►
From YouTube: 03 Codee parallelization capabilities
Description
No description was provided for this meeting.
If this is YOUR meeting, an easy way to fix this is to add a description to your video, wherever mtngs.io found it (probably YouTube).
A
Okay,
let's
continue
so
I
hope
you
had
the
first
sense
of
how
to
use
kodi
for
several
use.
Cases
in
particular
for
once,
cody
succeeds
with
its
technology
to
identify
opportunities
in
your
code,
in
particular,
for
offloading
to
gpus
how
you
can
follow
the
instructions
and
the
suggestions
to
actually
used
code
error,
writing
capabilities
to
annotate
your
source
code
with
openmp
and
open
ecc.
A
A
Some
of
the
challenges
that
are
really
typically
pointed
out
is
how
to
make
an
efficient
usage
of
the
memory
for
data
transfers,
in
particular,
and
for
execution
on
the
gpu
how
to
exploit
massive
parallelism.
That
means,
if
you
can
create
thousands
of
threads
on
the
gpu,
don't
create
only
hundreds
of
them
and
minimize
data
transfers,
because
this
is
one
of
the
typical
bottlenecks
that
you
can
find.
A
So
here
in
particular,
what
we
will
be
seeing
is
something
related
to
memory
usage.
That
is
how
our
design
or
our
decision
to
represent
our
data
in
a
particular
data
structure,
how
this
can
influence
or
have
an
impact,
positive
or
negative
in
the
data
transfers
of
your
or
in
the
complexity
of
coding.
A
A
So
very
briefly,
we
need
just
to
remember
very
briefly:
what
are
the
differences
from
the
point
of
view
of
programming
of
a
programmer
between
a
cpu
or
a
gpu?
In
the
end,
both
of
them
are
executing
threads
somehow
in
the
hardware,
but
typically
the
numbers
of
threads
to
be
executed
on
the
cpu
is
relatively
low.
A
A
second
difference
is
that
how
the
threads
are
coordinated
in
the
hardware
level
on
the
cpu.
Typically,
we
have
control
of
the
threads,
and
these
threads
are
executed,
all
of
them
at
the
same
time,
and
we
decide
how
the
communicators
synchronize
with
each
other
on
the
gpus.
Typically,
these
rules
are
not
so
straightforward.
They
are
more
complicated
and,
for
instance,
you
have
seen
that
threads
on
the
gpu
are
grouped
in
what
is
typically
called,
for
instance,
gpu
warps
that
executed
all
of
them
at
the
same
time,
using
the
same
instruction
instruction
counter.
A
A
The
amount
of
what
is
the
part
of
the
memory
system
that
it
has
access
to
is
restricted,
and
this
is
this
influences
that
we
program
for
it,
and
also
one
of
the
things
that
is
common
in
both
architectures
is
that
in
the
end,
the
exec
they
exploit
some
kind
of
vector
mode
on
the
cpu.
This
is
typically
exploited
through
ex
through
scene
instructions
or
vector
instructions,
while
in
the
gpu
more
or
less
the
equivalent
is
having
all
of
the
threads
within
the.
A
For
instance,
a
thread
work
to
execute
the
same
instruction
at
the
same
time
on
different
data
points,
so
somehow
cmd
a
vectorization
is
also
important
to
take
advantage
of
performance
on
the
gpu.
So
significantly,
there
are
significant
differences.
Even
this
high
level
description
of
the
of
the
architecture
you
we
can
have
a
sense
of
how
different
they
are
from
the
point
of
view
of
programming
for
these
different
types
of
hardware.
A
So
one
thing
apart
from
the
archival
architecture,
differences,
there
is
another
thing
that
we
need
to
consider
that
has
a
big
impact
on
performance
that
is
in
the
end.
Gpus
are
different,
separate
memory
than
the
cpus,
for
instance.
This
is.
We
typically
are
told
that
when
we
launch
a
program
on
the
gpu,
there
is
a
thread
that
starts
execution
on
the
cpu
side,
the
cpu
side,
somehow
at
some
point
of
loads
computation
to
the
gpu.
A
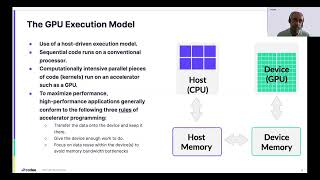
So,
in
the
end,
when
we're
talking
about
maximizing
performance,
what
we
see
is
there
are
several
rules
that
we
need
to
consider
basic
rules.
In
the
end,
we
need
to
transfer
data
from
the
cpu
memory
to
the
device
and
keep
it
there
so
that
the
computations
of
loaded
to
the
gpu
can
do
work
and
have
enough
work
to
do,
and
they
can
reuse
as
much
data
as
possible
and
make
an
efficient
usage
of
the
memory
bandwidth
of
the
tpu
and
in
the
end,
transfer
all
the
results
back
to
the
cpu.
A
A
Another
thing
we
need
to
to
consider
is
how
to
optimize
the
memory
layout
so
that,
in
the
end,
data
transfers
between
the
cpu
and
gpu
are
executed
efficiently
and
also
when
the
code
is
executed
on
the
tpu.
It
is
also
executed
efficiently
by
making
an
efficient
usage
of
the
memory
a
subsystem
available
in
the
in
the
gpu
and
also
in
order
to
other
challenges
that
we
will
not
be
addressing
today
and
tomorrow.
But
that
could
be
addressed
in
the
future.
A
Is
how
can
we
spawn
more
and
more
threads
to
take
advantage
of
the
thousands
of
spreads
that
are
typically
available
on
a
gpu
or
how
we
can
minimize
data
transfers
across
loop
nests
or
minimize
data
transfers
through
simulation
iterate
iterative
loops
that
we
can
identify,
so
that
the
data
can
be
reused
on
the
gpu
as
much
as
possible?
So.
A
A
The
second
thing
that
we
will
be
the
challenge
that
we
will
be
addressing
in
the
second
lab
of
of
today
is
optimizing,
the
memory
layout
for
data
transfers
and
in
particular,
we
will
be
dealing
with
what
is
called
array
shaping
or
shaping
of
arrays.
That
is
how
can
we
understand
if
one
my
1d
2d
3d
5d
array-
that
is
logically
a
multi-dimensional
array,
how
the
data
is
actually
laid
out
in
memory,
because,
depending
on
how
I
actually
code
or
use
the
data
structure,
to
actually
implement
my
matrix,
my
multi-dimensional
metrics?
A
This
will
have
an
important
impact
on
performance
and
even
on
correctness.
So
here
we
are
going
to
see
in
the
challenge
number
two:
how
selecting
the
data
type
the
data
structure
actually
impacts
on
the
shaping
of
arrays
that
we
need
to
manage
with
openmp
or
openhcc,
and
the
third
challenge
that
is
about
identifying
defects,
data
transfers.
A
We
will
be
seeing
tomorrow,
as
also
as
depending
on
how
we
use
what
data
structure
do
we
select.
We
maybe
have
a
need
to
address
the
problem
of
deep
copy.
That
is
whenever
the
data
is,
is
not
consecutive
in
memory,
but
is
spreading
memory
and
we
need
to
follow
pointers
to
actually
access
to
a
given
data
point
of
my
matrix
or
my
data
structure.
A
That
has
a
complexity
that
needs
to
be
managed
both
on
the
computational
side,
but
also
on
the
data
transfer
site,
and
it
means
typically,
this
is
not
managed
automatically.
This
needs
to
be
managed
explicitly
in
our
programs,
so
these
are
essentially
the
three
main
challenges
we
will
be
working
with
today
and
tomorrow.
A
So
in
order
to
understand
why
tools
are
needed,
remember
that
compilers
are
here
to
help
and
in
particular,
compilers
can
implement
application
program
interfaces
like
openmp
or
openacc
and
application
program
interfaces
are
designed
for
us
as
a
program
as
programmers
to
specify
what
the
compiler
needs
to
do
and
how
it
needs
to
do
it.
So
we
need
to
specify
the
what
and
the
how
it
is
our
responsibility
to
as
programmers
to
carefully
indicate
what
needs
to
be
done
at
each
moment
in
time.
A
We
cannot
expect
a
compiler
implementing,
openmp
or
pcc,
for
instance,
to
automatically
detect
opportunities
in
the
code
to
be
offloaded
to
the
gpu.
This
is
not
something
that
you
can
in
general,
expect
from
a
compiler
implementing,
openmp
or
openhcc.
Also,
the
compiler
will
not
guarantee
correctness.
It
is
you,
when
you
add
a
pragma.
A
You
are
telling
the
compiler
what
to
do
in
order
to
manage
an
offloading
opportunity
and
how
to
do
it,
how
to
actually
code
the
data
transfer.
So
it
is
your
responsibility
as
a
programmer
to
guarantee
that
you
are
using
the
application
program
interface
interface
properly,
so
the
compiler
can
do
the
job
of
the
hard
job
of
translating
high
level
practice
that
are
good
for
the
programmer
into
lower
level
code
that
can
execute
efficiently
at
the
hardware
level.
Okay.
So,
in
the
end,
we
as
programmers
we
need.
A
A
All
providing
this
information
provides
very
useful
information
for
the
compiler
to
do
many,
compile
time,
optimizations
and
in
particular,
also
to
do
correct
memory,
allocation
and
even
memory
data
transfers
from
the
cpu
to
the
gpu,
by
taking
a
look
at
the
array
shaping
information
for
the
gpu
of
loading,
a
problem.
So
how
does
do
we
specify?
Typically,
an
array
shape
the
shape
of
an
array?
A
Typically,
we
provide
the
name
of
the
array
x,
I
a
b
c
and
we
typically
provide
within
brackets
the
first
element
that
is
relevant
for
the
dimension
and
the
last
element
that
is
relevant
for
the
dimension.
Typically,
for
instance,
if
we
want
to
specify
that
we
have
a
one-dimensional
array
x
of
n
elements.
A
That
start
in
zero,
for
instance,
we
need
to
specify
if
the
element
is
called
x
x
and
within
brackets
0
columns
n
indicating
that
it
has
an
elements
in
the
fourth
dimension,
and
we
can
use
the
same
notation
to
specify
the
shape
of
the
array
in
multi
in
multiple
dimensions.
Okay-
and
you
can
see
that
both
openmp
and
openhcc
provide
a
syntax
to
specify
array
shapes.
A
A
A
So
this
is
very
good
information
for
the
compiler
because
it
can
trigger
and
enable
compiler
optimization
that
otherwise
could
not
be
possible.
So,
let's
look
at
what
happens
in
when
we
are
trying
working,
not
with
1d
matrices
of
one
dimension,
typically
called
vectors,
but
we
are
working
with
matrices
of
two
three.
Four
arrays
or
dimensions:
okay,
here
from
a
logical
perspective,
we
have
a
in
this
case
a
three
by
three
matrix,
where
we
have
different
elements
in
different
rows
of
the
matrix.
A
But
what
happens
from
the
point
of
view
of
the
programming
language
c,
c,
plus,
plus
and
fourteen-
have
different
rules
to
lay
out
the
data
in
memory
for
multi-dimensional
arrays,
and
this
is
what
is
typically
known
as
cc
plus
plus
implementing
a
raw
major
storage.
That
means
that
consecutive
elements
consecutive
rows
in
that
two
two-dimensional
matrix
are
stored
in
consecutive
memory
locations,
while
fortran,
for
instance,
uses
the
other
the
opposite
approach.
It
is
column
major,
so
consecutive
elements
in
columns
are
storing
consecutive
elements
in
memory,
so,
in
the
end,
the
developer.
A
We
as
developers
need
to
be
aware
of
how
the
programming
language,
which
are
the
programming
language
rules,
to
lay
out
the
data
of
our
multi-dimensional
arrays,
and
this
is
not
only
for
the
for
the
programming
language.
Also,
the
application
program,
interfaces
of
openmpr
or
an
openscc
have
rules
to
lead
to
deal
with
a
multi-dimensional
array
and
with
data
layout,
okay.
So,
let's
take
a
look
at,
for
instance,
different
declarations
of
this
array.
A
If
we
have
a
logical
matrix
of
three
by
three
elements
and
we
declare
it
in
c
as
a
double
array
of
three
by
three.
Essentially,
this
is
using
statically
allocated
memory,
both
in
c
and
fortran.
So
the
language
guarantees
that
all
the
nine
elements
will
be
stored
and
allocated
consecutive
memory
in
our
programs,
and
this
is
good
because
all
the
data
that
needs
to
be
transferred
to
the
gpu,
for
instance,
are
in
consecutive
memory
locations.
A
We
can
do
that
in
one
single
transaction
in
in
memory,
so
we
just
need
to
consider
that
cc,
plus,
plus
and
fortran
have
different
rules.
The
data
within
the
consecutive
memory
region
changes
the
position
of
the
same
data
and
once
in
c
consecutive
rows
in
consecutive
number
of
positions
in
fortran
consecutive
rows,
columns
and
consecutive
memory
positions.
A
A
What
this
actually
means
is
that
the
nine
elements
of
our
logical
array
are
stored
in
consecutive
positions,
but
for
its
role
in
in
this
in
this
case.
So
what
we
have
is
the
first
column
row
in
consecutive
memory,
the
second
row
in
consecutive
memory,
but
between
rows.
We
don't
have
guarantee
that
all
the
data
will
be
stored
in
consecutive
memory.
So
we
need
an
auxiliary
array
to
actually
keep
track
of
the
pointers
that
point
to
the
beginning
of
its
row.
So
this
is
essentially
what
we
do
when
we
use
dynamically
allocated
to
the
arrays.
A
So
in
the
end
we
are
responsible
for
allocating
the
memory
we
are
responsible
for
setting
the
correct
values
in
the
pointers
that
point
to
the
beginning
of
the
memory
positions.
So
when
dealing
with
openmp
openscc
with
data
transfers,
we
are
also
responsible
for
dealing
correctly
with
the
pointers
that
point
to
the
elements
in
the
in
the
malloc
arrays.
A
So
when
we,
when
you
look
at
real
codes,
you
in
between
the
statically
located
arrays
that
we
have
here
and
the
double
pointers,
for
instance
the
fully
dynamically
located
arrays.
What
we
observe
is
that
we
tend
to
use
intermediate
code
representations
that
somehow
has
half
the
advantages
or
and
the
pros
and
the
cons
of
statically
allocated
arrays
and
dynamic
allocated
arrays,
let's
consider,
for
instance,
this
alternative
way
of
representing
the
data.
A
What
we
have
is
we
can
preserve
the
the
ease
of
use
of
multi-dimensional
array
notations.
You
can
see
in
this
loop
that
we
can
use
the
notation
a
and
between
brackets
fourth
dimension,
I
access
to
the
eighth
row
and
in
the
second
dimension
I
access
to
the
jth
element
within
the
eighth
row.
So
I
don't
have
to
change
the
way.
A
In
contrast
in
content,
what
happens
is
that
we
need
to
adapt
the
computation,
the
loops
instructions
of
our
code
to
actually
explicitly
use
this
new
data
structure
representation.
So
here,
instead
of
having
access
to
the
position
a
a
row,
I
column
j.
What
we
need
is
to
actually
explicitly
code
the
element
that
we
will
be
accessing
from
the
beginning
of
the
first,
the
first
element
of
this
array.
This
is
what
we
see.
A
Typically,
as
a
of
I
multiplied
by
the
number
of
elements
in
a
row
plus
the
coordinate
of
the
column
that
we
want
to
access
to.
Okay.
So
essentially,
we
can
see
that
we
as
programmers
we
can.
We
have
different
alternative
ways
of
designing
our
data
structure
to
start
to
actually
store
all
the
data
points.
Until
until
this
moment
we
have
seen
a
dense
representations
of
tense
matrices.
A
What
this
means
is
that,
in
the
data,
we
see
all
the
elements
of
the
array
stored
of
the
matrix
stored
in
memory
independently
of
the
value
if
they
are
zero,
we
store
0
values
if
they
are
different
from
0.
We
store
this
different
from
0
values,
but
what
happens
in
also
in
many
real
applications
is
that
the
data
structure
needs
to
be
adapted
to
huge
large
matrices,
with
a
big
number
of
zero
elements.
A
So
here
many
times
in
different
scientific
domains,
we
use
sparse
matrix
representations
that,
in
the
end,
they
are
making
the
axis
more
complicated,
because
we
have
all
the
data
stored
in
consecutive
memory
positions
as
we
had
in
dense
arrays.
But
now
we
are
not
allocating
memory
for
zero
values,
because
we
know
that
those
elements
that
are
not
allocated
are
essentially
implicit,
er,
zero
values,
but
this
makes
more
complicated
to
know
exactly,
which
is
the
position.
A
One
call
index
matrix
that
stores
the
position,
the
column
position
within
the
row
of
the
matrices,
and
it
uses
an
auxiliary
array
that
indicates
they
start
the
position
where
each
of
the
rows
starts.
So
look
at
the
right.
We
are
just
traversing
all
the
elements
of
the
array,
but
look
at
the
complexity
of
how
this
needs
to
be
coded
again
by
choosing
a
data
representation,
either
dense
or
sparse,
to
represent
in
our
cc
plus
fortran
programs.
Our
logical
matrices.
A
We
need
to
adapt
the
code
to
actually
use
that
representation.
So
when
it
comes
to
coding
for
gpus,
the
key
question
here
is:
okay.
How
does
this
affects
in
practice
to
open
npr,
open
sec
practice?
In
particular?
How
does
this
affect,
for
instance,
to
data
transfers?
We
know
that
we
need
to
code
the
application
being
aware
of
the
data
structure
that
we
are
using,
but
what
happens
with
the
data
structure?
A
So
here
you
can
see
that
we
will
use
an
example
in
the
lab
that
is,
we
will
use
a
representation
of
a
2d
matrix
using
the
double
pointer
representation.
This
essentially
this
representation.
We
see
here
in
the
slide
12
and
what
we
see
here
on
the
right
is
different
ways
that
you
need,
in
which
you
need
to
manage
the
double
pointed
data
structure
in
openmp
and
openscc
in
openhcc.
You
can
see
that
you
have
in
the
copying
copy
out
and
copy
out
clauses.
A
You
have
the
name
of
the
array,
and
you
also
have
this
notation
for
array
shapes,
so
you
are
specifying
how
many
dimensions
the
array
has
in
this
case,
these
arrays
have
two
dimensions:
a
b
and
c
and
you're
also
specifying
the
first
position
and
the
number
of
elements
in
each
dimension.
So
you
are
telling
that
array
array
a
is
consists
of
m
multiplied
by
p
columns
elements
in
the
array.
A
So,
from
this
perspective,
openscc
provides
a
notation
that
is
quite
easy
to
use
and
easy
to
understand,
but
look
at
look,
for
instance,
at
the
openmp
implementation
in
openmp
implementation.
The
recommendation
is
to
explicitly
transfer
its
range
of
a
consecutive
elements
explicitly
using
a
enter
data,
a
clause
or
directive
in
the
code.
A
So
here
you
can
see
that
we
need
to
transfer
the
array
of
pointers
of
the
double
pointer
and
then
we
need
to
transfer
all
the
rows
independently
so
that
on
the
gpu
side,
the
pointers
on
the
matrix
of
pointers
are
correctly
set
by
openmp.
Okay.
So
somehow
we
want
to
show
here
in
this
lab
is
that
whenever
we
choose
the
data
structure
to
represent
multi-dimensional
arrays,
this
has
an
impact
on
the
way
we
code,
our
algorithms
in
the
in
the
program,
but
also
it
has
an
impact
on
how
we
need
to
use.