
initial
draft
of
an
implementation
for
page
builder
support
in
PWA
I
wrote
a
graph
QL
interface
that
is
meant
to
perform
sort
of
two
subsequent
calls
in
serial
and
one
is
to
recursively
descend
into
a
tree
of
rich
content
nodes
and
determine
what
their
implementation
and
role
should
be
and
then
to
perform
a
subsequent
get,
which
would
be
very
cached
in
order
to
obtain
both
the
the
the
data
for
those
subtypes
and
the
logic
and
component
implementations
for
displaying
them.
Very
briefly,
this
is
the
interface
I
left
off
the
final,
curly,
brace
and.
I
It
is
an
interface
which
all
other
types
of
nodes
like
columns
and
rows
etcetera,
would
implement,
there's
more
detail
in
the
Pope
in
the
proposal
itself
and
it's
recursive.
It
has
children
graph
QL
can't
do
arbitrary
recursion
so
for
each
layer
of
recursion.
You
have
to
specify
in
the
query-
and
this
is
intentional,
because
in
a
progressive
web
app
you
don't
want
to
let
the
server
content
specify
how
much
data
you
end
up
downloading.
I
Instead,
we
can
limit
the
amount
of
data
that
we
download
to
a
certain
set
of
layers
and
then
progressively
dive
deeper
into
a
very
complex
document,
and
so,
if
you
made
a
request
initially,
you
might
just
declare
a
fragment
so
that
you
could
reuse
it
and
then
request
one
layer
of
children
and
then
it
would
respond,
perhaps
with
something
indicating
that
the
role
of
the
parent
node
is
column,
that
it
has
a
tree
depth
of
four.
That
here
are
some
assets
that
are
in
descendants
of
the
tree.
I
This
would
be
rolled
up
and
and
aggregated
for
the
PWA
to
begin
doing.
Preload
of
and
then
the
descendant
roles
is
similar
in
that
it
is
a
hint
for
the
PWA
to
begin
pre
loading,
these
components,
and
then
it
declares
the
components
again,
because
the
query
was
against
the
interface.
It
doesn't
get
any
particular
unique
configuration
values
for
those,
but
in
the
subsequent
query
it
would
receive
them
so
put
more
broadly,
we
need
to
integrate
with
things
like
coral
UI.
I
I
The
one
thing
that
those
things
all
have
in
common
is
that
they're
trees,
and
so
he
could
potentially
use
this
visual
content
node
to
describe
a
generic
tree.
This
is
a
more
broad
sort
of
discussion
of
what
such
implementations
and
extended
types
that
implement
the
visual
content
know
it
might
look
like
so
you
could
obtain
the
column
and
then
in
parallel,
render
the
HTML
fallback
text.
So
that's
there
can
be
an
initial,
meaningful
paint
and
then
preload
the
necessary
data
and
then
in
parallel
load,
the
necessary
logic
and
run
a
subsequent
query.
I
Once
the
logic
has
come
down
to
explain
how
that
query
takes
place,
and
then
here
you
do
as
much
introspection
as
the
sorry
as
much
recursion,
as
the
implementation
in
particular
says
that
it
needs
for
page
builder,
column,
configure
for
page
builder
tabs.
Its
associated
query
might
say:
well,
I
want
to
do
four
layers
of
recursion,
because
that's
typically
the
depths
of
such
a
component
and
leaf
nodes
might
not
do
any
recursion
at
all.
I
So
this
does
seem
to
require
extra
requests,
but
I
think
that
it
also
guarantees
the
nature
of
results
and
the
requests
for
follow-up
information
are
necessary
in
order
for
us
to
adhere
to
the
most
cross-compatible
protocol.
I
think
it's
a
good
way
of
describing
and
defining
this
information,
and
it
would
be
easy
to
use
it
as
a
transmission
format
and
to
retain
the
fallback
friendly
storage
format
that
page
builder
currently
uses.
H
E
I
I
I
With
little
depth
you
shouldn't
have
HTML
that
goes
many
many
layers
deep
and
then
renders
videos
and
etc,
but
because
business
users
are
allowed
the
freedom
to
create
their
own
UI's
and
the
various
tools
that
create
those
UIs
may
generate
HTML
of
arbitrary
depth.
I
think
that
having
there
be
controllable,
amount
of
recursion
would
be
good
and
it
could
still
come
back
as
an
array,
potentially,
if
there's
other
advantages
to
that.
But
if
the,
if
your
suggestion
is
to
allow
us
to
download
an
entire
tree
of
content
definitions,
then
in
my
imagined
implementation.
I
We
wouldn't
do
that
and
we
wouldn't
do
it
on
purpose.
So,
since
if
author
has
written
something
that
is
eight
or
nine
or
ten
layers
deep,
then
what
if
the
PWS
interfaith
fetching
logic,
only
fetches,
two
or
three
layers,
then
the
client
might
see
the
data
loading
from
the
outside-in
or
the
content
loading
from
the
outside
in
which
is
a
best
practice
actually
because
it's
much
better
than
loading
from
the
top
down
and
then
causing
scroll
problems.
I
E
I
E
I
I
A
A
E
E
So
I
pay
this
better
because
you
can
and
use
any
type
of
structure.
If
is
you
need
to
know
notice,
you
can
request
if
you
need
ones
subset
of
not
what
you
are
also
can
request
it,
but
you
need
to
specify
is
like
nested
nested
nested,
because
actually,
if
you
try
to
introduce
nested,
you
need
to
project
structure,
because
you
also
need
to
specify
different
type
of
notice
on
every
level
is
a
request.
I
E
I
Wanted
to
make
sure
that
the
implementations
of
things
like
column
etc
were
actually
in
the
type
system
rather
than
being
somehow
blobbed
into
the
type
system
with
like
serialized
JSON
or
something
I
didn't
want
to
do
that.
So
I
wanted
you
to
be
able
to
once
you
understood
that
something
had
a
rule
of
accordion
and
that
you
knew
that
that
meant
the
schema
had
something
called
page
builder
accordion
or
something
that
you
could
request
or
page
builder
column.
I
You
could
request
these
actual
properties
and
on
and
in
an
array
you
could
continue
to
do
that,
but
you
would
still
have
to
have
this,
and
perhaps
you
would
just
append
to
a
local
copy
of
a
graph
QL
documents.
These
fragments,
as
you
learn
the
new
type
fragments
progressively
from
downloading
new
things.
So
then
yeah!
That's
an
idea.
Do
you
see
what
I'm
saying
yep?
I
I
E
Actually
is
disc
approach,
also,
a
lot
I'll
do
what
the
deepest
survival
just.
Is
this
the
same
query
just
just
before
five
root
node,
and
you
can't
what
just
some
leaf
of
three
and
renders
this
as
a
synchronous,
a
for
example,
because
previous
variants
are
not
in
the
you
need
to
specify
some
what
I
obey
this
is
the
same,
but
is
this
I
live
more
natural
to
specify
an
example
start
render
from
this
world
element.
H
I
Or
you
know,
probably
so,
okay
and
then
once
that's
done,
though,
the
root
node
may
have
its
own
metadata,
but
it's
also
possible
that
we
can
make
the
statement
that
root
nodes
have
no
metadata,
that
they're
simply
abstract
containers,
and
then
we
don't
need
to
get
any
metadata
from
this
specific
room.
Note
itself:
yep:
okay,
so
that's
a
possibility
and
then
yeah.
Then
we
can
specify
the
depth
yeah,
that's
the
thing
we
could
do
and
then
we
could.
I
We
could
shorten
the
queries.
I
think
I
think
we
could
certainly
request
a
very
small
amount
of
data
and
then
increase
this
depth,
but,
like
whatever,
is
the
manager
object
that
performs
these
queries
as
its
as
its
excessively
downloads,
the
implementation
of
you
know,
column
and
accordion
and
whatever?
Then
it
actually
has
to
mutate.
This
graph
QL
query
to
add
fragments
you
know
fragment.
You
know.